






文章信息
Published in:Proceedings of the 35th International Conference on Machine Learning, PMLR, 2018.
作者:Hanjun Dai, Hui Li, Tian Tian, Xin Huang, Lin Wang, Jun Zhu, Le Song
核心思想
本文提出了四种核心的图结构攻击方式,还量化了攻击者的攻击手段,包括以下三类:
- 白盒攻击(WBA):在这种情况下,攻击者可以访问目标分类器的任何信息,包括预测、梯度信息等。
- 实际黑盒攻击(PBA):在这种情况下,只能获得目标分类器的预测。当可以访问预测置信度时,我们将此设置表示为PBA-C;如果只能获得离散的预测标签,我们将此设置表示为PBA-D。
- 限制黑盒攻击(RBA):这种设置比PBA更进一步。在这种情况下,我们只能对一些样本进行黑盒查询,并要求攻击者对其他样本进行对抗性修改。
根据攻击者可以从目标分类器获得的信息量,我们可以将上述设置排序为WBA > PBA-C > PBA-D > RBA。
攻击方式主要包括使用强化攻击(Qlearning)、随机攻击、梯度攻击和遗传算法,分别应用于不同的攻击能力场景。其使用场景及计算复杂度如下:
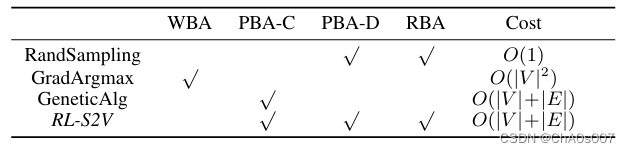
本文还是之后Zugner团队发表论文“Adversarial Attacks on Graph Neural Networks: A Comprehensive Review”的参考文献之一,Zugner团队所提出的Metattack方法来做全局攻击的思路就来自于本文所提出的梯度攻击。攻击方式非常类似,只不过本文攻击对象为原模型,Zugner所攻击对象为代理模型,攻击模型的损失函数亦有所改进。
问题描述
给定一个学习的分类器 f 和数据集中的一个实例 (G,c,y)∈D,图对抗性攻击者要求将图 G= (V,E) 修改为 G˜ = (V˜, E˜),使得分类器f在修改后的图上预测的准确率尽可能低。
当然图的修改亦有所限制,要求扰动边的数量不超过某个阈值
其中I是一个指示器,表明是否满足该条件N(G,b)表示b阶邻居节点
强化学习攻击器 RL-S2V
攻击的模型架构如下:
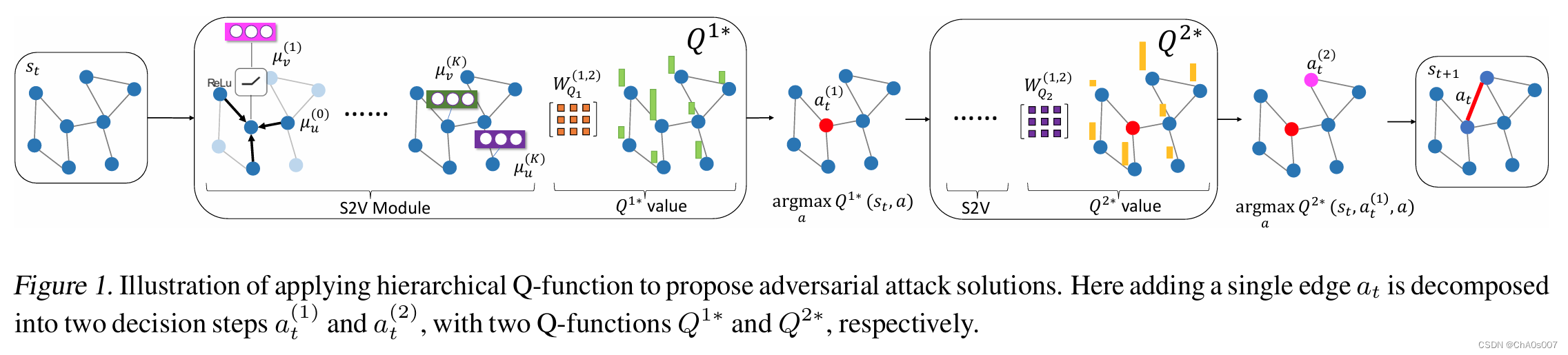
定义其动作空间及奖励函数如下:
Action 攻击者被允许添加或删除图中的边。因此,在时间步t执行的单个操作为
。然而,在
空间中执行操作过于昂贵。我们很快会展示如何使用分层操作来分解这个操作空间。
State 时间t的状态
表示为元组
,其中
是一个部分修改的图,其中一些边从 \(G\) 中添加或删除。
Reward 攻击者的目的是欺骗目标分类器。因此,只有在MDP的最后才会收到非零奖励,奖励为
在修改的中间步骤,不会收到任何奖励。也就是说,,对于所有 t = 1, 2, ..., m-1。在PBA-C设置中,如果可以访问目标分类器的预测置信度,我们也可以使用
作为奖励。
Terminal 一旦代理修改了m条边,过程就会停止。为简单起见,我们专注于具有固定长度的MDP。在较少的修改足够的情况下,我们可以简单地让代理修改虚拟边。
根据上述设置,从这个MDP中的一个示例轨迹将是:,其中
,对于所有
,且
。最后一步将有奖励
,对于所有
,中间奖励为零:r_t = 0
由于这是一个具有有限时间跨度的离散优化问题,我们使用Q学习来学习这些MDP。在我们的初步实验中,我们还尝试了优势演员评论等策略优化方法,但发现Q学习更稳定。因此,下面我们专注于使用Q学习进行建模。
本文将操作 分解为
,其中
。这样,单个边操作
就被分解为该边的两个端点。分层的Q函数可以建模如下:
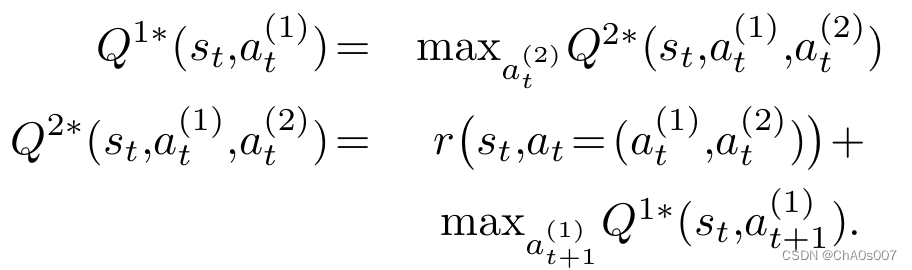
由于只有最后一步的奖励是非零的,并且修改预算 m 已给定,我们可以显式展开贝尔曼方程为:
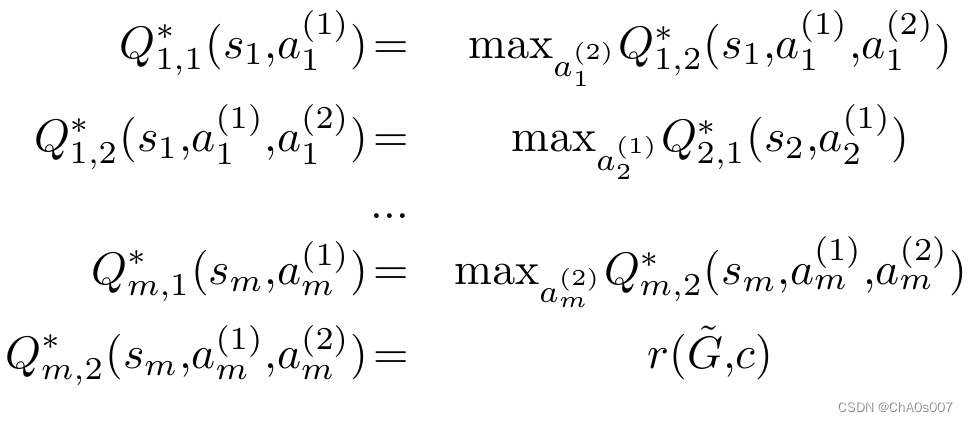
对于每一个节点学习一个Q函数代价是巨大的,所以本文关注一个更实际且具有挑战性的设置,即只学习一个 Q 函数。所学习的 Q 函数因此需要在所有 MDP 上泛化或迁移。
由于 Q 函数在状态图中对节点进行评分,因此使用 GNN 系列模型进行参数化是很自然的,以便学习一个具有泛化能力的攻击者。具体来说,Q1 被参数化为
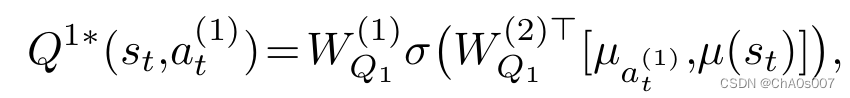
其中 是图
中节点
的嵌入,通过(structure2vec, S2V) 获得。
随机攻击
这是最简单的攻击方法,随机添加或删除图 G 中的边。当采样到边修改操作 a_t = (u,v) 时,我们只在其满足语义约束 I(·,·,·) 时才接受它.
梯度攻击
攻击结构如下:
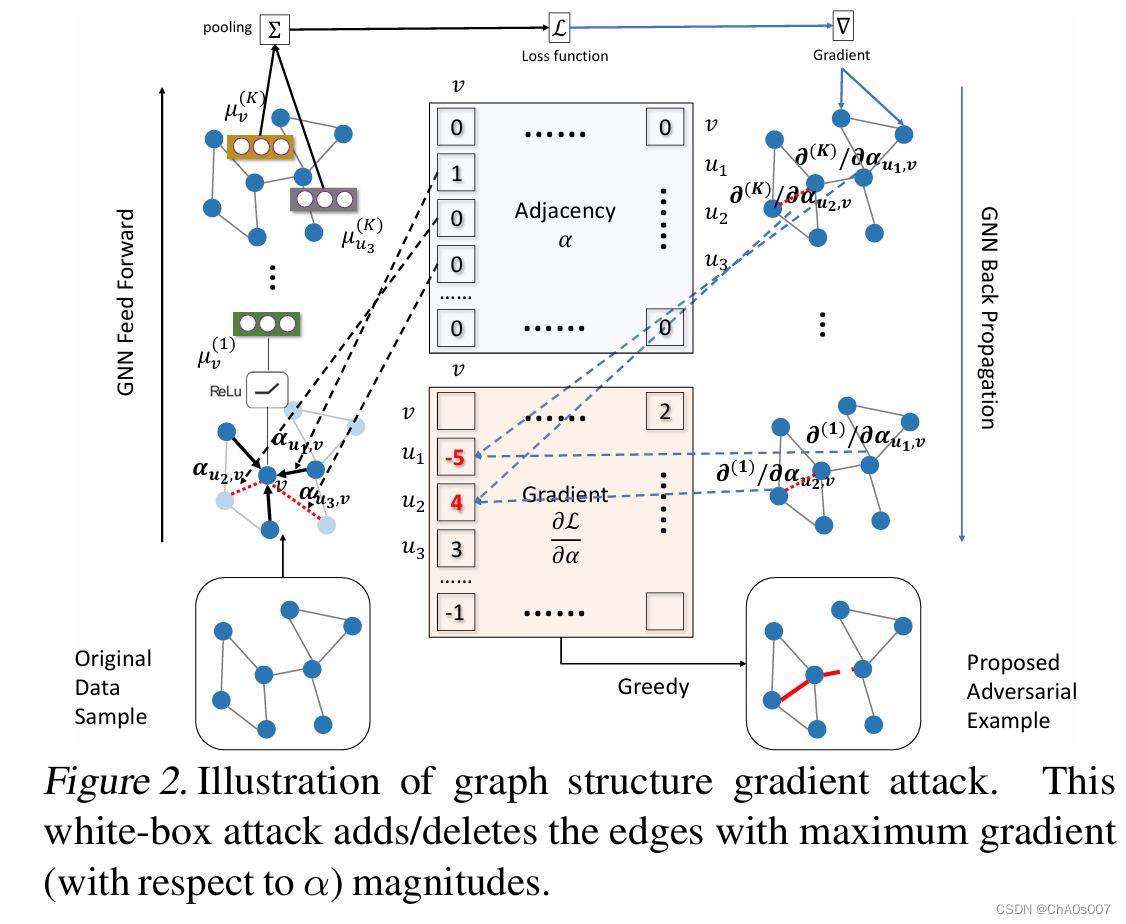
其核心思路就在于使用分类器f对于邻接矩阵求导,选取梯度最大的边进行修改,修改如下:

对比Metattack方法如下:
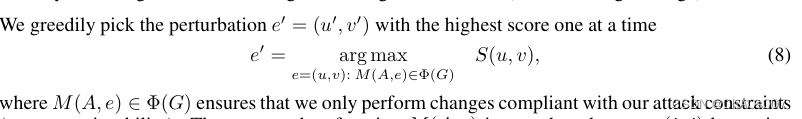
遗传算法
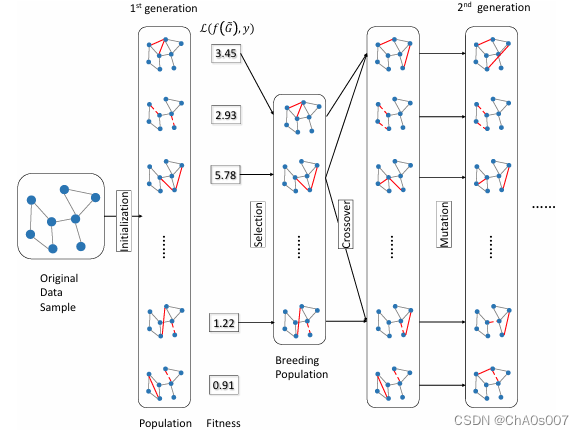
**种群**:种群指的是一组候选解决方案。我们将其表示为 \(P^{(r)} = \{\hat{G}^{(r)}_j\}_{j=1}^{|P^{(r)}|}\),其中每个 \(\hat{G}^{(r)}_j\) 是对原始图 \(G\) 的有效修改解。 \(r = 1, 2, ..., R\) 是代数的索引,\(R\) 是允许的最大进化次数。
**适应度**:当前种群中的每个候选解决方案将获得一个分数,用于衡量解决方案的质量。我们使用目标模型的损失函数 \(L(f(\hat{G}^{(r)}_j, c), y)\) 作为分数函数。一个好的攻击解应该增加这样的损失。由于适应度是一个连续分数,它在仅可访问分类标签的 PBA-D 设置中不可适用。
-**选择**:根据当前种群的适应度分数,我们可以进行加权采样或贪婪选择,以选择用于下一代的“繁殖”种群 \(P^{(r)}_b\)。
**交叉**:在选择 \(P^{(r)}_b\) 后,我们随机选择两个候选 \(\hat{G}_1, \hat{G}_2 \in P^{(r)}_b\),通过混合这两个候选的边进行交叉:
\[ \hat{G}' = (V, (E^{(1)} \cap E^{(2)}) \cup rp(E^{(1)} \setminus E^{(2)}) \cup rp(E^{(2)} \setminus E^{(1)})) \]
其中 \(rp(\cdot)\) 表示随机选择一个子集。
**变异**:变异过程也受到生物学启发。对于候选解 \(\hat{G} \in P^{(r)}\),假设修改的边为 \(\delta E = \{(u_t, v_t)\}_{t=1}^m\)。然后对于每条边 \((u_t, v_t)\),我们有一定的概率将其更改为 \((u_t, v')\) 或 \((u', v_t)\)。
种群大小 \(|P^{(r)}|\)、rp(·) 中使用的交叉概率、变异概率和进化次数 \(R\) 都是可以调整的超参数。由于适应度函数的限制,此方法只能在 PBA-C 设置中使用。此外,由于我们需要执行目标模型 \(f\) 以获取适应度分数,因此这种遗传算法的计算成本为 \(O(|V| + |E|)\),主要由 GNN 的计算成本组成。整体流程如图 3 所示。我们简单地称之为 GeneticAlg,因为它是一般遗传算法框架的一个实例。
实验结果
我们可以看到,尽管删除单个边是对图进行的最小修改之一,但在这些小图上,攻击率仍然约为10%,在Finance数据集中为4%。我们还进行了一项全面的攻击作为健全性检查,这是任何算法在攻击预算下都可以做到的最好的。如果允许两条边的修改,则分类器的准确率将降低到60%或更低。但是,考虑到图中的平均度不高,删除两条或更多的边将违反“小修改”约束条件。我们需要小心,只创建对抗样本,而不是实际更改该样本的真实标签。在这种情况下,GradArgmax表现得相当不错,这与图级攻击的情况不同。这里,相对于邻接矩阵的梯度不再是平均值,这使得更容易区分有用的修改。对于测试集II上的限制黑盒攻击,RL-S2V仍然学习到了一个能够泛化到未见样本的攻击策略。虽然在现实世界的数据集中我们没有金标分类器,但提出的对抗性样本很可能是有效的:(1)结构修改微小且在2跳内;(2)我们没有修改节点特征。
攻击效果如下:
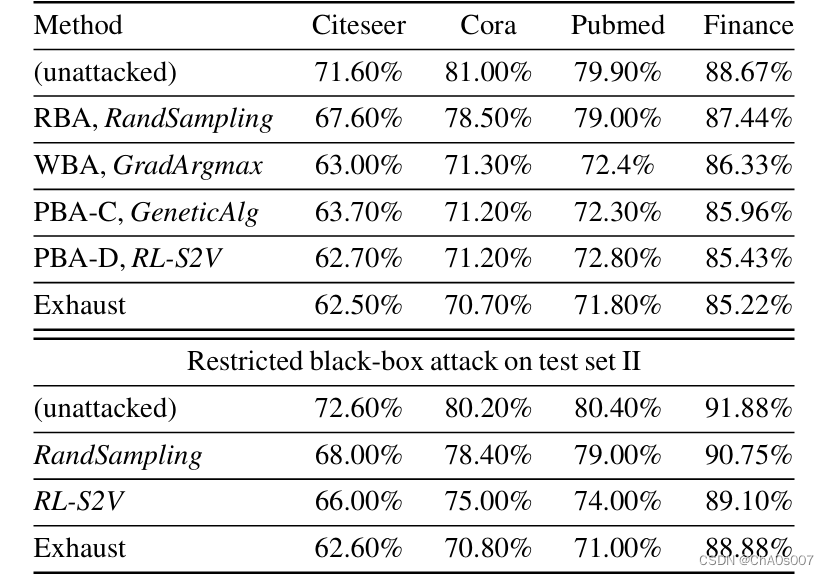
在表格的上半部分,我们报告了在各种设置和方法下,测试集I上的目标模型在攻击前/后的准确性。在下半部分,我们仅在RBA设置下报告了测试集II上的准确性。在这一部分中,仅能使用RandSampling和RL-S2V。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









