







前言
双十一到了,如何在平台上搜索自己想要商品的价格信息,实现快速的比价,这就利用到我们学到的爬虫知识。本篇文章主要是对JD商品的一个价格获取,文中涉及的代码仅做学习和爬虫工具功能演示。
网页分析
通常我们在JD的首页,输入我们要搜索的商品,点击搜索就会显示搜索商品的列表和价格信息。
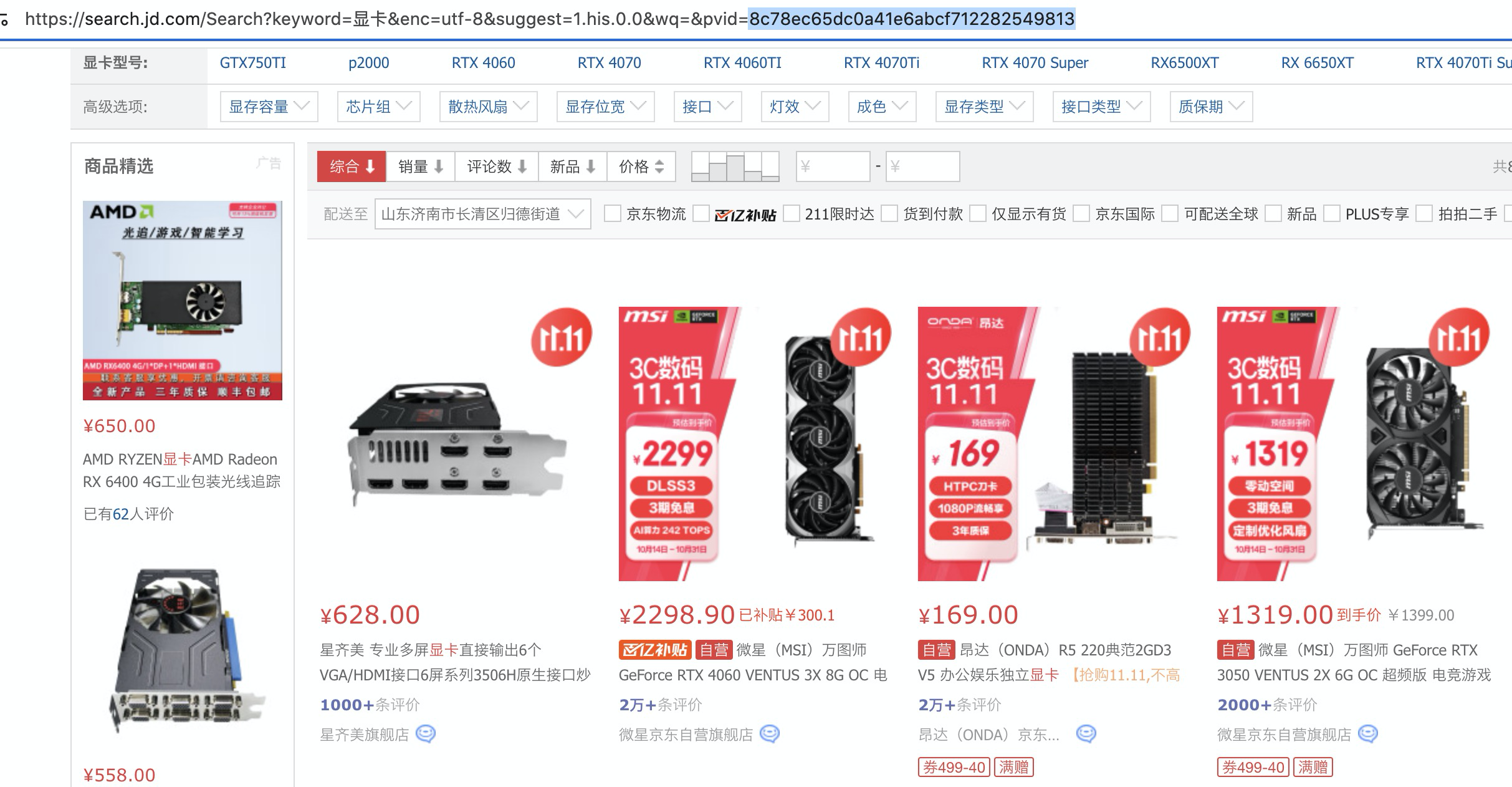
如上图,我们可以看到在url中,会有一个pvid的参数,这个应该是发起搜索请求时,js通过对用户的cookie以及其他一些参数加密生成的。如果我们将这个url粘贴到另一个浏览器,你会发现价格居然加密了。
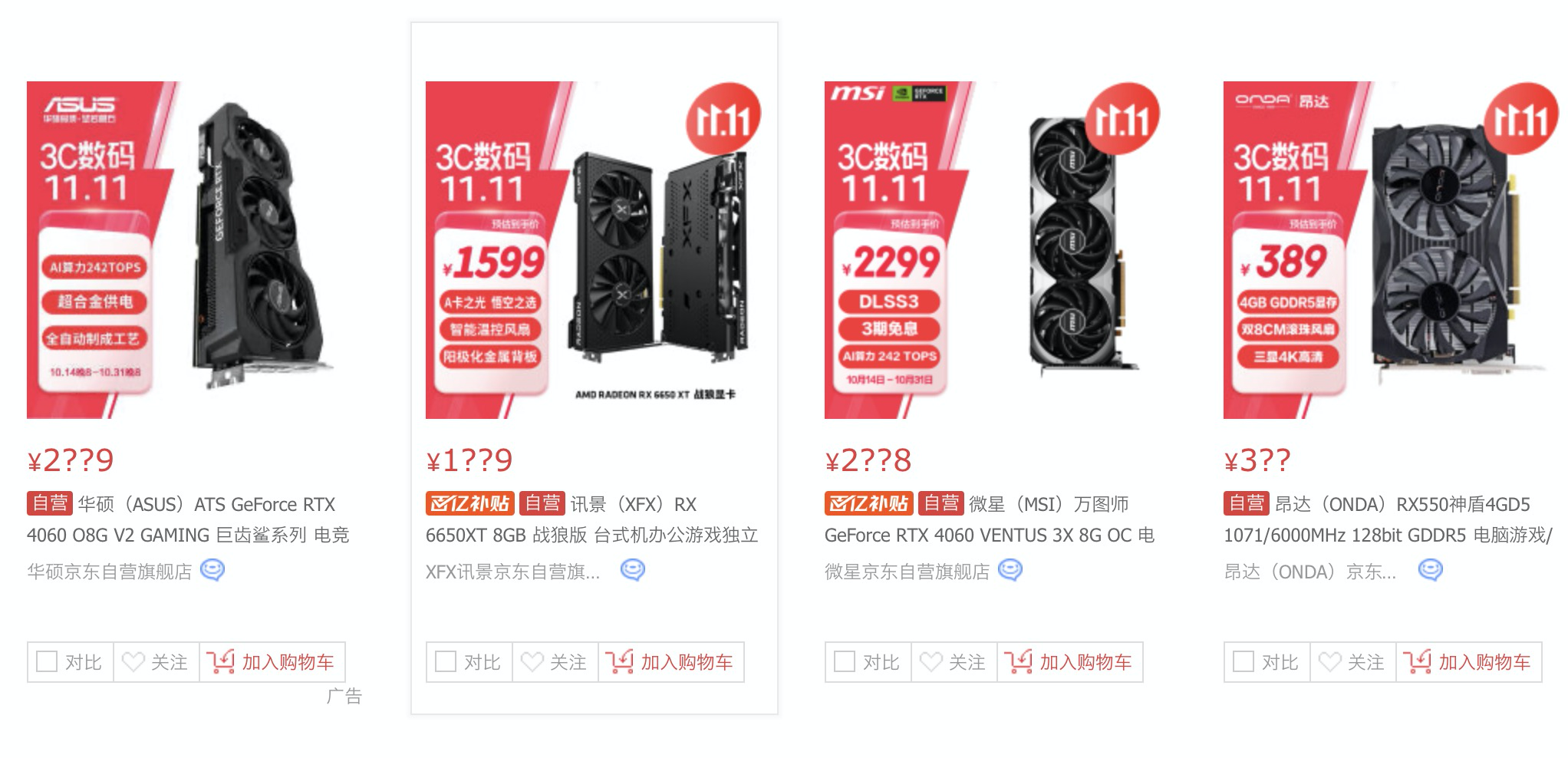
所以,这个pvid还是认浏览器的。为了让爬虫在访问时能够模拟这个js的请求动作,首先就要解决的就是这个pvid的问题,还有就是登录的问题。如果使用代码全部实现的话,会很麻烦,正好上一篇文章写了selenium,这里趁着机会就实操一下。
代码开发
首先是安装selenium,然后在代码中加载chrome驱动,因为我的笔记本上已经安装了chrome,直接使用即可,否则的话就要下载并引入驱动。
代码功能主要分为三个部分:
- 在JD首页输入内容搜索
- 实现登录
- 爬取商品价格信息
接下来就用selenium实现上面的三个功能。
1. 实现搜索
使用webdriver.Chrome加载并启动chrome。
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36',
}
# 设置请求头
chrome_options.add_argument(f"user-agent={headers['User-Agent']}")
# 启动浏览器
driver = webdriver.Chrome(ChromeDriverManager().install(), options=chrome_options)
这里使用Options添加了请求头信息,这里不添加也可以,因为selenium本来就是启动的浏览器,这些UA信息都是有的。接下来就是实现搜索框内容输入。
# 打开京东主页
driver.get("https://www.jd.com/")
time.sleep(2)
# 找到搜索框,并输入关键词
search_box = driver.find_element(By.ID, "key") # 搜索框的 ID 为 'key'
# 清除默认内容
search_box.clear()
search_box.send_keys("笔记本电脑")
# 按下回车键执行搜索
search_box.send_keys(Keys.RETURN)
# 等待搜索结果加载
time.sleep(3)
在selenium,通过find_element找到元素,元素的ID可以通过F12来定位。
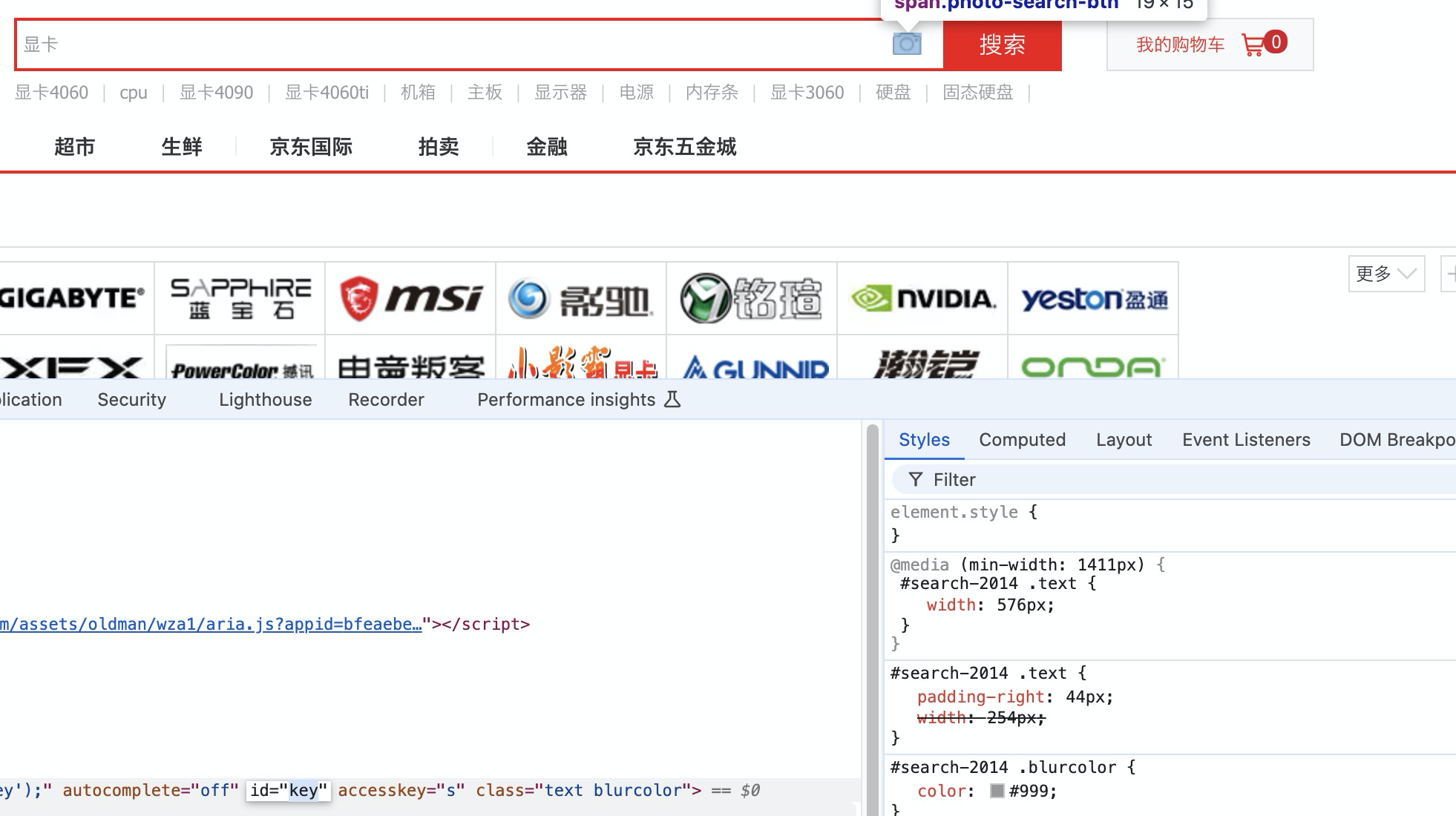
使用send_keys来输入文本和点击回车,启动程序效果如下:

这样就实现了页面的搜索功能。
2. 用户登录
在上面输入内容搜索之后,然后就弹出来了用户登录页面,这里还是还之前一样,通过定位用户名、密码的输入框,然后输入JD账号密码,然后实现点击登录。
sername_box = driver.find_element(By.ID, "loginname")
username_box.clear()
username_box.send_keys("18******")
# 输入密码
password_box = driver.find_element(By.ID, "nloginpwd")
password_box.clear()
password_box.send_keys("1*****")
# 点击登录按钮
login_button = driver.find_element(By.ID, "loginsubmit")
login_button.click()
效果如下,但是在点击登录之后,会弹出一个滑动拼图,这个应该是可以通过一些技术手段实现滑动的,但是这里我就手动实现了。

但是在后面的登录中,有时候不会触发登录,所以价格还是加密,所以可以在最前面直接访问登录页面,登录成功之后再进行搜索。
driver.get("https://passport.jd.com/new/login.aspx")
username_box = driver.find_element(By.ID, "loginname")
username_box.clear()
username_box.send_keys("18354141658")
password_box = driver.find_element(By.ID, "nloginpwd")
password_box.clear()
password_box.send_keys("1qaz@WSX")
login_button = driver.find_element(By.ID, "loginsubmit")
login_button.click()
time.sleep(20)
最后一定要sleep,这里的20s是留给滑动滑块或者输入手机验证码的时间。在登录之后,这就是一个正常的浏览器窗口,在未关闭前你可以在代码中实现重复搜索、查看价格等操作。

3. 商品信息获取
在登录页面之后,就可以对商品价格网页结构进行分析,通过定位元素的来获取价格。
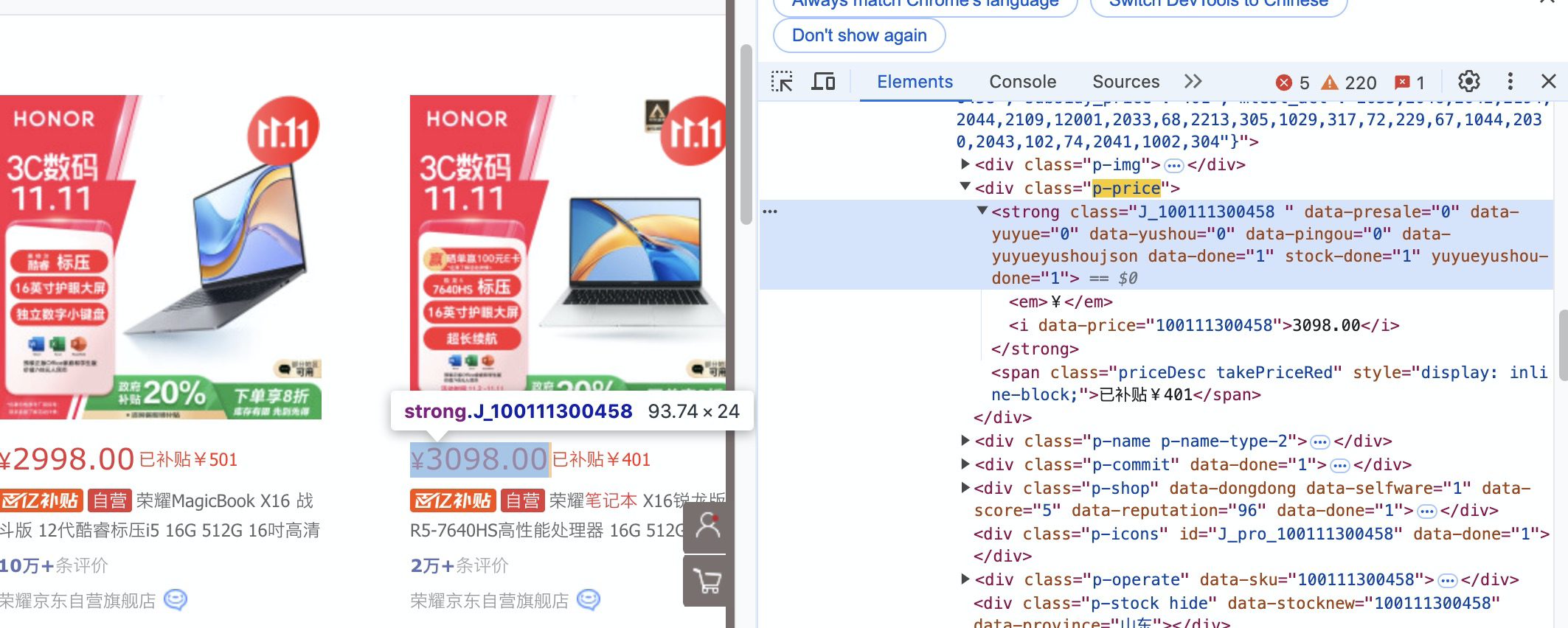
可以使用断点调试来解析网页数据,一个页面一共有30个商品,所以解析出来30个价格数据。
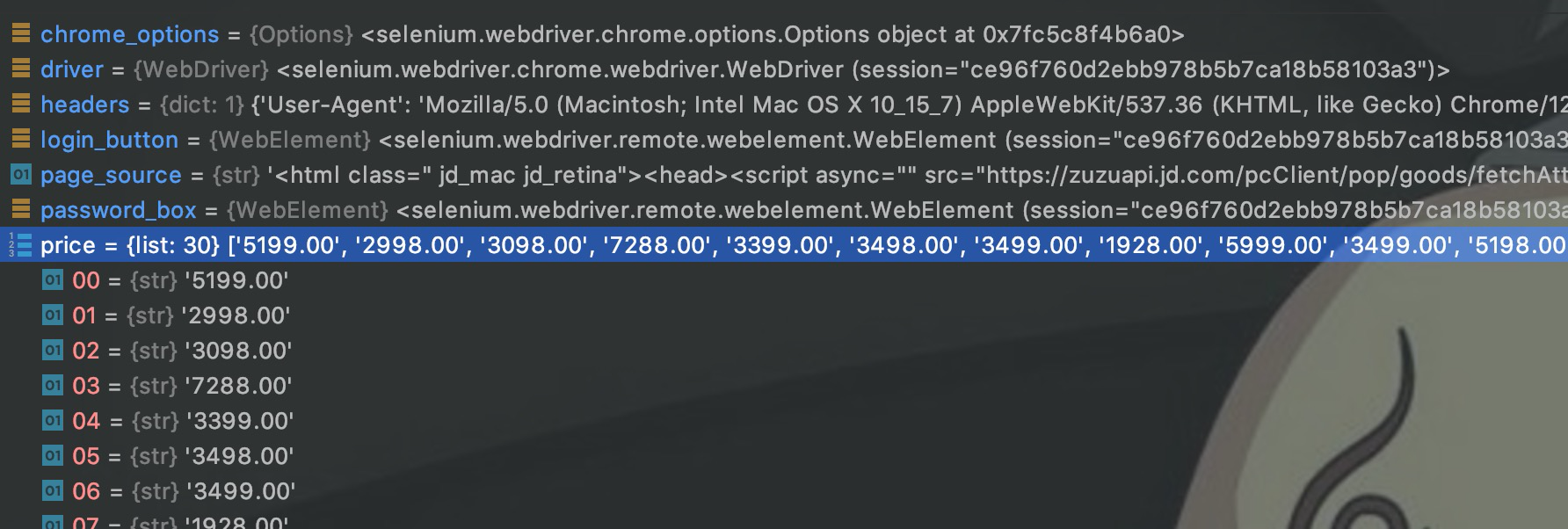
对店铺也可以解析,一个商品对应一个店铺,一共30个店铺信息。
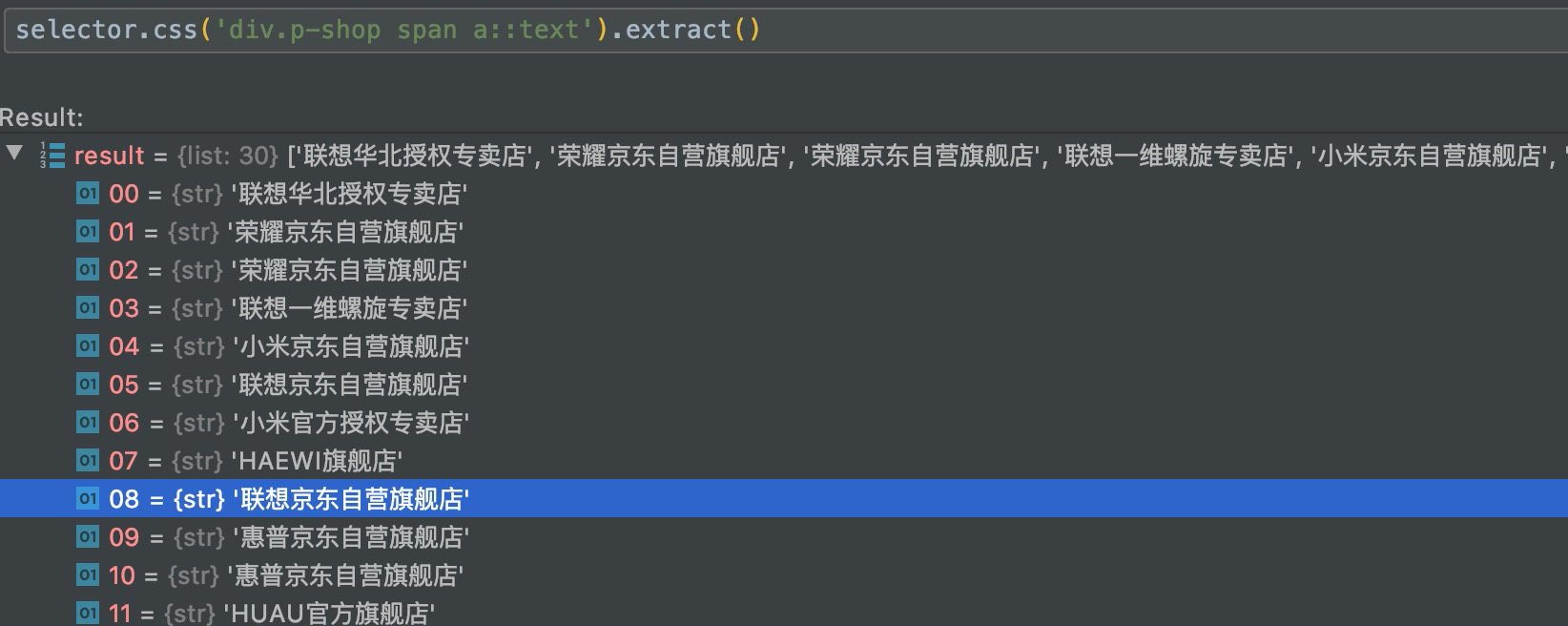
然后解析商品的描述信息,因为其内容一部分在em标签下,一部分在font标签下。
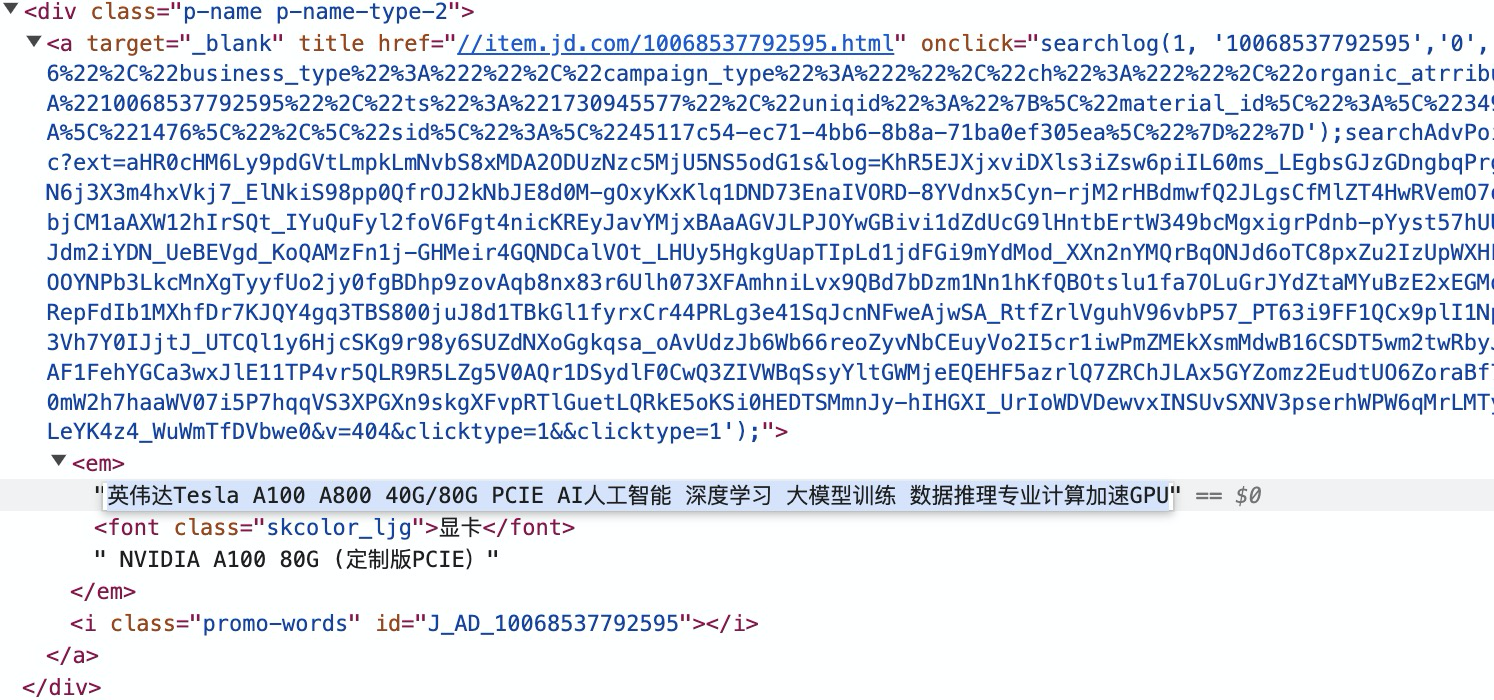
所以如果使用上面的解析方式,就会出现大于30行的数据,很多换行符。
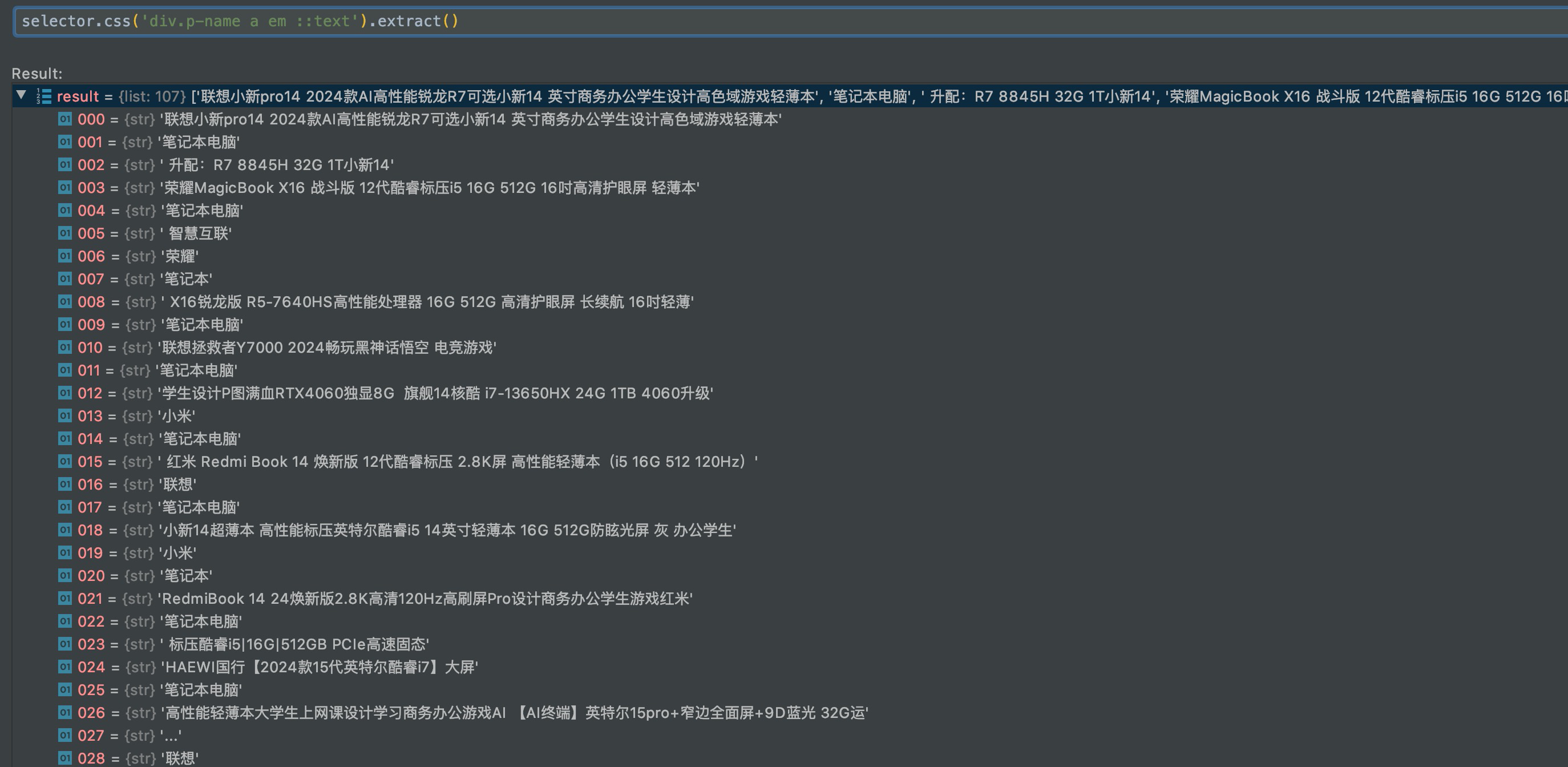
所以这部分的思路是先解析出来a标签,这样就是30个商品信息。
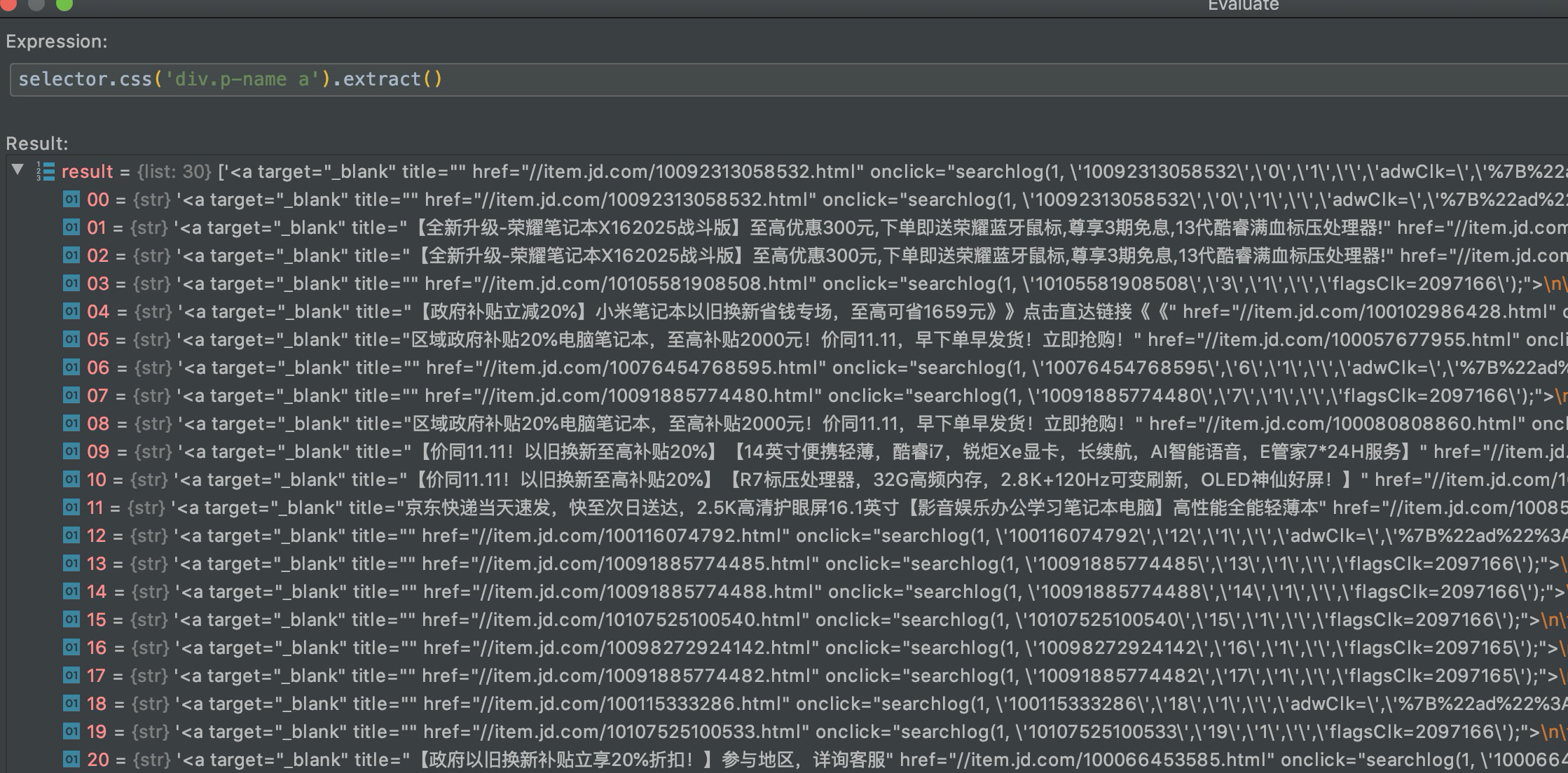
然后遍历a标签,将下面的所有文本拼接起来,并去掉换行符。
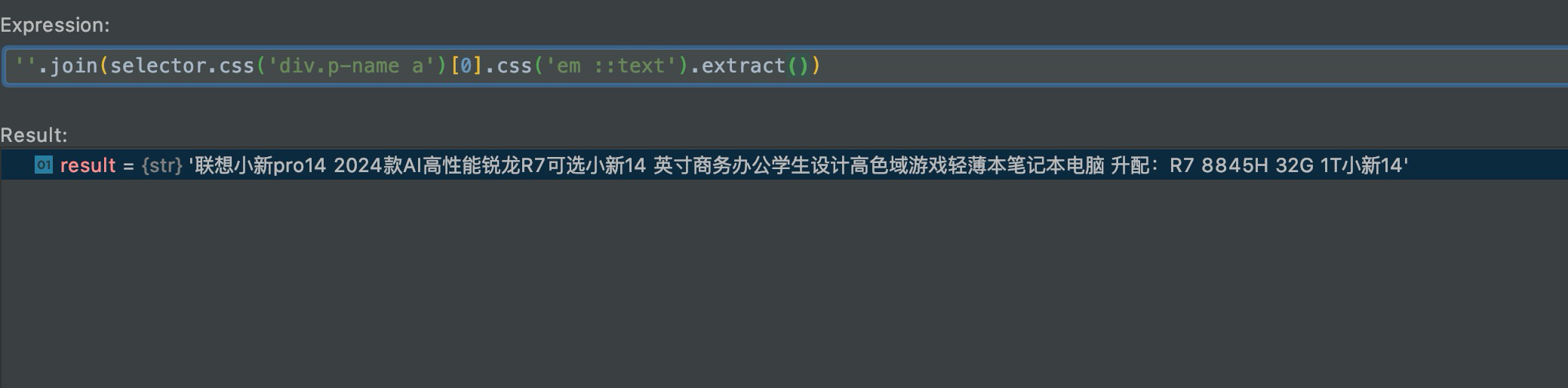
这样就获取到了商品的价格、店铺以及商品描述信息,代码如下:
page_source = driver.page_source
# 使用 Scrapy Selector 提取价格
selector = Selector(text=page_source)
prices = selector.css('div.p-price strong i::text').extract()
shops = selector.css('div.p-shop span a::text').extract()
infos = selector.css('div.p-name a')
infos_ = []
for info in infos:
infos_.append(''.join(info.css('em ::text').extract()))
for price, shop, info in zip(prices, shops, infos_):
print(price, shop, info)
运次代码,输出结果:

结语
这就是使用selenium对JD商品价格的一个获取,也可以看出selenium可以输入文本、模拟用户点击,这对于实现用户登录是非常友好的。手续可以使用selenium实现点击翻页获取更多的商品信息。

















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









