









数据的选择
- 列选择
- 行选择
- 行列同时选择
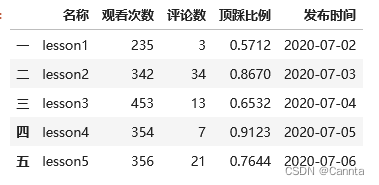
# 读入文件并重置索引
import pandas as pd
df = pd.read_excel('../test1/lesson4.xlsx')
df.index = ['一', '二', '三', '四', '五']
df
输出结果:
Section 1 列选择
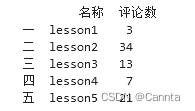
# (通过列名)只选择‘名称’列
print(df[ ["名称"] ])

# (通过列名)选择多个列
print(df[ ["名称", "评论数"] ])
# (通过列号)选择
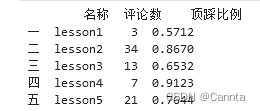
# df.iloc[ , ]中间两部分用逗号分隔,前面表示第几行(:表示所有行),后边表示第几列([0,2,3]表示第0\2\3列)
# 想要哪几行哪几列可以按需调整,只要放在列表里即可
print(df.iloc[ : , [0,2,3] ] )
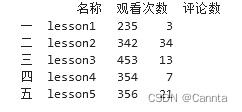
# 如果选择的列数比较多,不适合全部列出来,那么可以使用切片索引
print(df.iloc[ : , 0:3]) # 所有行,第0列到第2列
Section 2 行选择
# (通过行索引)只选择‘二’行
print(df.loc[ ["二"] ])

# (通过行索引)选择多个行
print(df.loc[ ["一", "三"] ])

# 通过iloc()
print(df.iloc[ [0,1,2] , [0,2,3] ] )
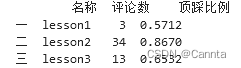
# 筛选满足条件的数据
print(df[ (df['观看次数']>350) & (df['评论数']>10) ])

Section 3 行列同时选择
# 索引数字
print(df.iloc[ [0,1,2] , [0,2,3] ] )
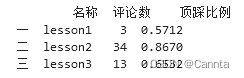
# 切片索引
print(df.iloc[ 0:3 , [0,2,3] ] )
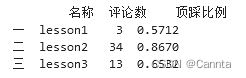
# 筛选条件
# 切片索引
print(df[df["观看次数"]>300 ][["名称","评论数"]] )
# 先选择观看次数大于300的所有列数
# 再选出 名称、评论数 的行
















 3413
3413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









