







python实现递归算法
一、开发环境
开发工具:jupyter notebook 并使用vscode,cmd命令行工具协助编程测试算法
编程语言:python3.6
二、实验内容
问题1,实现 fibonacci 的递归和非递归。要求计算F(100)的值,比较两种方法的性能要求1)有合适的提示从键盘输入数据;例如“Please input the number to calculate:”2)有输出结果(下同)
Fibonacci非常有名,这里就不多介绍了,直接实现代码。
非递归版本实现的fibonacci数列代码:
# 实现fibonacci的递归算法以及非递归算法
# fibonacco数列前几项 为了检验结果是否正确 1 1 2 3 5 8 13 21 34
# 使用非递归建立fibonacci数列
def fibonacci(n):
a = 1
b = 1
if n==1 or n==2:p
return 1
else:
for i in range(n-2):
a, b = b, a+b
return b
if __name__ == '__main__':
import time
n = int(input("Please input the number to calculate:"))
start = time.time()
print(fibonacci(n))
end = time.time()
print("非递归版本的运行时间为", end-start)
利用jupyter notebook的运行工具进行运行,运行的出的结果为:

递归版本实现的fibonacci数列代码(效率低下版本)
# 低效的做法
def fibonacci_recursion(n):
if n<=2:
return 1
else:
return fibonacci_recursion(n-1)+fibonacci_recursion(n-2)
这个版本的代码实现起来非常容易,并且十分易懂,不过缺点就是效率实在是太低了,当输入100的时候,计算了相当长的时间,所以考虑换一种思路,按照非递归版本的方法,从前依推导出后面的数据。
递归版本实现的fibonacci数列代码(换思路的版本)
# 使用递归建立fibonacci数列
def fibonacci_recursion(n, a=1, b=1, c=3):
if n < 3:
return 1
else:
if n==c:
return a+b
else:
return fibonacci_recursion(n, a=b, b=a+b, c=c+1)
if __name__ == '__main__':
import time
n = int(input("Please input the number to calculate:"))
start = time.time()
print(fibonacci_recursion(n))
end = time.time()
print("递归版本的运行时间为", end-start)
这一版本的代码虽然比起上面的复杂了点,但是效率还是非常快的。

EXTRA
上面的版本可以说是挺好的了,然而当我输入2000的时候,还是报错了

好像说是超过了最大递归的深度,爆栈了。
依稀地记得,以前写代码的时候有过这种问题的解决方案,于是开始百度。
然而尴尬的是找了半天,并没有找到我上次的那份代码,上次的好像是用上了装饰器解决问的,不过查到了另外的解决方案,使用尾递归优化,并使用了python的生成器机制。代码如下:
# python 使用尾递归优化
import types # 导入types模块
# 如果函数中出现了yield解释器会自动将函数当成生成器,此时是不会直接生成数的
# tramp的作用为:使生成器不断产生下一个数据
def tramp(gen, *args, **kwargs):
g = gen(*args, **kwargs)
while isinstance(g, types.GeneratorType): # 如果g为生成器的实例
g=g.__next__() #
return g
def fibonacci_recursion(n, a=1, b=1, c=3):
if n < 3:
yield 1
else:
if n==c:
yield a+b
else:
yield fibonacci_recursion(n, a=b, b=a+b, c=c+1)
if __name__ == '__main__':
import time
n = int(input("Please input the number to calculate:"))
start = time.time()
print(fibonacci_recursion(n))
end = time.time()
print("递归版本的运行时间为", end-start)
网上找到的代码是py2的版本的,最近都是用的py3,版本问题还真是头疼呀,花了点时间改了一下。
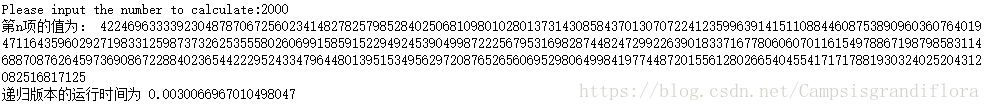 经过优化的递归函数效果惊人,2000以内的都不在是问题啦。
经过优化的递归函数效果惊人,2000以内的都不在是问题啦。
问题2,实现全排列算法
- 实现前20个奇数的全排列。
- 实现数字1,3,5,7,9五个数字的全排列
实现对数字1,3,5,7,9五个数字的全排列
# 实现全排列的算法。
# a) 实现数字1,3,5,7,9五个数字的全排列。
# b) 实现前20个奇数的全排列。
# 全排列函数
def full_arrangement(lis):
length = len(lis)
if length < 2: # 边界条件
return lis
else:
result = []
for i in range(length):
ch = lis[i] # 取出str中每一个字符
rest = lis[0: i] + lis[i+1: length]
for s in full_arrangement(rest): # 递归
result.append(ch+s) # 将ch与子问题的解依次组合
return result
if __name__ == '__main__':
lis = [1, 3, 5, 7, 9]
lis1 = list(map(str, lis))
import time
start = time.time()
print(full_arrangement(lis1))
end = time.time()
print("全排列运行时间:", end-start)
对五个数进行全排列的运行时间:

下一个问题:实现前20个奇数的全排列。
测试代码已经写好了,是这个样子的
lis2 = list(map(str, [x for x in range(40) if x%2!=0]))
print(lis2)
start = time.time()
print(full_arrangement(lis2))
end = time.time()
print("全排列运行时间:", end-start)
然而,emmm……,好像运行时间太长了点。
当对前10个奇数进行全排列的时候,运行结果如下图所示:
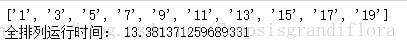
10个数花了13秒的时间,可见前20个奇数所用时间非常的长,然而现在并没有找到更好地优化解决方案,只能实现到这个地步,感到非常抱歉。
问题3,实现二分查找。
- 在 1 3 3 4 5 5 7 8 8 9 10 中查找得到7,返回其所在的位置。
- 随机生成10000个整数,查找数字 2025,返回其所在的位置。
原理:
折半查找法也称为二分查找法,它充分利用了元素间的次序关系,采用分治策略,可在最坏的情况下用O(log n)完成搜索任务。它的基本思想是,将n个元素分成个数大致相同的两半,取a[n/2]与欲查找的x作比较,如果x=a[n/2]则找到x,算法终止。如 果x<a[n/2],则我们只要在数组a的左半部继续搜索x(这里假设数组元素呈升序排列)。如果x>a[n/2],则我们只要在数组a的右半部继续搜索x。
要求:
1.必须采用顺序存储结构。
2.必须按关键字大小有序排列。
代码实现:
# 实现二分查找。
# a) 在 1 3 3 4 5 5 7 8 8 9 10 中查找得到7,返回其所在的位置。
# b) 随机生成10000个整数,查找数字 2025,返回其所在的位置。
import random
# 二分查找,如果在lis中找到n,则返回n的下标,如果找不到,则返回-1
def binary_search(lis, n):
length = len(lis)
left = 0
right = length-1
while left <= right:
mid = (left+right)//2
# 注意,注意,注意
# 这里要注意,py3使用//作为整除,好像程老师的书《算法分析与设计》P69页存在这个错误
if lis[mid] == n:
return mid
elif lis[mid] > n:
right = mid-1
elif lis[mid] < n:
left = mid+1
return -1
if __name__ == '__main__':
lis = [1, 3, 3, 4, 5, 5, 7, 8, 8, 9, 10]
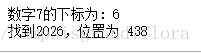
print('数字7的下标为:',binary_search(lis, 7))
# 随机生成10000个成递增的数据
x = 0
lis2 = []
for i in range(10000):
lis2.append(x)
x += int(random.random()*10)
find = binary_search(lis2, 2026)
if find == -1:
print('没有找到2026!')
else:
print('找到2026,位置为', find)
多次运行情况:
运行one

运行two
问题4,实现合并排序和快速排序,比较算法的性能。
输入数据为:3 2 5 7 8 9 5 0 1
- 随机生成10000个整数。
实现归并排序还有快速排序
归并排序的实现方式还是记得的,写起来也毫无压力,关于快速排序这个,以前用python写过两遍,可惜的是……全部在边界数据上失败了……快速排序果然还是有点难度的,就记得个大概的方法,所以这次的快速排序是照着我一起用C++写的版本写出来的,重新用python实现了一遍。
# 实现合并排序和快速排序,比较算法的性能。
# a) 输入数据为:3 2 5 7 8 9 5 0 1
# b) 随机生成10000个整数。
import numpy as np
import random
import time
# 将两个有序列表合并,归并排序的辅助函数
def merge(lis1, lis2):
i = 0
j = 0
lis3 = [] # 合并之后的列表
while i < len(lis1) and j < len(lis2):
if lis1[i] < lis2[j]:
lis3.append(lis1[i])
i += 1
else:
lis3.append(lis2[j])
j += 1
# 处理剩下的数据
while i < len(lis1):
lis3.append(lis1[i])
i += 1
while j < len(lis2):
lis3.append(lis2[j])
j += 1
return lis3
# 归并排序 分解列表操作
def merge_sort(lis):
if len(lis) <= 1:
return lis
middle = len(lis)//2
leftlis = lis[:middle]
rightlis = lis[middle: ]
left_sorted = merge_sort(leftlis)
right_sorted = merge_sort(rightlis)
return merge(left_sorted, right_sorted)
# 快速排序,划分操作, 快速排序的辅助函数
def split(lis, first, last):
pivot = lis[first]
left = first
right = last
while left<right:
while pivot < lis[right]:
right=right-1
while left < right and (lis[left] < pivot or lis[left] == pivot):
left=left+1
if left < right:
lis[left], lis[right] = lis[right], lis[left]
# 确定好基准位置
pos = right
lis[first] = lis[pos]
lis[pos] = pivot
return pos
# 快速排序实现
def quicksort(lis, first, last):
if first < last:
pos = split(lis, first, last)
quicksort(lis, first, pos-1)
quicksort(lis, pos+1, last)
return lis
if __name__ == '__main__':
lis1 = [3, 2, 5, 7, 8, 9, 5, 0, 1]
lis2 = [3, 2, 5, 7, 8, 9, 5, 0, 1]
print('使用归并排序:',merge_sort(lis))
print('使用快速排序:',quicksort(lis, 0, len(lis)-1))
# 生成两个一样的10000个随机数的列表, 使用deepcopy函数
lis1 = [ int(random.random()*10000) for i in range(10000)]
import copy
lis2 = copy.deepcopy(lis1) # 深度拷贝
# 测试运行时间
start = time.time()
# print(merge_sort(lis1)) # 打印排序的数据
merge_sort(lis1)
end = time.time()
print('使用快速排序,排10000个随机数的时间:', end-start)
start = time.time()
# print(quicksort(lis2, 0, len(lis2)-1)) # 打印排序的数据
quicksort(lis2, 0, len(lis2)-1)
end = time.time()
print('使用快速排序,排10000个随机数的时间:', end-start)
运行的结果:

这样看来,果然还是快速排序排的比较快呀~~~
三、实验总结
这次的实验内容以前全部用C++写过,现在代码还留着,所以这次使用了python语言全部重写一遍,感觉收获还是很多的,不仅使我重新巩固了有关算法方面的知识,还学会了很多新的知识和python技巧,比如优化递归的尾递归优化,py的cProfile性能分析还有itertools迭代工具模块等等,我再次深刻体会到学习算法是一件事情,把算法实现写出又是另外一件事情,也许某个算法的道理很简单,但是实现和编程过程还是需要很多的技巧的,看着写实验报告这么辛苦,于是决定把它放在博客上,就是这样。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









