






点击下方卡片,关注“自动驾驶之心”公众号
NuGrounding
论文标题:NuGrounding: A Multi-View 3D Visual Grounding Framework in Autonomous Driving
论文链接:https://arxiv.org/abs/2503.22436
核心创新点:
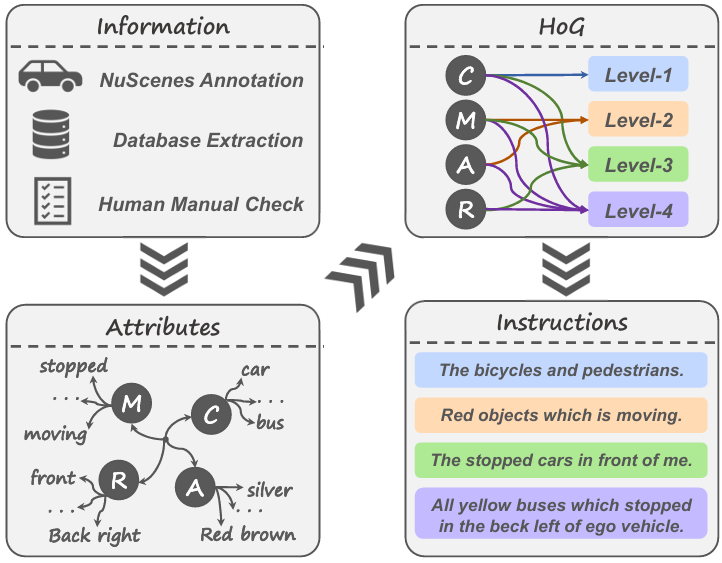
1. 多层级指令生成框架(HoG方法)
提出层次化 grounding 构建策略,通过组合目标属性(类别/外观/运动状态/空间关系)生成多粒度指令,覆盖4级语义复杂度(从单一属性到四属性联合),解决了传统数据集指令单一、语义贫乏的问题。该方法构建的NuGrounding数据集包含2.2M条指令,覆盖34,149帧多视角场景,支持多目标实例级定位。
2. 多模态融合定位范式
创新性设计"BEV检测器-上下文查询聚合器-融合解码器"三级架构:
BEV检测器 :通过稀疏对象查询(Object Query)编码3D几何先验
上下文查询聚合器 :解耦任务token为语义提示token和嵌入token,引入可学习上下文查询(Context Query)聚合多模态信息
融合解码器 :通过语义-几何交叉注意力机制,实现对象查询与上下文查询的特征融合,突破传统方法语义理解与空间定位的割裂限制
3. 几何-语义解耦优化机制
提出基于余弦相似度的查询选择模块,通过语义相似性矩阵筛选关键对象查询,结合自注意力与交叉注意力机制,实现语义相关性与几何精度的联合优化。相较传统方法,在NuGrounding数据集上实现50.8%的精度提升(Precision 0.59)和54.7%的召回提升(Recall 0.64)。

OpenDriveVLA
论文标题OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
论文链接:https://arxiv.org/abs/2503.23463
核心创新点:
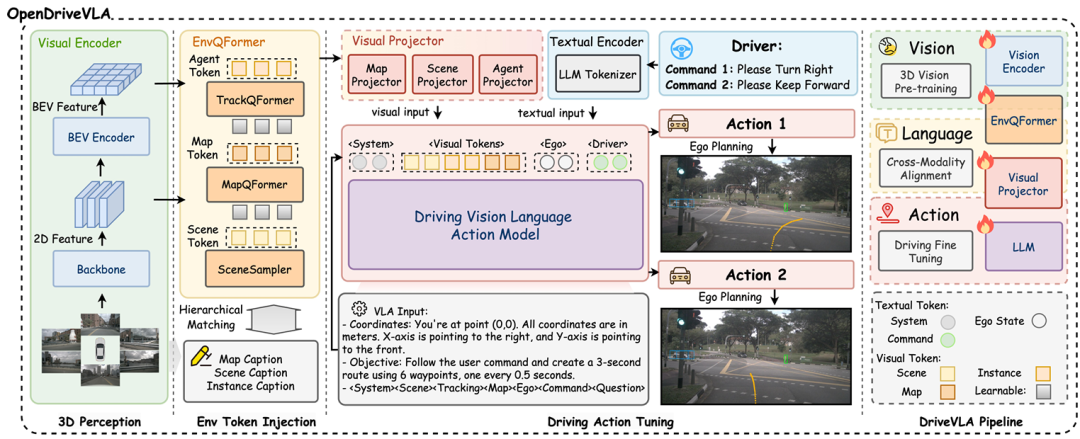
1. 分层视觉-语言特征对齐(Hierarchical Vision-Language Feature Alignment)
提出模块化投影机制,通过场景(Scene)、动态代理(Agent)、静态地图(Map)三类视觉查询模块,将多视图2D特征与BEV(Bird's Eye View)空间中的3D结构化视觉特征映射至统一语义空间,有效弥合视觉表示与语言嵌入的模态鸿沟,增强语言引导的轨迹生成可靠性。
2. 动态交互建模(Agent-Env-Ego Interaction Process)
引入条件式代理运动预测任务(Conditional Agent Motion Forecasting),通过自回归建模自车(Ego Vehicle)、动态代理(Dynamic Agents)及静态道路元素(Static Road Elements)之间的时空交互关系,提升复杂交通场景下的运动预测精度与轨迹可行性,确保避障能力与场景适应性。
3. 多阶段联合优化训练流程(Multi-stage Training Paradigm)
采用分阶段训练策略:
阶段1:冻结视觉编码器与语言模型,仅训练跨模态投影器(Projectors)实现视觉-语言对齐;
阶段2:通过驾驶指令调优(Driving Instruction Tuning)注入驾驶知识,提升语言模型对场景语义与任务需求的理解;
阶段3:端到端联合优化视觉编码器、跨模态投影器及语言模型,直接生成自车未来轨迹,平衡推理速度与规划效果。
4. 3D空间感知增强与幻觉抑制
基于视觉中心化查询模块(如Agent QueryTransformer)构建结构化环境表征,结合3D目标检测、跟踪与地图分割任务,强化空间感知能力,减少传统VLM在动态3D场景中的幻觉风险。
5. 开源模型驱动与性能优势
基于Qwen 2.5-Instruct等开源大语言模型,在nuScenes数据集上实现开环轨迹规划(L2误差0.33m)与驾驶问答(CIDEr 32.3)的SOTA性能,验证了视觉语言动作模型(Vision-Language-Action Model)在端到端自动驾驶中的可扩展性与有效性。
Scenario Dreamer
论文标题:Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments
论文链接:https://arxiv.org/abs/2503.22496
核心创新点;
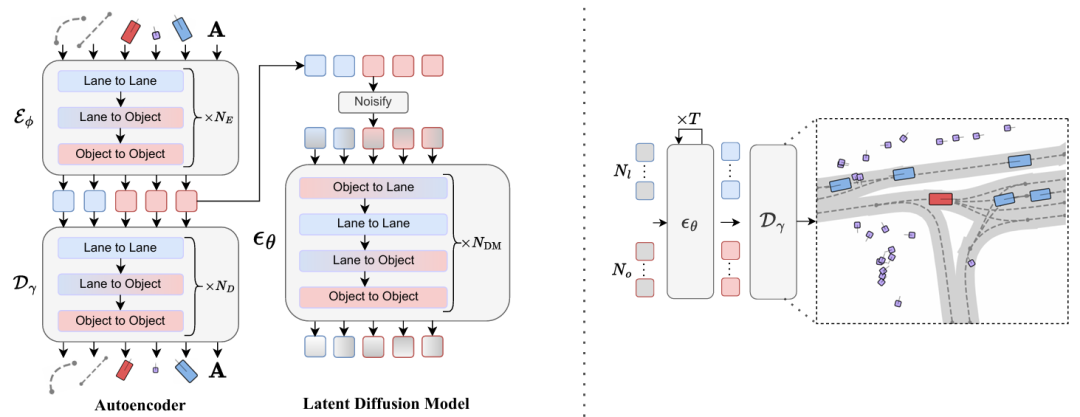
1. 向量化潜在扩散模型(Vectorized Latent Diffusion Model)
提出矢量化的车道与物体潜在表示 ,替代传统栅格化场景编码(rasterized scene encoding),直接生成包含车道图(lane graph)与动态物体(agent)的抽象场景表征。
通过双通道潜在扩散架构 ,分别对车道(
HLt)与物体(HOt)的隐变量进行去噪扩散建模,利用DDPM目标函数(Ldm= Et,Ht,ϵt [||ϵt − ϵθ(Ht, t)||²])实现高效训练,提升场景生成的结构保真度与计算效率。
2. 对抗性驾驶环境生成能力
生成长时程、对抗性驾驶场景 ,通过回报条件化(return-conditioned)的行为模拟模块,动态控制多智能体行为轨迹,显著提升对强化学习(RL)规划器的压力测试能力(如碰撞率、路径复杂度等指标)。
引入k-disks tokenization方案 ,对动态物体的运动状态(位置、朝向偏移)进行离散化编码,支持多类别交通参与者(车辆、行人等)的细粒度生成与交互建模。
3. 模块化生成框架
分阶段设计:
初始场景生成 :通过潜在扩散模型构建静态车道拓扑与初始物体分布;
行为模拟 :基于Transformer的多智能体轨迹预测模型(CtRL-Sim),结合指数倾斜(exponential tilting)策略,实现可调控的对抗性行为生成(如碰撞诱导或避障优化)。
4. 几何感知的动态扩展机制
提出基于分类器的车道数量预测模块 (
fϕ(NFP l | MFN)),动态推断新生成区域(IFP)的车道拓扑复杂度,解决传统方法中几何依赖性导致的生成不一致性问题。
CRLLK
论文标题:CRLLK: Constrained Reinforcement Learning for Lane Keeping in Autonomous Driving
论文链接:https://arxiv.org/abs/2503.22248

核心创新点;
约束强化学习框架的建模
将车道保持(Lane Keeping)问题形式化为带约束的优化问题,目标函数为最大化行驶距离奖励 ),约束条件为车道偏离成本 ) 和碰撞成本 )。
通过拉格朗日松弛技术(Lagrangian Relaxation)将约束优化转化为无约束优化问题,并利用梯度更新策略参数 ) 与拉格朗日乘数 ),实现约束的动态满足。
自适应权重系数学习机制
提出基于拉格朗日乘数( ))的动态权重调整方法,替代传统多目标强化学习(MORL)中固定权重组合。
奖励函数 ) 融合行驶效率( ))、车道偏离惩罚( ))和碰撞惩罚( )),通过梯度上升/下降联合优化策略参数 ) 与乘数 ),实现目标间的自适应权衡。
单时间尺度联合更新策略
采用单时间尺度框架(One-Timescale Framework)同步更新策略网络参数 ) 与拉格朗日乘数 ),解决了传统方法(如RCPO)因样本截断或双时间尺度设计导致的约束跟踪失效问题。
适配高保真物理仿真器(如Duckietown平台),显著降低计算成本并提升训练效率。
多场景验证与泛化性
在仿真(小型环路、复杂障碍场景)和实际环境(Duckiebot硬件平台)中验证方法有效性。
实验表明,相较于传统PPO算法(固定权重),CRLLK在行驶距离( ) 提升约48%)、车道偏离控制( ) 降低最高66%)及碰撞率(( ) 降低最高85%)上显著优化。
通过调整约束阈值 ),可灵活控制策略的保守性(如紧约束下减少车道偏离但牺牲行驶距离,),验证了方法的场景适应能力。
CoGen
论文标题:CoGen: 3D Consistent Video Generation via Adaptive Conditioning for Autonomous Driving
论文链接:https://arxiv.org/abs/2503.22231
核心创新点:
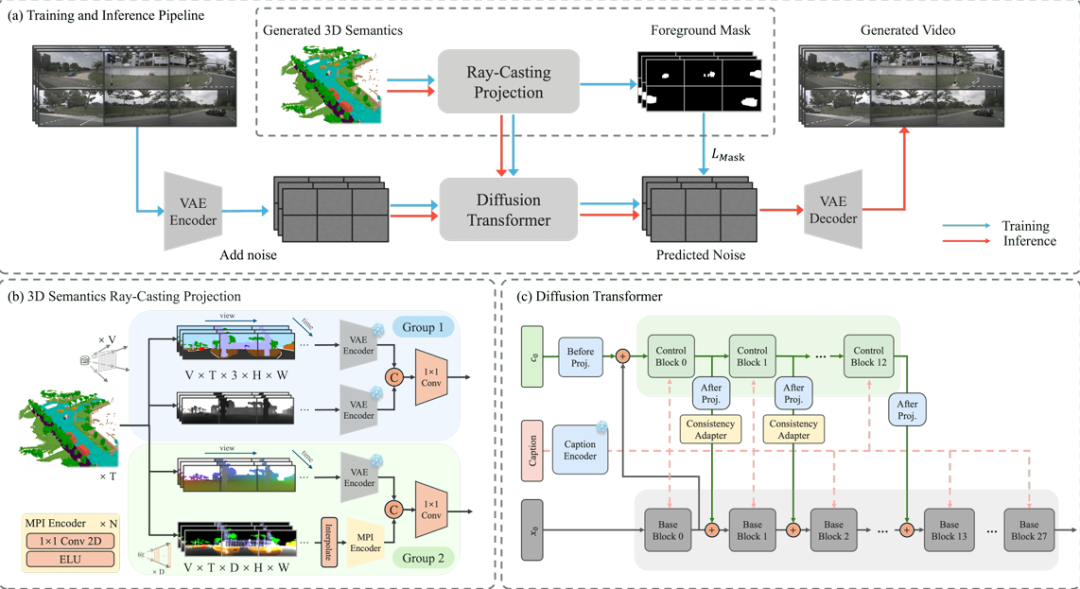
1. 3D语义条件生成与多模态投影
提出基于3D体素化语义网格的细粒度条件生成方法,通过射线投射技术将3D语义信息投影为四种互补的2D引导条件:语义图(Semantic Map)、深度图(Depth Map)、坐标图(Coordinate Map)和多平面图像(Multi-Plane Image, MPI)。这些条件通过联合编码几何结构与语义上下文,克服传统2D布局(如BEV地图)的几何简化与投影不一致问题,显著增强跨视角时空一致性。
2. 轻量级一致性适配器(Consistency Adapter)
设计了一种轻量化模块,集成于ControlNet与主干扩散模型之间,通过深度可分离卷积(Spatial Conv)、3D卷积(Temporal Conv)和多头自注意力(Temporal Attention)实现多条件自适应融合。该模块仅需微调即可增强长序列视频的帧间运动连贯性,并在多分辨率训练中保持高效性,FVD指标提升约1.11。
3. 前景掩码加权损失(Foreground-Mask Loss)
引入基于3D语义掩码的动态损失加权机制,通过射线相交检测生成二值前景掩码,对前景区域(如车辆、行人)施加更高权重,显著改善遮挡与远距离目标的细节保真度(FID降低1.58),缓解传统MSE损失对前景细节的忽视。
4. 混合训练策略与下游任务验证
提出部分3D语义引导的混合训练方案(50% 3D语义+50%传统布局),在数据标注不全时仍保持鲁棒生成性能(FVD仅上升5.39)。实验表明,生成视频在nuScenes数据集上达到SOTA性能(FVD=68.43),并显著提升下游任务指标(BEV分割mIoU=37.80,3D检测mAP=27.88),验证其实际应用价值。
TranSplat
论文标题:TranSplat: Lighting-Consistent Cross-Scene Object Transfer with 3D Gaussian Splatting
论文链接:https://arxiv.org/abs/2503.22676

核心创新点:
1. 基于优化标签权重的细粒度3D物体提取
在3D高斯泼溅(Gaussian Splatting, GS)框架中,提出通过优化每高斯物体标签权重(per-Gaussian object label weights)实现精准的3D分割。通过将2D掩码信息融入GS模型拟合过程,动态传递标签权重至子高斯(children Gaussians),显著提升对复杂结构(如细长卷须)的提取能力,克服传统方法依赖后处理分割的局限性。
2. 球谐系数调制的光照适应策略
提出一种无需显式材质属性估计的跨场景光照迁移方法。基于球谐函数(Spherical Harmonics, SH)理论,推导出辐射传输函数(radiance transfer functions),通过调制目标与源场景环境光照的SH系数比值,直接调整物体高斯的SH外观参数。该方法绕过对BRDF、光照强度等物理属性的解耦,有效避免传统逆渲染方法中的色彩偏移与噪声问题。
3. 高斯模型驱动的环境光照图估计
设计了一种从GS模型直接生成高动态范围(HDR)环境光照图的轻量化方法。通过渲染目标场景的立方体贴图(cubemap),结合加权球面采样策略(权重为sinθ)拟合SH系数,解决均匀采样导致的色调失真问题,实现光照条件的鲁棒建模。
4. 跨场景编辑性能优势
在合成与真实场景(如MipNeRF-360、TensoIR数据集)中,TranSplat在物体提取精度(PSNR提升约3 dB)、光照一致性(SSIM达0.97)与渲染效率(单帧0.3秒)上均优于GS-IR、TensoIR等基线方法,尤其在近朗伯(Lambertian)表面场景中表现出色,验证了方法在实用场景中的有效性。
Fine-Grained Evaluation
论文标题:Fine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
论文链接:https://arxiv.org/abs/2503.21505

核心创新点:
1. 细粒度评估框架
提出首个针对自动驾驶场景的多维度LVLM(Large Vision-Language Model)评估体系,覆盖感知-认知闭环 全流程,包含目标检测、场景理解、决策推理等6个层级任务。
2. 模型幻觉量化分析
设计基于驾驶场景的跨模态对齐误差度量 (Cross-modal Alignment Error, CAE),量化模型在复杂交通场景中生成文本与视觉输入的语义偏差,揭示现有LVLM在动态障碍物交互预测中的系统性缺陷。
3. 驾驶知识嵌入验证
通过结构化知识三元组 (<实体, 关系, 逻辑约束>)验证模型对交通规则与物理常识的编码能力,发现模型在时序因果推理(如让行优先级判断)上的显著性能衰减。
4. 多模态基准扩展
构建包含激光雷达点云-图像-文本 的多模态驾驶数据集(DriveBench),支持3D空间关系推理评估,填补现有基准在4D场景理解(时空联合建模)方面的空白。
EVolSplat
论文标题:EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
论文链接:https://arxiv.org/abs/2503.20168
项目链接:https://xdimlab.github.io/EVolSplat/

核心创新点:
1.全局体积化高斯表示
通过稀疏3D U-Net架构聚合多帧深度预测生成的噪声点云,构建全局特征体积(Feature Volume),直接预测3D高斯的几何参数(位置偏移Δμ、协方差Σ、不透明度α)。
2.几何与外观解耦建模
几何优化: 利用3DCNN提取的3D上下文信息优化高斯几何属性,通过递归位置偏移修正(Δ )补偿深度噪声。
外观预测: 引入遮挡感知的图像基渲染(Occlusion-aware IBR)模块,从参考视图的局部颜色窗口(W×W)动态预测高斯颜色,结合深度可见性掩码(Visibility Map)过滤遮挡区域噪声。
3.无界场景建模的半球背景模型
固定半球几何参数(半径、旋转),通过轻量级MLP从参考视图聚合颜色,支持动态车辆视角下的背景一致性渲染。
4.前馈式高效推理框架
训练策略: 联合优化几何与外观模块,结合L1+SSIM损失与α熵正则化(Entropy Regularization)。
推理效率: 在KITTI-360和Waymo数据集上实现83.81 FPS实时渲染,内存占用仅10.41GB(对比MVSplat降低35%),支持零样本跨域泛化(Zero-shot Generalization)。
微调加速: 基于预训练参数的微调(Fine-tuning)仅需<1000步即可收敛,超越传统3DGS每场景优化效率。
5.深度驱动的鲁棒初始化
集成Metric3D/UniDepth等单目深度估计器,通过深度一致性校验(Depth Consistency Check)与3D统计滤波去除异常点,构建鲁棒的全局点云。
本文均出自『自动驾驶之心知识星球』,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫码加入~


















 6159
6159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









