







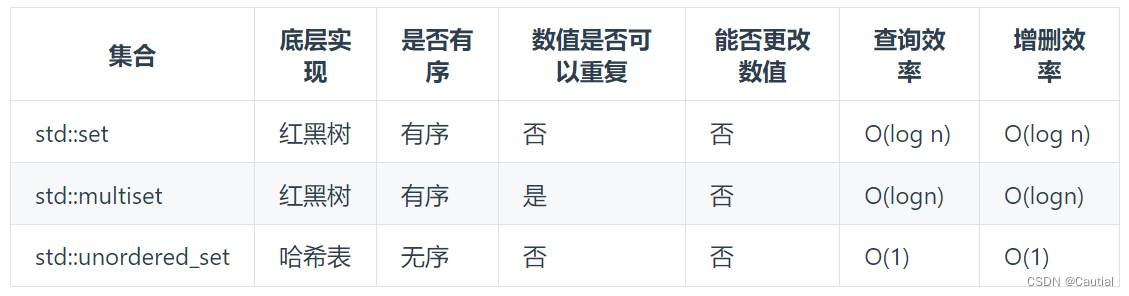
哈希表理论要点
- 哈希表适用场景:快速判断一个元素是否出现集合里,时间换空间策略
- 如果hashCode得到的数值大于哈希表的大小,会在再次对数值做一个取模的操作,保证索引数值一定可以映射到哈希表上
- 哈希碰撞:两个及以上数值映射到哈希表同一个下标索引的位置
- 解决哈希冲突:1. 拉链法——将冲突元素储存在链表中 2. 线性探测法——依次向后寻找空余的位置
- 常用的哈希结构:数组、集合(set)、映射(map)
242. 有效的字母异位词
文章讲解:代码随想录—242. 有效的字母异位词
思路:
首先能想到是用哈希表解决问题,因为需要先记录一个字符串出现过的所有字母和个数,然后依次取出另一个字符串中的字母和之前的记录做比较,如果匹配就返回true,不匹配则返回false。
重点是如何记录的问题,如果分别记录下字母和出现次数,就需要两层循环,时间复杂度高达O(n ^ 2)。
题目中只会出现26个小写字母,因此可以把数组建立为哈希表,数组大小只需要设置为26就好,数组下标对应顺序26个字母的位置,数组数值为该字符串中字母出现的次数。
所以由本题总结出,当已知元素个数可知且数量少、元素有规律时,可以用数组记录哈希表。
class Solution {
public:
bool isAnagram(string s, string t) {
int res[26] = {0};
for (int i = 0; i < s.size(); i ++) {
res[s[i] - 'a'] ++;
}
for (int i = 0; i < t.size(); i ++) {
res[t[i] - 'a'] --;
}
for (int i = 0; i < 26; i ++) {
if (res[i]) return false;
}
return true;
}
};时间复杂度:O(n)
空间复杂度:O(1)
349. 两个数组的交集
题目链接:LeetCode349. 两个数组的交集
文章讲解:代码随想录—349. 两个数组的交集
思路:
在LeetCode更改数据范围之前,本题元素范围很大,因此不建议使用数组。在 set 的数据结构选择中,因为题中输出元素不需要重复也不需要排序,因此选用 unordered_set,读写效率也是最高的。但后来限定了元素范围,因此可以用数组解决问题。
此外,set 相比于数组的缺点在于:直接使用 set 不仅占用空间比数组大,而且速度要比数组慢,set 把数值映射到 key 上都要做 hash 计算。因此在合适情况下还是应该选择使用数组。
//unordered_set算法
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> res;
unordered_set<int> nums(nums1.begin(), nums1.end());
for (auto num : nums2) {
if (nums.find(num) != nums.end()) res.insert(num);
}
return vector<int>(res.begin(), res.end());
}
};
//数组算法
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
int hash[1005] = {0};
unordered_set<int> res;
for (auto num : nums1) hash[num] = 1;
for (auto num : nums2) {
if (hash[num]) res.insert(num);
}
return vector<int>(res.begin(), res.end());
}
};unordered_set算法
时间复杂度:O(mn)
空间复杂度:O(n)
数组算法
时间复杂度:O(m + n)
空间复杂度:O(n)
202. 快乐数
题目链接:LeetCode202. 快乐数
文章讲解:代码随想录—202. 快乐数
思路:
读题后单纯的以为是计算问题,看过解析之后才发现题干中隐藏线索。对于快乐数的定义,需要明确的是,快乐数的各位平方和最后都会归为1,其他情况只会出现循环情况从而最后得不到1。
因此此题的解决要点就是,记录所有平方数的值,如果出现重复的就表明这个数一定不是快乐数,如果没有重复的直到最后得到结果为1,那么这个数就是快乐数。
因为元素范围很大,因此不能用数组解决问题了,也不存在重复元素和有序的问题,因此选用效率最高的 unordered_set 来解决。
class Solution {
public:
int getSum(int n) {
int sum = 0;
while (n) {
int i = n % 10;
sum += i * i;
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> num;
while (1) {
int sum = getSum(n);
if (sum == 1) return true;
if (num.find(sum) != num.end()) return false;
num.insert(sum);
n = sum;
}
}
};时间复杂度:O(log n)
空间复杂度:O(log n)
1. 两数之和
题目链接:LeetCode1. 两数之和
文章讲解:代码随想录—1. 两数之和
思路:
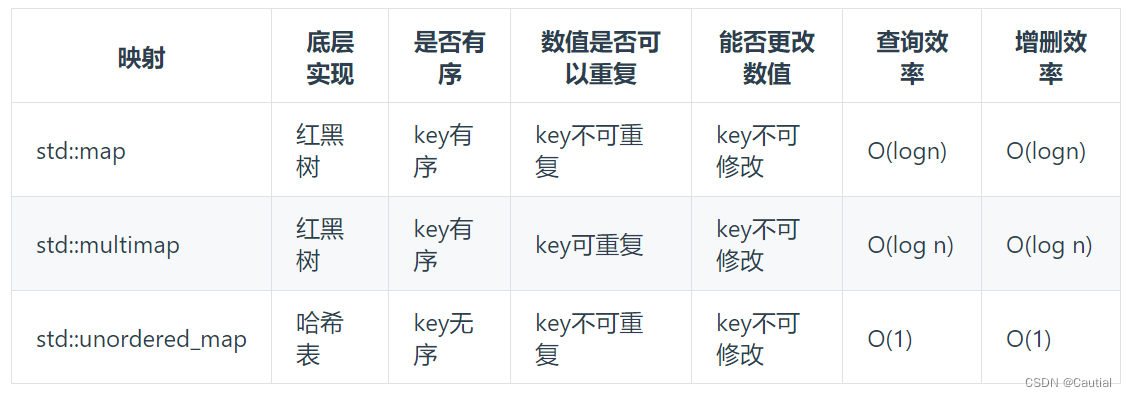
可以想到使用哈希表解决问题,对于数组中的每个 num,只需要在数组中找是否存在 target - num 就可以找到满足题意的两个数。
选择 map 而不选择 set 的原因:set 只能存一种类型的元素,而 map 可以存储两种。因为本题不允许重复使用同一个元素,因此需要对下标进行记录,防止重复使用。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> map;
for (int i = 0; i < nums.size(); i ++) {
auto item = map.find(target - nums[i]);
if (item != map.end()) return {item->second, i};
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};时间复杂度:O(n)
空间复杂度:O(n)
问题:
set 和 map 区别是什么?当需要储存1种元素时用 set;当需要储存两种元素时用 map。
总结:
第二遍刷已经很明确什么场合用什么数据结构了,数组适用于一种有限个数的元素,set适用一种大数量元素,map适用两种元素。
此外注意 map 中元素写法。















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









