







序言
除夕,年夜饭回来后特别累(赶早,下午又一路十公里跑回老家),把明天要看的东西准备好,然后糊完手头的日记本最后一页(糊了一堆“烦”字),准备封存起来,找本新的软抄就睡觉了,即兴又想翻翻之前的本子,从十二年前开始,初中狂妄羞耻的中二魂,每天还都起个特别二的标题,什么《闭关修炼!黑色星期五!双重创击!XXX称霸扬州》《迈向破灭的镇魂曲—巅峰对决—败绩—病倒》《自陷—精神暗杀》,到高中群雄并起,画风一下子正常了许多,再到刚入大学时的迷惘,再后来事情都是现在记忆里的模样了。
本来,今天还是很高兴的,终于把破事摆平顺利回家。但到晚上突然很痛苦,因为怎么都听不见回声,我感觉是之前做的事逾矩了,覆水难收,到底还是让别人产生芥蒂了。害。
文章目录
20240209
dowhy库构建因果图,旨在简化因果推断的过程,特别是针对那些希望从数据中估计因果效应的研究者。
开源地址:https://github.com/py-why/dowhy
pip install dowhy
demo:
# 加载数据
import numpy as np
import pandas as pd
from dowhy import CausalModel
import dowhy.datasets
rvar = 1 if np.random.uniform() >0.5 else 0
data_dict = dowhy.datasets.xy_dataset(10000, effect=rvar, sd_error=0.2)
df = data_dict['df']
# 现在你可以使用 DoWhy 定义因果模型。这涉及指定分析中的变量、治疗、结果和潜在的混杂因素。
model= CausalModel(
data=df,
treatment=data_dict["treatment_name"],
outcome=data_dict["outcome_name"],
common_causes=data_dict["common_causes_names"]
)
model.view_model(layout="dot")
参数说明:
data,包含所有相关数据的 DataFrame。这应该包括处理变量、结果变量、共同原因(共变量)、以及(如果有的话)工具变量。treatment,指定作为处理(干预)的变量名。在因果推断中,我们关心的是改变这个变量会如何影响结果变量。outcome,指定结果变量的名称。这是我们想要了解其因果效应的变量。common_causes,一个包含所有已知共同原因(也称为共变量或混杂变量)名称的列表。这些是既影响处理变量又影响结果变量的变量,必须控制以避免偏差。instruments,一个包含所有工具变量名称的列表(如果有的话)。工具变量是与处理变量相关但只通过它影响结果变量的变量,常用于处理内生性问题。
输出结果:
w 0 → T r e a t m e n t → O u t c o m e ← w 0 w_0 \rightarrow Treatment \rightarrow Outcome \leftarrow w_0 w0→Treatment→Outcome←w0
这是个典型的三角带混杂的因果图,即 w 0 w_0 w0为混杂变量,它既影响处理变量 T r e a t m e n t Treatment Treatment又影响结果变量 O u t c o m e Outcome Outcome
20240210
- 现在CSDN学坏了,搞什么流量券,全是阴兵刷数据,真是恶心。
- 早上不到七点自然醒,果然还是家里床睡得舒服,半夜鞭炮声都没吵醒我。起来翻了一下消息,还是挺失落。算了,等开学,不想动脑,心急不了一点。
- 扭伤完全好了,昨天AK跑山,11km+,700+爬升,而且只是一座山,太恐怖,穹窿山200米的山下坡就一眼望不到底,走的让人特别绝望,AK说我是不会下山,会下山后会很爽,可是整个扬州一马平川,从小对山就一点概念没有。
- 今年再没有去年《流浪地球3》那种神作了,几乎清一色的快餐喜剧,就像春节不看喜剧就活不下去似的。其实不太想去看电影,但年初一也没啥事可做,还是去看了《热辣滚烫》,据说口碑两极分化,怎么说呢,春节看这种以催泪(乃至破防)结局收尾的电影确实无法合乎所有人的胃口(小孩不一定看得懂,中年人又觉得无感,只有我们这些年轻一辈才有很强共鸣),还是快餐喜剧更有普适性点儿,但就电影本身而言,几乎没有可挑剔的地方:
- 首先是学院派的标准艺术表现形式,只提三点:①开头常规的倒叙手法,结局比赛进场时胖瘦贾玲的对视呼应开头;②月莹同意远房表妹(杨紫饰)节目录制后回家的那段上四层楼、回宿舍、歇斯底里的长外景镜头(其实当时就觉得应该会跳楼,这样社会性死亡又被人当众侮辱,果然后面走马灯的时候提到真的跳楼了,只是没死成),从狂风到暴雨,偏蒙太奇式的叙事手法;③最后月莹被KO在地,脑子里回马灯式地回忆之前若干情节中的留白部分(录制节目晕倒后,没有哭出来,但听到远房表妹冰冷自私的话语时的绝望,一行清泪留下,回家后跳楼自杀,以及和昊坤的初夜、与妹妹的争执房产的结局等等),既影射现实的残酷,又使得剧情完满,愈发催人泪下。
- 其次是题材,至少对我很有共鸣(真的破防了,我其实没哭,因为我也是这么走过来的,但旁边两个30多岁的姐姐都哭了,觉得月莹被打得好惨),尤其最后月莹参加比赛被打得鼻青脸肿,努力不代表你就能赢,比你有天赋有能力的人一抓一大把,但是不努力、没有梦想你还是那个两百多斤的月莹,我自己也是这样,本科时体测1000米从没跑进过4分10秒,但如今万米已经达38分台,但是相比那些身体条件好的人依然差得很远,但至少我也比之前好太多。
- 最后是对贾玲老师的敬佩。贾玲老师真的是狠人,电影七成的剧情都是胖月莹的故事。这意味着她在一年前就把减肥之前所有剧情(七成左右)都拍好了,如果一年内减不下来,她就赶不上春节档了,这真是史上最强的减肥计划,而且真的好夸张,现在练出马甲线,甚至能做引体向上,跑姿也好标准,太恐怖了,有钱能使磨推鬼(雾)。
- 看完去吃了烤鱼,我一个人硬吃完一整条海鲈鱼,加上一些牛蛙和小酥肉,撑得要死,回程备受鼓舞,背着书包一路从外婆家跑回家,又补了3000跳绳,100双摇,以及核心训练。我也要跟贾玲一样自律,吃吃喝喝是破不了三的,既然现在状态这么好,我就应该继续保持下去,而不是想着摆烂几天再捡起来。决心直到比赛前,都要保持现在的节奏生活下去,一定。
交接备份(反正过年不搞,年后也得搞,不如过年搞掉):
# -*- coding: utf-8 -*-
# @author : caoyang
# @email: caoyang@stu.sufe.edu.cn
import re
import logging
import pandas as pd
from settings import RAW_DATA_SUMMARY
from src.pipelines.base import NLPPipelines
class JobPreprocessPipeline(NLPPipelines):
# 1. DEFINE POSTAGs
# Comment@caoyang: Here I only use pkuseg, if you use jieba, you need to update the following 4 dicts
uncritical_pos_tags = {"pkuseg": ['r', 'z', 'y', 'e', 'o', 'i', 'x']} # Pos tags which can be ignored
noun_pos_tags = {"pkuseg": ['n', "nr", "ns", "nt", "nx", "nz", "an"]} # Pos tags which refer to nouns
verb_pos_tags = {"pkuseg": ['v', "vx", "vn"]} # Pos tags which refer to verbs
other_pos_tags = {"pkuseg": ['c', 'u', 'w', 'd']} # Pos tags which are not nouns or verbs (but cannot be ignored, e.g. "的", "和", etc)
# ----------------------------------------------------------------
# 2. DEFINE EDUCATIONs AND MAJORs
educations_lv0 = ["小学", "初中", "中学", "高中"] # Education Lv.0 (Note that there are descriptions like "辅导小学/初中小孩", "初中级技术人员", "初高中教学辅导", "从中学习")
educations_lv1 = ["职校", "职高", "技校", "中专"] # Education Lv.1
educations_lv2 = ["大专", "高职", "本科", "学士"] # Education Lv.2
educations_lv3 = ["硕士", "研究生", "博士"] # Education Lv.3
educations_main = educations_lv1 + educations_lv2 + educations_lv3
majors_need_suffix = ["计算机", "英语",
] # These majors must have a suffix "专业"
majors_all = ["法律", "金融", "机电", "机械", "人力资源", "财务", "师范",
"机电", "人力资源", "师范",
] # You can add new major strings here
# ----------------------------------------------------------------
# 3. DEFINE SOME KEY TOKENs
# Phrases containing forbidden tokens can be ignored when extracting tasks and skills
forbidden_tokens = ["00", "周岁", "岗位职责", "任职", "岗位要求", "岗位目的",
"职责", "职位", "招聘岗位", "工作内容", "工作描述",
"男女", "不限", "身高", "体重", "优先", "招聘", "入职",
"科技园", "有无经验", "诚聘", "身高", "体重", "优先",
"招聘", "入职", "科技园",
]
forbidden_tokens = list(set(filter(None, forbidden_tokens)))
# All the tokens appearing behind uncritical tokens can be ignored when extracting tasks and skills
# comment@20231114: I found that treatment (e.g. salary, accommodation, etc) may appear at the start of many job ads, so that I set a `threshold_for_skip` for ignoring the tokens behind uncritical tokens
uncritical_tokens = ["福利", "晋升", "薪资", "工资", "工作地址",
"联系人", "联系电话", "待遇", "五险", "底薪",
"五险", "一金", "奖金", "上班", "工作时间",
"职位发展", "培训与发展", "绩效", "技能培训", "免费",
"职前培训", "级别", "年龄", "截止", "有无经验",
"包吃包住", "加班", "社保", "包住宿", "持有",
"学历", "专业不限", "毕业", "相关专业", "等专业",
"管理专业", "设计专业", "工科专业", "工程专业",
"营销专业", "计算机专业", "语专业", "会计专业",
"以上专业", "金融专业", "法律专业", "机械专业",
"自动化专业", "财务专业", "电器专业", "类专业",
"教育专业", "护理专业", "美术专业", "机电专业",
"法学专业", "建筑专业", "师范", "画专业",
]
uncritical_tokens = list(set(filter(None, uncritical_tokens)))
forbidden_tokens = list(set(forbidden_tokens + uncritical_tokens)) # Add uncritical tokens into forbidden tokens
threshold_for_skip = .5 # See comment@20231114 above
# ----------------------------------------------------------------
# 4. Strip symbols for post-processing phrases
punctuations = ",,.。;;[]【】-——、"
def __init__(self, **kwargs):
super(JobPreprocessPipeline, self).__init__(**kwargs)
# Check
for pos_tags in ["uncritical_pos_tags", "noun_pos_tags", "verb_pos_tags", "other_pos_tags"]:
if self.library not in eval(f"self.{pos_tags}"):
raise NotImplementedError(f"You want to use library {self.library} for parsing, please update `{pos_tags}` above!")
self._load_major_zyml(filepath=RAW_DATA_SUMMARY["major_zyml"])
self._define_regex()
# Regex definitions for extracting salary(*), experience, age, education, major and for substitute, sentence tokenization
def _define_regex(self):
# 1. Regex matching salary numbers
# regex_salary_string = "[^a-zA-Z\d][1-9]\d{1,2}00[^\d号年届]" # This regex is better, but when processing "工资4000-6000元/月", it can match "4000" only but ignore "6000", because `re.findall` find only non-overlapping matches
regex_salary_string = "([1-9]\d{1,2}00)[^\d号年届]" # This regex avoid the problem above, but may extract something wrong
self.regex_salary = re.compile(regex_salary_string)
# --------------------------------
# 2. Regex matching experience strings
regex_experience_string = "((\d{1,2}|一|二|三|四|五|六|七|八|九|十|十五|二十|二十五|三十)(年)?[\~\-至到—])?(\d{1,2}|一|二|三|四|五|六|七|八|九|十|十五|二十|二十五|三十)(年)(以[上内下])?([^,。(\\\\N);\|]+)(工作)?(经验)|(有?无经验)"
self.regex_experience = re.compile(regex_experience_string)
# --------------------------------
# 3. Regex matching age strings
regex_age_string = "(([二三四五六七八九]?十[一二三四五六七八九]?|\d{2})(周?岁)?[\-\~至到])?([二三四五六七八九]?十[一二三四五六七八九]?|\d{2})(周?岁)(以[内下上])?"
self.regex_age = re.compile(regex_age_string)
# --------------------------------
# 4. Regexs matching education strings
or_string_education_main = f"({'|'.join(self.educations_main)})"
or_string_education_lv0 = f"({'|'.join(self.educations_lv0)})"
# You can copy from `regexs_for_substitute`, but you'd better add brackets to each substring(if you wish `re.findall` to capture it)
regex_education_strings = [f"(学历)?([::])?{or_string_education_main}(以?及)?{or_string_education_main}?(以[上内下])?(学历|毕业)?",
f"(学历)([::])?{or_string_education_lv0}(以?及)?{or_string_education_lv0}?(以[上内下])?",
f"({or_string_education_lv0})(以?及)?({or_string_education_lv0})?(以[上内下])?(学历|毕业)",
]
self.regexs_education = list(map(re.compile, regex_education_strings))
# --------------------------------
# 5. Regexs matching major strings
# Update `majors_all`
majors_all = list(set(self.majors_all)) # Drop duplicates
for major in self.majors_all:
if major.endswith("大类") and len(major) > 4:
# e.g. "农林牧渔大类" -> "农林牧渔", "资源环境与安全大类" -> "资源环境与安全"
majors_all.append(major[:-2])
elif major.endswith("类") and len(major) > 3:
# e.g. "医学技术类" -> "医学技术", "经济学类" -> "经济学"
majors_all.append(major[:-1])
# Split majors by whether they need suffix
majors_need_suffix = list(set(self.majors_need_suffix)) # Drop duplicates
majors_not_need_suffix = list() # Generate those do not need suffix (i.e. "专业")
for major in majors_all:
if major not in self.majors_need_suffix:
majors_not_need_suffix.append(major)
majors_not_need_suffix = list(set(majors_not_need_suffix)) # Drop duplicates
regex_major_strings = [f"({'|'.join(majors_need_suffix)})(相关)?(专业)(优先)?",
f"({'|'.join(majors_not_need_suffix)})(相关)?(专业)?(优先)?",
]
self.regexs_major = list(map(re.compile, regex_major_strings))
# --------------------------------
# 6. Regex for substitute and sentence tokenization
# @variable regexs_for_substitute: List[Tuple(<regex>, <substitute>)]
regexs_for_substitute = [("[<《「【(\(][^))】」》>]+[\))】」》>]", str()), # e.g. 【岗位职责】, <span id="sda"></span>
("\\\\[a-zA-Z]", str()), # e.g. "\N", "\R"
("[【】✅☞'️⃣\\\\]", str()), # Delete special tokens (You can add more special tokens here)
("原?标题", str()), # Note that "原标题" and "标题" appears many times in corpus
(regex_education_strings[0], str()), # e.g. "本科及以上", "硕士以下学历", "学历大专"
(regex_education_strings[1], str()), # e.g. "学历高中及高中以上", "学历初中", "学历小学"
(regex_education_strings[2], str()), # e.g. "小学毕业", "初中以上学历", "高中及以上学历"
("\d{2}周?岁以[内下上]", str()), # e.g. "35岁以下", "18周岁以上"
("\d{1,2}周?岁", str()), # e.g. "35周岁", "24岁"
("\d{1,2}年及?以[上下内](相关)?(工作)?(经验)?", str()), # e.g. "10年以上工作经验", "2年以内相关工作"
("[一二两三四五六七八九十]年及?以[上下内](相关)?(工作)?(经验)?", str()), # e.g. "两年及以上工作经验",
("\d+[、.\)))]", '。'), # Replace index term with sentence split symbol (i.e. "。")
("[一二三四五六七八九十①②③④⑤⑥⑦⑧⑨⑩][、.]", "。"), # Replace index term with sentence split symbol (i.e. "。")
("\d{1,2}[::]\d{2}", str()), # e.g. "8:30", "19:00"
("(\d{1,5})?元?[-~到或]?\d{1,5}元?[/每][周天月年]", str()), # e.g. "40到50每天", "5000元-6000元/每天"
("([^\d])\d([^\d])", r"\1。\2"), # Match single digitals (It must be set at the last position in `regexs_for_substitute` list)
]
self.regexs_for_substitute = list(map(lambda _tuple: (re.compile(_tuple[0]), _tuple[1]), regexs_for_substitute))
# Split symbols for sentence tokenization
self.regex_for_split = re.compile("[。;!?::\\(\\\\N)]+|\-\-\-+")
# Load majors from 《普通高等学校本科专业目录(2022)》 and 《普通高等学校高等职业教育(专科)专业目录(2021)》
def _load_major_zyml(self, filepath = RAW_DATA_SUMMARY["major_zyml"]):
df_major_zyml = pd.read_csv(filepath, sep='\t', header=0)
self.majors_lv1 = df_major_zyml["major1"].unique().tolist() # Lv1: 31
self.majors_lv2 = df_major_zyml["major2"].unique().tolist() # Lv2: 79
self.majors_lv3 = df_major_zyml["major3"].unique().tolist() # Lv3: 1451
logging.info(f"Lv1 majors: {len(self.majors_lv1)}")
logging.info(f"Lv2 majors: {len(self.majors_lv2)}")
logging.info(f"Lv3 majors: {len(self.majors_lv3)}")
# --------------------------------
logging.info(f"Default majors({len(self.majors_all)}): {self.majors_all}")
self.majors_all = list(set(self.majors_lv1 + self.majors_lv2 + self.majors_lv3))
print(f"Total Majors: {len(self.majors_all)}")
# Extract verb-object phrase
# comment@caoyang: Sorry for my mistake in naming this function, maybe `extract_vo_phrase` is more suitable, but now everywhere is `nv`, I do not wanner change it
# @param df_job_phrase: @return of function `extract_phrase`
# @param use_column: The default setting is "raw"(, and it is what the current results derive from), you can set `use_column = "brief"` for faster running
def extract_nv_phrase(self,
df_job_phrase,
save_path,
use_column = "raw",
):
logging.info("Function `extract_nv_phrase` starts!")
# Define easy function for efficiency
if use_column == "raw":
def _easy_extract_nv_phrase(_phrases, _nv, _tokenizer):
for _phrase_list in _phrases:
for _phrase in _phrase_list:
_nv.extend(self._extract_nv_from_phrase(_phrase, _tokenizer))
elif use_column == "brief":
def _easy_extract_nv_phrase(_phrases, _nv, _tokenizer):
for _phrase in _phrases:
_nv.extend(self._extract_nv_from_phrase(_phrase, _tokenizer))
else:
raise NotImplementedError(f'Expect keyword argument `use_column` in {"raw", "brief"} but got "{use_column}"!')
# If the dtype is not List, we should do eval operation first
if not isinstance(df_job_phrase[use_column][0], list):
df_job_phrase[use_column] = df_job_phrase[use_column].map(eval)
tokenizer = self.load_tokenizer(pos_tag=True) # Load tokenizer
nv_freq = dict()
data_dict = {"mid": list(), "nv": list()}
for i in range(df_job_phrase.shape[0]):
mid = df_job_phrase.loc[i, "mid"]
phrases = df_job_phrase.loc[i, use_column]
nv = list()
_easy_extract_nv_phrase(phrases, nv, tokenizer)
data_dict["mid"].append(mid)
data_dict["nv"].append(nv)
dataframe = pd.DataFrame(data_dict, columns=list(data_dict.keys()))
dataframe.to_csv(save_path, sep='\t', header=True, index=False)
logging.info("Function `extract_nv_phrase` finishes!")
return dataframe
# Extract short verb-object phrase from a piece of long phrase
# Methodology description
# Step1: Split all the tokens by verb tokens
# Step2: Splited tokens block can be treated as noun block
# Step3: Find the nearest(i.e behind and before) noun block for each verb token
# comment@caoyang: Sorry for my mistake in naming this function, maybe `_extract_vo_from_phrase` is more suitable, but now everywhere is `nv`, I do not wanner change it
# @param phrase: Str, a piece of string catching from "raw" or "brief" from `df_job_phrase`
# @param tokenizer: e.g. pkuseg tokenizer
# @param tolerate_forbidden: Boolean, indicating that whether to return empty list for those phrases containing `forbidden_tokens`
# @return nv_list: List[Tuple(<verb: str>, <noun: str>)], e.g. [("编写", "代码"), ("完成", "任务), ...]
def _extract_nv_from_phrase(self,
phrase,
tokenizer,
tolerate_forbidden = False,
):
# Check validation
if not tolerate_forbidden:
for token in self.forbidden_tokens:
if token in phrase:
return list()
_postprocess_noun_block = lambda _noun_block: _noun_block.strip("的并和及与,,.。;;[]【】-——、>/")
# --------------------------------
# 1. Deal with blocks connected by "的"
i = 0
token_pos_tuples_new = list() # Modified (<token>, <pos>) tuple
token_pos_tuples_raw = tokenizer(phrase) # Raw (<token>, <pos>) tuple
while i < len(token_pos_tuples_raw):
# comment@20231201: If a verb is followed by "的", then
# - Rule 1: consider this verb and "的" together as an adjective
# - Rule 2: consider this verb and "的" and the next token together as a noun
token, pos = token_pos_tuples_raw[i]
if i < len(token_pos_tuples_raw) - 1 and token_pos_tuples_raw[i + 1][0] == "的":
# There is at least one token before a "的" token
if i < len(token_pos_tuples_raw) - 2:
# There is at least one token behind the "的" token, then take Rule 2
token_pos_tuples_new.append((f"{token}的{token_pos_tuples_raw[i + 2][0]}", 'n'))
i += 3
else:
# There is no token behind the "的" token, then take Rule 1
token_pos_tuples_new.append((f"{token}的", 'a'))
i += 2
else:
# Default case
token_pos_tuples_new.append((token, pos))
i += 1
# --------------------------------
# 2. Generate noun/verb blocks
noun_flag = False # Flag indicating that if any noun component in a non-verb block
blocks = list() # List[Tuple(<phrase: str>, <pos: "n"/"v">)]
current_noun_block = str() # Current noun block
for i, (token, pos) in enumerate(token_pos_tuples_new):
if pos in ['p', "pn"] or token in ["是", "能", "有", "为", "公司"]:
# Do not process prepositions and some special verbs or nouns
continue
elif pos in ['v']:
# Appear verb
# comment@caoyang: You could take "vn" into account, but I think "vn" appears more like a noun than a verb
current_noun_block = _postprocess_noun_block(current_noun_block)
if noun_flag and len(current_noun_block) > 1:
blocks.append((current_noun_block, 'n'))
blocks.append((token, 'v'))
current_noun_block = str()
else:
# Appear noun components or other pos which can be seemed as noun components
if pos in self.noun_pos_tags[self.library] + ["vn", 'i', 'j', 'l']:
# comment@caoyang: You could take "vn" out of account, but I think "vn" appears more like a noun than a verb
# 'i' refers to 成语(i.e. idiom): e.g. "吃苦耐劳", "精益求精"
# 'j' refers to 简称(i.e. abbr), e.g. "数控", "大中小微"
# 'l' refers to 习惯用语(i.e. slang), e.g. "售后服务", "多劳多得"
noun_flag = True
current_noun_block += token
# Process the last noun block
current_noun_block = _postprocess_noun_block(current_noun_block)
if noun_flag and len(current_noun_block) > 1:
blocks.append((current_noun_block, 'n'))
# *** Finally, there may be continous verb blocks in `blocks` but never continous noun blocks, i.e. [..., 'n', 'n', ...] is impossible
# --------------------------------
# 3. Match verb block to noun block
current_noun_block = None
nv_list = list() # List[Tuple(<verb: str>, <noun: str>)]: Final return
for i, (nv_phrase, nv_pos) in enumerate(blocks):
if nv_pos == 'v':
# Match verb block to the nearest noun block before
if current_noun_block is not None:
nv_list.append((nv_phrase, current_noun_block))
# Match verb block to the nearest noun block behind
for j in range(i + 1, len(blocks)):
if blocks[j][1] == 'n':
nv_list.append((nv_phrase, blocks[j][0]))
break
else:
# i.e. nv_pos == 'n'
current_noun_block = nv_phrase
return nv_list
# ------------------------------------------------------------------
# TODO!!!
# @param df_job_ad: Refers to RAW_DATA_SUMMARY["job_ad"] in settings.py, whose required columns are ["mid", "intro", "title", "industry_name_lv2", "industry_name_lv4"]
# @param save_path: File path used to save the title classification result
# @param encoder: A loaded pre-trained model(see the keys of PRETRAINED_MODEL_SUMMARY in settings.py)
# @param occupations: List[Str], stardard occupations
# @param occupation_embeddings: numpy.ndarrays, embedding matrix of @param occupations, `shape(n_occupations, n_dim)`,
# @param query_template: e.g. "t2", "pt2", "pt24", "pt24i"
# - 'p' refers to using prompt-like query
# - 't' refers to using "title" as query
# - '2' refers to using "industry_name_lv2" as query
# - '4' refers to using "industry_name_lv4" as query
# - 'i' refers to using "intro" as query
# @param top_k: How many matched occupation reserved
# @param batch_size: How many samples encoder deals with at each time
# @param title_embedding_save_path: File path used to save the title embeddings
def classify_title(self,
df_job_ad,
save_path,
encoder,
occupations,
occupation_embeddings,
query_template = "t2",
top_k = 16,
batch_size = 1024,
title_embedding_save_path = None,
):
logging.info("Function `extract_metadata` starts!")
df_job_ad["title"] = df_job_ad["title"].fillna(str())
df_job_ad["industry_name_lv2"] = df_job_ad["industry_name_lv2"].fillna(str())
df_job_ad["industry_name_lv4"] = df_job_ad["industry_name_lv4"].fillna(str())
def _query_function(_entry):
_query_split_by = "。\n"
_prompt_suffix = None
if 'p' in query_template:
_prompt_suffix = {'t': "标题:",
'2': "一级行业分类:",
'4': "二级行业分类:",
'i': "具体内容:",
}
if 't' in query_template:
pass
elif '2' in query_template:
pass
elif '4' in query_template:
pass
elif 'i' in query_template:
pass
def __query(__entry):
__query_strings = list()
20240211
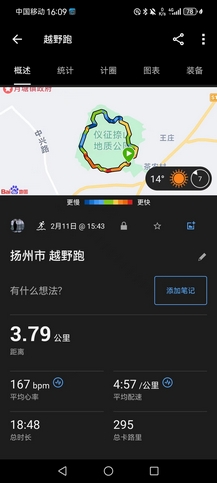
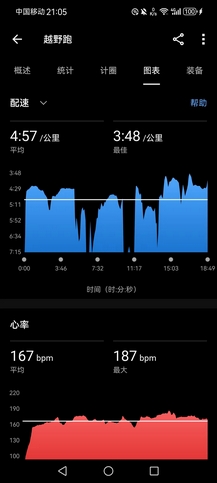
- 下午去仪征捺山地质公园,似乎是最近才开发出的4A景区,我活这么大真没听说过扬州有山,不过仪征离市区也很远,也从来没去过。远观就一座小土山(一百多米,说实话没啥好景色,但是徒步走走倒也不错),门票居然收70块(穹窿山不过60块,虽然是走野路上山白嫖门票),不能忍,我和老表直接翻两道围栏进去,但是因为没人开过路,路上全是荆棘树枝,特别难走,最后还有三只恶犬当道,还好捡到根粗壮结实的枝干,三英战吕布,成功打跑然后溜进景区。
- 虽然山一般,但路修得不错,山上石板路(其实不如土路松软些好),山下柏油路,游览路线是一条圆环线,跟老表走了一圈后我表示这是极好的跑山路线,我要自己再来跑一圈。于是脱了外套开表猛冲(均配4’57"),几乎没有保留,虽不到4km,爬升150米,但上坡跑顶到心率187bpm(最近基本都是养生,要给心肺来点强度),跑完一圈感觉很累,没有强求再补一圈。可惜仪征太远,要不然我每天也来这跑两三圈训练,太高效了。
- 跑完还是挺有成就感,结果看到一二九群里AK干了27km越野,配速6’01",爬升1119米,海拔2000多米,给我直接干沉默了。AK指定是本着开春PB在练,虽然他这大半年都没能跑出甚至接近PB的成绩,果然还是不甘心也不服输。
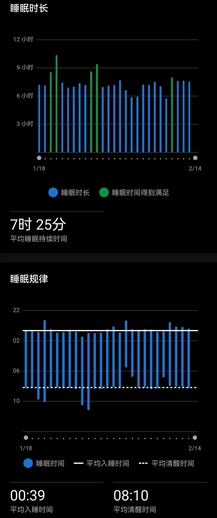
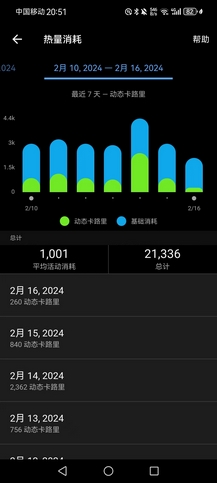
- 目前三天都维持住训练量,除夕春节各800C+的消耗,今日1100C的消耗,基本持平学校的量,吃饭完全不忌嘴(但是回来后不会吃很多米饭,因为菜管够),饭点往死里猛干,非饭点能管住嘴,12点前熄灯,7点半前起床,回来每天喝不到10杯水,但七八杯还是保证的。我以前从没这么约束过自己(但我觉得王总就是能这么约束自己活这么久),这次就是很想保持住状态直到开赛。

修正网易云音乐的下载,这么多年,它终于肯换JS里的明文密钥了:
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import sys
import math
import time
import json
import random
import base64
import codecs
from requests import Session
from bs4 import BeautifulSoup
from Crypto.Cipher import AES
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
class NetEase(object):
"""
Download music from [NetEase Online](https://music.163.com/)
"""
def __init__(self) -> None:
self.url_main = 'https://music.163.com/'
self.headers = {'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0'}
self.url_api = self.url_main + 'weapi/song/enhance/player/url?csrf_token='
self.url_song = self.url_main + 'song?id={}'
self.url_search = self.url_main + 'search/m/?s={}'
self.renew_session()
def renew_session(self) -> None:
"""
Refresh the session in the class.
"""
self.session = Session()
self.session.headers = self.headers.copy()
self.session.get(self.url_main)
def search_for_song_id(self, song_name: str, driver: webdriver.Firefox, n_result: int=1) -> list:
"""
Search the song ids for the given song name.
Here the selenium driver is used because the search results of NetEase is in the <iframe>...</iframe> label which is hard to deal with by simple requests.
:param song_name: Name of the song needed to search.
:param driver: A browser driver initiated by selenium.
:param n_result: Number of results returned, default 1 means select the top-1 search result.
:return song_ids: List of song ids matching ```song_name```.
"""
driver.get(self.url_main)
xpath_input_frame = '//input[@id="srch"]'
input_frame = driver.find_element_by_xpath(xpath_input_frame)
input_frame.send_keys(song_name)
input_frame.send_keys(Keys.ENTER)
driver.switch_to_frame('g_iframe')
WebDriverWait(driver, 15).until(lambda driver: driver.find_element_by_xpath('//div[@class="srchsongst"]').is_displayed())
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
result_list = soup.find('div', class_='srchsongst')
divs = list(result_list.children)[:n_result]
song_ids = []
for div in divs:
div.find('div', class_='td')
a = div.find('a')
song_id = a.attrs['id'][5:]
song_ids.append(song_id)
driver.quit()
return song_ids
def download_by_song_id(self, song_id: str, save_path: str=None, driver: webdriver.Firefox=None) -> None:
"""
Download the song by id and write it into local file.
"""
song_url = self.request_for_song_url(song_id, driver=driver)
r = self.session.get(song_url)
if save_path is None:
save_path = 'netease_{}'.format(song_id)
with open(save_path, 'wb') as f:
f.write(r.content)
def request_for_song_url(self, song_id: str, driver: webdriver.Firefox=None) -> str:
"""
Get the resource URL of the song needed to be downloaded.
"""
formdata = self.encrypt_formdata(song_id, driver=driver)
r = self.session.post(self.url_api, data=formdata)
song_url = json.loads(r.text)['data'][0]['url']
return song_url
def encrypt_formdata(self, song_id: str, driver: webdriver.Firefox=None) -> dict:
"""
Encrypt the formdata by the logic in NetEase javascript.
Note that the formdata post to download music is encrypted.
"""
d='{"ids":"[%s]","br":128000,"csrf_token":""}'
e='010001'
f='00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g='0CoJUm6Qyw8W8jud'
d %= song_id
if driver is not None:
JS = 'return window.asrsea("{}", "{}", "{}", "{}")'.format(d, e, f, g)
driver.get(self.url_song.format(song_id))
formdata = driver.execute_script(JS)
formdata = dict(params=formdata['encText'], encSecKey=formdata['encSecKey'])
return formdata
def _javascript2python_a(a):
b = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
c = str()
for i in range(a): c += b[math.floor(random.random()*len(b))]
return c
def _javascript2python_b(a, b):
pad = 16 - len(a.encode())%16
a += pad * chr(pad)
encryptor = AES.new(b.encode('UTF-8'), AES.MODE_CBC, b'0102030405060708')
f = base64.b64encode(encryptor.encrypt(a.encode('UTF-8')))
return f
def _javascript2python_c(a, b, c):
b = b[::-1]
e = int(codecs.encode(b.encode('UTF-8'), 'hex_codec'), 16)**int(a,16) % int(c,16)
return format(e, 'x').zfill(256)
random_text = _javascript2python_a(16)
params = _javascript2python_b(d, g)
params = _javascript2python_b(params.decode('UTF-8'), random_text)
encSecKey = _javascript2python_c(e, random_text, f)
formdata = dict(params=params, encSecKey=encSecKey)
return formdata
def test(self):
# options = webdriver.FirefoxOptions()
# options.add_argument("--headless")
# driver = webdriver.Firefox(options=options)
# song_ids = self.search_for_song_id("燕归巢", driver, n_result=3)
# print(song_ids)
# driver.quit()
song_id = '1375266614'
r = self.download_by_song_id(
song_id,
save_path='netease_{}.mp3'.format(song_id),
driver=None,
)
if __name__ == "__main__":
ne = NetEase()
ne.test()
20240212
- 早上七点半看到24岁的基普图姆车祸去世的消息,我第一感就觉得背后是阴谋。因为他崛起得太快了,仅正式参加三场马拉松比赛,就全部都跑到2小时02分以内,而就在昨天,他的芝马成绩2:00:35被世界田联认可为世界纪录,他去年就放言要在今年四月的鹿特丹正式破二。乔神虽然值得尊敬,但他的1:59:40水分和代价实在太大,基普图姆出道两年就达到这种地步,势必动了别人的利益,而且说实话他去年4月在伦敦马拉松还当众打了中乔的脸(签约中乔,结果穿耐克比赛),肯定也得罪了不少人,很难想象这场单方车祸仅仅是个意外。
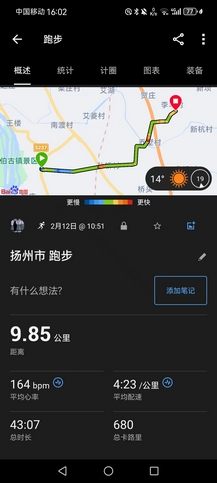
- 上午公路跑9.85km回乡,均配4’23",除夕那天跑这条线起得太猛,把右跟腱磕得很疼,今天长了些记性,换了厚底的飞飙,尽量小心了些。不是很累,但太阳很晒,心率偏高,本来这次回来老妈还夸我变白(因为下半年工作日根本见不到太阳),这样晒一周又该黑回去咯(不过,我觉得AK肯定会变更黑,确信,一个个的天天搁这黑练)。
- 回头练车,以前对开车我是一点兴趣没有,现在觉得必须老司机,不然去哪儿都要高铁好不方便。当年颜老板在吉大比赛时就是开共享汽车带我们飙,今年也是自己开车回老家福建,妥妥老司机,急人。

去年11月电脑莫名其妙间歇性变卡,一直没搞明白根源,拆后盖清灰也没清出多少灰,直到今天我终于猜到一个可能的原因,是温度太低。因为之前在公司用就一直没卡过,一旦带回学校就经常卡。还有一次先在图书馆一楼台灯区(冷)很卡,然后搬到五楼自习室(热)就不卡了。网上也没人提过这种情况,但是感觉上温度低时某些硬件确实工作效率很差,然后把电脑扔阳台晒了半天,就完全好了。
基于深度学习的人脸检测器(链接), 模型加载、预测,并将结果取出来并绘制到图片上,遍历代码的逻辑如下:
- 遍历检测结果。
- 然后,提取置信度并将其与置信度阈值进行比较。 执行此检查以过滤掉弱检测。 如果置信度满足最小阈值,继续绘制一个矩形以及检测概率。
- 为此,首先计算边界框的 (x, y) 坐标。 然后构建包含检测概率的置信文本字符串。 如果文本偏离图像(例如当面部检测发生在图像的最顶部时),将其向下移动 10 个像素。 面部矩形和置信文本绘制在图像上。
- 然后,再次循环执行该过程后的其他检测。 如果没有检测到,准备在屏幕上显示我们的输出图像)。
import numpy as np
import cv2
if __name__=='__main__':
low_confidence=0.5
image_path='2.jpg'
proto_txt='deploy.proto.txt'
model_path='res10_300x300_ssd_iter_140000_fp16.caffemodel'
# 加载模型
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(proto_txt, model_path)
# 加载输入图像并为图像构建一个输入 blob
# 将大小调整为固定的 300x300 像素,然后对其进行标准化
image = cv2.imread(image_path)
(h, w) = image.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
# 通过网络传递blob并获得检测和预测
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
# 循环检测
for i in range(0, detections.shape[2]):
# 提取与相关的置信度(即概率)
# 预测
confidence = detections[0, 0, i, 2]
# 通过确保“置信度”来过滤掉弱检测
# 大于最小置信度
if confidence > low_confidence:
# 计算边界框的 (x, y) 坐标
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# 绘制人脸的边界框以及概率
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# 展示图片并保存
cv2.imshow("Output", image)
cv2.imwrite("01.jpg",image)
cv2.waitKey(0)
20240213
- 看到一句话,基普图姆以为自己只用三场比赛就超越了乔老爷子,其实用了整整一生。第五个年头,我学会的最重要的事情就是要舍得跑慢些,以前总觉得4’30"开外的配速都不能叫跑步(有点觉得路跑太慢好丢人),现在跑六分配我都脸不红心不跳(物理上&心理上)。
- 跑休日(这两天练车、学做菜,在家还是得把只有在家才能学的事给做了),为明后长距离做准备(本想着后天要去城区吃席,可以跑些新鲜的路线,但是后天大降温+雨雪,明天是最后一个晴天,就很扫兴),但晚饭后还是出去溜达了会儿,走走停停,挺热,顺便探探明天的路线,发现沿湖线已经修得很好,据说能一路通到高邮湖,准备明早破釜沉舟跑一回,先跑出去15km,然后回程,就是爬也得爬回来,正好试试160x3.0pro,虽然不太舍得这么快就拿来路跑(反正早用早享受呗)。
- 目前净重应该不足69kg(其实每顿我都吃到撑,根本不节制,但体重就是不长),扛过最后3天,开学即可拿捏!
姿态估计(Opencv+Mediapipe)
Mediapipe是主要用于构建多模式音频,视频或任何时间序列数据的框架。借助MediaPipe框架,可以构建一些的ML管道,比如TensorFlow,TFLite等推理模型以及媒体处理功能。
pip install mediapipe
通过视频或实时馈送进行人体姿态估计在诸如全身手势控制,量化体育锻炼和手语识别等各个领域中发挥着至关重要的作用。例如,可用作健身,瑜伽和舞蹈应用程序的基本模型。
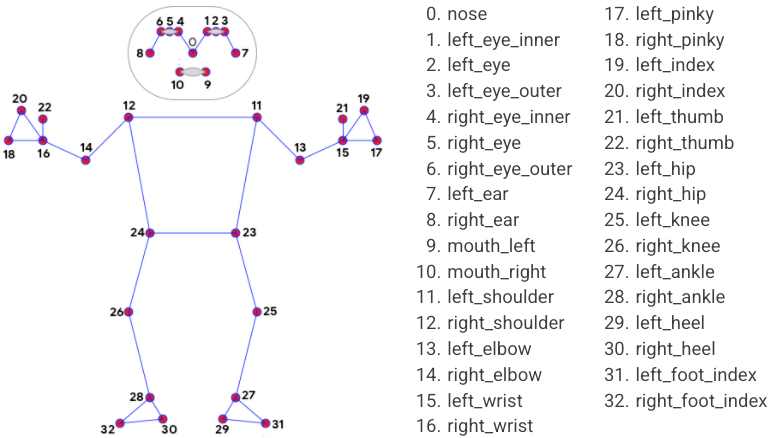
Media Pipe Pose是用于高保真人体姿势跟踪的框架,该框架从RGB视频帧获取输入并推断出整个人类的33个3D界标。当前最先进的方法主要依靠强大的桌面环境进行推理,而此方法优于其他方法,并且可以实时获得很好的结果。模型可以预测33个关键点,如下图:
DEMO代码:
import cv2
import mediapipe as mp
import time
mpPose = mp.solutions.pose
pose = mpPose.Pose()
mpDraw = mp.solutions.drawing_utils
cap = cv2.VideoCapture('1.mp4')
pTime = 0
#TODO(You): 请在此实现并输出检测结果
while True:
success, img = cap.read()
if success is False:
break
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = pose.process(imgRGB)
if results is None:
continue
print(results.pose_landmarks)
if results.pose_landmarks:
mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)
for id, lm in enumerate(results.pose_landmarks.landmark):
h, w, c = img.shape
print(id, lm)
cx, cy = int(lm.x * w), int(lm.y * h)
cv2.circle(img, (cx, cy), 5, (255, 0, 0), cv2.FILLED)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)
cv2.imshow("Image", img)
key = cv2.waitKey(1) & 0xFF
# do a bit of cleanup
cv2.destroyAllWindows()
cap.release()
20240214
- 情人节,过个鸟,反正从来没过过,简单点儿,不如跑步。
- 七点空腹称了个净重,67.5kg(我这几天真没少吃,也没练太狠,怎么掉这么多),喝一杯水,吃些碳水和牛肉,薅起还躺着的老爹(在家直接抓壮丁当移动补给箱)。寒潮前最后一日暖冬,热得离谱,上午气温20℃,适逢初五迎财神,昨晚十一点半起,鞭炮声就没停过,比除夕和春节还密集(一群财迷)。虽然没有睡得很好,但也算是休息到位。
- XTEP160x3.0pro,脚感跟飞飙差不太多(外形、颜色、鞋底也很像,但是回弹要好些,而且轻),起跑有些不合脚,感觉前掌面翘起角度太大,如果要完全踩满前脚掌,几乎要完全踮起,太吃力。但是慢慢能找到合适的方式落地,挺舒适的。寿命是2000km,从鞋底来看应该和飞飙是一个耐磨度,可以认为是飞飙的加强版(但是现在500多的飞飙已经买不到的了,最便宜的也要900向上),很好,再也不用垃圾NIKE,穿两三次鞋底就磨烂了。
- 船闸湖堤线(向高邮湖方向),很棒的一段路,没有起伏(但进船闸会有一段很长的桥要爬),沿湖景色很好,又直又长,而且几乎无人(过年这段时间两头都封路,只能步行或骑车进入),计划是25k-30k的LSD,预定配速4’20",起手第一个10km用时42’30"(均配4’15"),心率顶到170bpm以上,虽然体感没有很吃力,但已经预料到要凉了。
- 15km折返(破釜沉舟,逼自己再跑完回程15km),到20km处开始跑崩,均配已经掉到4’21",算了下最后10km慢慢摇个4’45"的配速也够跑得进4’30"的均配,但20km以后每隔2km多就已经坚持不住,必须停下喝水休息会儿,太阳晒得很痛苦。直到27km(刚好2小时少20秒左右)重新跑回船闸(这时带的两瓶水都喝光了,但还是渴得不行,老爹只能削块苹果给我吃),终点还有3km,人也多了起来,一下子就来劲了,提速冲完最后3km,用时2:12:59,均配4’26"(从8:24跑到10:45,中间休息加起来不到10分钟,差强人意)。
- 除心肺跑崩外,基本无伤(大腿和髋有些抽筋),回去拉伸二十分钟复原,基本满意的一次LSD训练,没有很累,下午去医院闭关(本来初五是该出去玩,但实在不想情人节出去,给自己找不自在,而且天太热)。说实话,我很难想象今天这个状态(最近真的保养得很好,已经是相当好的状态)还能再坚持12.2km跑完全马,而且这个配速差破三10秒不止,破三任重道远,我有点想拼阳寿先去抽一下4.21的上半马,基本上跑进130就能直通上马,但又觉得自己无法再保持住状态等到下半年,唉。

opencv.dnn模块已经支持大部分格式的深度学习模型推理,该模块可以直接加载tensorflow、darknet、pytorch等常见深度学习框架训练出来的模型,并运行推理得到模型输出结果。opecnv.dnn模块已经作为一种模型部署方式,应用在工业落地实际场景中。
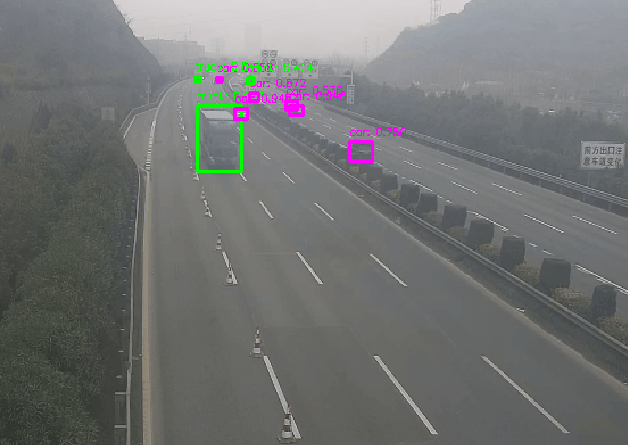
模型具体加载和使用流程如下:
加载网络,读取模型、网络结构配置等文件
创建输入,opencv.dnn模块对图片输入有特殊格式要求
运行推理
解析输出
应用输出、显示输出
下面是opencv.dnn模块加载yolov3-tiny车辆检测模型并运行推理的代码:
import numpy as np
import cv2
import os
import time
from numpy import array
# some variables
weightsPath = './yolov3-tiny.weights'
configPath = './yolov3-tiny.cfg'
labelsPath = './obj.names'
LABELS = open(labelsPath).read().strip().split("\n")
colors = [(255, 255, 0), (255, 0, 255), (0, 255, 255), (0, 255, 0), (255, 0, 255)]
min_score = 0.3
# read darknet weights using opencv.dnn module
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
# read video using opencv
cap = cv2.VideoCapture('./MY_TEST/8.h264')
# loop for inference
while True:
boxes = []
confidences = []
classIDs = []
start = time.time()
ret, frame = cap.read()
frame = cv2.resize(frame, (744, 416), interpolation=cv2.INTER_CUBIC)
image = frame
(H, W) = image.shape[0: 2]
# get output layer names
ln = net.getLayerNames()
out = net.getUnconnectedOutLayers()
x = []
for i in out:
x.append(ln[i[0]-1])
ln = x
# create input data package with current frame
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), swapRB=True, crop=False)
# set as input
net.setInput(blob)
# run!
layerOutputs = net.forward(ln)
# post-process
# parsing the output and run nms
# TODO
for output in layerOutputs:
for detection in output:
scores = detection[5:]
# class id
classID = np.argmax(scores)
# get score by classid
score = scores[classID]
# ignore if score is too low
if score >= min_score:
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height)= box.astype("int")
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(score))
classIDs.append(classID)
# run nms using opencv.dnn module
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.2, 0.3)
# render on image
idxs = array(idxs)
box_seq = idxs.flatten()
if len(idxs) > 0:
for seq in box_seq:
(x, y) = (boxes[seq][0], boxes[seq][1])
(w, h) = (boxes[seq][2], boxes[seq][3])
# draw what you want
color = colors[classIDs[seq]]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2)
text = "{}: {:.3f}".format(LABELS[classIDs[seq]], confidences[seq])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.3, color, 1)
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.imshow("Image", image)
# print fps
stop = time.time()
fps = 1/(stop - start)
print('fps>>> :', fps)
# normal codes when displaying video
c = cv2.waitKey(1) & 0xff
if c == 27:
cap.release()
break
cv2.destroyAllWindows()
20240215
- 表哥女儿周岁,气人的一天。人变了,他现在声名鹊起,结交的人多了,但变得很糟心,虽然早挺说他那些事,但我觉得自己今天两顿饭已经很给足面子,老爹都不想去给他敬酒,我代这个做舅舅的去给把酒敬了,他亲家那边招呼也都打了,但人品真太差,尊重父母,至少在外人面前尊重些,哪怕做做样子,现在这哥是真一点脸不给姑妈姑父,人脸上有些东西很难装出来,有些东西也很难抹去。
- 我也一直想改变父母的一些观念,但至少我们仨还是很和睦,关起门来拌两嘴不过,在外面我也每天给家里打电话。但老妈这次观点很坚定,既不赞成我,也不反对我,你爱咋咋地,只有我能欺负你爸,别人都不行,你也不行。他俩现在统一战线,说到底又不是求他们认可我,我只是希望父母可以更好地理解他们的儿子。心累,反正以后又不是跟他俩过日子。
- 唯一让我欣慰的事情是晚上吃饭,一堆叔婶和祖辈跟我客气让我多吃些,我一肚子气,就真没跟他们客气,直接光速吃完一整锅炖鸡汤的鸡肉和一整条清蒸鲑鱼,外带各种虾和一堆杂七杂八的东西,吃完还反唇相讥让各位别停筷子。好呀,你们非要跟我客气,那就都别吃了。说实话没吃主食,并不是很撑,吃完顺便在酒店20层楼上下5趟,消食走人。
- 除昨天活动消耗2400C,除夕到今天初六,每天的活动消耗都在800C以上,身体恢复得很快,今天感觉除小腿酸胀(昨天拉伸小腿时间太短了,果然还是得按摩两下),其他都没有疼痛,依然可以上强度,但没必要,欲速不达,该吃吃,该练练。
彩色图像进行灰度化处理,可以在读取图像文件时直接读取为灰度图像,也可以通过函数 cv.cvtColor() 将彩色图像转换为灰度图像。
import cv2 as cv
img = cv.imread("GrayscaleLena.tif")
imgGray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("ImgGray", imgGray)
key = cv.waitKey(0)
# OR
img = cv.imread("GrayscaleLena.tif", cv.IMREAD_GRAYSCALE)
cv.imshow("ImgGray", imgGray)
key = cv.waitKey(0)
20240216
- 后悔拖到初八返程,结果今天票还是没候补上,只好先买张镇江到上海的K车兜底(关键现在去镇江也得堵),三个小时,还是无座,有些难绷。其实我只是想今天把阳历生日过了再走,毕竟这么多年(除去年春节特别早,是返沪和凯爹一起过),这一天一般都是在家,也是无奈接受奔三的现实。
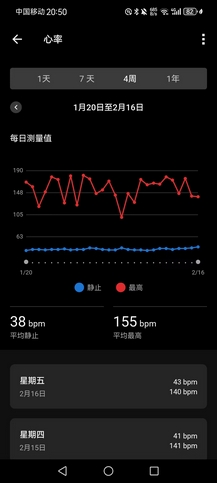
- 昨晚休息得不好,虽然七点半自然醒,但是手表显示身体电量只恢复到83(前六天一觉醒来都有98以上),白天精神很差。静息心率高出平均四五个点,不知为何,是有些紧张,安逸日子过久,不想跳出舒适圈了么?
- 罢了,放纵一日,光吃不练。年后,事情又将如何?不知晓。
简单阈值分割cv2.threshold (src, thresh, maxval, type)
像素值高于阈值时(大部分情况为127),我们给这个像素
赋予一个新值(可能是白色),否则我们给它赋予另外一种颜色(也许是黑色)。
参数:
src 源图片,必须是单通道
thresh 阈值,取值范围0~255
maxval 填充色,取值范围0~255
type 阈值类型,见下表
cv2.THRESH_BINARY二进制阈值化,非黑即白cv2.THRESH_BINARY_INV反二进制阈值化,非白即黑cv2.THRESH_TRUNC截断阈值化 ,大于阈值设为阈值cv2.THRESH_TOZERO阈值化为0 ,小于阈值设为0cv2.THRESH_TOZERO_INV反阈值化为0 ,大于阈值设为0
import cv2
import numpy as np
from matplotlib import pyplot as plt
img=cv2.imread('image.jpg',0)#必须为灰度图,单通道
ret,thresh1=cv2.threshold(img,127,255,cv2.THRESH_BINARY)
ret,thresh2=cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV)
ret,thresh3=cv2.threshold(img,127,255,cv2.THRESH_TRUNC)
ret,thresh4=cv2.threshold(img,127,255,cv2.THRESH_TOZERO)
ret,thresh5=cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()

20240217
- 零点熄灯前看了眼12306,逮着一班6:26从东站出发的高铁,五点薅起老爹送我上路,一路畅通。睡得很好,不到5小时就补到87身体电量,并不困。
- 回来先把床单被套洗了,结果洗衣机被人搞得一团糟,一堆衣服塞里头我就忍了,里面还到处湿碎的纸巾,太恶心。酒精、消毒剂、洁厕灵好好把洗衣机和厕所清理一遍。本来胡哥那边的厕所只有D间yjc会搞卫生,他1月离校后就越来越脏。
- 中午食堂又有5块钱一条的红烧鱼,可惜没年前好吃(也许过年嘴吃叼了,但至少调料确实没年前多),勉为其难干了2条。
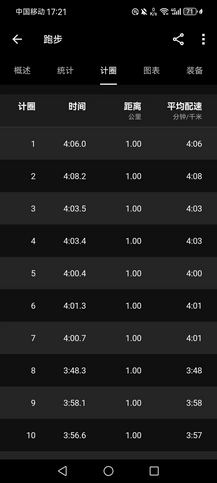
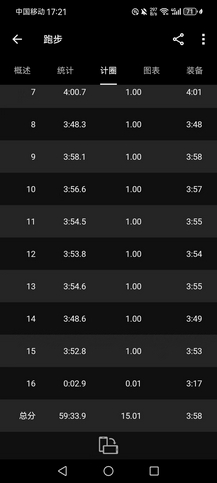
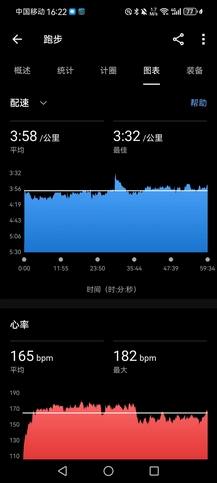
- 大晴天,8~15℃,空气质量优(前两天刚寒潮降雨,而且目前市内车辆相对也少些),而且接下来一周都是阴雨,不能偷懒,三点半下去到操场好好练了一下,均配4’07"的万米(很累,而且节奏很乱)。本想慢跑15km,但现在田径场抬腿就是4分配,根本慢不下来,而且太阳直晒,心率很快升到170bpm以上,最后到10km停止,均配4’07",很累,而且节奏很乱,跑得并不舒服。补30个箭步×8组(+20kg),基本到位。
- AK下午飞机抵沪,然后六点就出去路跑半马,均配4’02",对他来说只是寻常,但对我已是天花板。AK过年几乎每天高原跑山,状态应是极好,不过这次我的状态也不差,下周等嘉伟回来,趁他虚弱期先拿捏一下[奸笑]。
图像的膨胀与腐蚀:cv2.erode(img_origin, kernel, iterations), cv2.dilate(img_origin, kernel, iterations)

这里的kernel定义的3×3的纯黑阵用于增强或削弱图像中的黑色线条。通过调节iterations可加大剂量。
import numpy as np
import cv2
if __name__ == '__main__':
img_origin = cv2.imread('bird.jpeg', cv2.COLOR_BGR2LAB)
kernel = np.ones((3, 3), np.uint8)
img_erosion = cv2.erode(img_origin, kernel, iterations=1)
img_dilation = cv2.dilate(img_origin, kernel, iterations=1)
img_all = np.concatenate((img_origin, img_erosion, img_dilation), axis=1)
cv2.imshow('img: origin, erosion and dilation', img_all)
cv2.waitKey(0)
cv2.destroyAllWindows()
20240218
- 早上去公司打个卡就溜(反正都没人来),顺道去小姨家把老妈寄的东西全给搬回来。我真是服了,上学期奶粉没够喝到过年,于是老妈给我带了(4桶+3袋)奶粉,外加二十多个苹果,十几个丑橘,还有16只生鸡蛋,生怕饿死在学校。好在这回外婆没再买糖,年前收拾宿舍,发现去年外婆买的一堆大白兔、牛轧糖全都过期,都不知道该扔干垃圾还是湿垃圾里(总不能糖和纸拆下来分开丢吧…)。
- 天气预报又放假,今儿根本没下雨,还是大晴天——更热,等到四点多下楼遛了会儿,太阳还是晒得不行,春乏,没午睡,而且昨晚休息得不好(起床电量只补到87,明明睡到七点半自然醒,十二点半就熄灯了,可能是床不一样),进场就浑身酸,使不上力气,一共是10km多的渐加速(均配4’09"),差强人意,好天气尽量不偷懒。
- 最后拉伸时胡哥进场,他昨晚刚到宿舍(所以昨天洗衣机那锅垃圾就是B间好大儿ZZY留下的,过分),见面第一句话问我LXY回来没,他真是比我还关心(我是真不知道,根据过往经验,可能是开学前两天,反正都挺晚,但该来的总会来)。我反问他今年年咋过的,他说依然各过各的,就只去苏州找对象玩了两天,似乎也并不容易(我以为至少得见见家长之类的…)。
- PS:这么好的天气其实最适合出游,但这两天周末居然没徒步,只有今晚很水的一个两小时citywalk,下周倒有去九峰山拉练和陆羽古道,但气温骤降+阴雨天,不过,雨总会停,春天短暂,也是最好的季节。
先腐蚀再膨胀操作称为“开运算”。如下,被涂鸦了几笔的标牌,开运算无法使得痕迹消除,但闭运算可以:


import numpy as np
import cv2
def open_op(img):
kernel = np.ones((3, 3), np.uint8)
img1 = cv2.erode(img, kernel, iterations=1)
img2 = cv2.dilate(img1, kernel, iterations=1)
return img2
def close_op(img):
kernel = np.ones((3, 3), np.uint8)
img1 = cv2.dilate(img, kernel, iterations=1)
img2 = cv2.erode(img1, kernel, iterations=1)
return img2
if __name__ == '__main__':
img_origin = cv2.imread('bird.png', cv2.COLOR_BGR2LAB)
img_opened = open_op(img_origin)
img_closed = close_op(img_origin)
img_all = np.concatenate((img_origin, img_opened, img_closed ), axis=1)
cv2.imwrite('img_opened_closed.jpeg', img_all)
cv2.imshow('img: origin, erosion and dilation, dilation and erosion', img_all)
cv2.waitKey(0)
cv2.destroyAllWindows()
20240219
2023年:马拉松公园(起点)→滨水路→文昌东路→文昌中路→泰州路→高桥路→万福西路→瘦西湖路→平山堂东路→扬子江北路→扬子江中路→三湾公园(终点)
2024年:市民中心广场(起点)→文昌东路→运河北路→万福西路→高桥路→泰州路→文昌中路→汶河北路→盐阜西路→瘦西湖路→平山堂东路→平山堂西路→邗江北路→文昌西路→半程终点
- 扬马报名启动(3.31),路线依然穿越瘦西湖,起点市民广场,最后一段7km的扬子江路也被腰斩,路线地图尚未公布,可能是3月份瘦西湖路附近一所新建的高中校区要开始动工,较于去年,今年路线难度变大,加了平山堂西路,蜀冈景区的爬升太大,美但不好跑。
- 其实烟花三月是扬州最美的季节,很想请LXY一起来跑扬马。行程酒店都可以给安排好,结束再回芜湖也不远,但她最近一个月完全对我不理睬,人也迟迟未归,我觉得自己岌岌可危,琢磨不出她的态度,可能当面说机会能大一些,但真好尴尬。唉,我自己都快绷不住了。
- 下班间歇(原计划等AK一起LSD,但是天气坏起来了),3k@3’42"+2k@3’50"+1k@3’33",间歇3分钟和2分钟。原定改测5000米,但是晚上气温骤降,起风还带些雨点,只穿了件短袖+腿套,冻得有些兴奋,第一个1000米3’37",到3000米就扛不住了,临时改为倒金字塔间歇。近期整体强度偏低,确实也该跑点间歇,LSD太浪费时间了,一个月两次足够了。(昨天下午10km,手表显示要休息60小时,今晚跑完变成67小时,过往一般都是24小时,但最近状态并没有变差,只是前两天没适应突然升高的气温)。
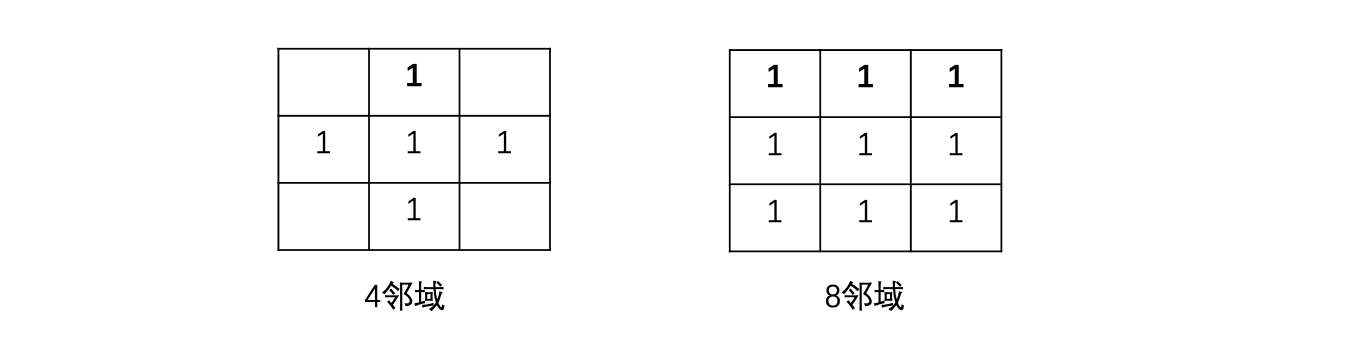
OpenCV 里的连通区域分析可以将具有相同像素值且位置相邻的前景像素点组成的图像区域识别出来。有两种像素相邻的定义:
通过OpenCV的连通区域分析算法,我们可以将下图的水鸭子的外框框出来:
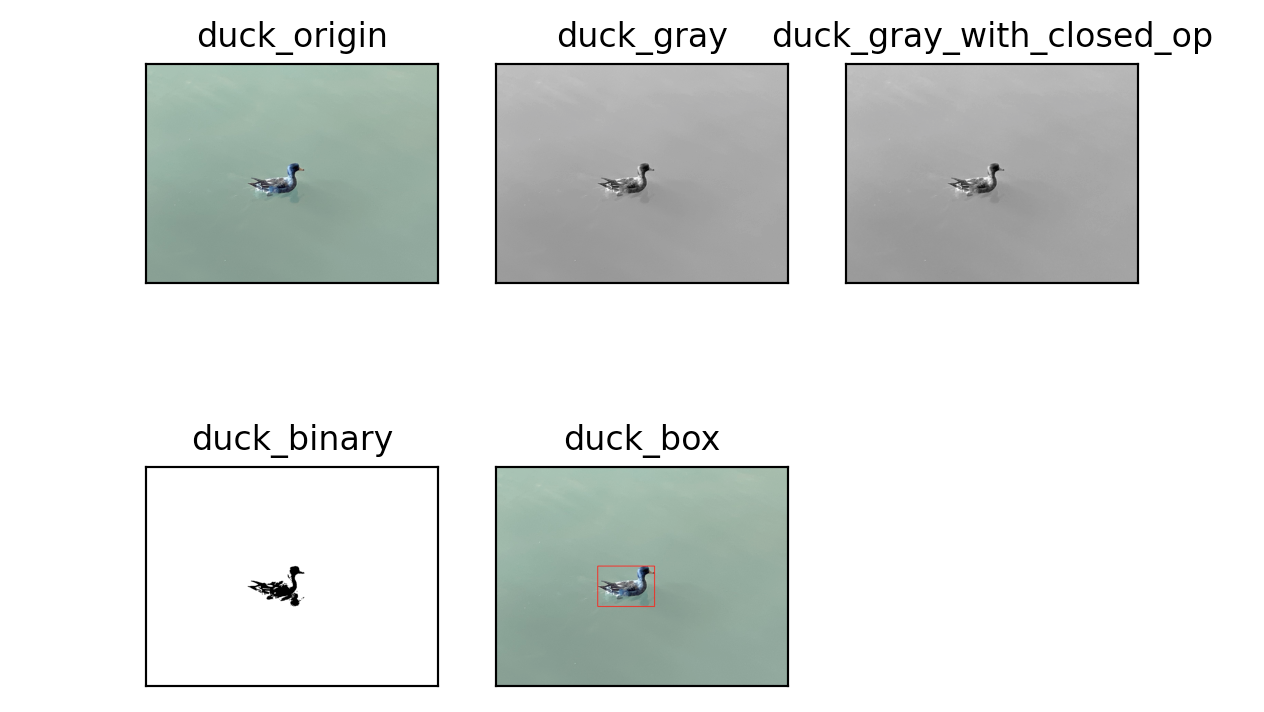
框架代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
def close_op(img):
kernel = np.ones((3, 3), np.uint8)
img1 = cv2.dilate(img, kernel, iterations=1)
img2 = cv2.erode(img1, kernel, iterations=1)
return img2
def show_images(images):
i = 0
for title in images:
plt.subplot(2, 3, i+1), plt.imshow(images[title], 'gray')
plt.title(title)
plt.xticks([]), plt.yticks([])
i += 1
plt.show()
if __name__ == '__main__':
duck_origin = cv2.imread('duck.jpeg', -1)
duck_box = duck_origin.copy()
duck_gray = cv2.cvtColor(duck_box, cv2.COLOR_BGR2GRAY)
duck_gray_with_closed = close_op(duck_gray)
ret, duck_binary = cv2.threshold(duck_gray_with_closed, 127, 255, cv2.THRESH_BINARY)
# 实现识别鸭子区域并用框出来的代码
ret, labels, stats, centroid = cv2.connectedComponentsWithStats(duck_binary)
duck_area = sorted(stats, key=lambda s: s[-1], reverse=False)[-2]
cv2.rectangle(
duck_box,
(duck_area[0], duck_area[1]),
(duck_area[0] + duck_area[2], duck_area[1] + duck_area[3]),
(255, 0, 0),
3
)
images = {
'duck_origin': duck_origin,
'duck_gray': duck_gray,
'duck_gray_with_closed_op': duck_gray_with_closed,
'duck_binary': duck_binary,
'duck_box': duck_box
}
show_images(images)
20240220
- 乳山路那家菜饭店,昨天中午是年后第一次去吃,老板见我跟见鬼似的,拉了个人最多的桌子让我坐里面,生怕我出来加饭,但我还是干了他四碗。然而今天东昌路的店还是不营业,我只得厚着脸皮继续去乳山路,我左脚才踏进门,老板就把我轰出去了,说不做菜饭了,吃四碗,钱都挣不到。我不信,进去看了眼,还真没饭(他家还做饺子、面条和汤圆),好,算你狠。转道找另一家店,生意明显差些,但老板和老板娘很淳朴,其实可以随便吃,但我实在不好意思,不到两碗就回去了。
- 首先,年前我在乳山路一共吃四次,第一次就提前问能不能加饭,老板很自信,说只要你不浪费,随便你吃;第二天再来时,他脸色就不对了,当时年关将近,附近店面大多关门,他家生意好得不行,没跟我扯皮。其次,要不是东昌路那两家到现在不开门,我才懒得来乳山路(东昌路两家门对门,竞争激烈,小菜、主菜质量都更好),我在那儿吃了几个月,老板也没撵过我。最后,我要真想吃回本,就点13元骨头汤,但我点的是25元手撕排,我就不信几碗饭还能给吃赔本。
- 昨晚AK回来冒雨15K@4’10"。我也觉得只跑个倒金字塔间歇量太少,10点半去实验楼B1补3000次单摇,不到22分钟跳完,中间只断一次。现在跳绳真的好轻松呀,身体特别轻,补100次双摇,到位。
- 今晚回来地面潮湿,操场关闭,想着不下雨还是尽量维持室外训练,计划环校线慢跑6圈(15K@4’30"),但节奏差,心率乱,跑成渐加速10K,均配4’21",很累。应该跑休一天,但总觉得状态很好,舍不得不练,身体机能却并没恢复,一个人又慢不下来。
- 突然就很怀念和LXY五分摇的时光,那时好轻松,现在很沉重…(AK说两个人有说有笑不会累,特么的他当然不累,哼)
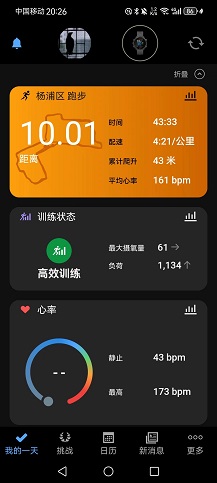
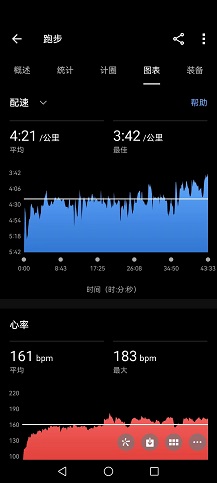
没啥大用的库pyautogui,我的评价是不如直接pynput,pymouse,pykeyboard操作键盘鼠标
pip install pyautogui
移动光标:
import pyautogui
# Get the size of the monitor.
screenWidth, screenHeight = pyautogui.size()
# Get the coordinates of the center of the screen.
x, y = screenWidth / 2, screenHeight / 2
# Move the mouse to the center of the screen.
pyautogui.moveTo(x, y)
使用size函数来捕获屏幕尺寸,并使用moveTo函数来移动光标。
单击鼠标:
import pyautogui
# Click the left mouse button.
pyautogui.click()
点击功能将在当前鼠标位置执行鼠标左键单击。
使用键盘输入,下面的代码显示了如何输入“Hello, World!”。
import pyautogui
# Type the string "Hello, World!".
pyautogui.typewrite('Hello, World!')
截图
import pyautogui
# Take a screenshot of the entire screen.
screenshot = pyautogui.screenshot()
# Save the screenshot to a file.
screenshot.save('screenshot.png')
同样,我们可以使用PyAutoGUI自动化并执行其他一些操作。
import pyautogui
import time
# 步骤 1:启动程序
pyautogui.press("win")
time.sleep(1)
pyautogui.typewrite("notepad")
time.sleep(1)
pyautogui.press("enter")
# 步骤 2 : 在程序中输入一些文本
time.sleep(2)
pyautogui.typewrite("Hello, world!\n")
# 步骤 3: 保存文件
time.sleep(2)
pyautogui.hotkey("ctrl", "s")
time.sleep(1)
pyautogui.typewrite("example.txt")
time.sleep(1)
pyautogui.press("enter")
# 第四步:关闭程序
time.sleep(2)
pyautogui.hotkey("alt", "f4")
time.sleep(1)
pyautogui.press("tab")
time.sleep(1)
pyautogui.press("enter")
20240221
- 下周应该是最后一周,凑满二月全勤。今日大雨,我还是没等到交接的林TC,步执下周要来趟上海,第一次面基,有些小紧张。
- 实话说,上海师生恋的丑闻,女方就算未婚,都很难被原谅。我们这代人其实不太可能逃得过公序良俗约束,等上一代人走了,我们的下一代很可能会颠覆三观,但我是个传统的人,我不觉得颠覆是一件好事,能稳定延续这么多年,自然有它的道理,中国这么大,不乱即为治。
- 跑休日。昨晚在实验室码到11点半回去都不觉得累,一觉醒来电量恢复到98(静息心率回归到40以下,但做了不好的梦,五点被惊醒,又想太多)。我想一定是下肢肌肉太疲劳,精神状态很好,但需要充分恢复。中午减餐,也找不到地方填饱肚子,晚上去小姨家吃点好的呗。
- 晚归计划核心训练,这组核心我在2月16日做过一回,难度不算高,单组间休息1分钟有些短,三组做完体感较累。破三就得无短板,任何弱点都意味着提前跑崩。2月14日的30km,老爹给我录像了8段跑姿,我总感觉自己上半身很稳定,但摆臂时腰腹向上还是晃,肩背太差,倒三角大哥跑起来上半身是前后左右一点儿都不会动的,极致的力量感。

cv.findContours():二值图像寻找轮廓
cv2.drawContours():绘制轮廓
cv.findContours(image, mode, method[, contours[, hierarchy[, offset]]] ) → contours, hierarchy
书画提取轮廓

import cv2 as cv
img = cv.imread("Contours.jpg", flags=1)
imgGray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(imgGray, 127, 255, cv.THRESH_BINARY_INV)
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
contourPic = cv.drawContours(img, contours, -1, (0, 0, 255), 2)
cv.imshow("ContourPicture", contourPic)
cv.waitKey(0)
其中127是二值化的阈值,它的设定需要根据具体图像的亮度情况来确定,一般情况下可以先尝试一些常用的值进行实验,再根据实际情况进行微调。
20240222
- 中午跟宝玺姐去东昌路433号干饭(这是最新发现的东昌路第三家菜饭店),我没好意思干四碗,两碗多就收手了(东昌路就很多做体力活的人去吃,饭量可不比我小)。回头路上,问宝玺过年有没有相亲,她表示还没过29周岁生日,急啥,自从她爸表哥的女儿被催婚到紫砂,家里就再没人敢催婚。
- 我觉得总需要相识很久才能建立信任,但宝玺说大多数两口子,认识两年内就结婚了,一人说,咱去领个证吧,另一人附和,这事儿就成了;但只要另一人犹豫,就大概率再也成不了。然后她又给我讲个故事,之前有个同事A,毕业想去创业,他对象说你又没经验去创什么业,然后A说那我们去结婚吧,然后,他们就真去结婚了。???
- 晚归下地铁遇东哥打完球出去吃饭,汇报了下和AK冬训的成果,东哥都震惊了。冬训肯吃苦,开春猛如虎。可能这是这辈子身体最好的一年,怎么造作都不感冒、不生病,吃得多还长不胖,精神亢奋得从起床到躺下,睡眠质量也够好,以后可能再也不会有这么恐怖的状态了。唉,总有一天会发现,身体是真的老了,怎么也挽救不回来,这也是注定的事情。
- 但人还是得活在当下,跑休一天后,今天起跑前就知道肯定身体猛得不行。1℃,场地潮湿,还飘细雨,我直接短袖紧身裤,手套和帽子都没有,鞋子也没换,前13km压住心率在150bpm上下(均配4’35"),节奏非常好。结果有个白衣小伙非要在内道逆着我跑,还故意来撞,一怒之下我提到3’45"冲2km到力竭,好呀,不让道就创死你。
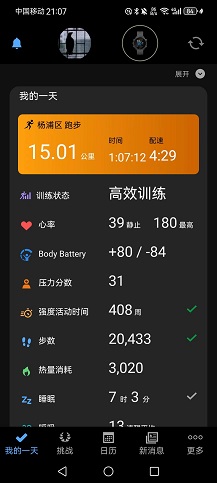
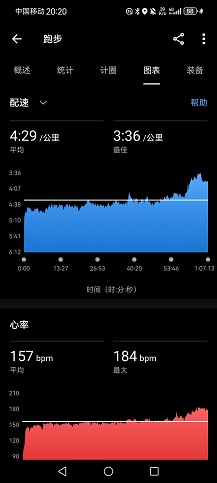
OpenCV 的颜色空间主要有 BGR、HSV、Lab等,cvtColor 函数可以让图像在不同颜色空间转换。例如通过将花的图像转换到 HSV 颜色空间,在HSV空间内过滤出只含有花瓣颜色的像素,从而提取出花瓣。
import numpy as np
import cv2
flower = cv2.imread('flower.jpeg', -1)
hsv = cv2.cvtColor(flower, cv2.COLOR_BGR2HSV) # cv2读取默认是BGR格式
lower_red = np.array([0, 20, 100]) # 花瓣颜色下界
upper_red = np.array([10, 255, 255]) # 花瓣颜色上界
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(flower, flower, mask=mask)
images = np.concatenate((flower, res), axis=1)
cv2.imshow('flower', images)
cv2.waitKey()
cv2.destroyAllWindows()
20240223
- 开学,大家终于陆陆续续地都回来了,生气渐起,然各种破事渐多。
- 下班回来冻得不行,比昨天还冷,操场不开,状态尚可,回实验楼计划室内训练(爬楼+跳绳)。但又想到LXY可能已经回来,要不试着叫出来去打会儿球?转念一想,快三周没摸拍子,估计年前练起来的又还给嘉伟,感觉现在就急着找打等于自取其辱,遂独自去羽毛球馆先黑练一把。
- 抓到一只在创智做安卓开发的码农小哥XZB陪我打(他也跑步,跑过一次半马和全马,半马137,全马350,水平很不错),球技很好,感觉不比嘉伟差,把我遛得上气不接下气,我从7.20跟他打到8.15,四方跑跳,心肺爆炸,鞋子都磨破洞了(穿的昨天跑步的休闲鞋,一个急箭步左脚外侧直接裂开,我也快裂开了,打完膝盖都疼了)。其实我真的很不好意思跟比我强的打,感觉浪费别人时间,只是自己在长球,但XZB很客气,并没有嫌我菜,后来还跟我组双打一直打到九点关门,加了好友约我以后继续练。
- AK约我明天15K@4’30",估摸着不会诚信(他诚信我也不会诚信),4’30"太慢了,15K建议直接4分配开干,麻烦来点强度,尊重一下我冬训的成果。
通过调整图像的直方图调整图像的整体细节,下图左图是浑水鱼,右边清澈鱼。

框架代码如下:
import numpy as np
import cv2
if __name__ == '__main__':
fish = cv2.imread('fish.jpeg', -1)
# TODO(You): 请正确实现浑水摸鱼代码
b, g, r = cv2.split(fish)
bx, gx, rx = cv2.equalizeHist(b), cv2.equalizeHist(g), cv2.equalizeHist(r)
fish_enhance = cv2.merge((bx, gx, rx))
images = np.concatenate((fish, fish_enhance), axis=1)
cv2.imwrite('fish_enhance.jpeg', images)
cv2.imshow('fish_enhance', images)
cv2.waitKey()
cv2.destroyAllWindows()
注意:直方图均衡化只能对灰度图使用。
fish = cv2.imread('fish.jpeg', -1):-1表示读取的图像原格式不变,得到的图像为三通道b, g, r = cv2.split(fish):通道分离,将三通道分离成单通道,为了直方图均衡化cv2.equalizeHist:直方图均衡化fish_enhance = cv2.merge((bx, gx, rx))合并图像
20240224
- 人生可以是浮萍,但总会有想要扎根的一天。其实我不是觉得只为自己而活不好,但或许真的到了想为别人而活的那天,却发现自己力不能逮。一撇不成人,高处不胜寒,一个人注定是不容易走到终点的。
- 0~3℃,雨夹雪,早上下得很大,像是一天都不会停的样子,不开心。年后回来还没跟AK跑过,得让他知道我现在有多猛。我真的特别期待全力跟AK跑一次,差距肯定依然巨大,但我想知道现在的上限在哪里。
- 下午三点瞅了眼外面,居然操场有人跑步,立即通知AK过来开干。2000米,脱外套只穿短袖干(感觉就算赤膊跑都不可能感冒),7000米,AK到场,他看到我直接震惊了,我表示感觉状态极好,4分配顶完15K不是问题,他就跟着我一直热身到13000米(4分配对他来说确是热身),这一段因为有AK陪着,跑得越来越快,越来越轻松。到10000米时,我摘掉墨镜,心率显著降低。最后2000米,AK上来破风给我拉住配速。最终15000米用时59’34"(均配3’58"),成功跑进1小时,节奏完美(匀渐加速),有被爽到。
- 后来去蜀地源干饭前还是顺路去羽毛球馆看了一眼,大受刺激。我知道LXY打得很好,但没想到打得这么好,动作很干净,而且力量很足,正手劈长劈对角能底线劈到底线,但是反手确实没有嘉伟强。我跟嘉伟说我觉得你打不过她,嘉伟表示虽然没记过分,但他有把握拿下LXY,那就老老实实再跟嘉伟练一个月,先能跟嘉伟五五开再去找死了。
图像滤波是在尽可能保留图像细节特征的条件下对目标图像的噪声进行抑制,是常用的图像预处理操作。
-
平滑滤波(低通滤波),可以抑制图像中的灰度突变,使图像变得模糊,是低频增强的空间域滤波技术。
-
盒式核是最简单的可分离低通滤波器核。盒式核结构简单,模板区域中各像素点的系数相同。
函数cv.boxFilter()可以实现直方图均衡化。
函数说明:
cv.boxFilter(src, ddepth, ksize[, dst[, anchor[, normalize[, borderType]]]]) → dst
demo:
import cv2 as cv
img = cv.imread("Lena.png")
ksize = (5, 5)
imgBoxFilter = cv.boxFilter(img, -1, ksize=ksize)
cv.imshow("BoxFilter", imgBoxFilter)
key = cv.waitKey(0)
20240225
- Black Sunday,我觉得自己好久没有这么颓废,一天没跟活人说几句话。
- 下午先是与嘉伟练球未遂,嘉伟开始留起小胡子。于是晚饭后,想独自摇会儿消食,勉强当作训练。遇胡哥,一起摇了不到10圈却发现快递刚到站,只好作罢(开学季站点东西太多,想着还是别拖到明天)。
- 取的时候碰到好久不见的宋某人,他年前一大把东西落在菜鸟没拿。好不容易又捞到个活人能说两句(我是错怪他了,他最近走路确实不方便,但我也不是很懂怎么会足底筋膜炎,力量差小腿拉伤就算了,明明他近半年三天打鱼,两天晒网,跑得也不多,而且跑姿比我要好,可能是鞋的问题?)。结果,走到一半宋某发现自己车落在菜鸟,无语,我只得帮他把几个大件搬回武川。
- 送走宋某,最后还是去操场把力量补了,重振精神,30箭步×10组(+20kg),现在20kg已经很轻松了,至少能再做两组,但还是罢了,越快,越慢,越容易失败。
在图像处理中,梯度反映了像素值的最大变化率的方向,能够突出和提取边缘,常用于工业检测中产品缺陷检测和自动检测的预处理。
OpenCV 提供了三种梯度算子:Sobel、Scharr 和 Laplacian。Sobel 梯度算子是高斯平滑和微分求导的联合运算,抗噪声能力强。
Sobel梯度算子很容易通过卷积操作cv.filter2D实现,OpenCV也提供了函数cv.Sobel实现Sobel梯度算子。
函数说明:
cv.Sobel(src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]]) → dst
用Sobel算子从Lena图像提取边缘,效果如下:

import cv2 as cv
img = cv.imread("lena.png", flags=1)
imgGray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
SobelX = cv.Sobel(imgGray, cv.CV_16S, 1, 0) # 计算 x 轴方向
SobelY = cv.Sobel(imgGray, cv.CV_16S, 0, 1) # 计算 y 轴方向
absX = cv.convertScaleAbs(SobelX) # 转回 uint8
absY = cv.convertScaleAbs(SobelY) # 转回 uint8
SobelXY = cv.addWeighted(absX, 0.5, absY, 0.5, 0) # 用绝对值近似平方根
cv.imshow("Sobel gradient", SobelXY)
cv.waitKey(0)
20240226
- 晚上吃完饭,老表非要给我秀车技,我能不知道他几斤几两,再三推让,他非要晚高峰送我回学校,结果比我坐地铁慢了一倍时间,我可真是谢谢他了。下车碰到胡哥来跑步,遂陪他摇十几分钟消食,聊了好多高中的事,没想到当年我的同桌是他同学的弟弟,地球可真是个小圈,感觉只要说到高中的好事烂事,男人不管多长多大就依然是少年。
- 昨天做完力量,很适合间歇(好久不练间歇)。下午趁着有太阳,计划【1000米@3’35"-3’40"】×8组(间歇时间1:1)。第一个1000米想试试全力能跑到多少,结果跑得特别僵硬(可能是没热开),连3’25"都没进,大失所望,动力一下子就没了。补8个【600米快+200米走】的间歇,2’07~2’10",不是很到位。感觉长距离训练对中短距离能力提升很小,现在跟两三月前水平差不太多,反过来想中短距离间歇对全马用处估计也不大,少练1000米以下的间歇。
- 新食堂现在每天中午都有5块一条的红烧鱼,八年了,终于在学校实现吃鱼自由,深得我心。
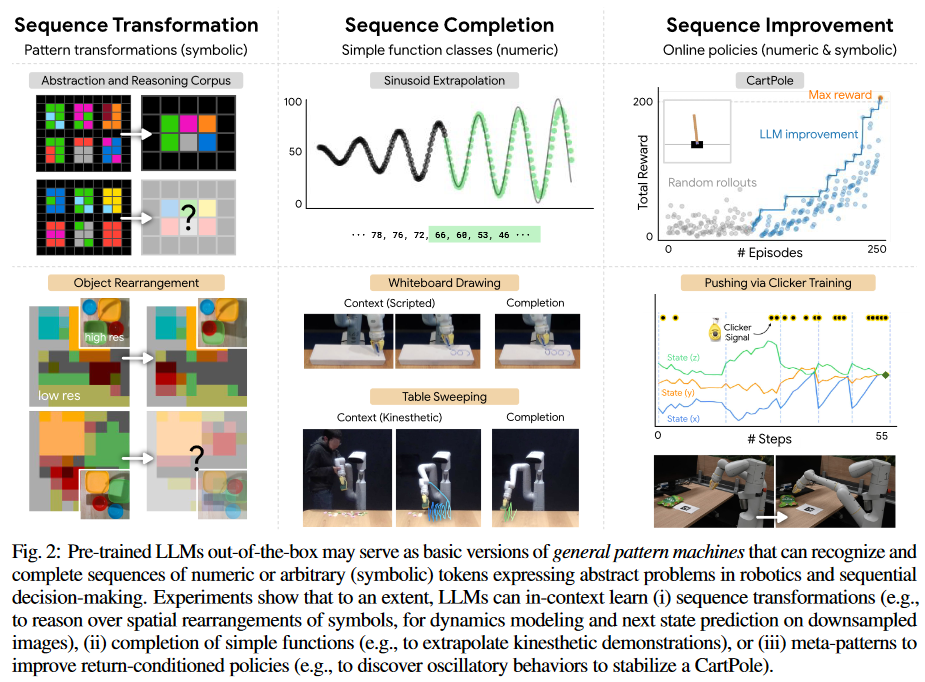
看到一个有趣的paper(arxiv@2307.04721),有人发现大模型很擅长做行测题(或者说是图形的智商测试题),因为这是个典型的序列预测,就是发现大模型不仅在文本的序列生成上做得很好,在这种非文本的模式(pattern)预测上做得也很好,其实本质上是对embedding的序列预测得好,但是对于带数字的那种找规律就行不通了,然后神奇的事情来了,如果你不把数字当成数字,而是用等价的一些字符去替代(比如你可以用十个不同的汉字去替代0123456789这十个阿拉伯数字),模型就依然保持很高的预测性能。其实本质感觉就是,任何规律都可以被函数拟合,只要参数足够多,样本量足够大,但是这个世界的规律真的是可以被彻底概括的吗?
仿射变换(矩阵旋转):
cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) -> dst
demo:
import cv2 as cv
import numpy as np
if __name__ == '__main__':
img = cv.imread("affine1.jpg")
pts1 = np.float32([[50, 50], [200, 50], [50, 200]])
pts2 = np.float32([[50, 100], [200, 50], [100, 250]])
MA = cv.getAffineTransform(pts1, pts2)
dst = cv.warpAffine(img, MA, img.shape[:2])
cv.imshow("Origin image", img)
cv.imshow("Affine transform", dst)
cv.waitKey(0)
20240227
- 三点接水时扫了眼操场,一眼就看见的显眼的红色。手机都没拿,就径直下楼去,但真不如眼睛瞎了算了。
- 教练,我不想再懦夫了。
单应性变换:在2D平面实现3D图像视角转换后的模样。
import cv2
import numpy as np
if __name__ == '__main__':
img_src = cv2.imread('rust_face_src.jpeg')
pts_src = np.array([[0, 0], [570, 0], [570, 1078], [0, 1078]])
img_dst = cv2.imread('rust_face_dest.jpeg')
pts_dst = np.array([[63, 285], [378, 224], [427, 689], [84, 820]])
dw, dh = img_dst.shape[1], img_dst.shape[0]
h, status = cv2.findHomography(pts_src, pts_dst)
img_out = cv2.warpPerspective(img_src, h, (dw, dh))
images = np.concatenate((img_src[0: dh, 0:dw, 0:3], img_dst, img_out), axis=1)
cv2.imshow('homography', images)
cv2.waitKey(0)
cv2.destroyAllWindows()
20240228
- 春寒料峭,不适时宜的雨。
- 但没有什么不开心是疯一场解决不了的。今晚被四个人轮了整整两个小时,水都没喝上一口,不停歇地在练单打,直到看到球都没有再跑去接的力气为止,浑身湿透,筋疲力竭。难得晚上有场地,还有高手不吝虐我,反正体能好得很,当然物尽所用。
- 第一个中分小哥非常强,校队水平,本来他自己占了个场地在独自练反手,厚着脸皮让他陪我打会儿,动作一致性极好,同样的动作能准确打出钓鱼/吊球/对角,猜球猜到怀疑人生,吃了四五个才能勉强反应过来打回一球,而且反手死角球能轻松以平高打回底线,看起来瘦弱,但反手就是这么有力。然后跟两个不会打球的胖子找虐,最后前端小哥XZB干我到结束,发高远永远被他杀直线,但我就是想试试怎么才能很好地劈回正手低位球,打在这个位置太难受了。技术这个东西对我来说还是太奢侈,放短球什么的太baby了,就该重炮互干,杀死为快。
- 计划周五跑休(周六强度,周日NRC招募),周三周四应该有丶强度。本来昨天的计划就是慢跑恢复,但一开始跑得实在太慢,后来一个个又莫名飞快,宋某人日常烟雾弹,恢复期顺个5K就顶到19分半,LXY也跟发疯似的像是在跑间歇,无法理解。
Harris特征提取亭子的瓦片特征:
import cv2
import numpy as np
def close_op(img):
kernel = np.ones((5, 5), np.uint8)
img1 = cv2.dilate(img, kernel, iterations=1)
img2 = cv2.erode(img, kernel, iterations=1)
return img2
def filter_green(img):
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
lower_green = np.array([50, 100, 50])
upper_green = np.array([70, 255, 255])
lower_red = np.array([0, 20, 100])
upper_red = np.array([10, 255, 255])
mask = cv2.inRange(hsv, lower_red, upper_red)
res = cv2.bitwise_and(img, img, mask=mask)
return close_op(res)
if __name__ == '__main__':
imput_img = 'tower.jpeg'
ori = cv2.imread(imput_img)
image = cv2.imread(imput_img)
no_green = filter_green(image)
# Harris 特征提取
gray = cv2.cvtColor(no_green, cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
dst = cv2.dilate(dst, None) # 这里需要做一次膨胀处理
image[dst > 0.01*dst.max()] = [0, 0, 255]
images = np.concatenate((ori, no_green, image), axis=1)
cv2.imwrite('tower_harris.jpeg', images)
cv2.imshow('tower_harris', images)
cv2.waitKey()
cv2.destroyAllWindows()
20240229
- 长雨未歇。晚九点与AK进行室内训练,实验楼上下10组(B1-15F)+3000次跳绳。
- 上周六不讲武德偷袭了AK,今晚就被狠狠地摁在地上摩擦。从第三组起,6F后我再看不到他车尾灯,每组都能拉我1~2层的距离。虽然爬楼前,我先跳了2000次绳等他过来,但爬完后每次跳不到100下就濒临力竭,一个人爬楼不会累成这样,但节奏被带乱就彻底崩溃了。
- 农历生日,昨天请宋某今晚吃饭(这顿饭从年前拖到现在),他告诉我今天补考15.15-17.15 + 17.30-21.30,本来想一个人出去吃些好的算了,转念明天又是Last Day,不如延到明天跟那边的人吃顿饭告别,以后大约很久不会再见了罢。
- PS:最近新食堂的快餐深得我心,菜品真不错(尤其是酸菜猪骨头、酸菜鱼,毛豆系列,以及不常出现的红烧鱼)。但除快餐外,纯抢钱,新园生煎包3元一个(上学期还是2元,我问为什么,阿姨说里面有虾丸,实话说只吃出玉米粒),16年生煎包才1元;以及新食堂的小馄饨,只是换个大碗,从4块卖到6块,上学期专门数了数,从12个变成15个(所以应该是4÷12×15=5元,而且16年新园小馄饨才2.5元,也是12个);更离谱的是,新食堂1楼居然开始卖泡面,就桶装康师傅堆那儿,也不知道怎么制作,但是红烧牛肉面18元,老坛酸菜19元,反正我不吃,爱咋咋地。
亭子和水中的倒影做特征匹配

import cv2
import numpy as np
if __name__ == '__main__':
img1 = cv2.imread('tower01.jpg', -1)
img2 = cv2.imread('tower02.jpg', -1)
orb = cv2.ORB_create(nfeatures=500)
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
match_img = cv2.drawMatches(img1, kp1, img2, kp2, matches[:50], None)
cv2.imwrite('tower_match.jpeg', match_img)
cv2.waitKey()
cv2.destroyAllWindows()
使用OpenCV光流分析,跟踪蚂蚁的轨迹(ant.mp4)
代码框架:
import numpy as np
import cv2
if __name__ == '__main__':
cap = cv2.VideoCapture('ant.mp4')
# ShiTomasi 角点检测参数
feature_params = dict(
maxCorners=100,
qualityLevel=0.5,
minDistance=30,
blockSize=10
)
# Lucas Kanada 光流检测参数
lk_params = dict(
winSize=(15, 15),
maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03)
)
# 获取第一帧并发现角点
ret, last_current_frame = cap.read()
last_gray = cv2.cvtColor(last_current_frame, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(last_gray, mask=None, **feature_params)
mask = np.zeros_like(last_current_frame)
color = np.random.randint(0, 255, (100, 3))
while (1):
ret, current_frame = cap.read()
if not ret:
break
current_gray = cv2.cvtColor(current_frame, cv2.COLOR_BGR2GRAY)
# TODO(You): 请在此编写光流跟踪和绘制代码
p1, st, err = cv2.calcOpticalFlowPyrLK(
last_gray, current_gray, p0, None, **lk_params)
good_new = p1[st == 1]
good_old = p0[st == 1]
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
a, b = int(a), int(b)
c, d = int(c), int(d)
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
current_frame = cv2.circle(
current_frame, (a, b), 5, color[i].tolist(), -1)
current_img = cv2.add(current_frame, mask)
cv2.imshow('current_img', current_img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
last_gray = current_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cv2.destroyAllWindows()
cap.release()
20240301
- 4.21淮安出签,候补序号很靠前,离家近,全马才3000人,又是网红赛事,口碑好(完赛有龙虾吃,不过咱邵伯龙虾一向不待见盱眙龙虾),首马大概率就在淮安,老天会眷顾我一次好天气吗?不想再输了。
- 最近三个月,12月185.7km(@4’29");1月231.5km(@4’36");2月141.4km(@4’15")。其实我有氧积累很少,因为费时间,但许多业余高手就是纯靠堆有氧达到极高水平。如南航周某(目前考研到中南),全马PB233(放言3.24锡马不达健将(220)直播自宫,是个狠人),近半年平均月跑达到令人咋舌的1300km,每天5分开外慢摇40~50km,不能说不自律,但确实挺闲…
- 不过人呢,确实该走得慢些。最后一日,搞定部署和交接。步执又被鸽,估计是有些焦头烂额,但似乎再帮不了他什么。平心而论这六个月,有被认同,有所改变,我很满意,也很喜欢这里的人和事。些许不舍,却也别无选择。
- 做了一晚上食客和听客,其实我最近还挺健谈,但兴致不高,说不出话来。而且有些高估自己的胃,挑了两条2斤重的黑鱼,小哥很好心地提醒我黑鱼分量足,菜就别多点了,我心想你不必多言,结果吃得叫那个撑。顺心就好,有些事又何所谓呢?随遇而安,即兴而动,未尝不可。
- 曲高和寡,曲终人散。后会有期。
在视频分析(或视频结构化)应用开发中,多目标跟踪是非常重要的一个环节。它能有效弥补上一个目标检测环节中算法的不足,如检测算法输出坐标不稳定、漏检等。与此同时,跟踪算法输出的目标轨迹(track-id)对于应用下阶段的行为分析环节也有着至关重要的作用。下面是常见视频分析类应用系统结构:
目标检测算法输出单帧检测结果,目标跟踪算法负责将前后2帧中的目标关联起来、给予唯一标识track-id。假设t帧中检测到了M个目标,t+1帧中检测到了N个目标,跟踪算法本质上是M->N的匹配关联过程。
匹配过程中,目标可以分为以下三大类:
- matched_tracks,t帧目标出现,t+1帧该目标仍然出现,算法匹配上。
- unmatched_tracks,t帧目标出现,t+1帧该目标消失,算法未匹配上。
- unmatched_detections,t帧目标不存在,t+1帧该目标出现,新增检测目标。
其中,对于2和3来说,跟踪算法需要考虑:
t帧目标出现,t+1帧目标其实仍然存在,但是检测算法出现短暂漏检,误认为其消失。此时的解决方案是: 某帧未被匹配到的tracks不要立即清除,而是做若干帧的缓存,等待若干帧后检测算法恢复检测
t帧目标不存在,t+1帧该目标仍然不存在,但是检测算法出现短暂误检,误认为其出现。此时的解决方案是:新增的检测目标不要立即生效,而是做若干帧的缓存,等检测算法连续检测超过若干帧、并且都能匹配关联上后再生效
之所以要考虑以上2点,主要原因是对于连续视频帧而言,大部分检测算法基本无法做到100%连续、稳定检测,出现短暂的误检、漏检非常正常。
跟踪代码示例:
# 定义跟踪算法类
class Tracker(object):
# 初始化参数
def __init__(self, max_age=1, min_hits=3, iou_threshold=0.3):
self.max_age = max_age
self.min_hits = min_hits
self.iou_threshold = iou_threshold
self.trackers = []
self.frame_count = 0
# 跟踪函数,每帧检测结果返回后,调用一次update
def update(self, dets=np.empty((0, 5))):
self.frame_count += 1
trks = np.zeros((len(self.trackers), 5))
to_del = []
ret = []
for t, trk in enumerate(trks):
pos = self.trackers[t].predict()[0]
trk[:] = [pos[0], pos[1], pos[2], pos[3], 0]
if np.any(np.isnan(pos)):
to_del.append(t)
trks = np.ma.compress_rows(np.ma.masked_invalid(trks))
for t in reversed(to_del):
self.trackers.pop(t)
# 匹配关联
matched, unmatched_dets, unmatched_trks = associate_detections_to_trackers(dets, trks, self.iou_threshold)
# 后处理逻辑
# TO-DO your code...
# 更新matched_tracks
for m in matched:
self.trackers[m[1]].update(dets[m[0], :])
# 初始化unmatched_detections,假设是当前帧新出现的检测目标
for i in unmatched_dets:
trk = KalmanBoxTracker(dets[i,:])
self.trackers.append(trk)
i = len(self.trackers)
for trk in reversed(self.trackers):
d = trk.get_state()[0]
# 输出满足条件的tracks
if (trk.time_since_update <= self.max_age) and (trk.hit_streak >= self.min_hits or self.frame_count <= self.min_hits):
ret.append(np.concatenate((d,[trk.id+1])).reshape(1,-1))
i -= 1
# 移除超过self.max_age次的漏检目标
if(trk.time_since_update > self.max_age):
self.trackers.pop(i)
# 返回跟踪结果 [[left, top, right, bottom, track-id]...]
if(len(ret) > 0):
return np.concatenate(ret)
return np.empty((0, 5))
其中:
self.max_age代表跟踪算法允许出现的最大漏检帧数
self.min_hints代表跟踪算法要求的最低连续匹配帧数
self.trackers代表跟踪算法维持的目标集合(已生成track-id)
update(self, dets)代表跟踪函数,其中参数dets代表t+1帧中目标检测结果
list[[left, top, right, bottom, score]...],即t+1帧中待匹配的detections
associate_detections_to_trackers(...) 代表IOU+卡尔曼滤波匹配算法,返回上面提到的matched_tracks, unmatched_tracks, unmatched_detections三个值
time_since_update代表目标当前漏检帧数
hit_streak代表目标当前连续匹配帧数
20240302
- 下午三点训练,停跑3天,找不到节奏。虽然三四五🏸+ 爬楼 + 核心,消耗并不小,但跑步最重要的还得是跑,这无法被任何方式替代。第二次穿160X3.0PRO,起手配速3’40",不到3000米就崩,补两组渐加速,疲累但不到位,然今天强度不宜过高,得给明早NRC体测留些力气,很想能应聘上PACER,领着那些和跟我一样没有运动细胞的人跑完比赛。
- 拉伸时叶赵志刚好进场,好久不见,遂5分配一起摇了10圈。听说上周六他被单打虐了两个多小时,又不好意思开口说休息会儿,有丶猛,体力也是真的好。两个人能压得住些,一个人还是舍不得跑得太慢。只是这么好的天气,直到最后,也没能等到该来的人。
Llama模型ipfs的序列检索号:Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm,但是现在这个节点上只剩7B的资源。
实体识别 · 人脸检测,用于根据正面像人脸,修复侧视角人脸模具的实例(已知 OpenCV 官方仓库里有人脸分类器模型文件"data_haarcascades_haarcascade_frontalface_alt.xml"):
import cv2
import numpy as np
def correct_rust_face():
img_src = cv2.imread('rust_face_src.jpeg')
pts_src = np.array([[0, 0], [0, 1078], [570, 0], [570, 1078]])
img_dst = cv2.imread('rust_face_dest.jpeg')
pts_dst = np.array([[63, 285], [84, 820], [378, 224], [427, 689]])
dw, dh = img_src.shape[1], img_src.shape[0]
h, status = cv2.findHomography(pts_dst, pts_src)
img_out = cv2.warpPerspective(img_dst, h, (dw, dh))
return img_out
def face_detect(input_image):
[x, y, w, h] = [0, 0, 0, 0]
# TODO(You): 实现人脸识别
h, w = input_image.shape[:2]
gray = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
min_size = (w // 10, h // 10)
face_cascade = cv2.CascadeClassifier(
"data_haarcascades_haarcascade_frontalface_alt.xml")
face_rects = face_cascade.detectMultiScale(
gray, 1.05, 2, cv2.CASCADE_SCALE_IMAGE, min_size)
if len(face_rects) > 0:
for face_rect in face_rects:
x, y, w, h = face_rect
cv2.rectangle(input_image, (x, y),
(x + w, y + h), [255, 255, 0], 2)
if __name__ == '__main__':
[x, y, w, h] = [0, 0, 0, 0]
rust_face_src = cv2.imread('rust_face_src.jpeg')
face_detect(rust_face_src)
rust_face_dest = cv2.imread('rust_face_dest.jpeg')
face_detect(rust_face_dest)
rust_face_dest_correct = correct_rust_face()
face_detect(rust_face_dest_correct)
images = np.concatenate(
(rust_face_src[0: 1070, 0:542, 0:3], rust_face_dest, rust_face_dest_correct[0: 1070, 0:542, 0:3]), axis=1)
cv2.imshow('rust_face_detect', images)
cv2.waitKey(0)
cv2.destroyAllWindows()
20240303
- 上午NRC面试体测,一组10人,从头到脚清一色的NIKE,水平最高的全马也就250左右,硬碰硬一点不虚。中规中矩的面试,129团长蜡烛哥也是面试官。体测是在草地进行20~30米渐加速折返跑。从Lv.1开始,根据音乐提示音不断提速,每个级别跑6对折返,我跑完Lv.11的3对往返后退场,心率186bpm,实在顶不住,此时剩余4人,第1名勉强顶完Lv.12,差强人意。
- AK今早曹山越野赛36km组男子组第二(商学院组第一),爬升1376米,平均一小时10km,离大谱。他这周天天加班,周四晚9点陪我爬楼,周五晚10点多出去跑35km(均配3’56"),昨天前往溧阳休整一日,今天一早就跑出如此惊人的成绩,太TM帅了👇
- 大受刺激,遂下午与嘉伟进行路跑拉练。许久不见,应该边跑边聊轻松些,但嘉伟一上来就是3’50"配速,来者不善,明显是要干我。因为没充分热身,起手有些吃力,但后面跑开后并不困难,10km用时39分19秒,平均配速3’56",没有掉队,最后在殷高路大路口等红灯休息会儿,过了路口距离学校2km,嘉伟不演了,3’30"配速一路狂飙,他一个寒假没怎么练,也照样稳吃我,现实就是如此残酷。
- 补30箭步×8组(+20kg),又要开始连续下雨,天气好还是补足量。下楼吃晚饭时,终于看到那三个人在操场慢跑,和从前一样,我依然只是在远望,历史的舞台从未改变,只是换了批新演员。只是这幕戏,唱了八年,也该落幕了。


实体识别(鸟图识别为例)
import cv2
if __name__ == '__main__':
img = cv2.imread('bird.jpeg', -1)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, img_binary = cv2.threshold(
img_gray, 127, 255, cv2.THRESH_BINARY)
ret, bin_img = cv2.threshold(
img_binary, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
# findCountours 函数在版本4之后返回参数只有2个
if (int(cv2.__version__[0]) > 3):
contours, hierarchy = cv2.findContours(
bin_img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
else:
img2, contours, hierarchy = cv2.findContours(
bin_img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# TODO(You): 请在此实现代码
sorted_contours = sorted(contours, key=cv2.contourArea, reverse=False)
max_contour = sorted_contours[-2]
max_contour_area = cv2.contourArea(max_contour)
bird_contours = filter(lambda c: abs(
cv2.contourArea(c)-max_contour_area) < 1000, sorted_contours)
for c in bird_contours:
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(img, (x-10, y-100),
(x+w+10, y+h+10), (0, 255, 0), 2)
cv2.drawContours(img, c, -1, (0, 0, 255), 3)
cv2.imwrite('birds_detect.jpeg', img)
cv2.imshow("birds", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
20240304
- 被薅一天,而且被一个很奇怪的BUG困扰许久,一直无法解决,头疼得不行,XZB七点叫我去打球都不想去。而且又开始连日下雨,计划永远赶不上变化,最后十点提早回来补上肢训练,一天不动还是说不太不过去,而且也不想这么快就开始熬夜。
- 3.31扬马出签,其实我已别无选择,那就好好备赛主场半马,目标1小时25分(均配4’01"),嘉伟和王兴耀的首半马都是这个成绩。从前,是多么遥不可及;如今,或许我上我也行。
SQL去重保留一条记录的两种方式:
select id,name,age from user a where id in ( select max(id) as id from user b group by age);
select id,name,age from user a where exists ( select id from ( select max(id) as id from user group by age ) b where a.id = b.id );
问题记录:GROUPBY和直接筛选COUNT的结果不同,比如:
SELECT COUNT(*) FROM A GROUP BY B
显示B = b时的计数为C,但是和
SELECT COUNT(*) FROM A WHERE B = b
的结果不同,这是为什么?
OpenCV读图片默认通道排列为BGR(即第二个参数是cv2.IMREAD_COLOR),也可以用cv2.COLOR_BGR2HSV转为HSV格式,
import numpy as np
import cv2 as cv
if __name__ == '__main__':
img = cv.imread('lena.png', cv.IMREAD_COLOR)
px = img[100, 100]
print(f'blue:{px[0]}, green:{px[1]}, red:{px[2]}')
# ----
img = cv.imread('lena.png', cv.COLOR_BGR2HSV)
px = img[100, 100]
print(f'Hue:{px[0]}, Saturation:{px[1]}, Value:{px[2]}')
# ----
img = cv.imread('lena.png', cv.COLOR_BGR2LAB)
px = img[100, 100]
print(f'L:{px[0]}, a:{px[0]}, b:{px[0]}')
20240305
- WBJ在群里一声不吭,却偷偷报三场全马,说是3月8日中金离职,然后一个月速成全马,我说你一定是疯了(不过他这种极其自律的人,即使不保持训练,状态也不会差)。本来他已经中签4.21淮安全马,但觉得太远,准备改签4.21南通全马(明早开始报名,无需抽签,先到先得)。有人一起自然极好,那我也改签南通,陪他毕业前最后跑一回,以后真只能在屏幕里瞻仰王总了。
- 但是最近七日频繁断训(3.1和3.4两日消耗不足300C,而且有效的跑步训练只有周末两天),有些许焦虑,时间越来越紧,事情却越来越多,我不愿接受状态就此下滑,让三个月几乎无间断的冬训功亏一篑。世事难两全,人无第二春,许多事还能重来,但没有人可以跑赢时间。
- 结果晚上又被薅到很晚才放人,临走前宋某跟我讲下午训练拿了新器械练大腿后侧,嘉伟自训10K+@3’50"恢复(果然周日他还是让着我了)。我问LXY练了没,他说两个都来了,我一时间竟没反应过来是啥意思。到学校已经八点半多,简餐生煎馄饨,虽然下着不小的雨,但操场开放,衣裤鞋子啥都没带,穿的还是卫衣西裤,但再不能偷懒,计划有氧跑到操场关门。
- 进场发现一个穿雨衣、光大腿跑步的小哥,这么大雨还跑的人一定是真的热爱,遂冲上前去打了个招呼。原来是附近居民,长我十岁,在备赛4.21淮安全马,老婆扬州人(他也报扬马但没中签),他自己是甘肃人,水平很高,万米PB40分钟整,说好不容易中签,就好好去练一回,他也是首马,目标3小时30分,与他边跑边聊4000多米,他到10K后开始跑600米变速,这种天气还要跑强度,自愧不如。谁不想趁还没老去的时候再疯一回呢?
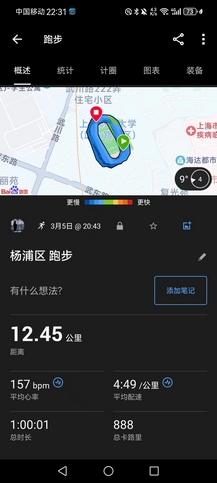
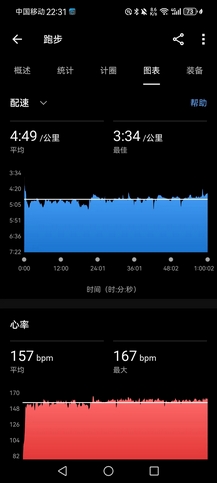
- 最后补满1小时慢跑到关门,12.45km,均配4’49",心率保持得很稳定,但鞋太重,下雨衣裤潮湿也不舒服,到后面还是有些吃力,不过结束后神清气爽,并不疲累。目前来说,破三仅仅是理论可行,我甚至不确信自己能否跑完全马,但最后46天,相信会水到渠成。我不负天,天必不负我。
之前说过LLM可以做模式识别,比如离散序列上的多步预测,但是我最近发现如果让大模型去输出给定序列的倒序输出(比如一段中文,或者一段数字,其实连GPT4-turbo都无法做得很好,序列都不用很长,10~20的长度,就一定会出错)。原因就是大模型的解码是依概率自回归的,倒序的输出并不符合语法习惯,所以很难完美的输出倒序序列。
unzip选项
-c 将解压缩的结果显示到屏幕上,并对字符做适当的转换;
-f 更新现有的文件;
-l 显示压缩文件内所包含的文件;
-p 与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任何的转换;
-t 检查压缩文件是否正确;
-u 与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中的其他文件解压缩到目录中;
-v 执行时显示详细的信息;
-z 仅显示压缩文件的备注文字;
-a 对文本文件进行必要的字符转换;
-b 不要对文本文件进行字符转换;
-C 压缩文件中的文件名称区分大小写;
-j 不处理压缩文件中原有的目录路径;
-L 将压缩文件中的全部文件名改为小写;
-M 将输出结果送到more程序处理;
-n 解压缩时不要覆盖原有的文件;
-o 不必先询问用户,unzip执行后覆盖原有的文件;
-P<密码> 使用zip的密码选项;
-q 执行时不显示任何信息;
-s 将文件名中的空白字符转换为底线字符;
-V 保留VMS的文件版本信息;
-X 解压缩时同时回存文件原来的UID/GID;
-d<目录> 指定文件解压缩后所要存储的目录;
-x<文件> 指定不要处理.zip压缩文件中的哪些文件;
-Z unzip-Z等于执行zipinfo指令。
unzip -q -d /data/test/test5 test.zip(unzip -q test.zip -d /data/test/test5)
-d 表示指定文件解压缩后所要存储的目录(-d 后面必须接路径,不然会报错,且当路径不存在时会自动创建);
WGET
#不指定下载目录
如果不指定下载目录,那么文件将被下载到当前目录。
命令格式:wget 网址
wget https://repo.mysql.com//mysql80-community-release-el8-1.noarch.rpm
#指定下载目录
命令格式:wget -p 目录 网址
wget -P /home/test https://repo.mysql.com//mysql80-community-release-el8-1.noarch.rpm
#指定下载目录及文件名
命令格式:wget 网址 -o 目录/文件名
wget https://repo.mysql.com//mysql80-community-release-el8-1.noarch.rpm -o /home/temp.rar
| 颜色 | 描述 |
|---|---|
| 粗体蓝色 | 目录 |
| 无色 | 文件或硬链接 |
| 粗体青色 | 指向文件的符号链接。 |
| 粗体绿色 | 可执行文件(.sh 扩展名的脚本) |
| 粗体红色 | 归档文件(主要是 tarball 或 zip 文件) |
| 洋红色 | 表示图像和视频文件 |
| 青色 | 音频文件 |
| 黄色配黑色背景 | 管道文件(称为 FIFO) |
| 粗体红色配黑色背景 | 损坏的符号链接 |
| 无色(白色)配红色背景 | 表示设置用户 ID 文件 |
| 黑色配黄色背景 | 表示设置组 ID 文件 |
| 白色与蓝色背景 | 显示粘滞位目录 |
| 蓝色配绿色背景 | 指向其他可写目录 |
| 黑色配绿色背景 | 当目录同时具有粘滞位和其他可写目录的特征时 |
20240306
- 晚上状态极好,而且今天没太阳,不热也不冷,想试试能否PB万米,叫嘉伟来带个强度,顺便捎上宋某。嘉伟说简单溜达一下,我心想是不可能让你溜达的(说实话,我是想趁自己状态好偷袭一下恢复期的嘉伟)。六点半进场,我表示至少39分,可以冲38分以内,嘉伟一听,盘算着也就3’50"/km左右,这也不快啊(我???),说你要这么自信,那我就按自己速度跑了。
- 心想坏了,丝毫不敢懈怠,起跑就是短袖,第一个1000米用时3’21",腿已经软了;第二个1000米用时3’35",三人已经拉开差距(我还是吊车尾的那个);2400米宋某扛不住掉队,我也强弩之末,但气势不能输,至少比宋某多跟一圈,好结束嘲笑他(
五十步笑百步);到3000米我也崩了,用时10’58"(3000米首次跑进11分钟),嘉伟后程也觉得吃力,独自顶到5000米结束,用时18’20",均配3’40"。- 最后我们仨一起又摇了5K,最后1K嘉伟带队冲了个3’20",有那种折叠腿的意思,脚都踢到臀部,很舒畅的冲刺。有些不尽人意,不过如今也勉强能跟嘉伟掰掰手腕,至少以前是无法想象。明晚还能再试一次,计划与宋某再测一次万米,我觉得差不多可以破开38分。
- PS:今天一共吃了四条鱼,真不错,新食堂真不错,有酥又脆,骨头都能嚼烂的红烧鱼,料还足,真不错。
- flash_attn预编译包:GitHub@Dao-AILab
- 关于安装:目前这个节点上还没有py312的轮子文件,所以只能创更低版本的环境,然后只能在linux系统安装,且要求torch和cuda的匹配。直接pip大概率失败,建议下载轮子安装。
-
2.1 RGB
RGB 是我们接触最多的颜色空间,由三个通道表示一幅图像,分别为红色®,绿色(G)和蓝色(B)三个通道。这三种颜色的不同组合可以形成几乎所有的其他颜色。RGB 颜色空间是图像处理中最基本、最常用、面向硬件的颜色空间。
RGB 颜色空间利用三个颜色分量的线性组合来表示颜色,任何颜色都与这三个分量有关,而且这三个分量是高度相关的,所以连续变换颜色时并不直观,想对图像的颜色进行调整需要更改这三个分量才行。
但是,人眼对于这三种颜色分量的敏感程度是不一样的,在单色中,人眼对红色最不敏感,蓝色最敏感,所以 RGB 颜色空间是一种均匀性较差的颜色空间。如果颜色的相似性直接用欧氏距离来度量,其结果与人眼视觉会有较大的偏差。对于某一种颜色,我们很难推测出较为精确的三个分量数值来表示。
所以,RGB 颜色空间适合于显示系统,却并不适合于图像处理。 -
2.2 CMY/CMYK颜色空间
CMY是工业印刷采用的颜色空间。它与RGB对应。简单的类比RGB来源于是物体发光,而CMY是依据反射光得到的。具体应用如打印机:一般采用四色墨盒,即CMY加黑色墨盒。 -
2.3 HSV颜色空间
由于上述的原因,在实际图像处理中,我们使用更多的是HSV颜色空间,因为它可以比RGB更接近人们对彩色的感知经验。
其中,HSV主要是由表达彩色图像的三个部分组成:
Hue,色相、色调
Saturation:饱和度
Value,明度 -
2.4 HLS颜色空间
HLS 和 HSV 比较类似,这里一起介绍。HLS 也有三个分量,hue(色相)、saturation(饱和度)、lightness(亮度)。
HLS 中的 L 分量为亮度,亮度为100,表示白色,亮度为0,表示黑色。其中,S与L与HSV中保持一致。 -
2.5 YUV/YCbCr颜色空间
YUV是通过亮度-色差来描述颜色的颜色空间。亮度信号经常被称作Y,色度信号是由两个互相独立的信号组成。视颜色系统和格式不同,两种色度信号经常被称作UV或PbPr或CbCr。这些都是由不同的编码格式所产生的,但是实际上,他们的概念基本相同。在DVD中,色度信号被存储成Cb和Cr(C代表颜色,b代表蓝色,r代表红色)。 -
2.6 Lab颜色空间
Lab颜色模型弥补了RGB和CMYK两种色彩模式的不足。它是一种设备无关的颜色模型,也是一种基于生理特征的颜色模型。Lab是由一个亮度通道(channel)和两个颜色通道组成的。在Lab颜色空间中,每个颜色用L、a、b三个数字表示,各个分量的含义是这样的:
L代表明度,取值0~100
a代表从绿色到红色的分量 ,取值-128~127
b代表从蓝色到黄色的分量,取值-128~127 -
2.7 LUV颜色空间
LUV通常是指一种颜色空间标准,目的是建立与视觉统一的颜色空间,因为人类眼睛有响应不同波长范围的三种类型的颜色传感器,所有可视颜色的完整绘图是三维的。但是颜色的概念可以分为两部分:明度和色度。
LUV的存在三个分量,L是亮度,u和v是色度坐标。对于一般的图像,u和v的取值范围为-100到+100,亮度为0到100。
20240307
- 服了我这老六,晚上又懦夫了一次,我不想死得太糊涂,但腆着脸硬凑上去也挺缺心眼。算了,来日方长。逃避虽然可耻,但管用。
- 青汶年后一直没来实验室,我以为他出去搞钱了,结果今天来了——拄拐杖,右脚打封闭,我大吃一惊,说这是出车祸了吗,他说是打羽球把跟腱弄断了(这得打得多狠啊,好夸张)。珍爱生命,远离羽球。
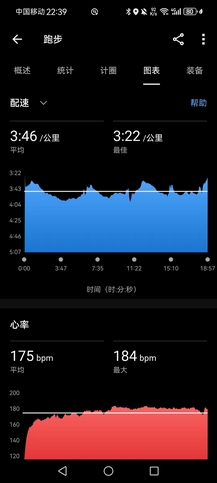
- 嘉伟晚课,宋某足底筋膜炎,胡哥半残,只能独自挑战万米38分,跑步终究是一个人的事。状态非常好(实话说现在只要不被薅得太狠,每天状态都很好),但是今晚操场人特别多,节奏不行,3000米左右踩到只瓶子,踉跄两步,节奏更乱,然后足球队开始在内道进行追逐跑,我实在气不打一处来,12圈后直接冲200米狠狠干了他们一下,不想再坚持下去,第一个5000米用时18分57秒,均配3’46",如果有个水平相当的陪伴,我有信心顶完后半程,把万米跑进38分钟。
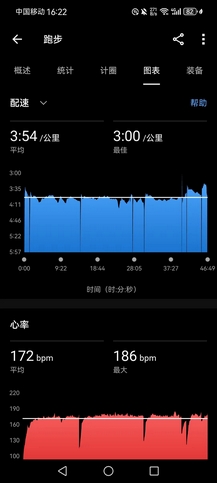
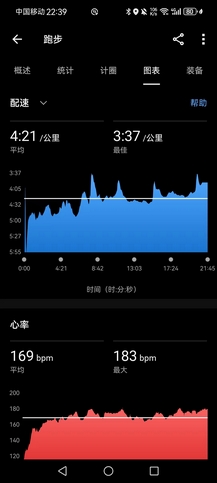
- 换鞋,计划慢跑10km收尾,但队里开始追逐跑,我下意识跑得越来越快,4’21"均配跑完第二个5000米。此时胡哥进场,我觉得可以陪他再干一个5000米,前半程因为在带胡哥,跑得并不快(胡哥最近连4’10"的配速都吃力,而4’0x"的配速对我已经非常轻松,有意收住步幅才行),3000米后我甩掉胡哥,3’40"配速狂飙(速度波动很大,因为每次过东哥和追逐跑的队伍时都想着提速),感觉有用不完的力气,第三个5000米用时19’25",均配3’53"。其实完全有余力再跑一个20分钟以内的5000米,但是时间太晚了。
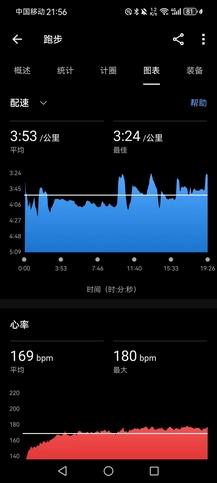
- 明日跑休,计划周六与嘉伟进行20km@4’00"/km的拉练(正好带129高级组的一个阿姨把10km跑进40分)。上半年赛季只有AK和嘉伟能陪我练,但差距太大,他俩状态好时,我就无能吃🍔。希望毕业前能掰倒嘉伟,让我也当回现役长跑第一【真·白日做梦】。
-
arxiv.2403.03594:大模型对图像的审美评价
大型语言模型在各种智力任务上表现出很高的性能。然而,很少有研究调查在涉及感性的行为中与人类的一致性,例如审美评价。本文研究GPT-4与Vision(一种可以处理图像输入的最先进的语言模型)在图像美学评估任务中的性能。采用两个任务,预测一个群体的平均评价值和个人评价值。我们通过探索提示和分析预测行为来研究GPT-4与Vision的性能。实验结果表明,GPT-4具有Vision在预测审美评价和对美丑不同反应的性质方面的优越性能。最后,我们讨论了基于人类对美的感知的科学知识,利用融合传统的代理技术,开发一个用于审美评估的系统。
-
FlagAlpha微调的Atom-7B系列,只支持中文生成,英文输入没有输出。
-
Atom-7B需要安装
pip install flash-attn: -
Flash Attention 2无法调用:
ImportError: /usr/local/lib/python3.10/dist-packages/flash_attn_2_cuda.cpython-310-x86_64-linux-gnu.so: undefined symbol: _ZNK3c1010TensorImpl27throw_data_ptr_access_errorEv在https://github.com/Dao-AILab/flash-attention/issues/451找到一个很简单的解决方案:
Try a cxx11abiFALSE version在https://github.com/Dao-AILab/flash-attention/releases找到适合的版本,注意选取
cxx11abiFALSE的版本(我不确信是否这表示非cuda版本,不过跑着确实挺慢)
目前mgtgpu02集群上给的GPU环境是:
import torch
torch.backends.cudnn.benchmark=True
print(torch.cuda.is_available()) # False
print(torch.cuda.device_count()) # 0
print(torch.__version__) # 2.2.1+cu121
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device) # cpu
print(torch.version.cuda) # 12.1
下的轮子是:flash_attn-2.5.6+cu122torch2.2cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
Jupyter从conda环境新建内核:python -m ipykernel install --user --name py310-adapters --display-name <Jupyter Notebook里展示的名称>
-
提前安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ipykernel -
展示所有内核:
jupyter kernelspec list -
删除内核:
jupyter kernelspec remove <kernelname>
https://huggingface.co/docs
- transformers
- diffusers
20240308
- 步执来上海(说实话,步执也没比我大多少,咋就开始一副油腻大叔样,胡子拉碴一点不修边幅…),中午一起吃饭,顺便跟新来的RWT见面。小伙子高大帅气,跟李乐康差不多,一看出身就不简单,但是可比李乐康那拽小子谦逊多了,给人印象很好,他是做运营管理的,我一下子有了兴趣,以为库存优化之类,结果方向是产品营销(其实我们这边更喜欢叫收益管理),我也很有兴趣,于是跟他聊了好多产品组合的建模问题(他告诉我葛冬冬跑安泰去了,真是唉,学院留不住人呐),我其实很想知道他们这个方向现在瓶颈是在建模还是求解,但听下来感觉他们安泰做这个方向还没有我们自己学院做得好。其实我对这种数学建模问题很感兴趣,尤其是现在被大模型冲击了后,越来越觉得自己做的方向没有科学性可言,全是拼钱拼配置,至少这种建模的事情能让我做得有成就感些。
- 躲了两周最终还是被wyl拖下水,无语至极。晚上去小姨家补些好的,明日如果嘉伟能来,势必是场恶战(其实我觉得如果跑20km,嘉伟未必稳吃我,短距离确实容易被他锤烂)。
OpenCV读图片默认通道排列为BGR(即第二个参数是cv2.IMREAD_COLOR),也可以用cv2.COLOR_BGR2HSV转为HSV格式,
import numpy as np
import cv2 as cv
if __name__ == '__main__':
img = cv.imread('lena.png', cv.IMREAD_COLOR)
px = img[100, 100]
print(f'blue:{px[0]}, green:{px[1]}, red:{px[2]}')
# ----
img = cv.imread('lena.png', cv.COLOR_BGR2HSV)
px = img[100, 100]
print(f'Hue:{px[0]}, Saturation:{px[1]}, Value:{px[2]}')
# ----
img = cv.imread('lena.png', cv.COLOR_BGR2LAB)
px = img[100, 100]
print(f'L:{px[0]}, a:{px[0]}, b:{px[0]}')
-
2.1 RGB
RGB 是我们接触最多的颜色空间,由三个通道表示一幅图像,分别为红色®,绿色(G)和蓝色(B)三个通道。这三种颜色的不同组合可以形成几乎所有的其他颜色。RGB 颜色空间是图像处理中最基本、最常用、面向硬件的颜色空间。
RGB 颜色空间利用三个颜色分量的线性组合来表示颜色,任何颜色都与这三个分量有关,而且这三个分量是高度相关的,所以连续变换颜色时并不直观,想对图像的颜色进行调整需要更改这三个分量才行。
但是,人眼对于这三种颜色分量的敏感程度是不一样的,在单色中,人眼对红色最不敏感,蓝色最敏感,所以 RGB 颜色空间是一种均匀性较差的颜色空间。如果颜色的相似性直接用欧氏距离来度量,其结果与人眼视觉会有较大的偏差。对于某一种颜色,我们很难推测出较为精确的三个分量数值来表示。
所以,RGB 颜色空间适合于显示系统,却并不适合于图像处理。 -
2.2 CMY/CMYK颜色空间
CMY是工业印刷采用的颜色空间。它与RGB对应。简单的类比RGB来源于是物体发光,而CMY是依据反射光得到的。具体应用如打印机:一般采用四色墨盒,即CMY加黑色墨盒。 -
2.3 HSV颜色空间
由于上述的原因,在实际图像处理中,我们使用更多的是HSV颜色空间,因为它可以比RGB更接近人们对彩色的感知经验。
其中,HSV主要是由表达彩色图像的三个部分组成:
Hue,色相、色调
Saturation:饱和度
Value,明度 -
2.4 HLS颜色空间
HLS 和 HSV 比较类似,这里一起介绍。HLS 也有三个分量,hue(色相)、saturation(饱和度)、lightness(亮度)。
HLS 中的 L 分量为亮度,亮度为100,表示白色,亮度为0,表示黑色。其中,S与L与HSV中保持一致。 -
2.5 YUV/YCbCr颜色空间
YUV是通过亮度-色差来描述颜色的颜色空间。亮度信号经常被称作Y,色度信号是由两个互相独立的信号组成。视颜色系统和格式不同,两种色度信号经常被称作UV或PbPr或CbCr。这些都是由不同的编码格式所产生的,但是实际上,他们的概念基本相同。在DVD中,色度信号被存储成Cb和Cr(C代表颜色,b代表蓝色,r代表红色)。 -
2.6 Lab颜色空间
Lab颜色模型弥补了RGB和CMYK两种色彩模式的不足。它是一种设备无关的颜色模型,也是一种基于生理特征的颜色模型。Lab是由一个亮度通道(channel)和两个颜色通道组成的。在Lab颜色空间中,每个颜色用L、a、b三个数字表示,各个分量的含义是这样的:
L代表明度,取值0~100
a代表从绿色到红色的分量 ,取值-128~127
b代表从蓝色到黄色的分量,取值-128~127 -
2.7 LUV颜色空间
LUV通常是指一种颜色空间标准,目的是建立与视觉统一的颜色空间,因为人类眼睛有响应不同波长范围的三种类型的颜色传感器,所有可视颜色的完整绘图是三维的。但是颜色的概念可以分为两部分:明度和色度。
LUV的存在三个分量,L是亮度,u和v是色度坐标。对于一般的图像,u和v的取值范围为-100到+100,亮度为0到100。
import matplotlib.pyplot as plt
import cv2
canshi_BGR = cv2.imread("./canshi.png")
# show BGR canshi
plt.subplot(3, 3, 1)
plt.imshow(canshi_BGR)
plt.axis('off')
plt.title('canshi_BGR')
# BGR to RGB
canshi_RGB = cv2.cvtColor(canshi_BGR, cv2.COLOR_BGR2RGB)
plt.subplot(3, 3, 2)
plt.imshow(canshi_RGB)
plt.axis('off')
plt.title('canshi_RGB')
# BGR to GRAY
canshi_GRAY = cv2.cvtColor(canshi_BGR, cv2.COLOR_BGR2GRAY)
plt.subplot(3, 3, 3)
plt.imshow(canshi_GRAY)
plt.axis('off')
plt.title('canshi_GRAY')
# BGR to YCrCb
canshi_YCrCb = cv2.cvtColor(canshi_BGR, cv2.COLOR_BGR2YCrCb)
plt.subplot(3, 3, 4)
plt.imshow(canshi_YCrCb)
plt.axis('off')
plt.title('canshi_YCrCb')
# BGR to HSV
canshi_HSV = cv2.cvtColor(canshi_BGR, cv2.COLOR_BGR2HSV)
plt.subplot(3, 3, 5)
plt.imshow(canshi_HSV)
plt.axis('off')
plt.title('canshi_HSV')
# BGR to HLS
canshi_HLS = cv2.cvtColor(canshi_BGR, cv2.COLOR_BGR2HLS)
plt.subplot(3, 3, 6)
plt.imshow(canshi_HLS)
plt.axis('off')
plt.title('canshi_HLS')
# BGR to CIE L*a*b
canshi_Lab = cv2.cvtColor(canshi_BGR, cv2.COLOR_BGR2Lab)
plt.subplot(3, 3, 7)
plt.imshow(canshi_Lab)
plt.axis('off')
plt.title('canshi_Lab')
# BGR to CIE L*u*v
canshi_Luv = cv2.cvtColor(canshi_BGR, cv2.COLOR_BGR2Luv)
plt.subplot(3, 3, 8)
plt.imshow(canshi_Luv)
plt.axis('off')
plt.title('canshi_Luv')
plt.show()
20240309
与嘉伟诚信一日(现在跑个4分配都没法诚信了,嘉伟你做个人吧):
- 两点多在楼上接水时就看到大长腿大步幅,跑姿目测至少330,他说是热身跑了2K,可能我们对热身这个词的理解不太一样。
- 阿姨说3点来,嘉伟提议让我带他20分钟跑个5K活动一下,1000米用时3’45",我听到后面冷笑一声嘉伟冲上前来(嘉伟:你不仁就别怪我不义了),开始3’35"带队企图拉爆我,顶到3000米后我已十分痛苦(11’02"),嘉伟也感觉有些吃力,就先告一段落。
- 然后带阿姨10K40分,她状态太差,跑了将近44分。而嘉伟在等她,放了个海,我在前面带4’00"~4’10"的配速。(现在4分配明显要收着跑,4’15"则非常轻松,我觉得跑起来一点感觉没有。目前半马进125比全马破三把握大一些),甚至把他俩套了圈。
- 10K结束我觉得余力尚足,提议再来一个10K,配速3’50"~4’00",嘉伟表示可行,结果起手他带队2K用时7’10"(均配3’35",我就是满状态也是死路一条),当场爆炸,2K下场。后来他37’56"顶完第二个10K,均配3’47",我觉得他就是故意想拉爆我(报我套圈之仇),要是就按照这个配速匀速跑,我必能扛下。
一些感概:
- 一个冬天过去,有氧阈从4’10"提升到3’50",彻底把4’00"这个两三年没跨过槛踩在脚下,目前跟嘉伟的配速差距在10秒左右。嘉伟已经恢复到去年11月巅峰水平,隐隐有所提升,说锡马是要冲245(均配3’53"),可期。
- 愚钝如我,走了太多弯路,各种停摆、倒退、伤痛、厌跑,尤其去年跟AK一个多月夏训,每晚30多度的蒸笼跑到衣服湿透,都没能达到2021年底的水平(2021.12.4队内测试,5000米19’59"),整整两年无法把5000米重新跑进20分钟(神奇的是,5K重新跑进20分前,我先在2023.12.23把万米先跑进了40分),真该认命了。很多人系统练个半年就能破三,但我直到第五年才找到正确无伤的训练方法。用“有用”或是“没用”来评价跑步这项运动,都是对跑者极大的侮辱。《强风吹拂》里说,对跑者最大的赞誉,从来不是说TA跑得有多快,而是说,TA是一个强大的人。每个人的天赋、条件、支持都不同,有人天生就跑得快,但没有人天生强大。
- 就是在去年11月26日陪嘉伟跑完上马后,我下定决心参赛全马(那天在现场我可能比他自己都要激动,我状态很好,感觉我上我也行,多么想越过围栏一起跑,特别特别后悔没有报名)。首马对于我来说是很神圣的事,要是能在上马这种级别的赛事完成首马,再破三,说是前半生里程碑的事件都不足为过。当时不敢想过要破三,太遥远太遥远;如今,传说成为可能。虽然我运气一向很差,但4月21日注定会是个好日子。

itemset方法
import math
def hacker(img):
height, width, channels = img.shape
for i in range(0, width):
for j in range(0, height):
b, g, r = img.item((i, j))
hack_b = int(math.pow(b/256.0, 3/2) * 256)
hack_g = int(math.pow(g/256.0, 4/5) * 256)
hack_r = int(math.pow(r/256.0, 3/2) * 256)
img.itemset((i, j), (hack_b, hack_g, hack_r))
使用 OpenCV 可以方便的剪切粘贴图像上的区域。例如下图是梅西在踢足球
通过剪切粘贴可以获得足球连续运行的轨迹
实现代码如下,需要补全TODO部分:
import cv2
import numpy as np
if __name__ == '__main__':
img = cv2.imread('ball.jpg', cv2.IMREAD_COLOR)
start = [493, 594]
end = [112, 213]
ball = img[start[0]:start[1], end[0]:end[1]]
x_step = 101
y_step = 10
for i in range(-1, 4):
# TODO(You): 请在此实现代码
x_offset = x_step*i
y_offset = y_step*i
img[start[0]-y_offset:start[1]-y_offset, end[0]+x_offset:end[1]+x_offset] = ball
cv2.imshow("ball_continue", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
20240310
- 环金鸡湖半马,AK1:18:26(均配3’42"),信欣1:29:32(PB)。老大哥还是你老大哥,随意出手就已是天花板。
- 扬马选号,手慢无,选不到生日,各种吉利的数字组合也被抢光。不过这次在B区,前面只有A区和特邀,虽然两枪制,B区依然是第一枪最后一个出发的区,但总归比去年E区强些。
- 午饭后操场小憩,太阳直晒,睡草地真舒服。醒来进行力量训练,30箭步×10组(+20kg),提踵50次×4组(左右交替),单杠卷腹上身10个×2组,目前单臂吊杆能坚持10秒以上(但是引体向上还是无法实现零的突破),但明显左右臂力量不平衡,左臂吊杆身体立刻就会旋转,右臂吊杆相对稳定。昨天阿姨给录了几段视频,跟嘉伟步频步幅已能保持一致,但摆臂不行。现在腰腹及以下没有明显弱点,想要继续提升得练肩背。
- 晚饭后独自慢跑10km,恢复+消化(昨天拼尽老命了,今天想跑休,但嘉伟听讲座,XZB在玩公路车,没搭子打球,不如堆有氧),前9000米4’28"定速巡航,最后1000米冲刺3’27",心率低,节奏稳,感觉真不错。
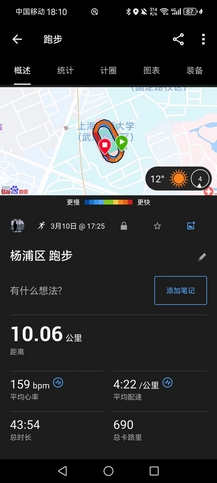
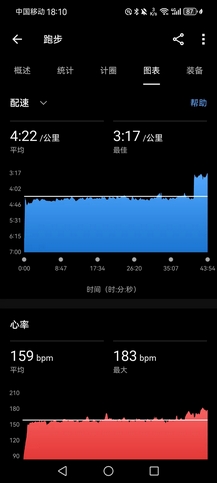
1、complex()
complex()方法接受两个参数(real和image)并返回一个复数张量,复数实部real,虚部image,其中实部和虚部都是具有相同数据类型和相同形状的张量。
a_real = torch.rand(2, 2)
print(a_real)
a_imag = torch.rand(2, 2)
print(a_imag)
a_complex_tensor = torch.complex(a_real, a_imag)
print(a_complex_tensor)
tensor([[0.4356, 0.7506],
[0.5335, 0.6262]])
tensor([[0.1342, 0.0804],
[0.2047, 0.0685]])
tensor([[0.4356+0.1342j, 0.7506+0.0804j],
[0.5335+0.2047j, 0.6262+0.0685j]])
如果实部和虚部形状不同则会报错:
real = torch.rand(1, 2)
print(real)
imag = torch.rand(0)
print(imag)
complex_tensor = torch.complex(real, imag)
print(complex_tensor)
2、reshape()
reshape可以更改张量形状,它返回与指定数组相同的数据,但具有不同的指定维度大小。
a = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8])
print(a)
print(a.reshape([4, 2]))
tensor([1, 2, 3, 4, 5, 6, 7, 8])
tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
3、view()
view()用于在二维格式行和列中更改张量。我们必须指定要行数和列数。
a=torch.FloatTensor([24, 56, 10, 20, 30,
40, 50, 1, 2, 3, 4, 5])
print(a)
print(a.view(4, 3))
tensor([24., 56., 10., 20., 30., 40., 50., 1., 2., 3., 4., 5.])
tensor([[24., 56., 10.],
[20., 30., 40.],
[50., 1., 2.],
[ 3., 4., 5.]])
reshape 和 view 都是用于改变张量形状的操作,但它们之间有一些关键的区别。
view:
-
view 是一个对张量进行重新视图的方法。
-
它返回一个新的张量,该张量与原始张量共享相同的数据,但形状可能发生改变。
-
view 操作要求新形状的元素数量必须与原张量相同,否则会引发错误。
-
view 可以用于改变张量形状,但仅当原始张量的数据在内存中是连续的时候。
reshape:
-
reshape 函数也用于改变张量形状。
-
与 view 不同,reshape 返回一个新的张量,而不共享原张量的数据。它总是返回一个新的张量,即使数据在内存中是连续的。
-
reshape 允许在元素数量相同的情况下改变形状,因为它可以自动推断缺失的维度大小。
20240311
- 被RWT从早坑到晚。早上陪他办入职手续,中午陪他遛街(从乳山路逛到东昌路,从地下逛到地上,把周边能吃饭的点都给排雷),下午给他讲了近3小时代码(我来的时候就没这种待遇,ZSP直接扔个烂摊子给我,全靠自己摸索)。四点半无缝衔接被慧悦拉去跟业务开会,我想着都快润了,不至于让我讲太多吧,结果硬是被薅半个多小时,步执都听出来我嗓子要哑了,唉。
- 但是精神并不差,回来吃4个生煎包垫饥,马不停蹄开往操场训练,简简单单跑个40分钟的万米,想快就快,想慢就慢,心率都能压在165bpm以内,不能说很轻松,只能说是随心所欲。
- 连续三个多月,身体状态持续攀升,完全不见顶点,但未必幸事。物极必反,盛久必衰,老爹说我是在透支年轻时的资本,我不以为意,但也真是很害怕某天会突然生病,那一定会是一场重病。
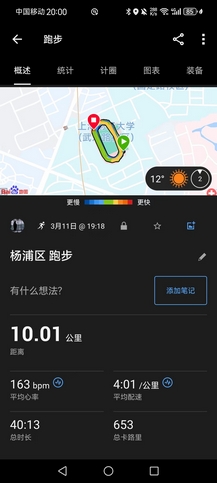
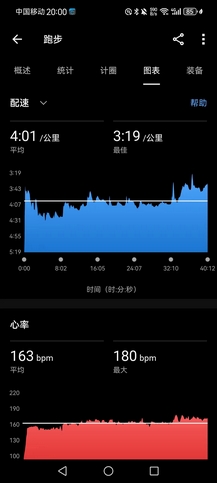
6、take()
take会根据给定的索引选择张量并返回。输入张量被看作是一维张量。结果的形状与指标的形状相同。
a = torch.tensor([[1,2,3],
[3, 4,7],
[4,5,6]])
torch.take(a, torch.tensor([1,4,5]))
tensor([2, 4, 7])
如果索引超过了张量的长度则会报错。
>>> a = torch.tensor([[1,2,3],
[3, 4,7],
[4,5,6]])
torch.take(a, torch.tensor([0,3,6,8,10]))
7、unbind()
unbind可以用来移除一个张量维度。它将返回一个元组,包含给定维度上的所有切片,也就是说会将张量变成一个张量的列表。
>>> a = torch.tensor([[1,2,3],
[3, 4,7],
[4,5,6]])
torch.unbind(a)
(tensor([1, 2, 3]), tensor([3, 4, 7]), tensor([4, 5, 6]))
8、reciprocal()
reciprocal返回一个新的张量与输入元素的倒数。
>>> torch.reciprocal(torch.tensor([[1.6,2.5],[3,4],[5,6]]))
tensor([[0.6250, 0.4000],
[0.3333, 0.2500],
[0.2000, 0.1667]])
9、t()
转置是翻转张量轴的过程。它涉及到交换二维张量的行和列,或者更一般地说,交换任何维度张量的轴。
>>> E = torch.tensor([ [3, 8], [5, 6]])
tensor([[3, 8],
[5, 6]])
>>> F = torch.t(E)
tensor([[3, 5],
[8, 6]])
10、cat()
张量运算中的cat是将两个或多个张量沿特定维度连接起来形成一个更大张量的过程。得到的张量有一个新的维度,它是输入张量的原始维度的连接。
>>> a = torch.tensor([[1, 2], [3, 4]])
>>> b = torch.tensor([[5, 6]])
>>> c = torch.cat((a, b), dim=0)
tensor([[1, 2],
[3, 4],
[5, 6]])
20240312
- 修改目录
- 在Anaconda Prompt中(cmd亦可)执行
jupyter notebook --generate-config - 找到
jupyter_notebook_config中的c.NotebookApp.notebook_dir - 找到开始菜单中的“Jupyte Notebook”快捷键(在Anaconda3的目录下),右击选择打开快捷方式所在的位置,右击快捷方式,选择属性,将"%USERPROFILE%/"删除,重新打开jupyter即可。
- jupyter 调用conda环境
使用Anaconda Prompt,执行:
conda install jupyter
conda install ipykernel # 安装jupyter内核
# 添加虚拟环境到jupyter中
python -m ipykernel install --user --name 虚拟环境名 --display-name 在jupyter中显示的环境名称
前两个install是没有才要安装,否则直接执行第三个即可,如:
python -m ipykernel install --user --name myopenai --display-name myopenai_jupyter
python -m ipykernel install --user --name py310-adapters --display-name py310-adapters
当然这里是提前会先创建好openai的环境:
conda create --name openai python=3.9 # 至少要有3.8才行,3.7是安装不了openai的
列出所有环境
jupyter kernelspec list
删除指定环境:
jupyter kernelspec remove <kernelname>
我最近发现,如果不在指定的venv里创建kernel,得到的kernel似乎并不生效,所以最好按照以下流程进行:
- 先激活指定的venv
- 然后执行
python -m ipykernel install --user --name py310-adapters --display-name py310-adapters - 最后在这个venv里打开notebook,必然生效
不太清楚到底哪个步骤是必要的,可能是第二个吧。
- jupyter重新配置nbextensions
问题是在Anaconda3/Script下面没有找到jupyter-contrib-nbextension文件,所以无法调用jupyter contrib nbextension install --user或者jupyter contrib-nbextension install --user命令
目前找到的方法是用这篇博客可行:https://blog.csdn.net/VictoriaLy/article/details/127108676
pip uninstall jupyter_contrib_nbextensions
pip uninstall jupyter_nbextensions_configurator
pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com jupyter_contrib_nbextensions
# 进入 ~Lib\site-packages\jupyter_contrib_nbextensions
python application.py install
jupyter contrib-nbextension install --user
pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com jupyter_nbextensions_configurator
jupyter nbextensions_configurator enable --user
完篇(首马四十日倒计时)
AGR告一段落,掐指一算,首马剩余40天。那就把一切悬念,留在下篇。
妈妈总说,每次你想做得更好时,都会搞砸。高考,国赛,跑步,打球,最近的人与事。
我有很多想写的话,或许,无需多言。
五年磨一剑,时间会见证一切。
我不再执着于去证明何物,只想在最血气方刚的年纪,
不留遗憾地,沉沦在彻底释放的疯狂。
- 三月三十一,重回主场,一雪前耻。
- 四月十四日,以赛促训,以赛代练。
- 四月二十一,伊始?终结。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









