









0.前言
谈到数据结构,用的最多的,也是最基本的两种,就是数组和链表。为什么我们讲HashMap之前,要先讲一下数组和链表呢?这要从他们两个的特点说起。
首先简单地说一下数组,它的特点有很多:只能用来存储同一类型的东西;长度是固定的,一旦声明了长度属性,就不能修改(数组的长度不等于数组内存储的元素的个数);数组在内存中的存储是连续的;数组内的元素通过下标(索引)来引用。
所以,我们可以得到这样的结论:数组的查找和修改速度很快,因为可以直接通过下标来引用,但是增加和删除上不是很方便,因为数组的长度不能修改。很多时候,当要存储的元素超出数组的长度时,只能通过新建一个更长的新数组来代替原来的数组的方法。
而链表作为和数组齐名的两种最基本的数据结构之一,它在很多方面与数组类似,主要的区别是,链表是链式结构,元素在链表中的存储是不连续的,它们之间通过指针依次连接。所以,链表的查找和删除很慢,要从根节点开始依次查找,但是增加和删除很方便,只需要改变指针指向的元素就可以了。
基于它们两个各有优缺,我们的主角终于可以出场了,兼具数组与链表的优点又巧妙地避开缺点的HashMap。
1.正文
在应用层面,HashMap就具有很大的优点。它不像数组那样只能用连续的整形数字作为索引,而是可以使用任意类型的对象。这些用作索引的对象称为“键”(Key),每个“键”在表中对应一个“值”(Value),组成一个“键值对”(”Associates the specified value with the specified keyin this map.” ---源码中的描述),可以更直观的储存所有类型的元素。
在存储时,HashMap里面的元素不是连续的,元素顺序也和存放顺序无关。而是根据要存储的Key,先进行一步hash计算(” Computeskey.hashCode() and spreads (XORs) higher bits of hashto lower. ”---源码中描述的具体的hash计算过程),得到他在HashMap中的索引(散列)位置,然后将Key和Value的值存储在该位置。
简单来说,HashMap是通过键的映射找到表中的某一个位置进行存储的。因此,根据这个关系,在进行查找操作时,可以不用遍历的方法直接通过计算得到索引位置(“Returnsthe value to which the specified key is mapped”---源码中对get()方法的描述),弥补了数组和链表在时间上的缺陷。
附:hash计算源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
附:存储元素的put方法源码:
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
*...
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);//putVal()是具体进行存储的方法,这里只是理解它首先进行了hash计算,具体的源码在下面会讲到。
}附:取出元素的get方法源码:
public Vget(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null :e.value;// 取出元素时同样先进行了hash计算
}再深入一点,元素在HashMap中到底是如何存储的?继续参考源码,我们找到上面出现过的putVal()方法。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;// 数组为空或者长度为零,增加数组的长度
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//索引位置为空时,将新节点存到数组的该位置
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();//节点超出限度,调用resize()方法增加数组长度
afterNodeInsertion(evict);
return null;
}
这段代码比较重要,所以我完整的拷贝了上来。我们可以发现,所有元素都会以节点形式进行存储,其中包含了Key-Value等相关信息。当我们要存储一个新的节点时,系统首先会检查一个叫做table的对象,然后我们看到table的声明和部分描述是这样的:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;很明显,这是一个用来存储节点类型元素的数组。也就是说,在我们的HashMap里面,也用到了数组,而且会首先考虑将数据存储在数组里面。我们经过hash计算得到了一个索引位置后,会检查数组中该位置是否为空。如果该位置为空,会直接将新节点存储在该位置;如果不为空,首先判断索引位置处的旧节点与新节点的Key是否相同。如果相同,替换旧节点;如果不同,在该索引位置的基础上,建立一个链表,将新节点存储为这个链表的最后一个节点,在这之前也要保证原来链表中不存在相同Key的节点。可以参照下面的图片进行理解。
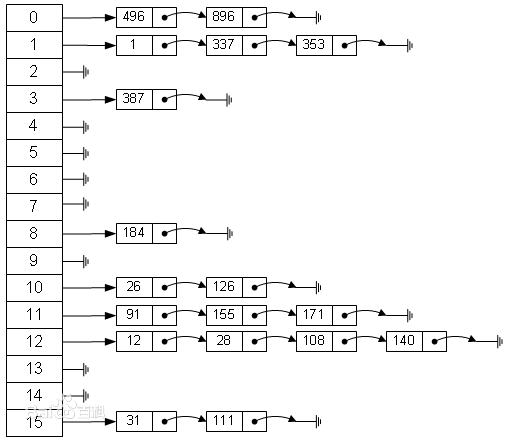
由此可见,HashMap原则上是可以不断存储新的节点,但是随着节点的增加,同一索引位置的节点太多,就不能发挥HashMap的优势。
因此,HashMap必须解决的一个问题就是“哈希冲突”:在不断的存储过程中,对于两个不同的Key,进过计算,对应同一个索引(散列)位置的现象,我们就叫做“哈希冲突(碰撞)”。
这个问题在系统的HashMap中已经有了一些特定的解决方法,比如事先定义一个限度(threshold),每次添加新的节点之后,计算一下已存储的节点数,如果超出这个限度,就调用一次resize()方法,增加数组的长度,并将原来的节点进行一次rehash(),重新进行存储,来减小哈希冲突的影响。
2.实现
最好的学习方法就是动手!
为了加深理解,建议自己手写一个简单实现的HashMap,最好再与系统的比较一下,对比源码进行修改。下面是我简单实现的一个HashMap代码,包括了存放元素、获取元素、获取元素个数、删除元素最基本的几项功能。
public class myHashMap<K, V> {
int num = 0;// 存储的元素的个数
Object[] data;// 初始化一个长度为6的数组
float rate = 0.75f;// 因子
public myHashMap() {
data = new Object[6];
}
public myHashMap(int size) {
Object[] data = new Object[size];
}
/**
* 存放元素
*/
public void put(K key, V value) {
// 计算Hash值(索引)
int index = Hash(key);
// 创建节点
Node<K, V> node = new Node<K, V>(key, value);
// 判断索引位置是否为空
if (data[index] == null) {
data[index] = node;
num++;
} else {
node.next = (Node<K, V>) data[index];
data[index] = node;
// 判断是否为重复的键
// 若不重复 元素个数+1 ;
// 若重复 元素个数不变 (重复的没有被覆盖,只是排在了后面,不会被get到)
if (!node.key.equals(node.next.key))
num++;
}
}
/**
* 哈希计算
*/
public int Hash(K key) {
int index = key.hashCode() % data.length;
// System.out.println(index);
return index;
}
/**
* 获取元素
*/
public V get(K key) {
// 计算Hash值(索引)
int index = Hash(key);
// 得到索引位置的节点
Node<K, V> node;
if (data[index] != null) {// 判断索引位置是否存在节点
node = (Node<K, V>) data[index];// 若存在 找到key相等的节点并返回
while (!key.equals(node.key)) {
if (node.next != null)
node = node.next;
else{
return null;
}
}
} else {// 若不存在 输出一条语句 返回一个null
return null;
}
return node.value;
}
/**
* 获取元素个数
*/
public int size() {
return num;
}
/**
* 删除元素
*/
public void remove(K key) {
// 计算Hash值(索引)
int index = Hash(key);
// 得到索引位置的节点
Node<K, V> node = (Node<K, V>) data[index];
// 判断索引位置是否存在节点
if (node != null) {// 若存在 判断是不是第一个节点
if (key.equals(node.key)) {// 若是第一个节点 判断是否只有根节点
if (node.next == null) {// 如果只有根节点 直接将根节点设为空
data[index] = null;
num--;
} else { // 如果有其他节点 直接将数组的索引位置指向第二个节点
data[index] = node.next;
num--;
}
} else {// 若不是第一个节点 判断索引位置是否只有根节点
if (node.next == null)// 若索引位置只有根节点 且根节点的key不是要删除的key 输出一条提示语句
System.out.println("key不存在");
else {// 若索引位置有其他节点 则需要找到对应key的节点的上一个结点
while (node.next != null && !key.equals(node.next.key)) {
node = node.next;
}// 然后判断对应key的节点是不是最后一个节点
if (node.next.next == null) {// 若是最后一个结点,将它的前一个结点的下一个节点指向null
node.next = null;
num--;
} else {// 若不是 将他的前一个节点指向他的后一个节点
node.next = node.next.next;
num--;
}
}
}
} else {// 若不存在 输出一条提示语句
System.out.println("key不存在");
}
}
}
public class Node<K,V> {
K key;
V value;
Node<K,V> next;
public Node(K key, V value) {
super();
this.key = key;
this.value = value;
}
}3.总结
这篇文章从初学者角度,简单地介绍了一下HashMap的应用场景,存储原理,以及简单的源码分析和实现的示范。
在此基础上,我们还可以进一步地分析系统的HashMap及与之相似的 HashTable, HashSet源代码,了解一致性哈希、布隆过滤,寻找更有效的散列算法、rehash算法......通过拓展不断加深理解。















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









