







链表理论要点
- 链表中的节点区别于数组,是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理,并通过指针串联在一起
- C++中链表的构造:
// 单链表 struct ListNode { int val; // 节点上存储的元素 ListNode *next; // 指向下一个节点的指针 ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数 };- 如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值
//使用自定义构造函数 ListNode* head = new ListNode(5); //使用默认构造函数 ListNode* head = new ListNode(); head->val = 5;- 链表中,删除的节点仍然保存在内存中。C++需要手动释放节点的这块内存;而Java、Python等语言有自己的内存回收机制,不用手动释放了
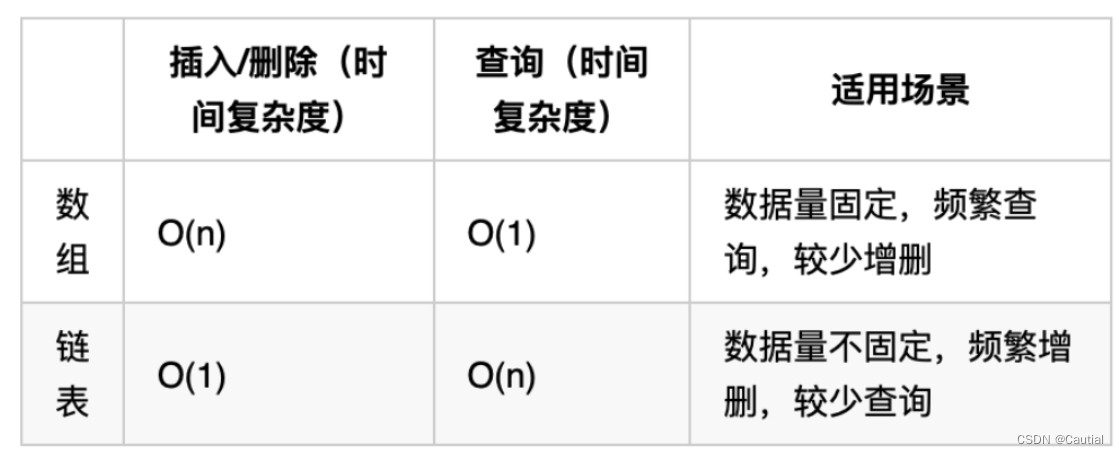
- 链表和数组的性能对比
203. 移除链表元素
题目链接:Leecode203. 移除链表元素
文章讲解:代码随想录—203. 移除链表元素
思路:
移除元素迅速想到可能移除的是头节点,因此需要设置虚拟头结点,然后按正常移除链表其他节点一样移除头结点
想到要设置两个指针,一个指向当前节点位置,一个搜寻不需要移除元素的指针,然后把当前指针节点的next指针指向不需要移除元素的指针即可
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* cur = dummyHead;
while (cur->next != NULL) {
if (cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
}
else cur = cur->next;
}
head = dummyHead->next;
delete dummyHead;
return head;
}
};时间复杂度:O(n)
空间复杂度:O(1)
707. 设计链表
题目链接:Leecode707. 设计链表
文章讲解:代码随想录—707. 设计链表
思路:就是链表的所有基本操作,个人认为掌握了这道题,链表这个数据结构基本没有问题了
class MyLinkedList {
public:
struct ListNode {
int val;
ListNode* next;
ListNode(int x) : val(x), next(nullptr){}
};
MyLinkedList() {
dummyHead = new ListNode(0);
size = 0;
}
int get(int index) {
if (index > (size - 1) || index < 0) return -1;
ListNode* cur = dummyHead->next;
while (index --) cur = cur->next;
return cur->val;
}
void addAtHead(int val) {
ListNode* tmp = new ListNode(val);
tmp->next = dummyHead->next;
dummyHead->next = tmp;
size ++;
}
void addAtTail(int val) {
ListNode* tmp = new ListNode(val);
ListNode* cur = dummyHead;
while (cur->next != NULL) cur = cur->next;
cur->next = tmp;
size ++;
}
void addAtIndex(int index, int val) {
if (index > size) return;
if (index < 0) index = 0;
ListNode* cur = dummyHead;
ListNode* tmp = new ListNode(val);
while (index --) cur = cur->next;
tmp->next = cur->next;
cur->next = tmp;
size ++;
}
void deleteAtIndex(int index) {
if (index > (size - 1) || index < 0) return;
ListNode* cur = dummyHead;
while (index --) cur = cur->next;
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp; //delete只是释放了tmp的内存,并非指向NULL,会变成随机值成为野指针
tmp = nullptr; //如果不加这一句,以后用到这部分地址就会变成乱指的野指针,指向任意地方
size --;
}
private:
int size;
ListNode* dummyHead;
};时间复杂度:index相关操作为O(index),其余为O(1)
空间复杂度:O(n)
206. 反转链表
题目链接:Leecode206. 反转链表
文章讲解:代码随想录—206. 反转链表
双指针法
思路:我能想到的第一想法就是设置三个指针,代码随想录里叫双指针,其实是设置了一个 cur 指针,cur 的前一个指针 pre,以及 cur 的 nex t指针 tmp。之所以设置 tmp 指针是因为 cur 指针反转后就找不到反转前的 next 指针了,因此需要保存一下反转前 cur 的 next 指针
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* cur = head;
ListNode* pre = nullptr;
ListNode* tmp;
while (cur != NULL) {
tmp = cur->next;
cur->next = pre;
pre = cur;
cur = tmp;
}
return pre;
}
};时间复杂度:O(n)
空间复杂度:O(1)
遇到的问题:不能一开始就设置 ListNode* tmp = cur->next,因为 cur 指向的头指针可能是空指针,此时的 tmp 就没有意义了
递归法
思路:和双指针法思路完全一样,只是把 pre 和 cur 指针作为参数传入到递归函数中了。递归法总结了从前往后反转和从后往前反转两种解法,个人觉得从后往前反转不是很好理解,且复杂度和从前往后反转一样,还是先记住前一种解法吧
从前往后递归
想法很好,只是脑袋总是转不过来,对递归不习惯
class Solution {
public:
ListNode* reverseList(ListNode* head) {
return reverse(NULL, head);
}
ListNode* reverse(ListNode* pre, ListNode* cur) {
if (cur == NULL) return pre;
ListNode* tmp = cur->next;
cur->next = pre;
return reverse(cur, tmp);
}
};时间复杂度:O(n)
空间复杂度:O(n)
从后往前递归
这个思想非常巧妙,但真的不好理解,画了个图才弄明白,递归思想真的神奇
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if (head == NULL) return NULL;
if (head->next == NULL) return head;
ListNode* last = reverseList(head->next);
head->next->next = head;
head->next = NULL;
return last;
}
};时间复杂度:O(n)
空间复杂度:O(n)
总结
链表的题还是很基础的,只要掌握了理论就基本都可以写出来
有一点注意的是,删除节点时,C++需要手动释放内存,不释放依然会通过,但这是一个好的习惯,能够节省空间、减少野指针带来的麻烦
此外,善用虚拟头结点能让思路更清晰、代码更简洁,考虑情况时不用非常麻烦
希望有空能把递归做法深入一下,很好玩















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









