






作者 | 自动驾驶专栏 编辑 | 自动驾驶专栏
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取

论文链接:https://arxiv.org/pdf/2305.18510.pdf

摘要

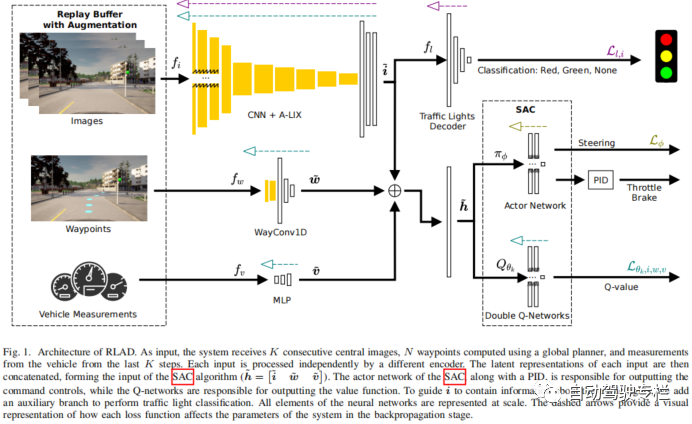
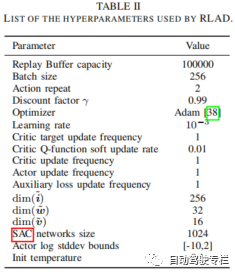
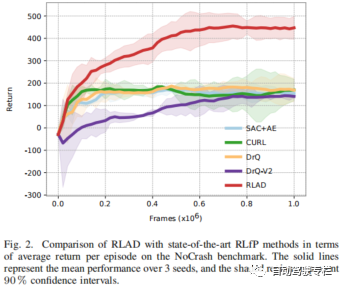
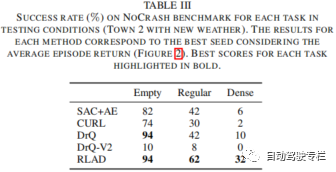
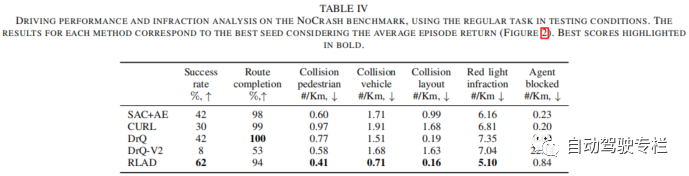
本文介绍了RLAD:城市环境中自动驾驶从像素进行强化学习。强化学习(RL)应用于自动驾驶(AD)中的当前方法着重于从驾驶策略训练中解耦感知训练。主要原因是要避免将卷积编码器与策略网络一起训练,众所周知,这将带来有关采样效率、退化特征表示和严重过拟合的问题。然而,这种范式将导致环境表示与下游任务不一致,从而可能导致次优的性能。为了解决这一限制,本文提出了RLAD,它是首个应用于城市自动驾驶领域的从像素进行强化学习(RLfP)方法。本文提出了若干技术来增强RLfP算法在该领域的性能,包括:i)利用图像增强和自适应局部信号混合(A-LIX)层的图像编码器;ii)WayConv1D是一种路径点编码器,其使用1D卷积来利用路径点的2D几何信息;iii)辅助损失来增加交通信号灯在环境的隐层表示中的重要性。实验结果表明,RLAD在NoCrash基准测试上显著优于所有最先进的RLfP方法。我们还对NoCrash-regular基准进行分析,结果表明,RLAD在碰撞概率和红灯违规方面均比所有其它方法表现更好。

主要贡献

本文的主要贡献总结如下:
1)本文提出了RLAD,这是首个在基于视觉的城市自动驾驶(AD)领域中使用增强学习(RL)同时学习编码器和驾驶策略网络的方法。本文还表明RLAD在该领域中显著优于所有最先进的RLfP方法;
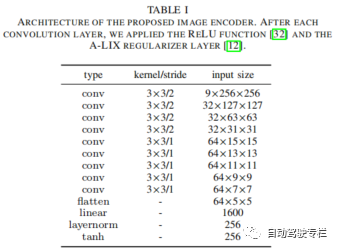
2)本文引入了一种图像编码器,该编码器利用图像增强和自适应局部信号混合(ALIX)层来最小化编码器的严重过拟合;
3)本文提出了WayConv1D,它是一种路径点编码器,使用2x2内核的1D卷积来利用路径点的2D几何信息,这显著提高了驾驶的稳定性;
4)本文对基于视觉的城市自动驾驶(AD)领域中最先进的RLfP进行了全面的分析,其中我们表明主要的挑战之一为遵守交通信号灯。为了解决这一限制,在图像的隐层表示中加入专门针对交通信号灯信息的辅助损失,从而增强了其重要性。

论文图片和表格



总结

本文引入了RLAD,它是基于视觉的城市自动驾驶(AD)领域中首个使用强化学习(RL)同时学习编码器和驾驶策略网络的算法。本文方法显著优于该领域中所有RLfP最先进的方法。尽管本文方法在端到端的城市自动驾驶(AD)中还不能与最先进的方法竞争,但是我们相信RLAD可以将RLfP应用于城市自动驾驶(AD)领域。与那些从策略网络中解耦编码器的方法相比,同时学习编码器和策略网络的方法在MuJoCo模拟器中的连续控制任务中表现出更好的性能。基于这些信息,我们有理由预计,城市自动驾驶(AD)领域中将出现类似的模式,我们相信RLAD是实现这一目标的第一步。
往期回顾
史上最全综述 | 3D目标检测算法汇总!(单目/双目/LiDAR/多模态/时序/半弱自监督)
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









