







1.环境准备,python环境,安装python-docx依赖包
命令:pip install python-docx
其他镜像地址:https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/python-docx/
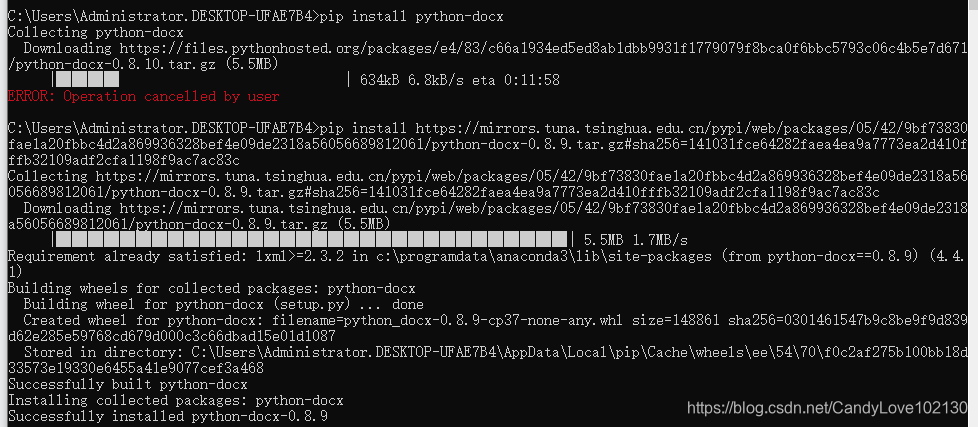
2.测试文档如下:

3.提取文字
import docx
if __name__ == '__main__':
# 获取文档对象
doc_path = 'E:/resource/video/test.docx'
doc = docx.Document(doc_path)
print("段落数:" + str(len(doc.paragraphs))) # 段落数
# 输出每一段的内容
for para in doc.paragraphs:
print(para.text)
tab = doc.tables
print("表格数:" + str(len(tab))) # 段落数
# 读取第1个表格
tb1 = doc.tables[0]
# 读取第一行所有单元格的内容
for row in tb1.rows:
for cell in row.cells:
print(cell.text)测试结果:
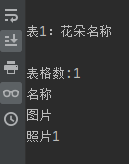
4.提取图片
import os
import zipfile
import shutil
def word2pic(path, zip_path, tmp_path, store_path):
# 将docx文件重命名为zip文件
os.rename(path, zip_path)
# 进行解压
f = zipfile.ZipFile(zip_path, 'r')
# 将图片提取并保存
for file in f.namelist():
f.extract(file, tmp_path)
# 释放该zip文件
f.close()
# 将docx文件从zip还原为docx
os.rename(zip_path, path)
# 得到缓存文件夹中图片列表
pic = os.listdir(os.path.join(tmp_path, 'word/media'))
# 将图片复制到最终的文件夹中
for i in pic:
# 根据word的路径生成图片的名称
new_name = path.replace('\\', '_')
new_name = new_name.replace(':', '') + '_' + i
shutil.copy(os.path.join(tmp_path + '/word/media', i), os.path.join(store_path, new_name))
# 删除缓冲文件夹中的文件,用以存储下一次的文件
for i in os.listdir(tmp_path):
# 如果是文件夹则删除
if os.path.isdir(os.path.join(tmp_path, i)):
shutil.rmtree(os.path.join(tmp_path, i))
if __name__ == '__main__':
# 源文件
path = r'E:\resource\video\test\test.docx'
# docx重命名为zip
zip_path = r'E:\resource\video\test\test.zip'
# 中转图片文件夹
tmp_path = r'E:\resource\video\test\tmp'
# 最后保存结果的文件夹
store_path = r'E:\resource\video\test\pic'
m = word2pic(path, zip_path, tmp_path, store_path)
运行结果:
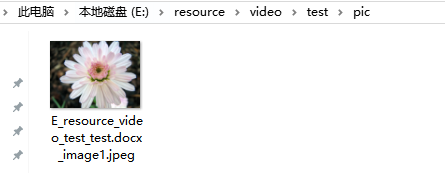
5,提取文字和图片,放入不同文件夹

代码:
# encoding=utf-8
import os
import zipfile
import shutil # 引入os(文件及目录操作)、zipfile(zip文件操作)、shutil(拷贝文件)库
import docx
from win32com import client
count = 1000
def get_text(file):
labels = []
# 获取文档对象
doc = docx.Document(file)
tab = doc.tables
tab_num = len(tab)
print("表格数:", str(tab_num))
for i in range(0, tab_num):
for j in range(1, len(tab[i].rows)):
labels.append(tab[i].rows[j].cells[0].text)
print(labels)
return labels
def pic2dir(doc_dir, file, labels):
file_zip = file[:-5] + '.ZIP'
os.rename(file, file_zip) # 重命名为zip文件
tmp_path = doc_dir + 'tmp'
f = zipfile.ZipFile(file_zip, 'r')
for img_file in f.namelist():
if "word" in img_file:
# 将压缩包里的word文件夹解压出来
f.extract(img_file, tmp_path)
f.close()
os.rename(file_zip, file)
pic = os.listdir(os.path.join(tmp_path, 'word/media'))
print(len(pic))
global count
nn = 0
pic.sort(key=lambda x: int(x[5:-5])) #image1.jpeg
for i in pic:
if i.endswith('.jpeg'):
pic_path = doc_dir + labels[nn]
if not os.path.exists(pic_path):
os.mkdir(pic_path)
shutil.copy(os.path.join(tmp_path + '/word/media', i), os.path.join(pic_path, str(count)+'.png'))
count += 1
nn += 1
# 删除缓冲文件夹中的文件,用以存储下一次的文件
for i in os.listdir(tmp_path):
# 如果是文件夹则删除
if os.path.isdir(os.path.join(tmp_path, i)):
shutil.rmtree(os.path.join(tmp_path, i))
return count
def doc2docx(doc_name):
try:
# 首先将doc转换成docx
word = client.Dispatch("Word.Application")
doc = word.Documents.Open(doc_name)
docx_name = doc_name[:-4] + '.docx'
# 使用参数16表示将doc转换成docx
doc.SaveAs(docx_name, 16)
doc.Close()
word.Quit()
except:
pass
return docx_name
if __name__ == '__main__':
doc_dir = 'E:/resource/video/test/11/'
os.chdir(doc_dir)
for file_name in os.listdir(doc_dir):
print(file_name)
if 'doc' in file_name:
file = doc_dir + file_name
if file_name.endswith('.docx'):
pass
else:
file = doc2docx(file)
labels = get_text(file)
if len(labels) > 0:
count = pic2dir(doc_dir, file, labels)
print(count)运行结果:

分类效果如下:
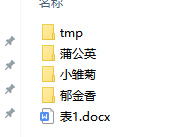
此类处理主要是机器学习收集训练数据时可以批量提取文字或图片。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









