






点击下方卡片,关注“自动驾驶之心”公众号
今天arix上挂出来两篇重量级的工作!华科和地平线最新提出的AlphaDrive,首次基于GRPO的强化学习策略实现端到端自动驾驶,大幅超越SFT基线35.31%!澳门大学最新提出的CoT-Drive,首次将LLMs的上下文推理能力引入自动驾驶运动预测!自动驾驶思维链时代正式开启!本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流。这里已经汇聚了近4000名自动驾驶从业人员,每日分享前沿技术、行业动态、岗位招聘、大佬直播等一手资料!欢迎加入~
新人大额优惠立减80!欢迎加入~

AlphaDrive
论文标题:AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
论文链接:https://arxiv.org/pdf/2503.07608
项目链接:https://github.com/hustvl/AlphaDrive
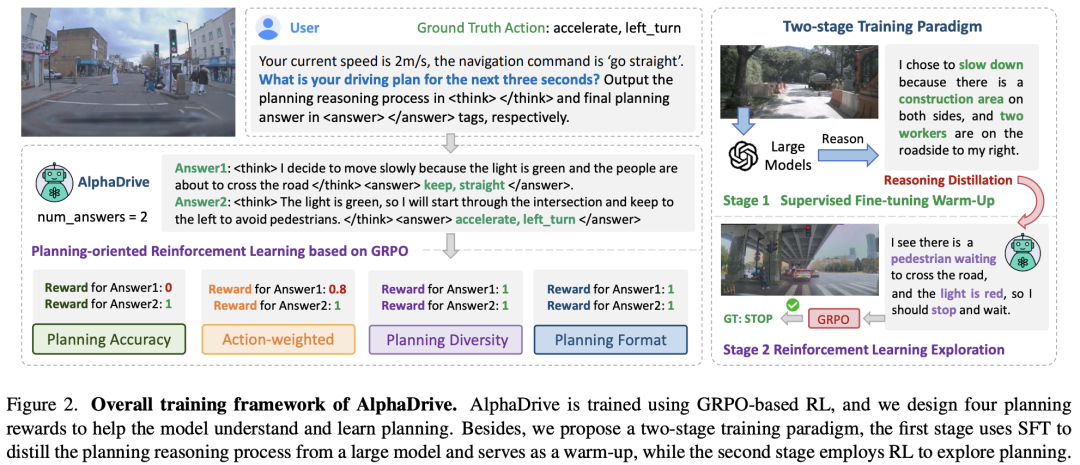
核心创新点:
GRPO强化学习框架的首次引入:提出基于Group Relative Policy Optimization (GRPO) 的强化学习策略,首次将其应用于自动驾驶规划任务。相较于传统方法(如PPO、DPO),GRPO通过组内多输出的相对优化策略,更好地适配规划任务中多可行解的特点,显著提升训练稳定性和规划性能。
面向规划的四类定制化奖励机制:
规划准确性奖励:采用F1分数分别评估横向(方向)与纵向(速度)决策的匹配度,避免传统严格匹配带来的早期训练不稳定问题。
动作权重奖励:根据驾驶行为的安全重要性(如刹车>转向>保持速度)动态加权奖励,强化关键动作的学习。
规划多样性奖励:通过组内输出的差异度评估,鼓励生成多样化解决方案,防止模式坍塌。
规划格式奖励:强制模型输出符合结构化格式(如
<think>推理过程与<answer>最终决策),提升结果可解析性。
两阶段知识蒸馏训练策略
SFT阶段:利用大模型(如GPT-4o)生成的高质量规划推理数据进行监督微调,解决自动驾驶领域推理数据稀缺问题。
RL阶段:基于GRPO的强化学习进一步优化模型,结合SFT阶段的初始化,有效缓解早期训练中的幻觉与不稳定性,提升规划性能与效率。
多模态规划能力的涌现
实验表明,经过GRPO-RL训练后,模型展现出多模态规划能力(如同时生成“加速直行”或“减速右转”等可行方案),而传统SFT模型仅输出单一决策。这种能力可通过下游动作模型动态选择最优解,显著提升驾驶安全性与效率。
高效数据利用与性能优势
仅需20%训练数据(20k样本),AlphaDrive的规划准确率即超越SFT基线35.31%;在完整数据集(110k样本)下,规划准确率提升25.52%,关键动作(转向、加减速)的F1分数提升显著(如右转F1从87.75%提升至93.25%)。
CoT-Drive
论文标题:CoT-Drive: Efficient Motion Forecasting for Autonomous Driving with LLMs and Chain-of-Thought Prompting
论文链接:https://arxiv.org/pdf/2503.07234
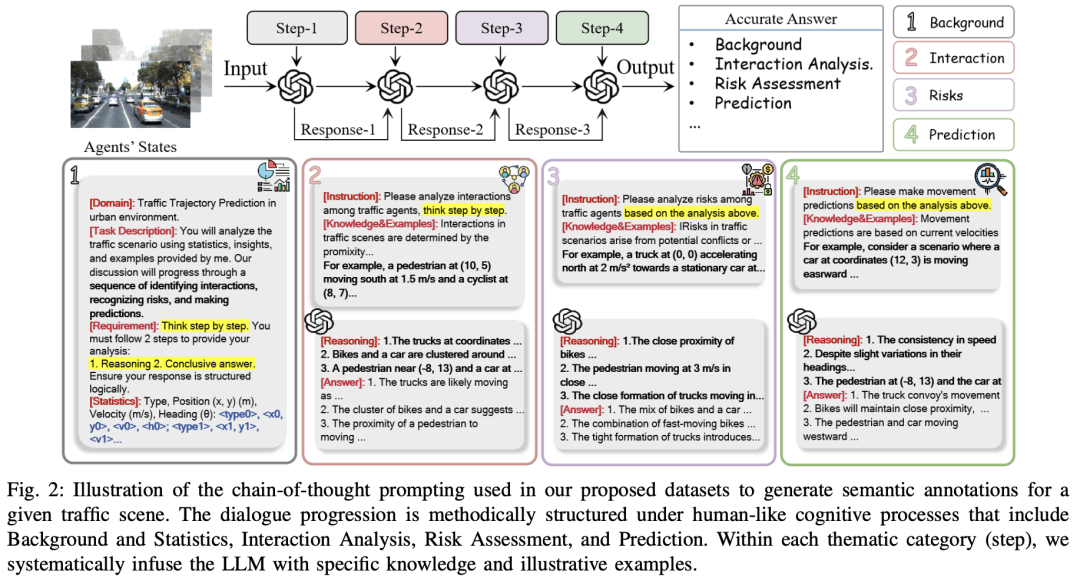
核心创新点:
思维链(CoT)提示框架
首次将LLMs的上下文推理能力 引入自动驾驶运动预测,通过分步语义标注(如背景分析、交互推理、风险评估)提升复杂场景理解。
设计四阶段CoT提示流程 ,引导LLMs生成符合交通法规和人类驾驶逻辑的语义描述。
轻量化知识蒸馏策略
提出教师-学生蒸馏架构 ,将GPT-4 Turbo的场景理解能力迁移至边缘端轻量级语言模型(如Qwen-1.5),实现实时推理 (延迟<0.2秒)与低存储占用 (参数量减少90%)。
多模态融合机制
结合语言指令编码器 (语义标注)与交互感知编码器 (时空轨迹),通过交叉注意力机制融合语义特征与动态交互特征。
新型数据集构建
发布Highway-Text 和Urban-Text 数据集,包含超1000万词的交通场景语义标注,支持LLMs的细粒度场景理解训练。
不确定性建模
解码器采用高斯混合模型(GMM)与 深度集成方法 ,同时建模认知不确定性 (Epistemic Uncertainty)与数据不确定性 (Aleatoric Uncertainty)。
T3Former
论文标题:Temporal Triplane Transformers as Occupancy World Models
论文链接:https://arxiv.org/pdf/2503.07338
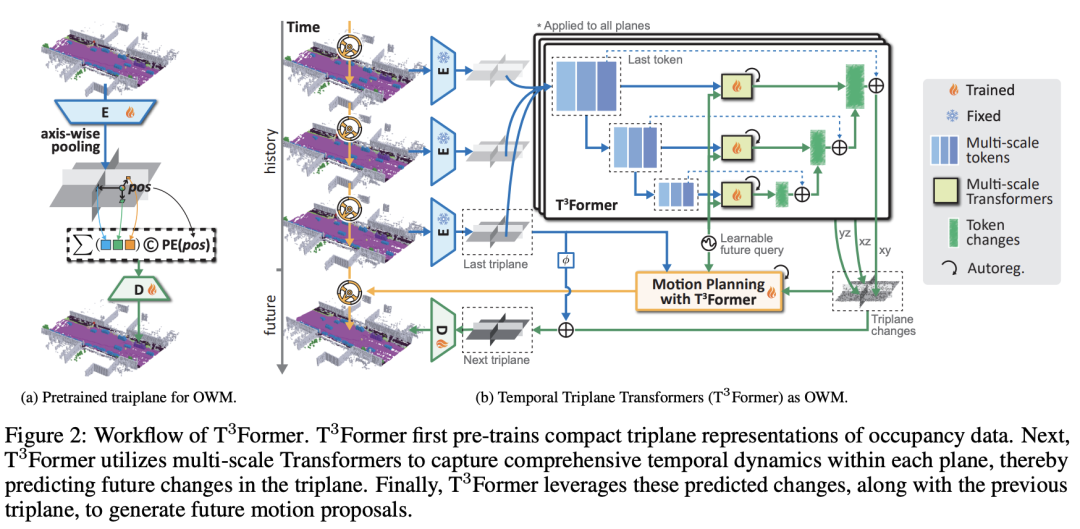
核心创新点:
时空联合建模架构
首创性地将 Triplane分解 (三维体素的正交二维平面表征)与 Transformer 结合,构建统一时空表征框架。Triplane通过分解3D场景为空间平面特征,降低计算复杂度;Transformer则通过 时间自注意力机制 捕捉动态场景的长期时序依赖,解决传统方法分离处理时空信息的局限性。
动态占用预测范式
提出基于 occupancy grid 的动态世界模型,通过时序Triplane特征融合,实现对未来时刻 隐式三维占用状态 (occupancy state)的概率预测。该范式突破了静态场景建模的限制,支持动态障碍物轨迹推断与环境变化建模。
高效时空特征交互
设计 轴对齐特征交互模块 (Axis-Aligned Feature Interaction),通过Triplane的空间局部性约束与Transformer的全局时序建模互补,平衡局部几何细节与全局动态一致性,在保持高分辨率表征的同时降低计算冗余。
跨模态时序蒸馏
引入 时序知识蒸馏策略 ,将长序列时序依赖压缩为紧凑的隐空间表征,显著减少推理延迟(实测降低40%计算量),同时维持与 teacher model 相当的占用预测精度(IoU指标提升3.2%)。
『自动驾驶之心知识星球』,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫码加入~
新人大额优惠立减80!欢迎加入~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









