






Qwen3 官方博客:https://qwenlm.github.io/blog/qwen3/
Github 仓库:https://github.com/QwenLM/Qwen3
#大模型 #LLM #Qwen
总结一下我最关心的几个点:
一、混合思维模式
Qwen3 能在两种模式下工作,实现「按需切换」:
思考模式 (Thinking Mode)
:处理复杂问题,比如数学推理、代码生成、深度分析的时候,模型会模拟人类的「慢思考」或「系统 2 思维」,进行详细的、逐步的推理(CoT),然后给出最终答案。 非思考模式 (Non-Thinking Mode)
:面对相对简单、直接的问题,模型则采用「快思考」或「系统 1 思维」,迅速给出答案,优先保证响应速度和效率。
用户可以通过「思维预算」(token 数)来控制,也可以显式地通过 API 参数 (enable_thinking) 或特定指令(如对话中的 /think, /no_think 标签)来指导模型采用何种模式。
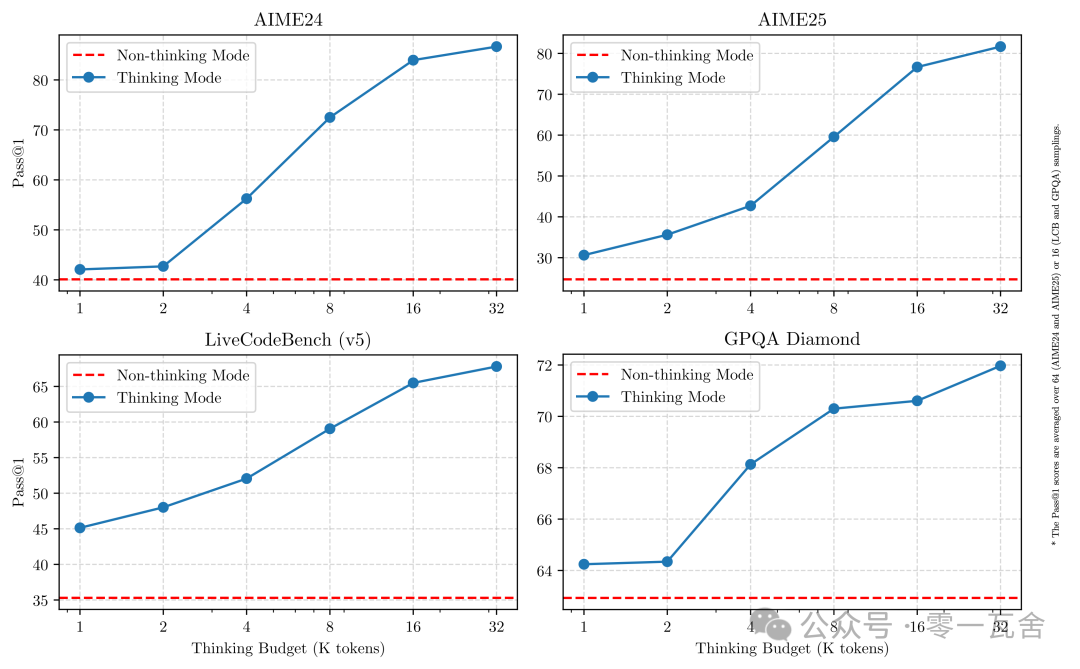
这个灵活度可能会带来应用上的一些新玩法。
二、架构与性能
这部分没有特别出人意料的东西。主打的架构是最近比较常见的 MoE:
旗舰模型
Qwen3-235B-A22B相对小巧的
Qwen3-30B-A3B
还有一系列不同参数规模的 Dense 模型(从 0.6B 到 32B)。
这次的命名方式终于让我舒服了一点
性能方面,从官方数据上看,感觉突破性没有特别强(当然终究还是要看实测)。我比较期待 Qwen3-30B-A3B 这个尺寸模型的实测表现。
这是官方的模型性能数据:
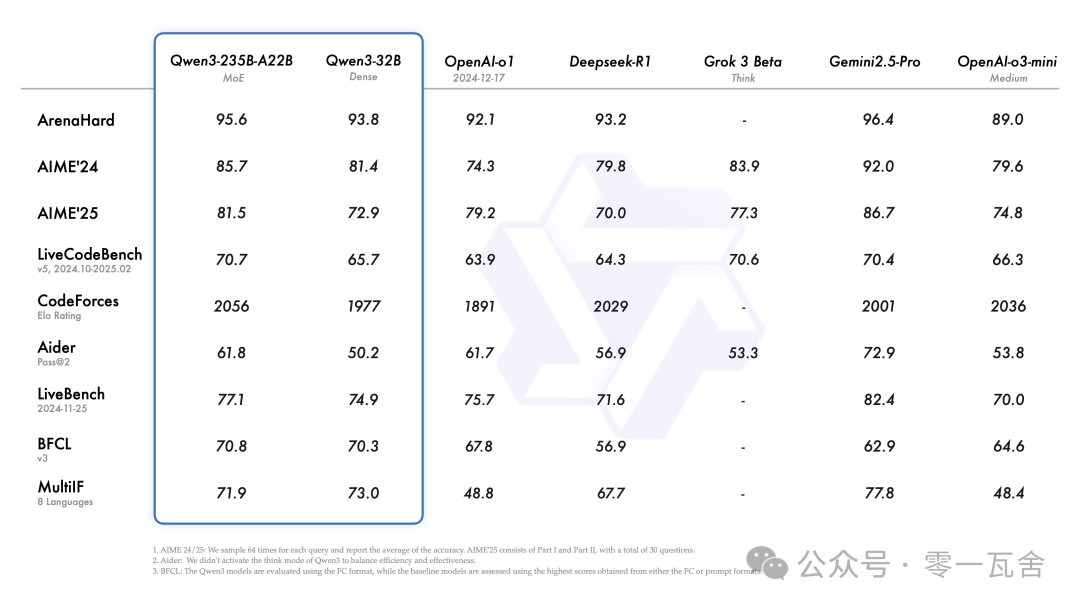
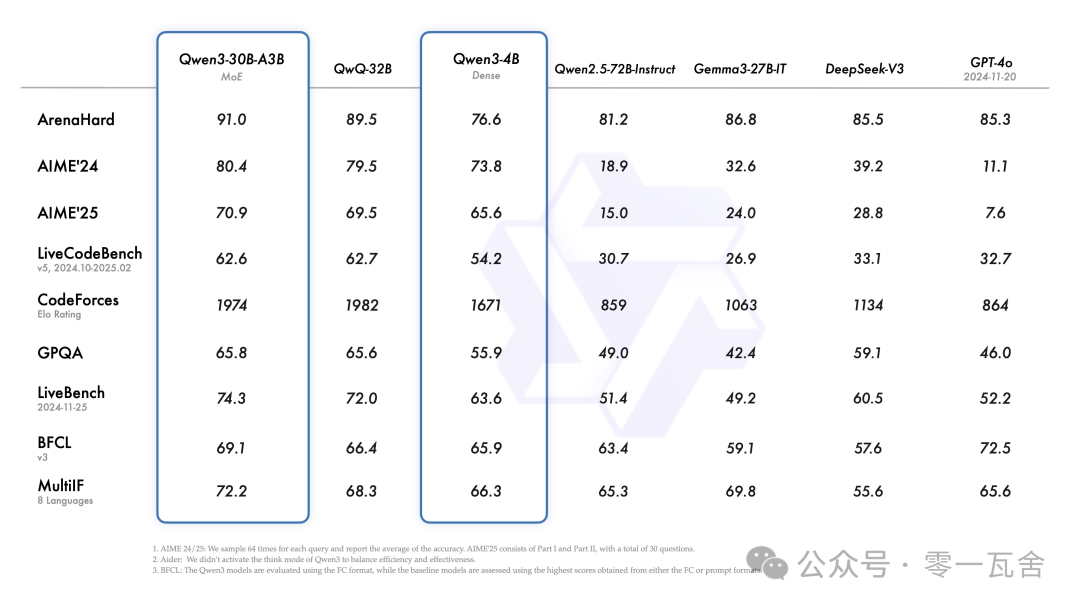
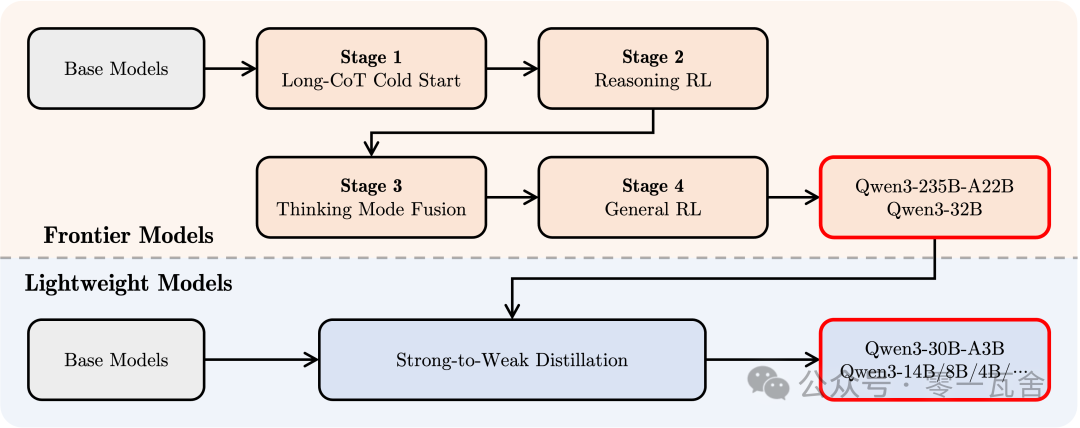
三、训练方式
预训练:
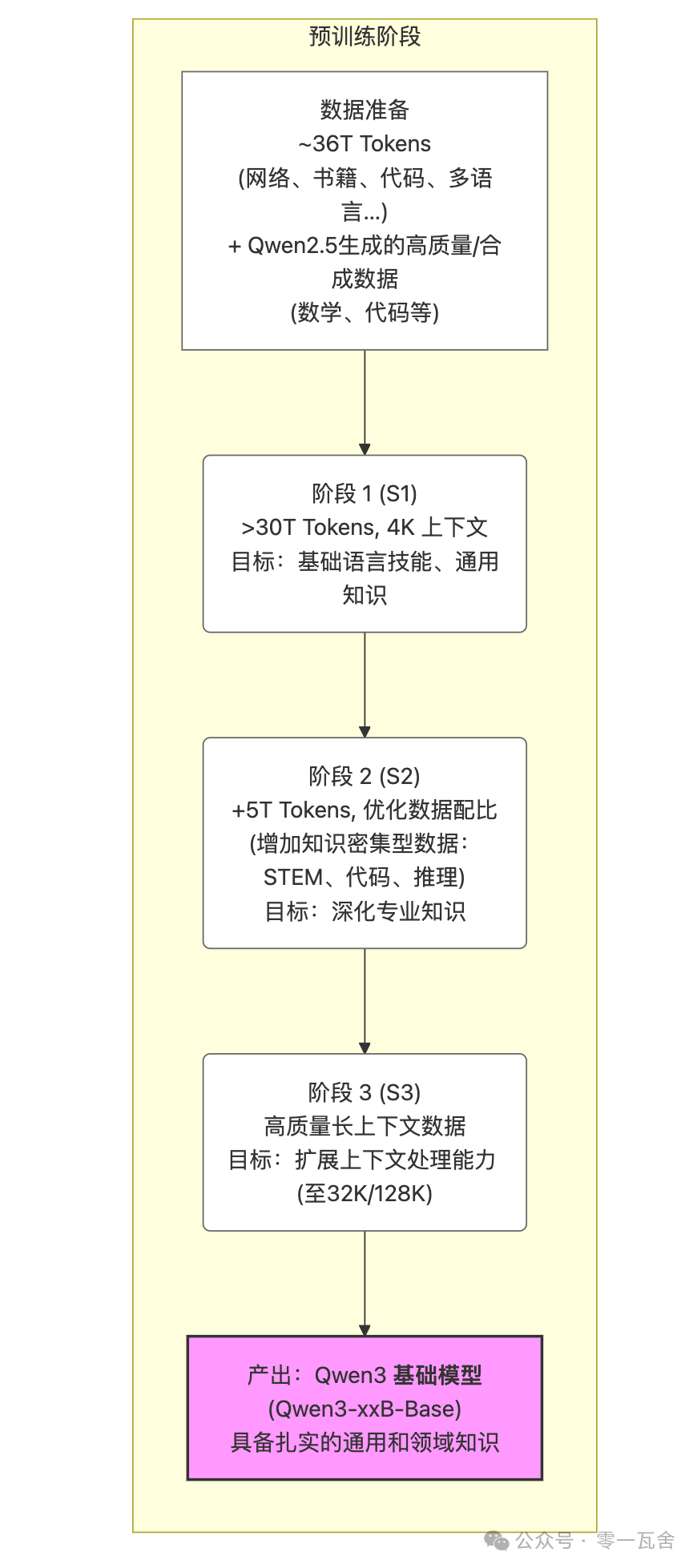
后训练:
graph TD
%% Define Styles for final models
classDef frontierFinal fill:#f8d7da,stroke:#e53e3e,stroke-width:2px,color:#721c24
classDef lightweightFinal fill:#cce5ff,stroke:#3182ce,stroke-width:2px,color:#004085
%% === Frontier Models Post-training ===
subgraph "顶尖模型 (Frontier Models) 后训练流程"
direction TB
Base_Model_Large["大型<b>基础模型</b><br>(e.g., Base for 235B, 32B)"] --> PT1;
PT1("阶段 1: 长思维链 (CoT) 冷启动<br>目标:学习基础推理") --> PT2;
PT2("阶段 2: 基于推理的 RL<br>目标:强化推理能力") --> PT3;
PT3("阶段 3: 思维模式融合<br>目标:融合思考/非思考") --> PT4;
PT4("阶段 4: 通用 RL<br>目标:提升通用能力/对齐") --> Final_Model_Large;
Final_Model_Large["产出: <b>顶尖指令模型</b><br>(e.g., Qwen3-235B-A22B, Qwen3-32B)<br>具备完整混合思维能力"];
class Final_Model_Large frontierFinal;
end
%% === Lightweight Models Post-training ===
subgraph "轻量级模型 (Lightweight Models) 后训练流程"
direction TB
Base_Model_Small["小型<b>基础模型</b><br>(e.g., Base for 30B, 14B, ...)"] --> Distill;
Distill("<b>强模型到弱模型蒸馏</b><br>(Strong-to-Weak Distillation)<br>将大模型能力迁移到小模型") --> Final_Model_Small;
Final_Model_Small["产出: <b>轻量级指令模型</b><br>(e.g., Qwen3-30B-A3B, Qwen3-14B, ...)<br>继承强大能力,更高效"];
class Final_Model_Small lightweightFinal;
end
%% === Link between Frontier and Lightweight ===
Final_Model_Large -- "作为 '强' 教师模型 (Teacher)" --> Distill;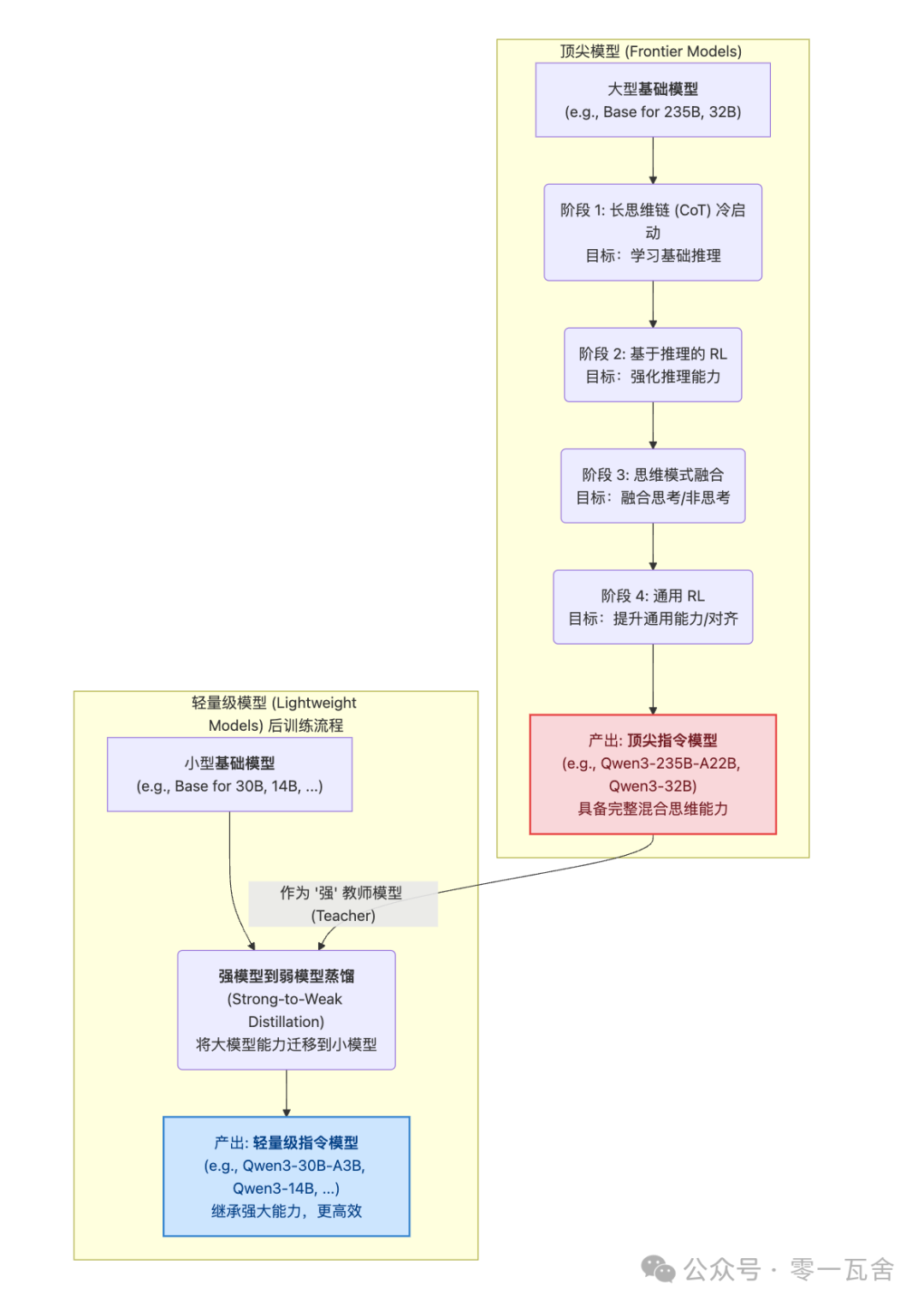
也可看官方给的后训练流程图:
四、支持 MCP
看到很多媒体的说法是「
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)我的目前的理解是,qwen_agent 这个 SDK 封装了 MCP 的用法,而不是 Qwen3 系列模型针对 MCP 协议数据进行了预训练或者后训练。不过这个理解有待证实,需要后面看一下 qwen_agent 的代码。
不过,无论如何,对于用户(开发者)都是一件好事。

















 8296
8296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









