






点击下方卡片,关注“自动驾驶之心”公众号
Diffusion-Based Generative Models
论文标题:Diffusion-Based Generative Models for 3D Occupancy Prediction in Autonomous Driving
论文链接:https://arxiv.org/abs/2505.23115
核心创新点:
1. 将3D占用预测重构为生成建模任务
首次提出通过扩散模型 (Diffusion Models)对3D占用网格进行生成建模,突破传统判别方法(如端到端映射图像到占用网格)的局限性。
核心贡献 :
通过建模3D场景先验 (3D Scene Prior)和联合语义关系,提升预测的物理一致性与细节完整性(如遮挡区域补全)。
利用扩散模型的多模态分布建模能力 (Multi-Modal Occupancy Distributions),生成符合视觉观测的多样化合理样本,支持下游规划任务的多场景推演。
2. 基于离散扩散过程的条件采样框架
提出针对离散分类变量 (Discrete Categorical Variables)的扩散建模方法,结合鸟瞰图 (BEV)特征作为条件输入,优化生成过程。
关键技术 :
离散扩散过程 :采用均匀转移矩阵(Uniform Transition Matrix)对占用网格进行噪声扰动,通过可学习嵌入层将离散标签映射到连续特征空间。
无分类器引导 (Classifier-Free Guidance, CFG):通过调整条件(ℓ_c)与无条件(ℓ_u)模型的logits加权(ℓ = (s+1)ℓ_c − sℓ_u),增强视觉条件对生成过程的控制力。
端到端训练 :以BEV模型的最终分类器前表示(C-R)为条件,联合优化视觉编码器与扩散模型参数。
3. 噪声鲁棒性与动态推理机制
噪声鲁棒性 :扩散模型的去噪能力天然适配占用标注中的传感器噪声与局部观测问题,显著优于判别方法。
动态推理 (Dynamic Inference Steps):通过控制采样步数(如10-15步),在推理效率与预测质量间灵活平衡(见表IX性能对比)。
4. 对下游规划任务的赋能验证
首次将占用预测的评估视角扩展至规划任务效能 (Planning Task Effectiveness),证明生成模型输出的占用场景更符合实际决策需求。
实验验证 :
在UniAD框架中替换BEV特征为生成的占用网格,显著降低碰撞率(Collision Rate)与轨迹L2误差(表VIII)。
无需可见掩码(Visible Mask)训练时,生成模型性能超越基于真实标注的判别方法,体现其对非可见区域的合理推断能力。
大额新人优惠!欢迎扫码加入~

RadarSplat
论文标题:RadarSplat: Radar Gaussian Splatting for High-Fidelity Data Synthesis and 3D Reconstruction of Autonomous Driving Scenes
论文链接:https://arxiv.org/abs/2506.01379
代码:https://umautobots.github.io/radarsplat

核心创新点:
1. 首例雷达驱动的3D高斯溅射框架
首次将3D Gaussian Splatting (GS) 引入自动驾驶雷达场景,构建显式高斯场景表示(公式9)。通过雷达物理约束的渲染方程(公式11)建模雷达波特性,解决传统NeRF方法(如Radar Fields)在噪声场景下的失效问题。
2. 雷达噪声建模与解耦
噪声检测:提出基于快速傅里叶变换(FFT)的噪声分类算法(公式2-3),精准识别多径效应(Multipath Effects)、接收机饱和(Receiver Saturation) 和散斑噪声(Speckle Noise)(图3)。
概率解耦:在功率反射率中引入噪声概率项(公式10),解耦目标占据概率与噪声,支持雷达逆渲染(Radar Inverse Rendering) 分离真实目标/噪声/多径(图9)。
3. 高保真雷达渲染管线
双增益投影:
俯仰投影(Elevation Projection):结合雷达俯仰天线增益累积高斯权重(公式11)。
方位投影(Azimuth Projection):通过方位天线增益的1D卷积实现波束成形(图20)。
4. 去噪与占据图监督
鲁棒去噪算法:基于噪声检测结果生成无噪掩膜,通过高斯平滑与衰减区域搜索构建初始占据图(Occupancy Map)(图5-6,算法3.3)。
占据图监督损失:以去噪后的占据图作为监督信号,通过损失项提升几何重建精度(公式12)。
DriveMind
论文标题:DriveMind: A Dual-VLM based Reinforcement Learning Framework for Autonomous Driving
论文链接:https://arxiv.org/abs/2506.00819
核心创新点:
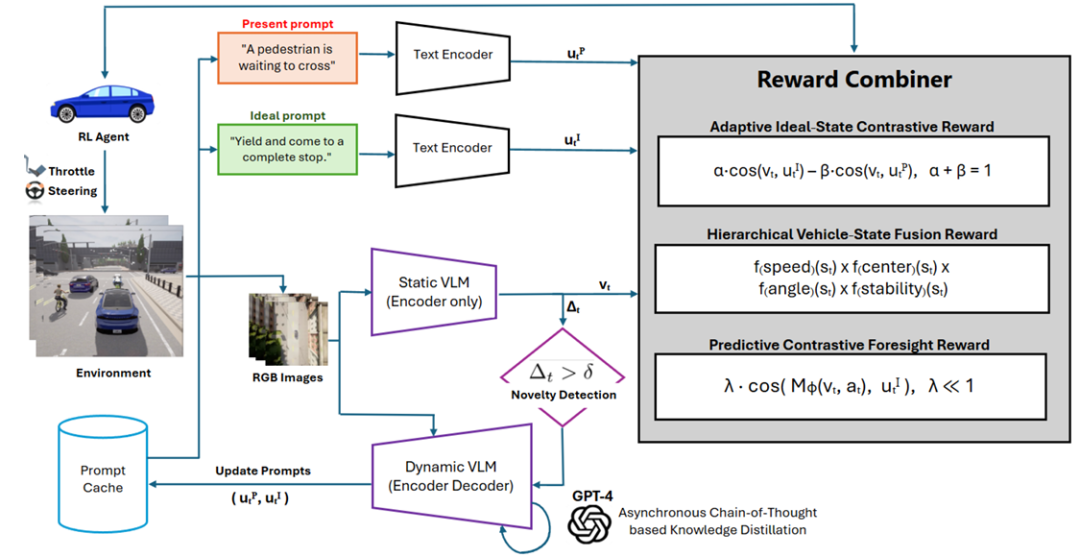
1. 动态双VLM架构与对比语义奖励
创新点 :提出动态双VLM架构,结合静态对比VLM编码器 与新颖性触发的VLM编码器-解码器 ,解决传统固定提示的语义僵化问题。
静态VLM :采用冻结的CLIP模型(ViT-bigG-14)对鸟瞰图(BEV)帧进行嵌入,通过固定“当前状态”(present)与“理想状态”(ideal)文本提示,生成对比语义奖励(Contrastive Semantic Reward)
动态VLM :基于SmolVLM-256M构建编码器-解码器,通过链式思维蒸馏 (Chain-of-Thought Distillation)微调,仅在语义嵌入漂移超过阈值时触发,生成自适应的“当前/理想”提示(如风险评估与路径规划),避免奖励黑客(Reward Hacking)。
2. 自调整语义奖励框架
创新点 :融合多模态奖励机制,实现可解释、安全的决策:
自适应理想状态对比奖励 (AICR):
动态调整正负提示权重(α+β=1),平衡安全探索与危险规避。
层次化车辆状态融合奖励 (HVFR):
通过乘性融合归一化运动学指标(速度、车道居中、航向对齐、横向稳定性),强制执行硬性安全约束(任一指标违规即惩罚)。
预测对比远见奖励 (PCFM):
基于紧凑世界模型(Compact World Model)预测下一语义嵌入,引导长期信用分配与前瞻性规划。
3. 零样本跨域泛化能力
创新点 :在真实行车记录数据(BDD100K)上验证语义奖励的零样本迁移性:
自适应理想状态对比奖励(AICR)分布偏移极小(Wasserstein距离=0.028,K-S统计量=0.105),表明模型在未见过的真实场景中仍能保持鲁棒的语义对齐。
无需微调即可适应真实世界的光照、天气变化及罕见事件(如道路损坏)。
GaussianFusion
论文标题:GaussianFusion: Gaussian-Based Multi-Sensor Fusion for End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2506.00034
代码:https://github.com/Say2L/GaussianFusion
核心创新点:
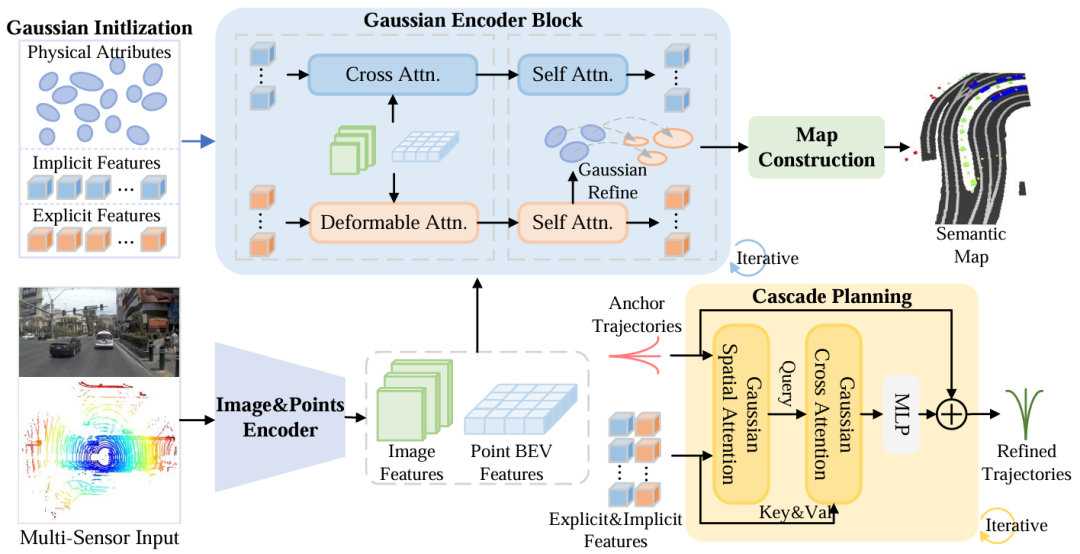
1. 基于2D高斯表示的多传感器融合框架
首次将2D高斯分布 (Gaussian Splatting)引入端到端自动驾驶的多传感器融合 (Multi-Sensor Fusion),通过物理属性(均值、尺度、旋转)和隐/显式特征建模交通场景。相比传统3D高斯表示,仅需BEV语义图监督,无需密集3D标注,显著提升计算效率。
2. 双分支特征融合架构
显式分支 (Explicit Branch):通过几何对齐的跨模态注意力(Cross-Attention)聚合多传感器局部特征,用于更新高斯的物理属性(如位置、语义),实现交通场景的显式重建 (Scene Reconstruction)。
隐式分支 (Implicit Branch):通过全局跨模态交互提取互补特征,直接服务于轨迹规划,解耦感知与规划任务的耦合性。
3. 级联规划头(Cascade Planning Head)
提出分层高斯查询机制 ,通过迭代优化锚定轨迹(Anchor Trajectories):
利用显式特征构建场景拓扑,隐式特征捕捉全局规划线索;
通过交叉注意力(Cross-Attention)动态聚合高斯特征,生成鲁棒轨迹。
该设计显著提升复杂场景(如无保护左转、密集交通)的轨迹预测精度。
4. 稀疏高斯表示的效率与可解释性优势
相比传统BEV融合的密集栅格化表示,高斯的空间稀疏性 (Sparsity)减少冗余计算,缓解内存瓶颈;
物理属性(如语义、位置)提供直观的场景解释,增强模型透明度,避免黑箱式注意力机制的模糊性。
5. 端到端验证与性能突破
在NAVSIM和Bench2Drive基准测试中,GaussianFusion以ResNet-34为骨干网络,分别取得85.0 EPDMS和79.4 DS的SOTA性能,验证了其在开放环路(Open-Loop)与闭合环路(Closed-Loop)场景下的鲁棒性与泛化能力。
智能驾驶进入新一轮的下沉期,行业前沿聚焦在大模型、VLA、端到端等方向。为此我们打造了一个专业的技术社区,follow学术界和工业界的最前沿!欢迎加入『自动驾驶之心知识星球』......
大额新人优惠!欢迎扫码加入~


















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









