






作者 | 求求你们别学了 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/643180137
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【3D目标检测】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!
本文只做学术分享,如有侵权,联系删文
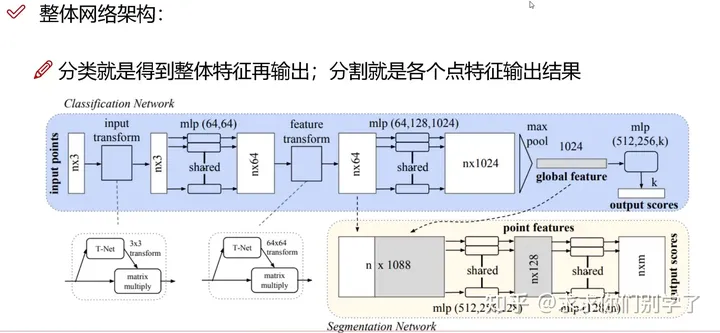
pointnet:
分别对每个点进行特征提取(卷积或者全连接),再MAX pooling得到全局进行输出。先将点云xyz三维升到64、128、1024维,然后对n个点云的维度进行MAX pooling到1024的特征进行分类。或者将其复制N份与n* 64加起来,进行分割。
pointnet++
pointnet的缺陷:缺少逐层的特征提取。pointnet++:实现了多层的一步一步的特征提取。(类似于图像的逐层提取特征)

VoxelNet
一种用于目标检测的深度学习模型,它将点云数据表示为三维体素化(voxel)形式,并利用卷积神经网络(CNN)提取特征,再用3D预测物体的位置和大小。与传统的基于图像的目标检测方法不同,VoxelNet可以直接处理点云数据,因此更适用于自动驾驶等领域中的三维场景。
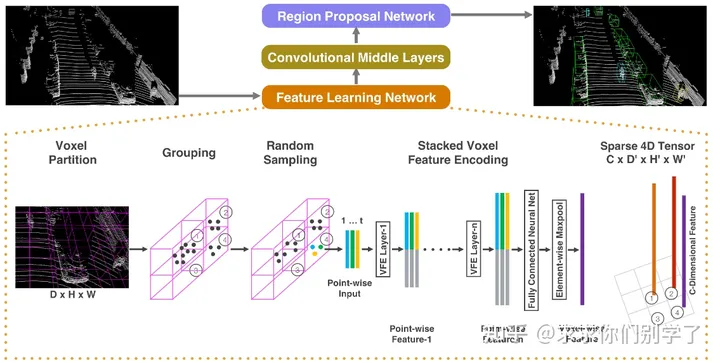
Voxel Partition (体素划分) :将点云划分为空间里的小立方体(体素);
Grouping (分组):按照上面的每个体素将点云分组;
Random Sampling (随机采样) :这里随机采样每个体素中的T个点,多于T的取T,少于T的则都取;
Stacked Voxel Feature Encoding (VFE, 体素特征编码) :将每个点云的特征长度变成7维[xi, yi, zi, ri, xi-vx, yi-vy, zi-vz](通过每个体素内的所有点可以求得质心的坐标为 (vx, vy, vz),然后本质上依次采用了两个pointnet依次堆叠起来,获得VFE层的输出特征。效果提升非常明显,因为没有两次pointnet,一次就将N个点max到一个点,在经过一次pointnet,能获得的信息就更多了。
Convolutional middle layers (卷积中间层) 3D卷积:最后的得到的特征图大小为 64 × 2 × 400 × 352(C,D,H,W)。在送入RPN之前先整合一下变成:128 × 400 × 352。后面用图像的方法
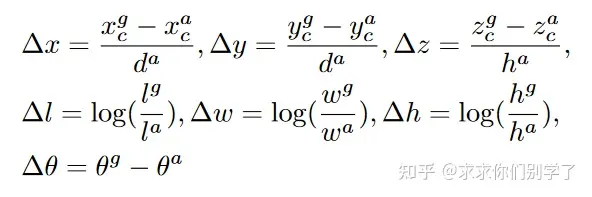
Second
用稀疏3D卷积去代替VoxelNet中的3D卷积层,提高了检测速度和内存使用;
VoxelNet论文有个比较大的缺点就是在训练过程中,与真实的3D检测框相反方向的预测检测框会有较大的损失函数,从而造成训练过程不好收敛。提出了方向二分类dir loss。
对于正负样本数量的极度不平衡问题,作者借鉴了RetinaNet中采用的Focal Loss。
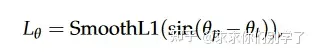
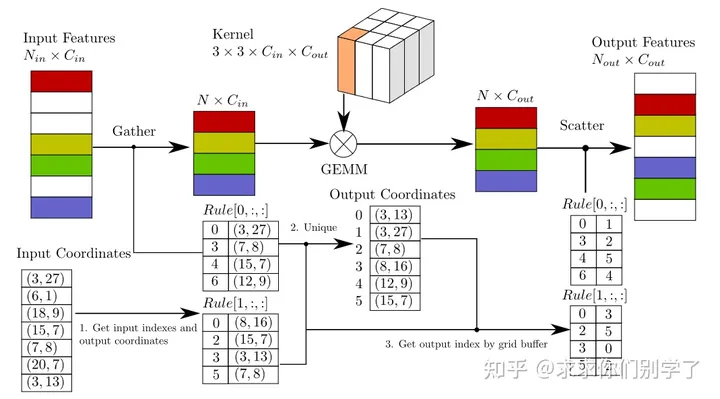
PointPillars
主打一个推理速度非常快,类似与图像2D检测。使用了 pillar而不是voxel的方式,一个(x, y) location只有一个pillar, 而不是many voxels, 元素便少了,自然速度就快了。(3D到2D的降维打击)
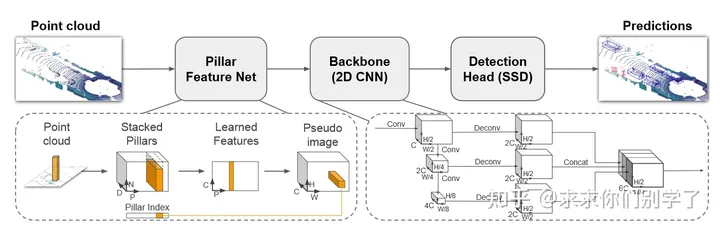
根据点云数据所在的X,Y轴(不考虑Z轴)将点云数据划分网格。即用一个个pillar柱子来代表

每个柱子随机采样N个点,不够补0
pointnet提取每个柱子的特征。原来的点云维度为D=9,处理后的维度为 C,那么我们就获得了一个(C,P,N)的张量。
Max Pooling到C,P维度,然后将P转换成W* H,即为C* W* H维度的伪图片。后续用图像的FPN思想。
损失函数与Second相同。
Second和PointPillars是与VoxelNet类似的点云目标检测方法,但它们采用的网络结构和处理方式略有不同。Second引入了稀疏3D卷积去代替VoxelNet中的3D卷积层,提高了检测速度和内存使用,并加入了一个方向dir预测的损失。PointPillars则将点云数据映射到二维BEV(bird's-eye view)图像中,并采用2D CNN对目标进行检测。相对而言,VoxelNet更注重点云的三维信息,而Second和PointPillars更注重速度和实时性。
centerpoint
使用点表示目标,简化三维目标检测任务:与图像目标检测不同,在点云中的三维目标不遵循任何特定的方向,box-based的检测器很难枚举所有的方向或为旋转的对象拟合一个轴对齐的检测框。但Center-based的方法没有这个顾虑。点没有内转角。这极大地减少了搜索空间。采用了图片检测里面centernet的思想,用点来表示物体,直接检测出3D目标的检测框中心点,并回归出检测框大小、方向和速度。它还加入了一个精细调整的阶段,对于前一阶段预测的检测框,使用检测框中心的点特征回归检测框的score并进行精细调整。
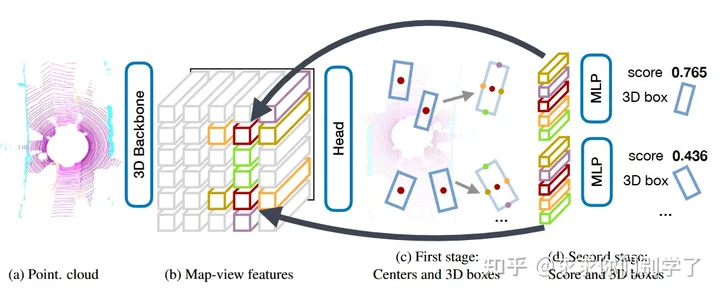
网络有四个输出:1.表征目标中心位置的热力图;2.目标尺寸;3.目标朝向;4.目标速度 (速度用于做目标跟踪,该思路来源于另一篇文章CenterTrack[2]) 。不难看出,这是一种典型的center-based anchor-free检测头。在文中,作者论述了采用这种center-based representation 对检测任务的两点好处:首先,点没有内在的方向。这大大减少了检测器的搜索空间,同时有利于网络学习对象的(rotational invariance)和等变性(rotational equivariance)。其次,在三维检测中,目标定位比对目标的其他三维属性进行更重要。这个反映在常用的评估指标中,这些指标主要依赖于检测到的目标和gt box中心之间的距离,而不是估计的3dbox的属性。笔者认为作者未提到的一个明显的好处则是,此类center-based representation方法不需要做NMS,能减少运算。
pointRCNN
类似图像中的二阶段RCNN的思想,也是获得一阶段框后进行微调。
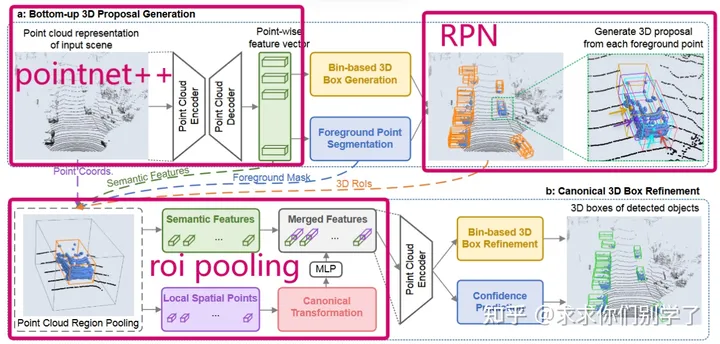
pointnet++提取点云特征,得到每个点的特征向量
对每个点进行RPN网络,分两类输出是前景还是背景。和图像不一样,图像是特征图每一个点都会生成K个框。此处进行了一个前景分割,哪一些点属于前景,每个前景会产生一个bbox(即候选框)
ROI POOling,类似pointnet的语义分割。把区域扩大一倍(能看到更多的信息),将特征ROI pooling到统一大小经过MLP,把前面提取出来的特征堆叠起来
最后进行一个分类和回归。人、车、自行车、背景类
需要注意的是,每个box的最终分类结果是由第一阶段得出,第二阶段的分类结果得到的是该类别属于前景或背景的置信度得分;此处实现与RCNN不同,需注意。
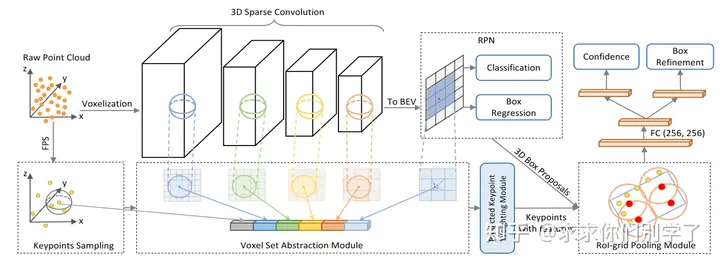
PV-RCNN
本文是一个将point_based的方法和voxel_based方法的结合的新型网络结构,基于网格的方法计算效率更高,但不可避免的信息丢失会降低细粒度的定位精度,而基于点的方法具有较高的计算成本,但可以通过点集抽象轻松实现更大的接收范围,并且提取存在的问题,这也是作者的论文出发点,结合这两种方法的优点。
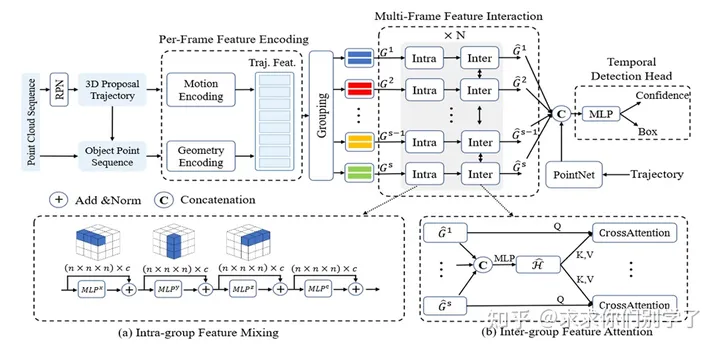
mppnet
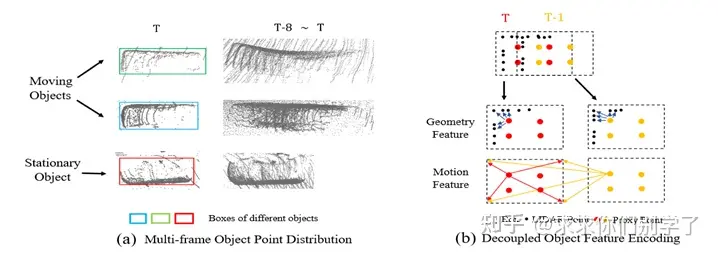
类似自动标注算法思路,将检测、跟踪、微调放在一起。先检测再跟踪,获得序列的粗糙框和物体点云。然后提出代理点的思想将点云特征和box特征结合。然后时序特征用注意力机制融合,加上box序列mlp编码。一起进行预测。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









