







自学爬虫 1 - What is 爬虫?
前言
记得17年实习,刚听到爬虫这个词的时候,感觉特别遥远。那时还特地从网上下载了一本<jsoup教程>,在公司看了三天左右,用Java写下了人生的第一个爬虫PoiCrawler,记忆尤为深刻。后来又为了Scrapy转战Python爬虫,在18年完成了从入门到实践的过程。
对于爬虫,我的定义就是:在Java中爬虫是Jsoup,在python中就是requests(urlib)库(Scrapy先不提)。它们将html内容下载下来,我们解析html、存储解析后的数据,就构建了整个爬虫的数据流程。
所以,在这里给爬虫粗略定义:爬虫 = 爬取网页 + 解析目标数据 + 数据存储
爬取网页
所谓的爬取网页,就是通过请求,将展示在浏览器的网页获取到。这是爬虫的第一步,也是比较重要的一步,通常我们听到的代理ip、代理服务器、UA伪装等就是在这一步实现的。
python中安装requests即可发起请求获取网页数据,代码如下:
import requests
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'}
response = requests.get('https://www.baidu.com', headers=header)
print(response.text)
java中导入jsoup.jar,使用jsoup发起请求,代码如下:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test{
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("https://www.baidu.com").get();
System.out.println(doc.body());
}
}
上述两种方法打印的数据,和你在浏览器访问 https://www.baidu.com数据时一样的。这就是爬虫的第一步,代码就像一个浏览器,根据输入的url对服务器发起请求,只是你的代码不会像浏览器一样,将html里面的标签和js代码解析并页面展现。在响应的数据中找到目标数据存放在哪个标签下,然后解析出来。
解析目标数据
解析目标数据就是把你想从网页上获取的数据想办法获取下来,常见的方法有xpath、css,这些选择标签的方法被称为选择器。
假设下面的html是通过请求获取到的网页数据:
<html>
<head>
<title>为什么Java天下第一</title>
</head>
<body>
<a id="a1" class="a2" href = "https://www.baidu.com">寻她千百度</a>
</body>
</html>
我想获取到<title>的文本和<a>的href属性和文本。
在python中我们可以使用BeautifulSoup来解析:
from bs4 import BeautifulSoup
html = 上面的html代码;
# 将String类型的html使用解析器解析
soup = BeautifulSoup(html, 'html.parser')
# select是将所有选中的属性放到list返回,select_one是只返回list中的第一个元素
# 这里的参数title是标签名选择器,string代表返回这个元素标签内包含的文本
title = soup.select_one('title').string
# 这里的#a1是css选择器,#a1代表id=a1,效果和.a2一样,代表class=a2的元素
tag = soup.select_one('#a1')
# attrs['href']代表选中的a1元素的href属性
href = tag.attrs['href']
content = tag.string
print(title, href, content, sep='\n')
输出结果如果所示:
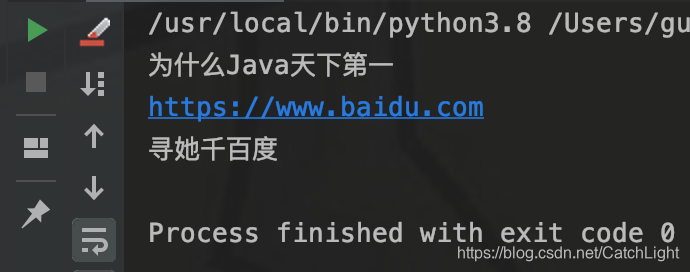
Java中使用Jsoup来解析
String html = 上面的html代码;
// 将字符串格式化成Document格式,connect()请求可以直接返回Document
Document doc = Jsoup.parse(html);
String title = doc.title();
// 通过id来获取a元素
Element a = doc.getElementById("a1");
// 获取a元素的href属性
String href = a.attr("href");
// 获取a元素的文本内容,即元素的><部分
String content = a.text();
System.out.println(title);
System.out.println(href);
System.out.println(content);
输出结果如图所示: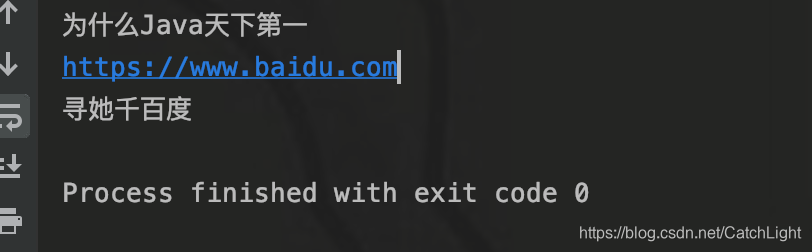
这样就把你想要的数据从网页上爬取下来。
数据存储
数据存储就是将解析下来的数据格式化的存到一个地方,像这种打印在控制台上只是为了方便查看爬取的数据,并不会保存、我们需要通过程序将存放到MySQL的表中或者excel里面,方便数据的使用。通常python通过pymyql来连接mysql,pandas或xwlt来操作excel。
结语
其实常见的爬虫简单的一,没有想象的那么复杂。入门的话用好requests和bs4就足够了。随着接触的爬虫越来越多,知识面越来越广泛,技术能力层面也会随之提升。在以后遇到的反爬虫技术也会让你快速成长,与天斗与地斗与反爬虫斗,其乐无穷。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









