










一、背景
因为工作的时候要做一些表单校验和精准搜索。所以写下这篇文章。
当涉及到正则表达式的理解和使用时,尽管它们提供了强大的文本处理能力,但其语法的复杂性常常让人倍感挑战。即使是对经常使用正则表达式的专业开发者来说,也常常会因为语法细节和复杂性而感到困扰。这种挑战性不仅体现在编写正则表达式的过程中,还体现在对已有表达式的阅读和理解上。为了克服这些困难,我们有必要对正则表达式的语法和用法进行系统的学习和总结,以便在需要时能够快速准确地使用它们。因此,本文旨在提供一个关于正则表达式的详细指南,以便读者在将来能够方便地回顾和参考。
测试工具地址:regex101: build, test, and debug regex
二、什么是正则表达式
正则表达式是由一些具有特殊含义的字符组成的字符串,多用于查找、替换符合规则的字符串。
三、元字符
即为有特定含义的字符,常见的元字符如下:

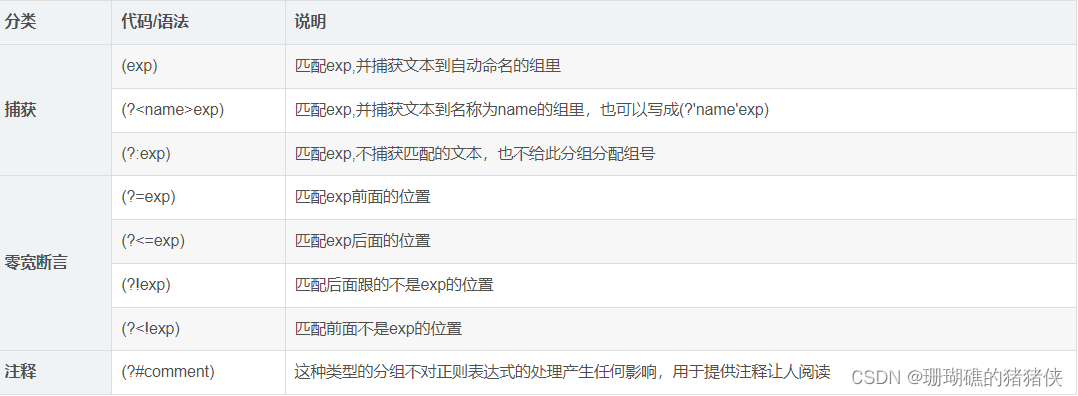
正则表达式元字符是那些在正则表达式中具有特殊意义的专用字符,它们可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。以下是一些常用的正则表达式元字符的举例:
.(点号):- 匹配除换行符之外的任何单个字符。例如,在字符串“abc\ndef”中,
.可以匹配“a”、“b”、“c”、“d”和“e”,但不能匹配换行符\n。
- 匹配除换行符之外的任何单个字符。例如,在字符串“abc\ndef”中,
*(星号):- 匹配前面的子表达式零次或多次。例如,
zo*能匹配 "z" 以及 "zoo"*。 等价于{0,}。
- 匹配前面的子表达式零次或多次。例如,
+(加号):- 匹配前面的子表达式一次或多次。例如,
zo+能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于{1,}。
- 匹配前面的子表达式一次或多次。例如,
?(问号):- 匹配前面的子表达式零次或一次。例如,
do(es)?可以匹配 "do" 或 "does" 中的 "do" 和 "does"。? 等价于{0,1}。
- 匹配前面的子表达式零次或一次。例如,
{n}:- n 是一个非负整数。匹配确定的 n 次。例如,
o{2}不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。
- n 是一个非负整数。匹配确定的 n 次。例如,
{n,}:- n 是一个非负整数。至少匹配 n 次。例如,
o{2,}不能匹配 "Bob" 中的 "o",但能匹配 "foooood" 中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。
- n 是一个非负整数。至少匹配 n 次。例如,
{n,m}:- m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,
o{1,3}将匹配 "fooooood" 中的前三个 o。"o{0,1}" 等价于 "o?"。
- m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,
^(脱字符):- 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。
$(美元符号):- 匹配输入字符串的结束位置。如果设置了 RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。
\b(退格符):- 匹配一个单词边界,即字与空格间的位置。例如,
\bhi\b匹配 "hello hi world" 中的 "hi",但不会匹配 "hiking"。
- 匹配一个单词边界,即字与空格间的位置。例如,
\B(非单词边界):- 匹配非单词边界。
\Bhi匹配 "hiking" 中的 "hi",但不会匹配 "hello hi world" 中的 "hi"。
- 匹配非单词边界。
[...](字符集):- 匹配方括号中的任何字符。例如,
[abc]匹配 "a"、"b" 或 "c"。你也可以使用范围,如[a-z]匹配任何小写字母。
- 匹配方括号中的任何字符。例如,
[^...](否定字符集):- 匹配任何不在方括号中的字符。例如,
[^abc]匹配除了 "a"、"b" 或 "c" 之外的任何字符。
- 匹配任何不在方括号中的字符。例如,
\d:- 匹配一个数字字符。等价于 [0-9]。
\D:- 匹配一个非数字字符。等价于 [^0-9]。
\s:- 匹配任何空白字符,包括空格、制表符、换页符等。等价于 [\f\n\r\t\v]。
\S:- 匹配任何非空白字符。等价于 [^\f\n\r\t\v]。
\w:- 匹配任何字类字符,包括下划线。等价于 [a-zA-Z0-9_]。
\W:- 匹配任何非字类字符。等价于 [^a-zA-Z0-9_]。
四、字符转义
有的时候需要用到元符号本身的话,就需要用到转义。比如:
1. 查找.、*符号是就会出现问题。这个时候我们就要用到\来取消这些字符的特殊意义
此时你就应该使用\.和\*,当然啦。你要哪个用\本身就使用\\。
例如:
\bwww\.cdy\.cn匹配www.cdy.cn
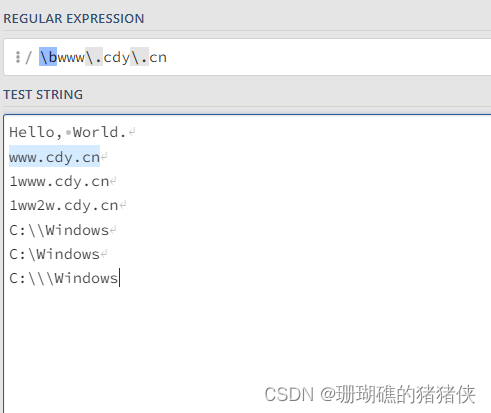
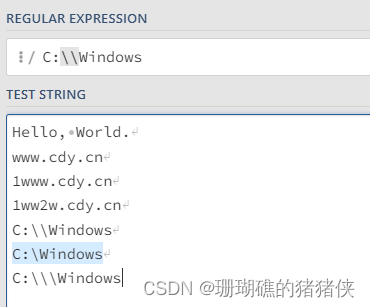
C:\\Windows匹配C:\Windows。
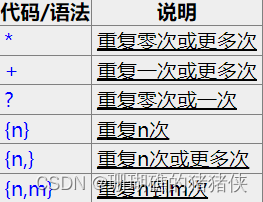
五、限定符
限定字符多用于重复匹配次数,常用的限定字符如下:
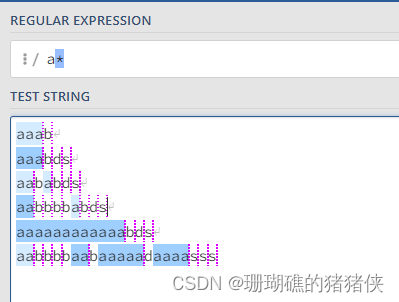
详解和实例:

a*结果如下图:
a+结果如下图:
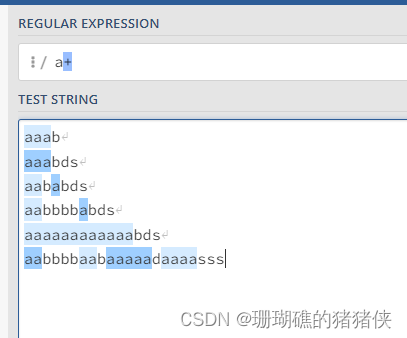
a?结果如下图:
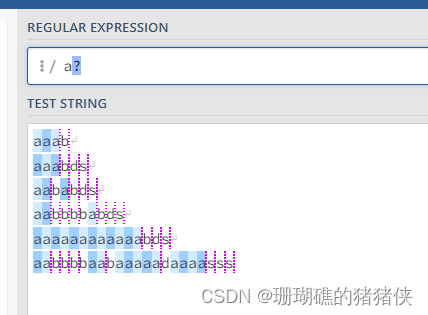
a{6}结果如下图:
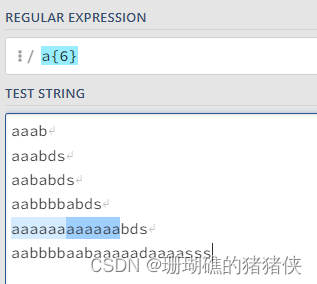
a{2,6}结果如下图:
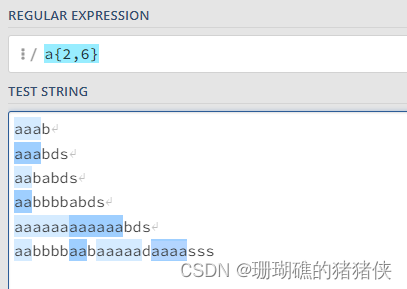
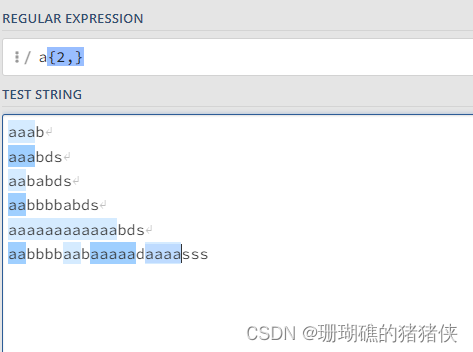
a{2,}结果如下图:
六、字符类
你想匹配没有预定义元字符的字符集合(比如字母c,d,y),应该怎么办?很简单,你只需要在方括号里列出它们就行了。

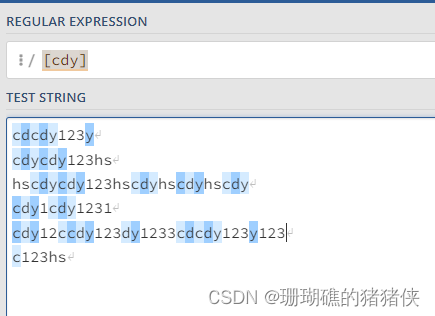
[cdy]就可以匹配任意一个括号内的字母了,下图:
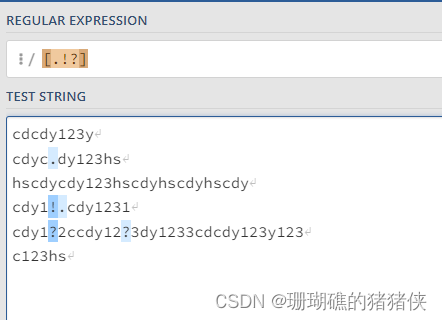
[.?!]就可以匹配任意一个括号内的标点符号了,下图:
我们也可以轻松地指定一个字符范围,像[0-9]代表的含意与\d就是完全一致的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话)。
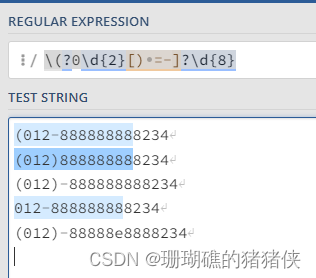
如下表达式:\(?0\d{2}[) =-]?\d{8}
首先是一个转义字符\(,它能出现0次或1次(?),然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格、=中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。结果如下图:
七、分枝条件
正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。
0\d{2}-\d{8}|0\d{3}-\d{7}:这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号,一种是4位区号,7位本地号。如下图所示:
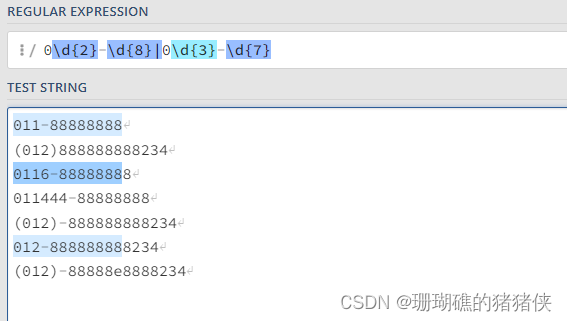
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}:这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。
八、分组
字符分组多用于将多个字符重复,主要通过使用小括号()来进行分组

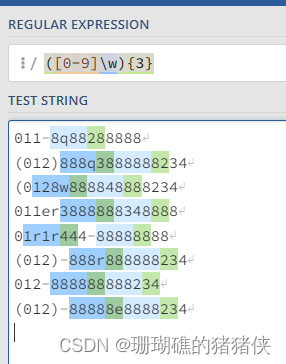
例如:([0-9]\w){3}
会匹配第一个为任意数字,第二个为任意字母或数字或下划线或汉字的两位数重复三次;
小括号的另一种用途是通过语法(?#comment)来包含注释。
例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)。
要包含注释的话,最好是启用“忽略模式里的空白符”选项,这样在编写表达式时能任意的添加空格,Tab,换行,而实际使用时这些都将被忽略。启用这个选项后,在#后面到这一行结束的所有文本都将被当成注释忽略掉。例如,我们可以前面的一个表达式写成这样。
九、反义
正则表达式中的反义(Negation)通常用于匹配不属于某个字符类或满足某个条件的字符。以下是一些使用反义的正则表达式示例:
1.匹配非数字字符:
使用 \D 来匹配任何非数字字符。例如,\D+ 匹配一个或多个非数字字符。
示例:Hello123 中,Hello 会被 \D+ 匹配。
2. 匹配非空白字符:
使用 \S 来匹配任何非空白字符。空白字符包括空格、制表符、换页符等。
示例:Hello World 中,Hello 和 World 会被 \S+ 匹配(假设中间有两个空格)。
3. 匹配非单词字符:
使用 \W 来匹配任何不是字母、数字、下划线或汉字的字符。
示例:Hello_World! 中,_ 和 ! 会被 \W 匹配。
4. 匹配非单词边界:
使用 \B 来匹配不是单词开头或结束的位置。
示例:在 Hello-World 中,- 两侧的位置都是 \B 的匹配对象,因为它不是单词的开头或结束。
5. 匹配除了指定字符以外的字符:
使用 [^...] 来匹配除了方括号内字符以外的任何字符。
示例:[^aeiou] 匹配除了 a、e、i、o、u 以外的任何字符。
6. 排除某个模式:
使用 (?!...) (如果支持)来排除某个模式。这是一个否定的前瞻断言,表示后面不能跟着某个模式。
示例:(?!abc)\w+ 匹配不以 abc 开头的单词。
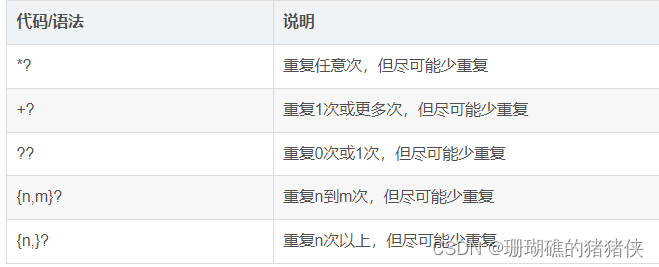
十、懒惰匹配和贪婪匹配
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
(?<= # 断言要匹配的文本的前缀
<(\w+)> # 查找尖括号括起来的内容
# (即HTML/XML标签)
) # 前缀结束
.* # 匹配任意文本
(?= # 断言要匹配的文本的后缀
<\/\1> # 查找尖括号括起来的内容
# 查找尖括号括起来的内容
) # 后缀结束a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
十、其他
上边已经描述了构造正则表达式的大量元素,但是还有很多没有提到的东西。下面是一些未提到的元素的列表,包含语法和简单的说明。
 我承认,我之前的说法可能给你带来了误解。我提及的‘10分钟’并非实际所需时间,而是为了鼓励你保持兴趣和耐心继续阅读。既然你已经深入阅读至此,这足以证明我的初衷已经达成。对于可能给你带来的任何困扰或疑惑,我深感抱歉,并诚挚地感谢你的理解和持续的关注。”
我承认,我之前的说法可能给你带来了误解。我提及的‘10分钟’并非实际所需时间,而是为了鼓励你保持兴趣和耐心继续阅读。既然你已经深入阅读至此,这足以证明我的初衷已经达成。对于可能给你带来的任何困扰或疑惑,我深感抱歉,并诚挚地感谢你的理解和持续的关注。”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









