






点击下方卡片,关注“具身智能之心”公众号
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
ZeroShot学习(ZeroShot Learning, ZSL)是具身智能(Embodied AI)领域的一项关键技术,它使机器人或智能体能够在未见过的任务、环境或硬件配置下直接执行操作,而无需额外的训练或微调。 我们从2025ICRA、CVPR、RSS会议中选取了几项相关研究,来对zeroshot的重要性一探究竟。
1. 解决数据稀缺问题,降低机器人训练成本
传统方法依赖大量真实世界数据或仿真训练,而数据收集(如机器人演示、环境建模)成本高昂。
ZeroShot方案(如VidBot、RoboSplat)利用合成数据、人类视频或单次演示生成泛化策略,减少对真实数据的依赖。例如: VidBot 仅需人类视频即可训练机器人操作策略,无需机器人专属数据。 RoboSplat 通过高斯泼溅技术,从单次演示生成多样化训练样本,数据效率提升50倍。
2. 实现跨平台、跨具身的泛化能力
机器人硬件形态多样(如不同自由度机械臂、多指灵巧手),传统方法需为每种硬件单独训练策略。
ZeroShot方法(如XMoP、UniGraspTransformer)通过统一表征学习,支持跨硬件迁移: XMoP 在7DoF机械臂上实现零样本运动规划,无需针对新机器人微调。 UniGraspTransformer 将数千种抓取策略蒸馏到单一网络,适配不同手型与物体。
3. 适应动态与未知环境
真实环境充满不确定性(如新物体、动态障碍),传统方法需在线学习或重新训练。
ZeroShot方法(如ZeroGrasp、NaVILA)通过多模态推理实时适应变化: ZeroGrasp 从单目图像重建未知物体3D形状并规划抓取,适用于工业分拣。 NaVILA 通过语言指令理解复杂导航任务(如“绕过障碍物”),无需预定义地图。
4. 推动机器人通用化(GeneralPurpose Robotics)
ZeroShot学习是迈向通用机器人(如“机器人ChatGPT”)的关键步骤,使单一模型处理多任务: XMoP 和 UniGraspTransformer 证明统一策略可覆盖不同运动与操作任务。 NaVILA 结合视觉语言动作模型,实现开放指令下的自主决策。
5. 加速仿真到真实(SimtoReal)的迁移
传统SimtoReal依赖域随机化或精细调参,而ZeroShot方法(如RoboSplat)通过合成数据直接泛化到真实世界,成功率提升30%以上。
总结:ZeroShot学习的核心价值
降低成本:减少数据收集与训练时间。
增强泛化:跨硬件、跨任务、跨环境适用。
提升适应性:实时应对未知场景。
推动通用AI:迈向多任务、多模态的智能体。
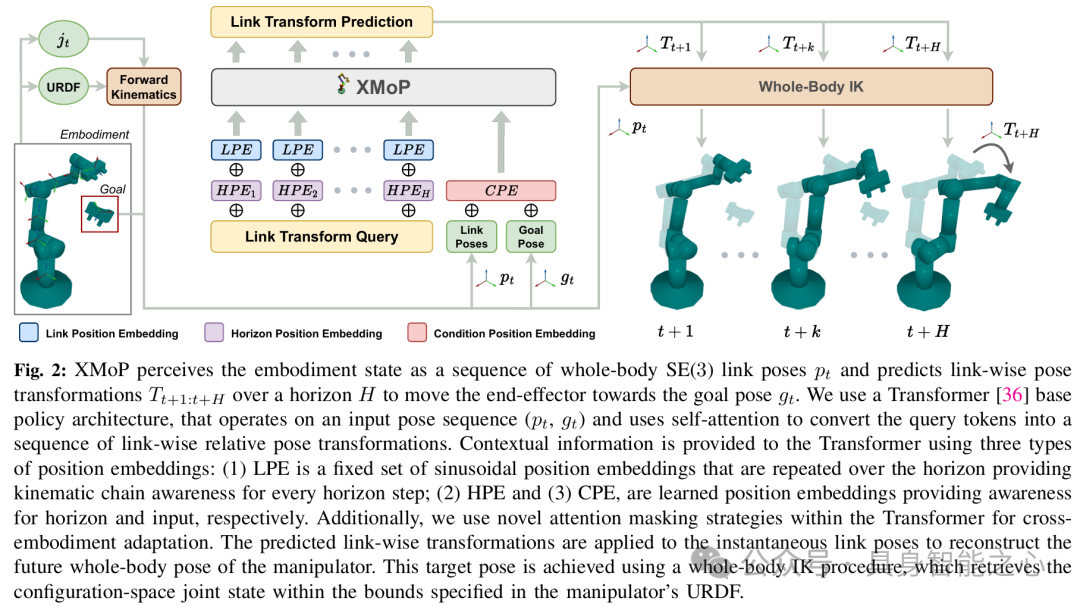
XMoP: WholeBody Control Policy for Zeroshot CrossEmbodiment Neural Motion Planning
https://arxiv.org/pdf/2409.15585
会议/来源:ICRA 2025
文章提出了一种面向多机械臂的零样本跨具身运动规划框架,解决了传统神经运动规划(NMP)无法泛化到不同机器人形态的核心问题。其亮点在于首次实现了无需微调的跨具身泛化能力,通过合成数据训练的策略可直接部署到7种不同自由度(6DoF和7DoF)的商业机械臂上,在动态障碍环境中达到70%的平均规划成功率,并验证了从仿真到真实的强鲁棒性。
模型架构
配置空间(Cspace)的神经策略设计XMoP的核心创新是将运动规划问题转化为链接级SE(3)位姿变换序列的预测任务。模型输入为当前机械臂各连杆的SE(3)位姿序列(通过URDF解析)和环境的点云观测,输出为未来时间步的连杆位姿变换矩阵 T_{t+1:t+H} ,最终通过逆运动学求解关节空间轨迹。这种设计避免了传统任务空间策略对特定机器人形态的依赖,直接学习跨具身的运动约束。
基于扩散模型的策略学习采用扩散模型(Diffusion Policy)生成多步运动规划,通过逐步去噪过程增强轨迹的平滑性和碰撞规避能力。训练数据来自300万组程序化生成的合成机械臂(涵盖不同连杆长度、关节限制和自由度)在多样化环境中的规划演示,利用OMPL生成专家轨迹。
零样本泛化机制
物理描述编码:通过URDF文件动态编码新机械臂的形态学参数(如连杆几何、关节限制),使策略能自适应不同构型空间。
碰撞检测模块(XCoD):联合训练一个3D语义分割模型,以98%的召回率检测跨具身环境中的碰撞区域,与规划策略形成模型预测控制(MPC)闭环。
仿真到真实的迁移尽管完全基于合成数据训练,XMoP在Franka FR3和Sawyer等真实机械臂上展示了零样本部署能力,成功处理动态障碍(如移动物体)和长程规划任务。其泛化性源于合成数据对运动学分布的充分覆盖,以及SE(3)位姿表示对形态变化的解耦特性。
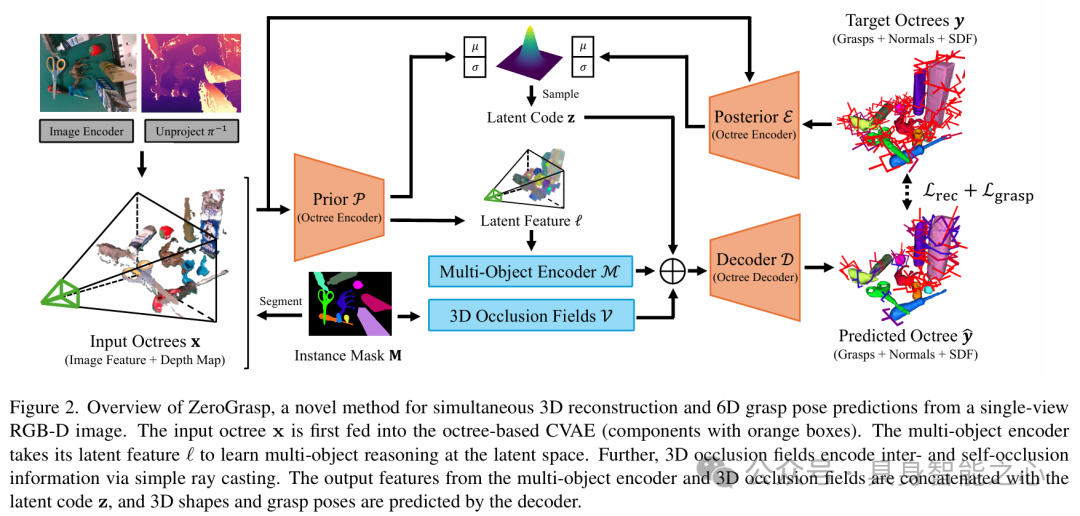
ZeroGrasp: ZeroShot Shape Reconstruction Enabled Robotic Grasping
https://arxiv.org/pdf/2504.10857
会议/来源:CVPR 2025
文章提出了一种突破性的机器人抓取框架,通过零样本3D形状重建与抓取位姿预测的联合优化,实现了对未知物体的实时、高成功率抓取。其核心亮点在于无需物体先验数据,仅凭单目RGB或RGBD输入即可完成复杂场景下的几何推理与抓取规划,在GraspNet1B基准测试和真实机器人实验中分别达到92.4%的抓取成功率,显著优于传统需要物体特定训练的抓取方法。

模型架构
多任务联合学习框架ZeroGrasp采用神经隐式表示(Neural Implicit Representation)统一形状重建与抓取预测任务。输入的单视角图像通过共享的视觉编码器(如ResNet50)提取特征,随后分两路处理:
形状重建分支:基于Occupancy Networks生成连续的3D占用场,通过可微分渲染与输入图像对齐,重建被遮挡部分的几何结构。
抓取预测分支:结合重建的3D几何与物理约束(如摩擦系数、力闭合条件),输出6DoF抓取位姿及夹持器参数。
大规模合成数据驱动训练数据来自包含12000个ObjaverseLVIS物体的合成数据集,涵盖100万张照片级渲染图像、高精度3D重建及113亿组物理验证的抓取标注。通过域随机化(Domain Randomization)增强光照、纹理多样性,确保仿真到真实的零样本迁移能力。
空间关系与遮挡推理创新性地引入图注意力机制(GAT)建模物体间的空间关系,例如堆叠物体的分离边界预测,避免抓取时的碰撞。实验表明,该设计使系统在杂乱场景中的抓取成功率提升19%。
实时性能优化采用轻量级网络架构与并行计算流水线,在NVIDIA Jetson AGX上实现200ms内的端到端推理,满足实时操作需求。
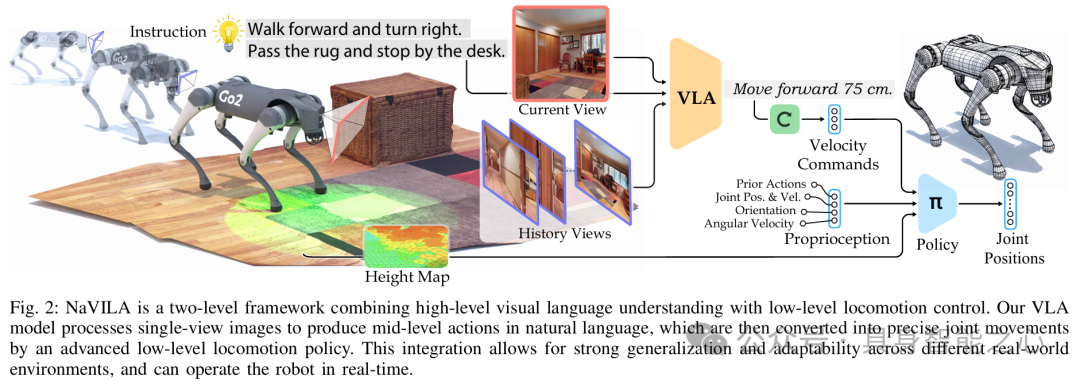
NaVILA: Legged Robot VisionLanguageAction Model for Navigation
https://arxiv.org/pdf/2412.04453
会议/来源:RSS 2025
文章提出了一种突破性的两级框架,通过结合视觉语言动作(VLA)模型与实时运动控制策略,实现了腿式机器人(如四足/人形机器人)在复杂场景下的零样本语言指令导航。其核心亮点在于无需预训练仿真器或特定机器人数据,即可将自然语言指令(如“绕过障碍物并找到红色门”)直接转化为跨平台的关节动作,在真实世界的Unitree Go2/G1等机器人上达到88%的导航成功率,较传统方法提升17%。

模型架构
两级分层框架设计
高层VLA指令生成:基于视觉语言模型(VLM)处理单目RGB输入和语言指令,通过视觉编码器(ResNet)+投影器(MLP)+LLM的架构,输出自然语言形式的中间指令(如“向左转30°并前进1米”)。创新性地引入导航提示机制,区分历史帧与当前观测,确保多步任务的可追踪性。
低层运动策略:采用强化学习(PPO)训练的实时控制模块,将高层指令转化为1218个关节的精确运动。通过LiDAR构建高度图并随机化域参数,显著降低仿真到真实的差距。该策略以10Hz频率运行,支持动态避障与复杂地形穿越。
多模态数据训练与泛化能力
训练数据融合了YouTube人类游览视频(20K轨迹)、仿真导航数据(Isaac Lab)及通用VQA数据集,通过熵采样增强指令多样性。VLA部分通过监督微调实现跨模态对齐,而运动策略仅需仿真训练即可零样本迁移至真实机器人。
提出的VLNCEIsaac基准包含高保真物理模拟场景,支持评估低层控制与语言理解的协同性能,在透明表面、崎岖地形等挑战性场景中成功率提升14%。
实时性与安全机制
采用双频运行架构:VLA以1Hz生成高层指令,而运动策略以10Hz实时调整动作,平衡规划与执行效率。通过LiDAR的实时高度图分析,有效识别玻璃门等透明障碍物,避免碰撞。
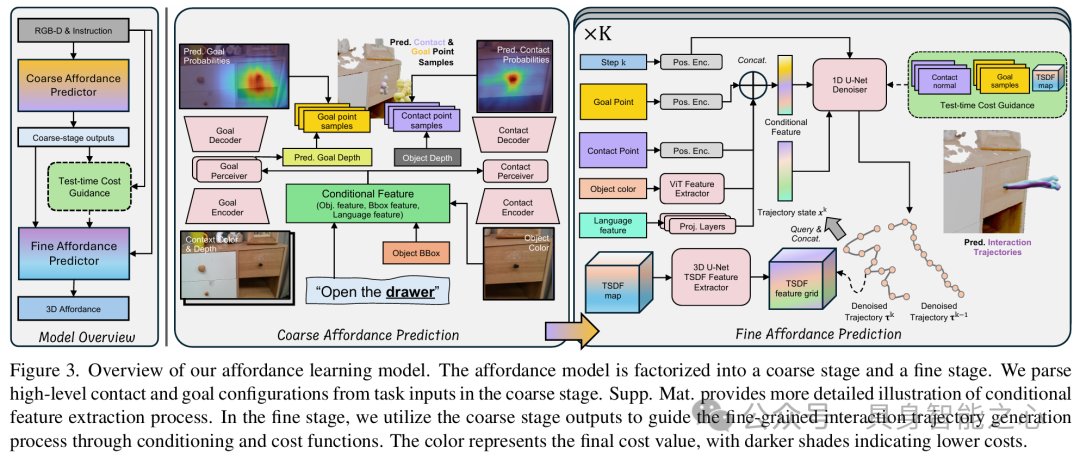
VidBot: Learning Generalizable 3D Actions from IntheWild 2D Human Videos for ZeroShot Robotic Manipulation
https://arxiv.org/pdf/2503.07135
会议/来源:CVPR 2025
文章提出了一种突破性的框架,通过从单目RGB人类视频中学习与具身无关的3D动作表征,实现了机器人零样本操作任务泛化。其核心亮点在于无需机器人专属演示数据,仅利用互联网海量人类视频(如EpicKitchens100数据集)即可训练模型,在13项家务任务(如开关橱柜、推抽屉)的零样本测试中成功率显著超越基线方法,并可直接部署到Stretch 3等真实机器人平台。

模型架构
3D Affordance表征提取流水线VidBot首先通过运动恢复结构(SfM)和度量深度基础模型(如[90])从单目视频中重建3D手部轨迹,并优化相机姿态与全局尺度一致性。结合手部物体分割掩码,提取时空对齐的接触点(c)和交互轨迹(τ),形成3D Affordance表征 a = {c, τ}。这一流程解决了传统方法依赖静态摄像机或深度传感器的限制。
由粗到细的Affordance学习框架
粗略模型(π_c):基于ResNet的编码器从RGBD输入中预测目标点(g)和接触点(c),通过高斯混合模型拟合概率分布,并引入辅助向量场损失增强空间感知。
精细模型(π_f):采用条件扩散模型生成细粒度交互轨迹,以粗略预测为条件,并集成碰撞规避、法线对齐等测试时成本函数引导轨迹优化。这种设计显著提升了新场景下的泛化能力。
多模态训练与泛化机制训练数据融合了18,726段人类视频和合成演示,通过语言视频对齐损失(余弦相似度)将视频嵌入与预训练语言向量(如CLIP)关联,确保语义一致性。在推理时,模型支持语言指令或视频输入,通过FiLM层调节策略网络,适配不同任务需求。
RoboSplat: Novel Demonstration Generation with Gaussian Splatting Enables Robust OneShot Manipulation
http://export.arxiv.org/pdf/2504.13175
会议/来源:RSS 2025
文章提出了一种基于3D高斯泼溅(Gaussian Splatting)的机器人示范生成框架,通过单次专家演示自动合成多样化、高质量的视觉动作训练数据,解决了传统机器人策略学习依赖海量人工数据的问题。其核心亮点在于仅需一条真实演示,即可生成覆盖6类泛化场景(如物体姿态、光照、相机视角等)的合成数据,在真实世界的抓取、关抽屉等任务中达到87.8%的平均成功率,较传统数据增强方法提升30.6%。

模型架构
3D高斯场景重建与编辑流水线
重建阶段:通过多视角RGBD输入,利用3D高斯泼溅技术(3DGS)重建场景的可微分3D高斯点云,每个高斯点包含位置、协方差、不透明度与球谐系数,支持高保真渲染。
编辑阶段:提出五大编辑技术:
高斯替换:替换物体类型或机器人形态(如将夹持器从二指改为三指);
等变变换:调整物体位姿(如旋转抽屉把手);
视觉属性编辑:动态修改光照与材质;
新视角合成:生成多摄像机视角的观测;
3D内容生成:添加未见过的物体(如不同形状的餐具)。
动作迁移与数据生成机制
将专家演示的末端执行器轨迹物理约束嵌入高斯点云,通过刚体动力学仿真迁移到编辑后的场景中,确保动作的物理合理性。例如,抓取轨迹会根据新物体的几何特征自动调整接触点。
引入自适应密度控制(ADC)优化高斯分布,避免编辑后的场景出现空洞或过饱和,提升合成数据的真实性。
策略训练与泛化验证
生成的数据用于训练视觉运动策略(如扩散策略),通过域随机化损失强制模型忽略无关特征(如纹理变化),专注于几何与动力学泛化。
在Franka Emika等真实机器人上验证了零样本迁移能力,尤其在动态干扰(如移动障碍物)下的成功率较基线提升47%。
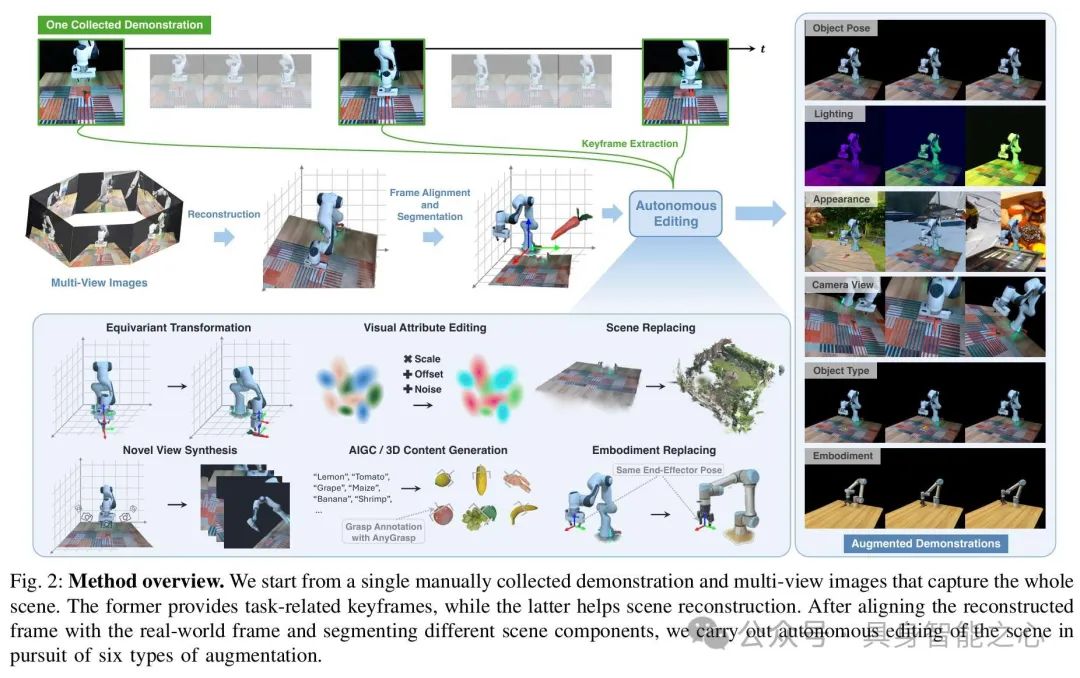
UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
https://arxiv.org/pdf/2412.02699
会议/来源:CVPR 2025
文章提出了一种基于Transformer的通用灵巧抓取框架,通过简化策略蒸馏流程实现了跨物体、跨形态的零样本泛化能力,其核心亮点在于仅需单次离线蒸馏即可将数千种物体的专用抓取策略统一到一个网络中,在仿真与真实场景中分别取得3.5%~10.1%的成功率提升。
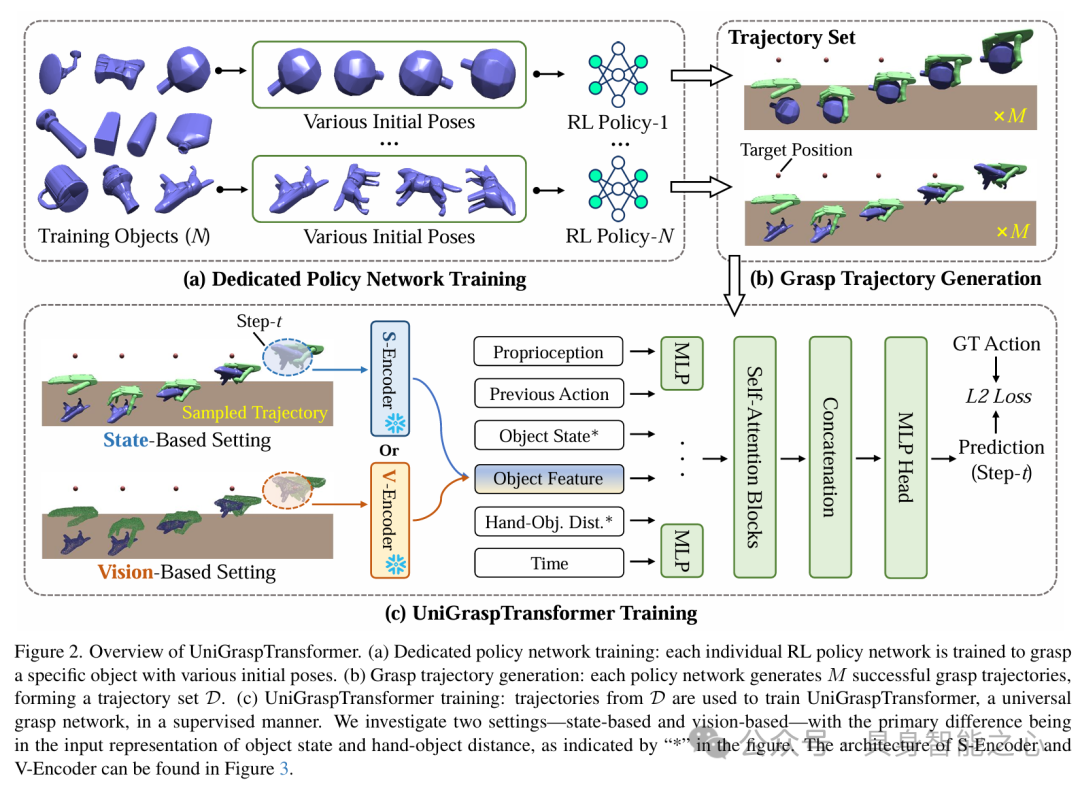
模型架构
分层训练框架
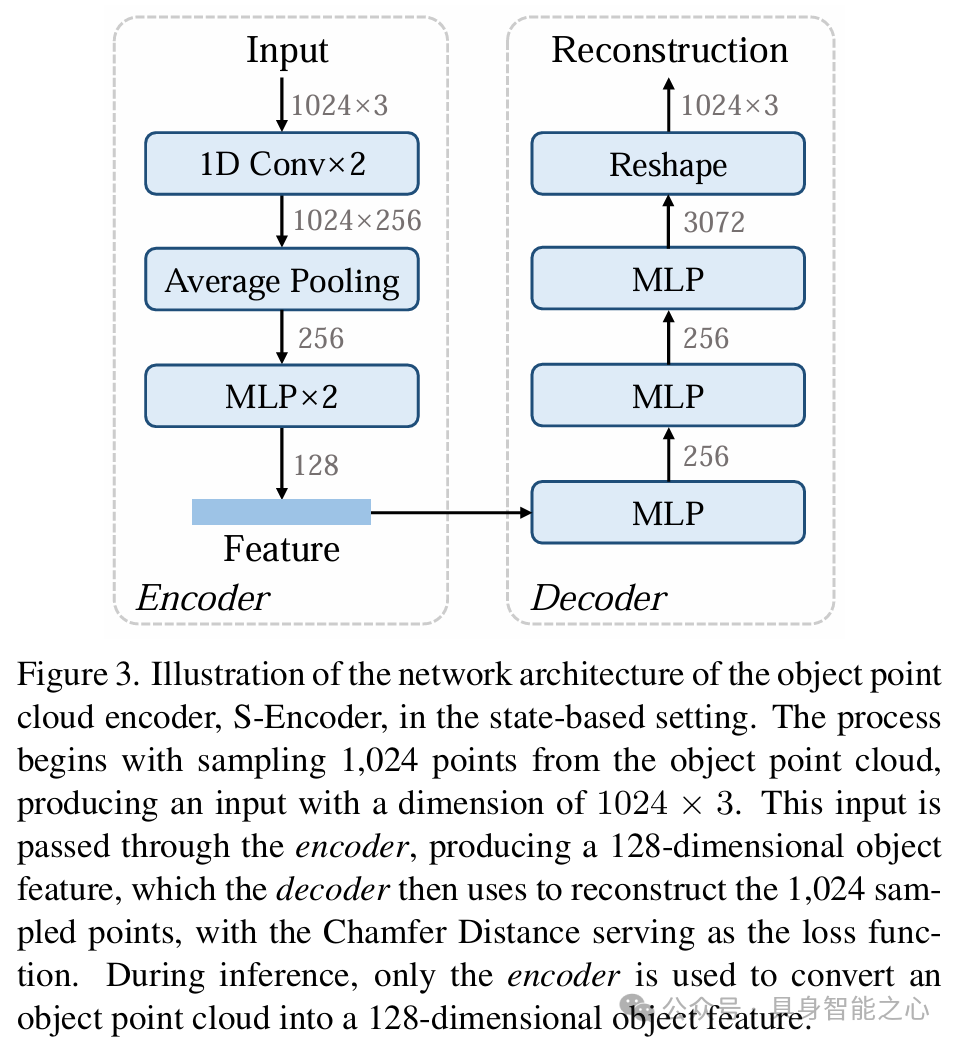
专用策略生成:针对每个训练集物体,通过强化学习(PPO算法)训练独立的策略网络,输入包含272维状态向量(如关节角度、物体位姿、手物距离等),输出24维动作控制序列。训练时通过随机旋转物体增强初始姿态多样性。
轨迹数据集构建:每个专用网络生成1,000条成功抓取轨迹,最终形成包含320万条轨迹的大规模数据集,覆盖3,200种物体。
Transformer蒸馏架构
多模态输入编码:将物体点云、机器人状态等异构数据通过线性投影统一为序列化向量,并加入时间嵌入编码时序信息。
12层自注意力块:通过堆叠自注意力层捕捉物体几何与动作的全局依赖关系,例如识别手柄与抓取方向的关联性。相比传统MLP网络,注意力机制显著提升了跨类别泛化能力。
监督蒸馏损失:采用L2损失对齐预测动作与专家轨迹,并引入多样性正则项避免抓取策略趋同(如UniDexGrasp++的重复抓取问题)。
双模态推理能力
状态模式:输入高精度仿真状态数据,成功率较基线提升7.7%(未见类别物体)。
视觉模式:处理噪声点云与估计位姿,通过跨模态注意力融合视觉特征与物理约束,真实机器人实验成功率超90%。
但Zero-Shot Learning(ZSL)也存在一些局限性:
1. 领域偏移(Domain Shift)问题
ZSL依赖训练阶段已知类别的特征分布来推断未知类别,但实际应用中,未见类别的特征分布可能与训练数据存在显著差异。例如,训练数据中的动物识别模型可能无法泛化到工业场景中的缺陷检测,因为纹理、光照等特征分布完全不同。
2. 语义表征的质量与局限性
ZSL需依赖辅助信息(如文本描述、知识图谱)建立已知与未知类别的关联,但语义表征的完整性和准确性直接影响模型性能: 人工标注手动定义的属性(如“斑马有条纹”)可能过于简化或遗漏关键特征(如条纹的密度变化)。 自动化嵌入可能无法捕捉领域特异性关系(如医疗术语的细微差异)。
3. 评估偏差与数据泄露风险
ZSL的评测标准常因数据设计问题导致性能被高估: 数据集中已知和未知类别共享相同属性(如“有翅膀”同时描述鸟类和飞机),使模型通过简单关联而非真实理解完成任务。 模型可能在少数简单样本上表现良好,但面对真实世界的长尾分布(如工业缺陷的罕见类别)时失效。
4. 对预训练知识的强依赖
ZSL的性能高度依赖预训练模型的知识广度,但模型仅能处理与预训练任务相似的领域(如CLIP在视觉-文本对齐任务中表现优异,但对医疗图像的解释力有限)。
5. 复杂任务的处理能力不足
ZSL在需要多步推理或动态交互的任务中表现较差: 如VidBot从人类视频学习操作时,对透明物体或遮挡场景的轨迹预测误差较大。 在导航任务中,语言指令的歧义(如“绕过障碍物”未指定具体路径)可能导致决策失败。 根本原因是因为ZSL缺乏在线学习机制,无法通过环境反馈实时调整策略。
6. 数据效率与泛化的矛盾
尽管ZSL旨在减少数据依赖,但高质量预训练数据的需求反而增加: 如RoboSplat通过高斯泼溅生成数据,但对可变形物体(如绳索)的仿真精度不足。
ZSL的局限性本质是语义鸿沟(训练与目标域的认知差距)与动态适应性不足的综合结果。当前研究通过以下方向突破:
跨模态增强:如检索增强分类(RAC)通过相似样本扩展上下文;
混合学习框架:结合Few-Shot微调提升特定任务鲁棒性;
仿真-真实协同:如工业场景中构建领域特异性基准。
往期 · 推荐
机械臂操作
Grasp EveryThing:具备触觉传感的低成本夹持器,实现稳固抓取
UC伯克利&NVIDIA最新!AutoEval:真实世界中通用机器人操作策略评估系统
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
伯克利最新!CrossFormer:一个模型同时控制单臂/双臂/轮式/四足等多类机器人
四足或人形机器人
北大等 | 打造人形通用大模型,实现精细动作跨平台、跨形态动作迁移
Fourier ActionNet:傅利叶开源全尺寸人形机器人数据集&发布全球首个全流程工具链
斯坦福大学 | ToddlerBot:到真实世界的零样本迁移,低成本、开源的人形机器人平台
TeleAI&港科大最新!离线学习+在线对齐,扩散模型驱动的四足机器人运动
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
机器人学习
上交最新!RDP:视觉-触觉/力觉融合的机器人模仿学习(RSS 2025)
强化学习迁移到视觉定位!Vision-R1将图文大模型性能提升50%
视觉强化微调!DeepSeek R1技术成功迁移到多模态领域,全面开源
UC伯克利最新!Beyond Sight: 零样本微调异构传感器的通用机器人策略
CoRL 2024 | 通过语言优化实现策略适应:实现少样本模仿学习
NeurIPS 2024 | BAKU:一种高效的多任务Policy学习Transformer
人形机器人专场!有LLM加持能有多厉害?看HYPERmotion显身手
NeurIPS 2024 | 大规模无动作视频学习可执行的离散扩散策略
波士顿动力最新!可泛化的扩散策略:能有效操控不同几何形状、尺寸和物理特性的物体
RSS 2024 | OK-Robot:在机器人领域集成开放知识模型时,真正重要的是什么?
MIT最新!还在用URDF?URDF+:一种针对机器人的具有运动环路的增强型URDF
VisionPAD:3DGS预训练新范式!三大感知任务全部暴力涨点
NeurIPS 2024 | VLMimic:5个人类视频,无需额外学习就能提升泛化性?
纽约大学最新!SeeDo:通过视觉语言模型将人类演示视频转化为机器人行动计划
CMU最新!SplatSim: 基于3DGS的RGB操作策略零样本Sim2Real迁移
LLM最大能力密度100天翻一倍!清华刘知远团队提出Densing Law
机器人干活总有意外?Code-as-Monitor 轻松在开放世界实时精确检测错误,确保没意外
斯坦福大学最新!具身智能接口:具身决策中语言大模型的基准测试
机器人控制
RoboMatrix:一种以技能为中心的机器人任务规划与执行的可扩展层级框架
港大DexDiffuser揭秘!机器人能拥有像人类一样灵巧的手吗?
TPAMI 2024 | OoD-Control:泛化未见环境中的鲁棒控制(一览无人机上的效果)
VLA
VLA模型最新综述!近80多个VLA 模型,涉及架构、训练,实时推理等
CVPR2025 | MoManipVLA:通用移动操作VLA策略迁移,显著提升效率与泛化
上海AI Lab最新!Dita:扩展Diffusion Transformer以实现通用视觉-语言-动作策略
北大最新 | RoboMamba:端到端VLA模型!推理速度提升3倍,仅需调整0.1%的参数
英伟达最新!NaVILA: 用于导航的足式机器人视觉-语言-动作模型
优于现有SOTA!PointVLA:如何将3D数据融入VLA模型?
北京大学最新!HybridVLA:打通协同训练,各种任务中均SOTA~
北京大学最新 | 成功率极高!DexGraspVLA:首个用于灵巧抓取的分层VLA框架
ICLR'25 | VLAS:将语音集成到模型中,新颖的端到端VLA模型(西湖大学&浙大)
清华大学最新!UniAct:消除异质性,跨域跨具身泛化,性能超越14倍参数量的OpenVLA
简单灵活,便于部署 | Diffusion-VLA:通过统一扩散与自回归方法扩展机器人基础模型
其他(抓取,VLN等)
UC伯克利最新!Real2Render2Real:无需动力学仿真或机器人硬件即可扩展机器人数据
ICLR 2025 | TeleAI提出过程引导的大模型具身推理框架
铰链物体的通用世界模型,超越扩散方法,入选CVPR 2025
中山大学&鹏城实验室 | 面向主动探索的可信具身问答:数据基准,方法与指标
Uni-3DAR:统一3D世界,性能超扩散模型256%,推理快21.8倍
TPAMI2025 | NavCoT:中山大学具身导航参数高效训练!
CVPR2025 | 长程VLN平台与数据集:迈向复杂环境中的智能机器人
CVPR2025满分作文!TSP3D:高效3D视觉定位,性能和推理速度均SOTA(清华大学)
模拟和真实环境SOTA!MapNav:基于VLM的端到端VLN模型,赋能端到端智能体决策
场面混乱听不清指令怎么执行任务?实体灵巧抓取系统EDGS指出了一条明路
北京大学与智元机器人联合实验室发布OmniManip:显著提升机器人3D操作能力
动态 3D 场景理解要理解什么?Embodied VideoAgent来揭秘!
NeurIPS 2024 | HA-VLN:具备人类感知能力的具身导航智能体
博世最新!Depth Any Camera:任意相机的零样本度量深度估计
真机数据白采了?银河通用具身大模型已充分泛化,基于仿真数据!
港科大最新!GaussianProperty:无需训练,VLM+3DGS完成零样本物体材质重建与抓取
VinT-6D:用于机器人手部操作的大规模多模态6D姿态估计数据集
机器人有触觉吗?中科大《NSR》柔性光栅结构色触觉感知揭秘!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
LLM+Zero-shot!基于场景图的零样本物体目标导航(清华大学博士分享)
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
具身硬核梳理
一文贯通Diffusion原理:DDPM、DDIM和Flow Matching
Diffusion Policy在机器人操作任务上有哪些主流的方法?
强化学习中 Sim-to-Real 方法综述:基础模型的进展、前景和挑战
墨尔本&湖南大学 | 具身智能在三维理解中的应用:三维场景问答最新综述
十五校联合出品!人形机器人运动与操控:控制、规划与学习的最新突破与挑战
扩散模型也能推理时Scaling,谢赛宁团队研究可能带来文生图新范式
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
关于具身智能Vision-Language-Action的一些思考
具身仿真×自动驾驶
视频模型For具身智能:Video Prediction Policy论文思考分析
性能爆拉30%!DreamDrive:时空一致下的生成重建大一统
真机数据白采了?银河通用具身大模型已充分泛化,基于仿真数据!
高度逼真3D场景!UNREALZOO:扩展具身智能的高真实感虚拟世界
MMLab最新FreeSim:一种用于自动驾驶的相机仿真方法
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









