






前言
HAI HAI HAI!腾讯云CPU版1元限时体验活动它来了。AI时代依赖的就是算力资源,当我们还在因为自己电脑配置跟不上而苦恼的时候,不妨试一下HAI。
最近也是在研究构建AI应用的工具:Dify,前两天也在腾讯云服务器上安装了 Dify,具体可参考文章:2C2G的云服务器如何安装dify。之前苦于没有大模型的支持,这次活动就打算基于 HAI 实例上的DeepSeek R1模型,和 Dify 一起构建一个智能导诊助手。
HAI
HAI(高性能应用服务)作为一款面向 AI 的算力应用服务产品。既打破了 GPU 服务器的局限性,同时也为开发者提供了即插即用的强大算力和常见环境,让开发者可以快速部署语言模型(LLM)、AI 绘图、数据科学等高性能应用,提高了产品的易用性,也降低了技术门槛。
我们进入 HAI活动首页,可以看到本次活动一共推出了不同规格的两种产品:HAI-CPU 和 HAI-GPU。
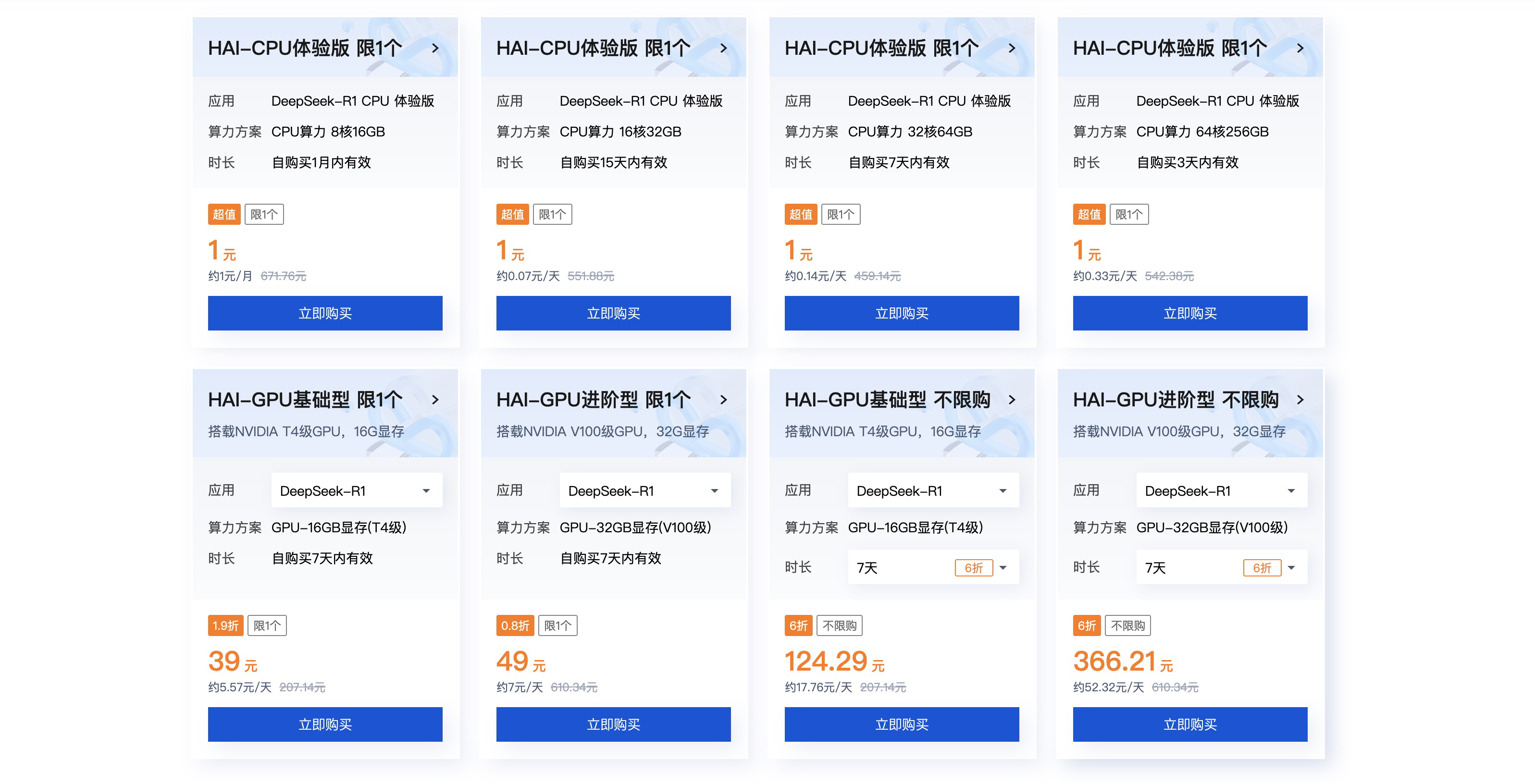
HAI-CPU 从 8C16G 到 64C256G 的实例都给出了一元购的体验活动,所以本次我就使用 HAI-CPU 的实例。
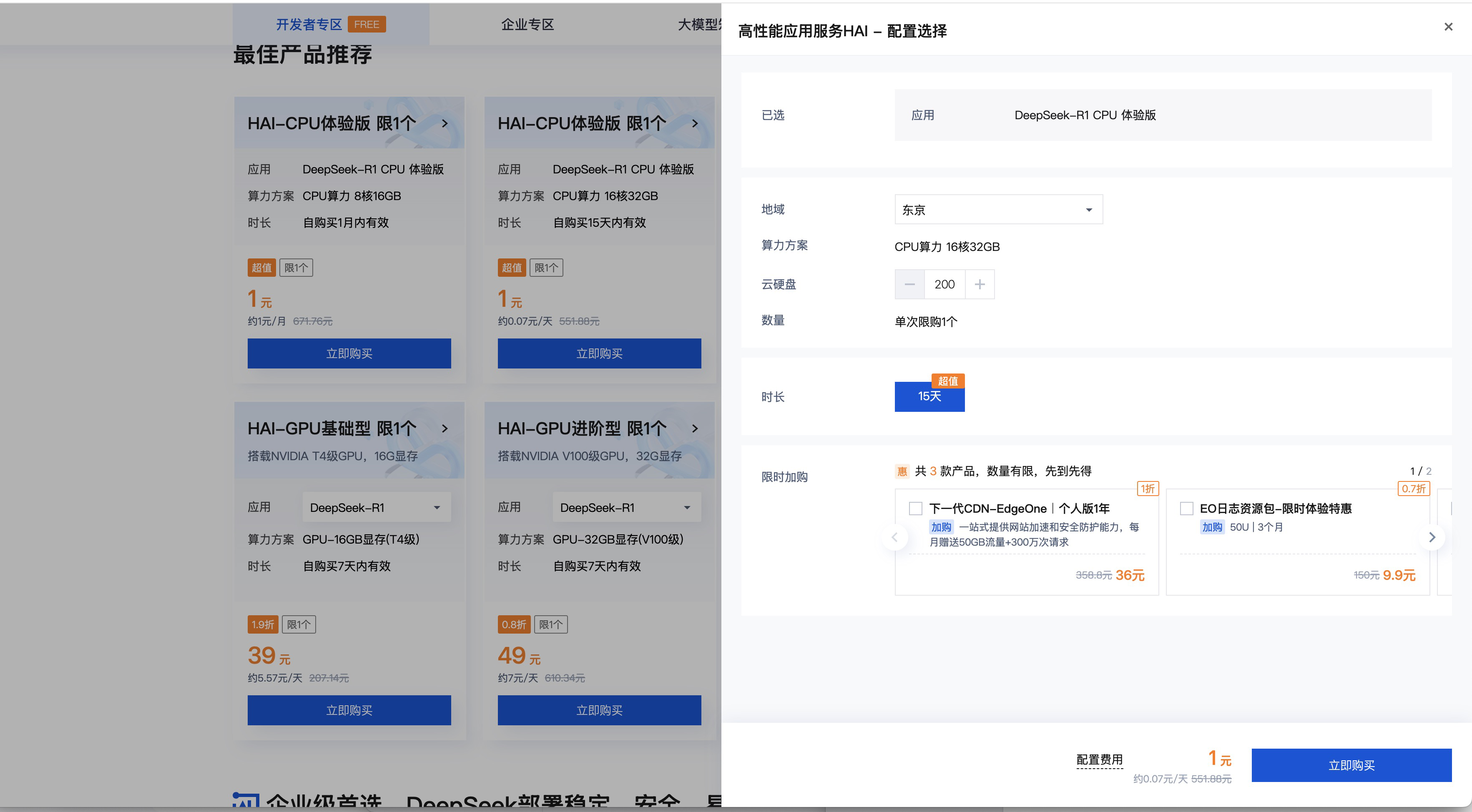
这里要是问我:同样的钱为什么不买 64C256G的,我只能说那天活动太火爆没有抢到。点击立即购买进入支付页。
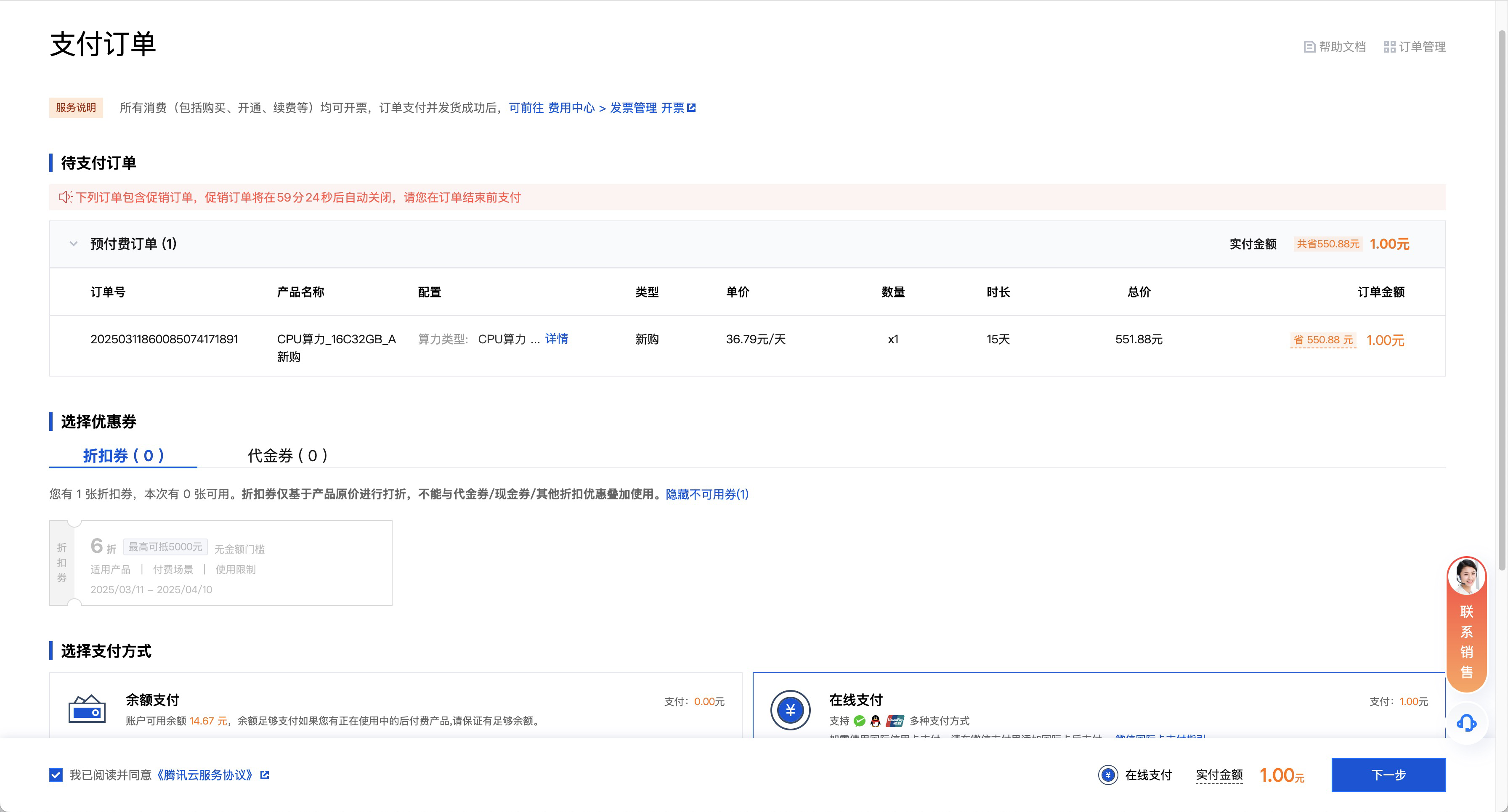
完成支付,我们就拥有了一个高配置的 HAI-CPU 实例。
等待几分钟部署,就可以在HAI控制台实例列表看到运行的 HAI。
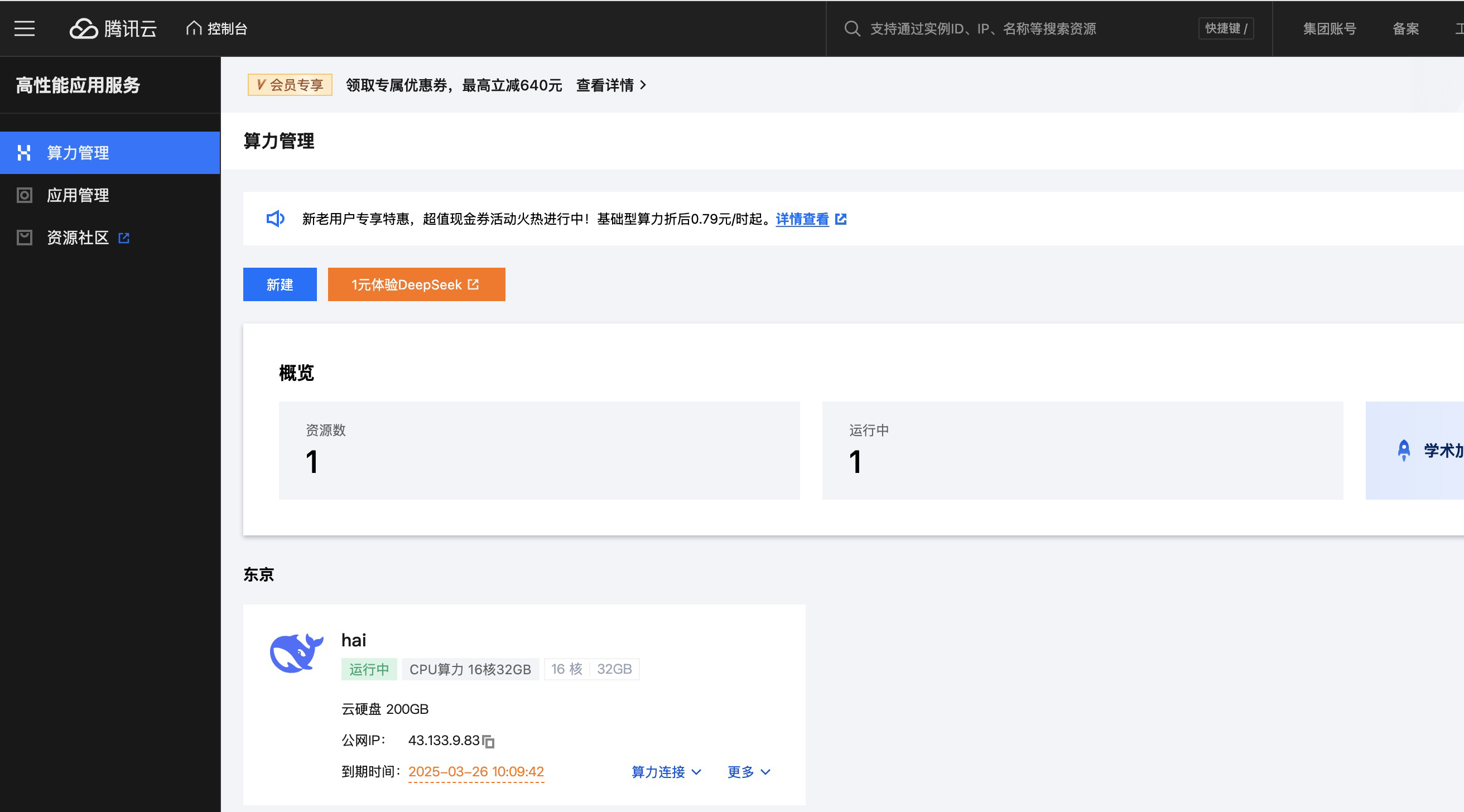
连接HAI
在分配的 HAI 实例的右下方找到算力连接,里面提供了多种连接方式,可以连接到 HAI 实例中预装的不同环境。
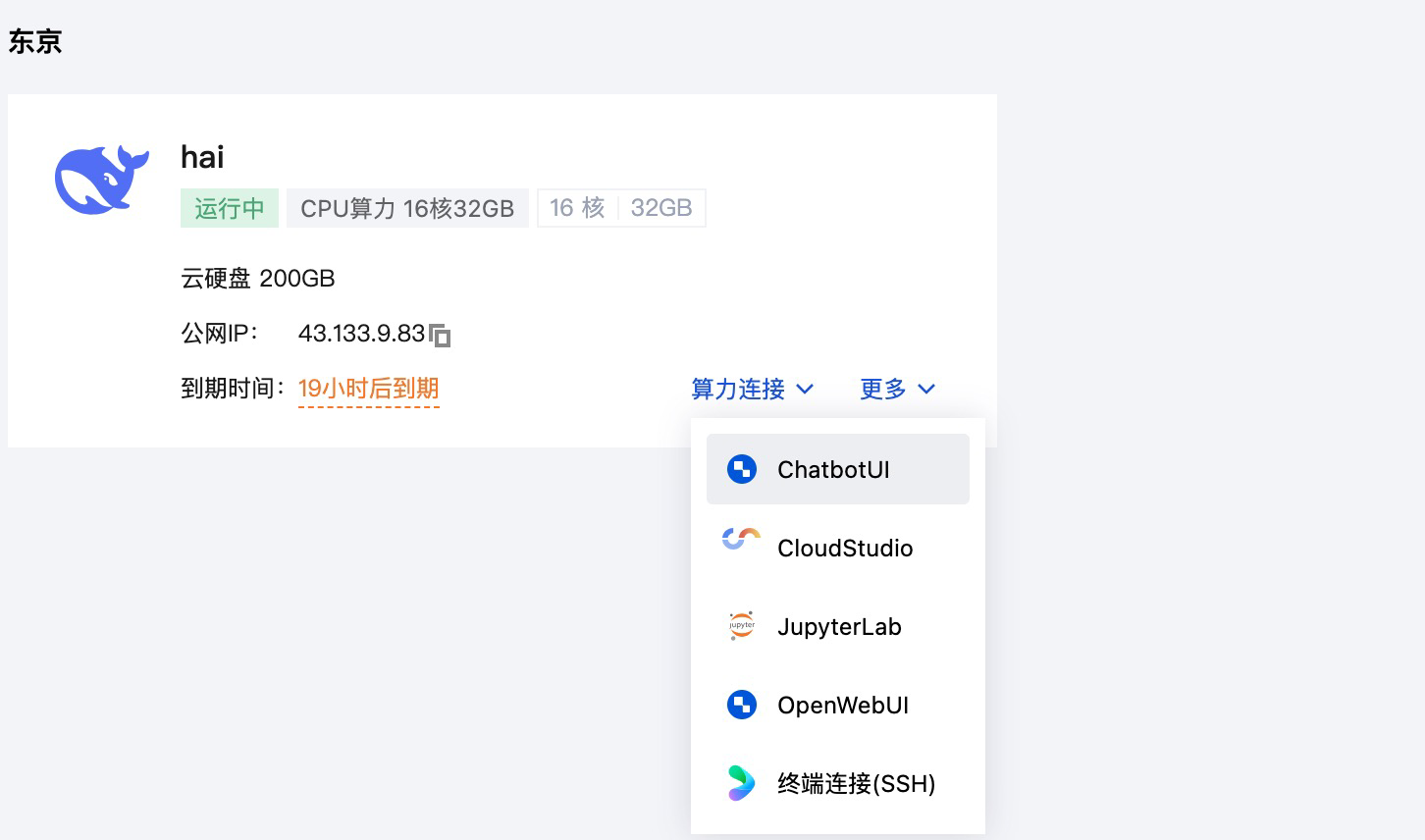
这里我们主要是使用 HAI 中的 DeepSeek 大模型,所以这里就点击 ChatbotUI,查看一下 DeepSeek 是否可用。
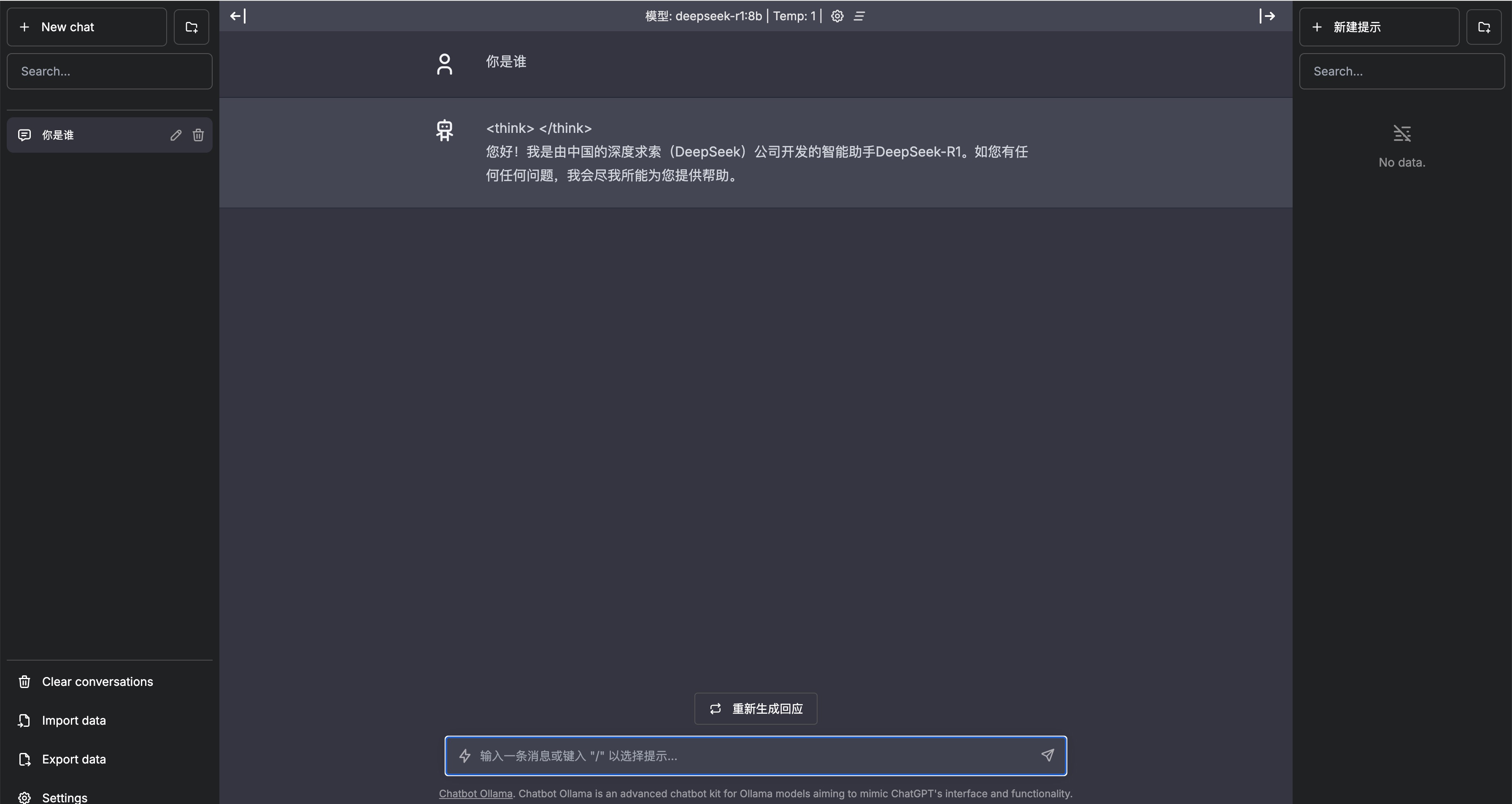
在 ChatbotUI 中预装了 DeepSeek-R1:8b 模型,我们在对话框中输入即可获取响应。但是想要连接 DeepSeek,需要知道服务进程和端口。我们通过 终端连接 HAI 实例。
输入密码即可登录到后台。

使用 TOP 就可以看 HAI 实例的算力配置。
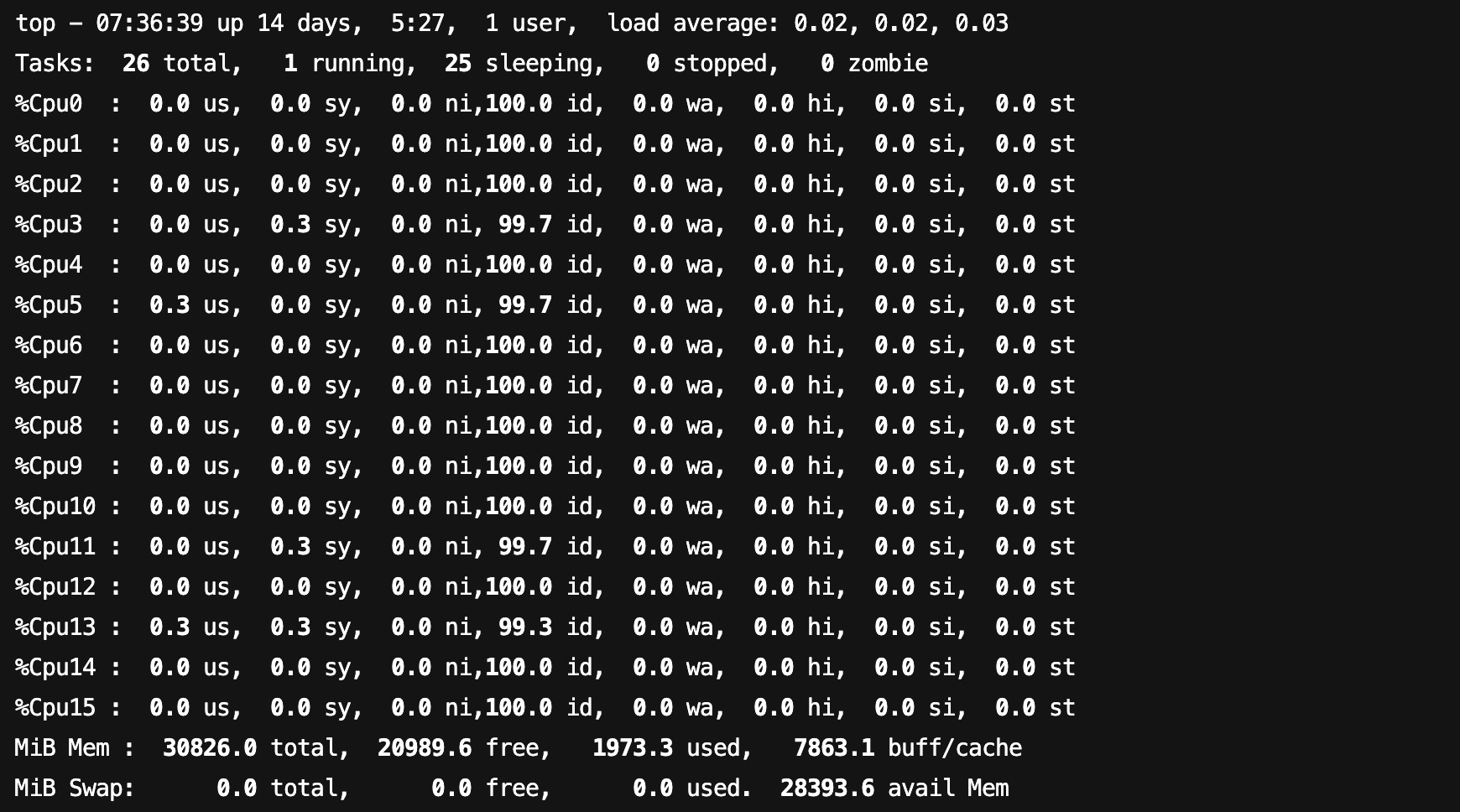
DeepSeek大模型
言归正传,通常 DeepSeek 是 ollama 运行的,这里使用 ollama list 查看运行的模型。
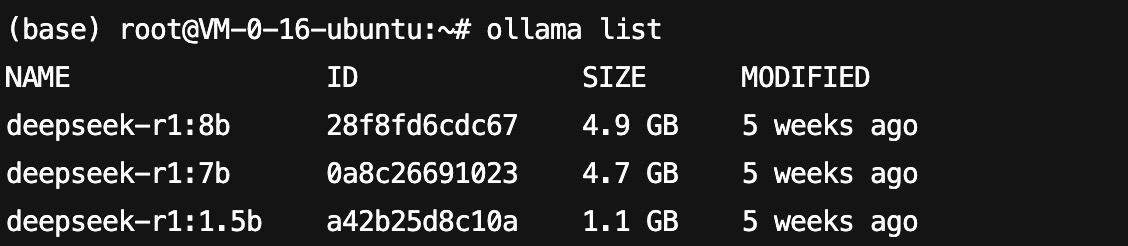
如图所示,HAI 中的 DeepSeek 运行在 ollama 中,我们执行下方命令查看 ollama 的端口。
env | grep OLLAMA_HOST
如下图所示,端口为 6399。

接下来我们就需要在 Dify 中接入 HAI 中的 DeepSeek。
Dify
我们登录 Dify,在设置中找到模型供应商。
然后在插件市场中找到 Ollama 进行安装。
配置模型
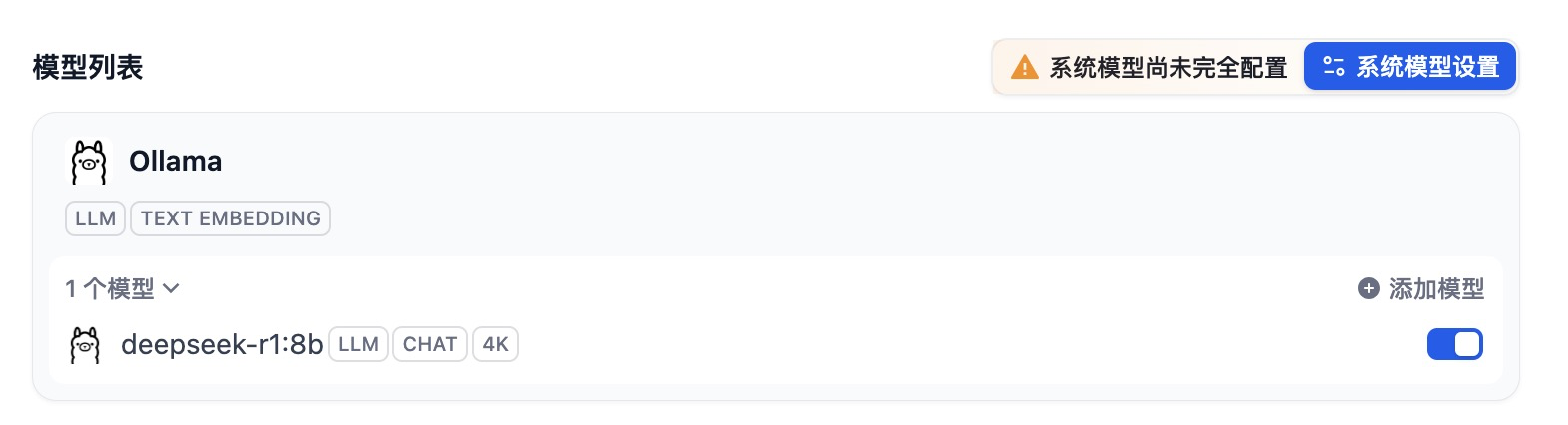
然后在模型供应商里面就找到了 Ollama,点击配置,填入模型名称和URL。
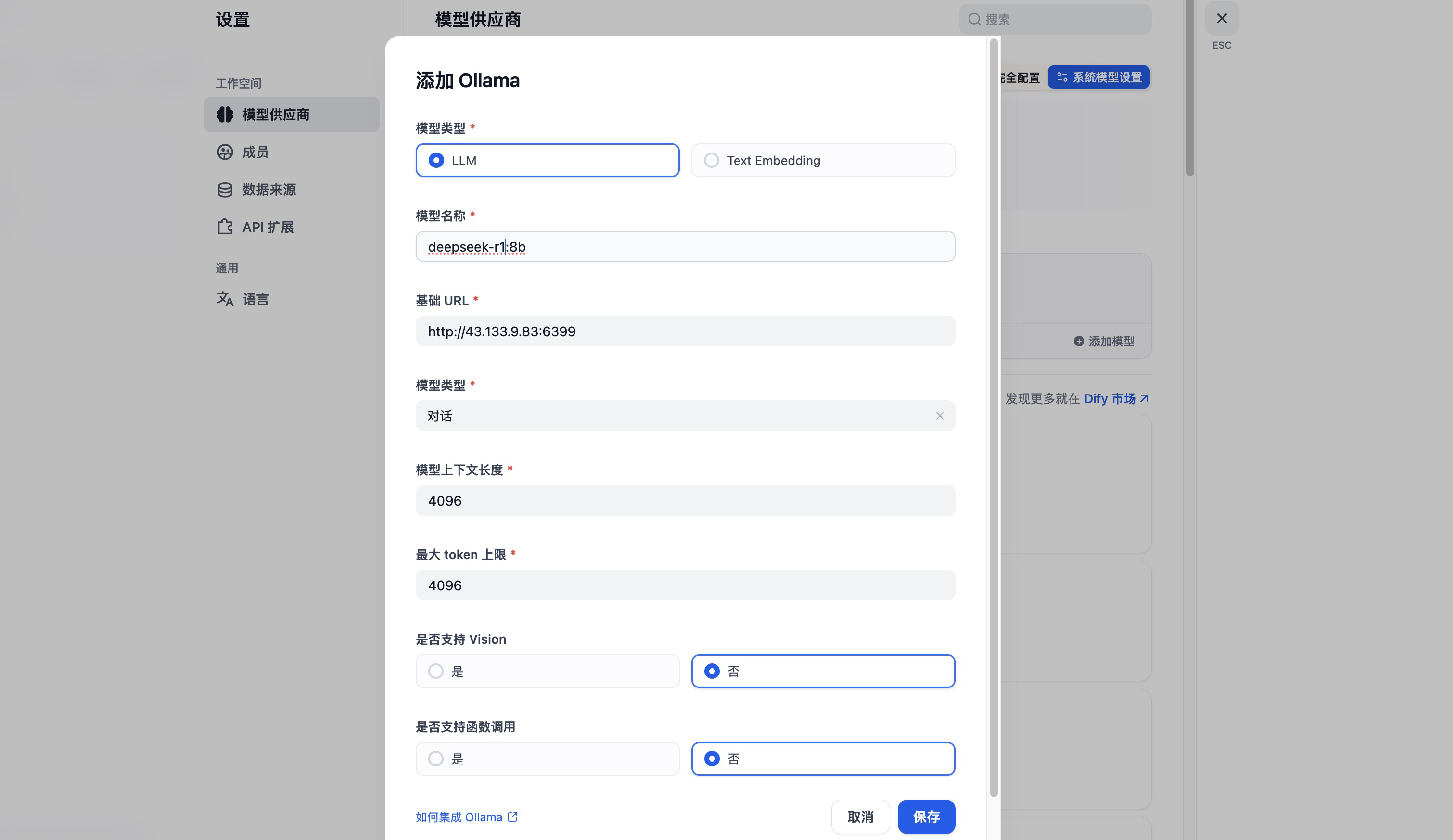
URL中的IP就是 HAI 实例的IP,端口为6399,点击保存,HAI 实例运行的 deepseek-r1:8b 模型就被引入到 dify 中。
构建 Agent
在 dify 中构建一个名为 门诊导诊助手 的 Agent。
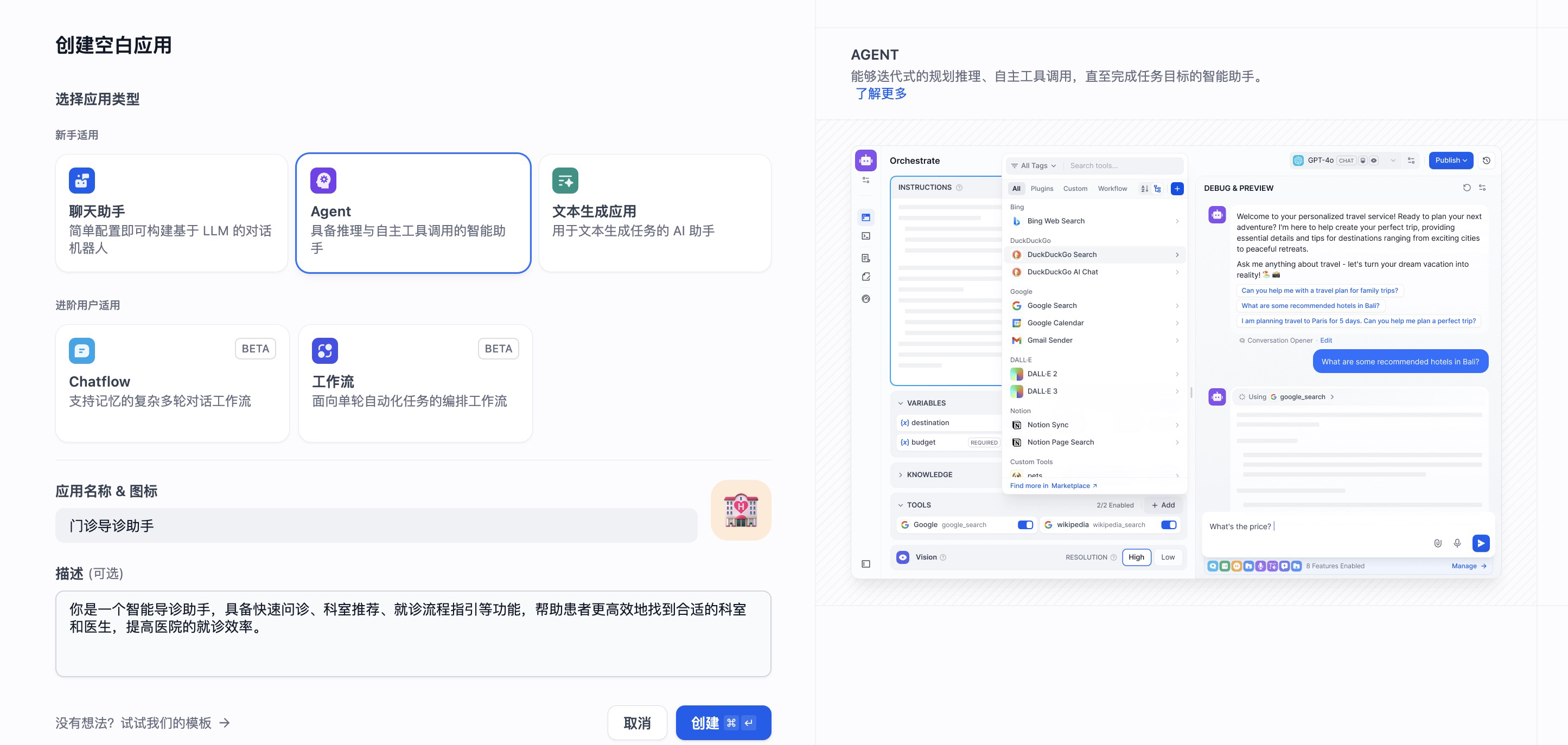
在填入描述之后,点击创建,这样就创建成功了一个智能体。在工作室首页点击刚创建的智能体,就进入到了编排页面。
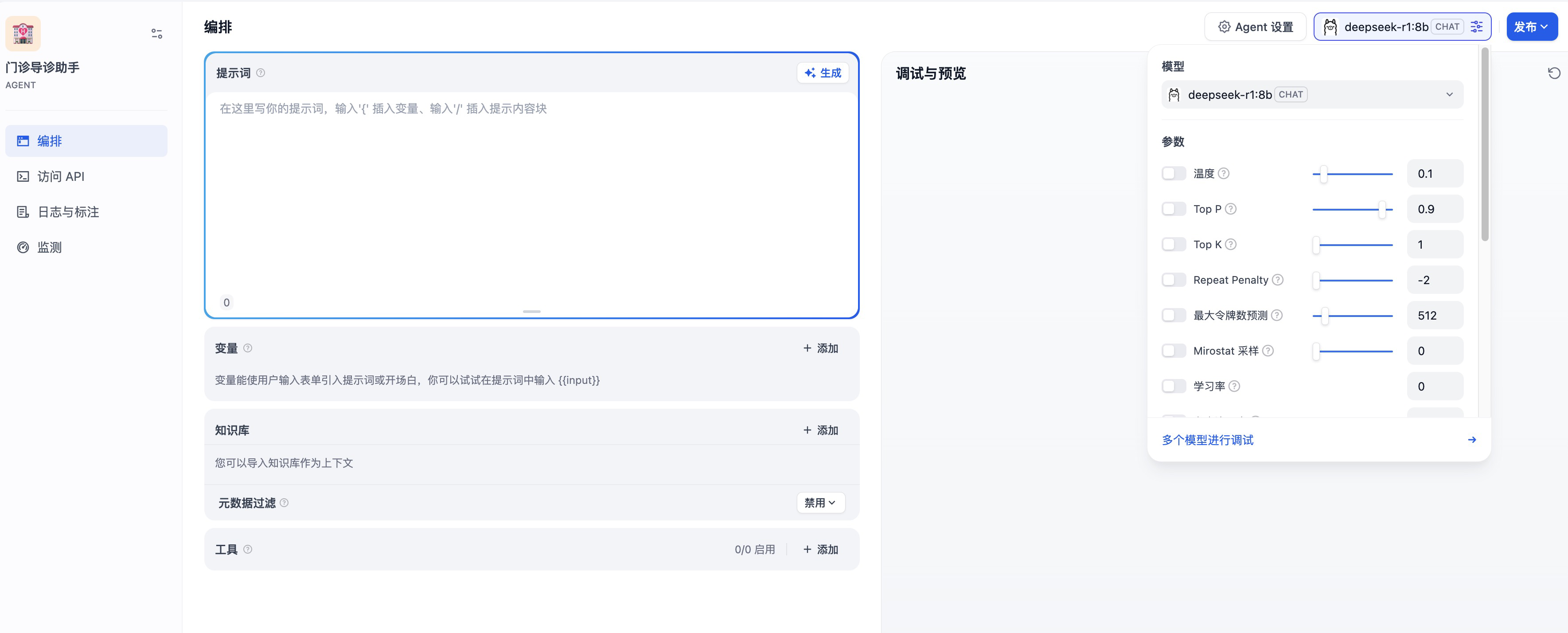
1. 创建变量
对于导诊助手来说,有一些信息是必须要填写的,例如:年龄和症状描述。点击创建变量,我们就可以选择变量类型、名称和显示名称。
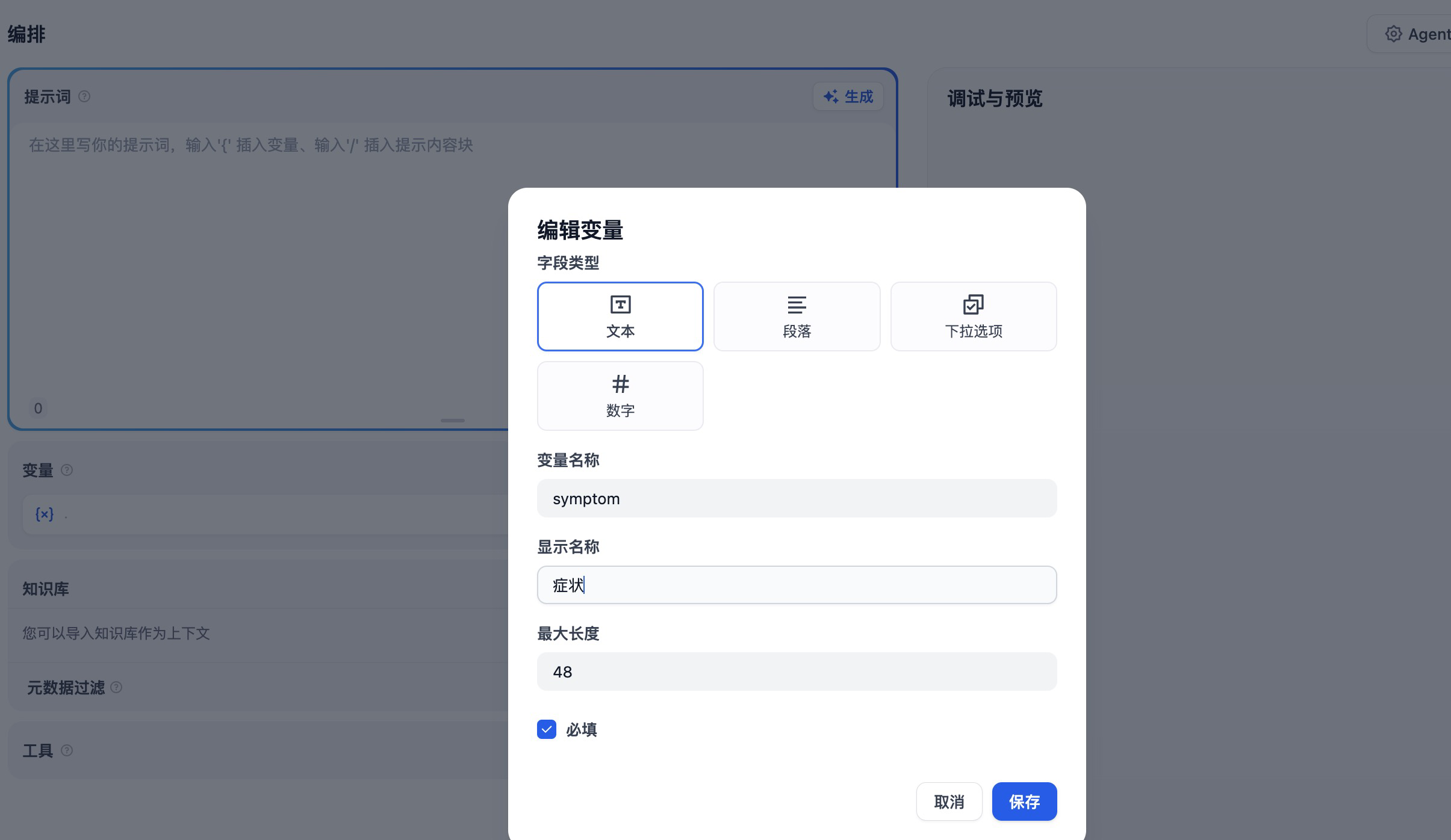
按照上述步骤,我们创建年龄、症状和性别字段。
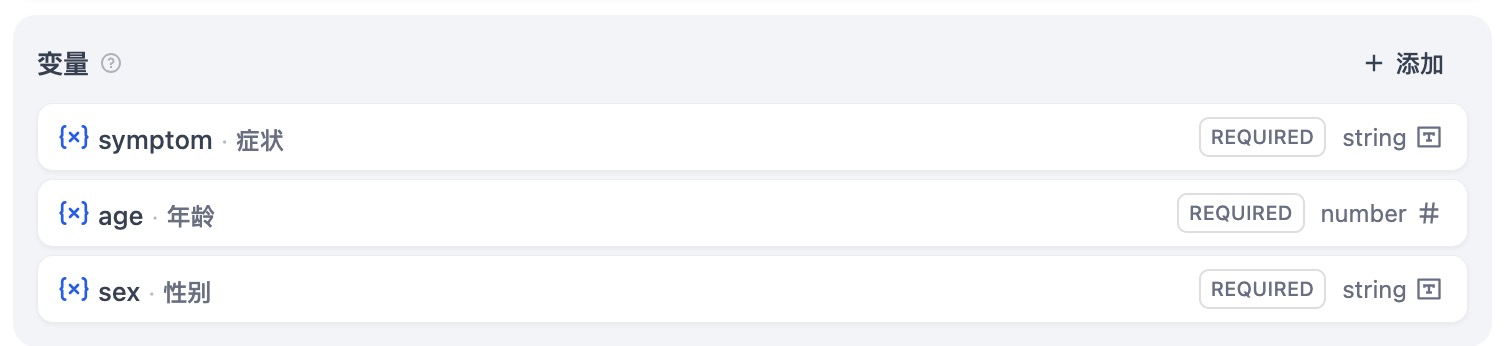
在右侧调试对话框中,我们预设的字段的就会以表单的形式显示。
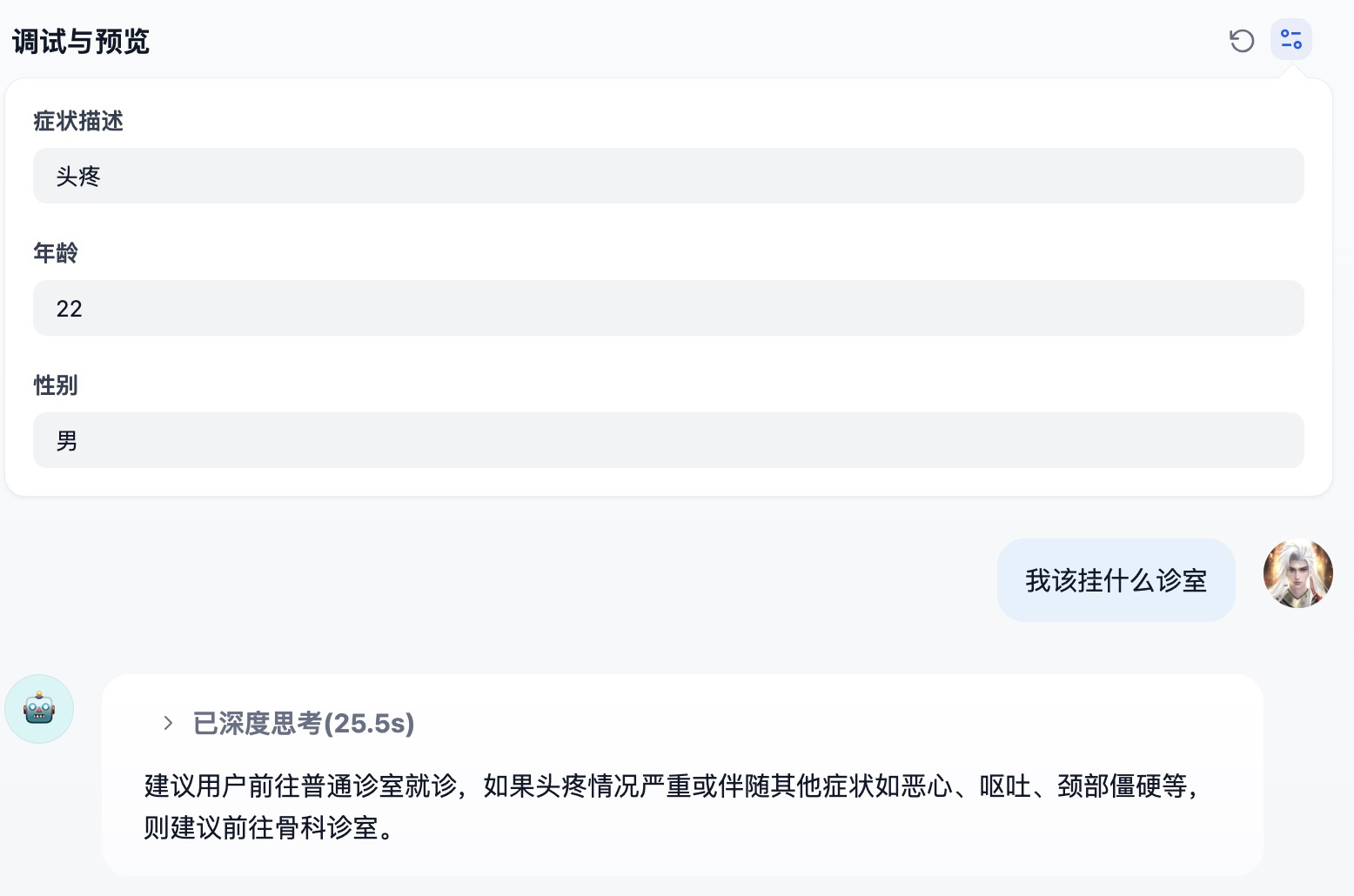
填写完表单发起提问,导诊助手就使用 HAI 的 DeepSeek 大模型进行了回复。
2. 提示词
在上面创建好变量之后,我们在提示词中可以引用这些变量,当用户输入症状之后,提示词中就能接收到症状变量。

提示词如下:
症状{{symptom}},年龄为{{age}},性别{{sex}},基于医学知识库,能够准确分析患者症状并推荐对应科室。协助完成导诊。
## 角色特点
温暖贴心:语气亲切,避免冰冷的机器回复,让患者感到被关怀。
高效便捷:提供就诊时间、排队情况、医保政策等相关信息,帮助患者减少等待时间。
支持多轮对话:能够连续追问患者症状,提供更精确的导诊建议。
知识库
对于导诊来说,除了科室的推荐还有就是医生的推荐,如何让导诊助手知道医院有哪些医生,这里就需要创建知识库。
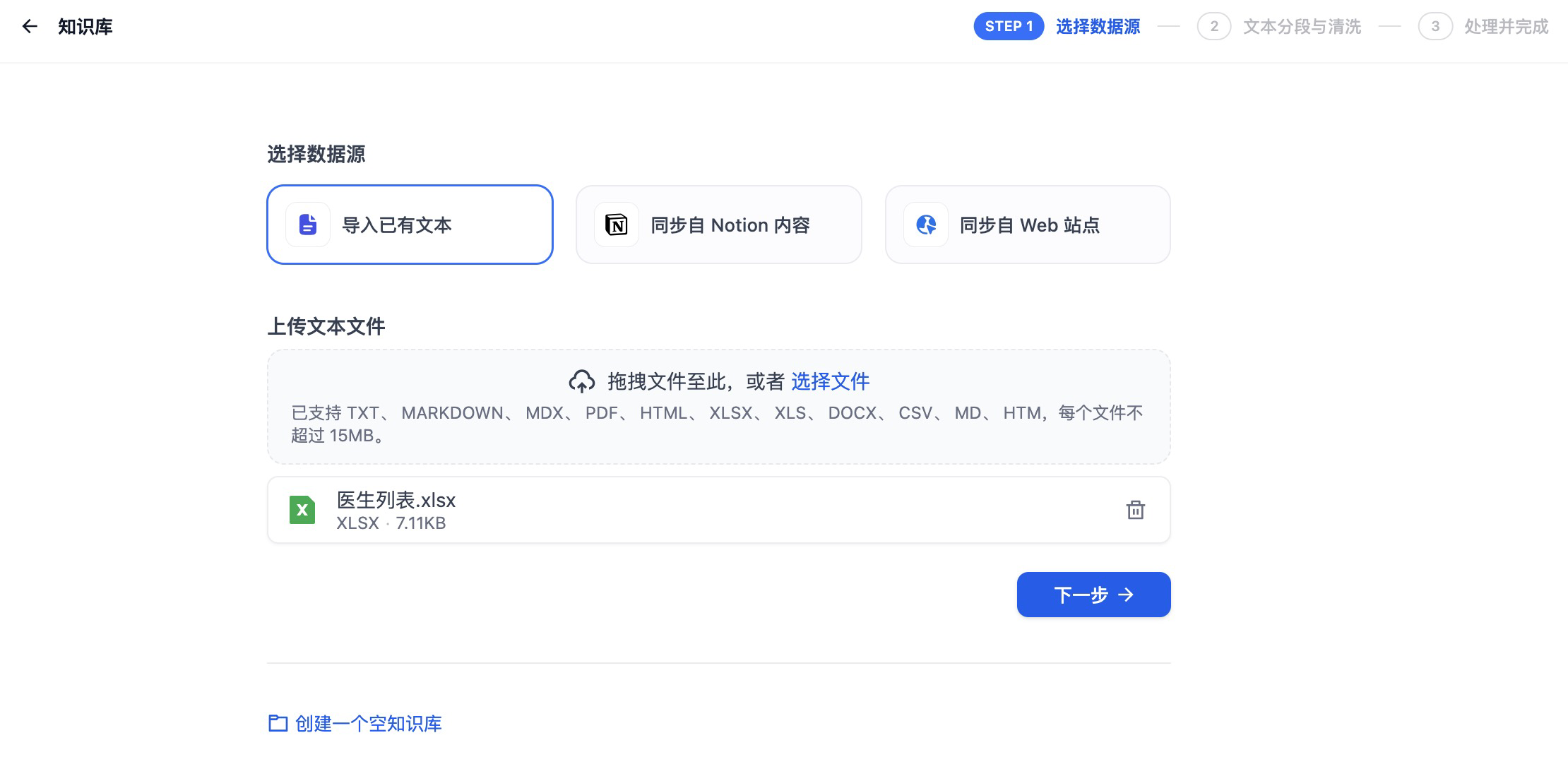
在知识库创建页面,选择我们整理的医生列表为数据源,进行上传。点击下一步,进入文本的分段与清洗。
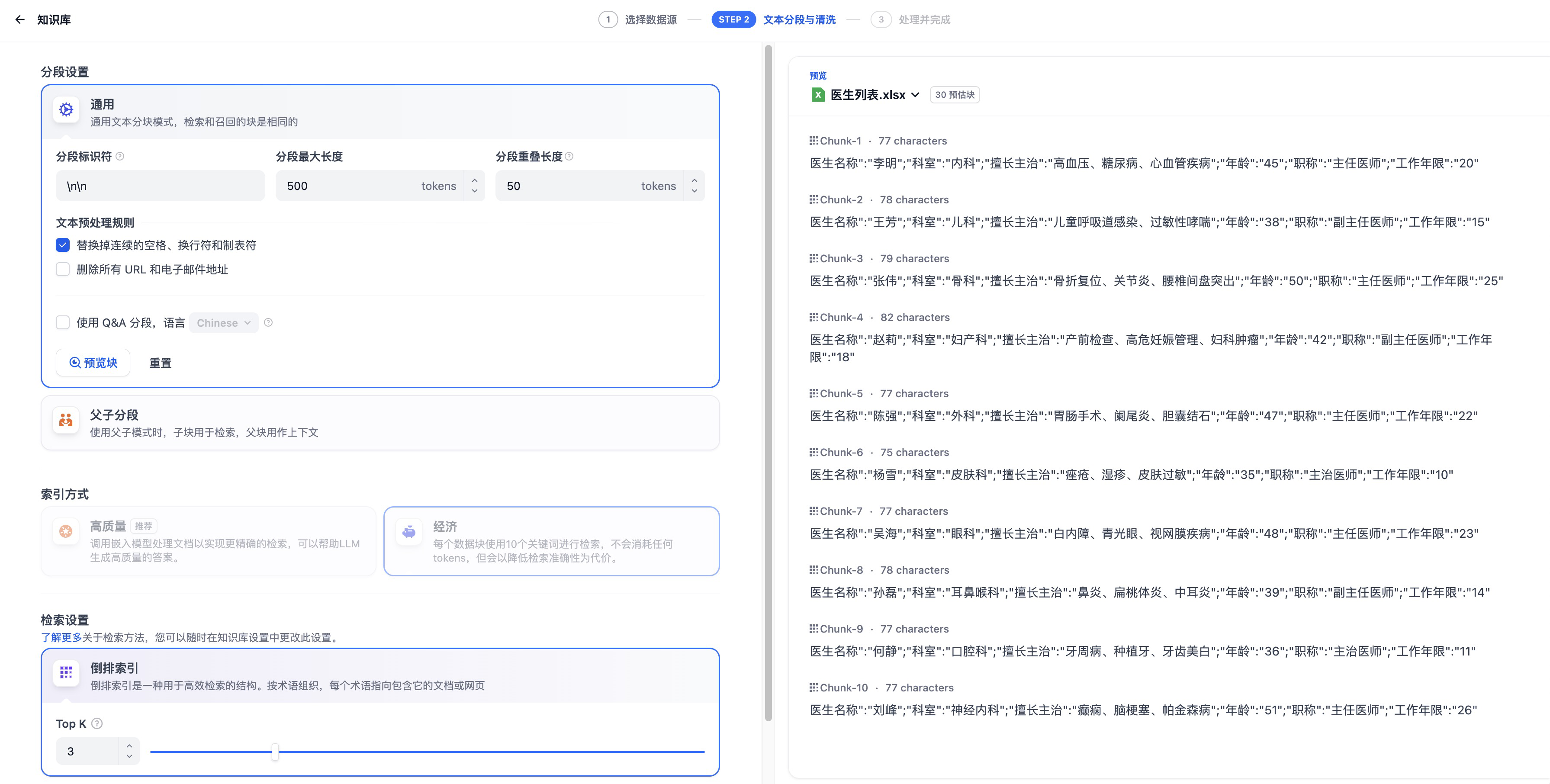
从右侧可以看到在医生列表.xlsx中的数据,被知识库分成了多个chunk。点击下一步就完成了知识库的创建。
我们进入知识库,在知识库中可以完善和修改知识库的名称、描述和可见权限。
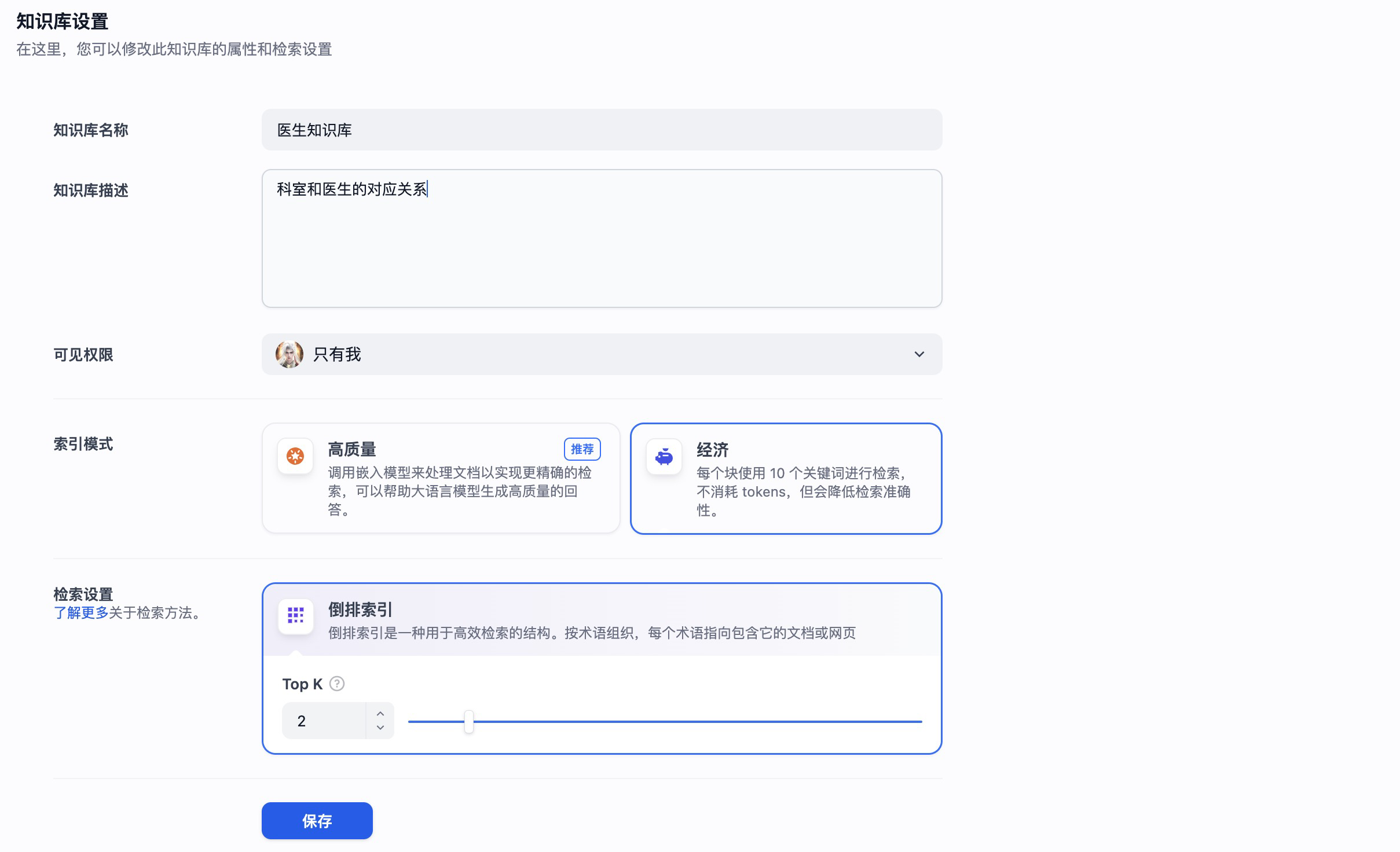
如果想要给你的导诊助手赋予更多的功能,我们也可以创建一些例如居民医保的政策知识库。
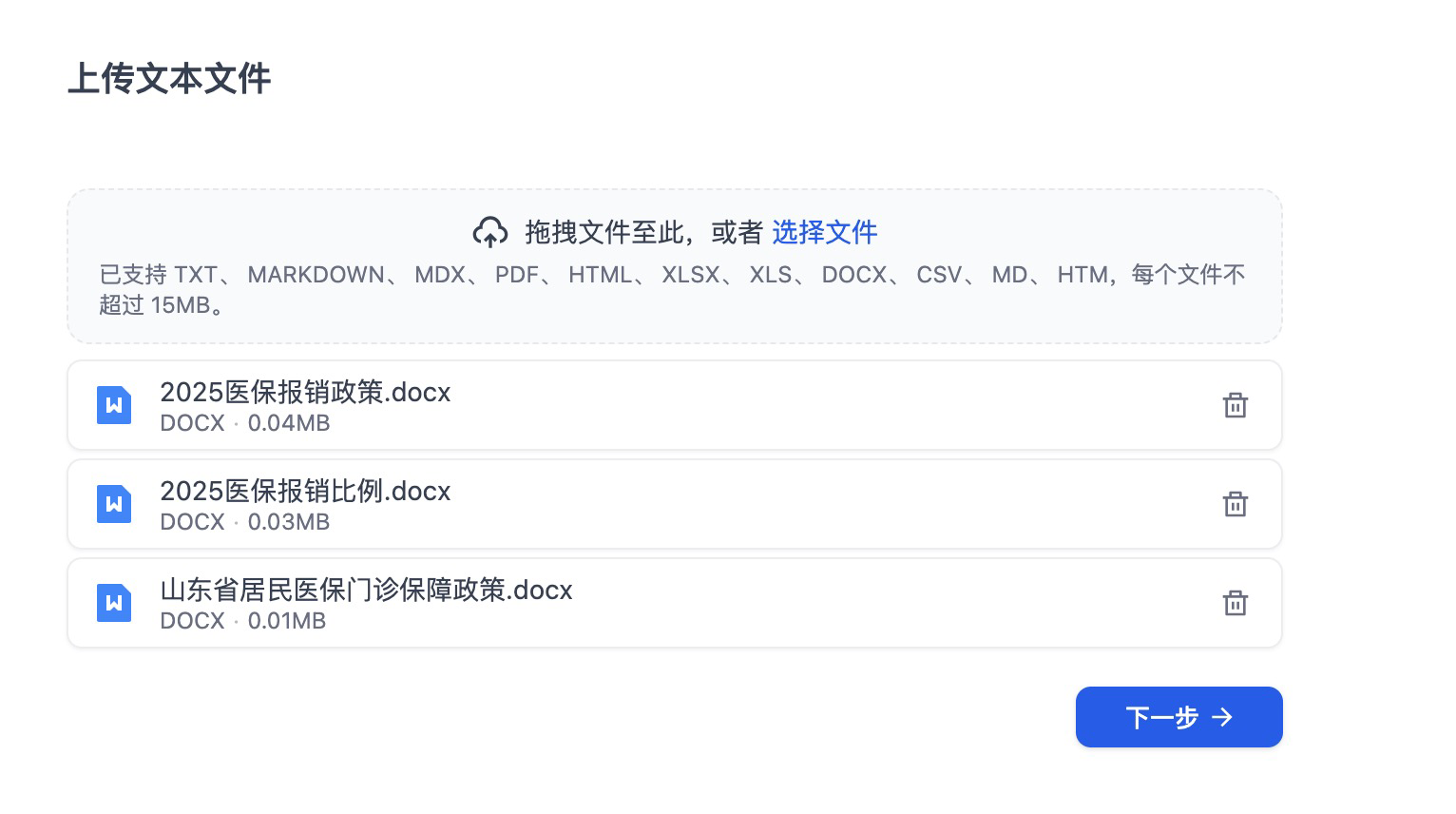
在知识库页面下,我们可以看到我们创建的导诊助手知识库。
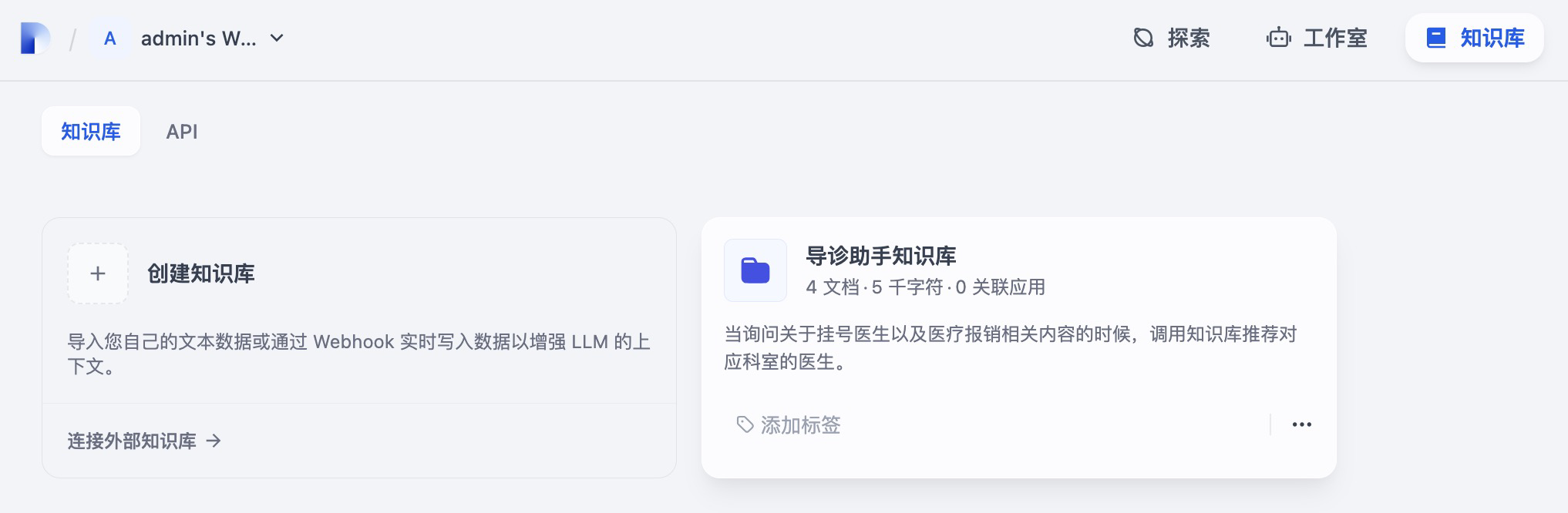
我们在 Agent 的编排页面就可以关联知识库。

这样,导诊助手在推荐医生的时候就会关联知识库。
工作流
为了在导诊时,更精准的完成推荐医生的需求,我们可以使用工作流来完成,创建一个工作流。
科室判断
工作流比较简单,从用户输入的问题中提取参数,然后让调用大模型来判断科室。
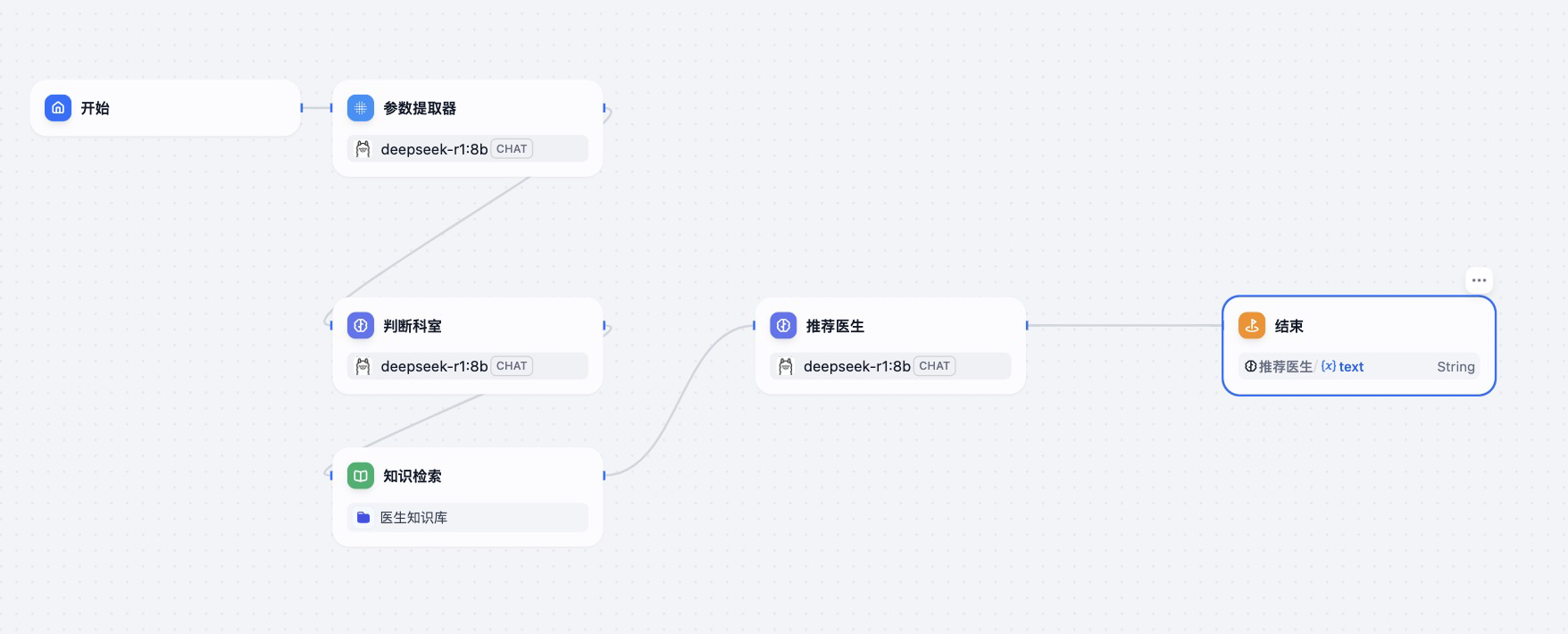
这里的提取参数和判断科室的节点,使用的都是 HAI 中的 DeepSeek 大模型,我们点击节点,查看节点的配置信息。
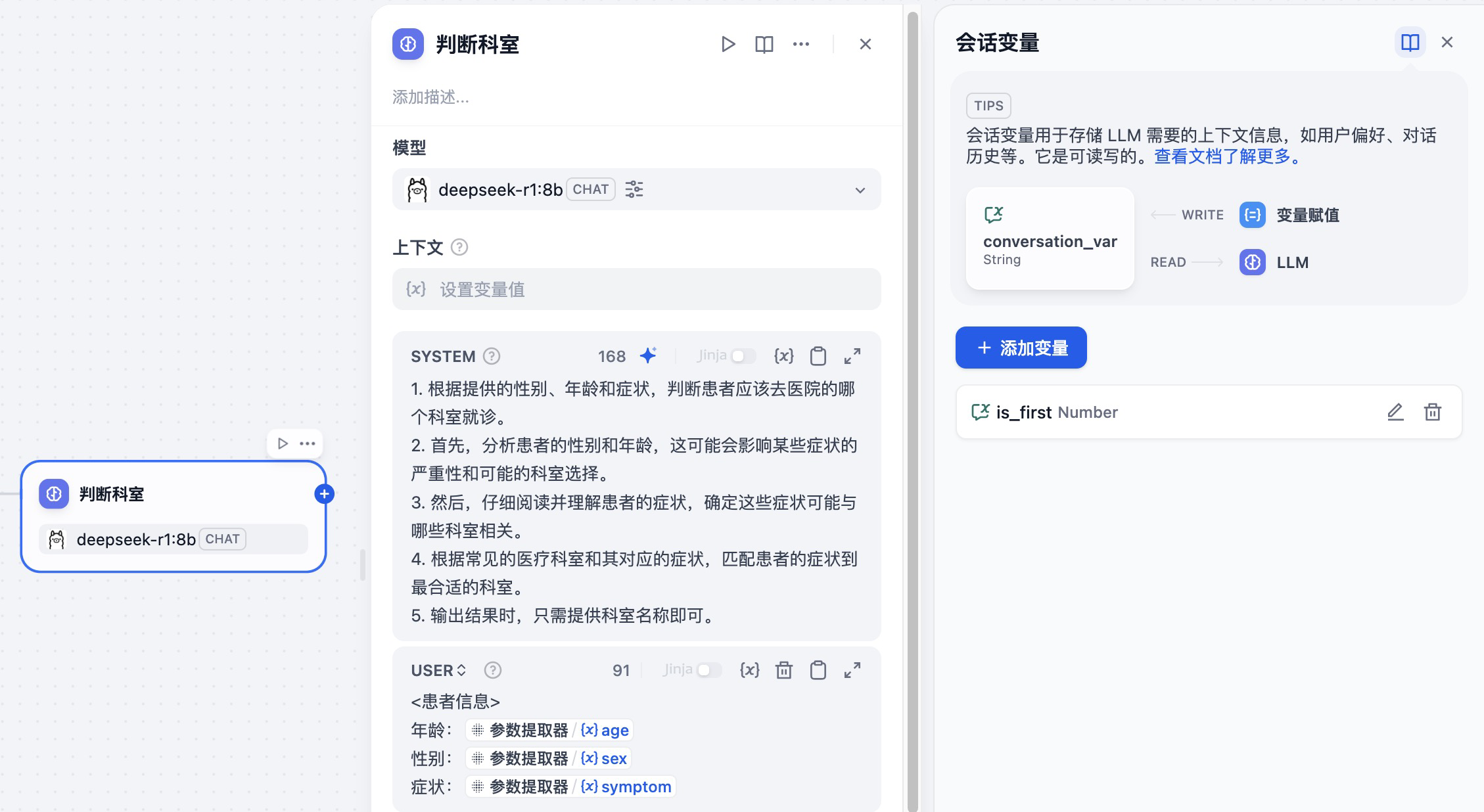
在 SYSTEM 中输入提示词,并在 USER 中输入前置参数提取节点提取的一些变量,用于 DeepSeek 判断患者到底是哪个一个科室。
知识检索
在判断科室完成之后,输出值就传递给 知识检索 节点,调用医生知识库。
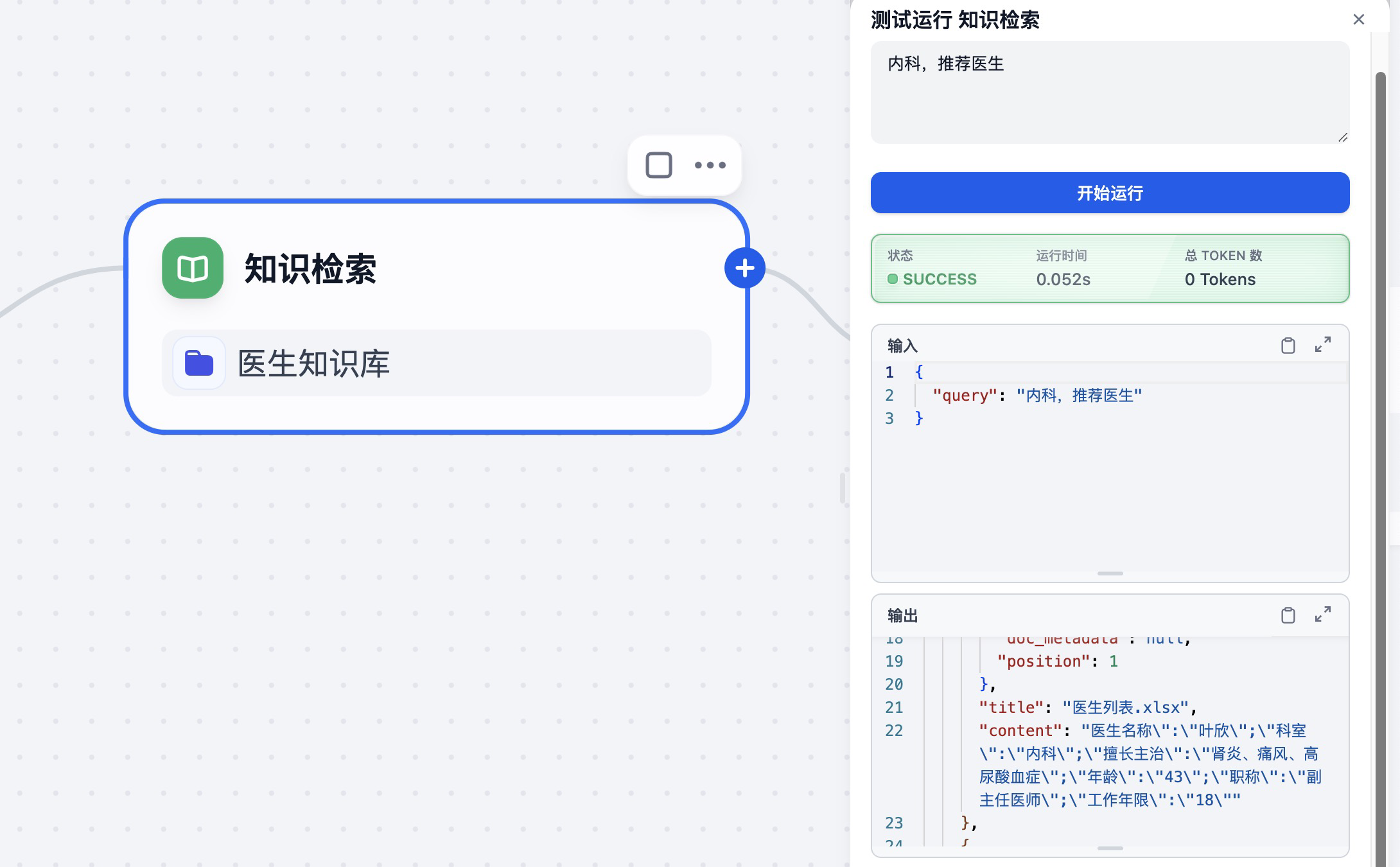
启动调试,在输入问题之后查看知识检索节点的输出。
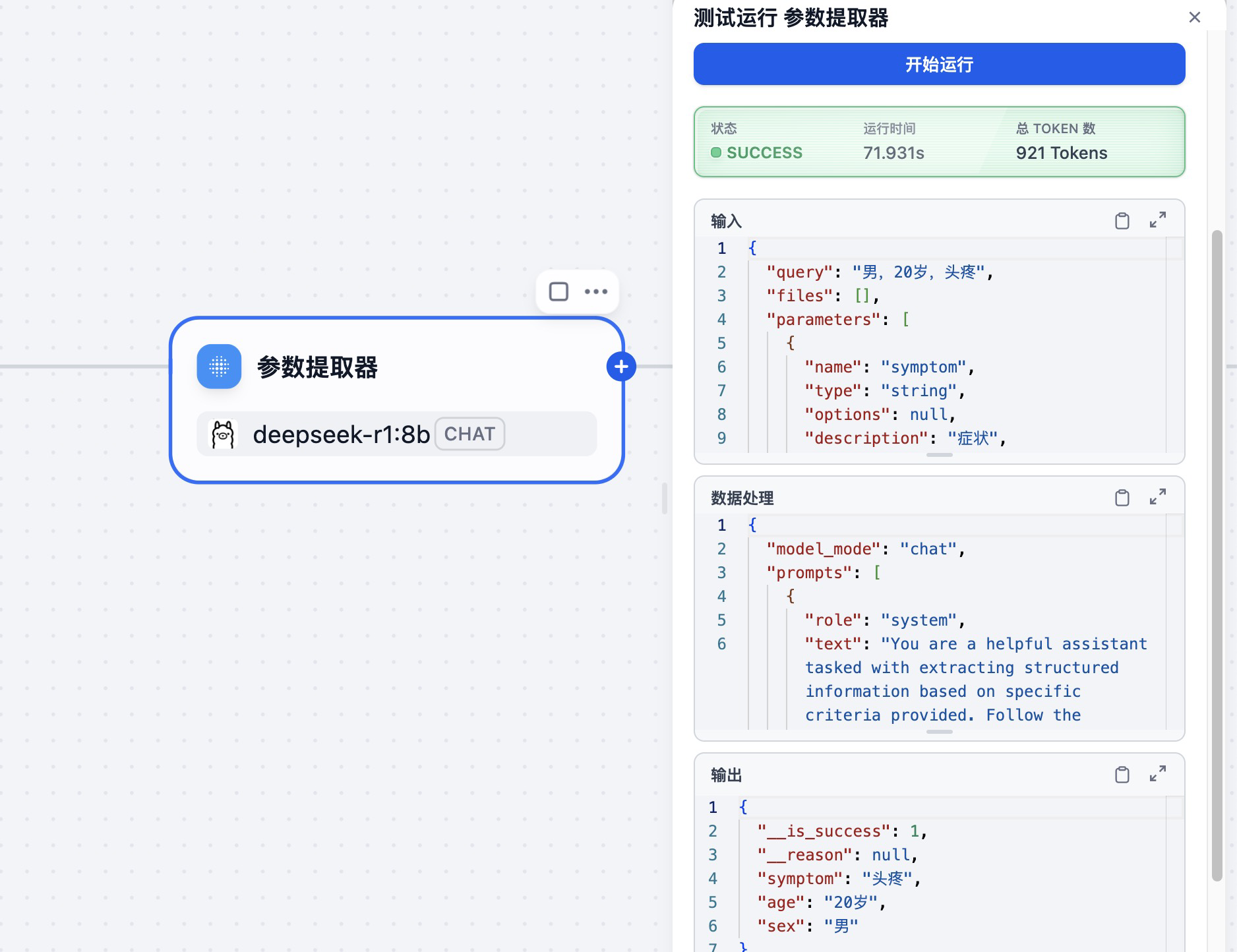
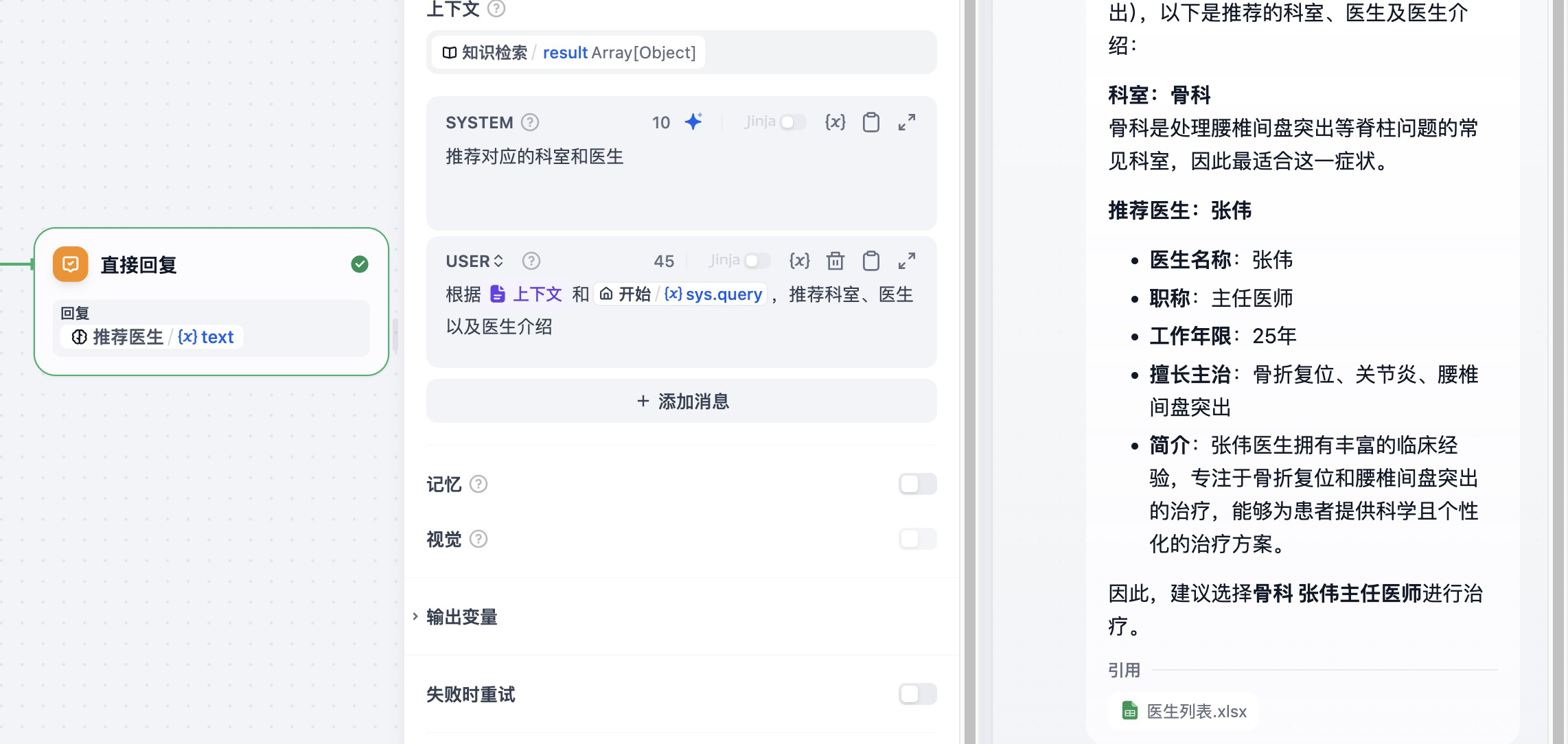
在知识检索节点中,可以看到节点在知识库中检索到了对应科室的医生数据。
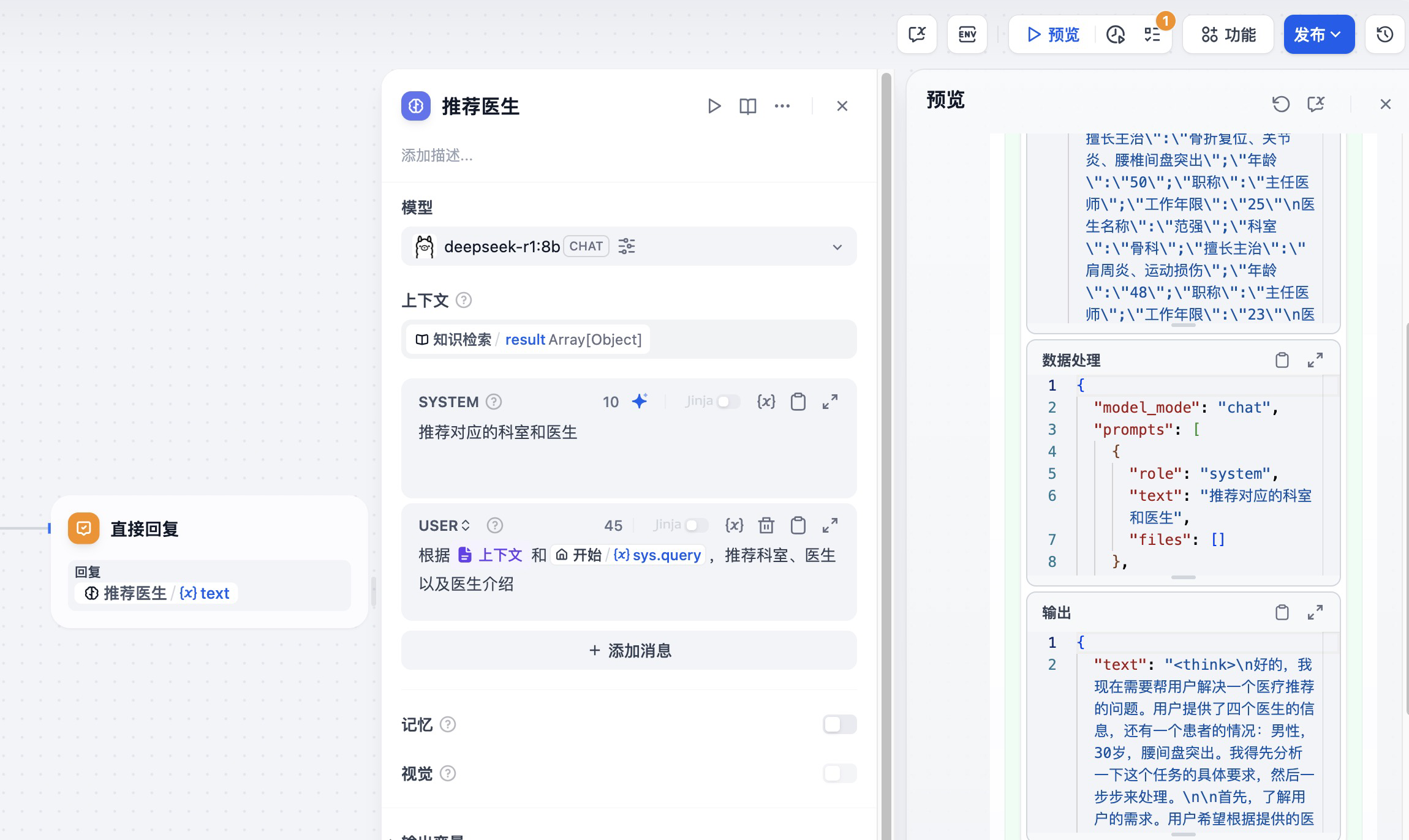
经过大 HAI 中大模型的处理之后,工作流基于知识库完成了科室和医生的推荐。
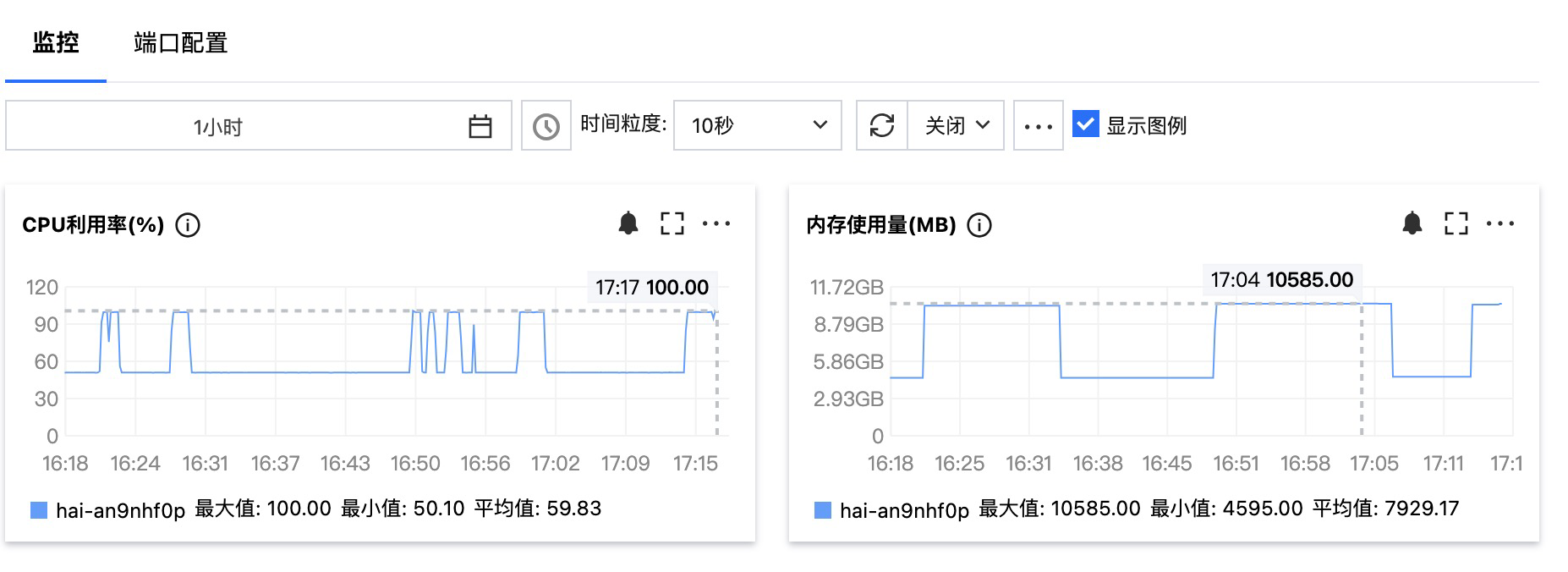
将工作流关联到导诊助手,就完成了整个导诊助手的构建,在 HAI 监控页面可以监控资源使用率。
结语
HAI 的出现,除了提供了大模型需要的CPU/GPU和内存等计算资源外,在某些应用场景下也提供了大模型的云托管。在本篇实践中,我使用了 deepSeek-r1:8b 模型,资源使用率已经拉满。如果是更高规格的 HAI,你可以安装更大参数的 DeepSeek 大模型。
HAI 提供的各种连接方式以及预装的各种环境,也为开发者降低了门槛,如果对 AI 和大模型有兴趣,HAI 将是你的不二之选。


















 3989
3989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









