









哈夫曼树
哈夫曼树又称最优二叉树,它是由 n 个带权叶子结点构成的所有二叉树中带权路径长度 WPL 最短的二叉树。
带权路径长度 WPL
设二叉树有 n 个带权叶子结点,从根结点到各叶子结点的路径长度与相应叶子结点权值的乘积之和称为 树的带权路径长度(Weighted Path Length of Tree,WPL)。
其计算公式如下:
W
P
L
=
∑
i
=
1
n
w
i
l
i
WPL=\sum_{i=1}^{n}w_il_i
WPL=i=1∑nwili
w
i
w_i
wi 表示二叉树的第
i
i
i 个结点的权值,
l
i
l_i
li 为从根结点到第
i
i
i 个结点的路径长度
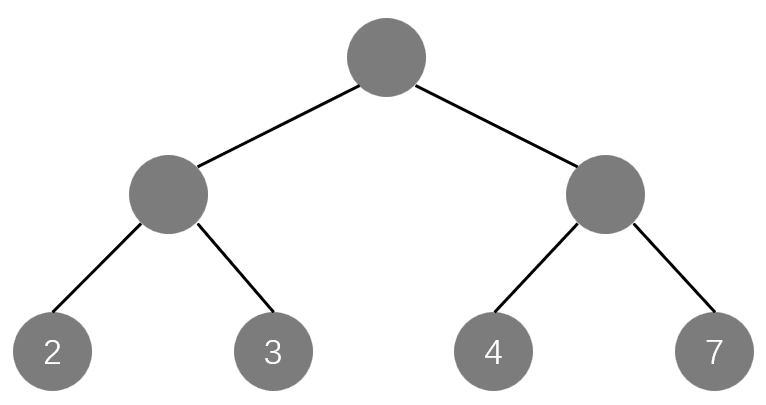
W
P
L
=
2
×
2
+
2
×
3
+
2
×
4
+
2
×
7
=
32
WPL=2\times2+2\times3+2\times4+2\times7=32
WPL=2×2+2×3+2×4+2×7=32
哈夫曼算法
我们需要的是 WPL 最小的带权叶子结点所构成的树,怎样能让 WPL 最小?
哈夫曼给出了一种算法,可以帮我们构造出这种树,因此称之为哈夫曼树。
算法步骤如下:
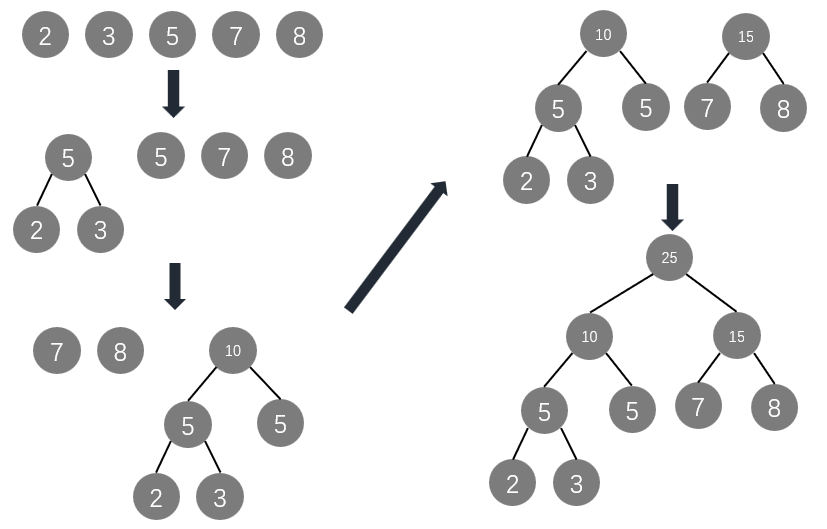
- 初始化:给定 n n n 个权值,构造 n n n 棵只有一个根结点的二叉树,构成一个二叉树集合 F F F
- 选取与合并:从 F F F 中选取根结点权值最小的两棵树,将它们根结点的权值相加并构造一个新的结点,让这两棵树作为新结点的左右子树
- 删除与加入:从 F F F 中删除上一步作为左右子树的两棵树,将新建立的二叉树加入到 F F F 中
- 重复 2, 3 两步,直到 F F F 中只剩一棵树,这棵树就是哈夫曼树
注意:对于同一组权值,构造出的哈夫曼树不是唯一的
例子:
哈夫曼编码
哈夫曼树具有叶结点权值越小,离根越远,叶结点权值越大,离根越近的特点,此外其仅有叶结点的度为0 ,其他结点度均为2。
因此我们可以利用这一特性对字符进行编码,对于使用频率较高的字符,其编码短一些,对于使用频率较低的字符,其编码可以长一些。
相较等长编码而言,使用哈夫曼编码对于使用频率不相等字符构造出一种 不等长编码,有助于获得更好的空间效率。
在设计编码时,要考虑解码的唯一性,如果一组编码中任一编码都不是其他任何一个编码的前缀,那么称这组编码为 前缀编码,其保证了编码被解码时的唯一性。哈夫曼树可用于构造 最短的前缀编码,即哈夫曼编码。
基本步骤如下:
- 输入一段字符序列,统计每个字符出现的频率(频数)
- 以频率(频数)作为权值构建哈夫曼树
- 通过从根结点到每一个叶子结点的路径进行编码,向左的路径记为 “0”,向右的路径记为 “1”
例子:
假设已经统计出 A, B, C, D, E, F 这 5 个字母的频数为 2, 3, 5, 7, 8
且以此构建出哈夫曼树如下
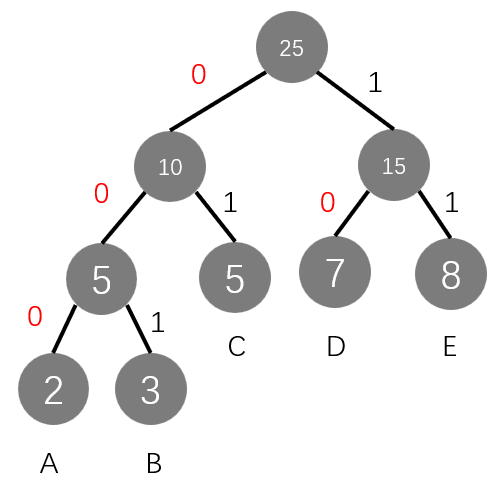
其编码为:
| A | B | C | D | E |
|---|---|---|---|---|
| 000 | 001 | 01 | 10 | 11 |
代码实现
框架
- 对于哈夫曼树,我们将其设计成二叉链表,编码的时候可以由上至下遍历二叉树,每个结点还包括一个权值和其对应的字符(除叶子结点以外都为
\0) - 对于用来存储树的集合 F F F ,因为经常要从中选取根结点weight值最小的树,所以我们选取 小堆 这个数据结构
- 使用哈希表来存储编码和字符的映射
struct HTNode
{
HTNode(unsigned int w, char ch = '\0')
: _weight(w)
, _ch(ch)
, _LChild(nullptr)
, _RChild(nullptr)
{}
unsigned int _weight;
char _ch;
HTNode* _LChild;
HTNode* _RChild;
};
class HuffmanTree
{
private:
// 仿函数,按weight,建小堆
struct CmpByWeight
{
bool operator()(const HTNode* p1, const HTNode* p2)
{
return p1->_weight > p2->_weight;
}
};
public:
private:
priority_queue<HTNode*, vector<HTNode*>, CmpByWeight> _HuffmanTree; // 小堆,存森林
unordered_map<string, char> _HuffmanCode; // 哈希表,存编码和相应字符的pair
};
统计字符频数与构建哈夫曼树
使用哈希表统计每个字符出现的次数:
unordered_map<char, unsigned int> StatisticalFrequency(const string& s)
{
unordered_map<char, unsigned int> tmp;
for (auto& e : s)
{
++tmp[e];
}
return tmp;
}
首先构造叶子结点插入堆中,然后递归进行编码,将每个编码和其对应的字符存到 _HuffmanCode 中:
void _HuffmanCoding(HTNode* root, string& tmp)
{
if (root->_LChild == nullptr && root->_RChild == nullptr)
{
_HuffmanCode[tmp] = root->_ch;
return;
}
_HuffmanCoding(root->_LChild, tmp += '0');
tmp.pop_back();
_HuffmanCoding(root->_RChild, tmp += '1');
tmp.pop_back();
}
// 创建哈夫曼树,生成哈夫曼编码
void CrtHuffmanTree(unordered_map<char, unsigned int>& frequency)
{
//插入叶子结点
for (auto& e : frequency)
{
_HuffmanTree.push(new HTNode(e.second, e.first));
}
//创建非叶子结点,建立哈夫曼树
while (_HuffmanTree.size() > 1)
{
// 分两次取出堆顶元素,构造新结点作为这两棵子树的父亲,并将新树入堆
HTNode* s1 = _HuffmanTree.top();
_HuffmanTree.pop();
HTNode* s2 = _HuffmanTree.top();
_HuffmanTree.pop();
HTNode* parent = new HTNode(s1->_weight + s2->_weight);
parent->_LChild = s1;
parent->_RChild = s2;
_HuffmanTree.push(parent);
}
// 递归,由上至下求哈夫曼编码
string tmp;
_HuffmanCoding(_HuffmanTree.top(), tmp);
}
构造与析构
void Destroy(HTNode* root)
{
if (root == nullptr) return;
Destroy(root->_LChild);
Destroy(root->_RChild);
delete root;
}
HuffmanTree(const string& s)
{
// 统计频数
auto&& m = StatisticalFrequency(s);
// 构建哈夫曼树并编码
CrtHuffmanTree(m);
}
~HuffmanTree()
{
Destroy(_HuffmanTree.top());
}
解码
void decode(const string& code)
{
string s;
int count = 0;
for (int i = 0; i < code.size(); ++i)
{
s += code[i];
auto&& it = _HuffmanCode.find(s);
if (it != _HuffmanCode.end())
{
cout << it->second;
++count;
s.clear();
}
}
if (!s.empty())
{
cout << "...输入的序列有误!" << endl;
printf("已成功解码 %d 个字符\n", count);
}
}
完整代码
完整代码将上述整合后,还增加了存储哈夫曼树和哈夫曼编码的文件操作。
#include <iostream>
#include <vector>
#include <string>
#include <queue>
#include <unordered_map>
#include <fstream>
using namespace std;
struct HTNode
{
HTNode(unsigned int w, char ch = '\0')
: _weight(w)
, _ch(ch)
, _LChild(nullptr)
, _RChild(nullptr)
{}
unsigned int _weight;
char _ch;
HTNode* _LChild;
HTNode* _RChild;
};
class HuffmanTree
{
private:
// 仿函数,按weight,建小堆
struct CmpByWeight
{
bool operator()(const HTNode* p1, const HTNode* p2)
{
return p1->_weight > p2->_weight;
}
};
void _PreOrder(HTNode* root, ostream& treeFile)
{
if (root == nullptr)
{
treeFile << '#' << endl;
return;
}
treeFile << root->_weight << ' ' << root->_ch << endl;
_PreOrder(root->_LChild, treeFile);
_PreOrder(root->_RChild, treeFile);
}
void _HuffmanCoding(HTNode* root, string& tmp)
{
if (root->_LChild == nullptr && root->_RChild == nullptr)
{
_HuffmanCode[tmp] = root->_ch;
return;
}
_HuffmanCoding(root->_LChild, tmp += '0');
tmp.pop_back();
_HuffmanCoding(root->_RChild, tmp += '1');
tmp.pop_back();
}
// 创建哈夫曼树,生成哈夫曼编码
void CrtHuffmanTree(unordered_map<char, unsigned int>& frequency)
{
//插入叶子结点
for (auto& e : frequency)
{
_HuffmanTree.push(new HTNode(e.second, e.first));
}
//创建非叶子结点,建立哈夫曼树
while (_HuffmanTree.size() > 1)
{
HTNode* s1 = _HuffmanTree.top();
_HuffmanTree.pop();
HTNode* s2 = _HuffmanTree.top();
_HuffmanTree.pop();
HTNode* parent = new HTNode(s1->_weight + s2->_weight);
parent->_LChild = s1;
parent->_RChild = s2;
_HuffmanTree.push(parent);
}
// 递归,由上至下求哈夫曼编码
string tmp;
_HuffmanCoding(_HuffmanTree.top(), tmp);
}
unordered_map<char, unsigned int> StatisticalFrequency(const string& s)
{
unordered_map<char, unsigned int> tmp;
for (auto& e : s)
{
++tmp[e];
}
return tmp;
}
void Destroy(HTNode* root)
{
if (root == nullptr) return;
Destroy(root->_LChild);
Destroy(root->_RChild);
delete root;
}
public:
HuffmanTree(const string& s)
{
// 统计频数
auto&& m = StatisticalFrequency(s);
// 构建哈夫曼树并编码
CrtHuffmanTree(m);
}
void decode(const string& code)
{
string s;
int count = 0;
for (int i = 0; i < code.size(); ++i)
{
s += code[i];
auto&& it = _HuffmanCode.find(s);
if (it != _HuffmanCode.end())
{
cout << it->second;
++count;
s.clear();
}
}
if (!s.empty())
{
cout << "...输入的序列有误!" << endl;
printf("已成功解码 %d 个字符\n", count);
}
}
// 打印并存文件
void Print(ostream& codeFile, ostream& treeFile)
{
// 存树
_PreOrder(_HuffmanTree.top(), treeFile);
// 存编码并打印
cout << "字符\t编码" << endl;
codeFile << "字符\t编码" << endl;
for (auto& e : _HuffmanCode)
{
cout << e.second << '\t' << e.first << endl;
codeFile << e.second << '\t' << e.first << endl;
}
}
~HuffmanTree()
{
Destroy(_HuffmanTree.top());
}
private:
priority_queue<HTNode*, vector<HTNode*>, CmpByWeight> _HuffmanTree; // 小堆,存森林
unordered_map<string, char> _HuffmanCode; // 哈希表,存编码和相应字符的pair
};
int main()
{
// 打开文件
ofstream codeFile("code.txt");
ofstream treeFile("tree.txt");
// 输入字符序列
string s;
cout << "请输入一串字符序列:" << endl;
cin >> s;
// 构建哈夫曼树,生成编码打印并存文件
HuffmanTree ht(s);
ht.Print(codeFile, treeFile);
//输入序列以解码
cout << "\n请输入01序列进行解码:" << endl;
cin >> s;
ht.decode(s);
return 0;
}
















 2249
2249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











