







文章目录
前言
加油!要振作起来!虽然毕业遥遥无期,但是要努力。不要被实验打倒!
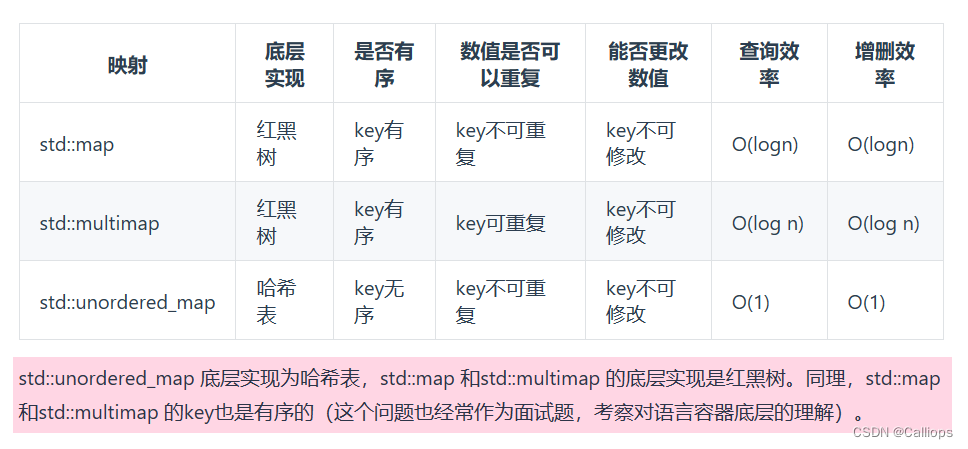
哈希表的理论基础:哈希函数,哈希碰撞(拉链法,线性探测法)、c++3中哈希结构

242.有效的字母异位词

思路
题目分析:就是A里的字母B是否全出现过,且B在A里面是否全出现过;
🎈本题补充知识点:视频中提到,三种hash结构:数组,set和map;那么三种什么时候使用呢?如果范围较小,数值较小,使用数组*,如果范围大,使用set;如果需要有k和对应的value,那就使用map*
回到本题:最多只有0-26个字母,范围小,使用数组;
总体思路
定义一个数组叫做record用来上记录字符串s里字符出现的次数。
大小为26,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值,存储位置连续。
对于s字符串,遍历的时候映射数组的下标所在的元素+1,再对于t字符串,遍历的时候映射数组的下标所在的元素-1;如果两个字符串满足条件,那么最后这样交互的操作之后数组一定全部为0,否则就不是。
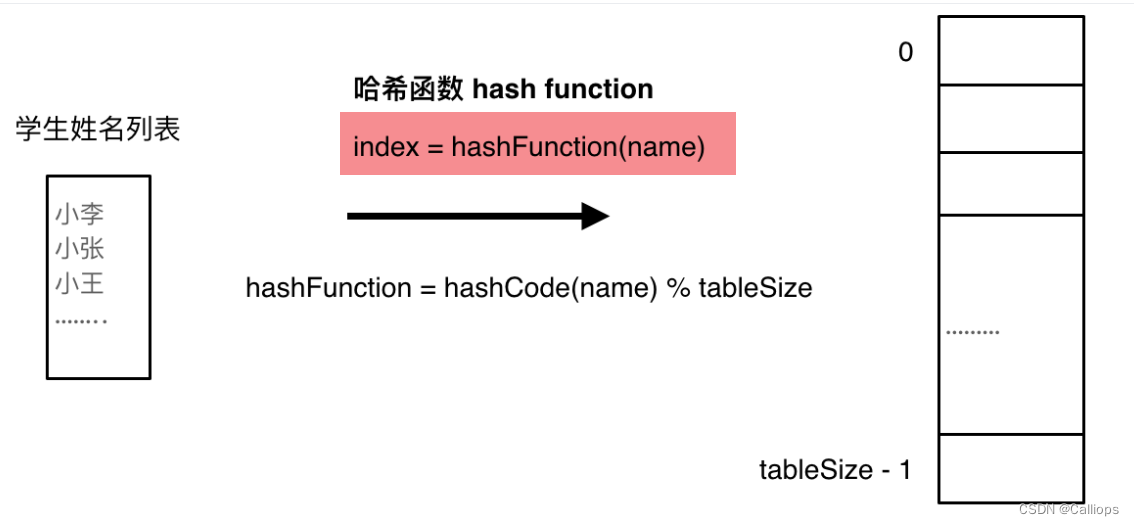
hash表编码方法
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
hash函数的方法是使用**s[i]-‘a’**的方法,因为编译器是自动将底层的ASCII码相减;如果是’a’,索引到的下标就是0,‘b’-‘a’肯定就是index为1;
- 时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
我对于hash表的加深理解
hash表进行编码的时候是将需要的内容编码到哈希表的index中,找index所对应的元素内容。也就是强调一下,编码的时候,是hash表容器的下标和目标内容进行相互转换编码
hash表来快速求解
自己写的注意点
- 代码优化:在python中for i in range(len(s)):改成for i in s就可以了
- python和c++不大一样,ASCII不能直接减,要加一个转换的ord在前面。。。。
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
record = [0] * 26
for i in s:
#并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[ord(i) - ord("a")] += 1
for i in t:
record[ord(i) - ord("a")] -= 1
for i in range(26):
if record[i] != 0:
#record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return False
return True
方法二 python特有的两种方法,没有使用数组
#use counter
class Solution(object):
def isAnagram(self, s: str, t: str) -> bool:
from collections import Counter
a_count = Counter(s)
b_count = Counter(t)
return a_count == b_count
#use defaultdict
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
from collections import defaultdict
s_dict = defaultdict(int)
t_dict = defaultdict(int)
for x in s:
s_dict[x] += 1
for x in t:
t_dict[x] += 1
return s_dict == t_dict
349. 两个数组的交集
题目链接
讲解链接

建议:本题就开始考虑 什么时候用set 什么时候用数组,本题其实是使用set的好题,但是后来力扣改了题目描述和 测试用例,添加了 0 <= nums1[i], nums2[i] <= 1000 条件,所以使用数组【使用数组更加合适其实】也可以了,不过建议大家忽略这个条件。 尝试去使用set。
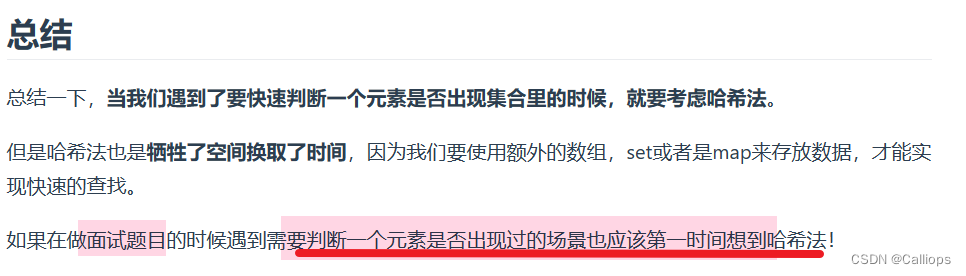
🎈再写一遍:哈希表最适合于解决给你一个元素,判断这个元素是否出现过
**此外,**如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费;
**问:为什么不全部使用set?**答:直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
注意:本题还要注意不要重复
思路
老师讲解的时候用的c++。建议使用unordered-set,效率高,并且会自动去重复;c++代码自己看吧
方法一 还是使用数组
因为改过了,所以可以使用数组来做;思路和上面一题差不多:
因为范围在0-1000之内,定义一个hash表(用数组定义,例如数组的size为1005),遍历nums1,index对应的元素就+1;遍历nums2,如果index对应的元素为1,说明1中出现过。
🧨注意:这里还是使用了set,因为set里面不重复;如果换成列表,用append,那么运行不通过,因为会返回重复的值啦
自己写的错误点:
- 记得最后set要转为list
- python的集合初始化格式为set()
#我自己写的
class Solution(object):
def intersection(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: List[int]
"""
result = set()
hash_ = [0]*1001
for i in nums1:
hash_[i] += 1
for j in nums2:
if hash_[j] >0:
result.add(j)
return list(result)
记录一下carl给的python的解法,寻找两个数组都不是零的方法是将他们相乘呀~,这个可以记一下
这个方法不用set也可以避免重复
class Solution(object):
def intersection(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: List[int]
"""
count1 = [0]*1001
count2 = [0]*1001
result = []
for i in nums1:
count1[i]+=1
for j in nums2:
count2[j]+=1
for k in range(1001):
if count1[k]*count2[k]>0:
result.append(k)
return result
方法二 使用set
python使用set就很简单。。。
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
return list(set(nums1) & set(nums2))
202. 快乐数

思路
总体思路:这道题目我想复杂了。。。。题目里面提到如果不是快乐数会循环:这里的循环的意思是sum会重复出现;如果sum重复出现了,那就是false,否则就求到1为止
还有一个问题是:如何求sum;求各个位数的平方和:先求各个位数:从个位数往前推,先对10取余,得到个位数的值,再除以10缩小10倍,重复操作。
时间复杂度: O(logn)
空间复杂度: O(logn)
方法一 正常求和sum
额外写一个get-sum函数来正常求数字位数的平方和。下面的get-sum可以背住,虽然简单但是重要
class Solution(object):
def get_sum(self,n):
sum_ = 0
while n:
sum_ += (n%10)*(n%10) #求个位数的平方
n = n//10#将n往后移一位
return sum_
def isHappy(self, n):
"""
:type n: int
:rtype: bool
"""
set_sum = set()
sum_ =0
n_new = n
while sum_ != 1:
sum_ = self.get_sum(n_new)
if sum_ in set_sum:
return False
else:
set_sum.add(sum_)
n_new = sum_
return True
方法二 python可以利用str来求和的
思路:将n换成str之后每一个字符串对应的值求平方和,很取巧;
此外,下面的代码中set换成列表也是一样的。
class Solution(object):
def isHappy(self, n):
"""
:type n: int
:rtype: bool
"""
record = set()
# new_sum = 0
while n != 1:
new_sum = 0
for i in str(n):
new_sum += int(i)**2
if new_sum in record:
return False
record.add(new_sum)
n = new_sum
return True
精简的代码写法:同理,上面拿set写,这我就用list写,都是一样的
class Solution:
def isHappy(self, n: int) -> bool:
seen = []
while n != 1:
n = sum(int(i) ** 2 for i in str(n))
if n in seen:
return False
seen.append(n)
return True
1. 两数之和
题目链接
讲解链接

多对的话只需要返回一个满足情况的答案就可以了。
- 再写一遍:每当需要查看一个元素是否出现过的时候,使用hash表。
思路
这道题目使用map解决,是哈希表里面非常经典的题目。
总体思路:判断这个元素是否之前遍历过;例如target为9,遍历到3的时候,就想知道6之前是否出现过;所以遍历过的数要存起来;
需要判断两个元素:这个数是否出现过+这个数对应的是什么index,需要存放两个元素;–使用map
- 元素数值为key,知道key之后找对应的value
四个重点
- 为什么会想到用哈希表:当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
- 为什么使用map结构:因为本题,我们不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
- map作用是什么:map目的用来存放我们访问过的元素,因为遍历数组的时候,需要记录我们之前遍历过哪些元素和对应的下标,这样才能找到与当前元素相匹配的(也就是相加等于target)
- map的value和key是什么:判断一个元素是否出现过,所以哈希表的key就是元素的值,此外还要知道index,所以value存放的是index
map中的存储结构为 {key:数据元素,value:数组元素对应的下标}。
补充:c++里面map有三种;使用unordered-map;因为效率高‘
时间复杂度: O(n)
空间复杂度: O(n)
方法一
我写的代码
犯错:一开始返回的写 的是[i,j],肯定报错==
class Solution(object):
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
map_ = {}
#首先遍历
for i in range(len(nums)):
j = target - nums[i] #找到对应的值
if j in map_:
return [i,map_[j]] #写代码的时候,这里的map_忘了写
map_[nums[i]] = i
return None
使用set集合也行;这里使用了python的列表index属性
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
#创建一个集合来存储我们目前看到的数字
seen = set()
for i, num in enumerate(nums):
complement = target - num
if complement in seen:
return [nums.index(complement), i]
seen.add(num)
总结
第二遍的时候我一定用c++来写,感觉python还有点不方便。。。。
今天晚上心情很平静,不焦虑,可能是因为今天没有做实验哈哈哈哈,果然不科研人就会幸福很多。















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









