






作者 | ReThinkLab 编辑 | sjtuRethinking
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天为大家分享上海交通大学ReThinkLab实验室最新的工作—Bench2Drive!首个端到端自动驾驶综合能力闭环评估开放平台!如果您有相关工作需要分享,请在文末联系我们!
也欢迎添加小助理微信AIDriver004,加入我们的技术交流群
编辑 | 自动驾驶之心

Website: https://thinklab-sjtu.github.io/Bench2Drive/
Github: https://github.com/Thinklab-SJTU/Bench2Drive
Paper Think2Drive: https://arxiv.org/abs/2402.16720
Paper Bench2Drive: https://arxiv.org/abs/2406.03877
Think2Drive 公众号宣传链接: Think2Drive
介绍
ReThinkLab于2023年10月推出Think2Drive[1],一个基于隐世界模型的自动驾驶决策模型。Think2Drive有效地解决类现实驾驶环境中存在的几十种极端场景,成为首个完成CARLA V2全场景的模型。基于Think2Drive专家模型,紧接着推出了首个端到端自动驾驶综合能力闭环评估开放平台Bench2Drive[2]。
在自动驾驶场景中,极端情况(corner case)往往由多种复杂因素和条件组合而成。人类在学习驾驶的过程中,通过不断的学习和进化,逐步掌握了解决复杂问题的能力。这种能力的培养是一个从简单到复杂、逐步递进的过程。人类智能体在面对复杂的极端案例时,并不是立即就具备解决方案,而是通过多次试验和积累经验,逐步掌握应对策略。同样,自动驾驶系统在应对复杂驾驶场景时也需要多种不同的能力,而不是依赖单一的能力。例如,应对城市交通中的行人、复杂交叉路口、动态交通信号和各种天气条件等,这些都需要自动驾驶智能体在多种场景中进行学习和适应。通过在多样化的场景中训练,自动驾驶系统能够不断优化其决策和操作能力,从而有效地应对现实世界中的复杂情况。
Waymo Robotaxis因大雾天气在旧金山市中心的街道上熄火,严重扰乱交通。
端到端自动驾驶评测的现状与空白
对于自动驾驶数据而言,由于采集数据时的局限性,大量的驾驶数据都是在有安全保障的前提下采集获得,缺乏极限的交互行为数据与驾驶员微操行为的数据。就如Elon Musk所说,由于人工干预的情况非常少或者没有复杂的交互,导致只有约万分之一的驾驶数据对训练有用。而要想提高自动驾驶性能,对于corner case数据的高质量人工标注和验证就成为了重要的因素之一。6月8日,理想汽车CEO李想在中国汽车重庆论坛上发表演讲。他表示最近团队致力于自动驾驶技术的突破,他们曾思考这样一个问题:人类开车为什么不涉及学习corner case? 从人类学习新事物的角度来讲,大脑在工作的时候,一般分为两套系统,分别用于处理直觉型的、快速响应的事件以及复杂逻辑推演的事件。大多数场景通过直觉型的、快速响应的能力可以得到解决,但对于罕见的事件或者复杂逻辑推演的事件,就需要专门的VLM模型来解决各种各样问题和各种泛化的问题。对于nuScenes中的数据而言,大部分数据属于“直觉型”的数据,不需要复杂的逻辑推演。由此可见,corner case这类罕见的或者需要复杂逻辑推演的事件对于自动驾驶来说至关重要。

Elon Musk提到只有万分之一的驾驶数据对训练有用,FSD仍需大量稀有异常情况下的数据(corner case)来提高精度
端到端自动驾驶Bench2Drive详解
目前常用的数据集如nuScenes, nuPlan, CARLA Leaderboard V2等存在一定的局限性,其中包括
开环评价指标失效: nuScenes通过对已采集数据的日志回放进行开环评估。然而,L2误差和碰撞率这两个指标无法全面反映算法在实际驾驶中的性能。因为L2误差只衡量预测值与真实值之间的平方差。同时,L2误差的绝对值大小受自车速度的影响,L2误差并不能反映驾驶安全性。而碰撞率虽然能够直接反映安全性问题,但它假设了他车行为不受自车影响,缺乏交互性。在实际应用中,驾驶性能不仅仅取决于这些孤立的指标,还包括对复杂交通场景的处理能力等多个方面。因此,单纯依赖L2误差和碰撞率来评估算法驾驶性能是不够全面和科学的,需要引入更多综合性的评估指标来全面衡量算法在真实驾驶环境中的表现。
闭环评价指标粒度过于粗糙: 在CARLA Leaderboard V2中采用驾驶分数作为评估指标。然而,在长路测试时,驾驶分数往往会随着不良驾驶行为的累积而呈指数级衰减。这种衰减机制导致了驾驶分数的不合理性和不稳定性,从而使得无法直观衡量不同算法之间的性能差异。
场景单一/缺乏corner case验证: 如下图所示,在nuScenes数据集中,从未来轨迹分布中可以看出,其驾驶行为大多数是直路行驶。这种情况导致了数据集中缺乏丰富的交互场景和多样性,且无法全面反映算法在真实世界中复杂多变的交通环境中的表现。由于数据集中corner case的稀缺,驾驶算法在处理这些场景时的表现无法得到充分验证。这可能导致算法在真实世界应用中面临无法预见的问题,从而影响驾驶安全性。
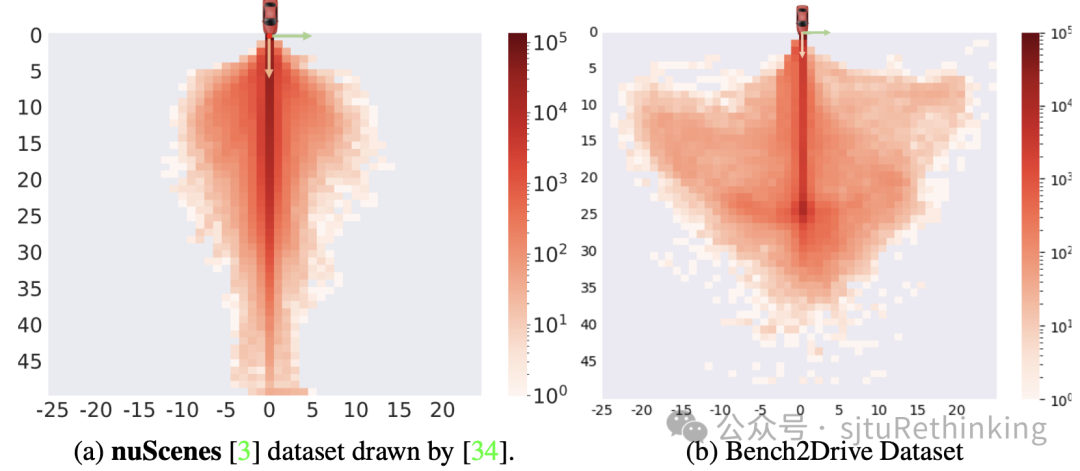
自车未来轨迹的分布。Bench2Drive拥有更多的转弯轨迹,表明动作多样性更丰富。
开环/闭环算法难较高下: 开环算法通常在静态数据集上进行评估,即算法仅对给定的感知数据进行处理,而不考虑其输出对环境的反馈。这种方法的优点在于评估过程较为简单,易于控制变量,但缺点是无法模拟实际驾驶中的动态反馈和连续决策过程。闭环算法则在动态或仿真环境中进行评估,考虑到算法输出对环境的影响,并根据环境的变化进行连续决策。这种评估方法更接近于实际驾驶情况,能够更全面地测试算法的鲁棒性和适应性。然而目前的开环算法和闭环算法在各自的数据集上争奇斗艳,很难进行同台竞技。
为了满足全面、现实和公平的完全自动驾驶(FSD)测试环境的迫切需求,我们提出了Bench2Drive,首个以闭环方式评估端到端自动驾驶(E2E-AD)系统综合能力的基准。我们致力于在自动驾驶场景中识别和解决这些corner case,通过多场景学习提升系统的综合驾驶能力,以确保更高的安全性和可靠性。
Bench2Drive是一个由专家模型Think2Drive收集的官方训练数据集,包含10000个视频片段以及200万全面的标注帧。我们的优势是,
全面的场景覆盖: Bench2Drive涵盖了44种不同的交互式场景(切入、超车和绕行等), 23种天气条件(如晴天、雾天、雨天等)和12个城镇(城市、村庄、大学等)。其中,
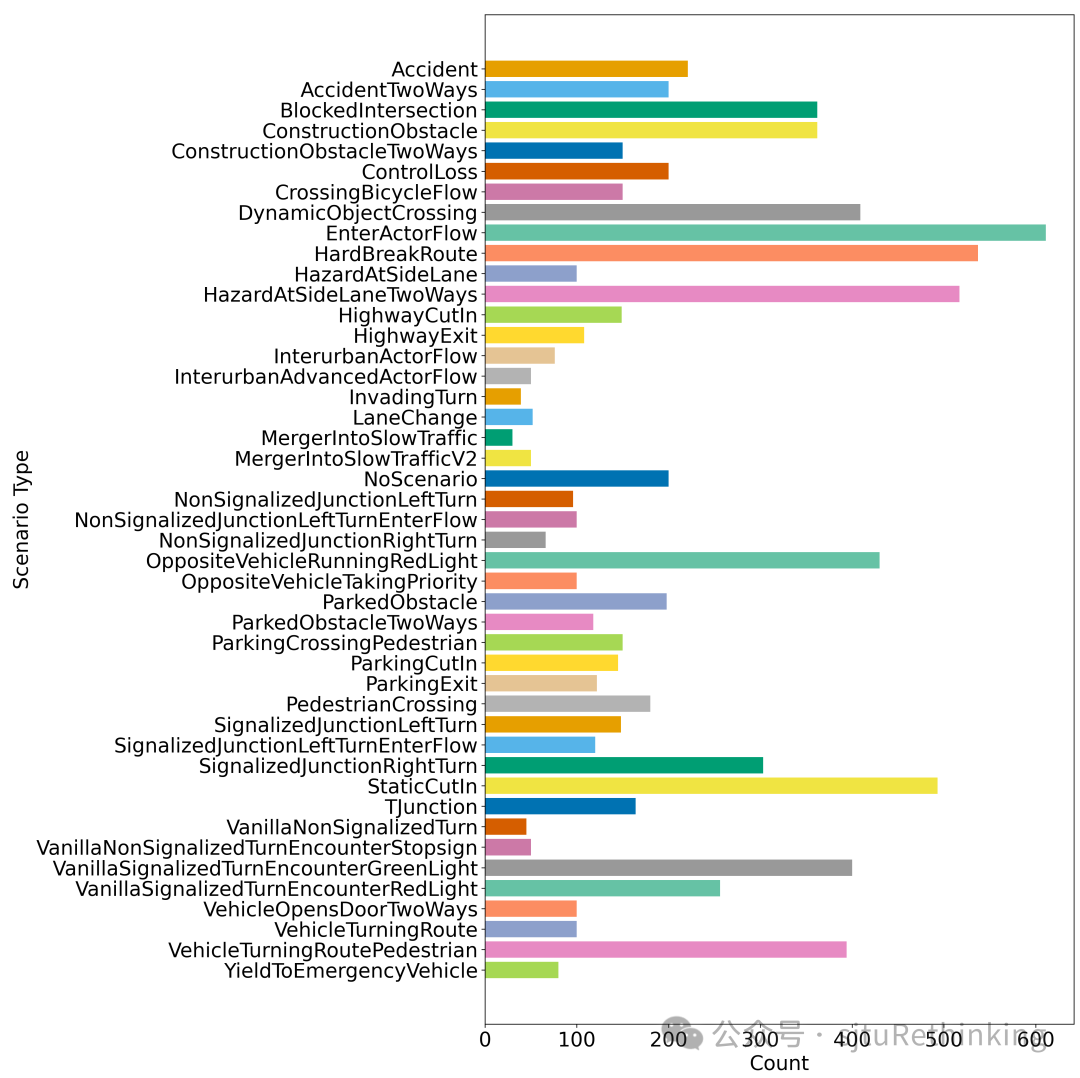
Bench2Drive 场景分布图
闭环综合能力评估: 我们总结了五种高级的驾驶技能:并线、超车、让行、交通标志、紧急刹车,并且细化了每项技能的得分。这种驾驶技能的解耦,使我们对自动驾驶系统的能力有更加深入全面的了解,从而找到性能不足的地方。
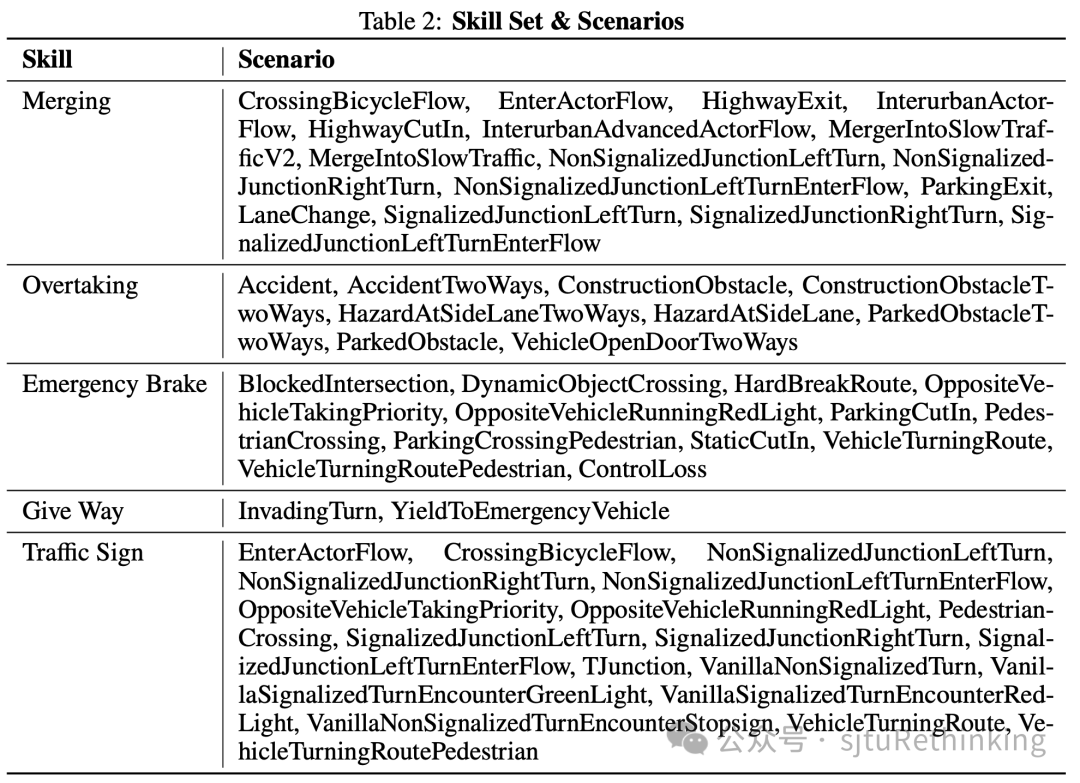
技能集 & 场景
闭环评测: 我们挑选了220条(5*44)短路线作为评测路线,每条路线大约只有150米长,并包含一个特定的复杂场景。
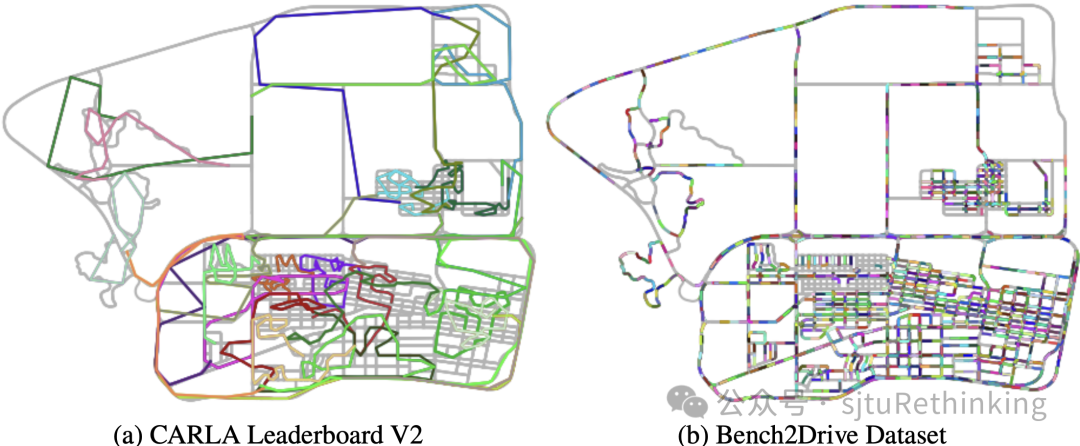
Town12上的路线长度。使用不同的颜色来表示不同的路线。Bench2Drive的短路线提供更平滑的评估。
六大基准算法实现(ADMLP, TCP, UniAD, VAD, ThinkTwice, DriveAdapter)
通过这种评估方式,将驾驶技能的不同能力展现出来,从而允许对44种不同技能集的自动驾驶系统熟练程度进行详细的比较。此外,每条路线的简短性减轻了指数衰减函数对驾驶分数的影响,使得不同系统之间的性能比较更加准确和有意义。这样一个结构化和有针对性的基准将更清楚地揭示每个自动驾驶系统的优缺点,促进有针对性的改进和更精细的技术开发。
专家数据集
为了方便社区重新实现现有的端到端自动驾驶方法,我们采用了与nuScenes类似的传感器配置:
1个激光雷达:64通道,85米范围,每秒600,000个点
6个摄像头:环绕覆盖,900x1600分辨率,JPEG压缩(质量级别20)
5个Radar:100米范围,30°水平和垂直视场
1个IMU和GNSS:位置、偏航角、速度、加速度和角速度
1个BEV摄像头:调试、可视化、遥感
高精度地图:车道、中心线、拓扑结构、动态灯光状态、灯光和停车标志的触发区域
此外,我们确保天气条件、场景和行为的分布尽可能均匀(nuScenes中大约75%的片段仅涉及本车直行)。
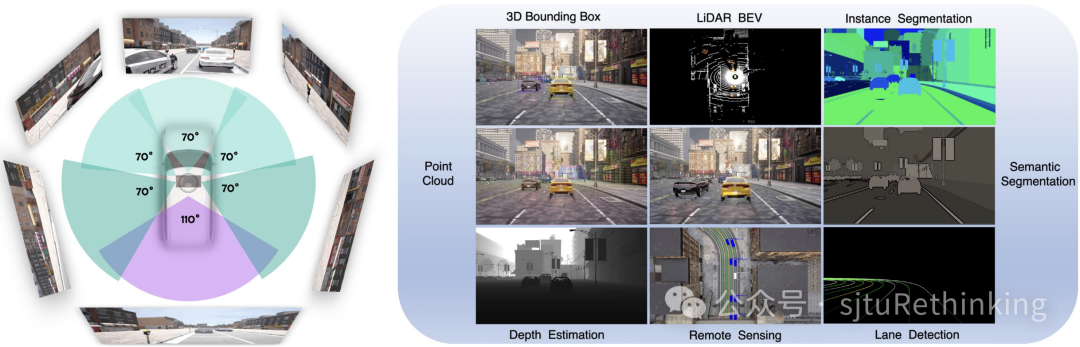
Bench2Drive 传感器设置与全面标注
端到端自动驾驶多项能力评估基准详解
现有的端对端自动驾驶评测框架如nuScenes、nuPlan、Navsim缺乏他车交互和复杂场景。而CARLA v1缺乏官方训练集导致算法对比不公平,同时缺乏复杂的场景。CARLA v2[3]通过计算所有提供路线的平均得分来评估自动驾驶系统的性能。虽然这种方法能够提供驾驶能力的总体概述,但却无法准确揭示不同方法的具体优劣。其现有基准测试,如Longest6和Leaderboard V2[4],覆盖了数公里的路程,导致驾驶得分指标的方差较大。之所以会出现这种方差,是因为违规分数通过累积乘法来惩罚错误,从而严重扭曲了结果。
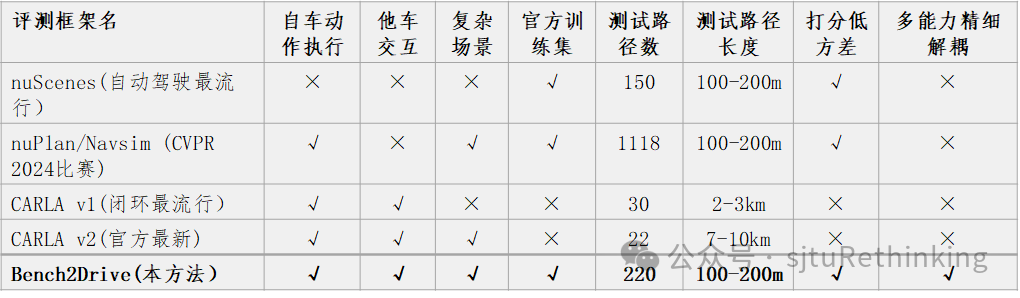
端对端自动驾驶评测框架的横向比较
我们总结了城市驾驶的5项高级技能:合并、超车、让行、交通标志和紧急制动(如下表所示),并报告每项技能的得分。这种设计使人们更清楚地了解自动驾驶系统哪些技能处理得有效,哪些技能处理得不好,从而更精细地了解系统性能。
端对端自动驾驶算法生态的支持
为了在CARLA中更好的实现开环的sota算法UniAD[9]/VAD[10],我们在初始设定时就对齐了nuScenes 的参数设定,包括传感器数量,像机的FOV/内外参等。由于UniAD/VAD这两个超级明星算法,目前没有开源的CARLA中的实现。数据对齐是第一步,第二步便是整个训练pipline的设计。为了解除历史遗留问题导致的官方实现中对torch/cuda等版本的限制,我们重构了BEVFormer/UniAD/VAD的代码实现,使得整个代码架构完全解藕torch/cuda版本,现以成功支持CUDA(11.8/12.1)及最新版本的torch(2.3)。我们开源了BEVFormer/UniAD/VAD在CARLA中的实现、pickle生成转化工具以及网络权重。我们已验证了整个pipeline对torch.compile和FlashAttention v2的支持和兼容性,为端对端自动驾驶的算法生态提供了有力的支持。除此之外,我们还复现了ADMLP[5]、TCP[6]、ThinkTwice[7]、DriveAdapter[8]等算法。
透过实验现象深度思考
开环与闭环评估指标的思考
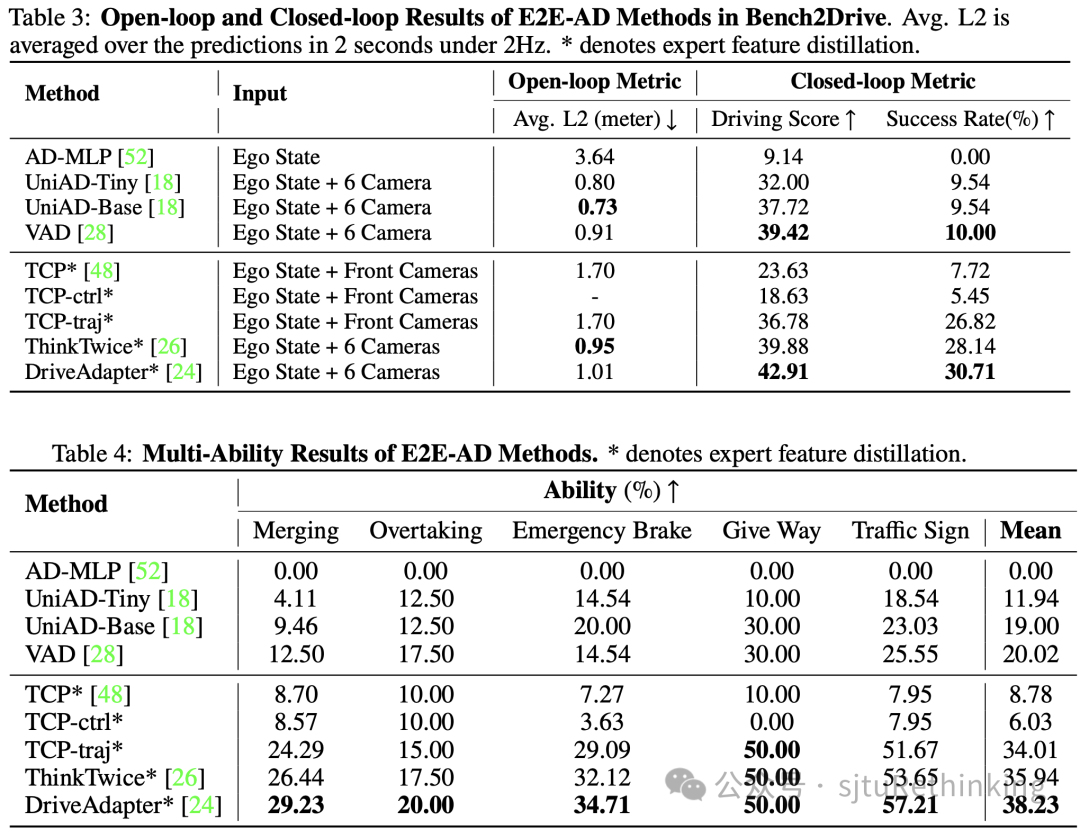
开环评估的局限性: 开环指标L2误差可以用来验证模型的收敛性和拟合状态,但在高级技能的比较中表现不佳。通过对比AD-MLP和VAD,我们发现AD-MLP的L2误差远高于VAD,其闭环性能自然相对与VAD相差甚远,似乎符合预期。但进一步观察发现,UniAD-Base的L2误差低于VAD,但闭环性能更差。这与之前的认知相矛盾。仔细分析发现,L2误差的绝对值大小受自车速度或他车行为的影响,无法准确评估驾驶的合理性和安全性。这也进一步说明开环评估对于自动驾驶评测来说,意义不大。
闭环评估的重要性:开环评估无法为数据集拟合良好的模型提供有意义的比较。闭环评估更能反映模型在复杂交互场景当中的性能和可靠性。
盲人开车(AD-MLP):AD-MLP不采用传感器数据,相当于“盲人开车”导致其在技能评估中表现极差。与nuScenes中的实验发现不同,AD-MLP在Bench2Drive中无法达到可接受的L2误差。这是因为Bench2Drive的未来轨迹分布与场景复杂多样,不再局限于直路行驶。
开环sota的对决(UniAD-Base VS VAD):UniAD-Base的L2误差低于VAD,但闭环性能更差。这表明开环评估忽略了包括分布偏移和因果混淆在内的问题。
闭环sota的对决: TCP、ThinkTwice和DriveAdapter是闭环评测中的姣姣者,TCP仅使用前视相机,感知范围有限,对于紧急让道,切入等场景无法感知后方车辆,其闭环性能低于采用环视相机的ThinkTwice和DriveAdapter。
专家特征蒸馏的重要性:TCP、ThinkTwice和DriveAdapter引入了专家特征蒸馏。专家特征蒸馏可以利用已有的驾驶知识,通过蒸馏过程将这些知识传递到模型中,减轻过拟合的问题。相比于未采用专家特征蒸馏的模型,TCP、ThinkTwice和DriveAdapter取得了较好的闭环评测效果,足以证明专家特征蒸馏的重要性。
模型大小对性能的影响(UniAD-Base VS Uniad-Tiny): 增加BEV的尺寸及模型大小对性能的提升符合最近NLP领域的一些共识(Scaling Law)。模型容量与模型大小息息相关,增加BEV尺寸同时也带来了更大的感知范围。
总的来说,尽管开环指标有助于评估模型的收敛性,但在高级能力评估中需要闭环评估来验证模型的实际性能。闭环评估的重要性在于其能够揭示模型在复杂交互环境中的表现,避免因开环评估的局限性导致的高性能陷阱。
招募天下corner case,共筑未来智能驾驶
人类在成长过程中,是一个不断学习进化的过程。复杂的corner case往往是多种条件和因素共同导致的,人类智能体并不是一开始就掌握了复杂问题的解决方案,而是由易到难,举一反三的过程。当然自动驾驶智能体也是,我们志在寻找工业界大量自动驾驶场景中的corner case,共同打造丰富的困难样本,推动自动驾驶领域的不断发展。
联系邮箱:yanjunchi@sjtu.edu.cn
结语
Bench2Drive作为一个新基准,专为评估端到端自动驾驶的综合能力而设计。我们开源了一个大规模且详细的数据集,供研究和训练使用。同时,我们提供了一套精细化评估驾驶技能的工具包,旨在全面测试和分析最新的自动驾驶方法。通过这些工具,我们深入分析了各方法的优缺点,助力学术界和工业界在这一领域的进步。我们诚邀广大研究者和开发者积极参与,分享使用心得,并提出宝贵的改进建议。
Reference:
[1]: Qifeng Li, Xiaosong Jia, Shaobo Wang, and Junchi Yan. "Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-V2)." arXiv preprint arXiv:2402.16720 (2024).
[2]: Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Driving[J]. arXiv preprint arXiv:2406.03877, 2024.
[3]: Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. "CARLA: An open urban driving simulator." In Conference on robot learning, pp. 1-16. PMLR, 2017.
[4]: CARLA: CARLA autonomous driving leaderboard (2022), https://leaderboard.CARLA.org/2
[5]: Jiang-Tian Zhai, Feng Z, Du J, et al. Rethinking the open-loop evaluation of end-to-end autonomous driving in nuscenes[J]. arXiv preprint arXiv:2305.10430, 2023.
[6]: Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. "Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline." Advances in Neural Information Processing Systems 35 (2022): 6119-6132.
[7]: Xiaosong Jia, Penghao Wu, Li Chen, Jiangwei Xie, Conghui He, Junchi Yan, and Hongyang Li. "Think twice before driving: Towards scalable decoders for end-to-end autonomous driving." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21983-21994. 2023.
[8]: Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, and Hongyang Li. "Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7953-7963. 2023.
[9]: Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai et al. "Planning-oriented autonomous driving." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17853-17862. 2023.
[10]: Bo Jiang, Chen S, Xu Q, et al. Vad: Vectorized scene representation for efficient autonomous driving[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 8340-8350.
ReThinkLab组简介与自动驾驶方向近年成果:
上海交通大学ReThinkLab成立于2018年,紧密围绕上海市人工智能、集成电路、生物医药三大先导产业,开展前沿交叉探索。ReThinkLab近年来在自动驾驶方向上的成果横跨自动驾驶中的感知、预测、决策领域,并开创性的深入探索了感知决策一体化自动驾驶,其中包括清华A/CCF-A类论文10余篇,CVPR2023最佳论文、CVPR2024最佳论文候选, 两篇Oral (<3%)工作;发表的内容包括BEV算法、LiDAR目标检测、车道线检测、轨迹预测、行为决策、端到端自动驾驶,在CARLA V1/V2,nuScenes, Waymo等多个公开数据集上取得了国际领先的性能,尤其是在端到端自动驾驶方面的工作已成为领域经典算法。近期代表性成果如下:
自动驾驶感知:
[1] ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation. ICLR 2024
[2] LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving. ICLR 2024
[3] SPOT: Scalable 3D Pre-training via Occupancy Prediction for Autonomous Driving. arXiv 2309.10527
[4] OpenLane-V2: A Topology Reasoning Benchmark for Scene Understanding in Autonomous Driving. NeurIPS 2023
[5] Distilling Focal Knowledge from Imperfect Expert. CVPR 2023
[6] OpenDenseLane: a New LiDAR-based dataset for HD map construction. ICME 2022
[7] PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark. ECCV 2022 (Oral)
自动驾驶预测:
[8] AMP: Autoregressive Motion Prediction Revisited with Next Token Prediction for Autonomous Driving. arXiv 2403.13331
[9] HDGT: Heterogeneous Driving Graph Transformer for Multi-Agent Trajectory Prediction via Scene Encoding. IEEE TPAMI, 2023
[10] Towards Capturing the Temporal Dynamics for Trajectory Prediction: a Coarse-to-Fine Approach. CoRL 2022
[11] Trajectory Prediction from Ego View: a Coordinate Transform and Tail-light Event Driven Approach. ICME 2022
自动驾驶决策:
[12] Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2). arXiv 2402.16720
[13] Learning Dynamic Graph for Overtaking Strategy in Autonomous Driving. IEEE TITS, 2023
端到端自动驾驶:
[14] DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving. IEEE/CVF International Conference on Computer Vision ICCV 2023 (Oral)
[15] Think Twice before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving. CVPR 2023
[16] Policy Pre-training for Autonomous Driving via Self-supervised Geometric Modeling. ICLR 2023
[17] ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning. ECCV 2022
[18] Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline. NeurIPS 2022
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









