







 本文详细介绍了EDA(Exploratory Data Analysis)在数据挖掘中的重要性,包括查看数据集基本信息、数据统计、缺失值处理、预测值分布分析、特征分析等方面。通过使用pandas、describe()、info()、matplotlib、seaborn和missingno等工具,对数据进行全方位探索,以发现数据特性、异常值和特征间关联,为后续的数据处理和建模提供指导。作者分享了个人经验,强调了系统化分析的重要性。
本文详细介绍了EDA(Exploratory Data Analysis)在数据挖掘中的重要性,包括查看数据集基本信息、数据统计、缺失值处理、预测值分布分析、特征分析等方面。通过使用pandas、describe()、info()、matplotlib、seaborn和missingno等工具,对数据进行全方位探索,以发现数据特性、异常值和特征间关联,为后续的数据处理和建模提供指导。作者分享了个人经验,强调了系统化分析的重要性。
数据的探索性分析(EDA)
1.EDA要做些什么
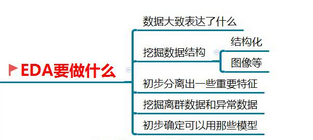
2.fork from Datawhale 零基础入门数据挖掘-Task2 数据分析 个人收获
(1)要养成看数据集的head()以及shape的习惯,这会让你每一步更放心, 如果对自己的pandas等操作不放心,建议执行一步看一下,这样会有效的方便你进行理解函数并进行操作
(2)总览数据概况:通过describe()来熟悉数据的相关统计量,通过info()来熟悉数据类型
- describe有每列的统计量,个数count、平均值mean、方差std、最小值min、中位数25% 50% 75% 、以及最大值 。看这个信息主要是瞬间掌握数据的大概的范围以及每个值的异常值的判断,比如有的时候会发现999 9999 -1 等值这些其实都是nan的另外一种表达方式,有的时候需要注意下
- info 通过info来了解数据每列的type,有助于了解是否存在除了nan以外的特殊符号异常
(3)判断数据缺失和异常

通过以下两句可以很直观的了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于 nan存在的个数是否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果nan存在的过多、可以考虑删掉。
下一步统计nan的个数,这里使用了sort_value函数来进行排序,设置inplace=True来使排序后的结果替换原来的数据,默认值为False。

Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
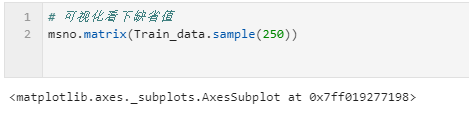
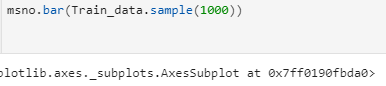
missingno库提供了一个灵活易用的可视化工具来观察数据缺失情况,是基于matplotlib的,接受pandas数据源。
可视化缺省值的分布,最右面表示数据的完整度,在数据较少情况下用矩阵,较多情况下使用条图。
import missingno as msno

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1583
1583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









