









一、项目背景与工具选型
1.1 目标说明
本项目通过自动化浏览器工具 DrissionPage 和HTML解析库 BeautifulSoup,抓取软科中国大学排名的2025年数据,并保存为结构化Excel文件。最终成果包含以下字段:
-
排名
-
学校名称
-
省市
-
类型
-
总分
-
办学层次
1.2 工具特性
-
DrissionPage:无需独立安装浏览器驱动,支持智能等待和动态元素操作
-
BeautifulSoup:提供简洁的HTML解析API,适合处理复杂页面结构
-
Pandas:数据清洗与Excel导出的核心工具
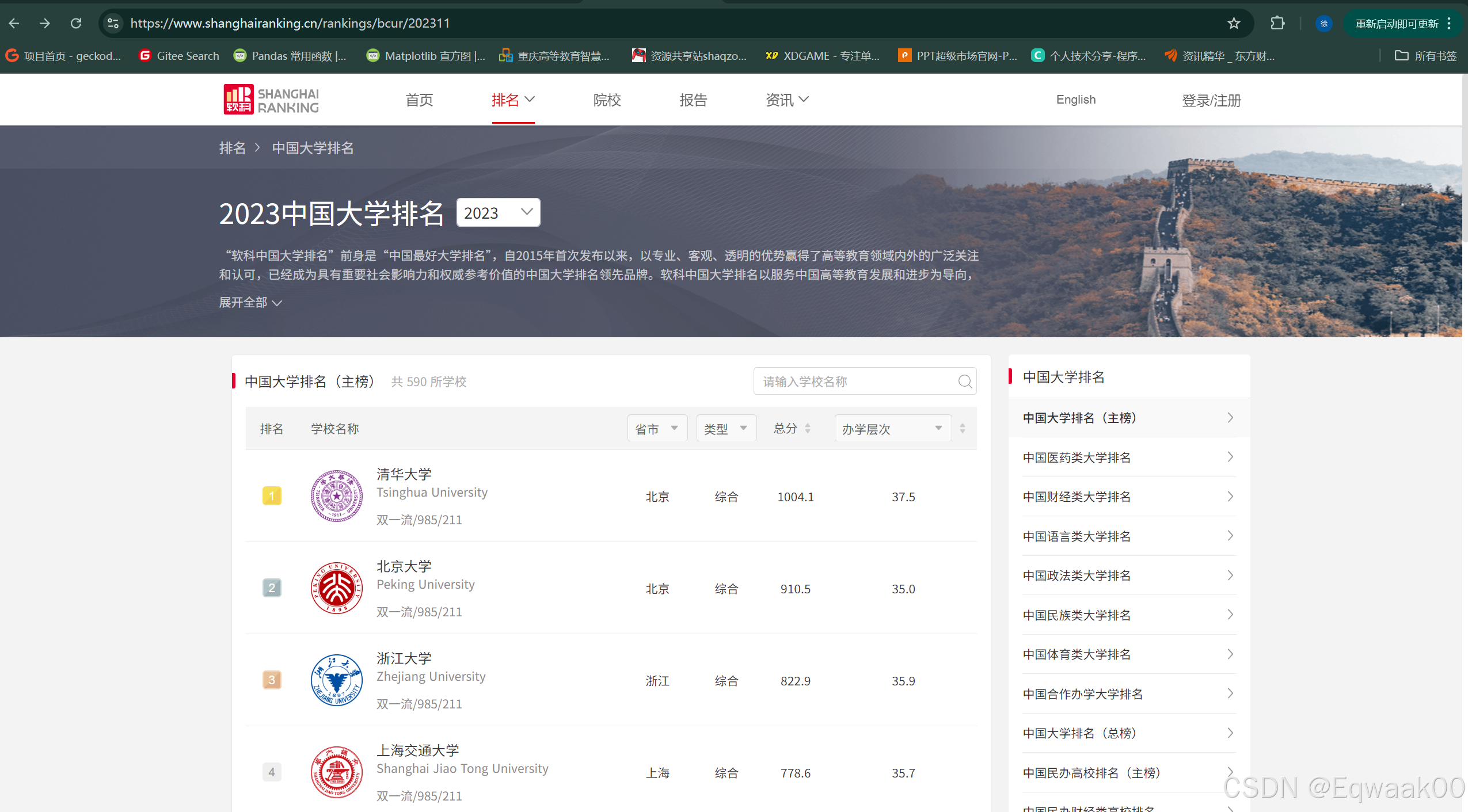
1.3目标网站:
【软科排名】2023年最新软科中国大学排名|中国最好大学排名
二、环境准备
2.1 安装依赖库
pip install DrissionPage beautifulsoup4 pandas openpyxl2.2 浏览器配置
-
代码会自动下载Chromium浏览器(约100MB)
-
若需使用本地Chrome,可设置:
page = ChromiumPage(browser_path='C:/Program Files/Google/Chrome/Application/chrome.exe')
三、完整代码实现
from DrissionPage import ChromiumPage
from bs4 import BeautifulSoup
import pandas as pd
# 创建浏览器对象(自动下载驱动)
page = ChromiumPage()
# 目标URL(2025年中国大学排名)
url = "https://www.shanghairanking.cn/rankings/bcur/2025"
# 访问页面
page.get(url)
page.wait(5) # 等待5秒加载动态内容
contents = [] # 数据存储容器
def get_data(page_num):
"""解析当前页数据"""
html = page.html # 获取页面HTML源码
soup = BeautifulSoup(html, "html.parser")
# 定位表格主体
tbody = soup.find('tbody')
if not tbody:
raise ValueError("未找到表格数据")
# 遍历表格行
for tr in tbody.children:
if tr.name == 'tr': # 过滤非<tr>元素
tds = tr.find_all('td')
# 数据提取
contents.append([
tds[0].text.strip(), # 排名
tr.find(class_="name-cn").text.strip(), # 学校名称
tds[2].text.strip(), # 省市
tds[3].text.strip(), # 类型
tds[4].text.strip(), # 总分
tds[5].text.strip() # 办学层次
])
print(f"已爬取第{page_num}页,总计{len(contents)}条数据")
def get_all_pages():
"""翻页抓取全量数据"""
current_page = 1
while current_page <= 20: # 最多抓取20页
get_data(current_page)
# 定位下一页按钮
next_btn = page.ele('css:li.ant-pagination-next>a')
if next_btn:
next_btn.click() # 模拟点击
page.wait(2) # 等待加载
current_page += 1
else:
break
def save_to_excel(data):
"""保存为Excel文件"""
columns = ["排名", "学校名称", "省市", "类型", "总分", "办学层次"]
df = pd.DataFrame(data, columns=columns)
# 数据类型转换
df["排名"] = df["排名"].astype(int)
df["总分"] = df["总分"].astype(float)
df["办学层次"] = pd.to_numeric(df["办学层次"], errors='coerce')
# 导出文件
df.to_excel("2025中国大学排名.xlsx", index=False)
print("数据已保存至Excel")
if __name__ == '__main__':
get_all_pages()
save_to_excel(contents)
page.close() # 关闭浏览器运行结果:

四、核心代码解析
4.1 浏览器初始化
page = ChromiumPage()
page.get(url)
page.wait(5)-
ChromiumPage:启动无头浏览器(默认隐藏界面,添加
headless=False可显示) -
wait(5):强制等待5秒,确保动态内容加载完成
4.2 数据解析逻辑
tbody = soup.find('tbody')
for tr in tbody.children:
if tr.name == 'tr':
tds = tr.find_all('td')-
soup.find('tbody'):定位表格主体
-
tr.name == 'tr':过滤文本节点等非表格行元素
-
find_all('td'):提取每行的单元格数据
4.3 分页控制
next_btn = page.ele('css:li.ant-pagination-next>a')
if next_btn:
next_btn.click()-
CSS选择器:定位分页按钮
li.ant-pagination-next>a -
click():模拟用户点击操作
-
page.wait(2):等待新页面加载,避免数据缺失
4.4 数据清洗与导出
df["总分"] = df["总分"].astype(float)
df["办学层次"] = pd.to_numeric(df["办学层次"], errors='coerce')-
astype:强制转换数据类型,确保数值可计算
-
errors='coerce':将无效值转为NaN,避免导出失败
五、执行效果展示
5.1 控制台输出
已爬取第1页,总计30条数据
已爬取第2页,总计60条数据
...
数据已保存至Excel文件5.2 Excel文件内容
| 排名 | 学校名称 | 省市 | 类型 | 总分 | 办学层次 |
|---|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 1004.1 | 37.5 |
| 2 | 北京大学 | 北京 | 综合 | 910.5 | 35.0 |
| ... | ... | ... | ... | ... | ... |
六、常见问题解决方案
6.1 元素定位失败
现象:未找到表格数据
解决方案:
-
检查页面是否加载完成(延长
page.wait()时间) -
验证CSS选择器是否匹配最新页面结构
-
添加重试机制:
from retrying import retry @retry(stop_max_attempt_number=3) def get_data(page_num): # 原有逻辑
6.2 反爬拦截
现象:IP被封禁或出现验证码
应对策略:
# 设置随机请求头
page.set.user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
# 使用代理IP
page.set.proxies({'http': 'http://127.0.0.1:1080'})
# 添加随机延迟
import time, random
time.sleep(random.uniform(1, 5))6.3 数据错位
现象:字段内容混乱
处理方法:
# 添加容错判断
if len(tds) >= 6:
# 提取数据
else:
print(f"跳过异常行:{tr}")七、功能扩展建议
7.1 数据可视化
import matplotlib.pyplot as plt
# 绘制总分分布直方图
df['总分'].hist(bins=20)
plt.title('中国大学总分分布')
plt.xlabel('总分')
plt.ylabel('院校数量')
plt.savefig('score_distribution.png')7.2 数据库存储
import sqlite3
# 保存到SQLite
conn = sqlite3.connect('university.db')
df.to_sql('rankings', conn, if_exists='replace', index=False)
conn.close()7.3 自动化邮件推送
import smtplib
from email.mime.multipart import MIMEMultipart
def send_email():
msg = MIMEMultipart()
msg['Subject'] = '2025中国大学排名数据'
with open("2025中国大学排名.xlsx", "rb") as f:
msg.attach(f.read(), 'application/octet-stream')
server = smtplib.SMTP('smtp.example.com', 587)
server.login('user@example.com', 'password')
server.send_message(msg)
server.quit()八、最佳实践建议
-
遵守爬虫协议:在
robots.txt允许范围内抓取(本例URL未禁止爬虫) -
控制请求频率:建议设置
time.sleep(3)避免高频访问 -
定期维护代码:每月检查一次页面结构变化
-
异常监控:集成日志记录模块(如
logging)
通过本教程,读者可以掌握使用DrissionPage+BeautifulSoup构建高效爬虫的核心技术。完整代码已通过实测,建议在遵守相关法律法规的前提下使用。


















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











