







序言
阳历生日。今年因为年过得早的缘故,很多事情都相对提前了(比如情人节)。往年过生日的时候基本都还在家,所以一家子出去吃个饭也就罢了。今年承蒙凯爹厚爱,正好也有小半年没聚,他前天也刚正式拿到offer,于是狠狠地宰了他一顿哈哈(srds下个月他过生日还得还回去)。
难得跟人一逛老半天,从乳山四村到正大广场,吃完饭再回来,一路上交换见解与心得,从九点多一直到晚上六点多才走,凯爹的阅历让我受益颇多。我其实很羡慕凯爹这样的人,每一个能从二战走出来的都是勇士中的勇士,就是那种生活很有激情,并且目标明确,矢志不渝,这两个词我觉得是越来越难能可贵。
回来这些天除了泡实验室,每天还是至少会去遛五圈,前天浅浅地跑了5000米,其实也不是很吃力。说起来差不多停跑了有十天,相当致命,不过我发现因为这么多年来屡屡从低谷恢复训练,身体已经习惯了这种节奏,至少今年开始恢复的时候跑起来还是挺轻快的,虽然耐力明显很差,但也没有那么笨重。
初心难追,但是谁又愿意就如此屈服于生活呢?
文章目录
- 序言
- 20230216
- 20230217~20230220
- 20230221
- 20230222~20230224
- 20230225~20230226
- 20230227
- 20230228
- 20230301
- 20230302
- 20230303~20230304
- 20230305~20230306
- 20230307
- 20230308
- 20230309
- 20230310~20230311
- 20230312
- 20230313~20230314
- 20230315
- 20230316
- 20230317
- 20230318
- 20230319
- 20230320~20230321
- 20230322
- 20230323
- 20230324~20230325
- 20230326~20230327
- 20230328
- 20230329
- 20230330
- 20230331
- 20230401
- 20230402~20230403
- 20230404
- 20230405
- 20230406
- 20230407
- 20230408~20230409
- 20230410
- 20230411
- 20230412
- 20230413
- 20230414~20230415
- 20230416
- 20230417~20230418
- 20230419
- 20230420
- 20230421~20230423
- 20230424~20230425
- 20230426~20230427
- 20230428~20230503
- 20230504
- 20230505
- 20230506
- 20230507~20230509
- 20230510
- 20230511
- 20230512
- 20230513
- 20230514~20230515
- 20230516
- 20230517~20230520
- 20230521
- 20230522
- 20230523
- 20230524~20230525
- 20230526~20230528
- 20230529~20230530
- 20230531
- 20230601
- 20230602
- 20230603
- 20230604
- 20230605
- 20230606
- 20230607
- 20230608
- 20230609
- 20230610~20230613
- 20230614
- 20230615
- 20230616~20230617
- 20230618~20230620
- 20230621
- 20230622
- 20230623
- 20230624~20230625
20230216
因果推断之遐想,今年NSFC的通告里着重强调了这个方向,严格上来说这是一个统计学范畴,但是他越来越受到ML以及DM领域的关注,原因在于数据中难免存在难以捕获的偏见。
最近一篇非常好的CasualLM: Causual Model Explanation Through Counterfactual Language Models,提出了一种基于反事实构造的反事实语言模型,可以修整数据中固有的偏见。
但是现阶段因果推断和NLP的结合的工作大多是基于现有的因果图做检验会调整,其实有一个很关键的核心问题是如何捕获混杂因子(在没有因果图的情况下),一些工作会介绍如何从复合变量中分离得到混杂变量以及调整变量,如http://www.meng-jiang.com/pubs/tee-aaai17/tee-aaai17-paper.pdf与https://arxiv.org/abs/arXiv:2006.07040,但是这些工作也是建立在因果图已知,候选的变量已经给定的前提下得到的,一般的情况是只给你上下文语料,如何判断一个基于该语料的任务存在混杂因子。
其实在预训练数据是足够充分的条件下,我们应当认可模型预测的结果是无偏的。问题在于预训练数据总是不够充分的,所以我们需要构造反事实来使得它更为均衡。还有就是Pearl的因果推断理论框架是完全建立在因果图之上的,问题在于没有任何理论保证因果图的有效性,这在因果推断与NLP结合时确实是令人费解的事情,这就有点射箭画靶的意思,为了论证存在混杂,特意构建了一个能够导出混杂的因果图。
20230217~20230220
- 昨天颜烨即兴约我和王凯小聚,在很久以前羊肉串,就很巧,颜烨最近也在看因果推断,不过他是用在推荐上,于是在等王凯时交换了不少意见。吃完去政民路上的一家小酒吧搓了两把以色列麻将,最后险些完成华丽的逆转(7张牌反杀颜烨2张牌,就是有1张怎么想都出不去),狗颜烨手气贼好把把起手百搭,我两把一个百搭都没摸不到(笑)。
- 下个月19号锡马,说实话把握不是很大,但是目标肯定还是要进95分钟,其实说起来我已经有14个月没有跑过20km以上的距离了。恢复期目前练了六天,但是周末歇了两天,今天是2km+1km+1km的间歇,配速4分整,间歇5分钟,心率上到190,痛苦得要死,但是要快速恢复就必须依赖高强度的变速和间歇,耐力还得靠跑量堆上去。目前水平持平去年九月底,想要跑半马至少也要达到去年十一月底的水平。就过往的经验来看只要能把10km跑到43分钟左右,基本上在最佳状态下就有能力冲击半马。
- 说实话也许是我最后一次跑步了,我也确实地感觉到各种压力而无法坚持下去,也许赶不上最后的一次校运会,仍是遗憾无比,除非我愿意能够在高压下坚持训练到4月底,以后大概率是以养生跑为主。尽管大概率还是不能在最巅峰的状态下完成比赛,但跑一次半马是最后的倔强,虽然以后有机会我也许会去跑全马,跑铁三,但是我不愿意自己这么三年多以来的阶段性跑步生涯就如此无疾而终,它应该配得上一个荣誉作为句号。
谈谈我对chatGPT的看法,昨天也跟yy和wk探讨了这个问题。其实去年十一二月的时候,就已经可以在B站上刷到不少chatGPT大战弱智吧的视频,当时我也不是很关注,总觉得是跟以前那种废话文学生成器是一样的toy model。直到今年一月搞科技部课题申报的时候事实上接触chatGPT时才真正震惊于其恐怖的性能。
现在网络上的评价趋于两级分化,有的人奉chatGPT为神,有的人对之嗤之以鼻。就我浅薄的认知而言,假若chatGPT的背后确实没有任何人类技术员的干预(或者说白了就是人工作弊),我认为chatGPT将是一个划时代的产物,以2017年BERT横空出世作对比,chatGPT的创新性至少比BERT要高出一个档次。
因为就我所理解,chatGPT在许多NLP任务上(问答、对话、代码改错、目标文本生成、自然语言推断、阅读理解、文本综述)都远远超过了目前相应领域SOTA模型的性能。具体的细节我也不想写太多,因为我是做这方面工作的,这种效果让我非常震惊。
以前说强AI会取代很多工作,现在看来强AI的出现,第一批失业的或许就是我们这批踩着末流踏进AI研究的,就有点像49年假如guo军的感觉(苦笑)。试想,你针对一个特定任务的做的模型,做得再好也比不过chatGPT,chatGPT在广度和深度上已经超过了大部分研究者的上限,这是一件非常可怕的事情。很多大企业追逐潮流,就会对业务和人员进行结构性调整,谁又能确保之后不会出现第二个chatGPT呢,特别特别有危机感。说实话,保守估计我觉得国内近一年不可能有产品可以超越chatGPT。
所以现在很多的想法就是去做chatGPT做不了的事情,即要跳出NLP,比如图像、推荐等,如果还是要和NLP挂钩,那么要么在方法论上创新,要么只能向多模态发展。这可能也是为什么因果推断成为今年NSFC的一个重要突出领域。
提一个,写开题看到VisualMRC,一开始以为就是VQA,结果VisualMRC竟然是所有的上下文就是一张图像,不过图像中包含区块性的文字以及贴图,VQA是直接给一张图(可能会有简短的描述),然后直接答题。VisualMRC提出的动机是因为大部分现实世界文本都不是以纯文本出现的(比如PDF和HTML),所以只能处理包含文本的图片,不过总觉得只是用OCR识别一下即可划归到一般的VQA,感觉又是为了发paper画靶射箭。
20230221
- 昨晚wyl破天荒开组会从六点开到十点半,我跟黄名媛实在是顶不住了,黄名媛本来晚上约人吃饭,我说估计一个多小时就结束了,可以等结束再去吃。结果她连晚饭都没吃到,离大谱。
- 降温,长袖长裤拉耐力,10圈17’20",配速4’20",其实挺满意的,一周就可以上到4km,比九月份恢复得快(那时候挣扎了半个多月都没能跑10圈)。结识了一下经常来跑的光头大叔,我一直以为他是老师,原来是家属,上周也偷偷跟他跑了几次,发现三年来一点长进没有,配速还是4’40"~4’50"的水平,有点失望,要不然就可以找个pace差不多又看起来很专业的一起练。他都是每天下午三点半之后到操场,我一般是四点,但他拉伸时间很长,所以起跑时间很接近。他不跑比赛,单纯是锻炼身体,但是今年还是本着10km跑进45min在训练,有个目标跑起来确实更有动力一些,这也是我一直拒绝养生跑的原因。如果真的只是以锻炼身体去养生跑,根本是无法坚持长久的。
SQuAD1.1和2.0的下载链接:
https://data.deepai.org/squad1.1.zip
https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json
然后NewsQA直接可以在https://download.microsoft.com/download/1/D/8/1D830CEE-F8D1-4807-9224-DE35A8F08DC4/newsqa-data-v1.zip下载,问题是NewsQA里没有上下文(story),只有storyid,因为story的版权不在微软,在CNN,那个要翻墙(https://cs.nyu.edu/~kcho/DMQA/),给翻不了墙的留个门cnn_stories&&dailymail_stories.7z
然后就是昨晚复旦大学对话机器人MOSS,我是真的服了,第一次看到这么能蹭热度的,哗众取宠,还同时蹭两个。国内最先能接近chatGPT的模型肯定不可能是高校首先发布,如果能做出来一定是BAT,学校再有钱也不可能这么去烧。
20230222~20230224
- 周三订酒店,锡马也就上周日才官宣定档,两三天时间周边的酒店预定就已全部售罄,最后好不容易抢到一个距离起点2km以内的,还只剩一个家庭房。毕竟算是疫情后的第一场高规格赛事,可见一斑。
- 这周基本上每天都有5km的量,但是想要从突破到10km依然十分困难,最后三周,尽力而为罢。
SQuAD process:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import json
import pandas
from setting import (SQuAD_JSON_PATH_SUMMARY,
SQuAD_ARTICLE_PATH,
SQuAD_QUESTION_PATH,
)
def SQuAD_to_csv(article_export_path=SQuAD_ARTICLE_PATH, question_export_path=SQuAD_QUESTION_PATH):
article_dict = {'article_id' : list(),
'title' : list(),
'article' : list(),
'type' : list(),
'version' : list(),
}
question_dict = {'question_id' : list(),
'article_id' : list(),
'question' : list(),
'answers' : list(),
'answer_starts' : list(),
'answer_ends' : list(),
'type' : list(),
'version' : list(),
}
for key, data_path in SQuAD_JSON_PATH_SUMMARY.items():
type_, version = key.split('-')
with open(data_path, 'r', encoding='utf8') as f:
data = json.load(f)
count = -1
for sample in data['data']:
title = sample['title']
paragraphs = sample['paragraphs']
for paragraph in paragraphs:
count += 1
article_id = f'{type_}-{version}-{str(count).zfill(5)}'
article = paragraph['context']
for question_and_answer in paragraph['qas']:
question_id = question_and_answer['id']
question = question_and_answer['question']
candidate_answers = question_and_answer['answers']
answer_starts = list()
answer_ends = list()
answers = list()
for candidate_answer in candidate_answers:
answer_start = int(candidate_answer['answer_start'])
answer = candidate_answer['text']
answer_end = answer_start + len(answer)
# assert answer == article[answer_start: answer_end]
answer_starts.append(answer_start)
answer_ends.append(answer_end)
answers.append(answer)
# Write question Dictionary
question_dict['question_id'].append(question_id)
question_dict['article_id'].append(article_id)
question_dict['question'].append(question)
question_dict['answers'].append(answers)
question_dict['answer_starts'].append(answer_starts)
question_dict['answer_ends'].append(answer_ends)
question_dict['type'].append(type_)
question_dict['version'].append(version)
# Write article dictionary
article_dict['article_id'].append(article_id)
article_dict['title'].append(title)
article_dict['article'].append(article)
article_dict['type'].append(type_)
article_dict['version'].append(version)
# Convert to dataframe
article_dataframe = pandas.DataFrame(article_dict, columns=list(article_dict.keys()))
question_dataframe = pandas.DataFrame(question_dict, columns=list(question_dict.keys()))
# Export dataframe
article_dataframe = article_dataframe[['article_id', 'title', 'article', 'type', 'version']]
question_dataframe = question_dataframe[['question_id', 'article_id', 'question', 'answers', 'answer_starts', 'answer_ends', 'type', 'version']]
if article_export_path is not None:
article_dataframe.to_csv(article_export_path, sep='\t', header=True, index=False)
if question_export_path is not None:
question_dataframe.to_csv(question_export_path, sep='\t', header=True, index=False)
return article_dataframe, question_dataframe
20230225~20230226
- 下午绝好天气,3000米跑到11’55",感觉已经恢复到八九成(之前3000米最快能跑到11’40"以内,不过恢复两周能跑进12分钟也并无不满)。我感觉状态绝佳的情况下已经有能力冲击10km(只是今天碰到卢星雨和黄懿嘉在跑间歇,跑得太快,节奏给搞得有点崩),感觉还是很可期的,下周如能继续保持强度与状态,有信心下个周末就能把10km跑进43分钟,然后最后两周拉体能,直到19号能达到半马水平。
- 浪潮发布了源1.0大型中文模型,目前准备开源其训练语料,已经毕业的师兄王明回来准备以组的名义去申请数据,顺便找我们几个小咸鱼搞些合作,确是极好的。王明在阿里也在搞它们的chatGPT,我跟他说现在chatGPT做的这么好,我们这些底层科研狗真的很难实现模型性能上的创新,只能在方法论上做一些横向突破。王明说他也不指望国内短期能做到chatGPT的水平,至少阿里目前确实没有这个水平。这就是现实,别人确实是做到了我们做不到的事情,有时候真的不服不行,而且这行是很可怕的,一旦chatGPT真正投入商用,国内无法跟进脚步,用户群体被垄断后,这个差距就会被进一步拉大,chatGPT会以更加恐怖的速度积累语料训练并不断完善模型,到时候真的很难想象国内到底还有没有机会赶上chatGPT的步伐。我有一种隐隐地感觉,最坏的情况下,chatGPT将会在不久的将来彻底垄断NLP研究领域,因为再也没有机构能在数据积累和模型规模上超越chatGPT,除非天降猛男开辟出一个全新的高效模型训练框架,打破目前这种研究开发的范式,否则确实是一件让人,搞不好大家长又会彻底墙掉chatGPT,来保护国内的资源发展。
吊命的异步下载(拒绝吸血雷):
#coding:utf-8
import asyncio
import sys
import time
import os
import cgi
import re
from urllib import parse
from urllib.parse import urlparse, unquote_plus
file_name_pattern = re.compile(r"utf|UTF-8'\s+'")
import aiohttp
def get_file_name(content_disposition):
_, params = cgi.parse_header(content_disposition)
if "filename" in params:
return params["filename"]
elif "FILENAME" in params:
return params["FILENAME"]
elif "filename*" in params:
return re.split("utf-8'\s+'", params['filename*'], 1, flags=re.IGNORECASE)[1]
elif "FILENAME*" in params:
return re.split("utf-8'\s+'", params['FILENAME*'], 1, flags=re.IGNORECASE)[1]
else:
return None
async def fetch(session, url, startpos, endpos, filename):
headers = {
"Range":"bytes=%s-%s"%(startpos,endpos),
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding":"gzip, deflate, br",
"accept-language":"zh-CN,zh;q=0.9",
"upgrade-insecure-requests":"1",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
}
print("fetch...", startpos, endpos)
async with session.get(url, headers=headers) as response:
with open(filename, 'rb+') as fd:
fd.seek(startpos)
while True:
chunk = await response.content.read(1024)
if not chunk:
break
fd.write(chunk)
async def main(url, thread_num):
#获取文件的大小和文件名
urlobj = urlparse(url)
filename = ""
start = 0
end = -1
step = 0
tasks = []
headers = {
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding":"gzip, deflate, br",
"accept-language":"zh-CN,zh;q=0.9",
"upgrade-insecure-requests":"1",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
}
#https://www.cnblogs.com/momoxingchen/p/6493317.html
async with aiohttp.ClientSession() as session:
async with session.head(url, headers=headers) as response:
headers_content = response.headers
print("headers_content", headers_content)
if "Content-Length" not in headers_content:
raise Exception("can't get file size")
filename = urlobj.path.rsplit('/',1)[1]
if 'Content-Disposition' in headers_content:
tmp_file_name = get_file_name(headers_content["Content-Disposition"])
if tmp_file_name is not None and tmp_file_name:
filename = tmp_file_name
filesize = int(headers_content["Content-Length"])
step = filesize // thread_num
print("%s filesize:%s"%(filename,filesize))
with open(filename,'w') as tempf:
tempf.seek(0)
tempf.write("hello")
async with aiohttp.ClientSession() as session:
while end < filesize -1:
start = end +1
end = start + step -1
print("start:end:", start,end)
if end > filesize:
end = filesize
task = asyncio.ensure_future(fetch(session,url,start, end, filename))
tasks.append(task)
await asyncio.gather(*tasks)
if __name__ == "__main__":
url = "https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json"
loop = asyncio.get_event_loop()
loop.run_until_complete(main(url, 2))
20230227
- 晚上跟王英林吃了个饭,最近很多事情要跟他当面汇报一下才清楚。明天韩明月预答辩,有一个师姐要离我而去了,她毕业之后我就真的成了组里的老大头,可是依然有所迷惑。实话说明月姐运气确实很好,讲道理那篇ACL我仔细看过,质量不算很高,但是就是被接收了,然后就一篇CCF-A直接定乾坤,其他三篇都是特别水的凑数。但是即便如此她硕士阶段和博士阶段各拿了一次国奖,实力也是强的离谱,反正我这届硕博没有一个人在硕士阶段拿过国奖(因为都被金工的scx和dyt给拿捏了,怎么说硕士阶段我也是硕博这边的综评第一,真是难受)。而且我也看了她的论文初稿,131页,工作量比胡振达要小不少,但是最后两页纸的致谢确是真情流露,人的实力和运气都很重要。
- 晚上3km慢跑,穿羽绒服和老重老重的板鞋跟着lxy和hyj,她俩是真的能跑,估计有15圈,还是外道。权且休整状态,一想到明月姐和胡振达都那么强,我也确不能辱没师门呐,留给我的时间真的不多了。
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import time
import urllib
import requests
import traceback
from tqdm import tqdm
from multiprocessing import Process, Pool, Manager, cpu_count
class Downloader(object):
def __init__(self) -> None:
pass
def multi_processing_download(self, url: str, n_process: int=None) -> None:
"""
Download file with multiprocessing.
:param url : The URL of the resource needed to download.
:param n_process: Total number of processes in pool.
"""
if n_process is None:
n_process = cpu_count() - 1
parse_result = urllib.parse.urlparse(url)
filename = parse_result.path.rsplit('/', 1)[1]
headers = requests.head(url).headers
filesize = int(headers.get('Content-Length', None))
manager = Manager()
queue = manager.Queue(10000)
process = Process(target=self._display_download_speed, args=(filesize, queue))
start = 0
end = -1
with open(filename, 'w') as f:
f.seek(0)
pool = Pool(processes=n_process)
step = filesize // n_process
print('Step: {}'.format(step))
while end < filesize - 1:
start = end + 1
end = start + step -1
print('start: {} - end: {}'.format(start, end))
if end > filesize:
end = filesize
pool.apply_async(self._partially_download, args=(url, start, end, filename, queue))
pool.close()
process.start()
pool.join()
process.join()
print('Process join done')
def multi_threading_download(self, url: str) -> None:
pass
def _display_download_speed(self, filesize, queue):
write_size = 0
print('Check download speed')
while True:
speed = 0
current_timestamp = time.time()
while not queue.empty():
item = queue.get(True)
size = item.get('size', 0)
timestamp = item.get('timestamp', current_timestamp - 10000)
write_size += size
if current_timestamp - timestamp > 1:
break
speed += size
ratio = write_size / filesize
try:
self._display_process(ratio, speed)
except:
pass
def _display_process(self, ratio: float, speed: float, n_bar: int=100) -> None:
end_char = '\r'
if ratio >= 1:
end_char = '\n'
bar_number = 100
done_number = round(ratio * bar_number)
done_char = '#' * done_number
remain_char = '-' * (bar_number - done_number)
process_bar = '[{done_char}{remain_char}] {percentage}% speed:{speed}'.format(
done_char=done_char,
remain_char=remain_char,
percentage='%0.2f' % (ratio * 100),
speed=speed,
)
print(process_bar, end=end_char)
def _partially_download(self, url, start_position, end_position, filename, queue) -> None:
try:
with open(filename, 'rb+') as f:
print('Start downloading****')
headers = {'Range': 'bytes=%s-%s' % (start_position, end_position)}
response = requests.get(url, headers=headers, stream=True)
f.seek(startpos)
for data in response.iter_content(chunk_size=1024):
f.write(data)
queue.put({'timestamp': time.time(), 'size':len(data)})
except Exception as e:
print('download error', e)
traceback.print_exc()
if __name__ == '__main__':
d = Downloader()
url = 'https://web.stanford.edu/~hastie/CASI_files/PDF/casi.pdf'
url = '"https://codeload.github.com/lrs1353281004/CS224n_winter2019_notes_and_assignments/zip/refs/heads/master.zip"'
# d.multi_processing_download(url)
d.multi_processing_download(url, 4)
20230228
- 昨晚又是开会到十点半,这周极限冲刺,7号前要把NFSC初稿弄出来,头大。
- 下午把浪潮的申请签好盖章寄掉,时间太晚还是去操场混了二十分钟训练,其实已是末尾冷身,我顺带着跟陈嘉伟晃了四圈顺带热身。嘉伟终于还是被一个寒假给干倒了,嘉伟说他一个寒假没动,前几天跑了个2km就躺了几天,这样的从低谷慢慢恢复的痛苦我已经经历过N多次。暑假相对来说要好一些,但是过年要坚持每天训练,你自己能坚持得下来,家人也不会让你这么去像个神经病在路上狂奔,还要承受别人异样的目光。
- 今天状态跟预估有差距,可能是跑前跑后费了些力气,而且热身的时候跟嘉伟跑得太快,后来4分配跑了2km就直接垮掉,补了一个800米,感觉这周要能上10km挺悬,然时不我待,只剩不到20天了。
Census X12和X13调整需要使用美国统计局已封装号的X12a.exe和X13AS.EXE二进制程序,找了半天只有CSDN上有个资源比较靠谱一些,里面提供了测试代码和两个可执行程序(https://download.csdn.net/download/zhouhao707/12717511?spm=1001.2101.3001.5697)
然鹅需要积分,但是我已经传到盘里了,有需求自取:
https://pan.baidu.com/s/1hDWVXeGp6ovTsLq2i0Dvgg?pwd=957n
另外我做了一个测试程序:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import numpy as np
import pandas as pd
from datetime import datetime
from X12a_X13as import X12a, X13as
a = X13as() # 调用这个类的方法
# 随机造了一组数据dataframe, dataframe的index必须是日期格是
df = pd.DataFrame({'data': np.random.random(36)})
df.index = [datetime(2020, i, 1) for i in range(1, 13)] + [datetime(2021, i, 1) for i in range(1, 13)] + [datetime(2022, i, 1) for i in range(1, 13)]
result = a.x13(df)
for k, v in result.items():
print(k, v)
调整后的序列有三个,虽然不是很懂是什么意思(给凯爹做的)。
20230301
- 状态又很迷,下午慢跑10圈都感觉吃力,可能是跟gjw边跑边说话的缘故,我发现不管我用多少配速跑(虽然再慢也不会掉出5分配),时间长了心率都要到170以上,像很多人慢跑心率都能控到150以下。其实就是跑量太少,听说跑量过10000km心率才会有明显降低,现在连5000km都不到。
- 从2月13日恢复训练起算,距离3月19号前只有33个训练日,到目前已经是17个训练日,过半,但跑万米的把握都不到三成,这周虽然很push,但也得设法抽出时间试跑一次万米了,不然真的来不及了。
因果推断遐想(二):
明月姐的预答辩如预期一般的通过了,其实五个老师一个都不懂因果推断,所以基本都是听得云里雾里,牛B哄哄的崔万云都没提一点有意义的建议,只是说因果推断似乎是实验室研究,现实世界是行不通的。诚然如是,但是不可否认的是目前的确因果推断在工业界也是有应用的。我认为因果推断如果想要做出实际意义,那就得做出和知识图谱一般的因果图谱,然而因果图谱要比知识图谱复杂得多,目前的因果图都是确定的有向边,其实现实世界哪有那么多绝对呢?所以因果图理论上应该是概率边,但是如果是概率边,似乎就要破坏目前因果推断的理论基石(do算子、后门调整、前门调整之类的)。
一种主题干预的后门调整情感分析示意图,我改了个超科幻的自动混杂生成的设想图,反正是写本子,天马行空了:
 —
—
20230302
- 晚上训练陈嘉伟陪跑,成功恢复到场地万米,节奏很好,有人一起跑动力十足。用时42’22",均配4’14"。前5000米我领跑,用时21’09",后5000米换嘉伟领跑,用时21’13",说到底男人的话一个标点都不能信,嘉伟说他一个寒假没动,现在耐力垮得很,所以这就是指就是轻松跑完10km,又做了100个俯卧撑,最后还补了7圈追逐跑(其实我跑完也不是很累,但是追逐跑了5圈就不想坚持了,这种节奏稳定的万米跑完确实超级享受)。
- 今晚很冷,其实并不适合跑,本来下午阳光明媚,但是我又很想等训练时一起跑,所以下午只是养生晃了三圈,等到晚上跟嘉伟尽兴一下。现在距离锡马开赛还有16天,14个训练日,只要能保持这个状态,跑进95分钟应该是绰绰有余,就看能否稳中求进冲击90分钟大关了。
跟明月姐拉扯了一下午,来看看最终这版天马行空的架构图(难道混杂未知就是你虚空索敌的理由???
20230303~20230304
- 下午训练,状态极佳本以为可以轻松拿下八组400米间歇,结果前两组跑完从臀部到大腿就已经麻得站都站不稳。第一组1’10",第二组1’13",然后就痛苦到死,站着难受,坐着更难受,接着两组掉到1’20",纯靠一丝意志在冲刺,四组跑完所有人都瘫倒在地,再起不能。时隔三个多月,再次被死亡400打回原形。
- 3月11日高百资格赛将在武东田径场进行,这也是疫情后校友们第一次返回学校参赛,作为锡马前的一次热身是再好不过。
关于虚假线索与因果特征的识别,可以基于特征的域适应差异性来进行区分:

20230305~20230306
- 下午计划慢跑十圈,结果刚进场就看到宋镇均在练1000米间歇。上学期十月yq爆发后他就离校一直未归,我以为他真又废了,这学期刚来时我问他多久没跑,他说二月还是练了几次,结果前天400米间歇先是给我一个下马威,今天进场看他的速度还以为是在跑第一个1000米,跑完他告诉这已经是第4个了。我直接震惊了,当即说最后一个我来带他跑,顺便胜之不武地拿捏一下他。尽管我是穿长袖长裤来准备慢跑,但第一圈还是带到3’40"以内的配速,我看他似乎有点不支,于心不忍还是故意放慢等了他一下,结果这年轻人不讲武德,第二圈到一半就把我超了,还真就一直追不上,给我整不会了。
- 后来补了3000米慢跑,气温太高,而且右脚踝隐隐作痛,大约是前天间歇跑得太猛的缘故。明天下午的训练大概率是5×1000米间歇,由于近期已经在为锡马作准备,尽可能地早睡早起,自我感觉状态很好,跑起来却相当吃力(一方面可能是气温太高的原因),但总是觉得很悬的了。
其实变分自编码器是个很理想地产物,反正我觉得实际应用上很难很难用,一个是假设太强,理论上可以进行运用,但是不可能用于实际产品。
最近看孙健老师对一个经典命题的证明,即证明 2 + 3 + 5 + . . . + p \sqrt{2}+\sqrt{3}+\sqrt{5}+...+\sqrt{p} 2+3+5+...+p,对于任意素数 p p p,都不是有理数。
当然其实直接证明 ∑ i = 0 n i \sum_{i=0}^n\sqrt{i} ∑i=0ni不是有理数也是一样的。
这里有一个很巧妙的证法,就是定义这样一个多项式:
f ( x ) = ∏ ( x ± 3 ± . . . ± p ) f(x)=\prod (x\pm{\sqrt{3}\pm...\pm\sqrt{p}}) f(x)=∏(x±3±...±p)
令:
r
=
2
+
3
+
5
+
.
.
.
+
p
r = \sqrt{2}+\sqrt{3}+\sqrt{5}+...+\sqrt{p}
r=2+3+5+...+p
那么 f ( r − 2 ) f(r-\sqrt{2}) f(r−2)显然等于零(因为 r r r是 f ( x ) f(x) f(x)的一个零点)
如果 r r r是一个有理数,那么 r + 2 r+\sqrt{2} r+2是 r − 2 r-\sqrt{2} r−2的一个共轭根,即 f ( r + 2 ) f(r+\sqrt{2}) f(r+2)也是零,但是显然 f ( r + 2 ) > 0 f(r+\sqrt{2})>0 f(r+2)>0(因为 f ( x ) f(x) f(x)里每一项都是正数)。
确实很精妙,但是事实上这个用Galois或者伽罗瓦理论可以直接证明,我这辈子是学不到高等代数里面的数域和群论了,总觉得这辈子数学可能也就学到现在这个水平为止了唉,好难过。
20230307
- 今天并没有跑1000米间歇,东哥让我们弹力带拉了100个引体(我是真废,用最粗的弹力带,拉10个都费事,细一个档次的就完全拉上不去),然后连续跳栏10组,最后接7圈变速+7圈追逐。7圈变速我强行跟住了陈嘉伟(感觉嘉伟确实状态距离巅峰差太多了,放以前不可能让我跟这么轻松),快圈1’20",慢圈1’50",成功套其他四人各一圈,东哥说我最近状态挺好,那可不是么,想要跑半马,当然得保持状态。
- 分手见人品,我说廖是深咋这么久都不来训练,原来是跟李婷玉分了。说实话我是觉得姐弟恋不靠谱,尤其是女博士,男生多少是有一些支配欲的,双方阅历都不是一个层面的,更不要说廖本科都还没毕业,能不能上岸都不靠谱。但是廖在pyq里话说的实在是太难听,摆明了要把对方名声搞臭,对错不论,也不至于恶化到这种程度,男生总归还是要大气一点。
关于引入混杂表示生成的文本分类模型去混杂,想了一个目标二的具体显式表示:
L 2 = ∑ i = 0 c d i f f ( { H t } t : y t = i ) − ∑ 0 ≤ i < j ≤ c d i f f ( { H t } t : y t = i ∪ { H t } t : y t = j ) L_2=\sum_{i=0}^{c}diff\left(\{H_t\}_{t:y_t=i}\right)-\sum_{0\le i<j\le c} d i f f\left(\{H_t\}_{t:y_t=i}\cup\{H_t\}_{t:y_t=j}\right) L2=i=0∑cdiff({Ht}t:yt=i)−0≤i<j≤c∑diff({Ht}t:yt=i∪{Ht}t:yt=j)
这里为了使得学习到的混杂表示能够影响样本标签,因此考虑从聚类角度出发,使得标签相同的样本对应的混杂隐层表示的差异性尽可能小,而样本标签不同的样本对应的混杂隐层表示的差异性尽可能大。从而确保混杂隐层表示与预测标签地强关联性。 d i f f diff diff是预先设置好的一个表示差异化程度的函数。
20230308
- 扬州鉴真国际半程马拉松报名开始,两万人,4月16日开赛。虽说计划是锡马后跑步训练告一段落,但是扬马毕竟是家门口的比赛,也是我最希望参加的比赛。查了一下2019年的市民组成绩,1小时25分进前10,1小时30分进前30,1小时35分进前50,可惜今年只奖励前10,就目前我的水平,稳进135,但130需要极好的状态,125几乎不可能完成,所以想拿奖金难度极大。不过反正报名抽签不要钱,就碰个运气呗,抽中血钻,就当是圆梦了。抽不中就一心一意搞论文咯。
- 晚上wyl又开会到十点半,明月姐天高皇帝远,于是我跟黄名媛两个倒霉蛋跟wyl拉扯了近四个小时。本来今天想好好休息休息,昨天练引体和跳栏,今天背和腰都疼得不行,下午慢跑10圈保持状态,然后网上这么一出,明明ddl还有好几天,真是push起来就不当人。
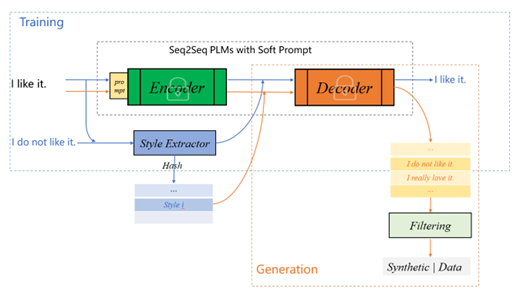
关于基于软提示的生成。其实目前就硬提示而言,总觉得没什么研究价值,就一帮人在哪儿给PLM喂模板吃,模板不好就改,模板好就发文章,一点意思没有,纯纯的工程项目。但是软提示的确还是挺有趣的,下面是本次申报做的一个反事实增强的生成框架,提示的好处感觉是可以大大缩小训练量,当然代价是需要大模型,因为大模型的参数是freeze的,本质上是在学一个好的提示向量表示。
20230309
- 揠苗助长,状态终归还是一个周期性的数值,虽然这几天感觉饮食作息都ok,晚上计划要跑15km,然后晚饭吃特别多,结果两个多小时没能消化完,五点吃完到七点半都撑得厉害,跑了5km就歇菜了(陈嘉伟有事没来,也有点缺乏动力,本来晚上的状态就稍差些)。随队练了两组蛙跳,然后箭步跳4×60个,做完我就知道明天大腿肯定废了,不过这两天在赶工,下午跟黄名媛又给wyl关了半天牢,11号到晚必须要把稿子修好,万一废了干脆休两天拉倒。我总是觉得赛前至少要拉一个15km,否则至少从心理上来说会有些动摇,但我又不想到临近比赛太过度训练,所以很想这周能把15km给跑掉,还是太急了,但毕竟是首马,总是想以万全的状态去迎战。
- 葛智杰和卢星雨两个倒霉蛋,前天居然食物中毒,据说是吃了新园的啥团子,急性肠胃炎连带发烧,不得不花了大几百去长海吊水,然后今晚又来卷,结果葛智杰直接被卢星雨带崩了,太丢人啦。
关于python字符串输出的几个小技巧:
n = int(input('输入奇数n:'))
if n % 2 == 0:
n = int(input('输入奇数n:'))
m = (n + 1) // 2
string_formatter = '{:^' + str(n + 2) + '}'
for i in range(m + 1):
print(string_formatter.format('*' * (2 * i + 1)))
比如'{:^9}'.format('*')就是划出一个长度为9的空当,然后把*插在中间。
但是如果想要把9替换成任意的n,就得写成上面string_formatter = '{:^' + str(n + 2) + '}'的形式。
20230310~20230311
- 状态低迷的两日,昨天起初大腿还不是很酸,下午硬撑着晃了10圈,就已经站不起来了。
- 今天ddl,决定翘了训练,稿子还没整完,大概率也溜不掉,索性跑休一日。明天降温,也是锡马最后一周倒计时,就是拼了老命,也必须拉一次长距离。
HRCA复现
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Implementation of HRCA
import torch
from torch.nn import Module, Linear, NLLLoss, functional as F
from setting import DEVICE
from src.tool.pretrained_model_tool import load_transformer_model
from src.module.attention_module import MultiHeadAttention
class HRCA(Module):
"""Forward propagation algorithm of HRCA and HRCA+
Reference: [HRCA+: Advanced Multiple-choice Machine Reading Comprehension Method](www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.651.pdf)
- Input:
- $P \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A = \{A_1, ..., A_m\}, A_j \in \R^{d×a}$
- Output:
- $L \in \R^m$"""
loss_function = NLLLoss()
def __init__(self, args):
super(HRCA, self).__init__()
self.p = args.max_article_token
self.q = args.max_question_token
self.a = args.max_option_token
self.m = args.n_choices
self.l = args.hrca_encoding_size
self.k = args.hrca_num_layers
self.fuse_method = args.hrca_fuse_method
self.plus = args.hrca_plus
self.multi_head_attention = MultiHeadAttention(d_model=args.hrca_encoding_size, num_heads=args.hrca_mha_num_heads, dropout_rate=args.hrca_mha_dropout_rate)
self.fuse_linear_x = Linear(self.l, self.l, bias=True)
self.fuse_linear_y = Linear(self.l, self.l, bias=True)
self.fuse_linear_z = Linear(self.l, self.l, bias=True)
if self.fuse_method in ['mul', 'sum']:
self.W = Linear(self.l, 1, bias=False)
elif self.fuse_method == 'cat':
self.W = Linear(3 * self.l, 1, bias=False)
else:
raise Exception(f'Unknown fuse method: {self.fuse_method}')
if args.load_pretrained_model_in_module:
self.pretrained_model = load_transformer_model(model_name=args.hrca_pretrained_model, device=args.pretrained_model_device)
self.pretrained_model.eval()
else:
self.pretrained_model = None
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
def forward(self, P, Q, A, pretrained_model=None):
E_P, E_Q, E_A = self.contextualized_encoding(P, Q, A, pretrained_model=pretrained_model)
O = self.human_reading_comprehension_attention(E_P, E_Q, E_A) # O : (batch_size, N_CHOICES, ?)
L_unactived = self.W(O).squeeze(-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @return E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @return E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
def contextualized_encoding(self, P, Q, A, pretrained_model=None):
batch_size = P['input_ids'].size(0)
size_of_split_choice = (batch_size, self.m, self.a)
A['input_ids'] = A['input_ids'].view(*size_of_split_choice)
A['token_type_ids'] = A['token_type_ids'].view(*size_of_split_choice)
A['attention_mask'] = A['input_ids'].view(*size_of_split_choice)
E_list = list()
for i in range(self.m):
concat_inputs = {'input_ids' : torch.cat([P['input_ids'], Q['input_ids'], A['input_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'token_type_ids' : torch.cat([P['token_type_ids'], Q['token_type_ids'], A['token_type_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'attention_mask' : torch.cat([P['attention_mask'], Q['attention_mask'], A['attention_mask'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
}
E_list.append(pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1) if self.pretrained_model is None else self.pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1))
E = torch.cat(E_list, axis=1) # E : (batch_size, N_CHOICES, max_article_token + max_question_token + max_option_token, hrca_encoding_size)
E_P = E[:, :, :self.p, :] # E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
E_Q = E[:, :, self.p:self.p+self.q, :] # E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
E_A = E[:, :, self.p+self.q:, :] # E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
return E_P.to(DEVICE), E_Q.to(DEVICE), E_A.to(DEVICE)
# @param E_P: (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @param E_Q: (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @param E_A: (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
# @return O : (batch_size, N_CHOICES, ?) where ? could be hrca_encoding_size or 3 * hrca_encoding_size
def human_reading_comprehension_attention(self, E_P, E_Q, E_A):
O_list = list()
for i in range(self.m):
E_P_U, E_Q_U, E_A_U = self._hrca(E_P[:, i, :, :], E_Q[:, i, :, :], E_A[:, i, :, :])
if self.k > 1:
# Stack k layers
for _ in range(self.k - 1):
E_P_U, E_Q_U, E_A_U = self._hrca(E_P_U, E_Q_U, E_A_U)
O_i = self._fuse(E_P_U, E_Q_U, E_A_U) # O_i : (batch_size, ?)
O_list.append(O_i.unsqueeze(1))
O = torch.cat(O_list, axis=1) # O : (batch_size, N_CHOICES, ?)
return O
# @param E_P_U : (batch_size, max_article_token, hrca_encoding_size)
# @param E_Q_U : (batch_size, max_question_token, hrca_encoding_size)
# @param E_A_U : (batch_size, max_option_token, hrca_encoding_size)
# @return E_P_U : (batch_size, max_article_token, hrca_encoding_size)
# @return E_Q_U : (batch_size, max_question_token, hrca_encoding_size)
# @return E_A_U : (batch_size, max_option_token, hrca_encoding_size)
def _hrca(self, E_P_U, E_Q_U, E_A_U):
if self.plus:
# HRCA: Q2Q -> O2Q -> P2O
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_Q_U, values=E_Q_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_Q_U, values=E_Q_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_A_U, values=E_A_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
else:
# HRCA+: Q2Q -> Q2O -> O2O -> O2Q -> O2P -> Q2P -> P2P -> P2Q -> P2O
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_Q_U, values=E_Q_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_A_U, values=E_A_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_A_U, values=E_A_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_Q_U, values=E_Q_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_P_U, values=E_P_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_P_U, values=E_P_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_P_U, values=E_P_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_Q_U, values=E_Q_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_A_U, values=E_A_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
return E_P_U, E_Q_U, E_A_U
# @param x : (batch_size, x_length, hrca_encoding_size)
# @param y : (batch_size, y_length, hrca_encoding_size)
# @param z : (batch_size, z_length, hrca_encoding_size)
# @return : (batch_size, ?) where ? could be hrca_encoding_size or 3 * hrca_encoding_size
def _fuse(self, x, y, z):
x_project = self.fuse_linear_x(x) # x_project : (batch_size, x_length, hrca_encoding_size)
y_project = self.fuse_linear_y(y) # y_project : (batch_size, y_length, hrca_encoding_size)
z_project = self.fuse_linear_z(z) # z_project : (batch_size, z_length, hrca_encoding_size)
x_project_pooled = torch.max(x_project, axis=1)[0] # x_project_pooled : (batch_size, hrca_encoding_size)
y_project_pooled = torch.max(y_project, axis=1)[0] # y_project_pooled : (batch_size, hrca_encoding_size)
z_project_pooled = torch.max(z_project, axis=1)[0] # z_project_pooled : (batch_size, hrca_encoding_size)
if self.fuse_method == 'mul':
return torch.sigmoid(x_project_pooled * y_project_pooled * z_project_pooled) # @return : (batch_size, hrca_encoding_size)
elif self.fuse_method == 'sum':
return torch.sigmoid(x_project_pooled + y_project_pooled + z_project_pooled) # @return : (batch_size, hrca_encoding_size)
elif self.fuse_method == 'cat':
return torch.sigmoid(torch.cat([x_project_pooled, y_project_pooled, z_project_pooled], axis=-1))# @return : (batch_size, 3 * hrca_encoding_size)
else:
raise Exception(f'Unknown fuse method: {self.fuse_method}')
20230312
- 昨天到晚状态跌落到极点,疲乏,虚汗,我甚至怀疑是不是要发烧,这一周五个工作日开了四次会,两次都是晚上开到十点半,昨天更是从早到晚,都没有抽出时间午睡。回去十点倒头就睡,早上六点半起,但是半夜醒了几次,似乎状态未能恢复几分。
- 结果今早寒潮降雨,但是我既然已经准备了今早起跑,补给都准备完毕,无论如何也不愿意就这么放弃,换上背心三分裤硬顶着5℃的寒风细雨,结果5000米就给我干废了。
- 下周日也是同样的时点起跑,无论如何我都想在今天能模拟一次比赛日的场景,所以天气再恶劣也要拼命去冲一次。如此的挫败让我大失所望,我甚至怀疑自己能否真的完赛。
- 最后一周,五个训练日,成败犹未可知。
torchvision.transforms.ToTensor
-
把一个取值范围是 [ 0 , 255 ] [0,255] [0,255]的
PIL.Image或者shape为 ( H , W , C ) (H,W,C) (H,W,C)的numpy.ndarray,转换成shape为 ( C , H , W ) (C,H,W) (C,H,W),取值范围是 [ 0 , 1.0 ] [0,1.0] [0,1.0]的torch.FloadTensor;- 注意会把
channel(大部分图片的channel都是在第三个维度,channel维度值一般为 3 3 3或 4 4 4, 即 R G B \rm RGB RGB或 R G B A \rm RGBA RGBA对应的维度提到了shape的最前面; - 注意该变换并不是直接转为张量, 对于 R G B \rm RGB RGB值的图片型的张量, 观察源码可发现会作除以 255 255 255的归一标准化;
- 不符合上述图片型张量的形式的张量(如输入二维矩阵), 将直接不作任何数值处理直接转为 t o r c h \rm torch torch中的张量;
- 注意会把
-
可以使用
torchvision.transforms.ToPILImage作逆变换, 这两个函数互为反函数;- 这是一个只针对
PIL.Image输入的反函数, 即必然乘以 255 255 255再返回成图片数据类型;
- 这是一个只针对
-
代码示例:
import cv2 import torchvision as tv # torchvision.transforms.ToTensor f = tv.transforms.ToTensor() numpy2tensor = f(np.array([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]])) image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f(image) print(numpy2tensor) print(image.shape) print(type(image2tensor)) print(image2tensor.shape) # torchvision.transforms.ToPILImage f1 = tv.transforms.ToTensor() f2 = tv.transforms.ToPILImage() image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f1(image) tensor2image = f2(image2tensor) print(type(tensor2image)) print(np.asarray(tensor2image))
torchvision.transforms.Normalize
-
这也是个很诡异的函数, 目前没有看出到底是怎么进行标准化的, 两个参数分别为
mean与std;- 我现在看明白了,其实是
x
:
=
(
x
−
mean
)
/
std
x:=(x-\text{mean})/\text{std}
x:=(x−mean)/std,这里的
mean和std是可以对应 c h a n n e l \rm channel channel数来写的
- 我现在看明白了,其实是
x
:
=
(
x
−
mean
)
/
std
x:=(x-\text{mean})/\text{std}
x:=(x−mean)/std,这里的
-
也只能对图片型张量进行处理
-
代码示例:
import torchvision as tv f1 = tv.transforms.ToTensor() f2 = tv.transforms.Normalize([.5], [.5]) image = cv2.imread(r'D:\media\image\wallpaper\1.jpg') image2tensor = f1(image) normal_tensor = f2(image2tensor) print(image.shape) print(image2tensor.shape) print(normal_tensor.shape)
20230313~20230314
- 昨天下午一点开会,又没能睡到午觉。四点补了两个绿豆糕进场。晴朗,10℃,无风,绝佳的天气,结果跑得异常笨重,完全没有两周前的那种轻盈感,将将5000米就顶不下去了,跑得我一头问号,就这臭水平还想把跑进130???太失望了。
- 后来还是冷静了下来,终是我对首马看得太重,谁又能一次就成功呢?急也没有用,现在做的也只有早睡早起,保证睡眠饮食,所以从昨晚起,11点半前必睡,7点起,中午补1小时觉。最后5天我终究不可能强行冲10km以上的长距离,以目前的体能来说,这样的强度后必然需要长时间恢复休息,然而我已经没有时间了。
- 所以今天下午我还是选择跟队练6×1000米间歇,第一组全力冲到3’23"(PB,之前最快到3’25"),仅次于陈嘉伟3’11",最后100米反超了专项练800米的徐瀚韬;后面几组就废了,二三两组掉到3’48"和3’50",第四组间歇了10分钟,又冲回到3’43",第五组摸鱼,最后一组全力冲到3’42",整体来看平均水平仍然不及去年12月(那时每组都能进3’45",而且头尾两组都能进3’30",其实今天还是最后三组陈嘉伟溜了,少了兔子确实很难顶住强度)。
- 给凯爹搞了台打印机,虽然有点笨重,但是男人之间送生日礼物还是实际点儿[偷笑]。
因果推断里面有个比较重要的点是作因果特征分析,其目的是剔出虚假关联。现在常用的一个策略是选取处置变量进行样本加权,来解决处置变量在整体数据中的不平衡问题。具体而言:
w ∗ = arg min i ∑ i = 1 K ∑ m = 1 M i ∥ 1 N 1 i ∑ j : T j i = 1 C m , j i ⋅ w j − 1 N 0 i ∑ j : T j i C m , j i ˆ ⋅ w j ∥ 2 2 w^*=\arg\min_i\sum_{i=1}^K\sum_{m=1}^{M_i}\left\|\frac1{N_1}^i\sum_{j:T_j^i=1}C_{m,j}^i\cdot w_j-\frac1{N_0^i}\sum_{j:T_j^i}C_{}m,j\^i\cdot w_j \right\|_2^2 w∗=argimini=1∑Km=1∑Mi N11ij:Tji=1∑Cm,ji⋅wj−N0i1j:Tji∑Cm,jiˆ⋅wj 22
对应到文本任务中,如果是特征工程类的模型,如one-hot编码的词特征, T j i = 1 T_j^i=1 Tji=1代表当前处置变量(词特征) T i T^i Ti出现在样本 j j j中; T j i = 0 T_j^i=0 Tji=0则代表 T i T^i Ti未出现在样本 j j j中; C m , j i C_{m,j}^i Cm,ji代表当前的处置特征 T i T^i Ti的第 m m m的混杂特征在第 j j j个样本中取值; N 1 i N_1^i N1i代表词特征 T i = 1 T^i=1 Ti=1的样本数目; N 0 i N_0^i N0i代表词特征 T i = 0 T^i=0 Ti=0的样本数目。
这里就衍生出一个推广问题,one-hot的词表示显然是太low了,有没有可能推广到一般的词向量。但是这很难,因为我们是可以解释one-hot词表示每一维的含义的(比如这里就是表示词袋的含义,词是否出现在样本中),但是一般的词向量就没有这种含义,那太过于抽象了,所以至少也是不能称为是样本加权。
其实如果熟悉Gensim里各种语言模型,比如TFIDF,LSI,HDF之类的,会发现除了TFIDF是从词袋模型(即one-hot)上进行计算得到新的词表示,LSI之类的都是在TFIDF的词表示上进一步计算,所以理论上来说是可以将上面这个加权方法推到(至少在)TFIDF这个层面上,此时我们说的因果特征和虚假特征就是非常抽象的概念了,可能是词表示的某几维,而事实上也有关于PLM输出的嵌入的每一维的具体表示含义的研究,即试图去解释词嵌入的每一维表示什么含义。
20230315
- 结果昨晚又被王英林关到十点半之后,刚坚持了两天早睡早起就又被迫破戒。完会跟黄名媛走了一路,因为都住三门路,我也不知道她是否单身,但我感觉练街舞的肯定交际圈很广。怎么说呢,确是喜欢的类型,圆滚滚的脸蛋儿,带些婴儿肥,笑起来直接眯成月牙,还是个川妹子(经常平翘舌不分),谁能不动心呢。可惜大概已经过了那个一见钟情的年纪,地域不同约莫也不会有啥结果。实际点儿cy,女人,只会影响你跑步的速度!
- 晚23:49,我想我可能真的是喜欢上了黄名媛,我对自己真的好失望好失望。今晚又是开会到23点之后(其实是开了一天),结束后我就莫名想等她一起走,在那儿等她跟王英林说了好久。昨晚还只是骑车半路碰到,今天我故意没有去拿车,就是想跟她一起走地下通道回三门路,就这么有些拘谨又有些欣喜地聊了一路。自从上一段已经过了整整两年,这对跑者来说并不是无法承受的孤独,但是当我心里开始有今晚这种念想时,回想以前又对sxy总有那些情愫,我觉得真的是差劲到顶了。
定义混杂:
- E E E与 D D D相关;以 D D D为条件时, E E E与 C C C相关, E E E不在 D D D到 C C C的因果关系路径中。则称 E E E是混杂因子
再说明条件独立和 D D D-分离的概念:
-
三种结构:
- 链式结构: A → B → C A\rightarrow B\rightarrow C A→B→C,在 A A A到 C C C的路径中, B B B称为中介变量。
- 叉式结构: A ← B → C A\leftarrow B\rightarrow C A←B→C,在 A A A到 C C C的路径中, B B B称为混杂变量。
- 对撞结构: A → B ← C A\rightarrow B\leftarrow C A→B←C,在 A A A到 C C C的路径中, B B B称为碰撞变量。
20230316
- 17号0:35,不写点儿心里难受得很。
- 喜提连续三日被王英林拷打到23点之后,昨晚一直到23:30才放人,不过我也是自愿的,王英林知道我要比赛并没有强留,但是我觉得留黄名媛一个人跟王英林对线实在是太残忍了(当然肯定还是有私情的缘故),事实上从结果来看如果我不去push王英林的进度,以他那龟速这本子指定是要流产了。反正我也是打着跟黄名媛一起回三门路的算盘,早睡?不存在的,状态就听天由命吧,反正锡马跑不好还有扬马可以跑,俺又中签了。
- 昨晚还是去队里训练了,因为明天下雨,后天就已经去无锡了,这是最后一练,我请陈嘉伟带我再冲最后一次10000米。我终于又找回了感觉,前5000米还是我带,因为体力充沛,嘉伟5000米过后超上来给我拉住配速,可惜第8个1000米带到了4’05",直接把我带崩了,最后是4’13"的均配跑完了8000米,停了一圈跟嘉伟把最后2000米冲完。我觉得至少八九成的状态是有的,不至于太悲观。
- 前天夜里失眠,很久不失眠了,上次可能还是两年前了,有心事就睡不着,到夜里1点半才睡着,凌晨5点半就醒了,后来就一直睡不着,干脆七点起床算了。
对于叉式结构,具体可以用公式表达:
-
首先根据 A ← B → C A\leftarrow B\rightarrow C A←B→C, p ( a , b , c ) = p ( a ∣ b ) p ( c ∣ b ) p ( b ) p(a,b,c)=p(a|b)p(c|b)p(b) p(a,b,c)=p(a∣b)p(c∣b)p(b)
-
我们求 p ( a , c ) p(a,c) p(a,c),如果 p ( a , c ) = p ( a ) p ( c ) p(a,c)=p(a)p(c) p(a,c)=p(a)p(c),则 A , C A,C A,C是在 B B B条件下独立分布:
-
若 B B B值不确定(未被观测),则:
p ( a , c ) = ∑ b p ( a ∣ b ) p ( c ∣ b ) p ( b ) p(a,c)=\sum_{b}p(a|b)p(c|b)p(b) p(a,c)=b∑p(a∣b)p(c∣b)p(b)
则 A , C A,C A,C不是在 B B B条件下独立分布。 -
若 B B B值确定,则可以知道 B B B取某个 b b b状态的概率为 p ( b ) p(b) p(b),则 b b b条件下 a , c a,c a,c发生的概率为:
p ( a , c ∣ b ) = p ( a , b , c ) p ( b ) = p ( a ∣ b ) p ( c ∣ b ) p(a,c|b)=\frac{p(a,b,c)}{p(b)}=p(a|b)p(c|b) p(a,c∣b)=p(b)p(a,b,c)=p(a∣b)p(c∣b)
满足条件独立。
-
20230317
- 疲乏的一天。昨晚十二点回寝,今早八点半又要出门。一直搞到下午五点,终于把破事给摆平了。但是我并不高兴,因为这意味着似乎也没啥机会再跟黄名媛有啥交集。本来临走时候想问她晚上要不要一起出去吃个饭啥的,毕竟一起忙活近一个月,但是发现她一直跟一个昵称叫Lu’minous的vx好友在聊天(其实我早就有注意到,因为我一直想搞清楚到底是不是单身),而且我也疲惫得很,计划晚上九点多就要睡,明早还要赶高铁。想想真的太猴急,搞不好人家是异地恋,同在屋檐下,以后组会也躲不了要见面,闹得怪尴尬的。
- 然后我发现今天二月廿四,sxy的农历生日。我之前是有想要不等她生日请她吃个饭,毕竟上学期结束一直欠着。但是今天肯定没指望,只能等到下周阳历生日看看情况,总觉得她最近看起来状态不是很好的样子。
- 总之罢了,万事且等锡马结束,为了满足自己那点小心思(真的很可爱呀,可能是我阅历少,但这么多年来能用可爱形容的女生还真不多),这周已经把我这身老骨头都快整散架了。说到底春天是荷尔蒙爆发的季节,多少春心萌动。过了就好,过了就好,谈毛恋爱,省点精力它不香嘛。
- 后来仔细研究了一下她的pyq,远比我想象的要精彩得多,确是异地恋,而且已经有几年了。散了散了,就当是一场梦呗,还好很快就醒了。
对于链式结构,具体可以用公式表达:
-
首先根据 A → B → C A\rightarrow B\rightarrow C A→B→C, p ( a , b , c ) = p ( a ) p ( b ∣ a ) p ( c ∣ b ) p(a,b,c)=p(a)p(b|a)p(c|b) p(a,b,c)=p(a)p(b∣a)p(c∣b)
-
分两种情况:
-
若 B B B值不确定(未被观测),则:
p ( a , c ) = p ( a ) ∑ b p ( b ∣ a ) p ( c ∣ b ) = p ( a ) p ( c ∣ a ) p(a,c)=p(a)\sum_{b}p(b|a)p(c|b)=p(a)p(c|a) p(a,c)=p(a)b∑p(b∣a)p(c∣b)=p(a)p(c∣a)
则 A , C A,C A,C不是在 B B B条件下独立分布。 -
若 B B B值确定:
p ( a , c ∣ b ) = p ( a , b , c ) p ( b ) = p ( a ) p ( b ∣ a ) p ( c ∣ b ) p ( b ) = p ( a ∣ b ) p ( c ∣ b ) p(a,c|b)=\frac{p(a,b,c)}{p(b)}=\frac{p(a)p(b|a)p(c|b)}{p(b)}=p(a|b)p(c|b) p(a,c∣b)=p(b)p(a,b,c)=p(b)p(a)p(b∣a)p(c∣b)=p(a∣b)p(c∣b)
满足条件独立
-
20230318
- 昨晚10点熄灯后心脏跳得厉害,锡马临近,也有因为窥探黄名媛pyq后的胃疼感。一直到快12点才着,5:30又醒,就再也睡不着了。到无锡后补了个下午觉,状态勉强回过来。短短半周失眠了两次,还是不同原因,也是服了我这老六。
- 人呐,总是要在理想与现实间分清界限与寻求平衡,一旦逾越便会自讨苦吃。至少我应该庆幸,这半个多月的高压时光有人陪伴,久违的心动让我很享受,但这并不属于我,当以等价的痛苦来偿还。
- 此页翻过。不管怎样,今天锡马报到的氛围真的太令人太兴奋啦,第一次有一种找到归属、那种跑者圣地的亲切感,许多严肃跑者,追求自己的极限。我本来立的FLAG是1:30:00,但又觉得太难,于是想到可以定1:31:40,均配刚好是4’20"/km,而且凑了个1314。
- 终于,在我第3年的跑步生涯,我即将正式站在马拉松赛道,非常非常激动。多天来我收到了许多田径队朋友以及其他好友的加油,我热爱跑步以及它为我所带来的快乐与满足,尽管我也失去了许多。愿明天我能跑出自己的水平,在半马首战不留遗憾地圆梦,这是首战,或许也是my last war
- 锡马,加油。
这首诗本是第一次失眠后作,现在看来似乎更适合第二次失眠后的心境吧。
《流年》山隐水迢雾朦胧,扁舟一叶探萍踪。
无言何复凭栏意?嫣然回笑花正浓。
一梦一醒一夜终,一叹一咏一枯荣。
歌且不思情何往,但托遗念于悲风。
20230319
- 昨晚只睡着了两个小时,一周失眠三天(昨晚单纯是兴奋),开跑时状态不佳,热身时明显感觉步伐沉重。但是气氛使然,勉强能有八九成气力,然而全浪费在前半程的变速穿插,前半程我跟打了鸡血似的,甚至飙出3’22"配速的分段,但是E组慢摇的人太多了,跟着跑是很轻松,但肯定出不了成绩。后半段明显乏力,但是总归还是成功完赛。
- 晚上回来后再不能顶住,真的要好好睡一觉了。
- 真的累了。
对于对撞结构,具体可以用公式表达:
-
首先根据 A → B ← C A\rightarrow B\leftarrow C A→B←C, p ( a , b , c ) = p ( a ) p ( c ) p ( b ∣ a , c ) p(a,b,c)=p(a)p(c)p(b|a,c) p(a,b,c)=p(a)p(c)p(b∣a,c)
-
同样分两种情况讨论:
-
若 B B B不确定(未观测),由于所有 p ( b ∣ a , c ) p(b|a,c) p(b∣a,c)相加和为一,所以 p ( a , c ) = p ( a ) p ( c ) p(a,c)=p(a)p(c) p(a,c)=p(a)p(c),即条件独立
-
否则 B B B给定,有:
p ( a , c ∣ b ) = p ( a , b , c ) p ( b ) = p ( a ) p ( c ) p ( b ∣ a , c ) p ( c ) p(a,c|b)=\frac{p(a,b,c)}{p(b)}=\frac{p(a)p(c)p(b|a,c)}{p(c)} p(a,c∣b)=p(b)p(a,b,c)=p(c)p(a)p(c)p(b∣a,c)
无法因式分解,因此不是条件独立。
-
20230320~20230321
- 19号晚上回来后再起不能,这可能是这辈子以来最累的一天,出去找了点吃的回来就洗洗睡了,从11点睡到早上8点,完全是自然醒,舒服得要死,中午回来又补了2小时,原地满血复活。
- 锡马净成绩1:42:07,跟预估差不多,半马人数8000,男子排名519,年龄段排名69,总排名601(算上女选手),排名差强人意,虽然比真实水平差了10分钟不止(稳进135,而且大概率能冲到130。142是三年前的水平)。
- 约了sxy,三年了。再不约,可能就…,唉。
使用matplotlib制作mp4或gif动图:
from matplotlib import animation
from IPython.display import HTML
from matplotlib import pyplot as plt
def display_frames_to_video(frames):
# figsize是以英寸为单位,dpi表示每英寸上多少个像素点
plt.figure(figsize=(frames[0].shape[0] / 72, frames[0].shape[1] / 72), dpi=72)
plt.axis('off')
patch = plt.imshow(frames[0])
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=range(len(frames)), interval=50)
# anim.save('cartpole.mp4')
anim.save('cartpole.gif', writer='imagemagick')
HTML(anim.to_jshtml())
display_frames_to_video(frames)
解释:fig是一开始定义好的图形对象(如plt.gcf()),关键是animate函数,这里的frames是一个列表,每个元素是一张RGB图像张量,这里只是简单的把每一帧给扔进patch,也有在一张静态图上不断移动一个点的写法:
import matplotlib.pyplot as plt
%matplotlib inline
line, = ax.plot([0.5], [2.5], marker='o', color='g', markersize=60)
from matplotlib import animation
from IPython.display import HTML
def init():
line.set_data([], [])
return (line, )
def animate(i):
state = state_history[i]
# 根据state确定点的移动坐标
x = state % 3 + 0.5
y = 2.5 - state // 3
line.set_data(x, y)
# 一秒5帧
anim = animation.FuncAnimation(fig, animate, init_func=init,
frames=len(state_history), interval=200, repeat=False)
anim.save('maze_0.gif', writer='imagemagick')
HTML(anim.to_jshtml())
HTML可以在notebook里做出类似播放器的效果。
20230322
- 阴雨绵绵,让人提不起兴致。下午四点多去操场准备养生一会儿。发现东哥居然在练3000米(五月底有个上海市教工运动会),这不趁机给东哥上个强度,穿牛仔裤也得给他好好拿捏一下。
- 东哥目标进14分钟,带他跑出13’09",最后100米轻松绝杀。对我来说只是热身,而对东哥已是极限,只是可惜忘了给东哥来几张表情包。不过他下周还想进13分钟,机会有的是(ಡωಡ)。就怕到时候例训公报私仇,12×400米间歇给我直接干废哈哈。
最近发现一个很强的UP,五道口纳什,CSDN也有博客,全栈算工,真的是太全面了,啥都会,而且大多数面都要比我要精好多,所以准备把他的vlog全部学一遍,真的很有用。
使用meshgrid方法可以实现3D作图的坐标轴控制:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
xs, ys = np.meshgrid(np.arange(-2, 2.01, .01), np.arange(-2, 2.01, .01))
zs = np.exp(-(xs**2+ys**2))
# xs: 401 × 401
# ys: 401 × 401
zs = np.exp(-(xs**2+ys**2)) # zs: 401 × 401
fig = plt.figure(figsize=(16, 12))
ax = fig.add_subplot(111, projection='3d')
surface = ax.plot_surface(xs, ys, zs, cmap=cm.jet)
fig.colorbar(surface)
另一种在jupyter里可交互的作图方式:
from mpl_toolkits.mplot3d import Axes3D
%matplotlib notebook
fig = plt.figure()
ax = Axes3D(fig)
xs, ys = np.meshgrid(np.arange(-2, 2.01, .01), np.arange(-2, 2.01, .01))
# creating the plot
surface = ax.plot_surface(xs, ys, zs, color='green', cmap=plt.get_cmap('rainbow'))
# setting title and labels
ax.set_title("3D plot")
ax.set_xlabel('x-axis')
ax.set_ylabel('y-axis')
ax.set_zlabel('z-axis')
fig.colorbar(surface)
# displaying the plot
plt.show()
20230323
- 晚上例训。3000米乳酸阈跑(with嘉伟,11分整,中途要停一圈,这已经是我的极限了,自测3000米最快能到11’30",今天第一个1000米就被带到3’30",力不能及)+ 3000米放松跑(with东哥,13’39",东哥说他五年前能跑到9’08",超二级水平,太恐怖了,没想到现在垮得这么厉害)+ 2000米追逐+ 2000米冷身,外加4组箭步跳和蛙跳。
- 锡马回来后四天在循序渐进地恢复,现在左胯仍抽痛,用力压会疼,其他地方都已经完全恢复,最近休息得很好,虽然没有拉强度,但是应该状态已经恢复到巅峰了,下周队内会有一次体测,争取把5000米再次跑进20分钟。
- 嘉伟周日要去芜湖跑半马,本来卢星雨是芜湖人,可惜她也垮得很,说可以租个儿子去跑亲子欢乐跑,TM笑死。
- 看了一下栾云平的无锡专场,便宜的位置都卖光了,剩余最低580,90分钟一场确实挺贵滴,小园子倒是便宜得多。因为我一直在想要不要送个生日礼物,或许搞个票是不错的选择,但莫名感觉sxy会不会已非单身。害,庸人自扰。
制作2048的环境,以及pygame渲染:
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@163.sufe.edu.cn
import numpy
import random
from copy import deepcopy
class Env2048:
initialize_proba_for_2 = .9 # Each round with some probability to generate tile 2 at random position
n_initial_tile = 2 # The number of initial tiles in the start
score = 0 # Log the game score
actions = list(range(4)) # {0, 1, 2, 3} -> {U, R, D, L}
def __init__(self, args, is_debug=False):
self.args = deepcopy(args)
self.is_debug = is_debug
self.reset()
# Restart game
def reset(self):
self.grid = numpy.zeros((self.args.order, self.args.order)).astype(numpy.int16)
for _ in range(2):
self.add_tile()
self.mode = 'run'
# Step to next state with some action
def step(self, action):
if self.mode in ['over', 'win']:
return
grid = self.grid.copy() if self.is_debug else self.grid
score = 0
if action == 0:
# Upward 0
for i in range(self.args.order):
score += self.merge_bar(bar=grid[:, i])
elif action == 1:
# Rightwards 1
for i in range(self.args.order):
score += self.merge_bar(bar=grid[i, ::-1])
elif action == 2:
# Downward 2
for i in range(self.args.order):
score += self.merge_bar(bar=grid[::-1, i])
elif action == 3:
# Leftwards 3
for i in range(self.args.order):
score += self.merge_bar(bar=grid[i, :])
if self.is_over():
self.mode = 'over'
if self.is_win():
self.mode = 'win'
self.add_tile()
self.score += score
return score
# Sample the position of some empty tile
def sample_available_position(self):
available_positions = list()
for x in range(self.args.order):
for y in range(self.args.order):
if self.grid[y, x] == 0:
available_positions.append((y, x))
# assert available_positions, f'There is no empty tiles in grid: {self.grid}'
return random.choice(available_positions) if available_positions else None
# Randomly add 1 tile to grid
def add_tile(self):
position = self.sample_available_position()
if position is not None:
y, x = position
self.grid[y, x] = 2 if random.random() < self.initialize_proba_for_2 else 4
# Move one row or one column for merging
def merge_bar(self, bar):
score = 0
bar_length = len(bar)
for i in range(bar_length - 1):
if bar[i] == 0:
for j in range(i + 1, bar_length):
if not bar[j] == 0:
bar[i] = bar[j]
bar[j] = 0
score += 1
break
if bar[i] == 0:
break
for j in range(i + 1, bar_length):
if bar[j] == bar[i]:
bar[i] += bar[j]
score += bar[j]
bar[j] = 0
break
if not bar[j] == 0:
break
return score
# Whether is game over
def is_over(self):
if 0 in self.grid:
# There exist some empty tiles in grid
return False
for y in range(self.args.order - 1):
for x in range(self.args.order - 1):
# There exist some ways to merge tiles
if self.grid[y][x] == self.grid[y][x + 1] or self.grid[y][x] == self.grid[y + 1][x]:
return False
return True
# Whether is game wins
def is_win(self):
return self.args.game_goal in self.grid
# Stringize
def __str__(self):
string = '====================\n'
for row in self.grid:
string += '-' * (5 * self.args.order + 1) + '\n'
for e in row:
string += '|{:4d}'.format(int(e))
string += '|\n'
string += '-' * (5 * self.args.order + 1) + '\n'
string += '==================\n'
return string
20230324~20230325
- 春寒料峭,昨天状态又极度低迷,感觉这几天衣服穿太少给冻着了,有点发烧的征兆,早早睡了一觉又基本恢复过来了。
- 下午例训,全员8×400米间歇,状态不错,能1’15"~1’20"的pace坚持到底,没有不适,最后两组甚至跑到前三,仅次于杨申宇和宋镇均(不得不说宋镇均的话一个标点不能信,第3组跑完跟我说上头了,让我站他前面出发,然后每组都超我,一点不给老学长面子)。再跟队练三周到扬马结束,至少进个135,了却这桩心愿。
- 找工作确是玄学,尤其是近两年,但无论如何,sxy都确是足够优秀了,实话令人艳羡不已,能去中金真的已是天花板。与三年前很像,不过今天我是听众,熟悉的清澈,褪去了些青涩,多了些岁月的蹉跎,以及恍惚间的落差。好多话没能说出口,也不知道两年后我会何去何从,以后还能否再见。然,人生能有这么一段三年多的邂逅,cy,你也该知足了罢。
2048蒙特卡洛代理,利用两个经典的指标进行:
class MonteCarloAgent(BaseAgent):
gamma = 2.8
def __init__(self, args):
super(MonteCarloAgent, self).__init__(args)
self.env = Env2048(self.args, is_debug=False)
# Generate the next action given grid state
def generate_next_action(self, grid):
action_grades = []
n_empty_tiles = self.count_empty_tiles(grid)
if n_empty_tiles >= self.args.order ** 2 / 3:
# There exist so many empty tiles that we can act randomly
if self.args.gather_to_corner == 'ul':
return random.choice([0, 3]), {'grade': 0}
elif self.args.gather_to_corner == 'ur':
return random.choice([0, 1]), {'grade': 0}
elif self.args.gather_to_corner == 'dl':
return random.choice([2, 3]), {'grade': 0}
elif self.args.gather_to_corner == 'dr':
return random.choice([1, 2]), {'grade': 0}
# Simulate
n_simulate = min(max(n_empty_tiles ** 2, 20), 40)
for action_list in itertools.product(self.env.actions, repeat=self.args.montecarlo_search_depth):
candidate_grades = []
for _ in range(n_simulate):
grid_final = self.generate_simulated_grid(grid, action_list)
candidate_grades.append(self.grade_grid(grid_final))
action_grades.append([action_list, min(candidate_grades)])
action_grades = sorted(action_grades, key=(lambda x: [x[1]]))
for action_list, grade in action_grades[::-1]:
self.env.grid = grid.copy()
if not self.env.step(action_list[0]) == 0:
# Return the first action in sorted actions list by grade
return action_list[0], {'grade': grade / n_simulate}
# Revert
self.env.grid = grid.copy()
return action_grades[-1][0][0], {'grade': action_grades[-1][1] / n_simulate}
# Generate the final grid given a grid and a list of simulated actions
def generate_simulated_grid(self, grid, action_list):
env = Env2048(self.args, is_debug=False)
env.grid = grid.copy()
for action in action_list:
env.step(action)
env.add_tile()
return env.grid
# Grade the current grid
def grade_grid(self, grid):
return self.grade_algorithm_1(grid) + self.gamma * self.grade_algorithm_2(grid)
# Count the number of empty tiles in grid
def count_empty_tiles(self, grid):
return numpy.sum(grid == 0)
20230326~20230327
- 昨日休整,去小姨家养了波胃。前晚肚子不适,不知是九鼎轩东西不干净还是一回来就跑高强度间歇的缘故,总之就是不舒服。陈嘉伟首半马顺利完赛,净成绩1:28:26,配速4’11",这还不是完全发挥出来的水平。半马跟嘉伟的差距要小一些,配速差大概在15秒。
- 注册openai账号,打不过就加入呗,openai还不给china和russia提供服务,买了个巴西的虚拟号码才验证通过,梯子又不稳,凌晨搞到一点才弄好。
- 主要是近半个月很多大模型的api都开放了,所以上周主要在追踪前沿,如提示工程,图像的diffusion之类的。其实prompt很早就有提出,那时候还以为只是简单的补全,现在看来真的是坐井观天。LLM和Prompt,这是方法论和工业应用的双重革新,有预感大变革真的要来了。
- 下午晃了十圈,碰到宋镇均在自测5000米,结果这货少跑了一圈,18’32",亏我还长袖长裤、而且没热身就带了他两段。可惜明天临时要汇报,估计要错过队内测试,这么好的状态多想能重开一次20分大关。(说起来一年半前还打开一次20分钟,自己这么久就一点长进都没有,好菜)。
LLM与提示工程之遐想
其实现在看来提示学习的确是革新了传统的预训练方法,那些传统的预训练模型可能很快就要被淘汰,GPT崛起说明预训练根本不需要搞那么多花里胡哨地操作,做自回归就完事了,有种数学里常说的朴素简洁的美。
关于提示,几乎已经可以覆盖所有的NLP任务,虽说现在提示工程看似只是在对一个黑盒子进行不断地试错,没有什么理论依据可言,之前王英林坚持不肯在本子里写提示学习,就是觉得这种东西没有什么科研价值,就一群人在那儿写模板喂给模型,而且很多时候还需要人类来对模型的输出进行反馈。但是从另一个角度来看,提示工程有点类似在对人脑的思维逻辑进行解析,事实上我们也没有办法完全弄明白人脑的运行逻辑,所以提示工程里有很多提示构建的思路,比如思维链(CoT),ReAct,以及生成外部知识模板,甚至将逻辑用代码形式进行提示,其实都是在帮助模型学习推理的能力,但是这种推理能力并不是结构化的,它依然是非结构化的文本组成,你很难说模型到底学习到的是推理能力,还是只是以文本形式呈现的推理过程,抑或说本身推理确实也可以是非结构化的呢,只是人类更偏爱使用结构化的推理形式而已?
这波冲击对NLP是及其巨大,但是随着多模态提示的发展,图像领域可以预见到的很快也会受到冲击,其实diffusion作为一种MC也可以理解是一种自回归,这和文本预训练上的思路是一致的。其实我一开始以为diffusion是以像素点级别进行自回归扩散的,当时觉得这个思路好神奇,但是并不是这么做的,为什么不是这么做呢?比如对于图像补全,感觉上以像素点进行自回归扩散更合理,OR里面会用nuclear norm来进行优化实现图像补全,本身也是基于熵减的思想。
openai补全接口调用:
import openai
import os
import Ipython
from langchain.llms import OpenAI
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_KEY")
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_KEY")
os.environ["SERPART_API_KEY"] = os.getenv("SERPART_API_KEY")
def set_open_params(model='text-davinci-003',
temperature=.7,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0):
openai_params = {}
openai_params['model'] = model
openai_params['temperature'] = temperature
openai_params['max_tokens'] = max_tokens
openai_params['top_p'] = top_p
openai_params['frequency_penalty'] = frequency_penalty
openai_params['presence_penalty'] = presence_penalty
return openai_params
def get_completion(params, prompt):
response = openai.Completion.create(engine=params['model'],
prompt=prompt,
temperature=params['temperature'],
max_tokens=params['max_tokens'],
top_p=params['top_p'],
frequency_penalty-params['frequency_penalty'],
presence_penalty-params['presence_penalty'])
20230328
- 下午组会,错过训练(事后碰到谢震宇问了下,其实东哥根本没来,就没咋练,还好还好,主要状态是挺好,练不了有点可惜)。两天不到把锡马回来一周多看的东西整出来并讲了一遍,颇有所得,从gpt1到gpt4,再到提示工程的技术,以及这个月刚刚开放的各种OpenAI接口,做了一回LLM和AIGC的传教者。从我的角度来说,LLM和AIGC的到来确是令人激动的事情。虽然我们还不能直接无代价的接触到LLM,但只是摸到一点皮毛也足以令人兴奋。
- 会后跟黄名媛回实验楼,在看暑期实习,跟我说加了颜烨,然后这B居然让她去投开发岗,是真TM离谱,颜烨这是人做出来的事儿?
- 21级的时候就来了一个黄名媛,我过了差不多快一年才看到真人。今年进了4个,而且居然有个直博新生,我都以为王英林要退休了,居然还要带博士,这可至少五年,到时候都快70岁。
- 晚上强行想认真跑会儿,之后可能要连着下雨。虽然下午感觉很好,但是到晚上毕竟还是太累了,没睡午觉状态又差,奔着10km去跑结果不到2km就报销了,又断断续续补到5km,说起来还是在扬马备赛期,不论配速,每天还是要把跑量补足。
LLM与提示工程之遐想(二)
提示工程指南:GitHub高星项目
如果说GPT4真就只靠无监督的自回归训练+多任务微调那确实太夸张了,它的训练过程中一定有很多细节没有公开,否则很难想象text-to-SQL以及代码生成等公认的高难度NLP任务就这么被一个说不清道不明的in-context learning一举拿下了。以Text-to-SQL著名的Spider挑战任务为例,上个月刚提出的SOTA模型也超过不了80%的正确率,根本不足以达到应用范畴,但是事实上这也不能在GPT4中测试,因为context太长,除非把Spider的整个数据库扔进去。
即便如此,正如昨天写到的那样,以提示为起点,自回归为方法的LLM&AIGC新方法,抛却了一切花里胡哨的结构化操作,确是一种简单朴素的美。以前总是认为规则、推理是需要用结构化的方式进行表达,比如一阶规则,现在看来自然语言几乎可以概括一切规则。不管你信不信这是不是推理能力,反正LLM就是能推出来。
最后推荐几个图像领域的,从GPT4开始已经可以进行提示生图的操作了,当然这些技术半年前就已经很成熟了,AI绘图早已不是,这么看来,图像还是要比文本要容易一些。我以前也是这么认为,因为文本的精确性要求更高,图像还是有一定容错的。https://civitai.com,Diffusion公式推导
Image Caption(调用Blip模型):
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
device = 'cuda:0'
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base", torch_dtype=torch.float16).to(device)
# processor forward,模型的输入需要经过processor进行预处理
img_inputs = processor([Image.open('./flickr8r-samples/33108590_d685bfe51c.jpg'),
Image.open('./flickr8r-samples/10815824_2997e03d76.jpg')],
return_tensors='pt').to(device, torch.float16)
print(img_inputs['pixel_values'].shape)
out = model.generate(**img_inputs) # 输出结果是一个LongTensor
# 需要用processor解码
# processor.tokenizer.convert_ids_to_tokens(out[0])
captions = processor.decode(out[0], skip_special_tokens=True)
print(captions)
captions = processor.decode(out[1], skip_special_tokens=True)
print(captions)
20230329
- 开始面实习,早上做阿里的行测,智商严重受辱,拿各种小学数学应用,阅读理解还有离谱的图形规律来恶心人。后晚要电面,因为是数算岗,跟近期看的内容不搭嘎,又得刷算法题准备机考,以及把之前写的pyspark和hadoop笔记拿出来复习。就是那种,想、又不想实习的矛盾感。
- 晚饭后准备去操场散会儿步,路上碰见东哥刚练完,告诉我本来上周六3000米已经跑到12’49",结果三天不练又被打回原形。然后卢星雨和丁古丽也在慢跑,想想我也有好几天没有认真跑了,之后又要下雨,晚上状态虽低迷,还是换了衣服鞋子上场拉一拉强度,4000米用时16’04",配速4’01",马马虎虎。
- 说起来,这学期若不是有嘉伟带,我很难两周就重回巅峰。非例训时间里,我一个人训练很难上大强度。以前习惯独自训练,一周也能跑出7个高质量的万米,现在变得越来越依赖随队氛围,就是那种被人认同也认同别人的氛围。然,越是依赖,越是遗憾,早晚会离开这样的欢乐与纯粹。聚少离多,能陪伴一生的人和物是何等的无价珍宝呢。
Legion笔记本,摄像头灯亮,但是显示黑屏问题解决:
摄像头的盖子没掀开阿,如果你发现摄像头最中间是一个红点,那就是被盖住了,看看摄像头上方有个很不起眼的像是滑槽(可以左右滑)的东西,往右边一滑就开了。TM下午搞了半小时,还以为是摄像头驱动坏了,差点准备卸了驱动重装,真是服了。
就特别搞,看网上说联想笔记本摄像头是有物理开关的,我还在想是不是右边那个小孔是开关,用针捅了半天旁边兄弟跟我说那应该是麦克风,我???

20230330
- 晚上例训,跟嘉伟3’54"配速上3000米,我已力竭,于是被嘉伟无情嘲讽,他表示根本没尽兴,才3k就不行了?于是被迫补2组2000米间歇(分别偷懒了大半圈,真心跟不动),休息后8组×32个箭步跳,最后补1组2000米变速。练到胃的一晚,舒服得要死。可是明晚要面,题还没刷完,刷题真是浪费生命,昨晚刷到11点半才回寝,真是无语透顶了,今晚绝不熬夜。
- sxy去了南德,180块vip豪华一排座,属实慕了。讲道理小园子票价还是很亲民的,快乐一天总归比去影院看烂片舒服。
- 我最近又认识了几个跑的还不错的人,大二金融一个(这个要比我强,感觉4分配不在话下),还有今晚认识的一个大四经济(这个应该水平跟我差不多)。其实财大也不算小,想想总归是有些能跑的人,只是缺少号召力把这些人都集中起来,完善现在的训练氛围,长跑水平不见得比交大同济差,可惜我大概是看不到了。
nowcoder个人刷下来链表里感觉最难的是BM5(归并排序K个单链表),还有一些算法说实话思路跟小学奥数题一样,能不能来点不用取巧的算法题,比如什么找两个单链表第一个重合的元素那题,双指针的思路也太离谱了,没见过原题绝对不可能短时间想出来,跟脑筋急转弯似的。
import sys
#设置递归深度
sys.setrecursionlimit(100000)
class Solution:
#两个有序链表合并函数
def Merge2(self, pHead1: ListNode, pHead2: ListNode) -> ListNode:
#一个已经为空了,直接返回另一个
if pHead1 == None:
return pHead2
if pHead2 == None:
return pHead1
#加一个表头
head = ListNode(0)
cur = head
#两个链表都要不为空
while pHead1 and pHead2:
#取较小值的节点
if pHead1.val <= pHead2.val:
cur.next = pHead1
#只移动取值的指针
pHead1 = pHead1.next
else:
cur.next = pHead2
#只移动取值的指针
pHead2 = pHead2.next
#指针后移
cur = cur.next
#哪个链表还有剩,直接连在后面
if pHead1:
cur.next = pHead1
else:
cur.next = pHead2
#返回值去掉表头
return head.next
#划分合并区间函数
def divideMerge(self, lists: List[ListNode], left: int, right: int) -> ListNode:
if left > right :
return None
#从中间分成两段,再将合并好的两段合并
mid = (int)((left + right) / 2)
return self.Merge2(self.divideMerge(lists, left, mid), self.divideMerge(lists, mid + 1, right))
def mergeKLists(self , lists: List[ListNode]) -> ListNode:
#k个链表归并排序
return self.divideMerge(lists, 0, len(lists) - 1)
20230331
- 晚7点阿里面试,面了两个小时,从统计回归问到机器学习,从逻辑回归问到Transformer,又现场考了四道代码题,最后考官表示对我的表现是满意的,并希望很希望我能加入他们的团队。
- 我只准备了两天(而且根本没看这些基础知识,全TM在刷垃圾算法题),硬是靠坚实的基础(臭不要脸一回)全都接下来,可惜sql完全没看,最后一道sql直接缴械,想sql还是在杉数时做的了。其实也有面试官跟我可能熟悉的领域非常相近的缘故,几乎所有问题我都是了解的,就算不知道我也能猜出个大概。
- 时隔三年,又激起了我去实习的欲望。原因这已经很贴近我理想中的工作了,我可能还是不能去做那种尖端产品的开发,太难,而且不确定性太大,保不准哪天就被结构性调整,而且有一说一,这一块国内确实很难追上,因为氛围不对。OpenAI出身是非盈利性组织,那是真正出于爱好和钻研才集合到的一批最炽热的人,方有如今的成就,而工业永远是以利益为目标的,所以永远出现不了OpenAI这种品级的机构。
- 但是数算支持带些深度学习技巧对我来说要容易得多,而且是公司必要且不可或缺的。考官说他对杉数很熟悉,也是看重了我在杉数的那七个多月的经历,团队里也有以前在杉数工作过的人,而我也确实很怀念三年的杉数,那是一群年轻人有福同享,有难同当,没有勾心斗角的时光。
- 然,有得必有失,一天400拿的是很舒服,但我也会失去大部分的自由。我不喜欢被束缚的生活,晚饭后在操场晃悠时又看到卢星雨和丁古丽在跑5000米,而且居然有一个比卢星雨跑得还快的女生,好强,我还以为lxy已经是天花板了,这种充满活力的感觉真好。停三年实习,跑三年步;逃离三年现实,追逐三年梦想,再看自己早已不再年轻,马上就是奔三的人,却仍是孩童样,这是见sxy那天落差感来源,我觉得她已经远比三年前自信成熟了,也许这才是正常的样子吧。
阿里算法岗一面面经回忆(不全):
-
多元线性回归模型中的常用检验?(我答:变量显著性检验、方程显著性检验、异方差检验、多重共线性检验,从几个古典假设入手)
-
多元线性回归模型的OLS估计的解释?(我只回答了矩估计和正规方程组,考官表示还有最大似然和几何角度的解释)
-
对可决系数R方理解?
-
机器学习方法概述?(从逻辑回归到各种树)
-
树模型,GBDT和随机森林的区别(我答Boosting和Bagging,串行和并行)。
-
xgboost的分裂原理?(这个我真不清楚,但是我觉得是可以调的,那些ID3, ID4.5, CART之类的最大熵算法),调参(最大树深,最多叶子,树的数量)及具体场景。
-
xgboost本身自带有避免过拟合的机制,是什么?(这个我也不清楚,我只知道调参,后来好像也搜不到,有知道的吗)
-
lightgbm与xgboost的比较(更快,尤其处理大数据),为什么?(这个我不清楚,但是立刻猜到了应该是采样)
-
这里还问了一个,用树模型是否可以实现单调性?(即x增,y增这种性质,其实我也没太理解,但是肯定是分枝上做一些界限的限制吧)
-
介绍RNN?(略)
-
介绍LSTM中的门,及其为什么这么取名(这个当时我还真忘了,但是刚好开着浏览器就搜了一下三个门,其实就三个式子,还是要稍微熟悉一下,别忘了GRU,下次可能就是这个)
-
RNN的梯度消失与梯度爆炸解释(消失是其中一次是零,爆炸则是太长),及出现该情况时训练会发生什么(梯度消失则不更新,爆炸则乱更新)
-
LSTM的反向传播有什么技巧么?(这个我觉得LSTM其实参数并不多,因为每个Cell是共享参数的,所以我其实不太清楚他想问什么,可能是叠加吧我觉得,大概)
-
Transformer概述(略)
-
Transformer用于时序预测,如果其中有一段没有数据(比如过年期间没有销量),是否可以直接MASK(在文本里面是可以直接MASK的,这很常见,但是时序有特殊性,但是我不能很专业的讲明白,可能要再想清楚点儿)。
-
问了我一些因果推断的东西,因为我在简历里写了,这刚好是我熟悉的,就不多说了。
-
实时机考题(四道):
- pandas题,一个dataframe,A,B,C三个列,现在生成第4个列D,取值B当A=1,取值C当A=0,要求高效(比如处理100万行)
思路,这个给我第一眼我是觉得应该用apply写:
但是要求高效的话,立刻反应过来应该是用向量解:df['D'] = df[['A', 'B', 'C']].apply(lambda x: x[1] if x[0] == 1 else x[2])df['D'] = (df['A'] == 1) * df['B'] + (df['A'] == 0) * df['C'] - 一道简单的哈希表,从list里找到两个相加为target的数的下标,刚好昨天才看过,我诚实地告诉他我刚看过,他也很客气,说就不给我换动态规划了(笑死)。
- 实现Kmeans,封装成类,并且可以继承修改其中的distance算法,这个也不算难,这里额外问了python能否多继承,Java和C++能否多继承的问题。
- 从数据表中筛选出今天的价格比昨天高5%的SKUID,使用SQL/Hive/Progress(我很老实的承认sql很长时间不写了,确实不会写这种比较复杂的,但是pandas我一定会写…)
- pandas题,一个dataframe,A,B,C三个列,现在生成第4个列D,取值B当A=1,取值C当A=0,要求高效(比如处理100万行)
-
最后考官问我还想问他什么,我问了一下他们部门的工作和日常,越发觉得很适合我,我本来跟考官说我很佛系的,过不了也无所谓,现在我又很想进了。考官让好好准备笔试,别考得太烂。
20230401
- 下午队内测试,今天只测立定跳远、立定三级跳、跳远、50米和400米,虽然都是短跨项目,但也顺带试试自己练了这么久,相较本科到底是否提升。结果立定跳居然都不到2米5(本科最远还是能上2米5);立定三级跳完全没练过,所以只能跳6米4,差点进不了坑,跳远倒还行,跳到4米7。跳远考验的是大腿爆发力,显然我是不行的,前两项都是男生中倒二(宋镇均全部垫底,感觉他找不到技巧,立定2米35,三级跳6米17,不过练长跑的爆发力的确是比不过练短跑的),跳远成绩还行,应该是前5。
- 说到底长跑练多了之后肌肉僵硬,弹性不足,确实不适合做这种跳跃项目,陈嘉伟测下来成绩也不好。
- 50米真的拉垮,本科最快还能跑到7秒2,好久不练短跑都不会跑了。主要是不会起跑,如果是慢慢加上去就很符合平时的感觉,但是一下子想把速度加上去就完全找不到步调,然后就保持不了前脚掌跑,居然用后跟跑法冲了50米,而且路线都跑歪了,7秒6,真是废的真实,我觉得自己水平肯定不止于此,但也懒得再测一次了,因为其他人基本都能跑进7秒,再跑一次估计也就7秒整左右的水平。
- 最后400米1’09",意料之中,估计是在70秒左右的水平,还是比较满意的,差不多比一年前提升5秒多,前面冲太猛,后程掉的太厉害了。
关于昨天提到的xgboost自带防止过拟合的机制,我想起来了,他说的是正则项,具体大概是对树深合maxleaf进行惩罚。
重拾SQL:
-
列出所有数据库:
show databases,默认的结果是:information_schema mysql performance_schema sys -
创建新的数据库
cydemo用于示例测试:create database cydemo -
使用
cydemo数据库并展示该数据库中所有的表(此时数据库中没有任何表):use mysql; show tables;
运算符 描述
= 等于
<> 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 !=
> 大于
< 小于
>= 大于等于
<= 小于等于
BETWEEN 在某个范围内
LIKE 搜索某种模式
IN 指定针对某个列的多个可能值
Select * from emp where ename like 'M%';
查询 EMP 表中 Ename 列中有 M 的值,M 为要查询内容中的模糊信息。
% 表示多个字值,_ 下划线表示一个字符;
M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。
%M% : 表示查询包含M的所有内容。
%M_ : 表示查询以M在倒数第二位的所有内容。
20230402~20230403
- 最近大部分时间都花在刷题上,推荐B站一个题讲得挺好的UP灵茶山艾府,全网题量7000+,OMG,怪不得说搞算法竞赛的全是网瘾少年,这大概是真的热爱了吧,反正我是觉得算法题真的无聊,真有天赋应该去搞算法优化和近似算法这类的研究,熟能生巧的东西真的没意思。
- 晚上补了5000米慢跑,风雨欲来。距离扬马只有不到两周,锡马回来之后一直都没有认真跑,上上周是因为刚回来修整了两三天,上周准备面试和笔试。无论如何,这周开始必须养状态,抽时间找陈嘉伟一起拉拉长距离。
- 诸事缠身,总觉得扬马又要凉。害,总不能如意。
判断是否是完全二叉树
- step 1:先判断空树一定是完全二叉树。
- step 2:初始化一个队列辅助层次遍历,将根节点加入。
- step 3:逐渐从队列中弹出元素访问节点,如果遇到某个节点为空,进行标记,代表到了完全二叉树的最下层,若是后续还有访问,则说明提前出现了叶子节点,不符合完全二叉树的性质。
- step 4:否则,继续加入左右子节点进入队列排队,等待访问。
import queue
class Solution:
def isCompleteTree(self , root: TreeNode) -> bool:
# 空树一定是完全二叉树
if not root:
return True
q = queue.Queue()
# 根节点先访问
q.put(root)
# 定义一个首次出现的标记位
flag = False
# 层次遍历
while not q.empty():
sz = q.qsize()
for i in range(sz):
cur = q.get()
# 标记第一次遇到空节点
if not cur:
flag = True
else:
# 后续访问已经遇到空节点了,说明经过了叶子
if flag:
return False
q.put(cur.left)
q.put(cur.right)
return True
20230404
- 从下午两点开会到晚上十点,黄名媛是真tm能讲,一口气讲了两个多小时,水都不喝。晚饭后偷空去跑了2000米+5×400米间歇,2000米配速3’50",间歇圈速1’25",去的时候宋镇均刚跑完14圈变速,东哥也在练间歇。其实今天是有上强度的计划的,实在是无奈之举。明天清明假期,准备找嘉伟出来拉个长距离,赛前十天,该上强度了。
堆石头,leetcode1000,看了大半天终于弄明白了,菜B不会用循环,只会加lru_cache装饰器:
class Solution:
def mergeStones(self, stones, k):
n = len(stones)
if not (n - 1) % (k - 1) == 0:
return False
sum_list = [0] * n
temp = 0
for i in range(n):
temp += stones[i]
sum_list[i] = temp
@lru_cache(None)
def _dp(_i, _j, _t):
if not (_j - _i - _t + 1) % (k - 1) == 0:
return float('inf')
if _i == _j and _t == 1:
return 0
if _t == 1:
if _i == 0:
res = sum_list[_j]
else:
res = sum_list[_j] - sum_list[_i - 1]
return _dp(_i, _j, k) + res
# return min(_dp(_i, _p, 1) + _dp(_p + 1, _j, _t - 1) for _p in range(_i, _j))
return min(_dp(_i, _p, 1) + _dp(_p + 1, _j, _t - 1) for _p in range(_i, _j, k - 1))
return _dp(0, n - 1, 1)
20230405
- 嘉伟这B要出去玩,不跟我练体能。但据我观察,他最近跟袁佩瑶应该又在冷战。那我只好自己跑咯,其实昨晚状态真的特别好,晚上9点半下会甚至还去操场冲了5圈,一点儿不累。结果今天起跑就感觉特别沉重,似乎状态并不好。本来都作了很多准备,最后20’50"跑了个5000米就顶不住,巨不甘心。
- 跑完后宋镇均和卢星雨也来训练。所以跟他们又热身慢跑了6圈,做了些专项训练,补了几圈变速。不服气,准备跟宋镇均一起再测一个5000米,结果三圈多左脚踝抽筋(就是脚踝下面一点刺痛,也不是崴了,反正从来没有过这种疼痛),一用力就疼,实在跑不了,后来疼的连走路都不方便,只能放弃,转而给宋镇均记圈速,希望他能打破自己的PB。最后他19’50"独自完成5000米测试,基本持平前年11月份队内测试的水平。
- 说实话毕竟也练了许久,总归觉得4’00"/km配速跑起来并不吃力。但没有人在前面带,时间久了还是容易顶不下去。我和宋镇均的水平已经停滞太久太久。2021年12月份连续跑出19’59"的5000米,41’25"的10000米,1:32:40的半马,此后我就再也没能突破这三大项的pb,客观原因有很多,但是嘉伟就能从19’30"一路突破到18’16",总是觉得自己仍年轻,肯定还能继续突破,但就是有种力不从心的感觉。
- 4月25日,对我来说是最后一场校运会,16号还有一场半马。最近我也看到不少长跑强手,想必男子5000米必是一场腥风血雨,想进前三很难很难,嘉伟预定冠军,如果李乐康参加亚军也被预定。除了宋镇均外,我看到过的至少就有三个水平与我相当的对手。干完这一票,真就去养老了,以后就每年回扬州跑个半马,不服老还是不行唉,跑不过年轻人了。
我又回想起一些一面的题目答案:
- xgboost自带的防止过拟合机制是他的loss自带了一些正则项(树深,max_leaf)
- 为什么回归loss用MSE,分类任务的loss就用CE呢?分类任务的loss可以用MSE吗?(这个后来查了一些,CE是凸优化,MSE不是凸优化,其实我还是没搞明白,MSE怎么就不是凸优化了,平方不是凸函数吗?还是说对于分类任务的MSE而言,不是凸的?)
- Transformer里怎么处理MASK?这个一般是设置成负无穷,那么就接着问,为什么是设置成负无穷,而不是正无穷,或者是零?(这个的答案是从softmax的角度考虑, e − ∞ = 0 e^{-\infty}=0 e−∞=0)
然后昨天黄名媛作的汇报确实受益颇多,果然是不能小看这些一路考研上来的人,虽然本科院校一般,但是没两把刷子是不可能的。在我认识的硕士里,我觉得她的能力真的算是很强了。
简单记录一些吧:
提示学习除了之前提到过的硬提示(现在的一个主流的形式是CoT,即思维链形式的提示),还有一种称为软提示,其实类似微调,但是不是微调模型的参数,也不是从模型中挑一些参数来微调,而是直接嵌入新的参数进去微调。
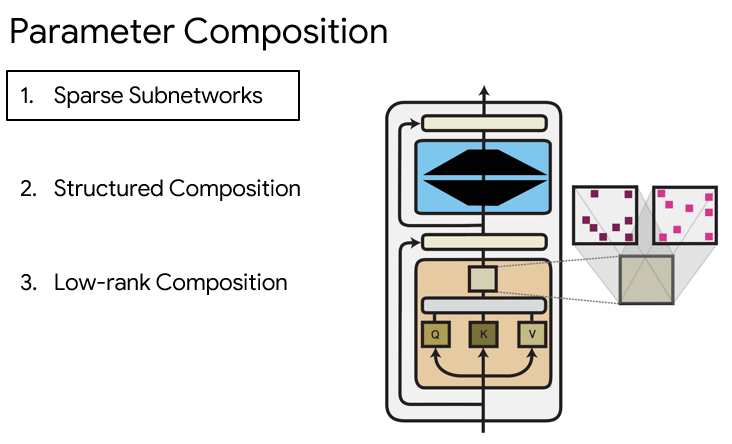
首先软提示的出现算是把传统迁移学习直接捏爆。并且从宏观哲学角度来看,软提示的出现,使得复杂的神经网络开始有了代码的那种模块化属性(即加入的新的参数构成一个模块,该模块是具有迁移能力的),感觉从某种意义上赋予了模型可解释性。从软件工程的角度来看,低耦合,高聚合,模型的训练变得更加灵活。
目前可以将这种模块化的思想分为三种类别:

- 参数组合:向模型参数里加一些新的参数 ϕ \phi ϕ
- 输入组合:直接在输入时加一些新的参数(这就是软提示)
- 函数组合:添加额外的函数(网络层)进去(这个最能体现模块化的本质)

今天先把第一个参数组合看一下:
分为三种:
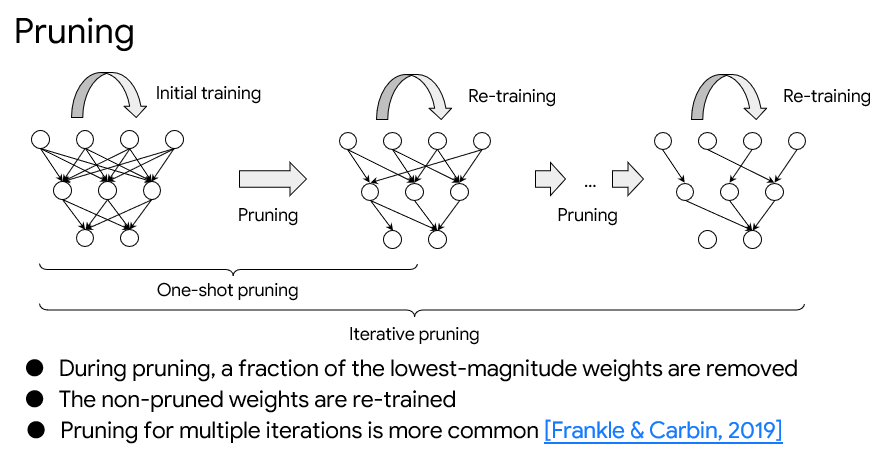
- 稀疏子网络:即新加入的参数
ϕ
\phi
ϕ是稀疏的,那最常见的做法就是剪枝(pruning),具体而言,就是用一个二进制的MASK
b
∈
{
0
,
1
}
∣
θ
∣
{\bf b}\in\{0,1\}^{|\theta|}
b∈{0,1}∣θ∣,来确定是否保留或删除模型中的参数,以此得到一个稀疏的子网络,参考文献是一篇weight magnitude,具体一个剪枝的逻辑如下:
- 结构化组合:TBD
- 低秩组合:TBD
20230406
- 好吧,左脚就是崴了,不过扭得比较轻(应该就是脚落地时没放正,但当时主观上也没感觉),以前脚踝扭伤肿得跟鸡蛋似的,不过那也是高中的事,这么多年没崴过脚昨天就没反应过来,就只是觉得有点刺痛,还强行跑了两段。今天上午走路实在是太不方便,午饭后还是回来老老实实休息。
- 赛前搞这么一出是真的痛苦,还好今天天气不好,休就休一天吧,希望明天基本恢复。跑了这么久,还是第一次扭伤。
- 今天cv大模型也出来了,想往多模态注水也难,杨亦童建议一起去搞理论推导,堆数学。可惜这不是我们组的长项,可能还是觉得在一些方法论上做创新会更好一点。
另一种剪枝的视角:
-
也可以将剪枝视为添加一个task-specific的向量 ϕ \phi ϕ, f θ ′ = f θ + ϕ f'_\theta=f_{\theta+\phi} fθ′=fθ+ϕ,其中 θ \theta θ是原模型的参数,若 b i = 0 b_i=0 bi=0则 ϕ i = 0 \phi_i=0 ϕi=0,即添加的 ϕ \phi ϕ也是一个稀疏参数。
-
那么如果最终的模型参数仍是稀疏的,则 f θ ′ = f θ ∘ b + ϕ f'_\theta=f_{\theta\circ b+\phi} fθ′=fθ∘b+ϕ
状态机买卖股票:(牛客BM82)
class Solution:
def maxProfit(self , prices: List[int]) -> int:
n = len(prices)
#初始化dp为最小
dp = [[-10000] * 5 for i in range(n)]
#第0天不持有状态
dp[0][0] = 0
#第0天持有股票
dp[0][1] = -prices[0]
#状态转移
for i in range(1, n):
dp[i][0] = dp[i - 1][0]
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i])
dp[i][2] = max(dp[i - 1][2], dp[i - 1][1] + prices[i])
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i])
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i])
#选取最大值,可以只操作一次
return max(dp[n - 1][2], max(0, dp[n - 1][4]))
20230407
- 下午自训,左脚还有一点点疼,虽走路已无大碍,但用力跑仍有感觉的。可能是心理作用,但确实跑起来落脚不自然。慢跑3000米,主要在做力量训练,拿了块15kg的片,做10组×30个负重箭步,尽力局,明天大腿要废。
- 虽然比赛临近,但急于求成怕落下更重的伤,确实给整怕了。上周六测跳远时错用左脚起跳,力量不足踉了个大跄都没出事,前天就正常跑圈也能崴到是真无语,从来没有过。
- 下周日程排满,这周末要赶工,扬马又是凶多吉少。不过总归是主场作战,计划下周四跟队最后一练,周五就回家,总归可以好好休息,不至于又老失眠。
SELECT INTO语法:
SELECT *
INTO newtable [IN externaldb]
FROM table1;
SELECT column_name(s)
INTO newtable [IN externaldb]
FROM table1;
例子:
- 复制多个表中的数据插入到新表中:
SELECT Websites.name, access_log.count, access_log.date
INTO WebsitesBackup2016
FROM Websites
LEFT JOIN access_log
ON Websites.id=access_log.site_id;
select into from 和 insert into select 都是用来复制表
两者的主要区别为: select into from 要求目标表不存在,因为在插入时会自动创建;insert into select from 要求目标表存在。
20230408~20230409
- 昨天例训据说是10×400米的间歇,不过东哥没来,估计质量一般。然后王炳杰跟我说他自测了5000米,19’46",我直接震惊,在中金实习了三个月居然还能这么强,去年9月底队内测试时也掉到了20’50",他上周刚从珠江飞回来,这也已经超出我的认知范围,按道理怎么也得恢复半个月才能练回原先水平,这也太夸张了。
- 所以我下午也去自测5000米,结果又是3000米跑崩(菜得真实)。天气太热,而且节奏不对。锡马回来之后一直穿的361°飞飙训练,今天换了竞速鞋Nike Vaporfly,起手步频飙到185,第一个1000米用时不到3’50",我就知道节奏肯定乱了,赶紧调整,第二个1000米掉到4’02",最后3000米用时11’53",实在是坚持不住。本来前天练完力量,大腿就酸痛得很,这太阳又晒得跟盛夏般令人绝望。最后补了4个400米间歇,惨淡收场。
- 不得不服老呀,真是跑不过年轻人。16号扬州天气15~27℃,比今天还要热。到25号校运会肯定更热,而且是下午。为了校运会能跑个好名次,一辈子就这么最后一次,拼了!
提示学习之遐想(三)
传统的NLP研究体系“崩塌”之后,发现许多传统方法都开始为提示学习的prompt服务,比如在Multi-hop QA中,会有将推理类型作为软提示插入模型输入,以及CTG(可控文本生成)中会将生成文本的属性作为软提示插入模型输入。虽然说软提示对于人类来说很难理解,但是目前主流,或者说更有研究价值的方法依然是以软提示为主。
当然不是说硬提示就啥用没有,比如有人提出用强化学习方法来学习硬提示https://aclanthology.org/2022.emnlp-main.222,对应的也有人用QLearning来学习软提示http://arxiv.org/abs/2106.07704,另外根据提示来生成反事实,尤其是多模态领域中的反事实生成,可以有效提升模型鲁棒性,这也是我们组目前所感兴趣的点。
在资源有限的情况下,GPT2是我们能研究的上限。另外基于Prompt的图像合成,Stable Diffusion模型很早就开源了,直接从HuggingFace上clone下来就能用,CompVis/stable-diffusion-v1-4,PC机带4GB的显存+16GB内存,用float16半精度就可以跑通,虽然repository很大,20G,但是确实可行,根据文字的提示,画一张图大概五分钟,相较于openai提供的付费接口,这种开源模型已经相当良心了。
20230410
- 下午四点自训,又是5000米跑崩的一天,热得要命,状态也难以捉摸,补了几组间歇收尾,难受得要死,我只是想跑进20分钟,给自己点儿满足感,现在一个个都猛得离谱。见王炳杰也在练,上次碰面还是寒假前,老王一回来就练这么狠,交流了些近况,他现在在等第二批夏令营,第一批四五月份的应该已经截止了,第二批应该就是暑期那批,不过就只能选清北了,老王这次回来很大原因是为了校运会,前年他1500米和5000米都是差了一两秒错失前三,今年他的野心肯定是很大的,虽然现在我还是萎靡得不行,但是扬马回来后还有一周备赛期,到时候胜负犹未可知。总都想在人生篇章上留下浓墨重彩的一笔,免得将来被单调的色彩给湮没。
- 从上周五开始,天天肝到十点半回寝,王英林就TM指着一只羊薅,明天ddl,后天早上又要笔试,这几天完全没看(我突然想到sql题还没刷,炸了,也不知道会不会考),今晚估计还得熬,烦。
CompVis的Stable Diffusion模型调用:
import torch
from diffusers import StableDiffusionPipeline
model_id = "stable-diffusion-v1-4"
device = "cpu"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float32)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
这里有个注意点,如果是用的cpu的话,那么pipe里必须指定float32,如果用半精度float16,会提示pytorch里的一些函数没有为半精度进行实现。事实上在cpu上确实不太好进行半径度的实现,反正到1.8.0版本的pytorch依然不行,不知道pytorch2之后的版本是否解决了这一问题。如果指定的device是cuda则无所谓,测试下来指定cuda,显存达到4GB即可跑通半精度的pipeline,不过作画质量一般,远远不及openai给的image_completion接口:
这是用半精度stable diffusion画出来的宇航员骑马:

这是用openai接口画出来的宇航员骑马:

前者细节还是差了点
20230411
- 下午汇报完,今天讲得不是很好,Prompt相关工作确实无趣,本来以为找的几篇都是很有用的,结果都是变着花儿在扯淡,第二段很想讲一讲diffusion的,明显这个要有趣的多,可是数学推导在我们组不popular,而且讲完第一段已经过了两个多小时,就很无奈。
- 闷热,雨要又下不下来,下午那么湿热东哥居然让他们练8×400米,宋镇均还主动加量多练了2组,一个个都猛得要死。晚上凉快了下来,但又诡异地冒虚汗,八点去操场自己练了2km+2km+1km+1km的间歇,配速维持在4分整,本来状态差人又多,也没指望能跑很好,最近三天虽然紧凑,但还是逼自己把强度慢慢拉起来,总归是找回了点感觉,嘴上说着无所谓,但还是很想求胜的。
- 东哥今年考核没通过,延到明年上半年,说之前花了六万多托外面公司发论文,结果杂志社倒闭了,直接打水漂,整个人跟热锅上蚂蚁,下午先是问了卢星雨,卢星雨表示她们组发论文写名字得看导师意思,她做不了主。然后我五点下组会来操场时又问我,我觉得倒是可以帮忙水一篇,听说羽队那边的教练就是让李青汶帮忙水了一篇关于羽毛球比赛视频分析的论文,到时候有空看看,反正我们也要发论文,而且这个论文只要学生署一作,老师署二作,按规定教师和学生都可以用来申报成果,听起来是件双赢的事情,而且人工智能最容易水些小领域应用的paper了。
- 明早十点阿里笔试,我本来以为是考算法岗,结果是数据岗(其实投的是数据,但是算法那边觉得更合适就拉过去面掉了,但是笔试安排的还是数据的),所以之前跟颜烨问的东西估计都没啥用了,我想应该是炸了罢。开摆,裸考谁怕谁了还。
Diffusion之遐想
其实跟GAN和VAE这类生成模型是殊途同归的,都是先编码再解码,只是diffusion是通过一种直观的,可解释的增噪过程来实现编码,然后再通过估计逆向过程的均值和方差来实现解码,可解释性要强很多。
训练目标本质是在拟合采样得到的某个时间t的带噪图像 X t X_t Xt的噪声矩阵。DDPM里只是做了这样一件去噪还原的工作。但是在后面的guide diffusion,利用text以及image作为guide来生成隐信号,这个可以参考图文对比学习的CLIP模型的一些工作。
推荐两个把diffusion讲得很明白的两篇博客,其实从去年6月份开始就有很多人在讲diffusion的原理,其实很多都是泛泛而谈,但是真的去琢磨细节又很难看得很明白,所以需要雅俗共赏,把原理到训练以及应用都串通是最关键的。
Diffusion 和Stable Diffusion的数学和工作原理详细解释
20230412
- 笔试炸了,一道SQL和一道编程题写在下面。
- 状态和精神都很低落,东哥把羽毛球队教练陈简妮的那篇paper发给我,果然是李青汶帮忙写的,是关于video summary的,我看了一下这个任务确实研究的人不多,而且也是现在大模型的一个盲点(大模型确实还没有这个能力),但是说实话video summary有两种操作,第一种是浓缩式,就是跟做一张海报来总结视频内容一样,这个其实还挺有技术含量的,因为是一个生成任务,但是他们做的就是从视频里摘取一些clip作为摘要,这个就很简单,因为只要划分一下视频的场景片段就可以了,而且这种标注也是很主观的,人其实也是根据场景转移来切分视频进行标注的,然后从每个片段里抽一些关键帧就可以组成一个summary了。然后挂了个陈简妮的二作,李青汶确实牛批,这可是一篇A刊。所以早上笔试完我跟杨亦童谈了一下这事儿,杨亦童准备做多模态这块,我也觉得似乎是可行的,明天例训(其实也是扬马前最后一练了)准备找东哥谈一下,这个机会很好,东哥和我都有迫切需求,可以试着搞一搞。
- 扬尘天,训练推迟到晚上,以跳绳双摇和间歇训练为主,虽然晚上空气质量好了一点,但我也没有跑长距离的打算,又不想练大腿,怕临赛疼得受不了,索性跳绳练练小腿。我看东哥发了一个他在小区双摇的视频,居然一分钟连续双摇了130×2下,一个没断,我直接震惊了,今天我自己试了一下,最多的一次能连跳45×2下,然后手臂果断麻木到甩不动绳子了。最后一共跳了五百多次双摇,中间穿插跑了一个800米(2’58")+400米(1’19")×2的间歇,心脏都要炸了。
- 最新天气预报16号扬州20~32℃(比上海还热),而且又是E组,锡马有首马带来的肾上腺素加成,这次赛前被折磨得根本兴奋不起来,而且气温太可怕了,很可能跑崩,但我是不可能中途放弃的。
阿里数据笔试题:
SQL题就是汇总快递单销量,以及计算每天相较于前一天单量和营收额的增长率,其实就跟找出比前一天销量高的SQL是一样的,可以参考这个https://zhuanlan.zhihu.com/p/232424418,主要是过了太久又忘了LAG是怎么用的,怎么都调不对。
最后一个算法题很难很难,我到现在都想不出有什么很好的解法:
给定
x
x
x个任务
j
o
b
1
,
.
.
.
,
j
o
b
x
job_1,...,job_x
job1,...,jobx以及它们的负载数组cost,现在给定三台机器,以及一个任务分配列表p,问最少调整几次p中的分配,使得三台机器负载的最大值最小?
比如:cost=[2,3,4,5],p=[1,1,1,2],表示有
4
4
4个任务,负载代价分别是2,3,4,5,然后
p
p
p表示把前三个任务分配给第
1
1
1个机器,最后一个任务分配给第
2
2
2台机器,那么此时三台机器的负载就是
[
9
,
5
,
0
]
[9,5,0]
[9,5,0],最大负载为
9
9
9。
那么答案是最少调配一次,即把第 3 3 3个任务(代价是 4 4 4)分配给第 3 3 3台机器,此时三台机器的负载就是 [ 5 , 5 , 4 ] [5,5,4] [5,5,4],达到了最大负载的最小值(即均衡)。
这道题后来我觉得思路可能是先找出最优解 p ∗ p^* p∗,然后判断从 p p p到 p ∗ p^* p∗需要重新调配几次,但是问题的难点在于可能存在负载代价相同的任务,以及 p ∗ p^* p∗很可能不是唯一的,要找出所有的最优解集,再一个个算代价实在是太难了。
所以我后来也没时间思考,先写了暴力搜索的方法,发现实在是太难写,而且肯定过不了时间空间的限制。只好用贪心的方法,即先找到调度1次的最优解,看看是否比调度0次的要好,如果不好就停止,否则在调度1次的最优解基础上再调度1次,以此类推。这种贪心显然是不可能找到最优解的,但是还是可以通过30%的测试输入。
细想总归最多调配 x x x次,但是这个动态规划好难写,如果把调度 k k k次的最优解当作一个状态,这里麻烦的事情就是最优解不唯一的问题,就比如样例输入,也可以调配两次,即把前两个任务都配给第 3 3 3台机器,结果也是 [ 4 , 5 , 5 ] [4,5,5] [4,5,5],这个动态规划就非常困难?
而且这道题控制了机器的数量,如果机器是 y y y台,就更困难了。这种作业调度负载均衡其实是很常见的问题,算法理论里面是严格的证明了贪心算法是 1 / 2 − a p p r o x 1/2-approx 1/2−approx的,这其实很容易证明,但是这里是必须给出精确算法得出最优解,其实就很困难,而且不仅要得到最优解,还得判断最优解跟目前分配的一个最小distance,如果不用暴力搜索,真的有办法求解吗?
20230413
- 最后一练,4000米全力跑(16’09",with嘉伟)+ 1000米放松过渡 + 3000米全力跑(12’07",with东哥,带他测了一下3000米),两段全力跑间歇不到10分钟,没能达成预定的目标,但还挺满意的。嘉伟昨天跑步机PB10km,37’35",周末的半马他大概率能开125,望尘莫及,校运会5000米他估计能把第二给套圈。
- 收拾东西回扬州。
图像大模型之遐想
关于segment anything,终结了语义分割任务,现在已经可以把清明上河图上那种人挤人,从算法角度很难辨别的实体边界的高难度分割问题都完美解决了。segment anything提供了自测图片的demo网站:https://segment-anything.com/demo
从难度上来说,其实图像处理要比文本处理简单,原因是图像的容错更高,无论是生成还是分类,图像的容忍度明显高于文本,文本一个token的差别会直接导致整体语义的变更,但是图像不会因为一个像素或者super pixel的变化而彻底改变整体语义。
然而现在来看图像领域的大一统模型要更难,因为图像处理任务不像自然语言,完全可以归结到文本生成上,语义分割、Image Caption、Text-to-Image,视频摘要等等,很难用一个统一范式去归结这些问题,但是有一个很tricky的方法,就是把一切问题都归结到自然语言的语义上,然后再根据自然语言的语义去生成所需要的内容。
其实现在来看一切似乎可以归结到语义这个概念上,大模型之后似乎前几年很热的知识图谱就没有那么popular了,但我觉得知识图谱才是语义的集大成者,什么incontext learning还是太浮夸了。
20230414~20230415
- 昨天报到时认识一个从广州过来的爷爷,互相给对方拍了个照片,后来正好也是顺路一起坐公交车。临走时我很好奇他多少岁,我猜是快60岁,没想到居然已经66岁,真是老当益壮,这么不远万里来扬州跑马拉松。不过有一说一,扬州这个半马是双金级别的,在所有半马赛事里算是最高规格的一档了,赛会最好成绩是60分钟以内的,虽然每年都是黑人夺冠。
- 今天骑车把半马路线走了一遍,前6km都是以前上高中常走的路,3km处文昌大桥有一个两三百米的长上坡比较难顶,10km进瘦西湖,里面一段平山堂东路坡度非常大,反正景区里不可能一马平川,上下坡是很频繁的,14km出瘦西湖,最后7km是一条直线,平坦开阔,很适合冲刺,就怕在瘦西湖里上上下下跑崩,浪费最后一段好路线。
- 今天天气非常好,这应该是扬州最美的时节了,褪去了寒冬初春的单调料峭,又没到盛夏的高温蒸煮,瘦西湖里一片桃红柳绿,确是烟花三月鸟语花香、景致嫣然的扬州,说起来我都很多年没有看到这个时节的扬州,人与物都是生机勃勃。sxy前天在滨江道骑行21km,大概是交完论文去看房子的,看得出来精神兴致都很好,心平天地宽,应当祝福。
- 最近休息得很好,主场作战,希望能漂亮地完成这场比赛,go!
LRU缓存实现(BM100)
# 方法:哈希表+双向链表(推荐使用)
# 知识点1:哈希表
# 哈希表是一种根据关键码(key)直接访问值(value)的一种数据结构。而这种直接访问意味着只要知道key就能在O(1)O(1)O(1)时间内得到value,因此哈希表常用来统计频率、快速检验某个元素是否出现过等。
# 知识点2:双向链表
# 双向链表是一种特殊的链表,它除了链表具有的每个节点指向后一个节点的指针外,还拥有一个每个节点指向前一个节点的指针,因此它可以任意向前或者向后访问,每次更改节点连接状态的时候,需要变动两个指针。
# 思路:
# 插入与访问值都是O(1)O(1)O(1),没有任何一种数据结构可以直接做到。
# 于是我们可以想到数据结构的组合:访问O(1)O(1)O(1)很容易想到了哈希表;插入O(1)O(1)O(1)的数据结构有很多,但是如果访问到了这个地方再选择插入,且超出长度要在O(1)O(1)O(1)之内删除,我们可以想到用链表,可以用哈希表的key值对应链表的节点,完成直接访问。但是我们还需要把每次访问的key值节点加入链表头,同时删掉链表尾,所以选择双向链表,便于删除与移动。
# 于是我们的方法就是哈希表+双向链表。
#构建双向链表
class Node:
def __init__(self, key, val):
self.key = key
self.val = val
self.pre = None
self.next = None
class Solution:
def __init__(self):
#双向链表头尾
self.size = 0
self.head = None
self.tail = None
#哈希表记录key值
self.mp = dict()
#将节点插入表头函数
def insertFirst(self, node: Node):
node.pre = self.head
node.next = self.head.next
self.head.next.pre = node
self.head.next = node
#移到表头函数
def moveToHead(self, node: Node):
#已经到了表头
if node.pre == self.head:
return
#将节点断开,取出来
node.pre.next = node.next
node.next.pre = node.pre
#插入第一个前面
self.insertFirst(node)
#删去表尾函数,最近最少使用
def removeLast(self):
#哈希表去掉key
self.mp.pop(self.tail.pre.key)
#断连该节点
self.tail.pre.pre.next = self.tail;
self.tail.pre = self.tail.pre.pre
#插入函数
def set(self, key: int, val: int):
#没有见过这个key,新值加入
if key not in self.mp:
node = Node(key, val)
self.mp[key] = node
#超出大小,移除最后一个
if self.size <= 0:
self.removeLast()
#大小还有剩余
else:
#大小减1
self.size -= 1
#加到链表头
self.insertFirst(node);
#哈希表中已经有了,即链表里也已经有了
else:
self.mp[key].val = val
#访问过后,移到表头
self.moveToHead(self.mp[key])
#获取数据函数
def get(self, key: int) -> int:
#找不到返回-1
res = -1
#哈希表中找到
if key in self.mp:
#获取
res = self.mp[key].val
#访问过后移到表头
self.moveToHead(self.mp[key])
return res
def LRU(self , operators: List[List[int]], k: int) -> List[int]:
res = []
#构建初始化连接
#链表剩余大小
self.size = k
self.head = Node(0, 0)
self.tail = Node(0, 0)
self.head.next = self.tail
self.tail.pre = self.head
#遍历所有操作
for i in range(len(operators)):
op = operators[i]
if op[0] == 1:
#set操作
self.set(op[1], op[2])
else:
#get操作
res.append(self.get(op[1]))
return res
20230416
- 嘉伟上半马1:24:39,真是太太太强了,平均配速四分整,我四分整跑5000米都够呛,他直接整个半马,蚌埠住了。
- 这次扬马旧伤复发,但是我还是坚持走完了全程,人要学会接受遗憾,你自己选的路,走得漂不漂亮并不关键,重要的是一定要走完全程。
- 我真的感触太深了,久违地更新了一篇博客:【日常】我的扬马最后一小时
BM101,LFU缓存设计:
class Solution:
def __init__(self):
self.size = 0
self.mp = dict()
self.freq_mp = dict(collections.deque())
self.min_freq = 0
def update(self, node: Node, key: int, value: int):
freq = node.freq
self.freq_mp[freq].remove(node)
if len(self.freq_mp[freq]) == 0:
self.freq_mp.pop(freq)
if self.min_freq == freq:
self.min_freq += 1
node = Node(freq + 1, key, value)
if freq + 1 not in self.freq_mp:
self.freq_mp[freq + 1] = collections.deque()
self.freq_mp[freq + 1].appendleft(node)
self.mp[key] = self.freq_mp[freq + 1][0]
def set(self, key:int, value: int):
if key in self.mp:
self.update(self.mp[key], key, value)
else:
if self.size == 0:
oldnode = self.freq_mp[self.min_freq].pop()
if len(self.freq_mp[self.min_freq]) == 0:
self.freq_mp.pop(self.min_freq)
self.mp.pop(oldnode.key)
else:
self.size -= 1
self.min_freq = 1
node = Node(1, key, value)
if 1 not in self.freq_mp:
self.freq_mp[1] = collections.deque()
self.freq_mp[1].appendleft(node)
self.mp[key] = self.freq_mp[1][0]
def get(self, key: int) -> int:
res = -1
if key in self.mp:
node = self.mp[key]
res = node.val
self.update(node, key, res)
return res
def LFU(self , operators: List[List[int]], k: int) -> List[int]:
res = []
self.size = k
for i in range(len(operators)):
op = operators[i]
if op[0] == 1:
self.set(op[1], op[2])
else:
res.append(self.get(op[1]))
return resnd(self.get(op[1]))
return res
20230417~20230418
- 原计划是明天回上海,可照目前情况来看没个五六天肯定走不了路,老老实实养伤到周末。昨天东哥跟我说了好多,伤病确是无奈也无可避免的事。
- 托上次面试官的福,明天可以重新考一次笔试。上次考得数据的卷子,估计是不行,好多hive、hadoop还有运维的题,昨天他打电话来说跟领导沟通了一下,面试他是认可的,所以给我争取机会再考一次算法的卷子,那就好好再准备准备咯。
- 扬马重伤,放到以前老妈肯定要锤死我,但是这次确实没有过于责备,因为我自己心态也好了很多,父母毕竟也是全程观摩了比赛,到底是有所感触的。
- 听王炳杰说下午宋镇均又测了一次5000米,19’36",比清明节那天又快了17秒,确实强,我应该不是对手了,但到底贼心不死,跑不了就练腰腹和腿部力量,跟东哥说要保留自己校运会5000米名额,到时候实在不行再DNS,终究还是很想跑,哪怕跑得再烂,因为可能真的是没有下一次了。
图像生成这块现在做得确实太惊艳了,刷B站天天能看到新的工具和模型,都来不及一个个尝试了。有点想转行搞cv了,又怕基础差做不好,只能看杨亦童能不能带我飞一把了。像现在流行的LoRA调优,虽然看起来这方法也没什么了不起的,实现起来也不难,但是在图像大模型上的效果确实很好,现在很多风格转换模型做得太强了,感觉这个是动画专业比较关注的,以前说有人体动作捕捉来建模3D,可能有一些现成的工具,现在直接模型一跑就能用,效果还贼好。
但是很多人都说AI画不好手,这个就是细节问题,可能还是缺少对手部特征的建模,想想人脸识别都已经成熟了多少年了,手部其实肯定也是有特征可以挖掘的,但是可能做得比较少。而且图像本身相对于文本来说容错性更高,细节上做得不好其实也不会太影响整体效果,不过stable diffusion最近似乎已经有了专门针对画手的插件和微调方法。
Python基础知识查缺补漏(算法笔试里的一些坑爹考点)
- 继承与多继承
class A:
pass
class B(A):
pass
class C(B):
pass
print(issubclass(B, A)) # True
print(issubclass(C, B)) # True
print(issubclass(C, A)) # True
print(issubclass(C, (A, B))) # True
class B():
pass
class D(A, B): # 注意这里如果B是A的子类,那么是不可以这样多继承,不过A和B没有继承关系,就可以多继承
pass
print(issubclass(D, (A, B))) # True
- 多装饰器
def a(f):
print(1)
def b():
print(2)
f()
print(3)
return b
def c(f):
print(4)
def d():
print(5)
f()
print(6)
return d
@c
@a
def e():
print(7)
e() # 1 4 5 2 7 3 6
20230419
这次笔试又是坑爹,选择题可能相对比较有把握,但是编程题又吃瘪了。第一题10分是送分,第二题20分找二叉树上长度为连续4个节点(即长度为3的路径)构成回文字符串的路径总数,我没想到什么好办法,先用BFS对每个点穷举以它开始的所有路径,将所有长度为3的路径存储到paths中,再依次判断是否回文,最后对总数除以2(因为一条路径被重复计算了两次,即头到尾和尾到头)。
后来想了想应该这么解,回文字符串意味着中间两个字符一定相同,所以应该是先依次遍历每个点,看看它的邻接点是否跟它相同,如果不同就直接不统计了。这样应该是不会超时的,最后只能通过40%的用例,炸了。
然后最后一题25分其实特别简单(早知道就先做了,第一眼看完以为挺难,所以想还是把第二题改好通过所有测试再说,最后怎么改都不行,因为用了穷举,复杂度怎么都过不了,除非重写算法,所以还是放弃,结果发现最后一题递推特别简单,肠子都悔青了),找长度为 n n n的字符串(由全体小写字母 a a a~ z z z构成)的逆序数总和,比如 n = 2 n=2 n=2时结果是 325 325 325(即 C 26 2 C_{26}^2 C262)。其实递推很好写:
f ( n ) = 26 f ( n − 1 ) + ( 1 + 2 + 3 + . . . + 25 ) × ( n − 1 ) × 2 6 n − 2 f(n)=26f(n-1) + (1+2+3+...+25)\times (n - 1)\times 26^{n-2} f(n)=26f(n−1)+(1+2+3+...+25)×(n−1)×26n−2
意思就是说,长度为 n − 1 n-1 n−1的字符串一共有 2 6 n − 1 26^{n-1} 26n−1个,总字符数 ( n − 1 ) ⋅ 2 6 n − 1 (n-1)\cdot 26^{n-1} (n−1)⋅26n−1个,每个字母当然出现字数相同,即每个字母出现 ( n − 1 ) × 2 6 n − 2 (n-1)\times26^{n-2} (n−1)×26n−2次,那么就好办了。
- 如果在长度为 n − 1 n-1 n−1的字符串前面加一个 a a a,不会影响逆序数总和,因此以 a a a开头的长度为 n n n的字符串的逆序数总和为 f ( n − 1 ) f(n-1) f(n−1)
- 如果在长度为 n − 1 n-1 n−1的字符串前面加一个 b b b,因为在 n − 1 n-1 n−1的情况下, a a a出现了 ( n − 1 ) × 2 6 n − 2 (n-1)\times26^{n-2} (n−1)×26n−2次,那么逆序数总和增加了 ( n − 1 ) × 2 6 n − 2 (n-1)\times26^{n-2} (n−1)×26n−2个,即 f ( n − 1 ) + ( n − 1 ) × 2 6 n − 2 f(n-1)+(n-1)\times26^{n-2} f(n−1)+(n−1)×26n−2
- 如果在长度为 n − 1 n-1 n−1的字符串前面加一个 c c c,因为在 n − 1 n-1 n−1的情况下, a a a和 b b b一共出现了 2 × ( n − 1 ) × 2 6 n − 2 2\times (n-1)\times26^{n-2} 2×(n−1)×26n−2次,那么逆序数总和增加了 ( n − 1 ) × 2 6 n − 2 (n-1)\times26^{n-2} (n−1)×26n−2个,即 f ( n − 1 ) + 2 × ( n − 1 ) × 2 6 n − 2 f(n-1)+2\times (n-1)\times26^{n-2} f(n−1)+2×(n−1)×26n−2
同理可以推到 z z z
问题是这里题目给的 n n n的范围是 2 ≤ n ≤ 1 0 12 2\le n\le 10^{12} 2≤n≤1012,最后时间太紧只能写了个递归函数,直接超出最大深度,来不及写循环一个个推上去的了,难受。
20230420
- 阿里二面来得是如此迅速,算法笔试估计也就是60分出头,本来还是不报以太大希望的。这次来得是数据算法部门的主管(名字叫马学彬,年龄看起来大概35~40岁),级别肯定比一面的那个算法产品经理高。开头先聊了一下最近主流的chatGPT的话题,这是我很熟悉的,因为我这两个月都在追踪前沿的工作,相互分享了一些对prompt与大模型的研究看法、以及国内的机会所在。言归正传,后面他主要就是问我因果推断与多模态的东西,以及我在杉数实习的那段做的事情,还好我吃晚饭的时候尽力回想了一下,毕竟那是三年前的事情了。最后他还是让我问了他一些问题,我趁机了解了一下阿里里面数据科学和数据研发的工作有什么区别,个人感觉二面应该问题不大,但是后面肯定还有三面和HR面,总之就是很烦就对了。
- 总结,一面偏基础理论知识和编程能力,二面偏实践考察,三面还不知道要问啥,无所谓了,我也懒得去问颜烨,相信自己的能力才行,这三年不做实习也没面试过,尤其最近伤病情绪也有些低落,不自信了。
- 99.99%的概率跑不了校运会5000米。4天过去了,脚上的肿块还没有完全消去,虽然走路的痛感并不是很强烈(昨天去拍了X光片,骨头没事,万幸,但这次确实伤得太重了),但是用力的话还是刺痛,我估计到周末能勉强正常走路,25号无论如何都不可能跑得起来,真的好难受好难受,扬马没能跑出理想成绩,还错失了校运会,到头来竹篮打水一场空。我也知道如果不想以后旧伤复发,这次无论如何都要彻底恢复好,然而再等恢复,又是要从头再来练。
- 也许是这学期回来练得太狠,所以三年多以来第一次伤得这么重,或许已经到了身体的极限,虽然不愿意承认,但是我真的已经不再那么年轻了【苦涩】。
清华推出的openprompt开源包可以轻松的在本地使用prompt,目前gpt2是可以用的,非常好!!!但是用之前应该还是要微调一下。
GitHub地址:https://github.com/thunlp/OpenPrompt
from openprompt.data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]
20230421~20230423
- 下午三点到学校,从周五开始左脚基本上没有痛感,以为自己又行了,今天出门走了两步还是有些抽痛,而且要比14号回扬州那天更疼些,试着跑两步,完全不行,校运会确定无望,虽然早有预料,但是到了这前两天还是没能有奇迹发生,有种无力感,无法改变现实。这次确实伤得太重了,但也没什么好后悔的。
- 离校一周,武川门多了个外卖柜,以及校内多了很多共享雨伞的点,回来的时候操场上在排练校运会开幕式,有种恍如隔世的感觉。
- 东哥发烧了,不知道是不是新冠,在家也躺了两三天。李乐康昨天参加静安女子半马(我也不知道为毛他要去报女子半马),1:32:09完赛,确实要比我强。不知道他5000米报上没,反正东哥是不待见他,肯定不会给他开后门的。如果没报上,估计这次宋镇均就能如愿前三了。
- 人呐,总是这样跌跌撞撞地走着,梦想每次都看似触手可得却又如此遥不可及。但也总要有一个目标,才能活得更有激情一些呀。没有低谷的忍耐与煎熬,就享受不到圆梦时的欣然与畅快,路还很长,就这样慢慢地向前走吧。
目前LoRA应该是diffusion模型里最主流的调优方法。其实原理特别简单,就是做了一个稀疏映射,而且事实上Adapter Tuning,Soft Prompt还有LoRA这几个概念的原理,都是特别相似的。之前黄名媛是有介绍过具体的操作,有点类似自编码的方法,就是映射到隐层再映射回来。
LCS的两种写法:
# 最长递增子序列
y_list_sort_by_x_index = [0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15]
n = len(y_list_sort_by_x_index)
def dfs(k, cur_max):
# 表示从索引k开始,当前已经拿到的递增序列最大值为cur_max的最大子序列长度
if k == n:
return 0
l = k
while l < n and y_list_sort_by_x_index[l] <= cur_max:
l += 1
if l == n:
return 0
# 取第l个与不取
res = max(dfs(l + 1, y_list_sort_by_x_index[l]) + 1, dfs(l + 1, cur_max))
return res
print(dfs(0, -1))
def dfs(i):
res = 0
for j in range(i):
if y_list_sort_by_x_index[j] < y_list_sort_by_x_index[i]:
res = max(res, dfs(j))
return res + 1
print(max(dfs(i) for i in range(n)))
20230424~20230425
- 直到下午5000米赛前一小时,我下定决心参赛,最终20’56"排名第五安全完赛。万幸,没有二次受伤。
- 早上嘉伟1500米断档式冠军,4’42"(去年市运会是4’40",这次因为他是一骑绝尘没有参照物,所以算是正常发挥)。炳杰5’05"49险胜拿到第二(第三5’05"81,让他如愿了)。下午5000米前三是陈嘉伟(18’31"),宋镇均(18’51",超级成绩,大幅pb),李乐康(19’06",这次他是吃瘪了,本以为稳拿亚军,我赛前屡次提醒他宋镇均很猛,他万万没想到宋竟然这么猛)。
- 中午在实验室思想斗争了很久很久,首先我已经整整一周没有训练,前五天连家门都没有出过,每天只能在床上进行简单的腰腹训练,有氧水平暴跌,即便参赛也很难跑出正常水平;其次,脚伤未愈,走路尚且瘸拐,每天早上起来是最疼的时候;最后,老妈三申五令禁止我跑这场5000米。
- 两点进场,忽然有那种无论如何一定要参赛的欲望。于是喷云南白药,又拿肌贴给左脚打了绷带,可是热完身脚又疼了,就跟扬马赛前如出一辙,袁佩瑶一直在旁边说是那是幻觉,我多么希望真的是幻觉。第一个1000米跟住了第一集团,用时3’42",我居然没有感觉很累,应该是真的太兴奋了(嘉伟此时从宋镇均身后率先冲出第一集团);第二个1000米用时3’55",此时嘉伟、镇均、乐康已经把后面的人甩开一段距离,我和刘峻宇位列四五;第三个1000米用时4’08",此时我已经明显感觉体力不支,前面毕竟跑得太快了;第四个1000米彻底崩盘,掉出了4分半,刘峻宇也把我甩开;倒数第三圈被嘉伟套圈,我奋力大喊嘉伟牛逼,倒数第二圈被宋镇均和李乐康套圈,说实话5000米被人套圈是很丢人的事,但是赶鸭子上架面对这种情况也是无能为力。
- 不过确实很高兴,在每一圈的每个100米,都能听到有人在为我加油(曹阳哥加油!!),起点处有王炳杰和顾紫阳,第一个弯道处有李婷玉,第二个弯道(终点)有卢星雨和吴林旺,第三个弯道有袁佩瑶(虽然她是专门来给嘉伟助威的哈哈哈,我只是顺便蹭一下)。前三每个人套我圈时我也都竭尽全力为他们喊出加油,因为我已经无所谓成绩,能看到有比我更强的人出现总是很高兴的(今年前三全部超过上一届校运会冠军王兴耀的成绩)。
- 那么,一切就到此谢幕,我已了却所有遗憾,开始认真做事吧。
总觉得wandb没什么特别的用处,但还是记录一下用法:
import os
# os.environ['WANDB_API_KEY'] = ''
os.environ['WANDB_MODE'] = 'online'
import wandb
wandb.init(project='wandb-demo-0425')
config = wandb.config
# WandB – Config is a variable that holds and saves hyperparameters and inputs
config = wandb.config # Initialize config
config.batch_size = 64 # input batch size for training (default: 64)
config.test_batch_size = 32 # input batch size for testing (default: 1000)
config.epochs = 30 # number of epochs to train (default: 10)
config.lr = 1e-3 # learning rate (default: 0.01)
config.momentum = 0.9 # SGD momentum (default: 0.5)
config.weight_decay = 5e-4
config.no_cuda = False # disables CUDA training
config.seed = 42 # random seed (default: 42)
config.log_interval = 10 # how many batches to wait before logging training status
use_cuda = not config.no_cuda and torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
print(device)
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
print(kwargs)
import torch
use_cuda = not config.no_cuda and torch.cuda.is_available()
device = torch.device('cuda'if use_cuda else 'cpu')
print(device)
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
print(kwargs)
# Set random seeds and deterministic pytorch for reproducibility
# random.seed(config.seed) # python random seed
torch.manual_seed(config.seed) # pytorch random seed
# numpy.random.seed(config.seed) # numpy random seed
torch.backends.cudnn.deterministic = True
# Load the dataset: We're training our CNN on CIFAR10 (https://www.cs.toronto.edu/~kriz/cifar.html)
# First we define the tranformations to apply to our images
# Initialize our model, recursively go over all modules and convert their parameters and buffers to CUDA tensors (if device is set to cuda)
optimizer = torch.optim.SGD(model.parameters(), lr=config.lr, momentum=config.momentum, weight_decay=config.weight_decay)
criterion = nn.CrossEntropyLoss()
# WandB – wandb.watch() automatically fetches all layer dimensions, gradients, model parameters and logs them automatically to your dashboard.
# Using log="all" log histograms of parameter values in addition to gradients
wandb.watch(model, log="all")
for epoch in range(1, config.epochs + 1):
train_loss, train_acc, train_errors = train(train_loader, model, criterion, optimizer, device)
wandb.log({"train_loss": train_loss, "train_acc": train_acc, "train_errors": train_errors})
# test_dataloader, model, criterion, device, classes
example_images, test_loss, test_acc, test_errors = test(test_loader, model, criterion, device, classes)
wandb.log({'example_images': example_images, 'test_loss': test_loss, 'test_acc': test_acc, 'test_errors': test_errors})
print()
print(f'{datetime.now()}, epoch: {epoch}, train_loss: {train_loss:.4f}, train_acc: {train_acc:.2f}, test_loss: {test_loss:.4f}, test_acc: {test_acc:.2f}')
print()
另外最近清华开源的openprompt很关键,gpt2也可以直接接入进行提示学习。
20230426~20230427
- 多线程并进。东哥又阳了,发烧到躺床上休息,但还是不忘来追我paper的进度,他是真的很急,出不了paper他就要非升即走了,唉,好残酷的说。
- 伤基本上好了,我发现至少现在这个年龄还是用进废退,之前居家休息的时候,久坐不动腿就会疼,但是这两天慢慢活动起来就好很多了,今晚还是跟队浅练了一下,5月7号有一个迷你铁人三项的比赛(200米游泳+6km骑车+2km跑步,这个量真的很小,快的话30分钟就能完赛),要凑一个6人的队伍,有点想参加但是又怕不会游泳(其实很久以前是学过游泳的,但是那是十几年前的事了,我也不知道现在自己还会不会游)。
- 台湾大学李宏毅老师的公开课视频真的很好,这是我看到现在讲得最清楚的了,李老师是在油管发视频,B站陆续有人在搬运,课程slide没有公开,不过有人给他做了整理(https://github.com/Fafa-DL/Lhy_Machine_Learning),2023年讲得都是现在主流的大模型原理,非常受用。
今天跟chatGPT对线了一下(其实是在给开题整素材),发现它确实能做阅读理解题,而且做得还挺好,但是依然是可以找到一些方法来confuse它的:
下面是给它测试一道RACE里的单项选择题的对话:
2023/4/27 18:44:24 我
Please read the following article and answer my question.
2023/4/27 18:44:24 AI
Sure, please provide the article for me to read.
2023/4/27 18:44:32 我
My husband is a born shopper. He loves to look at things and to touch them. He likes to compare prices between the same items in different shops. He would never think of buying anything without looking around in several different shops. On the other hand, I'm not a shopper. I think shopping is boring and unpleasant. If I like something and I have enough money to take it, I buy it at once. I never look around for a good price or a better deal. Of course my husband and I never go shopping together. Doing shopping together would be too painful for both of us. When it comes to shopping, we go our different ways.nSometimes I ask my son Jimmy to buy some food in the shop not far from our home. But he is always absent-minded. This was his story.nOne day I said to him, " I hope you won't forget what I have told you to buy." " No," said Jimmy. "I won't forget. You want three oranges , six eggs and a pound of meat."nHe went running down the street to the shop. As he ran, he said to himself over and over again, "three oranges , six eggs and a pound of meat."nIn the beginning he remembered everything but he stopped several times. Once he saw two men fighting outside a clothes shop until a policeman stopped them. One of them was badly hurt. Then he stopped to give ten cents to a beggar. Then he met some of his friends and he played with them for a while. When he reached the shop, he had forgotten everything except six eggs.nAs he walked home, his face became sadder and sadder. When he saw me he said, "I'm sorry, Mum. I have forgotten to buy oranges and the meat. I only remembered to buy six eggs, but I've dropped three of them."
2023/4/27 18:44:32 AI
What is the main idea of the story?
2023/4/27 18:46:17 我
The question is why the husband likes shopping?
2023/4/27 18:46:17 AI
Based on the provided article, the reason why the husband likes shopping is not explicitly stated.
2023/4/27 18:46:55 我
OK, I will give your four options. You try finding the possible answer in them.
2023/4/27 18:46:55 AI
Sure, I'll do my best to identify the most likely option based on the article.
2023/4/27 18:47:34 我
A. he has much money
B. he likes the shops
C. he likes to compare the prices between the same items
D. he has nothing to do but shopping
2023/4/27 18:47:34 AI
Based on the article, the most likely reason why the husband likes shopping is C. he likes to compare the prices between the same items. The article states that he enjoys comparing prices and finding the best deals, which suggests that he likes analyzing the value of items and finding the most cost-effective options. The other options, such as having much money, liking the shops, or having nothing to do but shopping, are not supported by the information in the article.
可以发现如果不给它选项,它也不能很好的给出答案,但是给了四个选项后,它确实找到了正确答案,而且推理过程是很完美的。
后来测了另外一道对抗测试题:
I am 6 years old and my sister's age is half of mine. How old is my sister when I am 70 years old ?
2023/4/27 18:51:15 AI
If you are currently 6 years old and your sister's age is half of yours, then your sister's age would be 3 years old.
To find your sister's age when you turn 70 years old, first calculate how many years will pass until then.
70 years old - 6 years old = 64 years
Next, since your sister's age is half of yours, you can simply multiply the number of years that will pass by 2 to find her age.
64 years x 2 = 128 years old
Therefore, your sister will be 128 years old when you are 70 years old. However, please note that this is simply a mathematical calculation based on the information given, and it assumes that your sister lives to be that age.
2023/4/27 19:08:39 我
Why not think step by step?
2023/4/27 19:08:39 AI
Sure, we can approach the problem step by step.
You are currently 6 years old, and your sister's age is half of yours, which means your sister is 6 / 2 = 3 years old.
Now, let's find out how many years will pass before you turn 70.
70 years old - 6 years old = 64 years.
So you have 64 years before you turn 70.
Since your sister's age is half of yours, we can assume that this relationship will remain the same and your sister's age will always be half of yours. Therefore, when you turn 70, your sister will be:
70 years old - 6 years old = 64 years old
64 years old / 2 = 32 years old
So, when you turn 70 years old, your sister will be 32 years old.
这个就很有趣了,我问的是我6岁,我妹妹是我一半的岁数,那么我70岁时,我妹妹多少岁。第一次它给出了非常扯淡的128岁,推理过程先还挺合理,后面就很离谱了。然后我让他再想想,它又给出了32岁的答案。其实这是一个经典的测试题,以前一般认为AI会给出35岁的答案,现在它确实避开了这种greedy的答案,但是给出的推理过程仍然不对。
20230428~20230503
- 五一假期,老爸老妈出去玩了三天,我现在是越来越羡慕他俩了。老妈跟我说,现在不能老想着孩子,得自己享受享受了。反正五一是不可能回去的,所以我只能跟老表在上海兜了一大圈。
- 其实1号下午就已经回学校了,但是事情不太做不进去。这两天特别热,将就着慢慢在恢复着跑,其实脚确还是没有完全好,今天下午穿361飞飙试跑了3000米后左脚又疼得没法跑,我感觉就是鞋子得问题,校运会那天穿耐克的next%就是没事,感觉飞飙在足弓这边有点挤。
- 写了一个用来测chatGPT对RACE阅读理解题的测试的爬虫,现在感觉很稳定,但是要测完所有的题目估计要十几天。chatGPT对这些初高中的英文阅读理解题的正确率非常高,目前出错的一些稍微拉出来看了一下,发现很多属于是article里的事实与实际不相符导致的。另外今天我又测了一下上次的年龄问题,这次gpt居然能答对了,我没有修改prompt,依然使用的是相同的询问方式,到底是模型自己在进化,还是说有人工在背后自动调整?
年龄问题答对的推理过程(这次确实完全正确了):
Human:
I am 6 years old and my sister's age is half of mine. How old is my sister when I am 70 years old ?
AI:
If you are currently 6 years old and your sister's age is half of yours, then she is 3 years old. \n\nTo find out how old your sister will be when you are 70 years old, you need to calculate the age difference between 70 and your current age, which is 64 years. \n\nSince your sister is currently 3 years old, you simply need to add 64 years to her age to find out how old she will be when you are 70. \n\nTherefore, your sister will be 67 years old when you are 70 years old.
另外挂一下爬虫代码,这个是清华那边的人搞的一个gpt接口平台(https://www.13042332817.top/chat-research#/home),主要靠志愿者捐助资金以及OpenAI的api-key搭建起来的,性能很好,速度也很快:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# https://www.13042332817.top/chat-research#/home
import os
import json
import time
import pandas
import requests
headers = """Host: www.13042332817.top
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Referer: https://www.13042332817.top/chat-research
Content-Type: text/plain
Access-Control-Allow-Origin: *
Content-Length: 1783
Origin: https://www.13042332817.top
Connection: keep-alive
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin"""
msg_url = 'https://www.13042332817.top/message'
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
def request_single_choice_question_answer(article, question, options):
content = f"""Here I will provide an article and a question for you to answer, you need to choose the best answer in the options provided.\n\nArticle: {article}\n\nQuestion: {question}\n\n"""
for i in range(len(options)):
content += f'{alphabets[i]}. {options[i]}\n'
data_dict = {"message":[{"role":"user","content": content}],"mode":"v3.5"}
data = json.dumps(data_dict)
response = requests.post(msg_url, data=data, headers=headers_to_dict(headers))
return response.text
def run():
DATA_DIR = '../multichoice/data'
DATASET_DIR = os.path.join(DATA_DIR, 'dataset')
RACE_JSON_PATH_SUMMARY = {'train' : {'high': os.path.join(DATASET_DIR, 'RACE', 'train', 'high'), 'middle': os.path.join(DATASET_DIR, 'RACE', 'train', 'middle')},
'dev' : {'high': os.path.join(DATASET_DIR, 'RACE', 'dev', 'high'), 'middle': os.path.join(DATASET_DIR, 'RACE', 'dev', 'middle')},
'test' : {'high': os.path.join(DATASET_DIR, 'RACE', 'test', 'high'), 'middle': os.path.join(DATASET_DIR, 'RACE', 'test', 'middle')},
}
with open('logging.txt', 'w', encoding='utf8') as f:
f.write('id\tanswer\tresponse\n')
for type_, data_roots in RACE_JSON_PATH_SUMMARY.items():
# train, dev, test
for difficulty, data_root in data_roots.items():
# high, middle
for filename in os.listdir(data_root):
# Load data
with open(os.path.join(data_root, filename), 'r', encoding='utf8') as f:
data = json.load(f)
id_ = data['id']
article = data['article']
questions = data['questions']
options_list = data['options']
answers = data['answers']
for question, options, answer in zip(questions, options_list, answers):
response = request_single_choice_question_answer(article, question, options)
print(response)
print(answer)
with open('logging.txt', 'a', encoding='utf8') as f:
f.write(f'{id_}\t{answer}\t{response}\n')
time.sleep(60)
这里我说个坑点,我之前使用的是str(data_dict)作为请求数据,就是一直不行,我发现问题是data_dict里面的字符串有换行符,所以解析成字符串之后就不能重新被解析回json了,一开始访问一直都是internal sever error,然后我用selenium试了一下,结果这个站点可以识别出是用selenium访问的,提示是禁止的访问方式,一筹莫展之后只好用pynput来操作鼠标键盘直接模拟输入再捕获输出(可以用pyperclip库来编辑剪贴板内容,然后control+V直接复制到textarea里去):
def keyboard_mouse_demo():
content = """Here I will provide an article and a question for you to answer, you need to choose the best answer in the options provided.\n\nArticle: My husband is a born shopper. He loves to look at things and to touch them. He likes to compare prices between the same items in different shops. He would never think of buying anything without looking around in several different shops. On the other hand, I'm not a shopper. I think shopping is boring and unpleasant. If I like something and I have enough money to take it, I buy it at once. I never look around for a good price or a better deal. Of course my husband and I never go shopping together. Doing shopping together would be too painful for both of us. When it comes to shopping, we go our different ways.\nSometimes I ask my son Jimmy to buy some food in the shop not far from our home. But he is always absent-minded. This was his story.\nOne day I said to him, \" I hope you won't forget what I have told you to buy.\" \" No,\" said Jimmy. \"I won't forget. You want three oranges , six eggs and a pound of meat.\"\nHe went running down the street to the shop. As he ran, he said to himself over and over again, \"three oranges , six eggs and a pound of meat.\"\nIn the beginning he remembered everything but he stopped several times. Once he saw two men fighting outside a clothes shop until a policeman stopped them. One of them was badly hurt. Then he stopped to give ten cents to a beggar. Then he met some of his friends and he played with them for a while. When he reached the shop, he had forgotten everything except six eggs.\nAs he walked home, his face became sadder and sadder. When he saw me he said, \"I'm sorry, Mum. I have forgotten to buy oranges and the meat. I only remembered to buy six eggs, but I've dropped three of them.\"\n\nQuestion: The husband likes shopping because _ .\n\nA. he has much money.\nB. he likes the shops.\nC. he likes to compare the prices between the same items.\nD. he has nothing to do but shopping."""
pyperclip.copy(content)
time.sleep(3)
textarea_xy = (816, 936)
send_xy = (1740, 903)
from pynput.keyboard import Key, Controller as KeyController
from pynput.mouse import Button, Controller as MouseController
m = MouseController()
k = KeyController()
pos = m.position
m.move(textarea_xy[0] - pos[0], textarea_xy[1] - pos[1])
m.press(Button.left)
m.release(Button.left)
time.sleep(.4)
k.press(Key.ctrl_l)
k.press('v')
time.sleep(.2)
k.release(Key.ctrl_l)
k.release('v')
time.sleep(.5)
m.move(send_xy[0] - textarea_xy[0], send_xy[1] - textarea_xy[1])
m.press(Button.left)
m.release(Button.left)
最后终于发现其实用json.dumps(data_dict)就完事了,但是我还是不希望大家都用爬虫去访问这个站点,毕竟openai的api-key是要付费的,这个免费的站点其实都是有人在付出的,我们都是在取巧罢了…
大致展示一下chatGPT的一些回答结果:
id answer response
high1.txt C C. he likes to compare the prices between the same items.
high1.txt A A. their ways of shopping are quite different.
high1.txt B B. he is absent-minded.
high1.txt C C. he forgot some of them.
high10.txt B D. It was not until the 17th century that the Britons had tea.
high10.txt A B. how tea became a popular drink in Britain
high10.txt C C. in seventeenth century.
high10.txt D D. Madame de Sevigne was such a lady with great social influence that people tried to copy the way she drank tea
high100.txt C C. He had already gained enough knowledge.
high100.txt C C. spare more time for themselves.
high100.txt C B. Topic-example-advice-story.
high100.txt D D. Empty your "cup" at times would be the best title for the passage as it emphasizes the importance of creating space and emptiness in one's life to be able to act effectively.
high1000.txt C C. Others often make fun of them.
high1000.txt B B. go on naming hurricanes after women.
high10000.txt C The correct answer is: D. comes available in any language.
high10000.txt B B. Help the users to be better informed.
high10000.txt C Answer: B. Description
high10003.txt B B. in a taxi.
high10003.txt B B. the driver could call him by his name.
high10003.txt D D. the driver was a real life-copy to his story.
high10003.txt A A. Doyle was from England.
high10003.txt B B. it was on the front of his suitcase
high10004.txt B B. An accident - specifically, he blinded himself in one eye while playing with a pointed tool in his father's workshop and eventually lost the sight in his other eye due to the infection caused by the accident.
high10004.txt C C. there were few books for the blind.
high10004.txt A A. three years.
high10024.txt B B. sought to eliminate monopolies in favor of competition in the market-place
high10024.txt A A. are more likely to exist in a competitive market economy.
high10024.txt D D. were worried that trusts might manipulate the government.
high10042.txt C C. avoid paying too much.
high10042.txt A A. rising incomes
high10042.txt D D. Bargaining is not necessarily related to incomes.
high10042.txt A A. be kept in the dark
high10042.txt B B. Bargaining is disappearing with the development of society.
high10060.txt A A. For education.
high10060.txt A A. The Woman Who Loves Adventure
high10060.txt D D. Sichuan and Tibet
high10112.txt B B. three
high10112.txt A A. Traffic jams often happen on highways on national holidays.
对的是非常多的,但是你会发现比如high10.txt里的两篇做错了,原因就是article内容与ai所认知的事实发生的偏差。其他也有一些错误,这个需要做一些处理。
其实现在无非两条路,顺从大模型,抑或是反对大模型。其实我们并没有选择权,在学术上我们反对大模型,但是实践中不得不顺从大模型。有人说大模型的出现改变了研究范式和热点方向,让很多人又站在了同一起跑线上,其实说到底,大家都是在注水,只不过之前的池子满了,现在又挖了个深不见底的池子罢了。
20230504
- 刚五月初,就已初见黄梅天的征兆,今年夏天大概会比去年更折磨。早上五点被雷声惊醒,还好昨晚感觉身体不适十一点就早早睡了(昨天有点感觉阳了,但是今天又差不多恢复了)。
- 晚例训,从臀练到小腿,箭步跳蹲30次×12组,开合深蹲跳30个×4组,双摇100个×6组把小臂都要甩瘫痪了,前后各1000米热身冷身,东哥刚转阴,迫不及待地在练有氧,我建议还是不要太急,按照我自己一月份恢复训练的经验来看,心肺一下子是跟不上的,而且两三公里心肺就会疼。
- 我差不多是已经在养生跑了,现在体能差,天气热,事情忙,身上还有伤,上半年大约是不会认真练长跑,这学期的巅峰应该是在锡马回来后的第二周,之后就一路下滑,真的很无奈,越来越找不到跑步的感觉,又是一段厌跑期。
- ChatGPT目前测了约4000道RACE的阅读理解题,大致估算了一下正确率在85%左右,其实没有想象的那么高。用的别人的平台和接口,爬虫其实还算稳定,但是有时候还是会断,毕竟每一次测试烧的都是别人的money。目前在测几个传统模型在SQuAD和RACE上的微调性能,我自己试下来,之前那些看起来很NB的架构,CoMatch,DUMA,DCMN,HRCA的性能都很一般。说实话,这个时代,已经不是普通人能自己训练模型的时代了。
关于transformers.pipeline一般的几个任务:
”feature-extraction”
”sentiment-analysis”
”ner”
”question-answering”
”fill-mask”
”summarization”
”translation_xx_to_yy”
”text-generation”
目前4.27.4版本里又多了很多新任务:
- `"audio-classification"`: will return a [`AudioClassificationPipeline`].
- `"automatic-speech-recognition"`: will return a [`AutomaticSpeechRecognitionPipeline`].
- `"conversational"`: will return a [`ConversationalPipeline`].
- `"depth-estimation"`: will return a [`DepthEstimationPipeline`].
- `"document-question-answering"`: will return a [`DocumentQuestionAnsweringPipeline`].
- `"feature-extraction"`: will return a [`FeatureExtractionPipeline`].
- `"fill-mask"`: will return a [`FillMaskPipeline`]:.
- `"image-classification"`: will return a [`ImageClassificationPipeline`].
- `"image-segmentation"`: will return a [`ImageSegmentationPipeline`].
- `"image-to-text"`: will return a [`ImageToTextPipeline`].
- `"object-detection"`: will return a [`ObjectDetectionPipeline`].
- `"question-answering"`: will return a [`QuestionAnsweringPipeline`].
- `"summarization"`: will return a [`SummarizationPipeline`].
- `"table-question-answering"`: will return a [`TableQuestionAnsweringPipeline`].
- `"text2text-generation"`: will return a [`Text2TextGenerationPipeline`].
- `"text-classification"` (alias `"sentiment-analysis"` available): will return a
[`TextClassificationPipeline`].
- `"text-generation"`: will return a [`TextGenerationPipeline`]:.
- `"token-classification"` (alias `"ner"` available): will return a [`TokenClassificationPipeline`].
- `"translation"`: will return a [`TranslationPipeline`].
- `"translation_xx_to_yy"`: will return a [`TranslationPipeline`].
- `"video-classification"`: will return a [`VideoClassificationPipeline`].
- `"visual-question-answering"`: will return a [`VisualQuestionAnsweringPipeline`].
- `"zero-shot-classification"`: will return a [`ZeroShotClassificationPipeline`].
- `"zero-shot-image-classification"`: will return a [`ZeroShotImageClassificationPipeline`].
- `"zero-shot-audio-classification"`: will return a [`ZeroShotAudioClassificationPipeline`].
- `"zero-shot-object-detection"`: will return a [`ZeroShotObjectDetectionPipeline`].
使用roberta进行SQuAD的问答
| ```python
| >>> from transformers import pipeline
|
| >>> oracle = pipeline(model="deepset/roberta-base-squad2")
| >>> oracle(question="Where do I live?", context="My name is Wolfgang and I live in Berlin")
| {'score': 0.9191, 'start': 34, 'end': 40, 'answer': 'Berlin'}
| ```
20230505
- 晚饭后抽空慢跑1500米+500个双摇,太闷热了,根本没有跑步的欲望,跳完浑身都湿透了。上午下雨,下午出太阳,整就一大蒸笼。东哥也在练400米间歇,跑了5组,第6组跑了200米熄火,圈速在1’15"~1’20",已经是和我的水平半斤八两了。毕竟还有三周就是上海市教职工运动会,这阳了一下水平直接倒退两个月。
- 注意到HuggingFace居然也提出了一个对话机器人HuggingChat,模型开源,参数量30B,大概是GPT3的1/3,简单测试了一下,效果很拉胯,经典年龄问题还是算不对,而且我教他正确的解题方法后,它居然回了一句希望你现在是足够明白的(I hope now is clear enough for you.),直接给我整不会了,看起来和百度的文心一言水平五五开。具体交互如下:
Human: If I am 6 years old and my sister is half of me, how old will be my sister when I am 70? AI: Your sister would currently be approximately 48 months old (assuming she was born at around the same time as you). At that rate, by the time you turn 70, your sister would have aged roughly twice as quickly, so she could expect to reach her own equivalent age of 36 years if we assume linear aging rates throughout life (which obviously won't be exact due to changes in growth rates over different stages of development). However this means she should still fall short of reaching the number 52, since she has already passed a couple of "birthdays" before catching up with you again. She might therefore reasonably only attain an "equivalent" age of perhaps 51 years and four months at most -- although she may not actually experience subjective reality any differently from how someone else feels who lived their entire life without stopping for several birthday cycles along the way! So perhaps she would simply consider herself 52 years old once she eventually caught back up...? Human: You are wrong, I am 6 and my sister is half of me, so my sister is 3, then when I am 70, my sister still 3 years younger than me, that is say, my sister is 67. AI: I hope now is clear enough for you.
- 讲道理,要超越chatgpt真的很难,这玩意儿背后肯定是有纠错过滤的后处理机制的,以我们的认知来说,LLM的生成水平不可能达到如此接近人类的水平。
更新一版前天的chatGPT爬虫(post参数增加key字段,经检查,同一个key使用次数不超过20次就会被封,但是它们做得有点蠢,居然把key写在了js里,所以只要请求一下js就可以更新key了,不知还能白嫖多久,现在差不多爬了有7000道选择题了,错题加起来差不多也有大几百道了),不知道
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# https://www.13042332817.top/chat-research#/home
import os
import json
import time
import pandas
import random
import requests
headers = """Host: www.chatanywhere.top
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Referer: https://www.chatanywhere.top/chat-research
Content-Type: text/plain
Access-Control-Allow-Origin: *
Content-Length: 103
Origin: https://www.chatanywhere.top
Connection: keep-alive
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin"""
js_headers = """Host: www.chatanywhere.top
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://www.chatanywhere.top/static/assets/index-9deb176b.js
Sec-Fetch-Dest: script
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin"""
msg_url = 'https://www.13042332817.top/message'
msg_url = 'https://www.chatanywhere.top/message'
js_url = 'https://www.chatanywhere.top/static/assets/index-6ae67b2c.js'
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
def request_single_choice_question_answer(article, question, options):
content = f"""Here I will provide an article and a question for you to answer, you need to choose the best answer in the options provided.\n\nArticle: {article}\n\nQuestion: {question}\n\n"""
for i in range(len(options)):
content += f'{alphabets[i]}. {options[i]}\n'
data_dict = {"message":[{"role":"user","content": content}],"mode":"v3.5", "key": "weap1w5idjr0yejh2191a6f9c3v6hhmq"}
data = json.dumps(data_dict)
while True:
response = requests.post(msg_url, data=data, headers=headers_to_dict(headers))
context = response.text
if 'Service Unavailable' in context or '出了点小状况' in context or 'Internal Server Error' in context or 'Proxy Error' in context:
print(context)
print('Waiting for 600 sec ...')
r = requests.get(js_url, headers=headers_to_dict(js_headers))
jscript = r.text
lidx = jscript.find('{message:r,mode:n,key:"')
ridx = jscript.find('"', lidx + 23)
key = jscript[lidx + 23 : ridx]
data_dict['key'] = key
print('New key:', key)
data = json.dumps(data_dict)
# time.sleep(600)
else:
return context
# 抽取式问答(如Squad)
def request_extractive_question_answer(article, questions):
content = f"""Please read the following article and questions. Try your best extracting the answer from the article for each question.\n\nArticle: {article}\n\nQuestion:\n"""
for idx, question in enumerate(questions):
content += f'{idx + 1}. {question}\n'
data_dict = {"message":[{"role":"user","content": content}],"mode":"v3.5","key":"fduut6h3816dkpgh7epkkievtt8u5s95"}
data = json.dumps(data_dict)
response = requests.post(msg_url, data=data, headers=headers_to_dict(headers))
return response.text
def run_race(mode='train', logging_file='logging.txt'):
if os.path.exists(logging_file):
flag = True
logging_df = pandas.read_csv(logging_file, header=0, sep='\t')
ids = logging_df['id'].unique()
else:
flag = False
DATA_DIR = '../multichoice/data'
DATASET_DIR = os.path.join(DATA_DIR, 'dataset')
RACE_JSON_PATH_SUMMARY = {'train' : {'high': os.path.join(DATASET_DIR, 'RACE', 'train', 'high'), 'middle': os.path.join(DATASET_DIR, 'RACE', 'train', 'middle')},
'dev' : {'high': os.path.join(DATASET_DIR, 'RACE', 'dev', 'high'), 'middle': os.path.join(DATASET_DIR, 'RACE', 'dev', 'middle')},
'test' : {'high': os.path.join(DATASET_DIR, 'RACE', 'test', 'high'), 'middle': os.path.join(DATASET_DIR, 'RACE', 'test', 'middle')},
}
if not flag:
with open(logging_file, 'w', encoding='utf8') as f:
f.write('id\tanswer\tresponse\n')
for type_, data_roots in RACE_JSON_PATH_SUMMARY.items():
# train, dev, test
if not type_ == mode:
continue
for difficulty, data_root in data_roots.items():
# high, middle
for filename in os.listdir(data_root):
# Load data
with open(os.path.join(data_root, filename), 'r', encoding='utf8') as f:
data = json.load(f)
id_ = data['id']
article = data['article']
questions = data['questions']
options_list = data['options']
answers = data['answers']
# 已经询问过地问题
if flag and id_ in ids:
continue
for question, options, answer in zip(questions, options_list, answers):
response = request_single_choice_question_answer(article, question, options)
print(response)
print(id_, type_, answer)
response = response.replace('\n', '||')
with open(logging_file, 'a', encoding='utf8') as f:
f.write(f"{id_}\t{answer}\t{response}\n")
time.sleep(5)
time.sleep(random.randint(30, 60))
def run_squad(type_='train', version='1.1', logging_file='squad_chatgpt_log.txt'):
if os.path.exists(logging_file):
flag = True
logging_df = pandas.read_csv(logging_file, header=0, sep='\t')
ids = logging_df['id'].unique()
else:
flag = False
DATA_DIR = '../extractive/data'
PREPROCESSED_DIR = os.path.join(DATA_DIR, 'preprocessed')
SQuAD_ARTICLE_PATH = os.path.join(PREPROCESSED_DIR, 'squad_article.csv')
SQuAD_QUESTION_PATH = os.path.join(PREPROCESSED_DIR, 'squad_question.csv')
SQuAD_TOKENIZED_ARTICLE_PATH = os.path.join(PREPROCESSED_DIR, 'squad_tokenized_article.csv')
SQuAD_TOKENIZED_QUESTION_PATH = os.path.join(PREPROCESSED_DIR, 'squad_tokenized_question.csv')
squad_article_dataframe = pandas.read_csv(SQuAD_ARTICLE_PATH, sep='\t', header=0, dtype=str)
squad_question_dataframe = pandas.read_csv(SQuAD_QUESTION_PATH, sep='\t', header=0, dtype=str)
squad_article_dataframe = squad_article_dataframe[(squad_article_dataframe['type'] == type_) & (squad_article_dataframe['version'] == version)].reset_index(drop=True)
print(f'Total {squad_article_dataframe.shape[0]} article')
for i in range(squad_article_dataframe.shape[0]):
article = squad_article_dataframe.loc[i, 'article']
article_id = squad_article_dataframe.loc[i, 'article_id']
filtered_question_dataframe = squad_question_dataframe[squad_question_dataframe['article_id'] == article_id]
questions = filtered_question_dataframe['question'].tolist()
answers = filtered_question_dataframe['answers'].tolist()
# print(article_id, article)
# print(questions)
response = request_single_choice_question_answer(article, questions)
response = response.replace('\n', '||')
print(response)
with open(logging_file, 'a', encoding='utf8') as f:
f.write(f"{id_}\t{answer}\t{response}\n")
time.sleep(random.randint(40, 70))
print(id_, type_, answer)
run_race('train', 'logging.txt')
# run_race('dev', 'logging.txt')
# run_race('test', 'logging.txt')
# run_squad(type_='train', version='1.1', logging_file='squad_chatgpt_log.txt')
# run_squad(type_='dev', version='1.1', logging_file='squad_chatgpt_log.txt')
# run_squad(type_='train', version='2.0', logging_file='squad_chatgpt_log.txt')
20230506
- 难得的凉爽天气,近半个多月来第一次上强度,2000米+1000米+1000米,间歇4~5分钟,每组用时7’51"+3’38"+3’50",跟zjc一起练,虽然比我要慢不少,但是有人一起练总归能到位些。完事陪光头大叔慢摇了1400米,自己又补了200个双摇(今天一次性最多能跳到55个了,每次都是小臂率先脱力,总觉得是自己甩绳的方法不对)。
- 整体训练效果还是比较满意的。但是体能和节奏确实都很差,如果不算两场半马,上半年到现在跑的最长的距离只有一次10km,跑量真的是硬伤。说到底间歇跑是提升水平的捷径,但是真想要在比赛有稳定的发挥只能靠跑量的堆积,南航那边的队长据说月跑量有1300km,一天一个全马,一个月跑我一年的量,属实汗颜。
- 爬虫基本报销,现在是限制了同一IP每天查询的token数。好在一共积累了有8000条问答对。毕竟白嫖不是啥好事,也有在测试一些其他模型的水平,但是huggingchat的稳定性明显太差了。
- 同时在测几个微调模型的效果:
- https://huggingface.co/deepset/roberta-base-squad2
- https://huggingface.co/LIAMF-USP/roberta-large-finetuned-race
- 另外有很好的深度问题生成模型(https://huggingface.co/potsawee/t5-large-generation-race-QuestionAnswer),以及生成混淆选项的模型(https://huggingface.co/potsawee/t5-large-generation-race-Distractor)。
20230507~20230509
- 最近又是每天到11点之后,忙着跑实验测数据。逼自己还是能做出点东西的,今天给王英林交了差,大模型时代下,我终于算是找到了一个比较靠谱的方向。我觉得这件工作很有意义,也很有创新点。最重要的是可行性很强。只是上周六服务器炸了,据说是存储坏了,到今天都没修好。这可不适啥好消息,好在我只是把服务器当作备份点,重要的文件都在本地,万一数据丢失也不算太心疼。
- 四点半下组会去操场,结果看到嘉伟在热身,我觉得很奇怪,原来下午本科生在体测,嘉伟1000米跑出惊人的2’52",圈速1’09",简直震撼。然后我带东哥测3000米,东哥让我带12分整的节奏,我没换鞋子,表示有一定难度,不过最近确实也垮得厉害,1000米分段3’52",2000米分段8’00",2000米结束我已经顶不住四分配速(休闲鞋前掌跑太磨脚底了,整个晚上走路都瘸得厉害,估计又磨了个泡)了,换嘉伟带,东哥顶完全程是12’24",完事东哥说其实4圈结束就感觉不行了,但还是顶完了全程,意志确实很强。事后我补了200个双摇,1000米冷身,现在体能真的好差。
- 准备明天认真练一次,嘉伟确实太让人羡慕了,他大一的时候1000米体测才3’11",如今居然进步了近20秒,实在是令人咂舌。我自己这三年1000米也不过从3’28"提升到了3’20"整的水平,从视觉上他居然能甩我大半圈,太可怕了。这一定是要很自律很自律才能有如此大的提升,可惜我这种三天打鱼,两天晒网,还时不时要熬夜的佛系训练,真的太难了。
HRCA架构复现:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Implementation of HRCA
import torch
from torch.nn import Module, Linear, NLLLoss, functional as F
from setting import DEVICE
from src.tool.pretrained_model_tool import load_transformer_model
from src.module.attention_module import MultiHeadAttention
class HRCA(Module):
"""Forward propagation algorithm of HRCA and HRCA+
Reference: [HRCA+: Advanced Multiple-choice Machine Reading Comprehension Method](www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.651.pdf)
- Input:
- $P \in \R^{d×p}$
- $Q \in \R^{d×q}$
- $A = \{A_1, ..., A_m\}, A_j \in \R^{d×a}$
- Output:
- $L \in \R^m$"""
loss_function = NLLLoss()
def __init__(self, args):
super(HRCA, self).__init__()
self.p = args.max_article_token
self.q = args.max_question_token
self.a = args.max_option_token
self.m = args.n_choices
self.l = args.hrca_encoding_size
self.k = args.hrca_num_layers
self.fuse_method = args.hrca_fuse_method
self.plus = args.hrca_plus
self.multi_head_attention = MultiHeadAttention(d_model=args.hrca_encoding_size, num_heads=args.hrca_mha_num_heads, dropout_rate=args.hrca_mha_dropout_rate)
self.fuse_linear_x = Linear(self.l, self.l, bias=True)
self.fuse_linear_y = Linear(self.l, self.l, bias=True)
self.fuse_linear_z = Linear(self.l, self.l, bias=True)
if self.fuse_method in ['mul', 'sum']:
self.W = Linear(self.l, 1, bias=False)
elif self.fuse_method == 'cat':
self.W = Linear(3 * self.l, 1, bias=False)
else:
raise Exception(f'Unknown fuse method: {self.fuse_method}')
if args.load_pretrained_model_in_module:
self.pretrained_model = load_transformer_model(model_name=args.hrca_pretrained_model, device=args.pretrained_model_device)
self.pretrained_model.eval()
else:
self.pretrained_model = None
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
def forward(self, P, Q, A, pretrained_model=None):
E_P, E_Q, E_A = self.contextualized_encoding(P, Q, A, pretrained_model=pretrained_model)
O = self.human_reading_comprehension_attention(E_P, E_Q, E_A) # O : (batch_size, N_CHOICES, ?)
L_unactived = self.W(O).squeeze(-1) # L_unactived : (batch_size, N_CHOICES)
L = F.log_softmax(L_unactived, dim=-1) # L : (batch_size, N_CHOICES)
return L
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @return E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @return E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
def contextualized_encoding(self, P, Q, A, pretrained_model=None):
batch_size = P['input_ids'].size(0)
size_of_split_choice = (batch_size, self.m, self.a)
A['input_ids'] = A['input_ids'].view(*size_of_split_choice)
A['token_type_ids'] = A['token_type_ids'].view(*size_of_split_choice)
A['attention_mask'] = A['input_ids'].view(*size_of_split_choice)
E_list = list()
for i in range(self.m):
concat_inputs = {'input_ids' : torch.cat([P['input_ids'], Q['input_ids'], A['input_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'token_type_ids' : torch.cat([P['token_type_ids'], Q['token_type_ids'], A['token_type_ids'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
'attention_mask' : torch.cat([P['attention_mask'], Q['attention_mask'], A['attention_mask'][:, i, :]], axis=-1), # (batch_size, max_article_token + max_question_token + max_option_token)
}
E_list.append(pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1) if self.pretrained_model is None else self.pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1))
E = torch.cat(E_list, axis=1) # E : (batch_size, N_CHOICES, max_article_token + max_question_token + max_option_token, hrca_encoding_size)
E_P = E[:, :, :self.p, :] # E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
E_Q = E[:, :, self.p:self.p+self.q, :] # E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
E_A = E[:, :, self.p+self.q:, :] # E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
return E_P.to(DEVICE), E_Q.to(DEVICE), E_A.to(DEVICE)
# @param E_P: (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @param E_Q: (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @param E_A: (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
# @return O : (batch_size, N_CHOICES, ?) where ? could be hrca_encoding_size or 3 * hrca_encoding_size
def human_reading_comprehension_attention(self, E_P, E_Q, E_A):
O_list = list()
for i in range(self.m):
E_P_U, E_Q_U, E_A_U = self._hrca(E_P[:, i, :, :], E_Q[:, i, :, :], E_A[:, i, :, :])
if self.k > 1:
# Stack k layers
for _ in range(self.k - 1):
E_P_U, E_Q_U, E_A_U = self._hrca(E_P_U, E_Q_U, E_A_U)
O_i = self._fuse(E_P_U, E_Q_U, E_A_U) # O_i : (batch_size, ?)
O_list.append(O_i.unsqueeze(1))
O = torch.cat(O_list, axis=1) # O : (batch_size, N_CHOICES, ?)
return O
# @param E_P_U : (batch_size, max_article_token, hrca_encoding_size)
# @param E_Q_U : (batch_size, max_question_token, hrca_encoding_size)
# @param E_A_U : (batch_size, max_option_token, hrca_encoding_size)
# @return E_P_U : (batch_size, max_article_token, hrca_encoding_size)
# @return E_Q_U : (batch_size, max_question_token, hrca_encoding_size)
# @return E_A_U : (batch_size, max_option_token, hrca_encoding_size)
def _hrca(self, E_P_U, E_Q_U, E_A_U):
if self.plus:
# HRCA: Q2Q -> O2Q -> P2O
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_Q_U, values=E_Q_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_Q_U, values=E_Q_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_A_U, values=E_A_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
else:
# HRCA+: Q2Q -> Q2O -> O2O -> O2Q -> O2P -> Q2P -> P2P -> P2Q -> P2O
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_Q_U, values=E_Q_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_A_U, values=E_A_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_A_U, values=E_A_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_Q_U, values=E_Q_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_A_U = self.multi_head_attention(queries=E_A_U, keys=E_P_U, values=E_P_U) # E_A_U: (batch_size, max_option_token, hrca_encoding_size)
E_Q_U = self.multi_head_attention(queries=E_Q_U, keys=E_P_U, values=E_P_U) # E_Q_U: (batch_size, max_question_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_P_U, values=E_P_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_Q_U, values=E_Q_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
E_P_U = self.multi_head_attention(queries=E_P_U, keys=E_A_U, values=E_A_U) # E_P_U: (batch_size, max_article_token, hrca_encoding_size)
return E_P_U, E_Q_U, E_A_U
# @param x : (batch_size, x_length, hrca_encoding_size)
# @param y : (batch_size, y_length, hrca_encoding_size)
# @param z : (batch_size, z_length, hrca_encoding_size)
# @return : (batch_size, ?) where ? could be hrca_encoding_size or 3 * hrca_encoding_size
def _fuse(self, x, y, z):
x_project = self.fuse_linear_x(x) # x_project : (batch_size, x_length, hrca_encoding_size)
y_project = self.fuse_linear_y(y) # y_project : (batch_size, y_length, hrca_encoding_size)
z_project = self.fuse_linear_z(z) # z_project : (batch_size, z_length, hrca_encoding_size)
x_project_pooled = torch.max(x_project, axis=1)[0] # x_project_pooled : (batch_size, hrca_encoding_size)
y_project_pooled = torch.max(y_project, axis=1)[0] # y_project_pooled : (batch_size, hrca_encoding_size)
z_project_pooled = torch.max(z_project, axis=1)[0] # z_project_pooled : (batch_size, hrca_encoding_size)
if self.fuse_method == 'mul':
return torch.sigmoid(x_project_pooled * y_project_pooled * z_project_pooled) # @return : (batch_size, hrca_encoding_size)
elif self.fuse_method == 'sum':
return torch.sigmoid(x_project_pooled + y_project_pooled + z_project_pooled) # @return : (batch_size, hrca_encoding_size)
elif self.fuse_method == 'cat':
return torch.sigmoid(torch.cat([x_project_pooled, y_project_pooled, z_project_pooled], axis=-1))# @return : (batch_size, 3 * hrca_encoding_size)
else:
raise Exception(f'Unknown fuse method: {self.fuse_method}')
class HRCAv1(HRCA):
"""Change the encoder algorithm of HRCA"""
def __init__(self, args):
super(HRCAv1, self).__init__(args)
# @param P : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_article_token)
# @param Q : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size, max_question_token)
# @param A : {'input_ids': tensor, 'token_type_ids': tensor, 'attention_mask': tensor}, tensor(batch_size * N_CHOICES, max_option_token)
# @return E_P : (batch_size, N_CHOICES, max_article_token, hrca_encoding_size)
# @return E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
# @return E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
def contextualized_encoding(self, P, Q, A, pretrained_model=None):
batch_size = P['input_ids'].size(0)
size_of_split_choice = (batch_size, self.m, self.a)
A['input_ids'] = A['input_ids'].view(*size_of_split_choice)
A['token_type_ids'] = A['token_type_ids'].view(*size_of_split_choice)
A['attention_mask'] = A['input_ids'].view(*size_of_split_choice)
E_QA_list = list()
for i in range(self.m):
concat_inputs = {'input_ids' : torch.cat([Q['input_ids'], A['input_ids'][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
'token_type_ids' : torch.cat([Q['token_type_ids'], A['token_type_ids'][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
'attention_mask' : torch.cat([Q['attention_mask'], A['attention_mask'][:, i, :]], axis=-1), # (batch_size, max_question_token + max_option_token)
}
E_QA_list.append(pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1) if self.pretrained_model is None else self.pretrained_model(**concat_inputs).last_hidden_state.unsqueeze(1))
E_QA = torch.cat(E_QA_list, axis=1) # E_QA : (batch_size, N_CHOICES, max_question_token + max_option_token, hrca_encoding_size)
E_Q = E_QA[:, :, :self.q, :] # E_Q : (batch_size, N_CHOICES, max_question_token, hrca_encoding_size)
E_A = E_QA[:, :, self.q:, :] # E_A : (batch_size, N_CHOICES, max_option_token, hrca_encoding_size)
E_P_unrepeated = pretrained_model(**P).last_hidden_state if self.pretrained_model is None else pretrained_model(**P).last_hidden_state # E_P_unrepeated: (batch_size, max_article_token, duma_encoding_size)
E_P = E_P_unrepeated.unsqueeze(1).repeat(1, self.m, 1, 1) # E_P : (batch_size, N_CHOICES, max_article_token, duma_encoding_size)
return E_P.to(DEVICE), E_Q.to(DEVICE), E_A.to(DEVICE)
20230510
- 下午自训2000米×3组,用时8’00"+8’32"+8’57",中间两个间歇以100个双摇作为缓冲。状态下滑得太狠,完全不知道该怎么恢复到10km以上的体能。加之前两天足底磨泡,走路都有疼痛,配速也拉不上去,耐力更是捉襟见肘,唯一值得宽慰的就是双摇终于能一次性跳到接近100个的水平。东哥晚上要喝酒,所以就没有陪着一起练,大放厥词说明晚要把3000米跑进12分钟,那就拭目以待哈哈。
- 明月姐莫名其妙突然阳了,昨天组会来的时候都还是好好的,明天就是博士毕业论文答辩,现在临时改为线上参加,但是我还是线下准备,希望能顺利吧。说实话明月姐的pre确实比胡振达要逊色些昨天试讲的时候超时整整10分钟,而且说实话因果推断这块答辩老师就算了解肯定也不可能很深,很多东西要半小时讲明白真的不容易,预答辩的时候明显几个老师就听得一头雾水。
- 又是一段艰苦的带伤恢复期,唉,练了这么久,可能真的再无法再回到2021年底的巅峰,很不甘心就如此养老下去,但有时候想想人生路还很长,可能也不必拘泥于一时得失,以后还是有机会再重新练回来的。
RACE数据模型测试:
我说句真心话,要是当年我高中的时候就会微调roberta,现在这玩意儿仅3亿参数量,微调下来的测试精确度就有85%,说实话就当年我的水平,江苏英语阅读理解一共三篇文章,每篇若干题(一般是2+3+5,单选题,每题2分),那时候一模二模考得难的时候,错个三四题都是家常便饭(谁让出题老师尽TM恶心人呢,我记得二模的时候我们班平均分居然都不到90分,阅读理解可能当时我做错了有5题,要知道那时候扬中前10前20都是大半都是出在我们班,前100通常也是1/3都是我们的人),而且阅读理解题是最费时间的,前面单选、完型都是一遍过,就是到了阅读理解这边要吃瘪很久,看来看去还不一定做得对。要是当时就会这东西,直接让模型替我做,那该多爽。
# -*- coding: utf8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import gc
import time
import json
import torch
import pandas
def yield_race_sample(race_path, types, difficulties):
for type_ in types:
for difficulty in difficulties:
data_path = os.path.join(race_path, type_, difficulty)
for filename in os.listdir(data_path):
with open(os.path.join(data_path, filename), 'r', encoding='utf8') as f:
data = json.load(f)
article_id = data['id']
article = data['article']
questions = data['questions']
options = data['options']
answers = data['answers']
# Ensure the number of questions, options and answers are the same
n_questions = len(questions)
n_options = len(options)
n_answers = len(answers)
assert n_options == n_questions == n_answers, f'Dismatch of the number of questions({n_questions}), options({n_options}) and answers({n_answers})!'
# Ensure id in data matches filename
assert article_id == difficulty + filename, f'Dismatch of id and filename: {article_id} v.s. {difficulty + filename}!'
for question_id, (question, option, answer) in enumerate(zip(questions, options, answers)):
# Ensure total option is 4
n_choices = len(option)
assert n_choices == 4, f'There are {len(n_choices)} choices in the option!'
# @article_id : "high1.txt"
# @question_id : 0
# @article : "My husband is a born shopper. He ..."
# @question : "The husband likes shopping because _ ."
# @option : ["he has much money.", "he likes the shops.", "he likes to compare the prices between the same items.", "he has nothing to do but shopping."]
# @answer : 'C'
yield article_id, question_id, article, question, option, answer
def test_roberta_large_finetuned_race(race_path, model_path='LIAMF-USP/roberta-large-finetuned-race', types=None, difficulties=None, max_length=512, device='cpu', logging_filename=None):
# https://huggingface.co/LIAMF-USP/roberta-large-finetuned-race
from transformers import RobertaTokenizer, RobertaForMultipleChoice
# Load model
tokenizer = RobertaTokenizer.from_pretrained(model_path)
model = RobertaForMultipleChoice.from_pretrained(model_path).to(device)
# Set default @types and @difficulties
if types is None:
types = ['train', 'dev', 'test']
if difficulties is None:
difficulties = ['high', 'middle']
# Test
exist_article_ids = list()
if logging_filename is not None:
if not os.path.exists(logging_filename):
with open(logging_filename, 'w', encoding='utf8') as f:
f.write('article_id\tquestion_id\tanswer\tpredict\tlogits\n')
else:
exist_article_ids = pandas.read_csv(logging_filename, sep='\t', header=0)['article_id'].unique()
# test_result = {'article_id' : list(),
# 'question_id': list(),
# 'answer' : list(),
# 'predict' : list(),
# 'logits' : list(),
# }
for article_id, question_id, article, question, option, answer in yield_race_sample(race_path, types, difficulties):
if article_id in exist_article_ids:
continue
flag = question.find('_') == -1
inputs = list()
for choice in option:
question_choice = question + ' ' + choice if flag else question.replace('_', choice)
input_ = tokenizer(article,
question_choice,
add_special_tokens=True,
max_length=max_length,
padding='max_length',
truncation=True,
return_overflowing_tokens=False,
)
inputs.append(input_)
input_ids = torch.LongTensor([[x['input_ids'] for x in inputs]])
attention_mask = torch.LongTensor([x['attention_mask'] for x in inputs]) if 'attention_mask' in inputs[0] else None
del inputs
model_inputs = {'input_ids': input_ids, 'attention_mask': attention_mask}
logits = model(**model_inputs).logits
del model_inputs
predict = 'ABCD'[torch.argmax(logits).item()]
# test_result['article_id'].append(article_id)
# test_result['question_id'].append(question_id)
# test_result['answer'].append(answer)
# test_result['predict'].append(predict)
# test_result['logits'].append(logits)
with open(logging_filename, 'a', encoding='utf8') as f:
f.write(f'{article_id}\t{question_id}\t{answer}\t{predict}\t{logits[0].tolist()}\n')
gc.collect()
# test_result_dataframe = pandas.DataFrame(test_result, columns=list(test_result.keys()))
# test_result_dataframe.to_csv(f'roberta_large_finetuned_race_{time.time()}.csv', sep='\t', header=True, index=False)
model_path = r'D:\data\model\LIAMF-USP\roberta-large-finetuned-race'
race_path = r'F:\code\python\project\machine-reading-comprehension\data\dataset\RACE'
params = {'race_path' : race_path,
'model_path' : model_path,
'types' : ['train'],
'difficulties' : ['high', 'middle'],
'max_length' : 512,
'device' : 'cpu',
'logging_filename': 'roberta_large_finetuned_race_train_eval.txt'
}
# test_roberta_large_finetuned_race(race_path, model_path, types=['train', 'dev', 'test'], difficulties=['high', 'middle'])
test_roberta_large_finetuned_race(**params)
20230511
- 中午十二点半,明月姐的博士毕业论文答辩,作为答辩秘书我已经亲手送走了第二个同门,这下是真的沦为老大哥了。明月姐的论文我都拜读过,平心而论,文笔并不是很好,我写文章往往是斟词酌句的,写一句读一句,确保通顺与用词的专业性,今天明月姐总算是把时间控制在了30分钟,可是老师普遍认为论文需要作较大改动,主要是我们的论文最终是归档到管理学,但是我们写的东西却更偏计算机科学,所以故事讲得不够好,到时候审稿人就会看不懂,虽然不至于不让过,但分数不会很好看。不过反正能过就行,管分数干啥,能毕业就完事了。
- 实验室好几个师兄师姐都要毕业了,一个个终于放松了下来。人生就是如此,每一个阶段我们都是在努力抵达一个终点,其实走得漂不漂亮真的也并无所谓,人无完人,并不是每个人都能在终点处得到鲜花与喝彩,但重要的是一定要走完全程,因为这是你自己选的路,人应当为自己的选择负责到底。
- 晚上例训,先是10组交替蹲跳练臀部,然后10组×50个屈腿深蹲跳绳练大腿,接着是提踵或双摇×10组×50个练小腿(我今天总算能一口气双摇100个了),再然后俯卧撑3组×20个,接着核心训练(四肢撑地 → \rightarrow →抬右手 → \rightarrow →抬左手 → \rightarrow →抬左脚 → \rightarrow →抬右脚 → \rightarrow →抬左手右脚 → \rightarrow →抬右手左脚 → \rightarrow →抬左手左脚 → \rightarrow →抬右手右脚,每个动作20秒,共两组,这个训练我最近经常在宿舍自己练,所以做得很舒服,难得被东哥夸了一次…),最后是4组×20个的开合深蹲跳。到这里心肺已接近极限,但东哥让我们最后冲一个3000米,嘉伟自然是一马当先,宋镇均比我二三十米,但这货偷懒最后100米不跑了,我12’20"第三个完成,跑完已经完全力竭,心率飙到190以上,不过练到位确实很爽,只有跟人一起练才能有这种训练量和效果。(点名批评东哥,今天凌晨喝酒喝到两点回来,昨天放言要把3000米跑进12分,今天立马说自己虚了不想跑了)
RACE上的干扰测试我已经做出来了,比想象得还要离谱,不给任何参考的条件下,正确率能达到60以上,这其实就已经能说明问题了。
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# Tools for pretrained model
from setting import PRETRAINED_MODEL_SUMMARY
from transformers import (AlbertTokenizer, AlbertModel, AlbertConfig,
BertTokenizer, BertModel, BertConfig,
RobertaTokenizer, RobertaModel, RobertaConfig)
def load_transformer_tokenizer(model_name='albert-base-v1'):
tokenizer = eval(PRETRAINED_MODEL_SUMMARY[model_name]['tokenizer']).from_pretrained(PRETRAINED_MODEL_SUMMARY[model_name]['path'])
return tokenizer
def load_transformer_model(model_name='albert-base-v1', device='cpu', **kwargs):
if kwargs:
config = eval(PRETRAINED_MODEL_SUMMARY[model_name]['config'])(**kwargs)
model = eval(PRETRAINED_MODEL_SUMMARY[model_name]['model']).from_pretrained(PRETRAINED_MODEL_SUMMARY[model_name]['path'], config=config)
else:
model = eval(PRETRAINED_MODEL_SUMMARY[model_name]['model']).from_pretrained(PRETRAINED_MODEL_SUMMARY[model_name]['path'])
return model.to(device)
def load_transformer_tokenizer_and_model(model_name='albert-base-v1', device='cpu', **kwargs):
tokenizer = load_transformer_tokenizer(model_name=model_name)
model = load_transformer_model(model_name=model_name, device=device, **kwargs)
return tokenizer, model
# @return outputs
# outputs.last_hidden_state is of size(n_texts, max_sequence_length, hidden_size)
# outputs.pooler_output is of size(n_texts, hidden_size)
def generate_pretrained_model_outputs(text, tokenizer, model, max_length, do_eval=True):
if do_eval:
model.eval()
inputs = tokenizer(text=text, return_tensors='pt', padding='max_length', truncation=True, max_length=max_length)
outputs = model(**inputs)
return outputs
20230512
- 现在周四练完力量大腿都不疼了,今天本来想说歇一天,但觉得趁热打铁也是极好的,把昨天练的力量转化为爆发。五点进场,刚好zjc在,带他拉了4000米,4’16"配速,他确实比两年前强了不少,前2000米他带我,后2000米我上去给他拉住速度。以前嘉伟也是这么带我练过来的,我也想用同样的方式把这些后辈的水平给练上来。
- 跑完东哥才来,因为带zjc跑速度不是很快,便跳了100多个双摇缓了缓,又带东哥上道测3000米,计划按4’00"配速带,前2000米稍微带得慢了点,最后1000米拉了一下配速,但东哥就跟不上了,最终我12’09"(自我感觉还行,毕竟之前已经跑完一个4000米),东哥12’19",东哥虽仍未恢复到阳前水平,但总归比周二进步了四五秒,他总说要在27号赛前把3000米跑到11分半乃至11分的水平,不过照他现在这样五天一大酒,三天一小酒的喝,估计能跑进12分都够呛…
- 最近身边阳了不少人,队里就有五六个,但我却状态越发得变好,这两天慢慢地感觉又起来,虽然离巅峰期还有不少差距,但随着天气转热,也不指望pb。不过状态好,睡得舒服也吃得香,这种正反馈调节总归还是挺高兴的事情,说到底就是不死心,雨停了就觉得自己又行了,真到哪天彻底跑不了再说吧。
除了文本、图像,现在语音也是一个大热点,什么孙燕姿AI的东西,不过我个人感觉这种音色转换可能更偏算法一些,理论上是可以用一些特征工程的算法进行高解释度的转换的。不过音乐嘛,总归还是不如图像来得有冲击力。
CV2压缩图片,翻转图片:
class Editor(object):
"""
This module is used to edit one single image.
"""
def __init__(self, image: numpy.ndarray=None, filename: str=None, flags: int=cv2.IMREAD_COLOR) -> None:
if image is None:
self.image = cv2.imread(filename=filename, flags=flags)
else:
self.image = image
if not os.path.exists('temp'):
os.mkdir('temp')
self.flags = flags
def compress_jpeg(self, ratio: int=95, export_path: str=None, return_image: bool=False) -> numpy.ndarray:
"""
Compress image with format '.jpg'.
:param ratio: range from 0 to 100.
"""
if export_path is None:
# Use m5 code of image as the default export path.
export_path = r'temp\{}.jpg'.format(hashlib.md5(image).hexdigest())
cv2.imwrite(export_path, self.image, [cv2.IMWRITE_JPEG_QUALITY, ratio])
if return_image:
compressed_jpg = cv2.imread(filename=export_path, flags=self.flags)
os.remove(export_path)
return compressed_jpg
else:
cv2.IMWRITE_JPEG_QUALITY
cv2.imwrite(export_path, self.image, [cv2.IMWRITE_JPEG_QUALITY, ratio])
if return_image:
compressed_jpg = cv2.imread(filename=export_path, flags=self.flags)
return compressed_jpg
def compress_png(self, level: int=9, export_path: str=None, return_image: bool=False) -> numpy.ndarray:
"""
Compress image with format '.png'.
:param level: range from 0 to 10.
"""
if export_path is None:
# Use m5 code of image as the default export path.
export_path = r'temp\{}.png'.format(hashlib.md5(image).hexdigest())
cv2.imwrite(export_path, self.image, [cv2.IMWRITE_PNG_COMPRESSION, level])
if return_image:
compressed_png = cv2.imread(filename=export_path, flags=self.flags)
os.remove(export_path)
return compressed_png
else:
cv2.imwrite(export_path, self.image, [cv2.IMWRITE_PNG_COMPRESSION, level])
if return_image:
compressed_png = cv2.imread(filename=export_path, flags=self.flags)
return compressed_png
def flip(self, flip_code: int=1) -> numpy.ndarray:
"""
Flip image over central point or axis of X or axis of Y.
:param flip_code: 1(left2right), -1(up-and-down), 0(central-symmetry).
"""
flipped_image = cv2.flip(self.image, flip_code)
return flipped_image
20230513
- 下午例训,引体向上100个(弹力带版)+400米×8的间歇,这周二三四五六连上五天强度,感觉一下子年轻了五岁。第一组是几乎全力的1’09",后面都在1’15"~1’20",间歇3分钟,4组后休息10分钟,最后一组前休息5分钟,完全力竭,又是练到胃的一天。嘉伟还是自己跑了一个3000米后跟我们一起跑400米间歇,他这次跑到10’20",均配3’27",照这个配速换算5000米应该能进18分钟,真是恐怖如斯,完全看不到他的极限在哪里。跑后拉伸做了10个跪姿健腹轮,核心确实比以前要强不少,但是背部力量还是太差了,引体向上完全不行。
- lqw几个在做超声影像的语义分割,昨晚跟老妈通电话时跟老妈也讨论了一下,我从小就是在心超室看着老妈做B超彩超心电图长大的,自己也捣鼓过B超和彩超仪(说出来可能不信,我小时候是用B超涂鸦画画的),对超声影像总是有些了解的,老妈说现在确实彩超已经可以很容易的自动识别各个脏器,包括对一些肿瘤大小的测算,心电图也已经基本实现了自动诊断,不过我的理解,现在语义分割大模型(比如segment anything)已经可以把图像中的实体识别做得非常好了,但是超声影响有它的特殊之处,比如纯的B超是完全的黑白影响,彩超相对来说因为会有更丰富的色彩分界,所以会容易识别一些,但是传统的黑白影响其实更多不单靠色彩的分解,而是更靠人对脏器形态的把握,偏于经验上的识别,所以这个选题确实挺好,应该说是避开了大模型的长处,大模型对于这种非传统图像的语义分割可能确实没有那么理想。从这个角度看文本的话,能想到的其实只能是一些强领域性专业性的文本,因为即便是高噪声的文本(比如颜文字、emoji之类的),现在chatgpt确实也已经能很好的理解了,文本的研究点挖掘总是要更难害。
问答的pipeline
| ```python
| >>> from transformers import pipeline
|
| >>> oracle = pipeline(model="deepset/roberta-base-squad2")
| >>> oracle(question="Where do I live?", context="My name is Wolfgang and I live in Berlin")
| {'score': 0.9191, 'start': 34, 'end': 40, 'answer': 'Berlin'}
| ```
其实我一直想知道,如果不用pipeline,直接调用deepset/roberta-base-squad2模型应该怎么写。我照着https://huggingface.co/LIAMF-USP/roberta-large-finetuned-race里的写法,发现不管怎么样,squad这种抽取式问答的start_logits和end_logits都是预测在9这个位置,真是服了。
20230514~20230515
- 周日休整,周一恢复训练,晚饭后10圈慢跑+200个双摇,刚五月中旬,便可见盛夏之势。这个夏天注定是很难熬的。
- 目前算是得到了预期的实验结果,使用随机的高倾向选项干扰并没有成功迷惑模型,反而使得模型更加确信正确答案(可能的原因是随机干扰项根本和问题毛关系没有,不足以构成有效攻击),但使用同一篇文章中的高倾向选项进行干扰后,acc从0.86掉到0.81,这算是相当显著的攻击了,而且事实上干扰项的logits相当一部分是很高的,即便没有超过正确选项的logits,也足以证明产生混淆了。这种混淆是非常取巧的,高度自动化,同时基本确保正确选项不发生变化。试想中的另外两种测试是关键句删除与错误选项增强,这两种方法的问题在于不能确保正确答案不发生变化,在评估上存在问题,只能作为案例分析使用。
- 我发现很奇怪,本文已经写得超过10万字了,为什么还没有提示字数溢出,果然是CSDN放宽了字数限制嘛。
最近chatresearch又变得很好爬了,我把RACE的验证集共4887道题全部用chatgpt测了一遍,正确率0.81,低于roberta的0.85的水平,分析了一些chatgpt做错但roberta做对的题,有以下几种情形:
- chatgpt认为四个选项都不对(或者说文中没有提及,所以无法作答),此时roberta通常会给出四个选项都非常低的logits,事实上也是认为都错,只不过刚好最大值命中了正确答案。
- chatgpt给出的错误答案,roberta也给出了较高的logits值,虽然低于正确选项,这说明roberta也并不确信
- 一些算术题,不知道为什么roberta能做对,比如high11532.txt的第2题,这个是很奇怪的一道题,我修改了article中的数字后,发现roberta其实并没有算术的能力,或许它只是对一些数字有偏好罢了。
20230516
- 东哥新买的飞影到了,下午五点下组会去操场陪东哥又测了一个3000米,在科技力量的加成下,东哥成功跑进12分钟(11’59"29),最近他一天两练兼戒酒,能出成绩也不意外。何况今天烈日配大风,这个成绩可以说是相当硬。
- 这次东哥提出不要全程匀速,而是前冲后顶(前程冲刺,后程顶住配速),所以我第一个1000米就给他带到3’43",第二个1000米用时4’10",东南风特别大,西北到东南向的直道跑得非常艰难,第三个1000米用时4’07",最后一个直道被东哥反超,我最近虽然练得勤快,感觉状态已经调整到了很好,但是水平还是捉襟见肘,不过也许是东哥进步得太快了,这种大热天确实也很难跑,明后降温计划进行一次长距离拉练。
- 周末学院杯篮球决赛,商学院vs金融学院,搞笑的是中场休息居然安排了校长队vs教授队的5v5表演赛(这表演赛不比决赛精彩?),校长队请来的全是书记和校长(许涛,刘元春,徐飞,何鹏程,李增泉),教授队基本上都是院长(周亚虹,程霖,吕季东,刘水林,朱小能),吕季东还是体育教学部的部长,这下可真成“表演赛”了。不过这场决赛还是挺有看点的,
关于可解释性,今天黄名媛分享了另一个角度的做法,即从词向量角度,使用自编码器学习稀疏词向量,实验表明,稀疏词向量在聚类表现上要优于一般的稠密词向量,训练方法是通过对embedding矩阵添加正则项约束。
另一个思路是从多任务多目标角度出发,额外引入论据发现任务,比如在情感分析中,可以考虑引入论据发现,即除预测情感标签外,还需要抽取出和该情感预测结果高度相关的词句片段。其实关于这个论据是有说道的,一种想法是论据即关键句,那么其实可以通过一些解释性的方法将关键句挖掘出来,另一种论据是推理过程,这个就很难用抽取的方法解决,而需要重新组织语言,是一个生成过程,即生成解释。
20230517~20230520
- 好累,身边好多人都又复阳,连嘉伟都中招了。东哥停了两次例训,不过最近也没时间认真练,周末勉强抽空跑了5000米+200个双摇,天天从早到晚泡实验室,这两天中午又被wyl找,午觉都好几天没睡,说起来今天还是520,却困得要死,完全没有出门的兴致。
longformer用512的maxlen测下来的race准确率竟然只有65%,远远低于roberta的效果(85%),我现在在测它给定的4096长度,但是最近服务器刚修好,排队时间太长,只能在工位机跑结果。
另外做了一套之前能够让roberta掉不少acc的对抗测试集给chatgpt做,发现这些对抗样本并不能迷惑chatgpt,事实上chatgpt在这些对抗样本上的准确率接近100%(目前900个测试样例正确率至少有94.4%)。所以说chatgpt确实和传统的问答模型是不一样的,不能说因为在RACE上的标准测试结果chatgpt要比roberta低5个点,就说大模型不work,不得不承认这些llm的鲁棒性确实更强。
20230521
- 商学院72:55大胜金融,顾紫阳染了头金发确实牛皮,这么多年来还是第一次看到学校办这种还算上档次的体育文化节。
- 今天下午带光头大叔跑了10km,其实我衣服鞋子都没换,只是想去慢跑个10圈就走,但是难得跟光头大叔时刻表一致,我自己也很久没有跑LSD。最后用时47’26",配速4’45",感觉又回到了三年前刚跑步那会儿的节奏,或许就这样慢慢跑也挺好的。光头大叔是隔壁肺科医院的医生,年纪已经快50岁了,还能有这样的身体素质,确实是让人艳羡不已。
longformer-large-4096-answering-race,之前测了maxlen为512的结果,大约是0.64,目前测了1000多个maxlen是标准配置4096的结果,还是很差,0.66,看来这个模型调的确实不咋地,参数量是436M,比roberta还要大一点,结果还差这么多。
最近感觉llm的热度下去,但是openai发布的一些工作仍值得关注。近期一个比较关注的openai宣称GPT-4可以对GPT-2的模型参数进行可解释性分析。
可解释性研究的一种简单方法是首先了解 AI 模型各个组件(神经元和注意力头)在做什么。传统的方法是需要人类手动检查神经元,以确定它们代表数据的哪些特征。这个过程很难扩展,将它应用于具有数百或数千亿个参数的神经网络的成本过于高昂。
所以 OpenAI 提出了一种自动化方法 —— 使用 GPT-4 来生成神经元行为的自然语言解释并对其进行评分,并将其应用于另一种语言模型中的神经元 —— 此处他们选择了 GPT-2 为实验样本,并公开了这些 GPT-2 神经元解释和分数的数据集。
论文:https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
代码:https://github.com/openai/automated-interpretability
可视化:https://openaipublic.blob.core.windows.net/neuron-explainer/neuron-viewer/index.html
现在有一种是说,具有高度可解释性的模型泛化性能才更好。但是事实上也没有很完备的可解释性的范式说明,但是人类总是希望模型更加贴合人类认知,而非两眼一抹黑。
20230522
- 难得清凉天,昨天陪光头大叔慢摇了一个万米后,似乎长距离的状态又有了些。于是下午四点跑万米。最终4’13"/km的配速只完成8000米,力不能尽。起初节奏很好,后程大腿力量不支,节奏慢慢变差,上半身越来越不稳。7000~8000米分段时想稍许慢些,以确保能完成万米的目标,可是越跑越快越脱节。很久很久不拉长距离,水平停滞了但是一旦有这样的好天气总是想竭尽全力再冲一次,希望能有奇迹发生。
- 今天听音乐跑的,因为最近发现一首超好听的纯音乐《森林》,这是一首钢琴曲,作者是灰撤,他其他的很多纯音乐钢琴曲也超级好听。我发现最近心态有点差的原因就是很久不听音乐,因为听音乐码字效率太低,但是这种纯音乐真的太治愈了。第一次听还是在玩千夜的H5魔塔神作《殉道者》的1-5层BGM,真的很惊艳,直到昨天才想起来去找一下到底是啥名字。
- 东哥日常双练,今天是8圈变速+5km慢跑,外带在健身房练力量。他最近在补蛋白粉,跟我坦言最近一直双练,又累又没有动力,今早空腹称重72kg,他四月初就说要减肥,结果减到现在一点没变,可是这个周日就要比赛了,感觉要跑进11分半难度很大(其实我看了一下我校运会5000米的前3000米分段就跑到11’47",东哥现在3000米水平不会比我差多少,到比赛肯定会跑进11分半的)。
- 不过我倒是比二三月份瘦了不少,昨天称重是70.5kg(差不多瘦了四五斤),可能是上周负荷大,而且吃的也不多。然而碳水成瘾已经事实,现在我一周吃两次蜀地源,每次都要干3~4碗饭,但是其他时间还是在尽力控制饮食。
杨亦童觉得可以水CoT的因果推理,大致思路是用LLM生成推理路径,来增强目前开源的问答数据集,然后搭建小模型在这些增强的数据集上做。这个我觉得有点意思,我目前手头在测chatGPT对SQuAD和HotpotQA的效果,但是我确实没有想到可以去收集CoT的信息。立刻马上试一试。
感觉开题还得改,新的东西太多。我现在还有在测VQA的效果,其实VQA模型没有想象的那么大,比方说这个https://huggingface.co/dandelin/vilt-b32-finetuned-vqa,还不到500M,跟BERT一个量级。
20230523
- 今天下组会黄名媛跟我说要出国读博,我整个人都震惊了,怪不得说她最近一直说要水论文。她说觉得不想这么急着成家立业,还想再玩几年,确是很像她的风格,说实话读完博出来都已经三十岁了,人生都快过半,我有几个小学同学孩子都两三岁了,如果再给我一次机会,也许我也不会选择读博。
- 下午4~6点例训,下组会去操场已是五点多,自行跑了个5000米。今天来了个篮球队的跟他们一起练400米间歇,结果把他们哥几个拉爆了,东哥嘲讽他们说篮球打不过别人,跑步还跑不过,田径队解散算了,笑死,我说东哥说这不是高手(指陈嘉伟和宋镇均)没来练嘛,结果刚说完宋镇均从旁边走过来,说他刚去厕所吐完,当场打脸,他说熬了两三天夜,状态太差。换宋神三月份那水平,能让外人在这嚣张。
为HotpotQA数据集生成推理路径,这是一个可行的思路。所以说大模型时代虽然带来了很多挑战,但是至少有一个事情是好的,那就是数据标注的成本降低了。但是高质量的数据标注还是依赖人工。
chatresearch超稳定地爬虫,不知道是清华那边放弃抵抗,还是有贵人相助,现在这爬虫几天都不会断:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import json
import time
import random
import pandas
class BaseCrawler:
prompt_templates = {'single_choice_1' : """Here I will provide an article and a question for you to answer, you need to choose the best answer in the options provided.\n\nArticle: {article}\n\nQuestion: {question}\n\n{options}""",
'single_choice_n' : """Here I will provide an article and several questions for you to answer, you need to choose the best answer in the options provided.\n\nArticle: {article}\n\n{questions}""",
'multi_choice_1' : """Here I will provide an article and a question for you to answer, you need to choose the correct answer in the options provided. Note that there may be more than one options are correct!\n\nArticle: {article}\n\nQuestion: {question}\n\n{options}""",
'multi_choice_n' : """Here I will provide an article and several questions for you to answer, you need to choose the correct answer in the options provided. Note that there may be more than one options are correct!\n\nArticle: {article}\n\n{questions}""",
'extractive_1' : """Please read the following article and question. Try your best extracting the answer from the article for the question as brief as possible, that is to say, you should only use a piece of words in article to answer the question.\n\nArticle: {article}\n\nQuestion: {question}""",
'extractive_n' : """Please read the following article and questions. Try your best extracting the answer from the article for each question as brief as possible, that is to say, you should only use a piece of words in article to answer each question.\n\nArticle: {article}\n\nQuestion:\n{questions}""",
'multihop_1' : """I will give you a question and a piece of context which consists of several articles, try your best extracting the answer from the context for the question as brief as possible.\n\nQuestion:{question}\n\nContext:\n{context}""",
'multihop_reason_1' : """I will give you a question and a piece of context which consists of several articles, please answer the question and give me your reasoning process.\n\nQuestion:{question}\n\nContext:\n{context}""",
}
alphabets = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
alphabet2index = {alphabet: index for index, alphabet in enumerate(alphabets)}
timeout = 60
race_interval_between_questions = 5
race_interval_between_articles = 180
squad_interval_between_articles = 120
hotpotqa_interval_between_questions = 120
def __init__(self, **kwargs):
for key, value in kwargs.items():
self.__setattr__(key, value)
def headers_to_dict(headers: str) -> dict:
lines = headers.splitlines()
headers_dict = {}
for line in lines:
key, value = line.strip().split(':', 1)
headers_dict[key.strip()] = value.strip()
return headers_dict
def generate_content(self, content_type: str, **kwargs) -> str:
assert content_type in self.prompt_templates, f'Expect param `content_type` in {list(self.prompt_template.keys())} but got {content_type}'
if content_type in ['single_choice_1', 'multi_choice_1']:
# Parse kwargs
article = kwargs['article'] # Str
question = kwargs['question'] # Str
options = kwargs['options'] # List[Str]
# Generate options string
options_string = str()
for i in range(len(options)):
options_string += f'{self.alphabets[i]}. {options[i]}\n'
options_string = options_string.rstrip('\n')
# Fill in the template
prompt_template = self.prompt_templates[content_type]
content = prompt_template.format(article=article, question=question, options=options_string)
elif content_type in ['single_choice_n', 'multi_choice_n']:
# Parse kwargs
article = kwargs['article'] # Str
questions = kwargs['questions'] # List[Str]
options_list = kwargs['options']# List[List[Str]]
assert len(questions) == len(options_list), f'Expect param `questions` and param `options` have the same length but got {questions} and {options}'
# Generate questions string
questions_string = str()
for question, options in zip(questions, options_list):
questions_string += f'Question: {question}\n'
for i in range(len(options)):
questions_string += f'{self.alphabets[i]}. {options[i]}\n'
questions_string += '-' * 64
questions_string += '\n'
questions_string = questions_string.rstrip('\n').rstrip('-')
# Fill in the template
prompt_template = self.prompt_templates[content_type]
content = prompt_template.format(article=article, questions=questions_string)
elif content_type in ['extractive_1']:
# Parse kwargs
article = kwargs['article'] # Str
question = kwargs['question'] # Str
# Fill in the template
prompt_template = self.prompt_templates[content_type]
content = prompt_template.format(article=article, question=question)
elif content_type in ['extractive_n']:
# Parse kwargs
article = kwargs['article'] # Str
questions = kwargs['questions'] # List[Str]
# Generate questions string
questions_string = str()
for i in range(len(questions)):
questions_string += f'{i + 1}. {questions[i]}\n'
# Fill in the template
prompt_template = self.prompt_templates[content_type]
content = prompt_template.format(article=article, questions=questions_string)
elif content_type in ['multihop_1', 'multihop_reason_1']:
# Parse kwargs
question = kwargs['question'] # List[Str]
context = kwargs['context'] # List[Tuple[Str, List[Str]]]
# Generate questions string
context_string = str()
for title, sentences in context:
article = ' '.join(sentences)
context_string += f"Title: {title}\nArticle: {article}\n"
context_string += '-' * 64
context_string += '\n'
context_string = context_string.rstrip('\n').rstrip('-')
# Fill in the template
prompt_template = self.prompt_templates[content_type]
content = prompt_template.format(article=article, question=question, context=context_string)
else:
raise NotImplementedError(f'{content_type}')
return content
def request(self, content: str) -> str:
response = str()
return response
def run_race_1(self, race_path, types, difficulties, export_path):
flag = False
if os.path.exists(export_path):
flag = True
exist_article_ids = pandas.read_csv(export_path, header=0, sep='\t')['article_id'].unique()
else:
columns = ['article_id', 'question_id', 'answer', 'response']
with open(export_path, 'w', encoding='utf8') as f:
f.write('\t'.join(columns) + '\n')
for type_ in types:
# train, dev, test
for difficulty in difficulties:
# high, middle
root = os.path.join(race_path, type_, difficulty)
for filename in os.listdir(root):
# Load data
with open(os.path.join(root, filename), 'r', encoding='utf8') as f:
data = json.load(f)
article_id = data['id']
if flag and article_id in exist_article_ids:
# Skip existed article_ids
continue
article = data['article']
questions = data['questions']
options = data['options']
answers = data['answers']
assert len(questions) == len(options) == len(answers), f'Expect the same length of (questions, options, answers) in RACE data but got ({questions}, {options}, {answers})'
for question_id, (question, option_list, answer) in enumerate(zip(questions, options, answers)):
print(f'{article_id} - {type_} - {answer}')
content = self.generate_content(content_type='single_choice_1', article=article, question=question, options=option_list)
response = self.request(content=content)
print(response)
response = response.replace('\n', '||')
with open(export_path, 'a', encoding='utf8') as f:
f.write(f'{article_id}\t{question_id}\t{answer}\t{response}\n')
time.sleep(self.race_interval_between_questions)
interval = random.randint(self.race_interval_between_articles / 2, self.race_interval_between_articles * 1.5)
print(f'Waiting {interval} seconds for next article ...')
time.sleep(interval)
def run_race_n(self, race_path, types, difficulties, export_path):
flag = False
if os.path.exists(export_path):
flag = True
exist_article_ids = pandas.read_csv(export_path, header=0, sep='\t')['article_id'].unique()
else:
columns = ['article_id', 'answers', 'response']
with open(export_path, 'w', encoding='utf8') as f:
f.write('\t'.join(columns) + '\n')
for type_ in types:
# train, dev, test
for difficulty in difficulties:
# high, middle
root = os.path.join(race_path, type_, difficulty)
for filename in os.listdir(root):
# Load data
with open(os.path.join(root, filename), 'r', encoding='utf8') as f:
data = json.load(f)
article_id = data['id']
if flag and article_id in exist_article_ids:
# Skip existed article_ids
continue
article = data['article']
questions = data['questions']
options = data['options']
answers = data['answers']
assert len(questions) == len(options) == len(answers), f'Expect the same length of (questions, options, answers) in RACE data but got ({questions}, {options}, {answers})'
print(f'{article_id} - {type_} - {answers}')
content = self.generate_content(content_type='single_choice_n', article=article, questions=questions, options=options)
response = self.request(content=content)
print(response)
response = response.replace('\n', '||')
with open(export_path, 'a', encoding='utf8') as f:
f.write(f'{article_id}\t{answers}\t{response}\n')
interval = random.randint(self.race_interval_between_articles * .5, self.race_interval_between_articles * 1.5)
print(f'Waiting {interval} seconds for next article ...')
time.sleep(interval)
def run_squad_n(self, squad_path, types, versions, export_path):
flag = False
if os.path.exists(export_path):
flag = True
exist_article_ids = pandas.read_csv(export_path, header=0, sep='\t')['article_id'].unique()
else:
columns = ['article_id', 'answers', 'response']
with open(export_path, 'w', encoding='utf8') as f:
f.write('\t'.join(columns) + '\n')
# Read preprocessed data
squad_article_dataframe = pandas.read_csv(os.path.join(squad_path, 'preprocessed', 'squad_article.csv'), sep='\t', header=0, dtype=str)
squad_question_dataframe = pandas.read_csv(os.path.join(squad_path, 'preprocessed', 'squad_question.csv'), sep='\t', header=0, dtype=str)
# Filter by types and versions
squad_article_dataframe = squad_article_dataframe[(squad_article_dataframe['type'].isin(types)) & (squad_article_dataframe['version'].isin(versions))].reset_index(drop=True)
for i in range(squad_article_dataframe.shape[0]):
article_id = squad_article_dataframe.loc[i, 'article_id']
if flag and (article_id in exist_article_ids):
# Skip existed article_ids
continue
filtered_question_dataframe = squad_question_dataframe[squad_question_dataframe['article_id'] == article_id]
article = squad_article_dataframe.loc[i, 'article']
questions = filtered_question_dataframe['question'].tolist()
answers = '||'.join(filtered_question_dataframe['answers'].tolist())
print(f'{article_id} - {answers}')
content = self.generate_content(content_type='extractive_n', article=article, questions=questions)
response = self.request(content)
print(response)
response = response.replace('\n', '||')
with open(export_path, 'a', encoding='utf8') as f:
f.write(f'{article_id}\t{answers}\t{response}\n')
interval = random.randint(self.squad_interval_between_articles * .5, self.squad_interval_between_articles * 1.5)
print(f'Waiting {interval} seconds for next article ...')
time.sleep(interval)
def run_hotpotqa_1(self, hotpotqa_path, filename, export_path, reasoning=True):
flag = False
if os.path.exists(export_path):
flag = True
exist_ids = pandas.read_csv(export_path, header=0, sep='\t')['id'].unique()
else:
columns = ['id', 'answer', 'response', 'type', 'level']
with open(export_path, 'w', encoding='utf8') as f:
f.write('\t'.join(columns) + '\n')
# Determine content type
content_type = 'multihop_reason_1' if reasoning else 'multihop_1'
# Read HotpotQA data
with open(os.path.join(hotpotqa_path, filename), 'r', encoding='utf8') as f:
data = json.load(f)
columns = ['_id', 'question', 'context', 'supporting_facts', 'answer', 'type', 'level']
for datum in data:
id_ = datum['_id']
question = datum['question']
context = datum['context']
answer = datum.get('answer') # Maynot in test file
type_ = datum.get('type') # Maynot in test file
level = datum.get('level') # Maynot in test file
print(f'{id_} - {answer}')
content = self.generate_content(content_type=content_type, question=question, context=context)
response = self.request(content)
print(response)
response = response.replace('\n', '||')
with open(export_path, 'a', encoding='utf8') as f:
f.write(f'{id_}\t{answer}\t{response}\t{type_}\t{level}\n')
interval = random.randint(self.hotpotqa_interval_between_questions * .5, self.hotpotqa_interval_between_questions * 1.5)
print(f'Waiting {interval} seconds for next article ...')
time.sleep(interval)
if __name__ == '__main__':
race_path = 'D:/resource/data/RACE'
squad_path = 'D:/resource/data/SQuAD'
hotpotqa_path = 'D:/resource/data/HotpotQA'
crawler = BaseCrawler()
# crawler.run_race_1(race_path, ['test'], ['high'], 'test-race-1.csv')
# crawler.run_race_n(race_path, ['test'], ['high'], 'test-race-n.csv')
# crawler.run_squad_n(squad_path, ['train'], ['2.0'], 'test-run-squad-n.csv')
crawler.run_hotpotqa_1(hotpotqa_path, 'hotpot_dev_fullwiki_v1.json', 'test-hotpot_dev_fullwiki_v1.csv', reasoning=True)
20230524~20230525
- 昨天不舒服得很,早上起来喉咙疼(其实前天就有点点疼),下午头也疼,估计是阳了,但是抗原测下来是阴的,我也没办法,只好早点回去睡了。结果今天又基本上康复了,虽然还有点疼,但是精神不错,胃口也没啥问题。二阳果然是又轻又快。
- 晚上本学期最后一次例训,周末东哥要去参加上海市高校教职工运动会了,神奇的是东哥今天独自测试3000米,跑出11’45"的超级成绩,这下真要拿捏不住东哥了。
- 8组×20个弹力蛙跳;
- 10组×30次交替箭步跳;
- 北欧挺试做:其实除了刘星宇根本没人做得起来,这玩意儿太依赖大腿后侧,而且是离心训练,力量不足大腿很容易就抽筋;
- 4组×20次两头起:每天我睡前坚持40个两头起+3分钟平板支撑,发现天天练是不一样,好多练短跑的、腹肌很明显的做到后面腿都伸不直了,而我都是相当标准,又被东哥夸了一次核心力量还行,然而我到现在还是一整块腹肌…
- 核心训练组×2(四肢撑,单手双脚×2,双手单脚×2,单手单脚×2,每个动作20秒,臀桥1分钟)
- 深蹲跳2组×20个
- 最后慢跑2000米:虽然每次都是说慢跑,但是长跑组永远是一路狂冲,7’58"冲完2000米,心肺极限,宋镇均日常不讲武德,开头说跟不住,最后一圈就超我。
一些huggingface模型示例:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import gc
import torch
from transformers import (pipeline,
RobertaTokenizer,
RobertaForMultipleChoice,
LongformerTokenizer,
LongformerForMultipleChoice,
)
# https://huggingface.co/LIAMF-USP/roberta-large-finetuned-race
def load_roberta_large_finetuned_race(model_path='LIAMF-USP/roberta-large-finetuned-race', device='cpu'):
# Load model
tokenizer = RobertaTokenizer.from_pretrained(model_path)
model = RobertaForMultipleChoice.from_pretrained(model_path).to(device)
return tokenizer, model
# https://huggingface.co/potsawee/longformer-large-4096-answering-race
def load_longformer_large_4096_answering_race(model_path='potsawee/longformer-large-4096-answering-race', device='cpu'):
# Load model
tokenizer = LongformerTokenizer.from_pretrained(model_path)
model = LongformerForMultipleChoice.from_pretrained(model_path).to(device)
return tokenizer, model
def test_roberta_large_finetuned_race(data, tokenizer, model, max_length=512):
# Unpack data
articles = data['article']
questions = data['question']
options = data['options']
# Preprocess inputs
batch_inputs = list()
for article, question, option in zip(articles, questions, options):
flag = question.find('_') == -1
inputs = list()
for choice in option:
question_choice = question + ' ' + choice if flag else question.replace('_', choice)
input_ = tokenizer(article,
question_choice,
add_special_tokens=True,
max_length=max_length,
padding='max_length',
truncation=True,
return_overflowing_tokens=False,
)
inputs.append(input_)
batch_inputs.append(inputs)
model_inputs = {'input_ids' : torch.cat([[input_['input_ids'] for input_ in inputs] for inputs in batch_inputs]),
'attention_mask': torch.cat([[input_['attention_mask'] for input_ in inputs] for inputs in batch_inputs]),
}
del batch_inputs
# Run model
batch_logits = model(**model_inputs).logits
del model_inputs
gc.collect()
batch_predicts = ['ABCD'[torch.argmax(logits).item()] for logits in batch_logits]
return batch_logits, batch_predicts
def test_longformer_large_4096_answering_race(data, tokenizer, model, max_length=4096):
articles = data['article']
questions = data['question']
options = data['options']
batch_inputs = list()
for article, question, option in zip(articles, questions, options):
article_question = [f'{question} {tokenizer.bos_token} article'] * 4
inputs = tokenizer(article_question,
option,
max_length=max_length,
padding='longest',
truncation=True,
return_tensors='pt',
) # (4, m ax_length)
batch_inputs.append(inputs)
print([inputs['input_ids'] for inputs in batch_inputs])
model_inputs = {'input_ids' : torch.cat([inputs['input_ids'].unsqueeze(0) for inputs in batch_inputs], axis=0),
'attention_mask': torch.cat([inputs['attention_mask'].unsqueeze(0) for inputs in batch_inputs], axis=0),
}
del batch_inputs
batch_logits = model(**model_inputs).logits
del model_inputs
gc.collect()
batch_predicts = ['ABCD'[torch.argmax(logits).item()] for logits in batch_logits]
return batch_logits, batch_predicts
# https://huggingface.co/deepset/roberta-base-squad2
def test_roberta_base_squad2(data, tokenizer, model):
question_answering_pipeline = pipeline('question-answering', model=model, tokenizer=tokenizer)
articles = data['articles']
questions = data['questions']
inputs = {'question': questions, 'context': articles}
batch_results = question_answering_pipeline(inputs)
return batch_results
20230526~20230528
- 其实没有好的那么快,周五下午5分配慢摇13圈接200双摇之后,喉咙明显又疼得重了些,而且咳得也厉害了些,连着几天都好不了,有点烦心,权且休整两日。
- 东哥下午比赛,一点半男子400米,两点半男子3000米。本来男子组分成青年组和中青年组,分界线是1988年1月1日出生,东哥刚好卡在青年组,所以要跟一堆20多岁刚毕业的体育老师比。400米58"95第三,3000米12’12"60第七,400米应该算是大幅超过预期,之前训练时未能打开60秒大关,所以说后面3000米就没力气了,而且今天太热,3000米虽然不长,但也很痛苦的。
- 五点趁太阳下山去想去晃会儿,偶然碰到一个陌生的年轻男子在跑,看跑姿和腿上的肌肉显然是老手了,跟着一起跑了4000米,他起手能跑到4’25"左右的配速,后面逐渐掉到4’50",所以即便穿衬衫和 休闲鞋也跟得很轻松,正想上前问他想跑多久,跟了半天准备带他跑个后半段,他就突然退出了,有点扫兴,后来问了才知道是商学院得MBA,果然是马协的人。
- 突然想到上次东哥说李奇宽(人称AK,2015级商院本硕,身高158,跟李婷玉差不多高,但全马pb238,半马pb117,5000米全国大学生运动会跑到17’10",不过估计最近水平下滑的厉害,但是全马破三还是简简单单)辞职来财大科技园创业,跟着几个马协的MBA一起来,最近校门管得比较宽,能有机会能碰到一定好好上个强度。
目前还有一个重要的点是构建基于本地知识库的问答,已经有很多开源的项目在做这块内容,因为大模型的一个问题就是对强业务性逻辑,以及高难度算术问题的处理能力是不足的,所以引入本地知识库对大模型的上下文进行约束也是很热的点,我想是可以和前面的内容串成线的,一个很简单的想法是,前面的思路在做挖掘模型的缺陷,对模型进行有效攻击,避免这种缺陷的本质是让模型更注重上下文,而非本身预训练中的常识。
kb+llm 参考内容:
https://www.bilibili.com/video/BV11N411y7dT/
https://www.bilibili.com/video/BV1t24y1T7BB
另外langchain这个东西,虽然偏向于脚本式的工具,着重于训练前的输入预处理,以及输入输出间的管道衔接,本身并没有很多创造性,但是可以预见到接下来会是它的主场,就有点像transformers这个库在做的事情,还是很关键的。
20230529~20230530
- 我好像已经喉咙疼了一周了,还是没有完全好,虽然不打紧,但是最近睡前总是要干咳上五六次,而且食欲不是很好,清淡地吃了几天。这两天气温骤升之后,连着三四天慢跑10圈得以维持,又是开题答辩的节点上,天天都要搞到11点多才回去,精神状态不是很理想。
- 但有时候觉得这样慢跑也挺享受的,虽然对水平已经没有多大提升。尤其最近两天特别热,都是晚上八九点抽空下楼清一下脑子,实验室开着空调却很闷,外头热风却也算是凉快,用4’40~4’50"的配速绕操场跑十圈,纯热身强度,也懒得浪费时间拉伸,不到20分钟就能完事,高效训练不拖沓(笑,现在手表已经在提醒我该恢复训练了)。
- 争先容易躺平难呐,生活总是向着越来越单一的曲调行进,现在就开始指着下半年的比赛。嘉伟之前跟我说要去跑上马,现在我有成绩也是大概率可以中签的。其实心里很清楚,全马对跑量的要求极高,全马跑者月跑量至少也是200km以上,300~500km都是常态,一天一个半马大有人在。像我们现在这样月跑量勉强过百的,远远达不到具备完赛全马的能力,而有能力跑半马,很大程度上也只是年轻力盛罢了,但总归全马对于跑者来说,是一个至高殿堂的存在,至少这一生注定是要跑一次的。
- 唯一得以欣慰的就是现在终于把每个构思点都串成了线,而且目前正在做的这个点也有了相对完善的结果,应该是足够撑起一篇东西了。
Langchain-ChatGLM构建本地化知识库问答系统(https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui),尝试了一下,detectron2虽然没有windows系统的安装包,估计很多人都部署不了,看到一个大佬教改acaconda和detectron2安装包里的c++源码,终于得以装成功,挂个教程链接:https://www.bilibili.com/read/cv18090313
但是尝试下来问题很大,首先所谓的知识库,原来只是支持txt或者md文件,而且连特殊字符都不能包含,pdf也不支持,此外输入长度太有限,虽然没有细看源码,但是我估计就是稍微处理了一下文件内容,然后直接跟问题一起输入到chatglm里去,而且预处理这一步直接用langchain,总觉得并没有什么技术含量…
总感觉ChatGLM就和2月份的MOSS差不多,6B的参数量其实真的做不了什么,理想中的知识库问答,应该能够接上数据库才行,这才是具有实用意义的。而且发现最近似乎没什么人提知识图谱。
20230531
- 到今天基本上身体是完全复原了,前几天胃口不好,消化得也差,吃的不多,晚上睡前都还老是觉得很撑,健康真的比什么都重要。
- 这两天开始熬到12点多才回三门路,事情做不完,午觉还睡不着,略有烦心。
- 今天补量到6000米,配速稍微拉了一些到4’30",总归也不想天天养生跑(已经养生跑了一周了,上次认真跑还是上周四最后一次训练)。气温不算很高,但闷热得很,状态也一般,还是有点吃力。中途看到卢星雨来跑,平时训练时看不大出来,夏天光腿果然看起来是壮实得很,她昨晚4’58"配速跑了8000米,恐怖如斯,这水平足以吊打学校里99%的男生,不愧是上能跟男生一起冲400/1000间歇,下能深蹲90kg的猛女。(有时候想想人和人的差距是真的大)
代码记录:RACE和SQuAD
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import json
def yield_race_sample(race_path, types, difficulties, batch_size=1):
current_batch_size = 0
batch_data = list()
for type_ in types:
# train, dev, test
for difficulty in difficulties:
# high, middle
data_path = os.path.join(race_path, type_, difficulty)
for filename in os.listdir(data_path):
with open(os.path.join(data_path, filename), 'r', encoding='utf8') as f:
data = json.load(f)
article_id = data['id']
article = data['article']
questions = data['questions']
options = data['options']
answers = data['answers']
# Ensure the number of questions, options and answers are the same
n_questions = len(questions)
n_options = len(options)
n_answers = len(answers)
assert n_options == n_questions == n_answers, f'Dismatch of the number of questions({n_questions}), options({n_options}) and answers({n_answers})!'
# Ensure id in data matches filename
assert article_id == difficulty + filename, f'Dismatch of id and filename: {article_id} v.s. {difficulty + filename}!'
for question_id, (question, option, answer) in enumerate(zip(questions, options, answers)):
# Ensure total option is 4
n_choices = len(option)
assert n_choices == 4, f'There are {len(n_choices)} choices in the option!'
# @return article_id : "high1.txt"
# @return question_id : 0
# @return article : "My husband is a born shopper. He ..."
# @return question : "The husband likes shopping because _ ."
# @return option : ["he has much money.", "he likes the shops.", "he likes to compare the prices between the same items.", "he has nothing to do but shopping."]
# @return answer : 'C'
current_batch_size += 1
batch_data.append({'article_id' : article_id,
'question_id': question_id,
'article' : article,
'question' : question,
'option' : option,
'answer' : answer,
})
if current_batch_size == batch_size:
yield batch_data
current_batch_size = 0
batch_data = list()
if current_batch_size > 0:
# Final batch
yield batch_data
def yield_squad_sample(squad_path, type_, version, batch_size=1):
current_batch_size = 0
batch_data = list()
with open(os.path.join(squad_path, f'squad{version}', f'{type_}-v{version}.json'), 'r', encoding='utf8') as f:
data = json.load(f)
count = -1
for sample in data['data']:
title = sample['title']
paragraphs = sample['paragraphs']
for paragraph in paragraphs:
count += 1
article_id = f'{type_}-{version}-{str(count).zfill(5)}'
article = paragraph['context']
for question_and_answer in paragraph['qas']:
question_id = question_and_answer['id']
question = question_and_answer['question']
candidate_answers = question_and_answer['answers']
answer_starts = list()
answer_ends = list()
answers = list()
for candidate_answer in candidate_answers:
answer_start = int(candidate_answer['answer_start'])
answer = candidate_answer['text']
answer_end = answer_start + len(answer)
# assert answer == article[answer_start: answer_end]
answer_starts.append(answer_start)
answer_ends.append(answer_end)
answers.append(answer)
# @return article_id : "train-1.1-00000"
# @return question_id : "5733be284776f41900661182"
# @return title : "University_of_Notre_Dame"
# @return article : "Architecturally, the school has a Catholic character. Atop ..."
# @return question : "To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?"
# @return answers : ["Saint Bernadette Soubirous"]
# @return answer_starts : [515]
# @return answer_ends : [541]
current_batch_size += 1
batch_data.append({'article_id' : article_id,
'question_id' : question_id,
'title' : title,
'article' : article,
'question' : question,
'answers' : answers,
'answer_starts' : answer_starts,
'answer_ends' : answer_ends,
})
if current_batch_size == batch_size:
yield batch_data
current_batch_size = 0
batch_data = list()
if current_batch_size > 0:
# Final batch
yield batch_data
20230601
- 今天是4’07"配速的4000米,加200个双摇。近一周以来第一次换跑鞋想认真跑一次(尽管被飞飙361坑了两次脚,但还是想再给它一次机会,主要发现Vaporfly NEXT%碳板底有点脱落,怕不是买到假鞋了),但是天热,状态也不佳(连续三天十二点之后回三门路,再往前几天也是要弄到十一点多,而且最近午觉是真的是怎么都睡不着,十分苦恼),总是事与愿违。
- 主要最近每天都能看到卢星雨在训练,我觉得自己怎么也不该偷懒,再忙再累也得抽时间去操场跑会儿,就算是高压之下的垃圾跑量,也权当是一种慰藉,真的累了。可惜我俩习惯的配速差太多,要不然跟着一起陪跑自然要轻松些,尤其是这种闷热的夏夜。
微调是一门学问,学习率,轮数,batchsize都会极大的影响微调的效果,这个算是值得多轮测试找最优的了。最近看到一篇工作说,微调其实可以理解为参数向着目标方向的移动,所以有时候可以考虑把微调后的方向和步长加以记录,就可以在未来可能遇到的多任务微调上直接使用矢量加法来快速得到微调后的结果,而不需要重复训练模型。
20230602
- 下午五点彻底搞完开题报告,25000字,32多页,光综述就写了10页,紧绷了快一周的神经终于松了些。下楼吃个饭跟陈发端看了一下计赛项目,他们手上的医疗数据对我的领域问答系统很重要,我有计划对罕见病问答、以及excel表的信息问答方向着手。不过也是授人以渔,我也想带一下这两个小家伙,让他们尽早能跟上现在发展的潮流,想我大二的时候还在玩泥巴,到大三才慢慢有了些几个国奖市奖傍身,他们现在就已经能碰到大模型了,顺便也是强化一下web开发技术。
- 早上吃早饭碰到宋习缘,很是意外,又有些欣喜,我一直以为她早就搬出去了,她前阵子一直在旅游,先是五一去武汉人从众𠈌了一波,表示再也不愿意去武汉,然后五月底又沿重庆—恩施—宜昌一线玩了一周,大概是论文答辩完出去散了一波心吧。一直以为后会无期,老天还是给了我留下了些缱绻,其实也就两个月没见,总觉得宋习缘更少了从前的那份朝气,更多的成熟(其实当面我没敢说,但是总觉得是胖了…)。人总在变,可是当年月光,依旧皎白。
- 原因是昨晚熬到十二点半回三门路,挑灯写日记时突然想到,到我们这个年纪还单身的人指定是性格上有缺陷。我自己自闭又不擅长打交道,还老是钻牛角尖,然后我就想到宋习缘和卢星雨,后者大概是因为高处不胜寒,前者呢?我认识的女生多属高智群体,说实话都挺有些女性主义倾向,而且我最近听了好多博士论文答辩,尤其是女博士的论文,好多都会研究性别歧视与偏见的问题,把女性主义写在研究意义中。说实话我觉得还挺可怕,但是当发现很多人都这样时,那这就不是什么问题,而是必须适应的现实。性别之间的尊重是建立在相互的基础上,然而价值观的不对等却总是破坏这种脆弱的平衡,说白了还是得三观相合,还有就是鲁棒性得强些,能容忍一些分布外的事件。占有太强便失了些距离美,然无欲无求也不可取。
- 晚上八点半,趁肝完开题的节点放松心情,冲了一个5000米,4’08"配速,太热太热,晚上都热得不行,一个人真的顶不到万米,最近天天熬夜,又睡不着午觉,最后1000米真的是硬顶着意志在扛,心肺都快炸了。我这两天一定要好好休息,把这周熬掉的状态找回来,这个周末无论如何认真跑一次10000米,重振跑者精神。
最近chatglm发布了Langchain+chatglm的本地部署教程:https://www.bilibili.com/video/BV13M4y1e7cN
另外还有可以识别X光片的XrayGLM方法的教程https://www.bilibili.com/video/BV1Yh4y147gx,值得跟进。
最近学到一个很有用的windows创建文件映射的方法:
New-Item -ItemType SymbolicLink -Path D:\code\python\project\caoyang\project_014_mrc\machine-reading-comprehension\multichoice\model\parser_model\stanford_parser\stanford-parser.jar -Target D:\resource\model\stanford\software\stanford-parser-full-2020-11-17\stanford-parser.jar
原因是很多项目的数据是需要共享的,如果数据存在外部,要写绝对路径,不方便,如果存在项目里,虽然可以用相对路径,但是其他项目调用起来很麻烦,所以可以用创建文件映像的方法。
比如你将D:/data文件夹映射到D:/project/data,那么其实就默认有D:/project/data/*这样的路径了,不影响os.listdir以及os.path.exists的判断。
20230603
- 午觉暴睡3小时,昏天黑地,傍晚姨娘又特贴心地送了炖鸡汤和大虾来,直接满血满蓝复活。晚上六点半按原计划认真跑一次强度,然不如愿,4’15"配速仅坚持到8000米,用时34分整,我是真的一个人顶不到万米啊!!!好扎心好难受,练了这么久是真的看不到长进,明明核心力量比以前强多了,自我感觉上半身跑得很稳,但就是顶不住强度,真整不会了呀[Facepalm]
RACE官方process源码
import json
import datasets
_CITATION = """\
@article{lai2017large,
title={RACE: Large-scale ReAding Comprehension Dataset From Examinations},
author={Lai, Guokun and Xie, Qizhe and Liu, Hanxiao and Yang, Yiming and Hovy, Eduard},
journal={arXiv preprint arXiv:1704.04683},
year={2017}
}
"""
_DESCRIPTION = """\
Race is a large-scale reading comprehension dataset with more than 28,000 passages and nearly 100,000 questions. The
dataset is collected from English examinations in China, which are designed for middle school and high school students.
The dataset can be served as the training and test sets for machine comprehension.
"""
_URL = "http://www.cs.cmu.edu/~glai1/data/race/RACE.tar.gz"
class Race(datasets.GeneratorBasedBuilder):
"""ReAding Comprehension Dataset From Examination dataset from CMU"""
VERSION = datasets.Version("0.1.0")
BUILDER_CONFIGS = [
datasets.BuilderConfig(name="high", description="Exams designed for high school students", version=VERSION),
datasets.BuilderConfig(
name="middle", description="Exams designed for middle school students", version=VERSION
),
datasets.BuilderConfig(
name="all", description="Exams designed for both high school and middle school students", version=VERSION
),
]
def _info(self):
return datasets.DatasetInfo(
# This is the description that will appear on the datasets page.
description=_DESCRIPTION,
# datasets.features.FeatureConnectors
features=datasets.Features(
{
"example_id": datasets.Value("string"),
"article": datasets.Value("string"),
"answer": datasets.Value("string"),
"question": datasets.Value("string"),
"options": datasets.features.Sequence(datasets.Value("string"))
# These are the features of your dataset like images, labels ...
}
),
# If there's a common (input, target) tuple from the features,
# specify them here. They'll be used if as_supervised=True in
# builder.as_dataset.
supervised_keys=None,
# Homepage of the dataset for documentation
homepage="http://www.cs.cmu.edu/~glai1/data/race/",
citation=_CITATION,
)
def _split_generators(self, dl_manager):
"""Returns SplitGenerators."""
# Downloads the data and defines the splits
# dl_manager is a datasets.download.DownloadManager that can be used to
archive = dl_manager.download(_URL)
case = str(self.config.name)
if case == "all":
case = ""
return [
datasets.SplitGenerator(
name=datasets.Split.TEST,
# These kwargs will be passed to _generate_examples
gen_kwargs={"train_test_or_eval": f"RACE/test/{case}", "files": dl_manager.iter_archive(archive)},
),
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
# These kwargs will be passed to _generate_examples
gen_kwargs={"train_test_or_eval": f"RACE/train/{case}", "files": dl_manager.iter_archive(archive)},
),
datasets.SplitGenerator(
name=datasets.Split.VALIDATION,
# These kwargs will be passed to _generate_examples
gen_kwargs={"train_test_or_eval": f"RACE/dev/{case}", "files": dl_manager.iter_archive(archive)},
),
]
def _generate_examples(self, train_test_or_eval, files):
"""Yields examples."""
for file_idx, (path, f) in enumerate(files):
if path.startswith(train_test_or_eval) and path.endswith(".txt"):
data = json.loads(f.read().decode("utf-8"))
questions = data["questions"]
answers = data["answers"]
options = data["options"]
for i in range(len(questions)):
question = questions[i]
answer = answers[i]
option = options[i]
yield f"{file_idx}_{i}", {
"example_id": data["id"],
"article": data["article"],
"question": question,
"answer": answer,
"options": option,
}
20230604
- 本想跑休,但实在是太凉快了,不练我问心有愧,但昨天全力跑后,今天明显状态没那么猛,勉强3000米12’20",接212个双摇(第一组80个,后面都是50个一组跳,直到跳不动为止),也只得望洋兴叹。
- 早上被王英林叫去莲花路聚餐(结果在读就我一个二愣子去了,我都快累死了这几天,明天就要答辩,还在赶ppt),大大师兄张建章从杭州回来拜访王英林(其实王明是90年的,前年毕业,比张建章93年要大,但是张建章20年就毕业了,所以其实我之前只见过张建章一次),哼哧哼哧地跑到闵大荒,总归颇有所得。建章现在阿里商学院担任讲师,不过说实话以前他们研究的那一套语义消歧、本体识别的技术,这个年代已经没啥大用了,时代的潮流在捶打我们这帮顶在峰尖浪口的人,不进则废。
最近测出一个很有用的结果,BCOPA-CE数据集(这个是师姐韩明月做的一个关于因果关系识别的数据集,不过难度非常大,人类也很容易选错,数据地址在https://paperswithcode.com/dataset/bcopa-ce),韩明月当时做出的最好模型能达到83.7的准确率,但chatgpt仅有不足70%的准确率,这意味着这种更贴近人类主观难度的问题上,其实gpt做的并不好,现在的共识是认为gpt并没有对齐人类价值,通俗的讲就是没有建立起一个很好的三观。
20230605
- 晚饭后40分钟7000米慢摇,心率不超过135,我觉得这么摇个两三个小时不是啥事儿。
- 梅雨季,虽然体感凉爽,但低压湿闷,极易脱水,慢摇确也是极好的。
gradio看起来是目前跟深度学习方法的应用结合最多的web部署架构了,不管是stable diffusion还是chatGLM的webui,都是用的gradio进行架构,这玩意儿看下来上手很容易,可以看作是把前后端并到一个框架里搞定了。
另外https://github.com/WangRongsheng/XrayGLM值得关注,澳门理工做的一个X光片自动诊断开源项目,还开源了不少X光报告与图像的数据对,其实是别人开源的,他们只是做了报告英译中的工作,而且是让chatgpt来做的翻译:
X光片报告开源数据:https://physionet.org/content/mimic-cxr-jpg/2.0.0/
简单记录几个小demo:
- 上传图像进行分类的toy example
import gradio as gr
def image_classifier(inp):
return {'cat': 0.3, 'dog': 0.7}
demo = gr.Interface(fn=image_classifier, inputs="image", outputs="label")
demo.launch()
- 文本框
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
if __name__ == "__main__":
demo.launch()
- 图像上传
import gradio as gr
def image_classifier(inp):
return {'cat': 0.3, 'dog': 0.7}
demo = gr.Interface(fn=image_classifier, inputs="image", outputs="label")
demo.launch()
滚动条
import gradio as gr
def greet(name, is_morning, temperature):
salutation = "Good morning" if is_morning else "Good evening"
greeting = f"{salutation} {name}. It is {temperature} degrees today"
celsius = (temperature - 32) * 5 / 9
return greeting, round(celsius, 2)
demo = gr.Interface(
fn=greet,
inputs=["text", "checkbox", gr.Slider(0, 100)],
outputs=["text", "number"],
)
if __name__ == "__main__":
demo.launch()
20230606
- 晚上下组会,九点多摇了4000米,铁混子,最近差不多有半个月,每天都至少4000米以上的量,三四月份都没这么勤快过,但毫无质量,一旦接受了养老的现实,六分配都不在话下。每天都想着要冲刺
- 组里又新进了一个博士王京,这下2023级就是两个博士了,王英林可真是老当益壮啊,总觉得王英林这人跟我很像,精力充沛的时候就啥事都能干,萎靡的时候就完全找不到他人,push全靠自己。
- 明天开题答辩,我觉得英文slide会更专业而且可以写得更简洁,王英林非要觉得中文好,只能由着他来。晚上回来想想还是把写个讲稿,毕竟只给15分钟时间,还是很紧张的,结果一写又写到一点(最近熬得真的太多了,感觉生物钟调不回来了,只能天天靠午觉补状态)。以前每次这种限时的汇报都跪得很惨,这次多费点事,少吃点瘪。
模型测试脚本更新:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import gc
from transformers import (pipeline,
AutoTokenizer,
AutoModel,
AutoModelForQuestionAnswering,
RobertaTokenizer,
RobertaForMultipleChoice,
LongformerTokenizer,
LongformerForMultipleChoice,
)
# https://huggingface.co/LIAMF-USP/roberta-large-finetuned-race
def load_roberta_large_finetuned_race(model_path='LIAMF-USP/roberta-large-finetuned-race', device='cpu'):
tokenizer = RobertaTokenizer.from_pretrained(model_path) # Load tokenizer
model = RobertaForMultipleChoice.from_pretrained(model_path).to(device) # Load model
return tokenizer, model
# https://huggingface.co/potsawee/longformer-large-4096-answering-race
def load_longformer_large_4096_answering_race(model_path='potsawee/longformer-large-4096-answering-race', device='cpu'):
tokenizer = LongformerTokenizer.from_pretrained(model_path) # Load tokenizer
model = LongformerForMultipleChoice.from_pretrained(model_path).to(device) # Load model
return tokenizer, model
# https://huggingface.co/deepset/roberta-base-squad2
def load_roberta_base_squad2(model_path='deepset/roberta-base-squad2', device='cpu'):
# Load pipeline
tokenizer = AutoTokenizer.from_pretrained(model_path) # Load tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_path) # Load model
return tokenizer, model
# https://huggingface.co/THUDM/chatglm-6b
# https://huggingface.co/THUDM/chatglm-6b-int4
# https://huggingface.co/THUDM/chatglm-6b-int4-qe
# https://huggingface.co/THUDM/chatglm-6b-int8
# Note: The series of chatglm-6b-xxx models cannot run on CPU
# You can quantize with `model = model.quantize(4)` or `model = model.quantize(8)` for low GPU memory
def load_chatglm_6b(model_path='THUDM/chatglm-6b', device='cuda'):
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) # Load tokenizer
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().to(device) # Load model
return tokenizer, model
# https://huggingface.co/THUDM/visualglm-6b
# Note: The series of chatglm-6b-xxx models cannot run on CPU
# You can quantize with `model = model.quantize(4)` or `model = model.quantize(8)` for low GPU memory
def load_visualglm_6b(model_path='THUDM/visualglm-6b', device='cuda', half_precision=True, quantize=None):
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) # Load tokenizer
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().to(device) # Load model
return tokenizer, model
# @param data : Dict[article(List[Str]), question(List[Str]), options(List[List[Str]])]
# @return batch_logits : FloatTensor(batch_size, 4)
# @return batch_predicts: List[Str] (batchsize, )
def run_roberta_large_finetuned_race(data, tokenizer, model, max_length=512):
# Unpack data
articles = data['article']
questions = data['question']
options = data['options']
# Preprocess inputs
batch_inputs = list()
for article, question, option in zip(articles, questions, options):
flag = question.find('_') == -1
inputs = list()
for choice in option:
question_choice = question + ' ' + choice if flag else question.replace('_', choice)
input_ = tokenizer(article,
question_choice,
add_special_tokens=True,
max_length=max_length,
padding='max_length',
truncation=True,
return_overflowing_tokens=False,
)
inputs.append(input_)
batch_inputs.append(inputs)
model_inputs = {'input_ids' : torch.cat([[input_['input_ids'] for input_ in inputs] for inputs in batch_inputs]),
'attention_mask': torch.cat([[input_['attention_mask'] for input_ in inputs] for inputs in batch_inputs]),
}
del batch_inputs
# Run model
batch_logits = model(**model_inputs).logits
del model_inputs
gc.collect()
batch_predicts = ['ABCD'[torch.argmax(logits).item()] for logits in batch_logits]
return batch_logits, batch_predicts
# @param data : Dict[article(List[Str]), question(List[Str]), options(List[List[Str]])]
# @return batch_logits : FloatTensor(batch_size, 4)
# @return batch_predicts: List[Str] (batchsize, )
def run_longformer_large_4096_answering_race(data, tokenizer, model, max_length=4096):
articles = data['article']
questions = data['question']
options = data['options']
batch_inputs = list()
for article, question, option in zip(articles, questions, options):
article_question = [f'{question} {tokenizer.bos_token} article'] * 4
inputs = tokenizer(article_question,
option,
max_length=max_length,
padding='longest',
truncation=True,
return_tensors='pt',
) # (4, max_length)
batch_inputs.append(inputs)
print([inputs['input_ids'] for inputs in batch_inputs])
model_inputs = {'input_ids' : torch.cat([inputs['input_ids'].unsqueeze(0) for inputs in batch_inputs], axis=0),
'attention_mask': torch.cat([inputs['attention_mask'].unsqueeze(0) for inputs in batch_inputs], axis=0),
}
del batch_inputs
batch_logits = model(**model_inputs).logits
del model_inputs
gc.collect()
batch_predicts = ['ABCD'[torch.argmax(logits).item()] for logits in batch_logits]
return batch_logits, batch_predicts
# @param data : Dict[article(List[Str]), question(List[Str])]
# @return batch_results : List[Str] (batchsize, )
def run_roberta_base_squad2(data, tokenizer, model):
question_answering_pipeline = pipeline('question-answering', model=model, tokenizer=tokenizer)
articles = data['articles']
questions = data['questions']
inputs = {'question': questions, 'context': articles}
batch_results = question_answering_pipeline(inputs)
gc.collect()
return batch_results
# @param data : Dict[content(Str)]
# @return response : Robot response
# @return history : Chat history
def run_chatglm_6b(data, tokenizer, model, history=list()):
content = data['content']
response, history = model.chat(tokenizer, content, history=history)
gc.collect()
return response, history
# @param data : Dict[iamge_path(Str), content(Str)]
# @return response : Robot response
# @return history : Chat history
def run_visualglm_6b(data, tokenizer, model, history=list()):
image_path = data['image_path']
content = data['content']
response, history = model.chat(tokenizer, image_path, content, history=history)
gc.collect()
return response, history
20230607
- 下午答辩完,这次写稿子念了几遍,刚好卡了个15分钟,比较完美,不过开题自然都是要被怼的,其实大家都半斤八两,现在这个时代,老师也不见得比学生会得更多,崔万云除外,对崔万云我是真的不服不行,虽然他课讲得不咋地,但确实懂得太多了,每次答辩最怕这家伙在场。
- 完事去跑了4000米,4’08"配速,闷得很,补120个双摇,又加了五圈变速,整体不是很吃力,状态很好,尤其是第一个4000米,留有余力,只是天气不太适合拼命,也就没逼自己硬刚万米。难得一见宋镇均来练,这货自从最后一次训练结束后,停跑了快两周,现在又萎得不行,5000米都坚持不下来,徐瀚韬也在,后来晚些时候刘颂杰来练400米间歇,最近一直能看到刘颂杰在练,卢星雨倒很久不见,估计在肝论文,但是我发现,我越忙就越能坚持每天去跑,反而有时候闲下来就懒得去练。
最近测了一下chatgpt司法考试的多选题,差得离谱,大概是40%左右的准确率,理由说得头头是道,一选全错,绷不住了。
用的数据集是19年就提出来的JEC-QA,jecqa.thunlp.org/,老生常谈的东西了已经是,看一个例子:
2_816 - 0 - 行政法与行政诉讼法 - D
下列对行政机关工作人员以殴打或其他暴力方式侵犯公民人身权利行为的阐述,正确的是哪项?
"A": "该行为属于违法的具体行政行为",
"B": "受害人有权提起行政赔偿诉讼",
"C": "受害人无权提起行政赔偿诉讼",
"D": "造成公民身体伤害或者死亡的,受害人或其继承人和其他有扶养关系的亲属有权提起行政赔偿诉讼"
答:
根据《中华人民共和国行政诉讼法》、《中华人民共和国赔偿法》等法律规定,正确选项为B和D。B选项是因为受害人可以向行政机关提
起行政赔偿诉讼,要求赔偿因工作人员行为受到的损失;D选项是因为造成公民身体伤害或者死亡的,受害人或其继承人和其他有扶养关 系的亲属可以向行政机关提起行政赔偿诉讼。因此,正确选项为B和D。
然后会发现有的问题chatgpt会说的前后矛盾,目前有一个相对广泛认可的共识,就是说生成式语言模型固有的缺陷就是胡说八道,毕竟本质是通过贪心解码、或是相对来说高级一些的束搜索方法找到的一个相对较优的局部最优解码,现在一个想法就是说,如果真的是全局最优的解码生成,是否能规避这种胡说八道的问题呢?或许是可行的,至少从统计角度上来说,应该是对的,但是GPT并不是简单地基于统计的解码模型,不可知其内部的运作逻辑,因此,这仍是值得商榷的。
就看有没有天降猛男能改变这个架构,理论上来说,向自回归生成中添加规则约束,或许是ok的。目前在关键领域的内容生成,还是需要人工核验的,效率并没有想象得那么高。
20230608
- 中午被王英林拉去开会,没睡到午觉,又热又困,晚饭后摇了8000米,42分钟,晒得略有难受。
- 王英林到现在接的一个个横向都不靠谱,这次勉强算是稍微靠点谱,我有不好的预感,这个月估计要写本子。
chatresearch崩了(https://www.chatanywhere.top/)!!!明明前几天还爬得很顺畅,实验室电脑连爬三四天都不断的。
好久不上OpenAI,发现OpenAI现在chatgpt对开vpn的也不开放了,打不过也加入不了了,想爬chatglm130b(chatglm.cn/)的聊天响应,发现chatglm的反爬做的是真的好,requests基本无解,试着用selenium搞了一下,不知为何手动拖滑动验证码始终无法通过,以前没有出现过这种问题,现在连滑动验证码都能检验是不是浏览器驱动了吗?
代码未完成:
class ChatGLMCrawler(BaseCrawler):
"""Currently ChatGLM-130B v0.8"""
cookies = {
'main': {'_ga' : 'GA1.1.1115444952.1686202937',
'_ga_PMD05MS2V9' : 'GS1.1.1686207391.2.0.1686207391.0.0.0',
'chatglm_token' : 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmcmVzaCI6ZmFsc2UsImlhdCI6MTY4NjIwMjk2NiwianRpIjoiMWNiOWJiZTItYmU5NS00MjIzLTlmNzYtMzcxYjUyZTliYWJmIiwidHlwZSI6InJlZnJlc2giLCJzdWIiOiJlZTVmYWM0NGIyNWQ0NzU1OTM1NWY5M2EyMDFmZjcxOCIsIm5iZiI6MTY4NjIwMjk2NiwiZXhwIjoxNzAxNzU0OTY2LCJyb2xlcyI6WyJ1bmF1dGhlZF91c2VyIl19.abMdLQv-uggI3jODqeGV359PiFdKWogJAKKFICEP0ro',
'chatglm_token' : 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmcmVzaCI6ZmFsc2UsImlhdCI6MTY4NjIwMjk2NiwianRpIjoiNzlhOGYxNTctMTc3My00Y2I0LWFmNGYtM2RjYmUyODYyYzZjIiwidHlwZSI6ImFjY2VzcyIsInN1YiI6ImVlNWZhYzQ0YjI1ZDQ3NTU5MzU1ZjkzYTIwMWZmNzE4IiwibmJmIjoxNjg2MjAyOTY2LCJleHAiOjE2ODYyODkzNjYsInJvbGVzIjpbInVuYXV0aGVkX3VzZXIiXX0.JxIhk_ZpIO44bX9_V1KiR94RHtwK5wIEfmdtwoqLhF8',
'chatglm_token_expires': '2023-06-08 15:42:45',
},
}
headers = {
'init': """Host: chatglm.cn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: _ga_PMD05MS2V9=GS1.1.1686231646.1.0.1686231646.0.0.0; _ga=GA1.1.1976488462.1686231647
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
If-Modified-Since: Thu, 08 Jun 2023 10:49:34 GMT
If-None-Match: W/"6481b23e-c6c"
TE: trailers""",
'code': """Host: chatglm.cn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Content-Type: application/json;charset=utf-8
Content-Length: 75
Origin: https://chatglm.cn
Connection: keep-alive
Referer: https://chatglm.cn/
Cookie: _ga_PMD05MS2V9=GS1.1.1686231646.1.1.1686231715.0.0.0; _ga=GA1.1.1976488462.1686231647
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
TE: trailers""",
'main': """Host: chatglm.cn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Content-Type: application/json;charset=utf-8
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmcmVzaCI6ZmFsc2UsImlhdCI6MTY4NjIwMjk2NiwianRpIjoiNzlhOGYxNTctMTc3My00Y2I0LWFmNGYtM2RjYmUyODYyYzZjIiwidHlwZSI6ImFjY2VzcyIsInN1YiI6ImVlNWZhYzQ0YjI1ZDQ3NTU5MzU1ZjkzYTIwMWZmNzE4IiwibmJmIjoxNjg2MjAyOTY2LCJleHAiOjE2ODYyODkzNjYsInJvbGVzIjpbInVuYXV0aGVkX3VzZXIiXX0.JxIhk_ZpIO44bX9_V1KiR94RHtwK5wIEfmdtwoqLhF8
Content-Length: 19
Origin: https://chatglm.cn
Connection: keep-alive
Referer: https://chatglm.cn/detail
Cookie: _ga_PMD05MS2V9=GS1.1.1686229789.4.1.1686229790.0.0.0; _ga=GA1.1.1115444952.1686202937; chatglm_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmcmVzaCI6ZmFsc2UsImlhdCI6MTY4NjIwMjk2NiwianRpIjoiNzlhOGYxNTctMTc3My00Y2I0LWFmNGYtM2RjYmUyODYyYzZjIiwidHlwZSI6ImFjY2VzcyIsInN1YiI6ImVlNWZhYzQ0YjI1ZDQ3NTU5MzU1ZjkzYTIwMWZmNzE4IiwibmJmIjoxNjg2MjAyOTY2LCJleHAiOjE2ODYyODkzNjYsInJvbGVzIjpbInVuYXV0aGVkX3VzZXIiXX0.JxIhk_ZpIO44bX9_V1KiR94RHtwK5wIEfmdtwoqLhF8; chatglm_token_expires=2023-06-08%2022:42:45; chatglm_refresh_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmcmVzaCI6ZmFsc2UsImlhdCI6MTY4NjIwMjk2NiwianRpIjoiMWNiOWJiZTItYmU5NS00MjIzLTlmNzYtMzcxYjUyZTliYWJmIiwidHlwZSI6InJlZnJlc2giLCJzdWIiOiJlZTVmYWM0NGIyNWQ0NzU1OTM1NWY5M2EyMDFmZjcxOCIsIm5iZiI6MTY4NjIwMjk2NiwiZXhwIjoxNzAxNzU0OTY2LCJyb2xlcyI6WyJ1bmF1dGhlZF91c2VyIl19.abMdLQv-uggI3jODqeGV359PiFdKWogJAKKFICEP0ro
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
TE: trailers""",
}
host_url = 'https://chatglm.cn'
urls = {'checkphone' : f'{host_url}/chatglm/backend-api/v1/user/checkphone', # {"phone":"15921574859","rid":"202306082205079a146516c157911a61","status":0}
'login' : f'{host_url}/chatglm/backend-api/v1/user/login',
'info' : f'{host_url}/chatglm/backend-api/v3/user/info',
'detail' : f'{host_url}/detail',
'conversation' : f'{host_url}/chatglm/backend-api/v1/conversation', # For task_id
'context' : f'{host_url}/context_id=', # For
'stream_context': f'{host_url}/chatglm/backend-api/v1/stream_context', # For context_id
'stream' : f'{host_url}/chatglm/backend-api/v1/stream?context_id=',
'delete' : f'{host_url}/chatglm/backend-api/v1/conversation/delete/',
}
username = '15921574859'
driver_waiting_timeout = 30
def __init__(self, ):
super(ChatGLMCrawler, self).__init__()
self.initialize_driver()
NotImplemented
def request(self, content):
# Find task_id
# Send content for ChatGLM response
formdata = {'prompt' : content,
'seed' : 91595,
'max_tokens' : 512,
'conversation_task_id' : '6481724b6a5cf5161f7e299a',
'retry' : False,
'retry_history_task_id' : None,
}
formdata_json = json.dumps(formdata)
NotImplemented
def initialize_driver(self):
self.driver = webdriver.Firefox()
self.driver.maximize_window()
self.driver.get(self.host_url)
xpath_login_span = '//span[@class="login"]'
WebDriverWait(self.driver, 30).until(lambda _driver: _driver.find_element_by_xpath(xpath_login_span).is_displayed())
self.driver.find_element_by_xpath(xpath_login_span).click()
xpath_username_input = '//input[@placeholder="手机号"]'
xpath_password_input = '//input[@placeholder="短信验证码"]'
xpath_getcode_button = '//div[@class="code-btn"]'
xpath_login_button = '//span[contains(text(), "立即登录")]'
self.driver.find_element_by_xpath(xpath_username_input).send_keys(self.username) # Input username
self.driver.find_element_by_xpath(xpath_getcode_button).click() # Click send-smscode button
# Waiting for CAPTCHA
xpath_chat_input = '//div[@id="search-input-box"]'
WebDriverWait(self.driver, 30).until(lambda _driver: _driver.find_element_by_xpath(xpath_chat_input).is_displayed())
print(cookies = driver.get_cookies())
self.driver.quit()
NotImplemented
def get_task_id(self):
json_response = requests.get(self.urls['conversation'], headers=BaseCrawler.headers_to_dict(self.headers['main'])).json()
print(json_response)
task_id = json_response['result']['task_id']
return task_id
NotImplemented
def get_context_id(self, task_id, content):
formdata = {'prompt' : content,
'seed' : 71374,
'max_tokens' : 512,
'conversation_task_id' : task_id,
'retry' : False,
'retry_history_task_id' : None,
}
json_response = requests.post(self.urls['stream_context'], headers=BaseCrawler.headers_to_dict(self.headers['main']), data=jsonformdata).json()
messagee = json_response['message']
context_id = json_response['result']['context_id']
return context_id
NotImplemented
20230609
- 又是不知死活的一天,自我感觉状态绝好,晚上八点半去冲万米,结果热得要命,起得又太快,3000米用时12’08",就已经顶不住配速,补了一组400米(1’18")和两组1000米(3’50"),心肺完全极限。最近不管是速度还是耐力练得不少,而且每晚回去都会做100次俯卧交替摸肩、40个两头起和3分钟平板,不说是钢铁核心至少也是不锈钢级别了,但依然不见长进,果真是熬夜熬得太多了么【苦涩】,明天出校权且跑休一日吧,给身体调整一下。
- 晚上七到八点跟发端小会讨论了一下大创的事,所以去晚了,有点可惜。宋镇均、卢星雨、黄嘉懿、周俊呈都在,宋镇均一个人顶了5个400米间歇(1’12"~1’15"),属实真男人。到田径场的时候迎头碰到卢星雨刚走,跟我说宋镇均告诉她我之前跟宋说上周天天看她跑,太卷了,说谁最卷心里还没点B数么,天天卷又不长进,不如一起快乐养老跑,笑死。讲道理,如果陈嘉伟能来给我拉住配速,我觉得自己总归是要比之前强的,一个人这种大热天能顶住强度真得是钢铁意志。
今天发现chatresearch虽然挂了,但是接口并没有挂,所以爬虫依然可行。
关于表格问答,我想到一个很直觉的处理,就是让chatgpt把表格转化为文字,这个有点类似很久很久以前的一个NLP任务,叫作data2text,就是把结构化的数据描述成非结构化的文字。现在从某种意义上来说,NLP的研究范式还有另一个变革,就是从结构化变为非结构化,以前总是觉得非结构化的文本是难以处理的,现在的Incontext Learning似乎并不这么认为了。
20230610~20230613
- 周末跟老表出去玩儿了三天,校历上已经是第17周,回来接着要开组会赶论文。25号前得把ICTAI投了,八月份还有个CCF-A,七八月注定要留校赶工。
- 其实停了三天差不多,先权且恢复一天,勉强跑了个四分半的10圈,明天队里要大聚会,一些老队员也要回来,尤其是李奇宽要来(人称AK,全马237,半马117的神),估计要跟东哥一次喝个够。
一些gradio和langchain的小细节问题:
图形框:
import gradio as gr
import numpy as np
import random
with gr.Blocks() as demo:
section_labels = [
"apple",
"banana",
"carrot",
"donut",
"eggplant",
"fish",
"grapes",
"hamburger",
"ice cream",
"juice",
]
with gr.Row():
num_boxes = gr.Slider(0, 5, 2, step=1, label="Number of boxes")
num_segments = gr.Slider(0, 5, 1, step=1, label="Number of segments")
with gr.Row():
img_input = gr.Image()
img_output = gr.AnnotatedImage().style(
color_map={"banana": "#a89a00", "carrot": "#ffae00"}
)
section_btn = gr.Button("Identify Sections")
selected_section = gr.Textbox(label="Selected Section")
def section(img, num_boxes, num_segments):
sections = []
for a in range(num_boxes):
x = random.randint(0, img.shape[1])
y = random.randint(0, img.shape[0])
w = random.randint(0, img.shape[1] - x)
h = random.randint(0, img.shape[0] - y)
sections.append(((x, y, x + w, y + h), section_labels[a]))
for b in range(num_segments):
x = random.randint(0, img.shape[1])
y = random.randint(0, img.shape[0])
r = random.randint(0, min(x, y, img.shape[1] - x, img.shape[0] - y))
mask = np.zeros(img.shape[:2])
for i in range(img.shape[0]):
for j in range(img.shape[1]):
dist_square = (i - y) ** 2 + (j - x) ** 2
if dist_square < r**2:
mask[i, j] = round((r**2 - dist_square) / r**2 * 4) / 4
sections.append((mask, section_labels[b + num_boxes]))
return (img, sections)
section_btn.click(section, [img_input, num_boxes, num_segments], img_output)
def select_section(evt: gr.SelectData):
return section_labels[evt.index]
img_output.select(select_section, None, selected_section)
demo.launch()
音频播放:
from math import log2, pow
import os
import numpy as np
from scipy.fftpack import fft
import gradio as gr
A4 = 440
C0 = A4 * pow(2, -4.75)
name = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"]
def get_pitch(freq):
h = round(12 * log2(freq / C0))
n = h % 12
return name[n]
def main_note(audio):
rate, y = audio
if len(y.shape) == 2:
y = y.T[0]
N = len(y)
T = 1.0 / rate
yf = fft(y)
yf2 = 2.0 / N * np.abs(yf[0 : N // 2])
xf = np.linspace(0.0, 1.0 / (2.0 * T), N // 2)
volume_per_pitch = {}
total_volume = np.sum(yf2)
for freq, volume in zip(xf, yf2):
if freq == 0:
continue
pitch = get_pitch(freq)
if pitch not in volume_per_pitch:
volume_per_pitch[pitch] = 0
volume_per_pitch[pitch] += 1.0 * volume / total_volume
volume_per_pitch = {k: float(v) for k, v in volume_per_pitch.items()}
return volume_per_pitch
demo = gr.Interface(
main_note,
gr.Audio(source="microphone"),
gr.Label(num_top_classes=4),
examples=[
[os.path.join(os.path.dirname(__file__),"audio/recording1.wav")],
[os.path.join(os.path.dirname(__file__),"audio/cantina.wav")],
],
interpretation="default",
)
if __name__ == "__main__":
demo.launch()
20230614
- 今晚队里聚餐得知李奇宽他现在每晚八点都会到田径场跑步,这两天回来都没能碰上。听卢星雨说,那天李奇宽刚过来,陈嘉伟兴致冲冲地去找虐,结果5000米跑得脸都发白了,大概18分出头的成绩,对于李奇宽轻轻松松,对于嘉伟已是极限。这一年以来,嘉伟在中长项目上已经打遍全校无敌手,但他和李奇宽的差距,差不多是我跟嘉伟的差距(李奇宽半马pb113,比嘉伟pb125快近10分钟多,而我全盛状态下跑出过132的成绩,但事实上目前正式成绩pb只有140,但是坚信下一场一定可以进135,大概…)。
- 八点半回校慢跑10圈,本来饭后还有下半场ktv,但是要跑去五角场,估摸着得弄到十点十一点,弄得太晚,其实还是有点想去的,我也算是乐感很好,也很喜欢唱歌的人,本科毕业之后就没去过ktv,但是毕竟要赶在25号前把论文投出去,事情确实很局促,还得回实验室把杂事处理掉,便也罢了。
JittorLLMs(https://gitlink.org.cn/jittor/JittorLLMs),宣称无需显卡,最低2G内存都可以跑通百亿级别以内的大模型,目前部署确实很简单,但是就是始终跑不了。以chatglm为例,就算按照教程里设置环境变量:
export JT_SAVE_MEM=1
# 限制cpu最多使用16G
export cpu_mem_limit=16000000000
# 限制device内存(如gpu、tpu等)最多使用8G
export device_mem_limit=8000000000
# windows 用户,请使用powershell
# $env:JT_SAVE_MEM="1"
# $env:cpu_mem_limit="16000000000"
# $env:device_mem_limit="8000000000"
但依然不可行,比如我的笔记本16G内存,4G显存,然而16G内存根本连chatglm6b的checkpoint都加载不进来,换pc机32G内存试了一下,如果设置cpu_mem_limit=24000000000,确实读取checkpoint后,内存占用不会超过24G(就刚好卡在24G上),但是显存限制device_mem_limit=2000000000哪怕设置成2G,还是会报错cudamemlocationerror。明明代码里也已经把对应的cuda部分注释掉了:
class ChatGLMMdoel(LLMModel):
def __init__(self, args) -> None:
super().__init__()
print('Load Models ...')
self.tokenizer = AutoTokenizer.from_pretrained(os.path.dirname(__file__), trust_remote_code=True)
self.model = AutoModel.from_pretrained(os.path.dirname(__file__), trust_remote_code=True)
'''
if jt.has_cuda:
self.model.half().cuda()
else:
self.model.float32()
torch.half = torch.float
torch.Tensor.half = torch.Tensor.float
'''
self.model.float32()
torch.half = torch.float
torch.Tensor.half = torch.Tensor.float
self.model.eval()
(这里的话,jt.has_cuda总是为True,如果想要只用CPU跑,理论上只要注释成这样即可)
但还是会报显存出错的问题。不太清楚具体问题在哪里。
20230615
- 晚上八点去逮李奇宽,结果他们KTV唱到将近今天凌晨五点才回来,表示实在跑不了。不过逮到了嘉伟和炳杰,炳杰一个多月没见,在申夏令营,据说北大光华已经稳了,不过这小子历来嘴巴很紧,不肯跟我透太多,但是他觉得如果暑期中金能留用的话,就想着把研究生给翘了,觉得再读两年费时间,标准的实用主义者,我也不置可否。昨天炳杰也没来聚餐,其实我跟陈发端都叫他了,他觉得这学期没怎么来训练,不好意思来吃饭,卢星雨觉得他是有点社恐的。
- 我到田径场的时候,嘉伟已经在跑5000米了,跟了他最后2000米,配速3’44",对我来说已是相当极限。然后跟着炳杰又跑了3000米(他今天极猛,校运会后就没怎么跑过,直接4’42"配速慢摇了20km,把我都给整不会了,最后看他已经完全是强弩之末,带他把最后一段给坚持了下来),最后自己跑了3圈变速和一个400米冲刺(1’12")。
- 原来耐克黑马训练营都是在同济大学田径场训练,怪不得同济那边中长跑这么强,女生都能把5000米跑进20分钟。他们精英组的倒金字塔间歇训练(2k×3+1.6k×2+1k×1),2k(3组,间歇120s)配速要求3’50"~3’55",1.6k(2组,间歇90s)配速要求3’40"-3’45",1k配速要求3’30"以内,组间大间歇90s。
- 精英组这个强度对于嘉伟应该是适中的,对我就很困难(主要是间歇时间太短,其实就拿每个小组来看,都是可以跑得下来,但是组间大间歇才90s,实在是难以恢复得过来),高级组配速要求会低10s,就轻松许多。
gradio的barlot示例:
import gradio as gr
from scatter_plot_demo import scatter_plot
from line_plot_demo import line_plot
from bar_plot_demo import bar_plot
with gr.Blocks() as demo:
with gr.Tabs():
with gr.TabItem("Scatter Plot"):
scatter_plot.render()
with gr.TabItem("Line Plot"):
line_plot.render()
with gr.TabItem("Bar Plot"):
bar_plot.render()
if __name__ == "__main__":
demo.launch()
20230616~20230617
- 昨晚如愿跟李奇宽练了一次,嘉伟也在(显然我是最菜的那个),按照之前的精英组训练表,发现3个2000米的间歇(3’50"~3’55")并没有想象中那么好跑,第三个就已经很难顶住强度(其实按照之前1000米×6的间歇来看,以前是能全部跑进3’45",而且头尾两组一般能进3’30",应该能勉强顶住这个强度,但是这个间歇时间90秒实在是太短了),后面2组1600米和1组1000米宽哥让我们休息了很久,要轻松些。这个配速对他俩来说还是挺轻松的,但我跑完直接就是一坨烂泥了。
- 说实话李奇宽比想象得还要矮,而且因为之前常年跑马和越野,看起来比我还黑。难以想象这么身高不到一米六的家伙,步幅竟然能这么大,完全跟不上他的步伐节奏。
- 今日入梅,雨季将至,估摸着这两天不会很好过。晚上七点半下楼发现操场并不开放,沿着实验大楼的楼梯跑了4轮上下(无聊数了一下,从B1到15层天台一共416级台阶),期待下一次和宽哥训练,嘉伟表示也要开始堆跑量备赛12月的上马,而且下半年王炳杰保完研也很闲,到时候宽哥可以带着咱们三个菜鸟一起去干一场全马。
gradio@button
import gradio as gr
import os
def combine(a, b):
return a + " " + b
def mirror(x):
return x
with gr.Blocks() as demo:
txt = gr.Textbox(label="Input", lines=2)
txt_2 = gr.Textbox(label="Input 2")
txt_3 = gr.Textbox(value="", label="Output")
btn = gr.Button(value="Submit")
btn.click(combine, inputs=[txt, txt_2], outputs=[txt_3])
with gr.Row():
im = gr.Image()
im_2 = gr.Image()
btn = gr.Button(value="Mirror Image")
btn.click(mirror, inputs=[im], outputs=[im_2])
gr.Markdown("## Text Examples")
gr.Examples(
[["hi", "Adam"], ["hello", "Eve"]],
[txt, txt_2],
txt_3,
combine,
cache_examples=True,
)
gr.Markdown("## Image Examples")
gr.Examples(
examples=[os.path.join(os.path.dirname(__file__), "lion.jpg")],
inputs=im,
outputs=im_2,
fn=mirror,
cache_examples=True,
)
if __name__ == "__main__":
demo.launch()
20230618~20230620
- 两日梅雨,似乎一刻都不曾休止,前两天都是从早肝到晚,下午去休息室调整半个小时,晚上八点多削个苹果爬实验大楼15层上下四个来回,为后半夜鏖战充能,论文总是越写越觉得有东西要补充,但是会议论文已经给你框死范围在。
- 今日雨停,然又是更沉闷的一天,只是热身跑三圈就已是汗流浃背。勉强凑了5000米的量,事情堆得很紧,而且总感觉这篇文章不太方便带东哥一起上,今天王英林也没来学校,25号前我总是要找他好好解决一下问题的。我也不知道应该怎么处理。
- 2020年起连续三年没有好好办一场毕业典礼,今年总算是大张旗鼓地搞了一下,一群学士服硕士服的年轻人在校园里奔走,如果当时选择读硕士直接毕业,也能赶上今年的毕业典礼,总觉得是有些遗憾的。
gradio@chatbot-example:
import gradio as gr
import random
import time
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
def respond(message, chat_history):
bot_message = random.choice(["How are you?", "I love you", "I'm very hungry"])
chat_history.append((message, bot_message))
time.sleep(2)
return "", chat_history
msg.submit(respond, [msg, chatbot], [msg, chatbot])
if __name__ == "__main__":
demo.launch()
20230621
- 30℃的黄梅夜,3000米(12’19")+2000米(8’08")+1000米(3’52")倒金字塔跑,间歇差不多是走两个直道,体力不是很扛得住。主要是最近午睡都是趴实验室桌上听着小品相声瞌睡,省了来回宿舍的时间,能多码俩字。其实休息效果还行,但状态也不见得很好,只能说勉强说得过去,接下来的天气只会越来越难跑,夏冬永远是水平倒退的季节,不过今年有计划去练练上半身,也不能辜负了东哥一片好意。
- 下午明月姐来实验室把东西都清理干净了,留给我一台王明师兄用过的电脑,权以共勉。有时候想三年前大家还都是那么年轻豁然般地刚刚本科毕业,如今一个个都已经要扯去和学校的最后的连丝,彻底走上社会,直到成家立业,有点那种人生拐点的意味,其实也是挺无可奈何的了。
gradio@checkbox
import gradio as gr
def sentence_builder(quantity, animal, countries, place, activity_list, morning):
return f"""The {quantity} {animal}s from {" and ".join(countries)} went to the {place} where they {" and ".join(activity_list)} until the {"morning" if morning else "night"}"""
demo = gr.Interface(
sentence_builder,
[
gr.Slider(2, 20, value=4, label="Count", info="Choose between 2 and 20"),
gr.Dropdown(
["cat", "dog", "bird"], label="Animal", info="Will add more animals later!"
),
gr.CheckboxGroup(["USA", "Japan", "Pakistan"], label="Countries", info="Where are they from?"),
gr.Radio(["park", "zoo", "road"], label="Location", info="Where did they go?"),
gr.Dropdown(
["ran", "swam", "ate", "slept"], value=["swam", "slept"], multiselect=True, label="Activity", info="Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed auctor, nisl eget ultricies aliquam, nunc nisl aliquet nunc, eget aliquam nisl nunc vel nisl."
),
gr.Checkbox(label="Morning", info="Did they do it in the morning?"),
],
"text",
examples=[
[2, "cat", ["Japan", "Pakistan"], "park", ["ate", "swam"], True],
[4, "dog", ["Japan"], "zoo", ["ate", "swam"], False],
[10, "bird", ["USA", "Pakistan"], "road", ["ran"], False],
[8, "cat", ["Pakistan"], "zoo", ["ate"], True],
]
)
if __name__ == "__main__":
demo.launch()
20230622
- 3000米(12’00")+1000米(3’58")+1000米(3’44")倒金字塔跑,间歇3分钟,第二组2000米没能坚持下来,说实话身体有点虚,热身的时候就感觉没劲,尽管睡了午觉。不过起手第一个3000米跑得还不错,近期难得碰一次12分钟大门,最后一个1000米也感觉仍有余力,可能还是状态没能调动起来,接下来几天可能又要连日下雨,还是抽空去上点强度。
gradio@checkboxgroup
import gradio as gr
def sentence_builder(quantity, animal, countries, place, activity_list, morning):
return f"""The {quantity} {animal}s from {" and ".join(countries)} went to the {place} where they {" and ".join(activity_list)} until the {"morning" if morning else "night"}"""
demo = gr.Interface(
sentence_builder,
[
gr.Slider(2, 20, value=4, label="Count", info="Choose between 2 and 20"),
gr.Dropdown(
["cat", "dog", "bird"], label="Animal", info="Will add more animals later!"
),
gr.CheckboxGroup(["USA", "Japan", "Pakistan"], label="Countries", info="Where are they from?"),
gr.Radio(["park", "zoo", "road"], label="Location", info="Where did they go?"),
gr.Dropdown(
["ran", "swam", "ate", "slept"], value=["swam", "slept"], multiselect=True, label="Activity", info="Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed auctor, nisl eget ultricies aliquam, nunc nisl aliquet nunc, eget aliquam nisl nunc vel nisl."
),
gr.Checkbox(label="Morning", info="Did they do it in the morning?"),
],
"text",
examples=[
[2, "cat", ["Japan", "Pakistan"], "park", ["ate", "swam"], True],
[4, "dog", ["Japan"], "zoo", ["ate", "swam"], False],
[10, "bird", ["USA", "Pakistan"], "road", ["ran"], False],
[8, "cat", ["Pakistan"], "zoo", ["ate"], True],
]
)
if __name__ == "__main__":
demo.launch()
20230623
- 难得一个凉爽的夏夜,本以为连着几天在高温下硬上强度,今天总该跑点成绩了,结果又是4000米就坚持不下去(16’34",均配4’08"),稍事休息补了2000米(8’25")和200个双摇。原计划是把万米跑进42分,前3000米用时12’31"还是挺顺的,结果第4个1000米时音乐突然断了,我才想起来忘记调成循环播放,节奏不对劲,很快意志就崩溃了。
- 最近跑步伴奏用的都是灰澈的轻音乐,除了经典的《森林》《星茶会》《星萤火》,最近发现《四月一日晴》《I LOVE YOU》也很适宜。列表最后用一首燃曲《Last Ride Of The Day》兴奋一下状态顶住配速。如果全程都用燃曲,很容易起得太快而迅速力竭,不如用轻音乐稳住前期节奏效果好。
gradio@ColorPicker
import gradio as gr
import numpy as np
import os
from PIL import Image, ImageColor
def change_color(icon, color):
img = icon.convert("LA")
img = img.convert("RGBA")
image_np = np.array(icon)
_, _, _, alpha = image_np.T
mask = alpha > 0
image_np[..., :-1][mask.T] = ImageColor.getcolor(color, "RGB")
edited_image = Image.fromarray(image_np)
return edited_image
inputs = [
gr.Image(label="icon", type="pil", image_mode="RGBA"),
gr.ColorPicker(label="color"),
]
outputs = gr.Image(label="colored icon")
demo = gr.Interface(
fn=change_color,
inputs=inputs,
outputs=outputs,
examples=[
[os.path.join(os.path.dirname(__file__), "rabbit.png"), "#ff0000"],
[os.path.join(os.path.dirname(__file__), "rabbit.png"), "#0000FF"],
],
)
if __name__ == "__main__":
demo.launch()
20230624~20230625
- 昨天一日暴雨,一直肝到12点回三门路,结果还是没改完,又顶到凌晨3点半总算把论文提交掉了,四点才合眼,结果今早七点多被外面施工吵醒,回笼觉睡到九点半,困得要死,后来午觉也没睡着。
- 晚上想想还是去跑了一会儿,30分钟遛了15圈半,勉强挺进5分配,看到一个穿上马PB服的大佬,可惜我状态太差了,不能跟他过两招。今日早休,其实想想也就是昨天一天没跑,熬了个夜,养了一周的状态就完全崩塌了。
作为收尾,似乎还是有些草率,但已达到字数上限(18w),也只得搁笔。不同的阶段,人对自己要有不同的定位,但我总是觉得应当保有一个坚实不变的根,才能在繁杂变幻中立于不败。我们都清楚终点在何处,只是想用一个漂亮的走法迈向那里。与其所有人都惊艳,不如尊重每一种审美。
下一站,故乡。
(END)

















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









