






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到自动驾驶我睡觉来分享个人学习Occupancy Network的经验总结,纯干货!如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【占用网络】技术交流群
自动驾驶之心 · 特约解读 | 自动驾驶我睡觉
编辑 | 自动驾驶之心

挑战赛地址:https://opendrivelab.com/AD23Challenge.html#Track3
近期位于第三赛道的占据预测竞争十分激烈,小编个人认为主要是三个方面(也是唯一没有干过美丽国的赛道),现在无论是基于环视的还是前视的,无论是纯激光的,还是纯视觉,还是多传感器融合的,暂且不说,就仅仅聊聊近期感受。
1.2022 CVPR上,特斯拉宣布将在其自动驾驶车辆中发布一种全新的算法。这个算法被命名为Occupancy Networks,任务的提出是认为此前的3D目标检测所检测出的3D目标框,不足描述一般物体(数据集中没有的物体),在此任务中,则把物体切分成体素进行表达,要求网络可以在3D体素空间中,预测每个体素的类别,可以认为是语义分割在3D体素空间的扩展任务,具体预测图如下图所示。

2.自动驾驶领域数据集的人工标注成本偏高,少则百万多则不计其数3.大模型的加入使得学术方向再大模型方向青睐有佳,单对于中小厂的落地,少则半年(半年之后不知道又出什么新的方向了)
对于网络上很多总结性的文章,很多作者都不发表感受,不懂他们好像只是知识的搬运工,或者是纯纯的翻译总结机器,还不如直接让GPT帮你读了总结来的快。看起来发言高大上,其实就是糊弄小白的论文翻译机器
本文从下面几个方面来聊聊最近看了这些占据预测的资料的感受以及想要落地的方向;
一.造数据(也就是我们说的制造训练的数据集)
在目前的阶段雷达点云数据的标注可谓风生水起,很多自动驾驶行业的公司因为需要有自己的数据集,大量的标准便出现了,随着近年transformer的崛起,需要更多的数据,所以在小编看的这些论文中很多实验室都在想办法在提高评估指标的同时,减少人力标准成本-->>**自监督学习(Self-Supervised Learning)/半监督学习(Semi-Supervised Learning)等变得到广泛的重视,这里盘点的主要是近两年的一些资料,太遥远的就不去考古了。下面阐述论文中的造数据过程:
1.SurroundOcc(2023):Title:SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving
1):多帧点云拼接,提出了一种 two-stream pipeline,可以将静态场景和可移动物体分别拼接,然后在体素化之前将它们合并成完整的场景。
2):Poisson 重建密集化,首先根据局部邻域中的空间分布计算法向量,随后将点云重建成三角网格,进而填补点云中的空洞,得到均匀密布的顶点,最后再转换回密集的体素
3):使用 NN 算法进行语义标注,对具有语义信息的点云进行体素化得到稀疏的占据标签,然后使用最近邻算法(Nearest Neighbor, NN )算法搜索每个体素最近的稀疏体素,并将其语义标签分配给该体素。这一过程可以通过 GPU 进行并行计算以提高速度。最终得到的密集体素提供了更加真实的占据标签和清晰的语义边界。
个人总结:此造数据的方式很不错,而且并非什么很高深的技术,实现泊松重建可以有很多改良方式具体google,最近邻优点:思想简单,准确度高,对噪声不敏感。缺点:计算量大,难解决样本不平衡问题,需要大量内存。
2.OpenOccupancy(2023):Title: OpenOccupancy: A Large Scale Benchmark for Surrounding Semantic Occupancy Perception
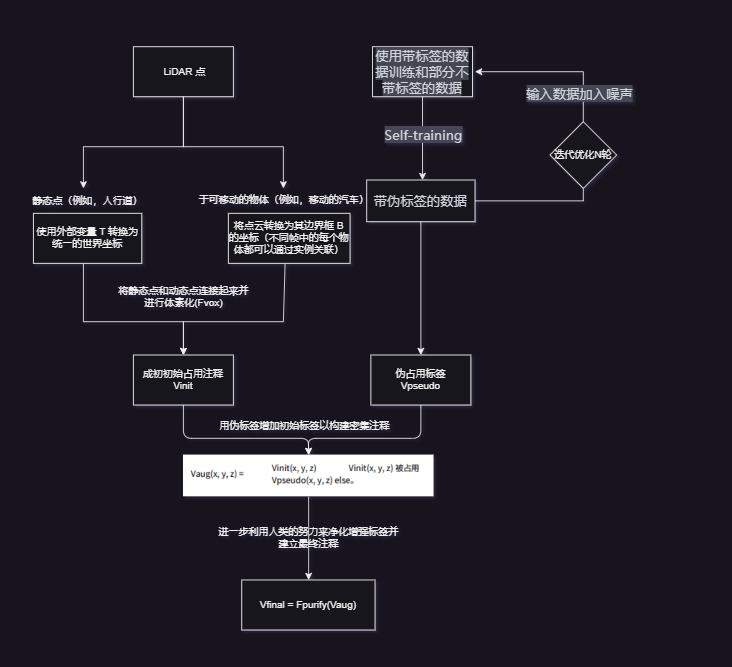

个人总结:以上是小编总结的这篇论文造数据的过程,亮点是使用了新颖的伪标签来取代数据中没有的标签,但是前期训练这些伪标签的工作量没有评估不做评价,还有后期需要净化增强标签建立最终注释,作者也没有具体量化。
3.OVO(2023):Title: Open-Vocabulary Occupancy
提出了开放词汇占有率 Open Vocabulary Occupancy (OVO),这是一种新的方法,允许对任意类别进行语义占有率预测,且在训练过程中不需要三维注释。
1)从预训练的 2D 开放词汇分割模型到 3D 占用网络的知识蒸馏 2)用于生成高质量训练数据的像素-体素过滤个人总结,这篇看的头疼,大致总结下就是:先通过2D蒸馏模块,将2D开放词汇分割模型的知识转移到3D占有率网络中,实现从2D图像到3D场景的语义转换。再使用2D到3D特征转换模块,将2D图像中的特征转换为3D特征,以更好地捕捉场景的语义关系。然后利用设计的3D网络,对3D特征图中的语义关系进行学习和细化,以提高语义占有率预测的准确性。最后引入占有率头,用于推断每个体素的几何和语义信息,从而实现准确的语义占有率预测。总的来说就是把2D的语音信息通过知识蒸馏和3D体素特征相关联,然后对其关系惊醒学习和细化增强准确性。
4.OccBEV(2023):Title: Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
此论文主要叙述了一个 3D decoder 利用多视角图像的鸟瞰图(BEV)特征来预测三维几何占用,使模型能够对三维环境有一个更全面的理解所以导致Occ-BEV 的一个显著优势是,它可以利用大量未标记的 image-LiDAR 对进行预训练
1)提出了一个三维几何占用解码器,利用多视图图像的鸟瞰图特征来预测三维场景中的几何占用 2)使用占用预测头来学习预测每个体素是否包含点云数据个人总结:通过这种方式,模型可以从未标记的图像-LiDAR对中学习到三维场景的几何结构,通过预测三维几何占用情况来进行训练,小编理解的就是把这些传感器分布到BEV空间中,然后再各自的交集中寻找点对并联立起来。
5.Occ3D(2023):Title: Occ3D: A Large-Scale 3D Occupancy Prediction Benchmarkfor Autonomous Driving
从多视角图像中估计物体的详细占据状态和语义信息。为了支持这一任务,文章开发了一个标签生成流程,生成了密集且可见性感知的场景标签。文章还提出了一种名为CTF-Occ的模型,通过粗到细的方式在三维空间中聚合二维图像特征,实现了优秀的三维占据预测性能。
标签生成流程旨在生成密集且可见性感知的场景标签,用于训练和评估三维占据预测模型。1)点云聚合:首先,将来自多个帧的点云进行聚合。对于静态场景中的点云,直接进行聚合。对于动态物体,根据每帧的边界框注释和相机姿态,将它们进行变换和聚合。
2)LiDAR可见性:为了生成密集的占据标签,需要确定每个体素的可见性。通过将每个LiDAR点与传感器原点连接形成一条射线,判断射线是否与体素相交。如果射线与体素相交,则将该体素标记为“占据”;否则标记为“空闲”。
3)相机可见性:由于任务是基于视觉的,因此还需要生成相机的可见性标签。对于每个相机视角,将占据的体素中心与相机中心连接形成一条射线。沿着射线,将第一个占据的体素及之前的体素标记为“可见”,其余的标记为“不可见”。未被任何相机射线扫描到的体素也标记为“不可见”。
个人总结:对于上述的方式,感觉对于动态物体的处理和标签生成的准确性等方面可以进一步改进和优化,对于小规模的数据集和相机视角较少的场景可行,对于较大规模的数据集可能需要更高的计算资源和时间来完成标签生成,上述的可见性可参考NeRf(神经辐射场关于光线传播和辐射场的理解)
6.Scene as Occupancy(2023):Title:Scene as Occupancy 作者使用了一种几何感知的表示方法,将物理3D场景划分为一个个的网格单元,并为每个单元分配语义标签,建立语义标签的过程包括将LiDAR点云分为前景对象点和背景点,通过线性插值近似注释中间帧的3D框,然后生成占据数据并进行后处理
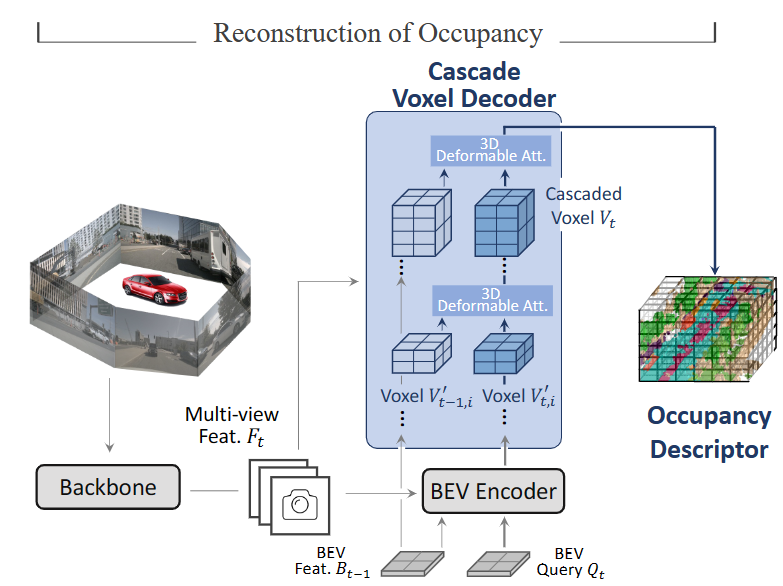
1)提出的OCCNet首先重建占据描述符,目标是为支持下游任务获取一个代表性的占据描述符。OCCNet采用了级联的方式(解码过程被分为多个阶段,每个阶段都负责恢复特定的信息),通过多个级联阶段的迭代,从鸟瞰图特征中解码3D占据特征。2)使用了基于体素的时间自注意力和空间交叉注意力来恢复高度信息,并结合了可变形的3D注意力模块以提高效率。
个人总结:对于上述的方式,个人理解最主要的是通过时间注意力机制使两个相邻关键帧之间的线性插值来近似注释中间帧的3D框,使用累积的背景点和前景对象点生成占据数据,包括微调、注释未知背景点和去除噪声。
7.4D Occupancy Forecasting(2023):Title:Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting 之前的占据预测方法主要集中在(BEV)上,而本文提出的方法将其扩展到了四维空间。作者认为,通过预测未来时刻的点云数据,可以更准确地预测场景的占据情况,四维空间就是增加了时间!!!1)使用符号"z"来表示真实的四维空间时间占据,它表示特定时间点上的三维位置的占据状态。2)使用符号"V"来表示离散化后的四维空间时间体素,其中每个体素表示特定时间点上的三维位置的占据状态。3)使用已知的传感器内参和外参,将四维空间时间体素中的占据状态转化为点云数据,从而根据传感器的位置和方向,从已知的四维空间时间体素中查询点云数据。个人总结:对于这篇论文的详细总结麻烦各位老爷移步小编写的这篇”4D占据预测(预测未来时刻的点云数据,可以更准确地预测场景的占据情况)"这篇加入了IMU做监督信号,相对于上述的几篇文章感觉可落地性更高,工程化更贴切。
二.模型(此栏主要是讨论下基于指标的对个模型的对比)
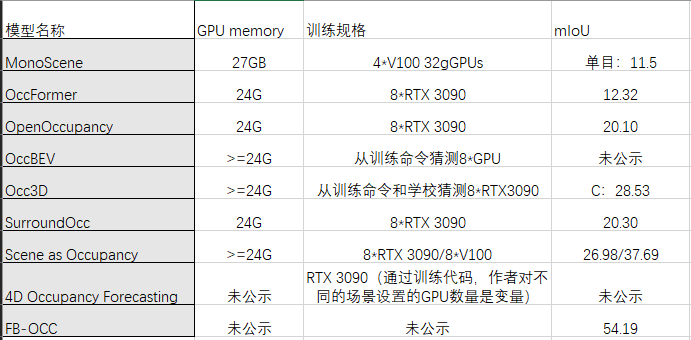
模型复杂度的评估暂且不说,我们从能力角度和训练规模对比评估,每篇论文里面的 IoU 和 mIoU 都不尽相同,此处仅选取了 MonoScene 论文中的指标作为对比:
利用联合交点(IoU)作为地理坐标。它将体素识别为占用或空(即,将所有占用的体素视为一类)其中TPo , FPo , FNo 是占用体素的真阳性、假阳性和假阴性预测的数量
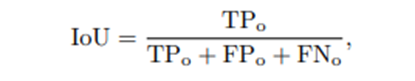
我们计算每个类别的平均IoU(mIoU)作为语义指标,其中TPc、 FPc、 FNc表⽰对c类的真阳性、假阳性和假阴性预测的数 量, Csem是类的总数。噪声类在评估中被忽略。
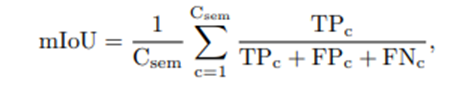
1.MonoScene:(单目mloU)
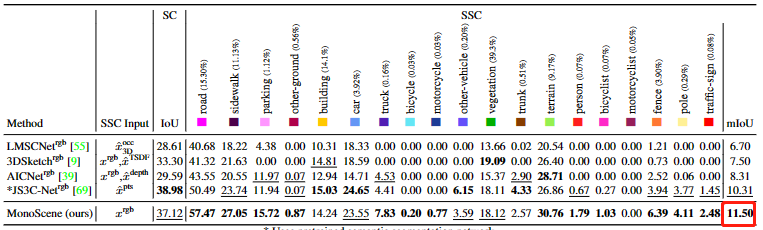
2.OccFormer:
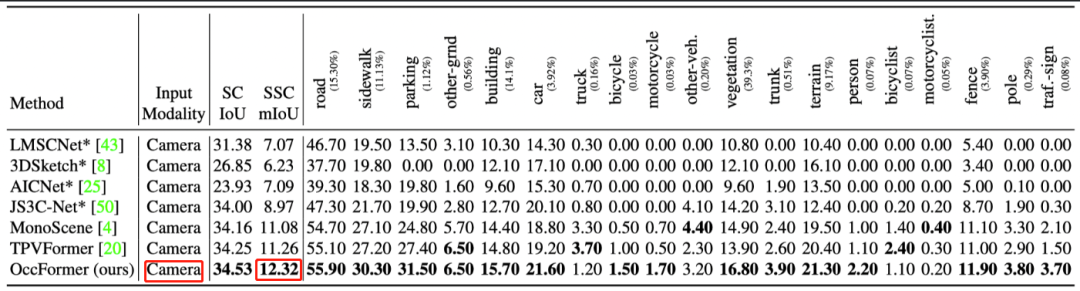
3.OpenOccupancy:
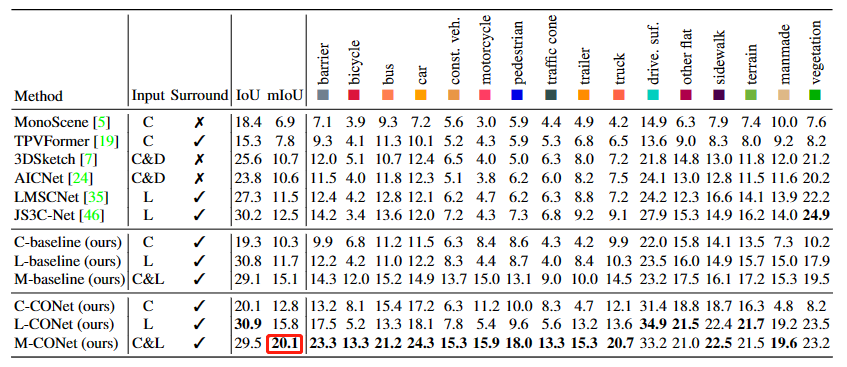
4.OccBEV(未作占据mloU评价)
5.Occ3D:(纯视觉评估)
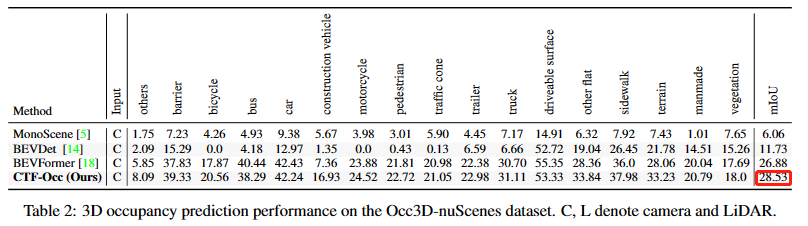
6.SurroundOcc:
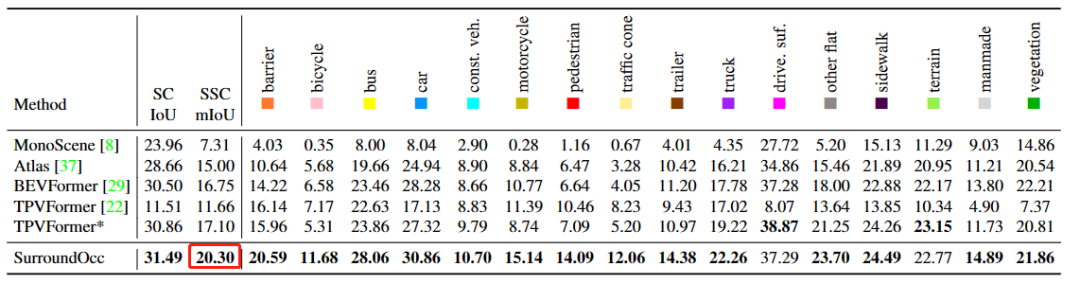
7.Scene as Occupancy:
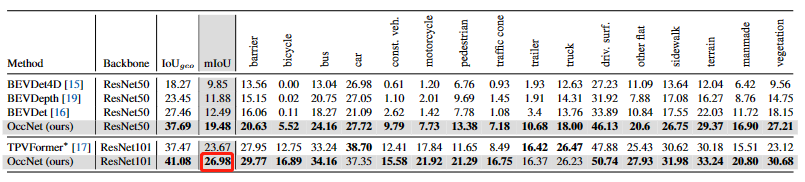
8.4D Occupancy Forecasting这篇并做mIoU的指标评估,暂且无法与上述模型进行直接对比,但是从下图中可以看出:
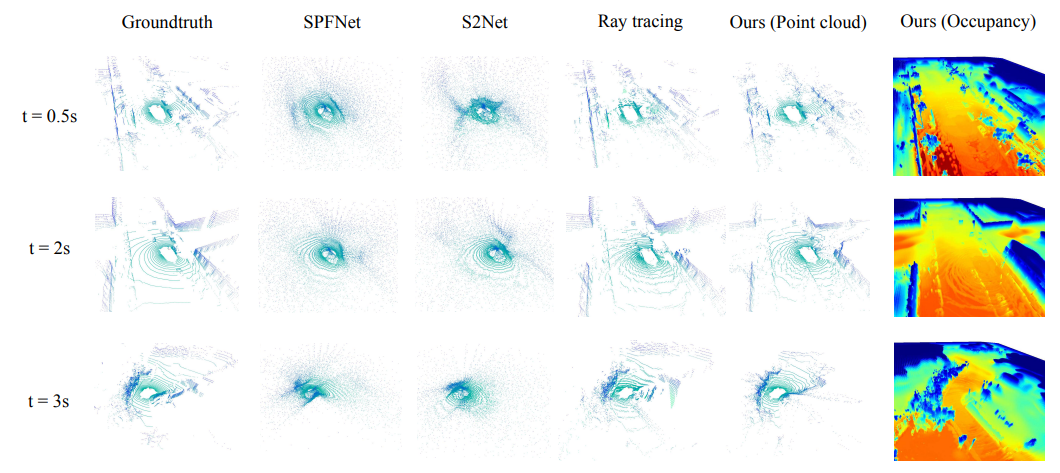
与简单的基于聚合的光线追踪相比,能够通过时空完整的构建4D场景。与Scene as Occupancy类似用时间作为监督是除了大模型外的另一个重要方向之一。
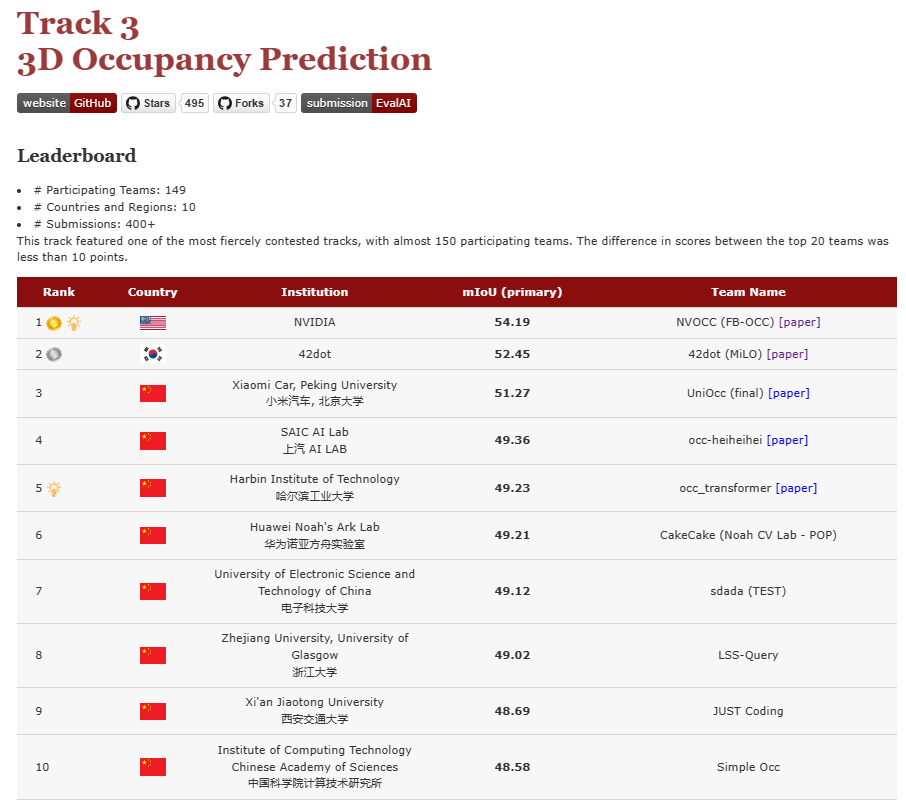
9.FB-OCC(mIoU目前最高)FB-BEV利用LSS中生成的3D体素空间,来作为BEV queries的初始值,使其可以更好的优化,最后将两部分的特征进行融合,使网络对于3D空间有更好的精细化描述,具体还请移步小编的FB-OCC CVPR23 3D Occupancy Prediction 挑战赛冠军方案解读
三.总结
这篇是对现有网格中心感知技术在自动驾驶中的重要性和应用做的综述,论文地址:A Comprehensive Review 综述(https://arxiv.org/pdf/2303.01212.pdf)
个人认为:与基于目标的表示相比,基于网格的表示的显著优势如下:对障碍物的几何形状或语义类别不敏感,对遮挡的抵抗力更强;理想的多模态传感器融合,作为不同传感器对齐的统一空间坐标;鲁棒不确定性估计,因为每个单元存储不同障碍物存在的联合概率。然而,以网格为中心的感知的主要缺点是高复杂性和计算负担。
鸟瞰图二维栅格表示 BEV网格是道路车辆障碍物检测的常用表示,以网格为中心的感知的基本技术是将原始传感器信息映射到BEV网格单元,这些网格单元在不同传感器模态的机制上有所不同。下面从两个方面来概述:1)LiDAR-based Grid Mapping 在以往的点云信息和语义信息匹配或者说姿态对其方面,例如将点云体素化为统一网格,并使用手工特征对每个网格单元进行编码,并不准确或者说并不成功,学习特征成为一种趋势。例如:VoxelNet堆叠体素特征编码(VFE)层以编码体素内的点交互,并生成稀疏的4D体素特征。然后VoxelNet使用3D卷积中间层来聚合和重塑该特征,并将其通过2D检测架构。为了避免硬件不友好的3D卷积,PointPillars和EfficientPillarNet中基于pillar的编码器学习点云柱上的特征,可以将特征散射回原始柱位置以生成2D伪图像。PillarNet通过将加密的pillar语义特征与neck模块中的空间特征相融合,进一步发展了pillar表示,以最终检测方向解耦的IoU回归损失
2)Deep Fusion on Grids 多传感器多模态融合是汽车感知的一个长期问题,融合框架通常分为早期融合、深度融合和晚期融合。其中,深度融合在端到端框架中表现最佳,以网格为中心的表示为多个传感器和代理之间的深度融合提供了统一的特征嵌入空间。
1)多传感器融合:相机是几何损失但语义丰富,而激光雷达是语义损失但几何丰富。雷达在几何和语义上是稀疏的,但对不同的天气条件是鲁棒的,深度融合融合了不同模态的潜在特征,并补偿了每个传感器的局限性。
激光雷达相机融合:一些方法在更高的3D级别执行融合操作,并支持3D空间中的特征交互
UVTR:根据预测的深度分数对图像中的特征进行采样,并将点云的特征与体素相关联,以实现跨模态交互的体素编码器。
AutoAlign和AutoAlignV2:AutoAlign设计了交叉注意力特征对齐模块(CAFA),使得点云的体素化特征能够感知整个图像并执行特征聚合。AutoAlignV2通过跨域DeformCAFA和相机投影矩阵来获取图像特征映射中的参考点,而不是通过网络学习对齐。
FUTR3D和TransFusion:FUTR3D采用基于查询的模态不可知特征采样器(MAFS)提取多模态特征,根据3D参考点。TransFusion依靠LiDAR BEV特征和图像引导生成对象查询,并将这些查询与图像特征融合。
BEVFusion:BEVFusion是一种简单而鲁棒的方法,通过统一共享BEV空间中多模态输入的特征来实现融合。
DeepInteration和MSMDFusion:这两种方法设计了在BEV空间和体素空间中进行多模态交互,以更好地对齐不同传感器的空间特征。
相机雷达融合:了弥补雷达的不足,相机-雷达融合被提出作为一种低成本感知解决方案,它将相机的语义信息与雷达的几何信息相结合
OccupancyNet和NVRadarNet:这两种方法仅使用雷达进行实时障碍物和自由空间检测。
SimpleBEV、RCBEVDet和CramNet:这些方法研究了在BEV上表达雷达特征并与视觉BEV特征融合的不同方法。RCBEVDet使用PointNet++网络处理多帧聚合雷达点云。CramNet将相机特征作为查询,将雷达特征作为值,以在3D空间中沿像素射线检索雷达特征。SimpleBEV将多帧雷达点云体素化为二进制占用图像,并使用元数据作为附加通道。RRF通过投影和采样从每个相机产生3D特征体积,然后连接光栅化的雷达BEV图,通过降低垂直维度,最终获得BEV特征图。
激光雷达-Camera-雷达融合:激光雷达、雷达和相机融合是一种适用于所有天气的强大融合策略。
RaLiBEV采用了一种基于交互式transformer的bev融合,该融合融合了LiDAR点云和雷达距离方位热图。FishingNet使用自上而下的语义网格作为公共输出接口,以进行激光雷达、雷达和摄像机的后期融合,并对语义网格进行短期预测!
2) 多智能体融合:统的网格感知方法通常基于单个智能体系统,但在复杂的交通场景中存在一些限制。然而,车辆对车辆(V2V)通信技术的进步使得车辆可以共享它们的感知信息。CoBEVT是第一个可以协同生成BEV分段地图的多智能体多相机感知框架。在这个框架中,自我车辆根据发送者的姿态对接收到的BEV特征进行几何warp,然后使用具有融合轴向注意力(FAX)的transformer将其融合。动态占用网格图(DOGM)还显示了减少多车辆协同感知融合平台中不确定性的能力。
以上这篇综述相关占据领域的一些旁门知识梳理,下面进入占据网络的总结
3.1 3D Occupancy Prediction
尽管BEV网格简化了动态场景的垂直几何结构,但3D网格能够以相当低的分辨率表示驾驶场景的完整几何结构,包括道路表面和障碍物的形状,代价是较高的计算成本。LiDAR传感器自然适用于3D占用网格,但点云输入有两个主要问题:第一个挑战是从障碍物表面反射的点推断全场景几何体。第二种是从稀疏的激光雷达输入中推断出密集的几何体,基于相机的方法正在3D占用mapping中出现,图像的像素自然密集,但需要将深度图转换为3D占用率!
作者上述给的观点其实都指向了本文的主要论点:点云语义场景的重建-->>如何更优雅的推断出场景中的事物
1)基于LiDAR的语义场景补全TPVFormer的方法,它使用稀疏LiDAR分割标签代替密集体素网格标签,用于监督来自环绕视图相机的密集语义占用。相比于具有固定分辨率的体素标签,点云标签更易于获取(成熟的注释和自动标记技术),并且可以作为具有任意感知范围和分辨率的体元网格的监督。
2)基于Camera的语义场景重建1.基于显式体素的网络:-MonoScene是第一个基于单目相机的室外三维体素重建框架,它使用SSC任务中的密集体素标签进行评估,包括一个用于连接2D和3D U-Net的2D特征视线投影(FLoSP)模块和一个用于增强上下文信息学习的3D上下文关系先验(CRP)层。
-VoxFormer是基于两级transformer的框架,从深度图中稀疏可见和占用的查询开始,然后将其传播到具有自关注的密集体素。
-OccDepth是基于立体的方法,通过立体软特征分配模块将立体特征提升到3D空间。
-TPVFormer是第一个仅使用稀疏LiDAR语义标签作为监督的环绕视图3D重建框架,它将BEV推广为三透视视图(TPV),通过垂直于x、y、z轴的三个切片来表达三维空间的特征,并使用3D点查询来解码占用率。
2.隐式神经渲染:INR是用连续函数表示各种视觉信号,作为一种开创性的新范式, 神经辐射场(NeRF)由于其两个独特的特点:自我监督和照片逼真这里借用了网上的一张图,主人发现请轻喷

具体来说,NeRF 使用一个全连接神经网络(即MLP,Multi-Layer Perceptron)来表示场。给定一个3D坐标和一个方向,这个神经网络能够输出该坐标处的颜色和透明度。为了从一个新的视点生成场景的2D图像,NeRF 对沿着该视点视线的所有3D坐标进行积分,计算所有这些点的颜色和透明度,然后根据这些点的颜色和透明度以及它们与视点的距离来生成最终的2D图像。优点:生成极其逼真和高质量的图像,同时对场景的3D结构也有很强的理解,缺点:速度较慢,因为它需要在每个像素处进行大量的3D坐标的积分计算
3.2时间网格中心感知
由于自动驾驶场景在时间上是连续的,因此利用多帧传感器数据获取时空特征和解码运动线索是网格中心感知的重要问题。顺序信息是对现实世界观察的自然增强,运动估计的主要挑战是,与可以容易地将新检测到的物体与过去的轨迹相关联的物体级感知不同,网格不存在明确的对应关系,这增加了精确速度估计的难度。
对于作者上述提出的观点表示认同,对于紧急的感知任务而言,小编更多的工作是在1)和2)中,未来的发展方向也可能会偏向于这个方向
1)序列BEV(鸟瞰视图)特征的时间模块:这个模块主要负责处理BEV特征的时间序列。其中的一个关键概念是通过车辆的自我姿态在不同的时间戳将BEV空间进行包裹和对齐。这种基于包裹的方法有不同的变体,包括使用简单的卷积块进行时间聚集,使用可变形的自关注来融合包裹的BEV空间等。其中一种更先进的方法是UniFormer,它通过在当前BEV和缓存的过去BEV之间建立虚拟视图,实现更大的感知范围和更好的远程融合。
2)短期运动预测:短期运动预测主要有两种主要的方法:一种是以激光雷达为中心,其目标是在接下来的1.0秒内预测非空柱上的运动位移;另一种是以视觉为中心,其目标是预测未来2.0秒的实例流。这两种方法都需要精确的定位和多帧数据的特征提取,而且还需要对中心、偏移和未来流量进行精确的预测。
3)长期占用流:这个任务的目标是预测给定历史对象的长期占用状态。这是通过在占用网格图上建立流场,通过顺序流向量将遥远的未来网格的占用状态追踪到当前时间位置。这种方法结合了最常用的两种运动预测表示:轨迹集和占用网格。其中有一些先进的方法如DRF、ChaufferNet、道路规则和MP3等,它们通过使用自回归序列网络预测占用残差,通过解码占用流中的轨迹,或者预测每个网格的运动向量及其可能性等方式,实现更精确的长期占用预测。
3.3网格中心感知的有效学习
1)多任务模型:通过预测几何、语义和时间任务,可以提高每个模型的准确性,基于LiDAR的方法无法完成未观察到的网格区域的估计,而基于相机的方法可以推断观测背后的某些类型的遮挡几何体,而联合3D目标检测和BEV分割是一种流行的组合,它在一个统一的框架中处理动态对象和静态道路布局的感知,给定共享的BEV特征表示,用于目标检测的预测头部和用于分割的预测头部共同工作,最近的研究开始在基于BEV的多任务框架中实现更多的主要感知任务。
2)自监督模型的运用:强调了在LiDAR点云上的自我监督预训练,核心问题是设计一个预定义的任务以实现更强的特征表示,这些任务可以源于时间一致性、区分性约束学习和生成性学习,且发展方向一定是多模态多融合的相互监督,对于学习几何和运动的等重要性不言而喻,例如:PillerMotion和MonoDepth2
3)计算效率高的网格感知:主要是内存高效的3D网格映射和有效的视图转换技术
作者提出了一些方法来提高内存效率,例如体素哈希和Octomap,后者使用基于八叉树的方法来实现高效的概率3D映射。其次,作者介绍了连续映射算法,它是一种高效的3D占用描述方法,能够支持任意分辨率的计算和存储。这其中,作者提出了一些具体的方法,如高斯过程占用图(GPOM)、希尔伯特映射、BGKOctoMapL、AKIMap和DSP地图。其次介绍了一些有效的视图转换方法,包括BEVFusion、BEVDepth和GKT,这些方法都通过设计有效的算子来优化Vanilla LSS的计算成本,提高了计算效率。
这篇文章主要是对最近一个月的3D占据网络的感知方向的一些个人见解,欢迎同行提取意见,相互学习。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,如果您希望分享到自动驾驶之心平台,欢迎联系我们!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码免费学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、Occupancy、多传感器融合、大模型、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









