










 本文介绍了欧拉路径的概念,重点阐述了Hierholzer算法的步骤,以及如何将其应用于LeetCode中的旅行行程问题。算法通过深度优先搜索和逆序入栈策略找到连通图的欧拉路径,具有O(mlogm)的时间复杂度和O(m)的空间复杂度。
本文介绍了欧拉路径的概念,重点阐述了Hierholzer算法的步骤,以及如何将其应用于LeetCode中的旅行行程问题。算法通过深度优先搜索和逆序入栈策略找到连通图的欧拉路径,具有O(mlogm)的时间复杂度和O(m)的空间复杂度。
一.问题概述
欧拉路径是什么?
通过图中所有边的简单路。(换句话说,每条边都通过且仅通过一次)也叫”一笔画”问题。
通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
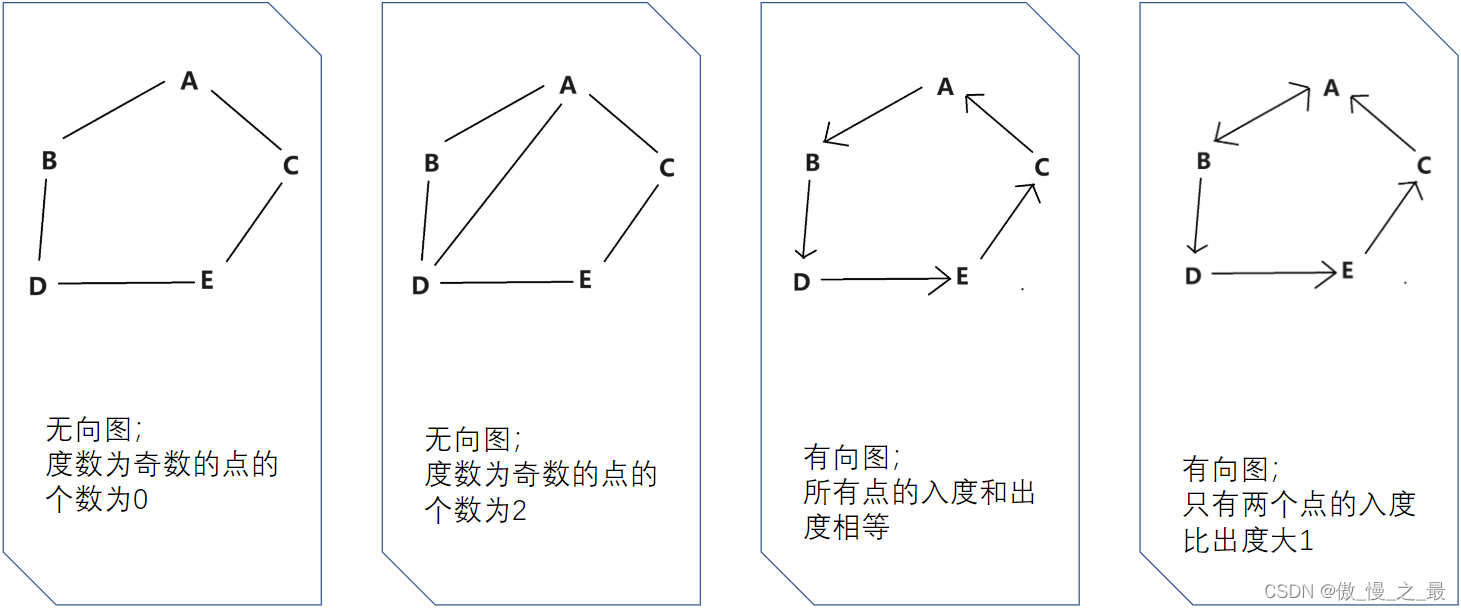
判定(充要条件)
- 图是连通图,即不存在断连的点;
- 若是无向图,则这个图的度数为奇数的点必须是0或2;
- 若是有向图,要么所有的点的入度和出度相等,要么有且只有两个点的入度分别比出度大1或者小1。
二.算法思想
Hierholzer算法流程
1.对于无向图,判断度数为奇数点的个数,若为0,则设任意一点为起点,若为2,则从这两个点中任意取一个作为起点;
对于有向图,判断入度和出度不同的点的个数,若为2,则设入度比出度小1的点为起点,另一个点为终点。
2.从起点开始进行递归,对于当前节点x,扫描与x相连的所有边,当扫描到某一条边(x,y)时,删除该条边,并递归y,扫描完所有边后,将x加入队列。
3.倒序输出答案队列。
4.从起点开始,每一次执行递归函数,相当于模拟一笔画的过程。递归的边界显然就是路径的终点,对于一个有欧拉路径的图,此时图上的所有边都已被删除,自然就不能继续递归。由于存储答案是在遍历以后进行的,答案存储也就是倒序的,因此要倒序输出答案。
欧拉路径举例
三.leetcode——重新安排行程
1.题目出示

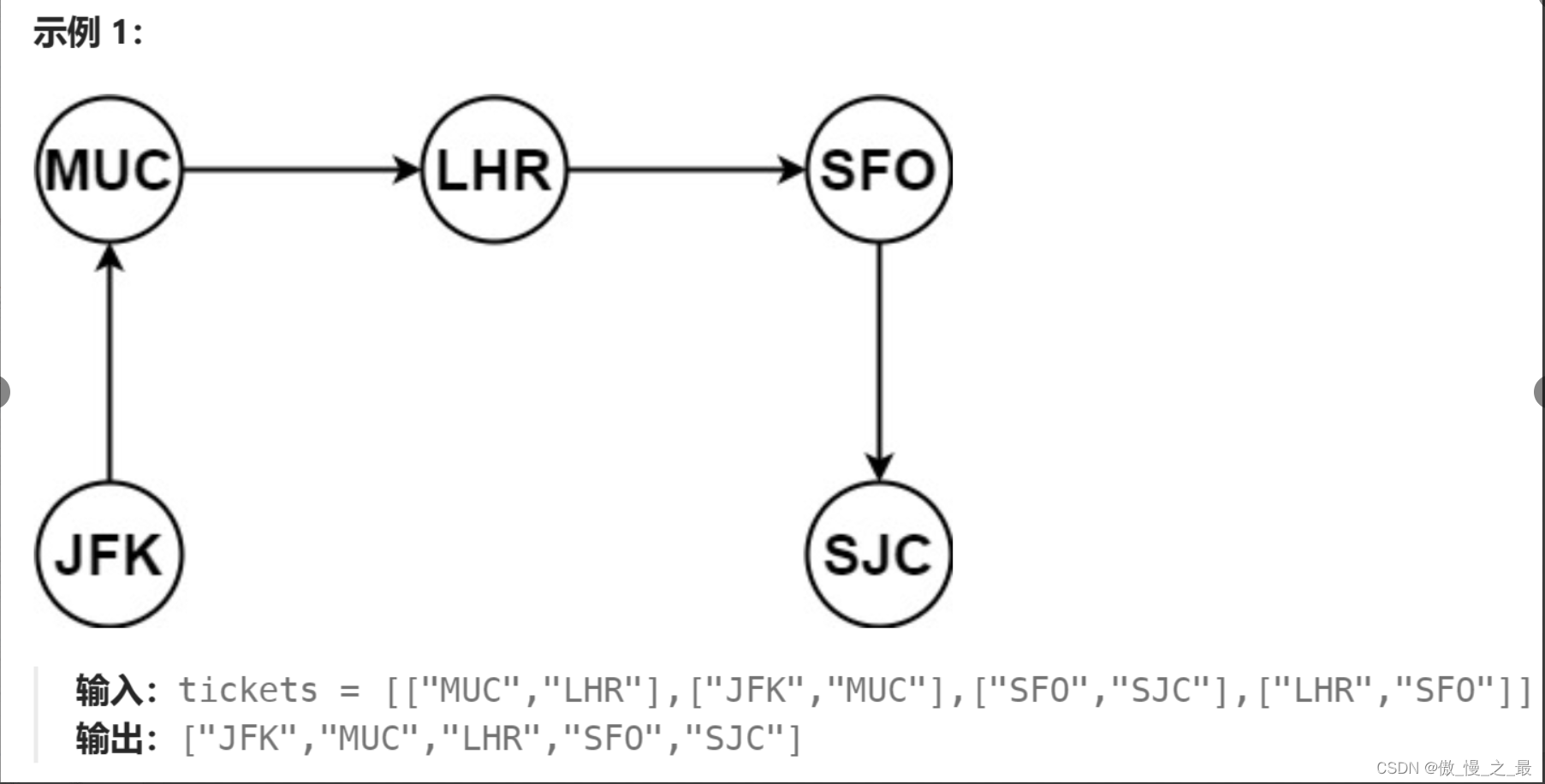
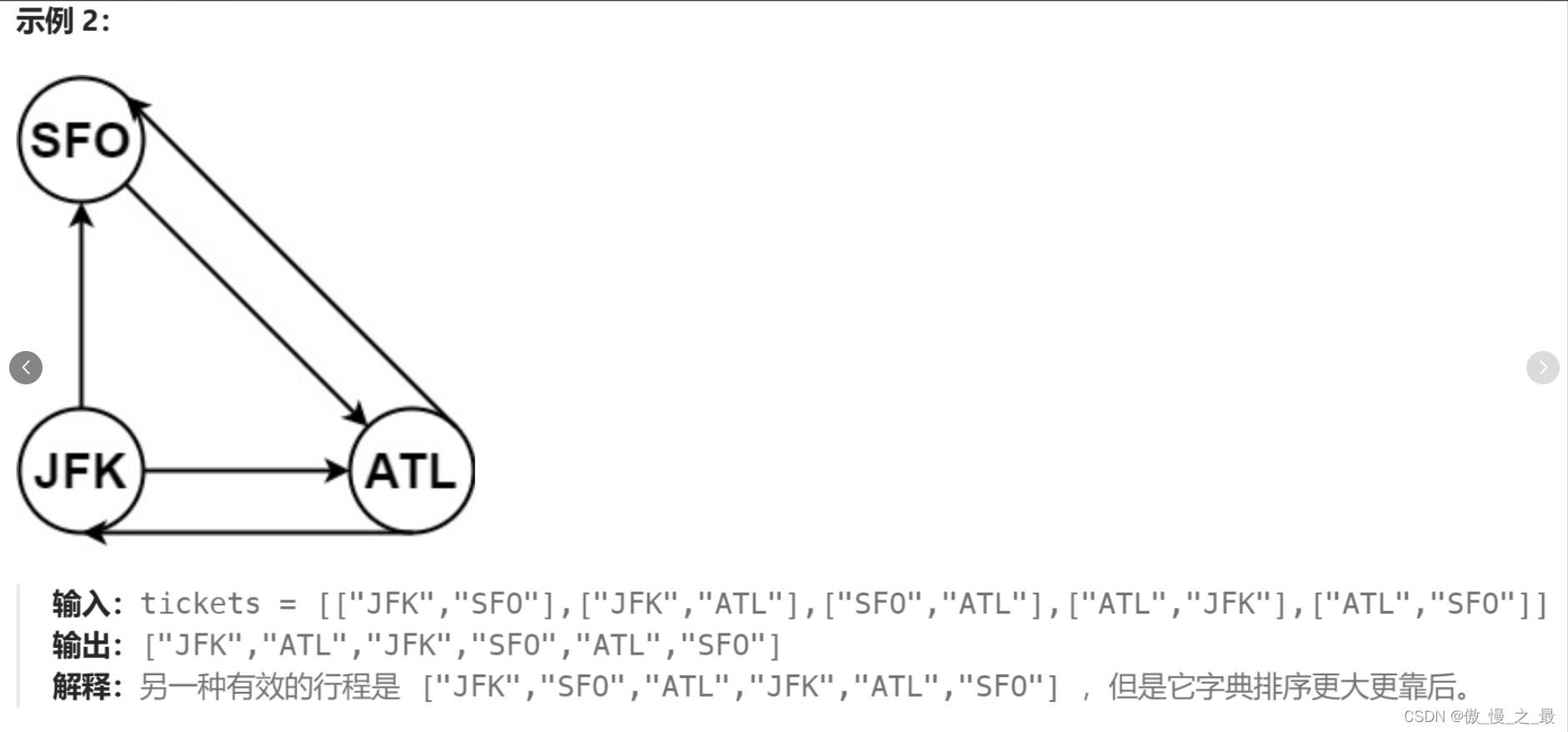
2.思路讲解
Hierholzer 算法用于在连通图中寻找欧拉路径,其流程如下:
从起点出发,进行深度优先搜索。
每次沿着某条边从某个顶点移动到另外一个顶点的时候,都需要删除这条边。
如果没有可移动的路径,则将所在节点加入到栈中,并返回。
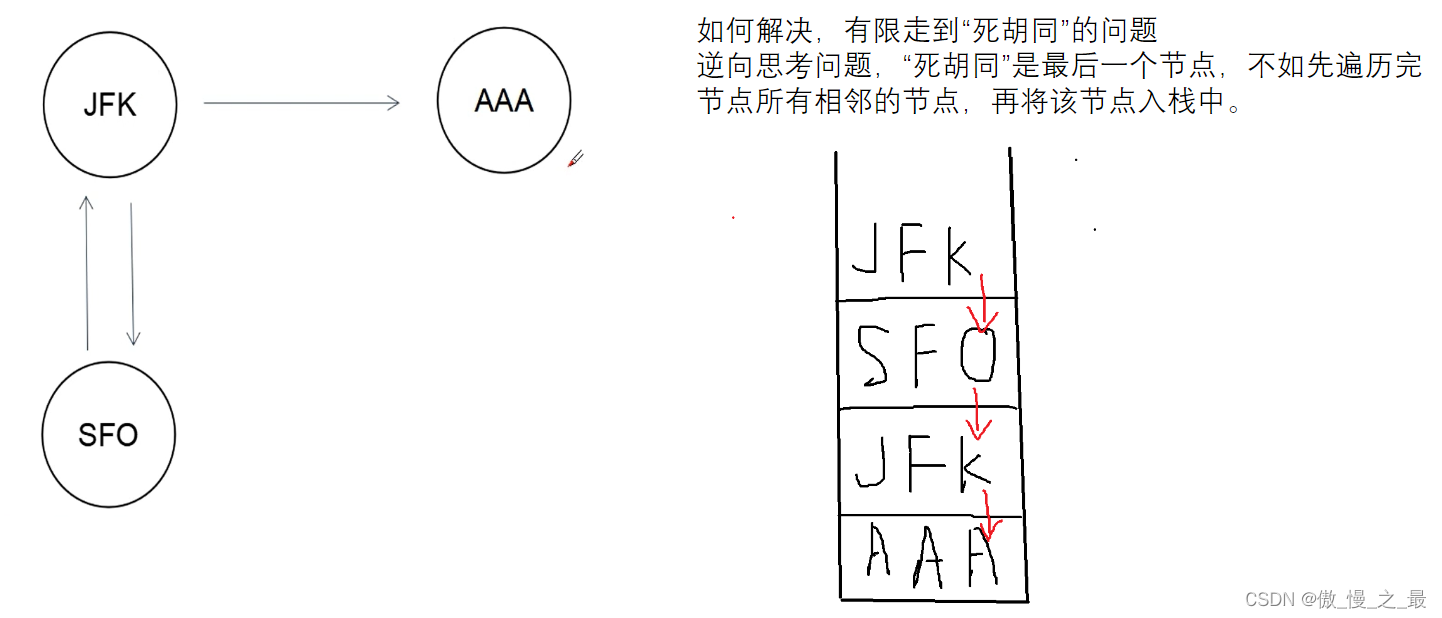
当我们顺序地考虑该问题时,我们也许很难解决该问题,因为我们无法判断当前节点的哪一个分支是「死胡同」分支。
不妨倒过来思考。我们注意到只有那个入度与出度差为 1 的节点会导致死胡同。而该节点必然是最后一个遍历到的节点。我们可以改变入栈的规则,当我们遍历完一个节点所连的所有节点后,我们才将该节点入栈(即逆序入栈)。
对于当前节点而言,从它的每一个非「死胡同」分支出发进行深度优先搜索,都将会搜回到当前节点。而从它的「死胡同」分支出发进行深度优先搜索将不会搜回到当前节点。也就是说当前节点的死胡同分支将会优先于其他非「死胡同」分支入栈。
这样就能保证我们可以「一笔画」地走完所有边,最终的栈中逆序地保存了「一笔画」的结果。我们只要将栈中的内容反转,即可得到答案。
3.算法思想
本题思路
- 必须从JFK机场出发;
- 字典序,每次有限走字典小的路径;
- 每张票最少保证用且用一次,所以每走完一次需要擦除走过的路。
Hierholzer算法流程
- 选择任一顶点为起点,遍历所有相邻边;
- 深度搜索,访问相邻顶点,将经过的边都删除;
- 如果当前顶点没有相邻边,则将顶点入栈;
- 栈中的顶点倒序输出,就是从起点出发的欧拉路径。
4.代码实现
// 将字符串形式的机场代码转换为整数ID
int str2id(char* a) {
int ret = 0;
for (int i = 0; i < 3; i++) {
// 假设机场代码为3个字母,通过累加26的次方和字符与'A'的差值来计算ID
ret = ret * 26 + a[i] - 'A';
}
return ret;
}
// 比较函数,用于qsort排序,按照起始机场ID逆序、目的地机场ID逆序排序
int cmp(const void* _a, const void* _b) {
int** a = (int**)_a, ** b = (int**)_b;
// 如果起始机场ID不同,则直接返回差值;如果相同,则比较目的地机场ID
return (*b)[0] - (*a)[0] ? (*b)[0] - (*a)[0] : (*b)[1] - (*a)[1];
}
// 主函数,构建旅行路线
char** findItinerary(char*** tickets, int ticketsSize, int* ticketsColSize, int* returnSize) {
// 初始化每个机场的目的地列表长度为0
memset(vec_len, 0, sizeof(vec_len));
// 为栈分配内存,用于存储访问顺序
stk = malloc(sizeof(int) * (ticketsSize + 1));
stk_len = 0;
// 临时数组,用于存储机票信息的ID形式
int* tickets_tmp[ticketsSize];
for (int i = 0; i < ticketsSize; i++) {
// 为每张机票的ID形式分配内存
tickets_tmp[i] = (int*)malloc(sizeof(int) * 2);
// 将机票信息的字符串形式转换为ID形式
tickets_tmp[i][0] = str2id(tickets[i][0]);
tickets_tmp[i][1] = str2id(tickets[i][1]);
// 保存ID对应的字符串到id2str数组中,便于后续恢复字符串形式
id2str[tickets_tmp[i][0]] = tickets[i][0];
id2str[tickets_tmp[i][1]] = tickets[i][1];
}
// 使用qsort对机票ID信息进行排序
qsort(tickets_tmp, ticketsSize, sizeof(int*), cmp);
// 遍历排序后的机票ID信息,构建每个机场的目的地列表
int add = 0;
while (add < ticketsSize) {
int adds = add + 1, start = tickets_tmp[add][0];
// 找到所有以start为起始机场的机票
while (adds < ticketsSize && start == tickets_tmp[adds][0]) {
adds++;
}
// 设置起始机场的目的地列表长度
vec_len[start] = adds - add;
// 为起始机场的目的地列表分配内存
vec[start] = malloc(sizeof(int) * vec_len[start]);
// 将目的地ID填充到列表中
for (int i = add; i < adds; i++) {
vec[start][i - add] = tickets_tmp[i][1];
}
// 更新add,处理下一个起始机场
add = adds;
}
// 从"JFK"机场开始进行深度优先搜索,构建访问顺序
dfs(str2id("JFK"));
// 设置返回数组的长度
*returnSize = ticketsSize + 1;
// 为返回的字符串数组分配内存
char** ret = malloc(sizeof(char*) * (*returnSize));
// 将栈中的机场ID转换回字符串形式,并逆序存入返回的数组中
for (int i = 0; i < *returnSize; i++) {
ret[(*returnSize) - 1 - i] = id2str[stk[i]];
}
// 释放临时数组占用的内存
for (int i = 0; i < ticketsSize; i++) {
free(tickets_tmp[i]);
}
// 返回构建的旅行路线数组
return ret;
}四.性能分析
复杂度分析
时间复杂度:O(mlogm),其中 m 是边的数量。对于每一条边我们需要 O(logm) 地删除它,最终的答案序列长度为 m+1,而与 n 无关。
空间复杂度:O(m),其中 m 是边的数量。我们需要存储每一条边。


















 2936
2936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











