






作者 | AmazingRoad 编辑 | 汽车人
原文链接:zhuanlan.zhihu.com/p/587140851
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
后台回复【标定工具】获取2D检测/分割/关键点,3D点云检测分割标注工具!
1什么是数据闭环
自动驾驶中的数据闭环,是指算法研发由case-driven转向data-driven的核心步骤。我大概整理了下数据闭环的链路,如下图所示:
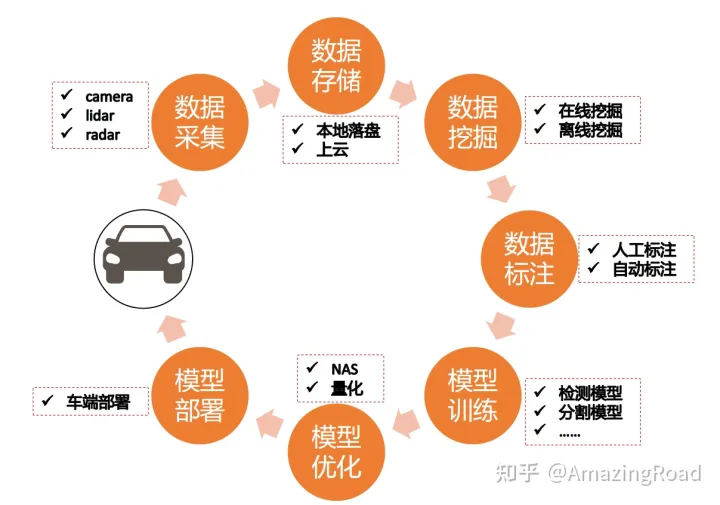
链路中的环节包含工具链路打通和算法开发两部分。
算法开发主要有数据挖掘、数据标注、模型优化这三部分。
这里面数据标注中的自动标注,即AutoLabeling是目前数据闭环中最为核心的部分。
数据挖掘和模型优化,也是需要攻克和解决的点,只不过从成本和效率上,目前优先级没有自动标注高。
2AutoLabeling方案
以下的讨论以目标检测任务为例。
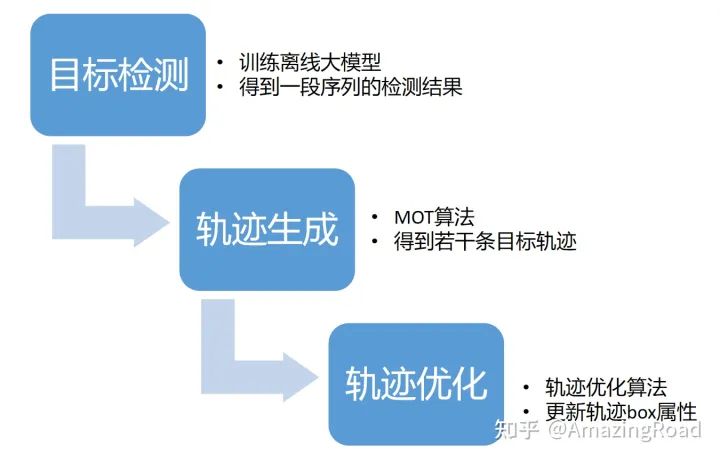
Pipeline
目标检测任务的主要pipeline流程包含目标检测、轨迹生成、轨迹优化三部分
其中目标检测模型、MOT算法,都有比较成熟的算法,所以AutoLabeling中创新点主要体现在轨迹优化这个步骤。
学术界的SOTA
目前关于AutoLabeling的完整方案方面的论文不是很多,这里面比较有代表性的有:
谷歌的Waymo在2021年发表的:《Offboard 3D Object Detection from Point Cloud Sequences》
Uber的ATG(Advanced Technology Group)在2021年发表的:《Auto4D: Learning to Label 4D Objects from Sequential Point Clouds》
Open MMLab在2022年发表的:《MPPNet: Multi-Frame Feature Intertwining with Proxy Points for 3D Temporal Object Detection》
下面对这三篇文章做了个简单地总结和对比:
| 论文 | 机构 | 轨迹优化的方法 | 发表年限 |
|---|---|---|---|
| Auto4D | Uber | BEV空间特征 | 2021.01 |
| Offboard3D | Waymo | Point-Based | 2021.03 |
| MPPNet | OpenMMLab | Former(基于Attention) | 2022 |
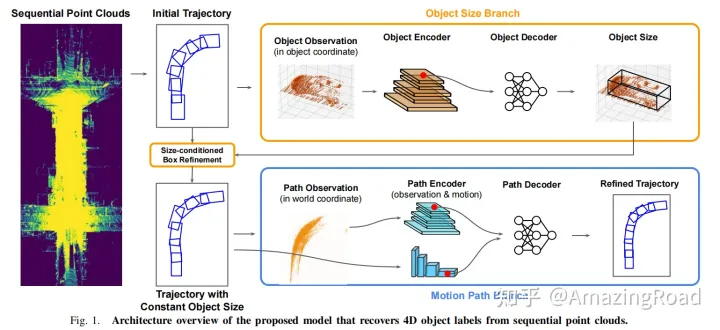
Auto4D的轨迹优化
Size Branch: 累积全轨迹点(时域信息忽略),BEV编码,得到全局的稳定size。
Update:基于最近corner align,更新全轨迹的box属性。
Path Branch:累积全轨迹点(保留时域信息,但时域和高度channel合并),BEV编码,得到相邻帧位移
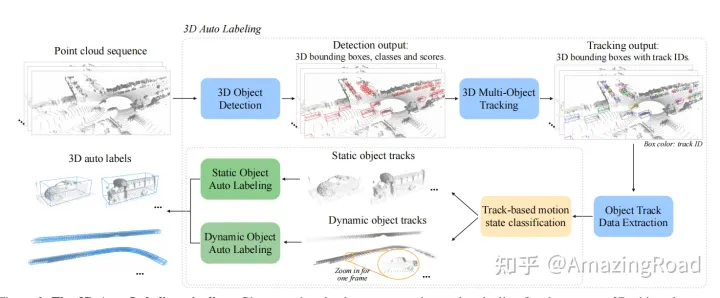
Offboard3D的轨迹优化处理
动静态判断:box中心点方差<1m/s^2,首尾帧中心点偏移<1m,则为静态,否则为动态。
静态轨迹优化:前背景分割网络对box周围的原始点进行分割,box回归网络得到box属性(基于PointNet)
动态轨迹优化:对于点进行前背景分割+点序列编码,对于框进行序列编码,最后加2层box回归网络。
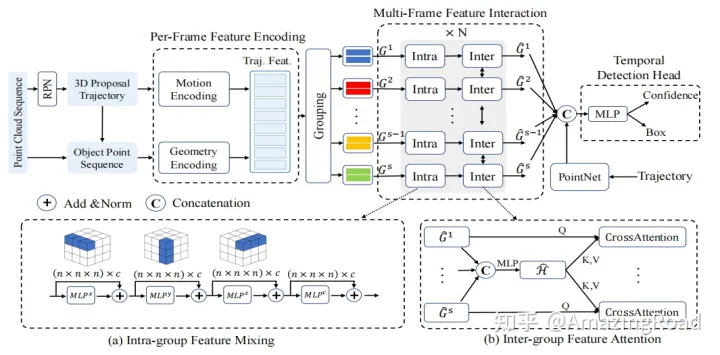
MPPNet
选取代理点:每个框均匀选择代理点(4x4x4)
单帧提取特征:提取几何特征、运动特征
组内特征编码:x、y、z、c通道分割使用MLP进行feature mixing
组间特征编码:使用Former结构,共享K、V,进行feature mixing
3D检测头:使用Tranformer Decoder
往期回顾
Make RepVGG Greater Again!揭示重参化量化崩溃根因并解决(美团)

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
















 2314
2314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









