






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到Xiangyu Wei来分享他们CVPR2023 Workshop中稿的最新3D检测高效融合新方案—DynStF,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【3D目标检测】技术交流群
@自动驾驶之心原创 · 作者 | Xiangyu Wei
编辑 | 自动驾驶之心

为什么提出这个方法?
早期工作一般用多个先前帧增强激光雷达输入提供了更丰富的语义信息,从而提高了3D目标检测的性能。然而,由于运动模糊和不准确的点投影,多帧中拥挤的点云可能会损害精确的位置信息。这篇工作作者提出了一种新的特征融合策略DynSTF(动态-静态融合),它利用当前单帧(静态分支)的准确位置信息增强了多帧(动态分支)提供的丰富语义信息。为了有效地提取和聚合互补功能,DynSTF包含两个模块,即Neighborhood 交叉关注(NCA)和动态静态交互(DSI),通过双路径架构运行。NCA将静态分支中的特征作为查询,将动态分支中的特性作为键(值),在计算注意力时,解决了点云的稀疏性问题,只考虑了邻域位置。NCA融合了两个功能在不同的特征图比例,然后DSI提供全面的交互。DynSAF在nuScenes数据集上进行了广泛的实验,在测试集上,DynSAF将PointPillars在NDS中的性能大幅提高,从57.7%提高到61.6%。当与CenterPoint结合时,框架实现了61.0%的mAP和67.7%的NDS,从而实现了最先进的性能!
提出的背景?
激光雷达传感器由于其在深度信息方面的高精度,被广泛用于自动驾驶背景下的3D物体检测。最近利用鸟瞰图(BEV)基于激光雷达信息的方法主要可分为两类:基于体素的和基于pillar的,在速度和精度上各有千秋!前一组方法一般会将空间中的点划分为均匀分布的体素,并获得具有多个3D矢量层的特征。后一种方法通过在2D图像中的每个位置生成pillar,将3D点转换为伪图像,该pillar在垂直轴上的大小等于整个可用空间,因此能够使用2D卷积直接获取特征表示。在没有垂直轴上的特征压缩的情况下,基于体素的方法产生了更高的性能,而基于pillar的模型在计算中更高效,在实时应用中更受欢迎!
激光雷达点云包含精确的几何形状和物体的精确位置,但它受到红外规则点密度的影响:点在靠近激光雷达传感器的区域密集,而在远处非常稀疏。检测具有较少点的目标是非常困难的。一些工作建议使用多个激光雷达扫描(帧)提供了更丰富的点云信息,以消除由于点的稀疏性而引起的不确定性。来自多个scan的点 直接聚合并通过将相对时间戳信息扩展为额外维度来区分输入数据,这也增强了具有宝贵时间信息的网络。图1说明了多帧和单帧输入之间的差异,在该场景中,汽车前面有几辆车和行人。只需扫一次,就可以很容易地根据物体表面的明确点来确定物体的位置。然而,在累积了十次点云扫描后,在车辆和行人周围观察到运动模糊,使得运动物体的边缘变得模糊,无法准确识别(请参见放大图像),从而导致对具体位置的混淆。总之,多帧激光雷达输入通过增强具有有意义的运动特征(动态信息)的输入来提高识别性能,但抑制了单帧在精确目标定位能力(静态信息)方面的优势!
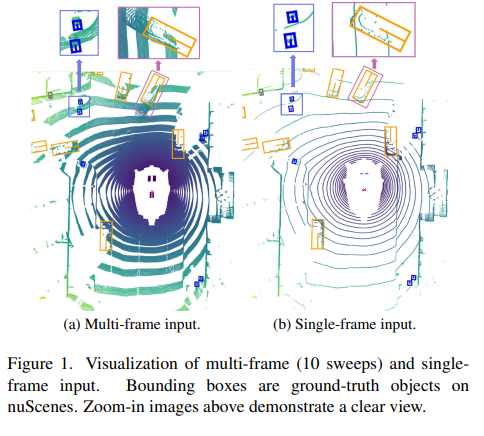
现有的工作通常只采用多帧点云数据作为输入,基于上述观察,论文提出了一个新的统一框架DynSTF,代表动态静态融合,通过将多帧输入提供的丰富语义信息与单帧数据中的准确位置信息有效融合,来弥补当前的研究空白。ynSTF是首次尝试部署用于从多帧和单帧激光雷达输入中提取和融合特征的双流架构。DynSAF部署了一种双路径架构,以在2D主干上同时操作来自两种输入类型的BEV特征。为了解决特征交互问题,引入了两个融合模块,即邻域交叉attention(NCA)和动态静态交互(DSI),在不同级别的两个分支之间进行特征融合。注意力机制适用于产生交叉注意力,但vanilla 交叉注意力模块全局计算注意力矩阵。激光雷达BEV特征图是稀疏的,其中相关特征是局部分布的。考虑到BEV特征的这一特点,不需要计算全局注意力,因为它不会带来显著的好处,但会带来计算开销。因此,论文选择将交叉关注局限于邻近区域。NCA将来自单帧分支的特征视为查询,并从多帧特征图中获得查询邻域中的关键字和值。主干中的几个block之后,特征图将变得密集。在这个阶段,使用基于CNN的DSI模块,在每个像素位置进行全面交互,融合特征包含丰富的语义上下文和准确的位置信息,提高了检测精度。
常用的多模态融合方法剖析
多模态融合是一种流行的方式,一些工作提出了融合相机和激光雷达数据的框架,其中性能比使用单一模态更强。还有一些特征融合工作不需要多个传感器,将BEV特征与RV(距离视图)特征融合,因为RV提供了密集的特征,而BEV特征是稀疏但不重叠的。将两个视图结合起来可以提高性能,因为它提供了全面的空间上下文。HVPR(混合体素点表示)利用基于体素的特征和PointNet++中使用的基于点的特征,以这种方式,将有效提取的体素特征与来自点流的更精确的3D结构相集成。由于几何信息在投影到2D BEV空间时丢失,MDRNet用体素特征丰富了BEV特征,以保持几何信息。本文提出了一种基于多帧和单帧激光雷达输入特性的新特征融合策略,该策略在整个BEV特征处理过程中保持两个分支中的特征相互作用。策略是在2D BEV空间上进行端到端训练,可以直接应用于任何最先进的架构,以提高性能!
主要方法阐述
最新的基于激光雷达的3D检测方法将原始点云从激光雷达点云序列中分离出来,并使用(相对)时间戳作为额外的特征维度来提高检测性能。该设置在用单个帧作为3D检测的输入来补偿点云的稀疏性方面是有效的。来自前一帧的点云将在定位中带来模糊性,尤其是对于拥挤场景中的移动目标。为了缓解这种不利影响,论文建议部署交叉注意力,以有效地将输入序列中的时空语义特征和当前帧中的准确定位信息融合在一起。双路径架构被设计为分别处理当前点云和聚合点云,其中提取的特征被逐步融合。框架被称为“DynSTF”,将多帧分支称为“动态分支”,将单帧分支称称为“静态分支”,以突出每个分支中丰富的运动信息和准确的位置信息!
遵循一般的3D激光雷达目标检测器设置,不需要任何额外的输入信息。目前的检测器,如基于pillar框架,在体素化后将点云投影到BEV特征空间(体素特征 编码),而基于体素的框架通常额外地用3D主干来处理体素。所有主流基于pillar/基于体素的架构都可以直接作为DynSTF中的动态分支来部署,复杂的3D主干可以用于处理体素以获得BEV特征。然而,静态分支被设计为轻量级的,并且只需要VFE来编码BEV特征,在静态分支中不需要3D主干。DynSTF对BEV特征进行运算。动态分支的投影BEV特征图表示,静态分支的,其中C、W和H分别表示生成的BEV图的通道数、宽度和高度。在开始特征融合之前,如果Fs的维度变化,则用额外的卷积层处理Fs,以达到与Fd相同的维度。两个分支之间的特征融合在我们的DynSTF中使用NCA进行回归,如图2所示。
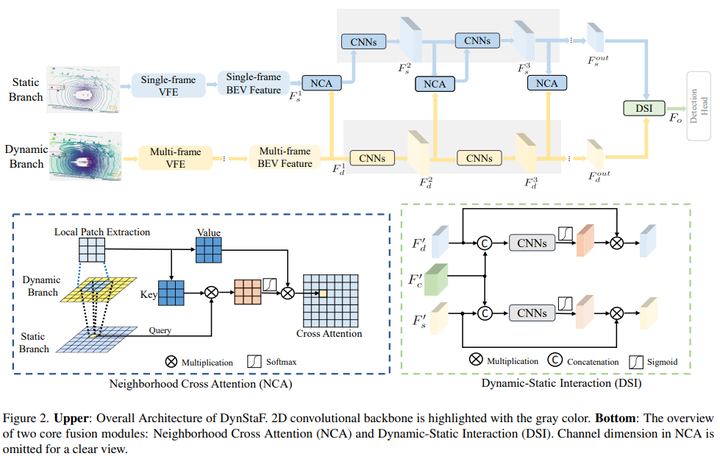
Neighborhood交叉关注模块
考虑到来自静态分支的BEV特征提供了目标位置信息,并且在动态分支中可以找到丰富的时空语义信息,本文使用中的特征作为查询,并从中生成关键字和值来实现交叉关注。由于同一目标的相关特征在两个特征中都应该位于相似的位置,在BEV特征图的背景下,特定查询附近的局部信息对于建立交叉注意力更为重要。此外,BEV特征图相对较大但稀疏,其中只有少数像素被非空pillar占据,限制邻域也有助于节省计算成本,交叉注意的图示如图2(左下)所示。
动态静态交互(DSI)模块
经过CNN和NCA块的处理,特征图变得密集且信息丰富。尽管NCA已经用动态分支的局部特征增强了静态分支,但它不能保证保留所有详细的语义。因此,我们在检测头之前添加了一个交互模块,以充分整合来自两个分支的特征。给定表示为的单帧分支的特征,来自多帧分支的和,两个特征图的级联用于指导交互,因为它包含了两个特征的综合视图。三个卷积层首先分别处理、和,其输出在这里表示为、和。DSI将它们作为输入并使用CNN块为每个分支生成两个特征图,如图2(右下)所示。DSI的两个输出分量与连接在一起,然后是另一个CNN块,以产生输出,并将其输入检测头。
首先使用卷积层来标记BEV特征图,并将其表示为m-dim特征向量的序列,例如来自静态分支的特征序列是。标记化特征Fs线性投影到查。对于多帧分支中的标记化特征序列,使用线性层将其投影到密钥和值,单帧特征图中的查询i的交叉注意力Ac计算为:
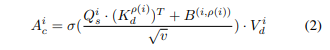
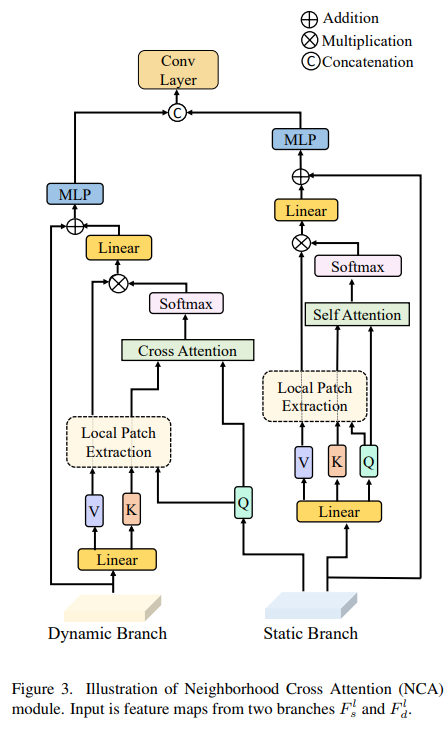
在A^i_c的顶部添加了另一个线性层,使用快捷方式和两个额外的线性层来进一步处理该输出。为了用准确的位置信息增强特征,使用相同的算法计算单帧分支的自注意,但使用线性投影来从单帧特征中获得查询、关键点和值。来自交叉注意力和自注意力的输出的级联被馈送到卷积层,从而导致NCA模块的最终输出,NCA的完整操作如图3所示!
实验对比
作者在nuScenes上进行了实验,这是一个在现实世界中收集的大规模数据集,包含多个传感器数据。本文只使用激光雷达数据(频率为20FPS)来处理3D检测任务。训练集中总共有700个视频序列,验证和测试集中各有150个视频。继之前的大多数工作之后,对多帧输入使用了10次扫描,以响应前0.5秒内的激光雷达信息,标记了从汽车、行人到交通锥等10个类别。
训练损失:定位损失(L1 loss)、分类损失(focal loss)和方向损失(交叉熵损失),其权重分别为0.25、1.0、0.2。用于训练基于CenterPoint的模型的损失是anchor-free的,包括分类损失和回归损失,前者是权重为1的预测标签和GT标签之间的交叉熵损失,而后者是权重为0.25的边界框的L1回归损失。
训练策略:对于基于PointPillars的模型,x轴/y轴的点范围设置为[-51.2m,51.2m],z轴设置为[-5,3]。在训练过程中,点沿x轴和y轴随机翻转,应用范围为[-π/8,π/8]的围绕z轴随机旋转。此外,随机全局缩放因子设置在[0.95,1.05]的范围内。当使用体素大小为(0.075m,0.075m,0.2m)的CenterPoint时,沿z轴的随机旋转设置为[-π/4,π/4]。在所有训练中都部署了类平衡采样。实验是在OpenPCDet框架下进行的,所有模型都在8个V100 GPU上训练了20个epoch,bs大小为32!
和其它方案对比
在nuScenes训练集上训练本文的模型,并在验证集上进行评估。表2报告了与其它最先进方法的比较,本文使用mAP和NDS作为评估指标。为了比较不同的结果,还考虑了每种策略与原始论文中报告的主干模型相比的性能增益,因为不同训练的主干模型可能会使模型的性能有所不同。与使用多帧作为输入重新实现的PointPillars相比,DynSAF将mAP和NDS分别提高了5.8%和4.1%。与使用CenterPoint作为主干的所有其他SOTA方法相比,DynSTF在这两个指标上都实现了最大的性能增益。本文的CP+DynSAF在NDS和mAP上分别达到67.1%和58.9%,在验证集上实现了最佳性能,性能提升在两种主干模型上都很重要,突出了DynSTF的兼容性。
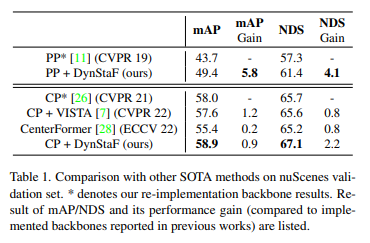
nuScenes测试集的结果:除了离线评估之外,还在nuScenes测试服务器上将DynSAF与其他SOTA单模型进行了比较,测试阶段未使用测试时间增强(TTS)。为了进行公平的比较,与表1中没有TTS的结果进行了比较。方法分为两组:(1) 不包含3D卷积运算的基于pillar的方法;(2) 具有3D卷积块的基于体素的方法。
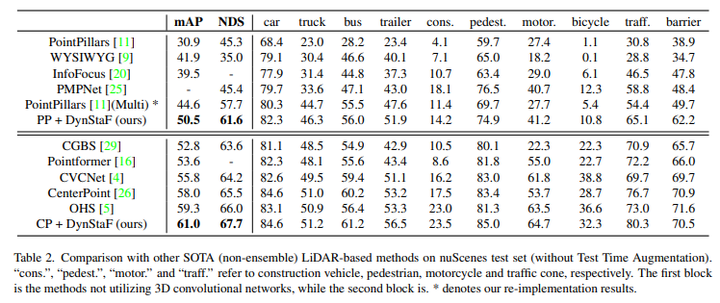
由于以前基于pillar的方法通常只部署单个框架作为输入,论文还为重新实现的PointPillars提供了一个基线,并将多框架作为输入进行公平比较。当使用多帧时,vanilla PointPillar的mAP和NDS分别达到44.6%和57.7%。使用Dyn-StaF,PointPillars得到了很大的改进(在mAP中为5.9%,在NDS中为3.9%),使基于pillar的模型具有最先进的性能:mAP为50.5%,NDS为61.6%。此外,可以观察到个体目标类别的显著改进,例如,在交通锥和障碍物上,DynSTF与之前的最佳结果相比,mAP分别提高了6.3%和12.5%。与基于体素的方法相比,DynSTF显著增强了基于pillar的主干,缩小了性能差距!
消融实验
本节深入分析了融合策略中每个组件的有效性,即NCA、DSI和双路径架构。所有消融研究都是在NuScenes验证集上进行的,并使用PointPillars作为基线模型。结果列于表3中,使用多帧点云作为输入,在没有任何特征融合的情况下,PointPillars的NDS和mAP分别达到57.33%和43.66%。如果使用朴素特征融合(表示为“仅CNN”)来替换每个block后的NCA模块,即连接两个特征并在其上添加CNN层,则性能提高到59.74%的NDS,这验证了两个特征分支都具有互补信息。使用更复杂的融合模块,即提出的NCA模块,NDS进一步提高到60.53%,与基线相比,mAP增加了很大的幅度(4.27%),这表明在稀疏点云的情况下,使用基于transformer的交叉注意力机制是有效的。当特征图密集时,使用DSI更有效,因为看到仅NCA的融合不如最终方法NCA+DSI!
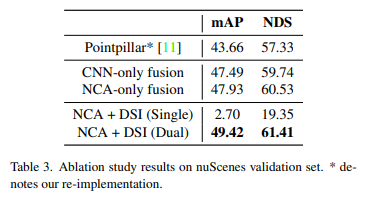
论文研究了表3中第二个region block中双通路架构的有效性。与两个特征流不同,只采用了一个单一的特征融合路径,即图2中用灰色突出显示的2D CNN block的单帧和多帧分支共享权重。该模型的较差性能(表示为“单个”)证明了单个主干不可能同时处理单帧和多帧特征,这也揭示了多帧和单帧包含不同的信息。本文的DynSTF(“Dual”)在使用所有组件的mAP和NDS上分别达到了49.42%和61.41%的最佳性能,证明了提出的特征融合策略的优势!
更多分析
其它交叉注意模块:可变形DETR学习关注参考点周围的一小组密钥,这与NCA类似地发现了局部注意力,不同的是,采样偏移(关键点的位置)在可变形注意力模块中是可学习的,而NCA在邻域内产生“全局”注意力。可变形DETR已被证明在基于LiDAR点云的特征融合中是有效的,为了在论文的用例中发现可变形注意力的能力,用可变形DETR层替换了基于pillar的DynSTF中的NCA模块。然而,却看到性能下降:NDS下降到60.04%,mAP下降到47.01%。这表明整个邻域对于建立两个分支之间的交叉注意力至关重要。此外,作者还探索了两个分支的特征最终交互的一些其他方法,例如,我们调整了CBAM模块来学习两个分支之间的交叉注意力。更换DSI时(在基于pillar的DynSAF中),NDS和mAP分别下降到60.70%和48.42%,这些结果显示了NCA和DSI在聚合特征和增强两个分支之间的交互方面的优势。
静态分支的效率:在基于CenterPoint的DynSTF中,聚合2D卷积块中的特征,并将两个块中的通道维度保持为CenterPoint中的一半。发现此设置不仅有效而且在最终性能上是有利的。由于论文使用了与动态分支相同的分支,即3D卷积主干用于单帧输入,并且信道维度设置为与原始CenterPoint中的相同。得到了66.28%的NDS和58.41%的mAP,这低于DynSAF的结果,原因可能是单个帧输入不足以训练复杂的主干。DynSTF的当前设计提供了较低的计算成本,同时在3D检测中提供了令人满意的性能!
结果分析
论文定性地展示了DynSTF在三维检测任务中的优势,图4显示了使用CenterPoint作为主干的预测,在第一个场景中,左侧有一队车辆(如图4a所示),CenterPoint无法精确检测几辆车的位置(用红色圆圈标记),图4b中的DynSTF正确定位了这些车辆。此外,与基线相比,DynSAF减轻了假阳性,第二个例子是在一条被许多建筑包围的城市街道上收集的,一群行人走在汽车的右后侧。如图4a所示,在这种情况下,多帧输入被点云淹没,使得检测变得困难。例如,在图4c中,步行行人的点云将非常拥挤,因此模型预测错误(用右侧的红圈标记)。使用DynSTF,单个帧可以提供每个行人的更清晰视图,因为点云更稀疏,这两个例子显示了我们的DynSTF在精确预测位置和避免假阳性检测方面的优势。
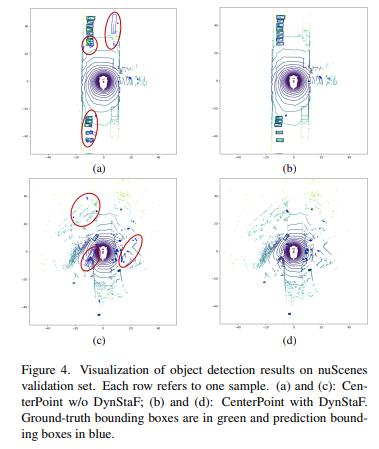
图5展示了相机视图中的预测,具体突出了DynSTF在密集点云背景下的能力。论文展示了三种具有挑战性的视图,其中对象彼此闭合。在左前和右前视图中,可以观察到车辆的遮挡,并且预测对大多数目标都是正确的。在前视图中,存在更多的遮挡,例如一群行走的行人,DynSTF可以检测所有目标,但无法完美地处理遮挡位置!
参考
[1] DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object Detection.CVPR2023
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









