






点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享西安交通大学最新的工作!DualDiff+:基于奖励引导的双分支扩散模型实现高保真自动驾驶场景生成!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『场景生成』技术交流群
论文作者 | Zhao Yang等
编辑 | 自动驾驶之心
题目:DualDiff+: Dual-Branch Diffusion for High-Fidelity Video Generation with Reward Guidance
paper:https://www.alphaxiv.org/abs/2503.03689
github:https://github.com/yangzhaojason/DualDiff
DualDiff: Dual-branch Diffusion Model for Autonomous Driving with Semantic Fusion accepted by ICRA2025.
在自动驾驶领域,如何高精度且高保真地重建驾驶场景是一个关键挑战。当前的方法往往采用有限的条件信息来生成场景,例如依赖3D边界框或鸟瞰图(BEV)道路地图对前景和背景进行控制。这类简化的条件编码存在明显局限,难以全面刻画真实驾驶场景的复杂性,导致与基于视角的图像生成模型不匹配,从而出现生成结果不准确等问题。具体来说,现有方案主要面临以下痛点:
条件编码不充分:许多方法使用的条件表示(如3D边界框、BEV语义图等)过于简化,无法充分表征场景中的丰富信息。这种欠完善的条件输入会与图像生成网络产生视角不匹配,从而影响生成图像的准确性。
跨模态融合不足:在多传感器、多模态信息融合方面,现有方法缺乏动态聚焦相关信息的机制,难以有效整合来自不同来源的线索。这会限制生成场景的质量,例如无法同时兼顾视觉外观与语义内容。
缺乏视频整体一致性:许多生成技术侧重于单帧的像素细节优化,而忽略了视频序列的全局时空一致性。这导致生成的视频在帧间可能出现不连贯的现象,难以满足自动驾驶对连续场景的要求。
以上局限使得驾驶场景的高保真视频生成仍然困难。针对这些问题,西安交通大学、浙江大学、中国科学技术大学的研究者提出了全新的方法——DualDiff+。该方法通过引入更丰富的条件输入和创新的模型架构,显著提升了多视角下驾驶视频的生成质量和一致性。
双分支扩散模型架构
DualDiff+模型架构概览:采用前景-背景双分支的扩散生成架构。上面分支专注于前景动态物体(车辆、行人等),下面分支专注于背景静态场景(车道、建筑等),通过U-Net结构在中间融合两分支特征输出完整场景。模型以多源条件信息为输入(包括相机视角下的占据采样结果等),通过语义融合注意力机制(SFA)提取前景和背景各自的特征序列,再经由残差连接融合于U-Net解码器中。视频生成采用两阶段训练策略:第一阶段训练空间-时间注意力(ST-Attn)和时间的注意力模块;第二阶段引入奖励引导扩散(RGD)框架并结合低秩适配(LoRA)微调注意力权重,从而提升生成视频的全局一致性和语义连贯性。
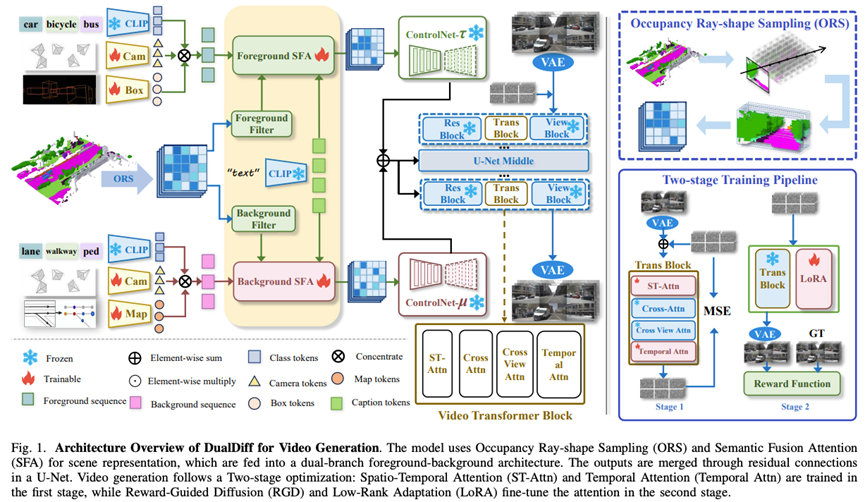
为实现上述目标,DualDiff+ 提出了多项关键技术创新:
Occupancy Ray-shape Sampling (ORS)
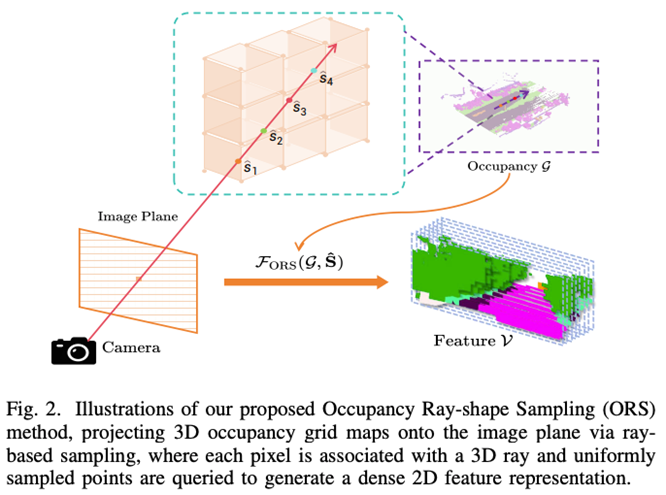
为了提供更丰富且精准的条件输入,DualDiff+ 提出了 Occupancy Ray-shape Sampling(ORS)方法,并结合 Multi-Plane Image(MPI)表示构建了细粒度的三维语义感知结构。ORS 通过摄像机的内外参,令每个图像像素对应一条在三维空间中的视线射线,并沿射线方向采样多个点,从场景的三维占据网格(occupancy grid)中提取每个采样点的占据信息和语义特征。这些采样结果随后投影回图像平面,形成了密集的射线向量编码,使每个像素都携带了视线方向上的空间结构信息,包括前景的实体轮廓与更远背景的场景布局。
通过这种分层采样策略,DualDiff+ 在每个摄像机视角下隐式构建了类似多平面图像(MPI)的表达形式,将场景表示为多个平行深度平面,每个平面包含不同深度处的语义和几何信息。这种表征不仅丰富了像素级条件输入,还有效增强了多摄像头之间的几何一致性和空间连贯性,避免了传统BEV语义图或3D边界框描述中常见的视角不匹配问题。MPI 式表示为模型提供了统一的三维先验,使得从任意摄像头视角生成的视频片段都能保持内容一致、结构准确,尤其适用于自动驾驶中的多摄像头融合和复杂交通场景的真实合成。
前景感知掩码 (FGM) & 语义融合注意力 (SFA) 机制
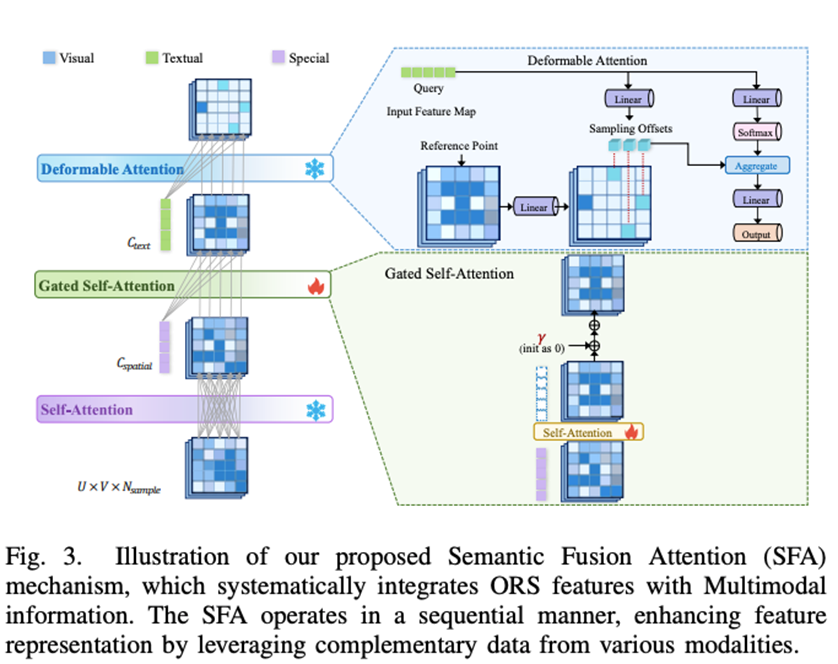
为了提升前景目标的生成质量,DualDiff+ 引入了前景感知掩码(Foreground-Aware Mask, FGM)机制。在扩散模型的训练中,FGM 根据前景目标(如车辆、行人)在图像中的投影区域动态生成权重掩码,对其像素赋予更高的损失权重,从而引导模型更加关注前景的细节还原。该策略对远距离、小尺度或形状复杂的物体尤其有效,有助于提升生成视频中前景目标的清晰度与结构保真度。
同时,DualDiff+ 还设计了语义融合注意力机制(Semantic Fusion Attention, SFA),用于多模态条件信息的动态融合。SFA 通过空间自注意力、门控交叉注意力和可变形注意力三阶段处理流程,自动聚焦于与语义条件(如文本描述、类别标签)高度相关的多模态条件特征,增强多源信息间的协同建模能力。该机制使模型在图像生成过程中兼顾像素细节与语义一致性,尤其适用于复杂驾驶场景下的多模态条件控制。
奖励引导 (Reward Guidance) 策略
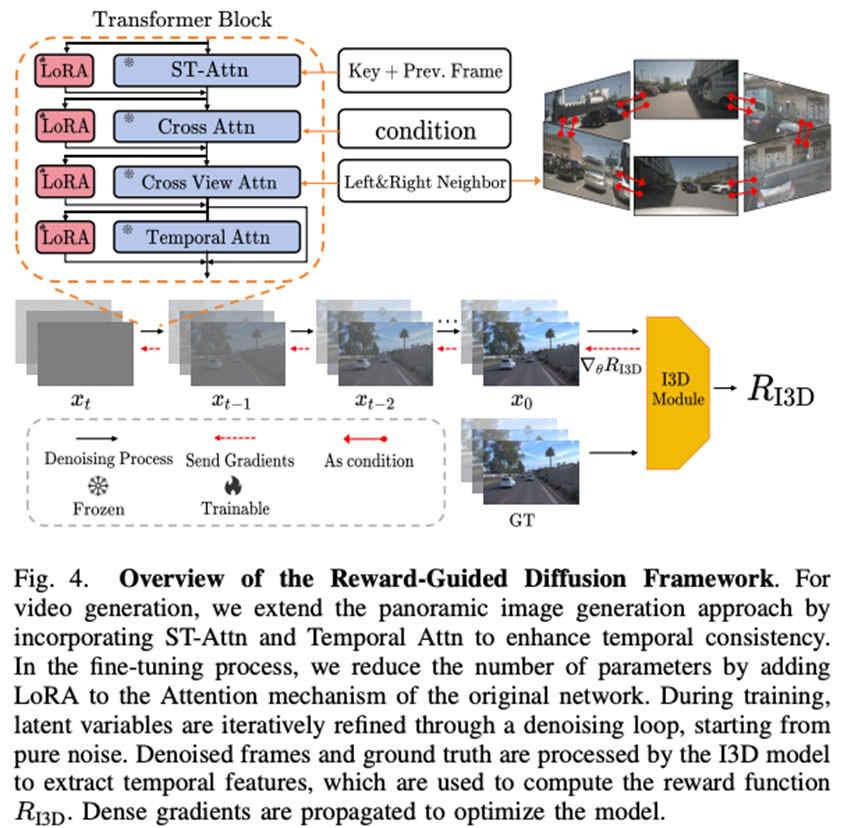
为了确保视频序列在全局上的连贯性和真实性,DualDiff+ 在视频生成阶段引入了奖励引导机制。具体而言,作者提出了奖励引导扩散(Reward-Guided Diffusion, RGD)框架,将强化学习中的“奖励”思想融入扩散模型的生成过程中。RGD 构建了一个基于高层语义特征的奖励模型,该模型以真实视频数据为参考,对生成视频的质量进行评估打分。这个奖励函数是可微分的,能够衡量生成视频与真实视频在语义结构上的差距,并将评分结果反馈给扩散模型。在训练的第二阶段,DualDiff+ 从随机噪声开始逐帧生成视频,同时根据奖励模型给出的反馈不断调整生成策略。每一次迭代,扩散模型都会尝试提高奖励分值,即让生成的视频在全局一致性和语义连贯性上更接近真实数据。通过这种方式,奖励引导策略有效地避免了仅关注像素级损失可能导致的偏差,促使模型在长时间序列上保持逻辑合理的演变。简言之,RGD 让 DualDiff+ 学会“评价”自己的生成,并朝着更优的方向优化,从而输出高质量、连贯的驾驶场景视频。
实验结果与性能指标
论文在 nuScenes 等自动驾驶数据集上对 DualDiff+ 进行了大量实验评估,结果显示该方法在生成质量和下游感知性能上都达到了新的最先进水平。在视频生成质量方面,DualDiff+ 相比最佳基线模型显著降低了FID分数(降低了 4.09%)。这意味着 DualDiff+ 生成的视频帧与真实数据分布更加接近,视觉逼真度更高。此外,其视频序列的一致性也有所提升——FVD等时序指标优于现有方法。在BEV感知等下游任务中,DualDiff+ 展现出生成数据对感知模型的高度辅助价值:以生成的视频训练或评估感知算法,BEV语义分割任务中车辆类别的 mIoU 提升了 4.50%,道路类别 mIoU 提升了 1.70%;在BEV 3D 目标检测任务中,前景目标的 mAP 提高了 1.46%。这些指标的提升表明,与DualDiff+生成的数据进行训练或测试,可以使自动驾驶感知模型更准确地识别道路场景中的关键目标,更多详细指标见论文
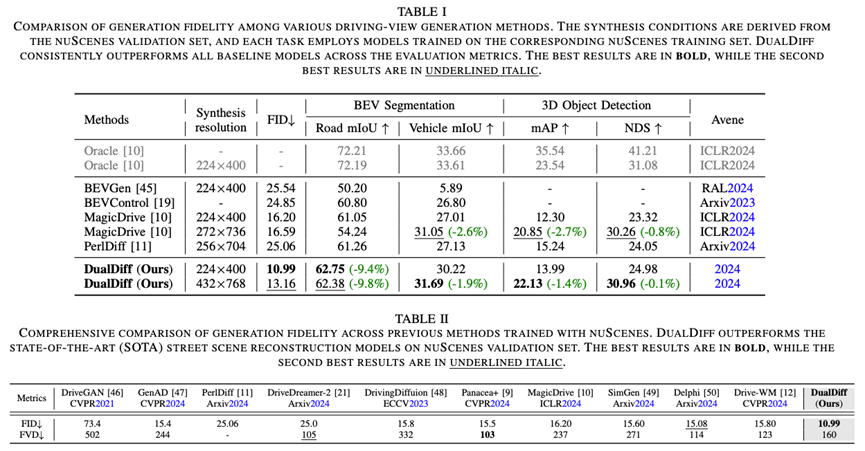
值得注意的是,DualDiff+ 的改进不仅体现在定量指标上,在视觉效果上也有明显提升。论文作者提供的生成视频片段显示,无论是车辆的外观细节,还是不同相机视角下场景的连贯性,DualDiff+ 均较以往方法更加逼真、自然。这种高保真的视频生成能力,为自动驾驶仿真提供了一个高质量数据源,有望减少真实路测数据的依赖。

潜在影响与自动驾驶实际价值
DualDiff+ 为自动驾驶系统带来了多方面的实际价值。在数据增强与模拟训练方面,其生成的高保真驾驶视频可有效扩展训练集,尤其适用于危险场景与长尾事件(如事故、恶劣天气),显著降低真实数据采集的成本与风险。作为虚拟仿真引擎,DualDiff+ 能提供具有时空一致性的多视角视觉输入,有助于评估多传感器感知、决策与控制系统的稳健性。此外,凭借对语义结构与全局连贯性的精准建模,所生成的视频保留了关键语义线索,为目标检测、分割等下游感知任务提供了高质量训练数据支持。
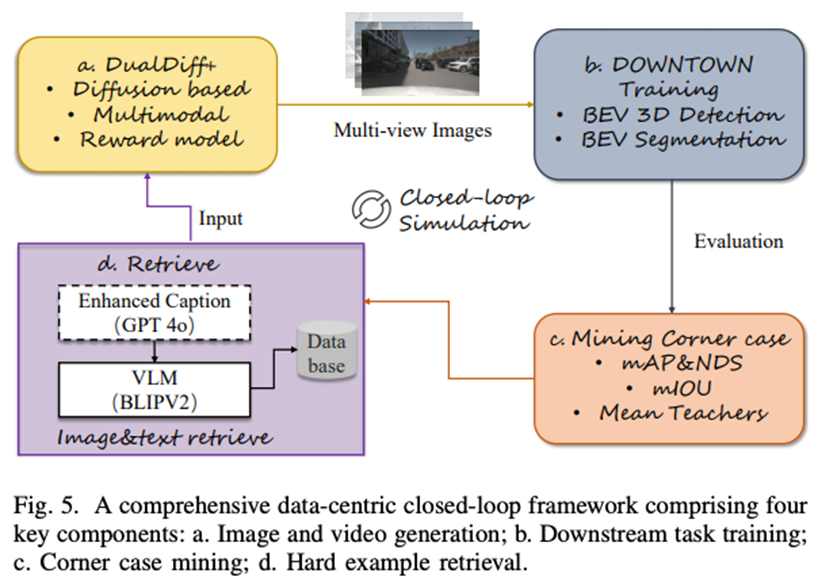
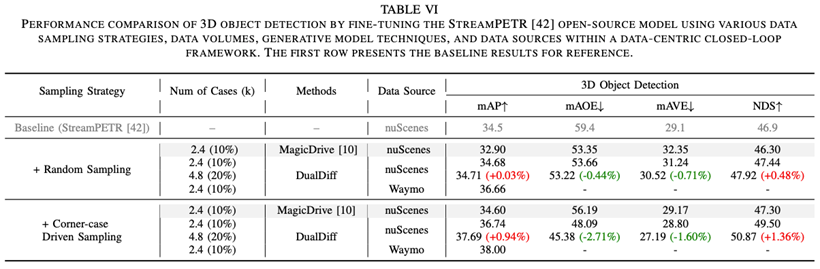
总体而言,DualDiff+ 将扩散生成、3D语义感知与强化学习引导相结合,构建出一个具备高质量、多模态控制能力的视频生成框架,不仅推动了学术研究前沿,也展现出强大的实际应用潜力,有望成为未来自动驾驶开发流程中的核心组成部分。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









