






文章信息:
作者:
代码:
论文地址:
核心思想
现有的梯度攻击是对训练集攻击,只有当训练集大小超过50%才会对全局有效
摘要
最近的研究表明,结构扰动在降低图神经网络(GNN)在半监督节点分类(SSNC)任务中的准确性方面具有显著效果。然而,基于梯度的方法为何具有破坏性尚未深入探讨。在本研究中,我们发现了一个有趣的现象:对抗边在图中并不是均匀分布的,大多数扰动是在中毒攻击中围绕训练节点生成的。结合这一现象,我们从数据分布的角度解释了基于梯度的攻击方法的有效性,并重新审视了SSNC中的中毒攻击和规避攻击。从这一新视角出发,我们在经验和理论上讨论了一些其他攻击趋势。基于分析,我们提供了九条关于攻击和防御的实用建议,并利用这些建议改进现有的攻击和防御方法。此外,我们设计了一种快速攻击方法和一种自训练防御方法,这些方法优于现有的最先进方法,并且能够有效扩展到像ogbn-arxiv这样的大型图。我们通过在四个基准数据集上的广泛实验验证了我们的主张。
Introduction
图神经网络(GNNs)近年来在众多基于图的任务中得到了广泛研究,主要集中在半监督节点分类(SSNC)任务上。证据表明,GNNs 对对抗性结构扰动非常脆弱。攻击者可以通过不显著地修改图结构来显著降低分类准确性。大多数攻击方法都是基于梯度的,将邻接矩阵视为参数,并通过攻击损失的梯度对其进行修改。然而,我们仍然缺乏一个通用框架来解释它们的有效性。
我们认为,基于梯度的方法的破坏性源于它们有效增加训练节点和测试节点之间的分布偏移能力。为了更详细地说明这一点,我们首先提出一个有趣的现象:基于梯度的方法生成的恶意修改在图中并不是均匀分布的。大多数修改集中在训练节点周围,而图的最大部分(测试-测试部分)几乎没有受到影响。具体来说,我们应用了两种代表性的攻击方法,MetaAttack 和 PGD。数据划分遵循 10%/10%/80%(训练/验证/测试)的比例。此外,我们发现只有 MetaAttack 能够根据训练集的大小自适应调整攻击倾向(攻击训练节点或测试节点),这种适应性使得 MetaAttack 在数据划分的情况下优于其他方法。这启发我们从另一个角度研究攻击方法的有效性,即分布偏移,这同样考虑了训练集和测试集之间的差异。这引出了以下挑战:
如何在图对抗攻击场景中表述分布偏移?
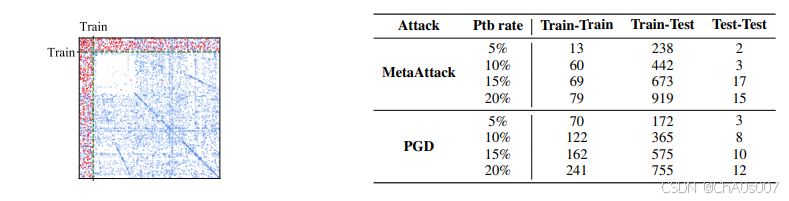
左侧:被 MetaAttack 攻击的 Cora 数据集的邻接矩阵,其中蓝色点表示原始边,红色点表示对抗边。绿色虚线是训练节点和测试节点的边界。右侧:在不同扰动率下,Cora 数据集中对抗边的位置统计。Train-Train 表示扰动边连接两个来自训练集的节点。Train-Test 和 Test-Test 也遵循相同的规则。
为了解答上述问题,本文首先澄清了主流领域(例如图像分类)和 SSNC 中攻击之间的差异:(1)半监督节点分类 是一个传导性任务,攻击者可以访问训练节点和测试节点;(2)图中的节点既具有特征又具有结构信息,而其他数据类型可能仅包含特征,例如图像有像素或文本有单词。考虑到这两个差异,我们对图对抗攻击中的分布偏移进行了形式化,并理论上证明了围绕训练节点的扰动有效地扩大了分布偏移。我们探索了影响对抗边位置的因素,如代理损失和梯度获取。
利用分布偏移的表述,之前工作中一些未解释的现象变得清晰。例如,为什么基于梯度的攻击方法显著优于启发式的同质性方法 DICE?为什么大多数修改是插入而不是删除?我们将从理论和经验两个方面进行分析。
基于上述分析,我们提出了若干实用建议,以改进和指导图上的攻击和防御。为了验证这些建议,我们进行了广泛的相应实验。此外,我们设计了一种快速且简单的启发式攻击方法,基于增加分布偏移,其性能与基于梯度的方法相当,并且能够有效扩展到像 ogbn-arxiv 这样的大型图。我们还提供了一种基于自训练的方法,以提高 GNN 的鲁棒性。代码可在 https://github.com/likuanppd/STRG 获得。
我们的主要贡献总结如下:
- 我们发现一个有趣的现象,即扰动在图上分布不均,这激励我们从数据分布的角度重新审视图对抗攻击,并定义图攻击场景中的分布偏移。
- 我们探索了一些未解释的现象,并从数据分布的角度提供相关的理论证明。我们认为,图攻击的有效性本质上来自于增加分布偏移,这是对抗攻击的根本性质。
- 我们提供了一些实用建议,以指导图上的攻击和防御。我们进行了广泛的实验以支持我们的主张,并验证这些技巧的有效性。实现细节和数据集的统计信息见附录 A.1
符号说明
设 表示一个无向、无权重的图,包含 N 个节点,其中 V 和 E (不包含自环)分别是节点和边的集合。图的拓扑结构也可以表示为一个对称邻接矩阵
。所有节点的原始特征可以总结为矩阵
。节点v_i 的一阶邻域表示为 N_i ,包括节点 v_i 本身。此外,所有节点的标签表示为 y 。每个节点与标签
相关联,其中
。我们用
表示一个 GNN,
表示参数。
半监督节点分类(SSNC)。在本文中,我们研究 GNN 在半监督节点分类(SSNC)任务上的鲁棒性,其可以表述为:给定图 G、节点特征 X 和节点标签的子集 ,目标是学习一个函数
,将节点映射到标签集,以便能够预测未标记节点的标签。未标记节点的真实标签表示为 \( y_U \),相应的节点集合为 \( V_U \)。
图对抗攻击。在本文中,我们探讨 GNN 在 SSNC 中的鲁棒性,针对图结构进行灰盒非目标攻击。在这种设置下,攻击者拥有与防御者相同的数据,但防御模型及其训练权重是未知的。对抗攻击可以分为两类,即中毒(训练时)攻击和规避(测试时)攻击。攻击者的目标是找到一个最优的扰动图,以尽可能降低分类器的整体性能,这可以表述为:
其中 \( \hat{A} \) 是扰动图 \( \hat{G} \) 的邻接矩阵,\( \Phi(A) \) 是满足不可察觉约束的邻接矩阵集合:,其中 \( \Delta \) 是最大扰动率。 \( L_{atk} \) 通常为 \( -L(f_\theta^*(\hat{A}, X)_U, \hat{y}_U) \) 或 \( -L(f_\theta^*(\hat{A}, X)_L, y_L) \),其中 \( \hat{y}_U \) 是由代理分类器预测的未标记节点的伪标签。为简化符号,我们分别称它们为
和
。
是代理 GNN 的参数,在规避和中毒攻击中是不同的。在规避攻击中,它是固定的,并在干净图上训练,但在中毒攻击中,它可以随着图的逐渐污染而反复重新训练。
基于梯度的攻击方法的关键在于将邻接矩阵视为参数,并通过攻击损失的梯度修改图的结构。
图结构攻击新思考
对抗边的位置
为了更好地理解图的哪个部分受到扰动,我们提出了一个意图分数(IS)来量化对抗边在图上的分布。由于 GNN 模型是置换不变的,因此我们可以调整节点索引,然后将邻接矩阵分割成以下形式:
其中 \( A_1 \in \mathbb{R}^{N_1 \times N_1} \),\( A_2 \in \mathbb{R}^{N_1 \times N_2} \),\( A_3 \in \mathbb{R}^{N_2 \times N_2} \),\( A_1 \) 是连接两个训练节点的边的矩阵,\( A_2 \) 是表示训练节点与测试节点之间边的矩阵,\( A_3 \) 是表示两个测试节点之间边的矩阵。\( N_1 \) 和 \( N_2 \) 分别是训练集和测试集中的节点数量。
IS 可以描述攻击算法更倾向于在邻接矩阵的哪个部分(\( A_1 \)、\( A_2 \) 或 \( A_3 \))生成对抗边。它可以表述为:
其中 \( E \) 是原始边集,\( \tilde{E} \) 表示攻击模型插入或删除的边,\( i \) 表示邻接矩阵的部分。IS 可以展示邻接矩阵中扰动的密度(见表 1、表 4 和图 5)。
表 1 显示了在不同数据划分下,使用两种中毒方法(MetaAttack 和 PGD)攻击 Cora 数据集的结果。MetaAttack 会根据训练集的大小自适应调整攻击倾向。当训练集较小时,算法倾向于修改训练节点周围的局部结构。随着训练集规模的增大,\( IS_3 \) 增加,意味着对抗边更可能在测试节点周围生成。当训练集大小为 50% 时,所有的 IS 都接近 1,同时对抗边在图上的分布几乎是均匀的。更多其他攻击方法及更多数据集的结果见附录 A.2 中的表 4。
我们发现只有 MetaAttack 具有这样的适应性,这使得它在中毒攻击中极为有效。其他代表性的基于梯度的攻击方法,如 PGD 和 FGSM,将始终专注于修改训练节点的局部结构,而不考虑训练集的大小。这种适应性本质上在生成攻击时区分了训练节点和测试节点。这促使我们从另一个视角研究这个问题,即同样考虑训练集和测试集之间的差异——分布偏移。
图攻击中的分布偏移
当训练分布与测试分布相距较远时,机器学习模型无法良好表现。直观上,训练集越小,训练分布越容易受到扰动。这些基于梯度的方法的破坏力可能源于它们有效地增加了分布偏移。我们首先需要在图对抗攻击中形式化分布偏移。
与其他领域的攻击(如图像分类)不同,在 SSNC 中形式化分布偏移时应考虑结构信息。我们假设所有节点特征都是从 \( p(x|y) \) 中采样的,并定义一个社区特征以考虑结构信息:
并假设任意节点 \( i \) 的社区特征遵循分布:
一阶邻域在结构信息中起着最重要的作用,因此我们在这里不考虑高阶邻域。所有社区特征和相应标签可以视为从干净图上的联合分布 中采样的。在图对抗攻击中,有三个关键分布——
和分类器
。在干净图中,我们假设
和
与真实分布
相同。在扰动图中,我们考虑攻击结构作为扰动相应分布。具体来说,我们将训练和测试节点的结构变化视为这些节点是从偏置的 \( p_{train} \) 和 \( p_{test} \) 中采样的。
SSNC 是半监督的。攻击者可以修改整个图结构,包括训练和测试节点。SSNC 与图像分类之间的区别在于,\( p_{train} \) 和 \( p_{test} \) 可以同时受到扰动。
意识到这一差异至关重要。例如,在图像中毒攻击中,攻击者只能扰动训练数据以使模型偏置。相比之下,在图的中毒攻击中,攻击者可以扰动测试数据,使无偏模型在偏置数据上进行测试。
扰动后,\( p_{train} \) 和 \( p_{test} \) 可能与真实分布 \( p(\tilde{x}, y) \) 不同,这种差异可能导致分布偏移。通过简单的因式分解,我们可以写成:
在结构攻击的设定中,标签不会翻转,因此我们假设 \( p(y) \) 在所有分布中是共享的。当由于结构扰动而导致 \( p_{train}(\tilde{x}|y) \) 和 \( p_{test}(\tilde{x}|y) \) 不同时,分布偏移就会出现,因此我们将图对抗攻击中的分布偏移定义为:
本质上,攻击是为了增加分布偏移,但在中毒攻击和规避攻击中,具体扰动 \( p_{train}(\tilde{x}|y) \) 或 \( p_{test}(\tilde{x}|y) \ 是不同的。
对于规避攻击,扰动 \( p_{train} \) 几乎是无效的。分类器已经训练完成,可以视为无偏模型。在训练节点上浪费有限的修改是不明智的。
对于中毒攻击,从分布的角度来看,攻击训练集和测试集的含义是不同的。攻击训练集是以某种方式扰动 \( p_{train}(\tilde{x}|y) \),使得分类器 \( p_\theta(y|\tilde{x}) \) 拟合一个偏置分布。另一方面,在中毒攻击中扰动测试集类似于规避攻击的情况。模型在干净数据上训练良好,并在偏置分布上进行测试。我们的实证结果表明,如果训练集的大小较小,基于梯度的方法倾向于扰动训练节点的局部结构。我们推测,这是因为在 SSNC 中,训练集越小,攻击训练节点结构的效果越显著(定理 4.1,证明见附录 A.3)。
假设1
我们考虑一个图 \( G \),其中每个节点 \( i \) 具有特征 \( x_i \in \mathbb{R}^d \) 和标签 \( y_i \in \{0, 1\} \)。我们假设 (1) \( G \) 是 \( k \)-正则的;(2) 任意节点 \( i \) 的特征是从与其标签相关的正态分布 中采样的,并且与其他节点独立。\( \Lambda \) 是一个对角矩阵,对于类别 0 和 1 是相同的;(3) 图是一个同质图。 同质比为 \( h \),这意味着每个节点连接
个具有相同标签的节点,并且
。
定理 1
考虑一个遵循假设 4.1 的图 \( G \)。扰动率为 \( \Delta \),训练集大小为 \( t \)。训练集的大小越小,均匀插入异质边(连接两个不同标签的节点)到训练集中造成的分布偏移越大。MetaAttack 在中毒攻击中的成功(如表 4 所示)可以归因于同样的原因。它可以自适应地调整 IS,以便在训练集较小的时候攻击训练集,但随着训练集大小的增加而改变攻击测试集。值得注意的是,MetaAttack 的性能随着训练集的增加呈现出先下降后上升的趋势,因此这种策略可以有效地扩大分布偏移。
代理损失和梯度计算的影响
在实施攻击算法时,有两个因素影响对抗边的分布:(1)代理损失和(2)梯度的获取方式。Ma 等人(2020);Geisler 等人(2021)研究了各种代理损失对攻击性能的影响,如交叉熵(CE)、Carlini-Wagner(CW)、非目标 CE 等。与他们不同,我们关注的是用于计算损失的节点问题。 和
是两种广泛使用的损失。我们发现它们导致不同的攻击倾向。使用 \( L_{train} \) 和 \( L_{self} \) 的攻击方法将分别专注于训练和测试节点。此外,MetaAttack 是一个特殊情况,因为它能够自适应调整对抗边的位置。我们发现这种适应性源于其计算梯度的方式,即元梯度。
Ltrain 或 Lself 的影响
表 5 显示了使用 Ltrain 或 Lself 时 PGD 的攻击倾向和性能。我们仅提供 Cora 数据集的结果,但在其他常用的 SSNC 数据集上也观察到了类似的结果。Ltrain 会使攻击算法倾向于攻击训练节点,而 Lself 则使其攻击测试节点。
表 5:在 10% 扰动下,Cora 上对抗边的定位统计。Num 表示对应区域中的对抗边数量。Evasion 和 Poison 是 GCN Kipf & Welling (2017) 在规避和中毒攻击下的对抗准确率。我们将更强的攻击用粗体突出显示。

(IS1,train-train,IS2,train-test;IS3,test-test.
Evasion,先训练,后攻击;Poison,先攻击后训练)
Ltrain 关注训练节点的损失,这主要与这些节点的局部结构有关。因此,在计算梯度 时,仅会修改与训练节点相关的邻接矩阵部分,即 Train-Train 和 Train-Test。PGDtrain 在中毒攻击中有效,但在规避攻击中失败。这一结果是预期的,因为 ptrain 受到良好扰动,而 ptest 几乎保持不变。Train-Test 中有一些边,但图的最大部分,即 Test-Test,几乎没有变化。
Lself 利用未标记节点的伪标签计算损失,因此大多数修改围绕未标记节点进行。尽管 PGDself 在规避攻击中似乎有效,但在中毒攻击中的准确度下降并不如 PGDtrain 明显。我们认为主要有两个原因:(1)测试集远大于训练集,因此相同的扰动在 ptest 中带来的变化小于在 ptrain 中的变化。(2)我们使用交叉熵损失进行这些实验。Geisler et al. (2021) 表明,交叉熵损失使算法主要攻击已经被错误分类的节点。这种攻击在中毒攻击中是有效的,并且可以进一步偏向模型。然而,在规避攻击中,攻击错误分类的节点并不会导致准确度下降。
另一个使用 Lself 的例子是 PR-BCD Geisler et al. (2021),这是一种新颖的规避攻击。我们在表 6 中展示了其在 Citeseer 上攻击的扰动位置统计。可以看到,所有扰动都是围绕测试节点生成的,从而导致有效的性能。
梯度计算
MetaAttack 是一个特殊案例,因为它能够调整对抗边的分布。即使在今天,许多从业者仍然认为它是小规模图上的中毒攻击的最先进方法。根据定理 4.1,这种适应性使得 MetaAttack 倾向于攻击在 ptrain 和 ptest 中更容易受到扰动的分布。换句话说,它识别出显著增加分布偏移的结构修改。
我们发现这种适应性来自于其计算梯度的方式。让我们回顾一下 Zügner & Günnemann (2019) 中表达的元梯度:
其中 \(T\) 是通过普通梯度下降获得最优参数的训练步数,学习率为 \(\alpha\)。在其他基于梯度的方法中,参数 \(\theta\) 通常是固定的且与计算梯度 无关(Xu et al. (2019a); Wu et al. (2019))。然而,在 MetaAttack 中,\(\theta\) 会随着图的逐渐污染而迭代重新训练,并且会考虑相对于邻接矩阵的导数。
MetaAttack 的有效性和适应能力源于这种梯度计算方法。如果参数在梯度计算中是固定的或与之脱离,MetaAttack 的表现将类似于 PGD。表 7 显示了 Metaself、Metatrain、Detachself、Detachtrain、Fixself 和 Detachtrain 的性能。
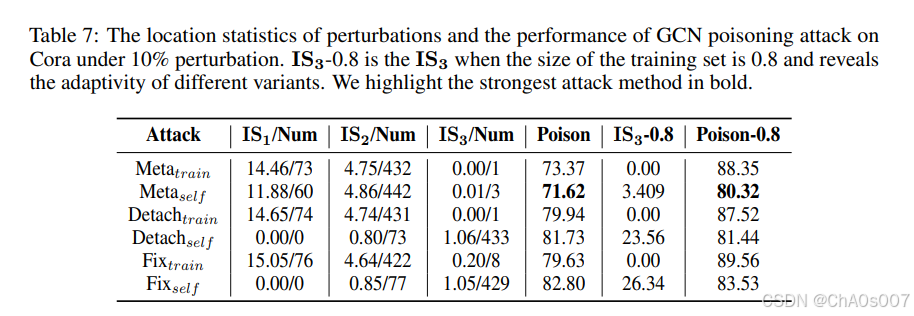 Detach 和 Fix 是 MetaAttack 的两个变体。前者将参数从元梯度计算中分离,后者在干净图中训练后固定参数。Metaself 是唯一一个始终攻击 ptrain 和 ptest 中更容易受到扰动的分布的变体。其他使用 Lself 的攻击方法仅会攻击测试节点,但当测试集较小时,Metaself 也会攻击训练节点。这是因为元梯度会通过公式 3 考虑训练过程,而这与训练节点相关。因此,训练节点的局部结构与元梯度计算有关。Detach 和 Fix 的表现类似于 PGD,其倾向性与代理损失密切相关,即 Lself 或 Ltrain。
Detach 和 Fix 是 MetaAttack 的两个变体。前者将参数从元梯度计算中分离,后者在干净图中训练后固定参数。Metaself 是唯一一个始终攻击 ptrain 和 ptest 中更容易受到扰动的分布的变体。其他使用 Lself 的攻击方法仅会攻击测试节点,但当测试集较小时,Metaself 也会攻击训练节点。这是因为元梯度会通过公式 3 考虑训练过程,而这与训练节点相关。因此,训练节点的局部结构与元梯度计算有关。Detach 和 Fix 的表现类似于 PGD,其倾向性与代理损失密切相关,即 Lself 或 Ltrain。
正如预期的那样,Metaself 在数据划分方面优于所有变体。值得注意的是,当训练集较小时,使用 Ltrain 的变体通常表现更好,而使用 Lself 的变体在测试集较小时则更具破坏性。
**不同的代理损失**
为了确保这种倾向不是由特定类型的损失引起的,我们探讨了 Graph Attack 中其他两种损失的影响,包括 Carlini-Wagner 损失(Xu et al. (2019a)):
和掩蔽交叉熵 MCE(Geisler et al. (2021)):
其中 \(c^*\) 是真实标签,\(V^+\) 表示已正确分类的节点。对于 CW 和 MCE,我们也可以根据用于计算损失的节点将其划分为 Lself 和 Ltrain。
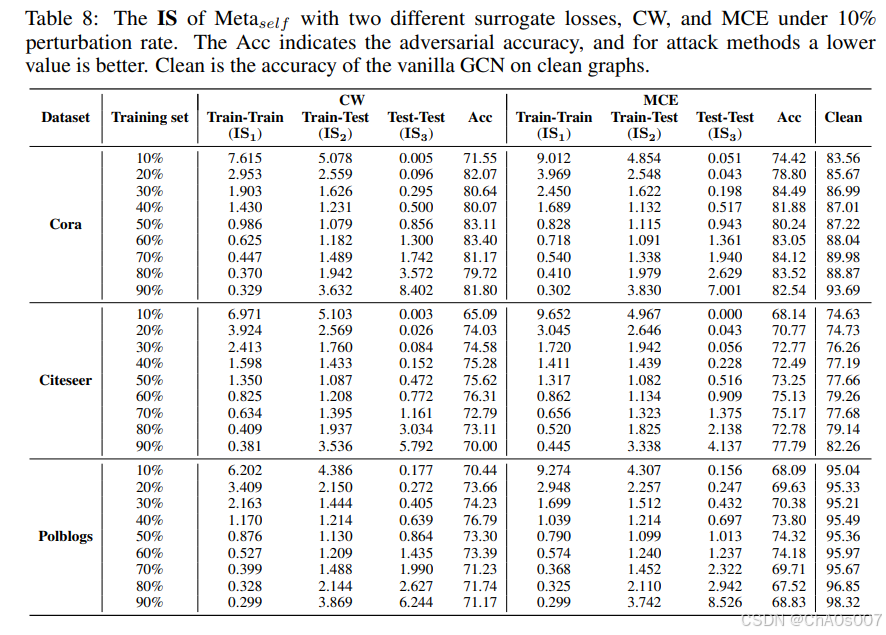 在表 8 中,我们展示了 Metaself 使用 CW 损失和 MCE 损失的 IS。Metaself 使用 CW 和 MCE 也可以根据训练集的大小调整扰动的分布,这与 CE 损失一致。结合所有结果,我们得出结论,影响对抗边分布的关键在于用于计算损失的节点,而不是代理损失的类型。
在表 8 中,我们展示了 Metaself 使用 CW 损失和 MCE 损失的 IS。Metaself 使用 CW 和 MCE 也可以根据训练集的大小调整扰动的分布,这与 CE 损失一致。结合所有结果,我们得出结论,影响对抗边分布的关键在于用于计算损失的节点,而不是代理损失的类型。
Lself 中的伪标签
使用伪标签的攻击与使用真实标签的攻击行为相似(见表 9;Meta-true 意味着 Meta-self 使用真实标签生成扰动,而不是伪标签)。
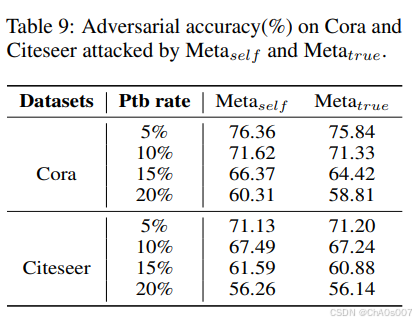 我们猜测这是因为,在同质图中,伪标签通常是准确的。因此,使用 Lself 的攻击将集中在修改测试节点的局部结构上,以使预测远离真实标签。在许多情况下,测试集的大小相对较大,因此很难通过修改测试结构来增加分布偏移,依据定理 4.1。这种情况下,像 PGDself 这样的算法会失败。
我们猜测这是因为,在同质图中,伪标签通常是准确的。因此,使用 Lself 的攻击将集中在修改测试节点的局部结构上,以使预测远离真实标签。在许多情况下,测试集的大小相对较大,因此很难通过修改测试结构来增加分布偏移,依据定理 4.1。这种情况下,像 PGDself 这样的算法会失败。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









