






作者 | 柴可宁 编辑 | 智能车情报局
原文链接:https://zhuanlan.zhihu.com/p/636622001
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【数据闭环】技术交流群
本文只做学术分享,如有侵权,联系删文
01
前言
BEV算法的开发已经到了深水区,各家都投入了大量的精力去做bev的落地开发,其中一块最关键的就是如何高效的完成BEV的数据标注,无论是BEV 3D目标, BEV去高精地图或者是BEV Occupancy。
相比于车端的感知算法,自动标注系统更像是一个不同模块组成的系统, 充分利用离线的算力和时序信息,才能得到更好的感知结果, 实际落地的时候,对于工程师的能力要求上了一个档次,想要把这些大模型大系统玩转的好和高效,也是非常不容易的。
时隔一年,看到Chatgpt的横空出世和人工智能大模型的井喷式爆发,也看到了SAM的zero shot的迁移能力,感觉技术发展实在是太快了
参考Chatgpt的训练方式, 大规模无监督的预训练 + 高质量数据集做具体任务的微调, 可能也会成为量产感知算法下一阶段需要发力的方向。
记录一下一些看到的学术界新的自动标注的方案,好几个工作都来自AI Lab 和 业界顶尖的玩家,真的非常给力。
去年的时候分享的BEV的自动化数据标注方案V1.0 :《柴可宁:数据闭环的核心 - Auto-labeling 方案分享》
也对我们自己的实际业务,做一些总结和思考, 内容比较多,工作也比较忙,会抽空闲的时候分几次更新, 有很多不对的地方,欢迎大家补充讨论!
3d目标 auto-labeling - 基于长时序激光雷达
Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object Detection (图森)
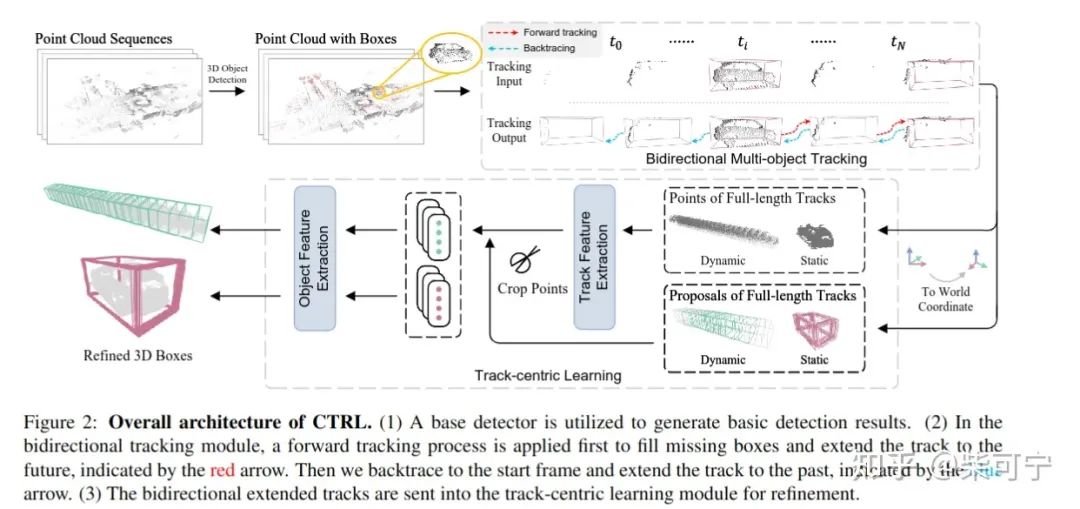
1、整体框架和之前的Auto4D, 3DAL都是差不多的,分为base detector + MOT + Refine三个模块, 在细节的实现上优于前面的方案
2、Base Detector 用了FSA, 这个地方也可以用任何的其他检测器,或者多模型做ensemble.
3、Tracking 模块采用了 Immotal Tracker, 并且做了forward tracking 和 backward tracking, 然后再将正反匹配的两次轨迹去重和组合,这个地方的核心目的是尽可能得到完整的连续轨迹, 会引入一些FP, 不过没关系,后续可以优化
4、Track-Centric Learning 是这篇论文的核心,和前作相比,有三个核心点:
-MIMO(Multi Input Multi Ouput): 3DAL 是Multi input Single output, 这个会造成一个问题就是前后的尺寸不连续, 人类标注员在标注的时候,一般都会选择整个物体序列中点云比较好的时刻,确定尺寸,然后确保全时序尺寸一致,这个标注在实际中也是非常重要的,如果时序尺寸不一致,对训练出来的结果尺寸前后容易跳变
-动态静态不分类,前作中对于物体动态静态先做了分类,然后单独处理。本文中,觉得没有必要,反而减少了物体的多样性,阻碍了数据的泛化。比如物体低速运动,或者一个人转圈啥的。所以在流水线中统一处理,大大简化了流程 (不过这个点,我们在实操过程中发现,如果物体是静态的,定位比较准确的话,直接使用世界坐标系插值会更加准确,基本都可以达到0.9甚至0.95以上的IOU,如果refine容易让物体的IOU反而有一点下降)
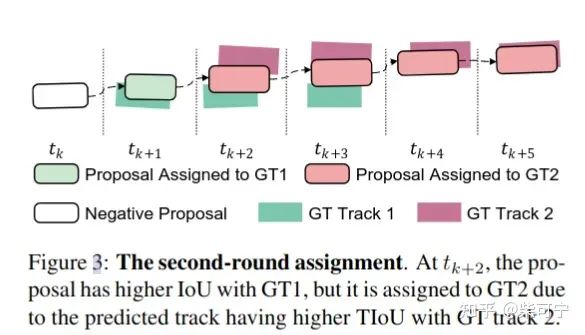
-设计了 full sequence track iou 来做轨迹的第一阶段匹配, 二阶段匹配再做轨迹内部的gt和proposal的关联,这样可以减少误匹配,鼓励更加高质量的IOU的Proposal作为正样本,并且具有时序连续性,让模型往整体轨迹最优的方向去做优化。
整体来说,效果能有大幅提升,实现上也更加简介高效,并且速度也比3DAL 快20倍(MIMO的设计和序列点云统一化坐标系的处理和特征提取模块,在训练可以用批处理并行)。
但是有一个点,无论精度多高的自动标注系统,还是需要人来做一些质检,才能用于量产中的项目。如果能在模型输出的时候,有一个flag, 能让质检员知道,哪些框需要检查,哪些是绝对OK的, 可以大大增加质检的效率,否则质检员很多时间还是得看一下每个bbox的质量,是否贴边啊啥的,其实还是比较费时间的。微调一个框和重新标注一个框,其实速度差不多。
DetZero: Rethinking Offboard 3D Object Detection with Long-term Sequential Point Clouds (AI LAB)
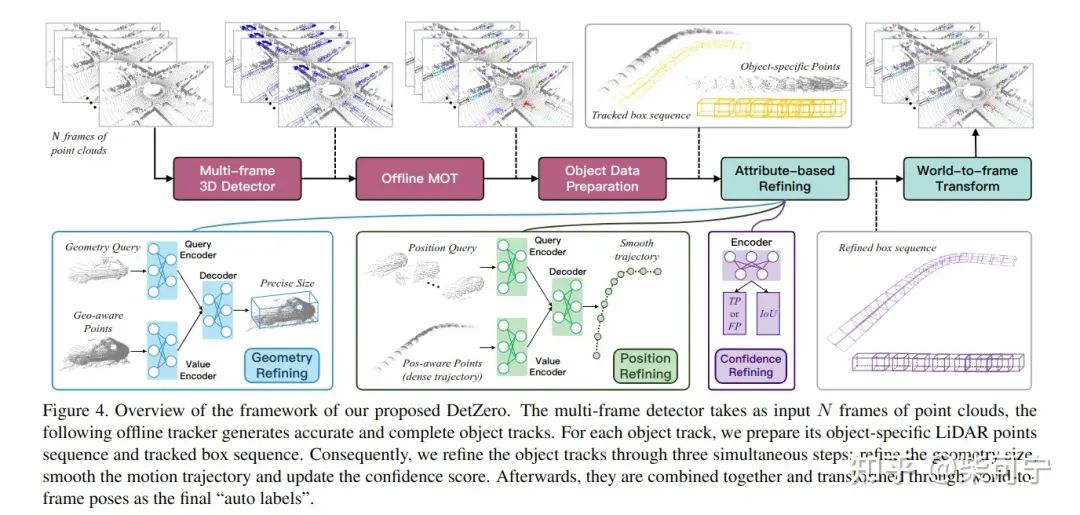
1、整个框架也是差不多的, 3段式, 检测 + MOT + Refine , 核心点在于强调上游的高召回率和跟踪, 下游强调细致的高精度优化
2、检测 采用了 centerPoint, 采用了多帧点云融合,TTA, Model Ensemble
3、MOT 也参考了Immotal Tracker 的一些思路, 前向和后向都做一次跟踪, 然后采用WBF来融合两次跟踪的框
4、核心是接下来的refine模块, 将下游优化分为三个目标, 形状优化(时序一致), 轨迹优化(时序平滑), 得分优化 (更容易筛选高质量框)
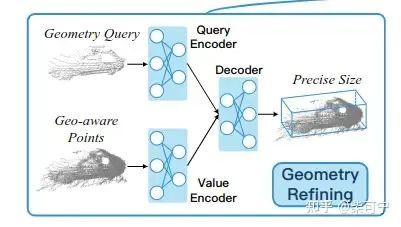
-Geometry Refine:
将一个轨迹内的点云都转换到物体中心坐标系,
Porposal to Point Encoding: 对每个点进行特征增强,加入每个点到bbox 6个面的距离 (这个地方参考之前的Lidar2阶段网络中的一些操作, 让模型知道点和框的关系,相当于把单帧的点云和框做了联合编码 )
在所有点云中,随机选取t个样本, 每个样本有对应的256个随机选择的点
每个点也是按上述 Proposal-to-Point Encoding 增强的
用PointNet 给选取的T个样本提取特征,生成初始几何查询 Q_geo
用PointNet 给全部的点云提取特征, 得到 Key_geo 和 V_geo
通过万能的 transformer来回归目标size(l,w,h)对应的embedding , 得到lwh
-Position Refine:
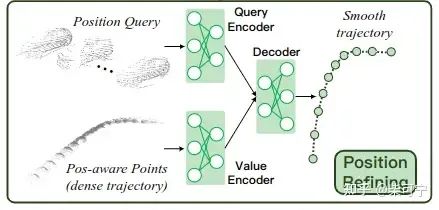
Position-aware Points Generation:
对于第i个目标, 随机从轨迹中挑选一个作为新的局部坐标系。然后将其他轨迹的所有框都转换到这个坐标系。
然后从每一帧选取随机固定的点,对于每个点,额外计算每个点到8个角点之间的距离, 从而得到27维的特征向量。
便于训练,所有的对象轨迹都用零填充到相同的长度
这个点的两个随机操作非常重要,相当于做了数据的増广, 一个是随机选择轨迹中的任意一个位置作为新的局部坐标系,一个是随机选取一些固定的点。
Attention-based Local-to-Global Position Interaction:
和geometry refine 中的query一样, Q_pos = Lx D, L代表轨迹长度,D代表特征,包含了 position-aware feature 和 confidence score
用PointNet 提取整条的目标轨迹, 得到 K_pos 和 V_pos, n_pos 代表点云的长度
Q_pos 首先送到自注意力模块中, 来捕获自身和其他模块之间的相对距离, 此外,在每个查询的位置应用一维掩码来权衡自注意力
Q_pos 和 K_pos, V_pos 送到corss_attention模块中,对局部到全局上下文位置进行建模
最后预测局部坐标系下面 dx, dy, dz的offset偏亮,以及theta 的航向角offset
Confidence Refine Module:
因为前面 3d detctor + offline tracking 会生成很多的3D框, 可能很多是FP或者是低IOU的, 因此,引入了一个置信度参考模型(CRM),
第一个是分类分支,通过更新分数来确定TP 还是 FP。如果预测 和gt 的IOU 低于一个值, 则为负样本, 如果高于某一个值,为正样本, 其它bbox没有影响
第二个是IOU预测分支, 预测回归到底有多少IOU。
将两个分支的结果融合,得到最后的更新分数
通过三个模块的refine优化,在高IOU下的表现非常优化,且输出得分是和TP/PF和IOU高低挂钩的。但是没有报告执行的时间,整体思路更加接近auto4d, 不过用transformer模块来做建模。
3d目标 auto-labeling - 基于SAM的2次开发
基于强大的SAM, 在3d点云标注方向,也有很多很有意思的2创, 尝试利用SAM强大的泛化能力,自动化的完成标注。
SAM3D: Zero-Shot 3D Object Detection via Segment Anything Model (百度)
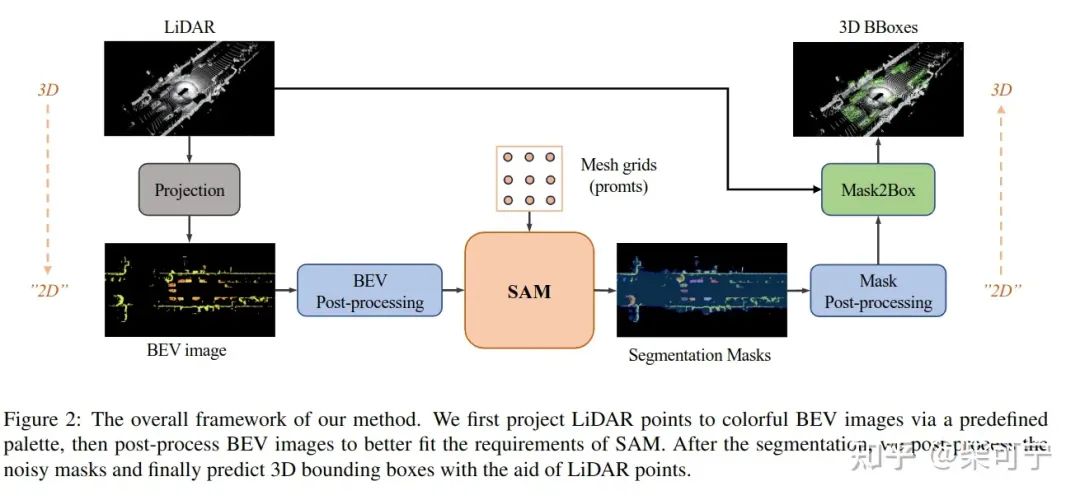
将点云做bev投影映射,转换成bev Image
对于bev image做预处理, 对于intensity啥的处理一下
利用sam + mesh girds promts 完成语义分割
将分割后处理, 得到2D bbox, 然后在通过点云,得到3d bbox
非常有意思的尝试,但是估计离实际使用还是有比较大的距离
效果不是特别好, 且很多问题无法解决,比如树下站着几个人,bev下是无法标注的。
不过可以预见,基于sam的标注,在3d领域肯定会有更好的应用。
3D-Box-Segment-Anything - (AI Lab)

在图像里面点一个位置,自动得到3dbox + mask. 细节可以看这个视频:
https://www.techbeat.net/talk-info?id=768&utm_campaign=0426%E9%99%88%E7%8E%89%E5%BA%B7&utm_medium=%E7%9F%A5%E4%B9%8E&utm_source=%E7%9F%A5%E4%B9%8E&gio_link_id=LPdzg0q9
实际试了一些,效果还可以,但是非常依赖于检测网络 VoxelNext的结果,这也就注定了这个在工业界肯定是不太够的,大量的框实际中还需要做很多调整。
但是sam这个潜力真的很大,在3d领域还需要一些优化和适配,大模型标注对于传统的手工标注一定是降维打击的。
Segment Any Point Cloud Sequences by Distilling Vision Foundation Models - Shanghai AI Lab
待更新!
3D去高精度地图 auto-labeling - 基于激光雷达
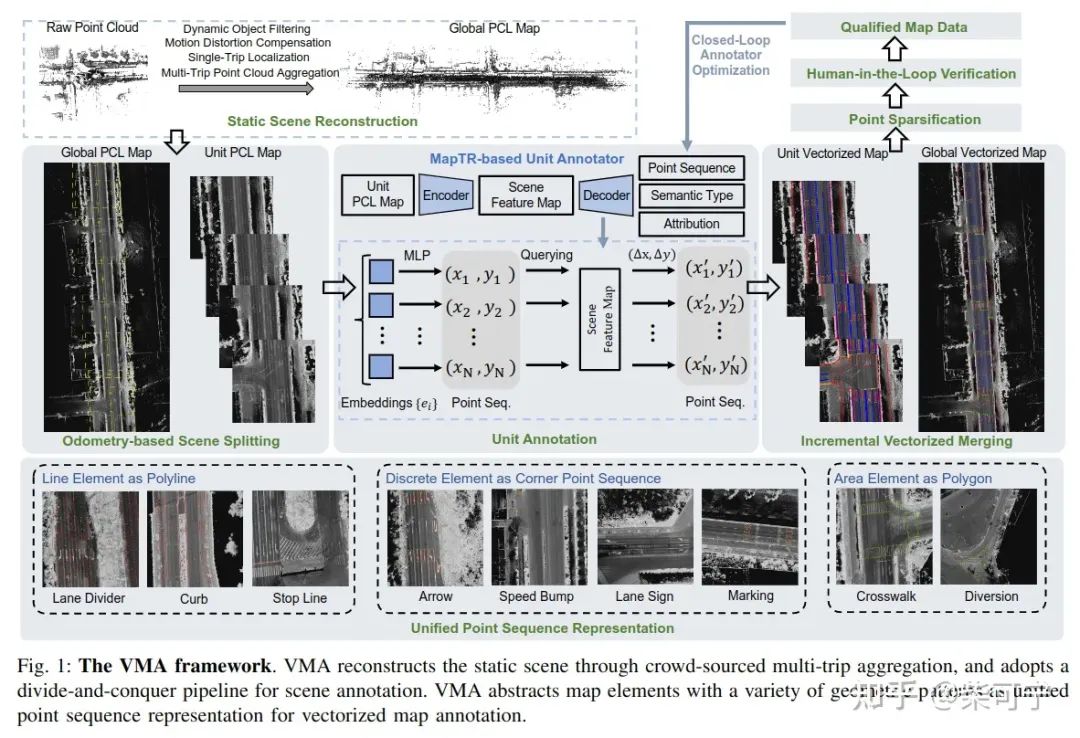
VMA: Divide-and-Conquer Vectorized Map Annotation System for Large-Scale Driving Scene (地平线 & HUST)
3D 去高精度地图 auto-labeling - 基于纯视觉BEV
MV-Map: Offboard HD-Map Generation with Multi-view Consistency (复旦大学)

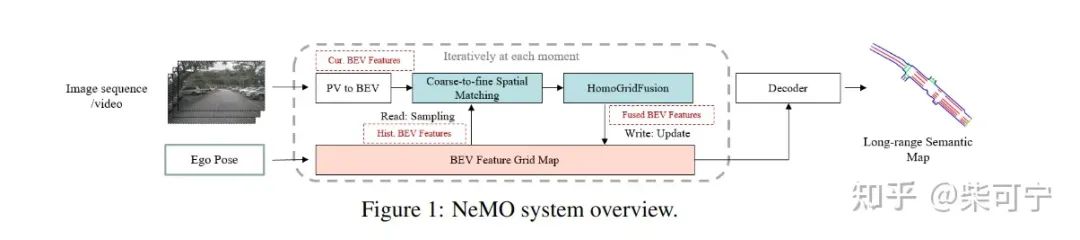
NeMO: Neural Map Growing System for Spatiotemporal Fusion in Bird's-Eye-View and BDD-Map Benchmark (华为)
3D 场景重建预训练 - 基于视觉 Occupancy
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction (PKU)

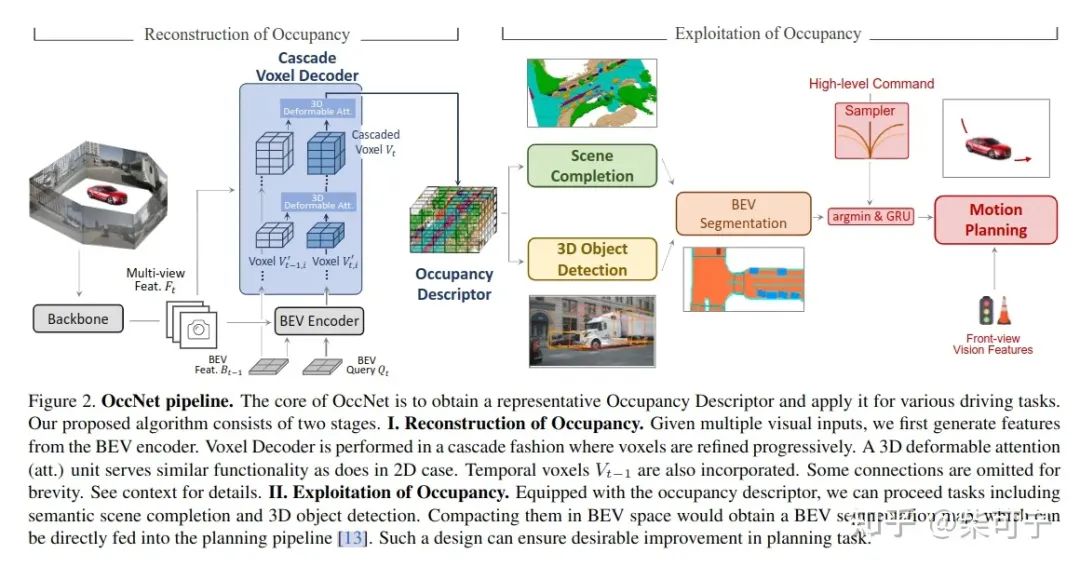
scene as Occupancy (AI-Lab )
3D 场景重建预训练 - 基于激光雷达
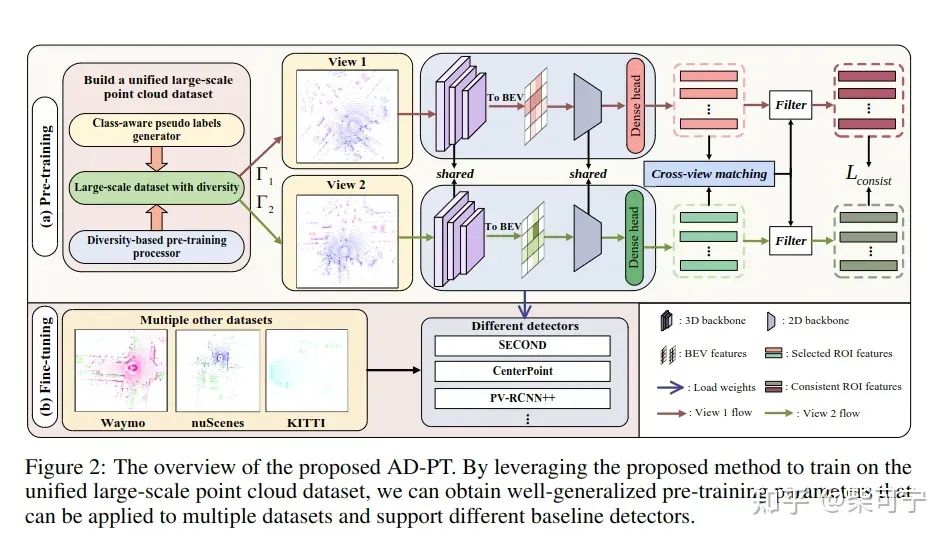
AD-PT: Autonomous Driving Pre-Training with Large-scale Point Cloud Dataset (AI-Lab)
ALSO: Automotive Lidar Self-supervision by Occupancy estimation (法雷奥)

3D场景重建预训练 - 基于Nerf
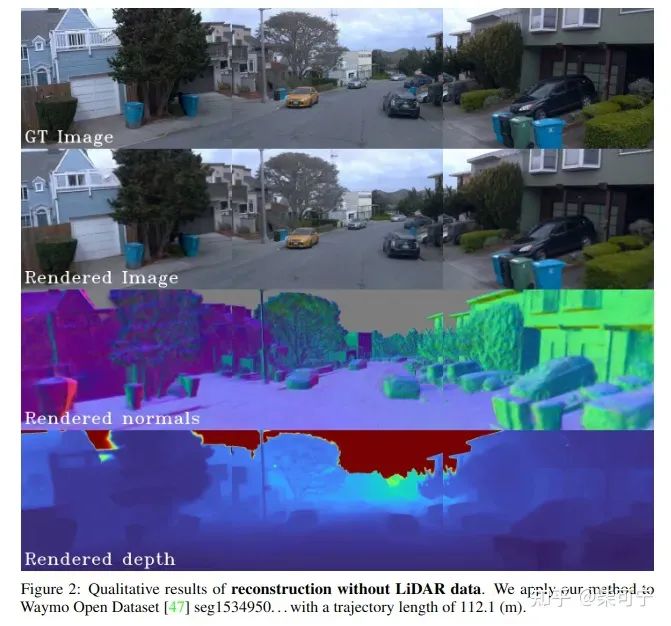
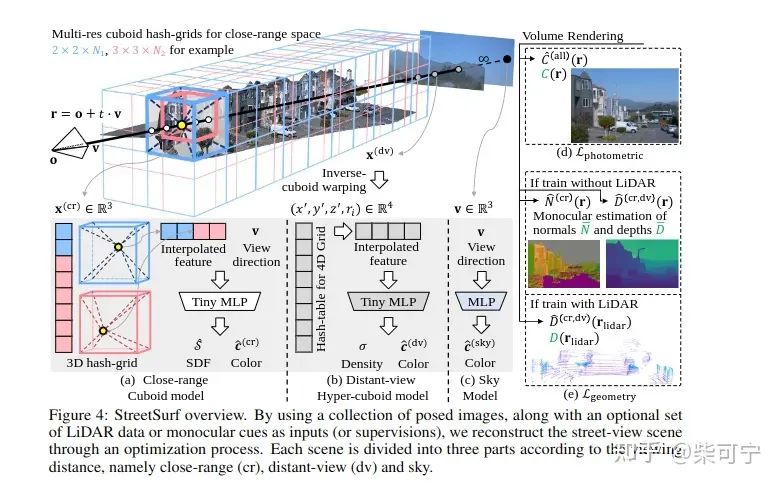
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views (Shanghai AI Lab)
Reference:
Guo, Jianfei, et al.StreetSurf: Extending Multi-View Implicit Surface Reconstruction to Street Views. June 2023.
Boulch, Alexandre, et al. ALSO: Automotive Lidar Self-Supervision by Occupancy Estimation. Dec. 2022.
Yuan, Jiakang, et al. AD-PT: Autonomous Driving Pre-Training with Large-Scale Point Cloud Dataset.
Tong, Wenwen, et al. Scene as Occupancy.
Min, Chen. Occ-BEV: Multi-Camera Unified Pre-Training via 3D Scene Reconstruction.
Zhu, Xi, et al. NeMO: Neural Map Growing System for Spatiotemporal Fusion in Bird’s-Eye-View and BDD-Map Benchmark.
Xie, Ziyang, et al. MV-Map: Offboard HD-Map Generation with Multi-View Consistency.
Chen, Shaoyu, et al. VMA: Divide-and-Conquer Vectorized Map Annotation System for Large-Scale Driving Scene. Apr. 2023.
Liu, Youquan, et al. Segment Any Point Cloud Sequences by Distilling Vision Foundation Models.
Chen, Yukang, et al. VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking.
Zhang, Dingyuan, et al. SAM3D: Zero-Shot 3D Object Detection via Segment Anything Model. June 2023.
Ma, Tao, et al. DetZero: Rethinking Offboard 3D Object Detection with Long-Term Sequential Point Clouds. June 2023.
Casia, LueFan. Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR Based 3D Object Detection.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近2700人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦语义分割、车道线检测、目标跟踪、2D/3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、在线地图、点云处理、端到端自动驾驶、SLAM与高精地图、深度估计、轨迹预测、NeRF、Gaussian Splatting、规划控制、模型部署落地、cuda加速、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









