







Pandas数据结构
Series和DataFrame
series的数据结构,呃,不多说,直接看
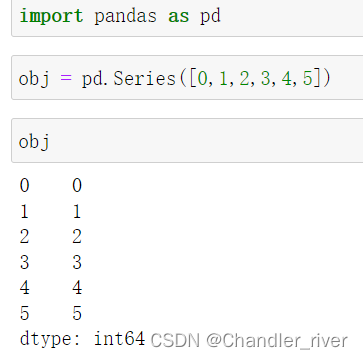
values表示值,index表示索引

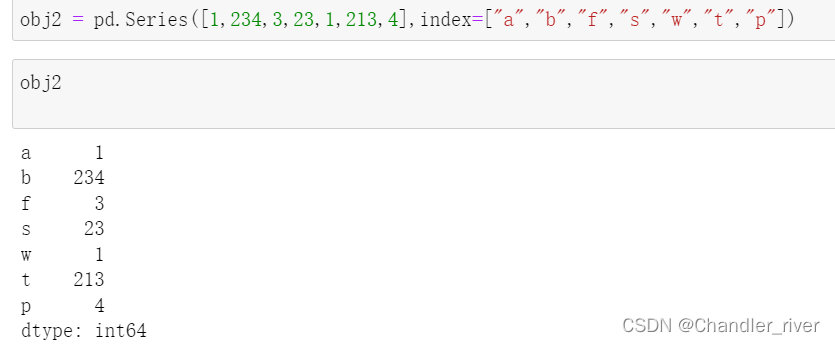
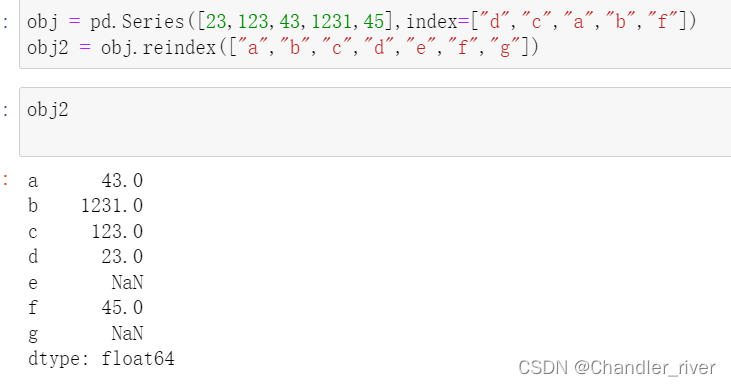
自主创建索引
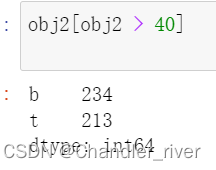
根据索引查看值

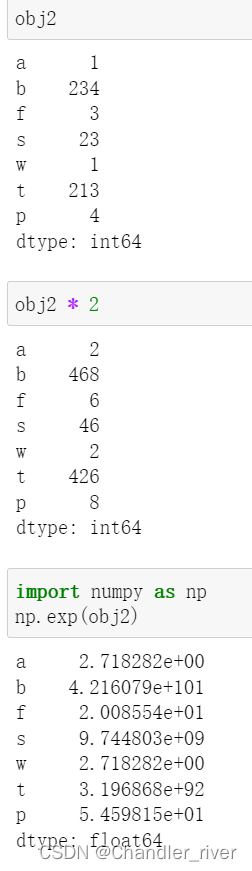
应用数学函数选择值
对整个数据表做操作
检查某元素是否再series里

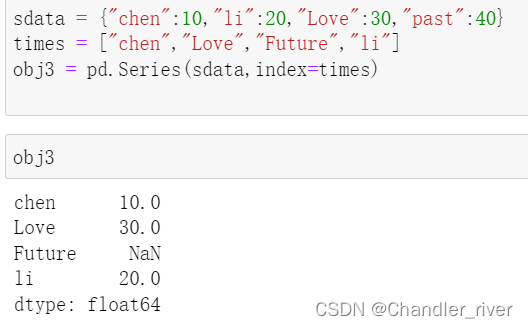
通过字典生成Series
index里有而原字典里没有的,以NaN替代,就是没有数据
index里没有的,也不会有
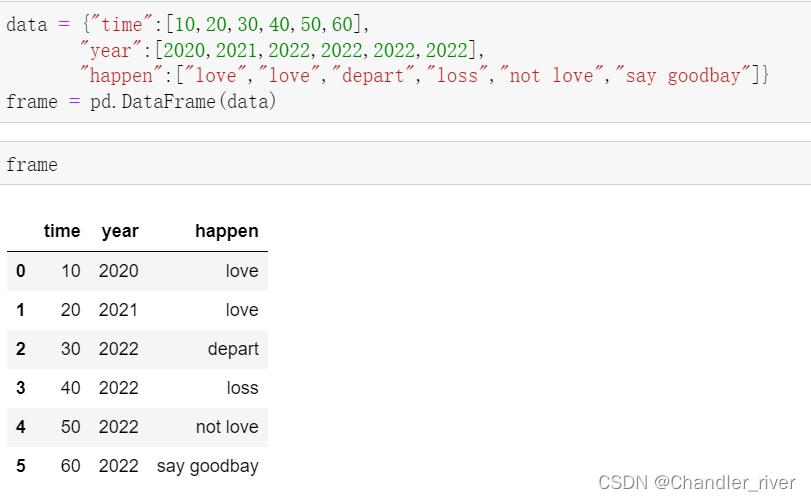
那么对于DataFrame呢
先创建一个试试:
用head方法,他会展示前5行

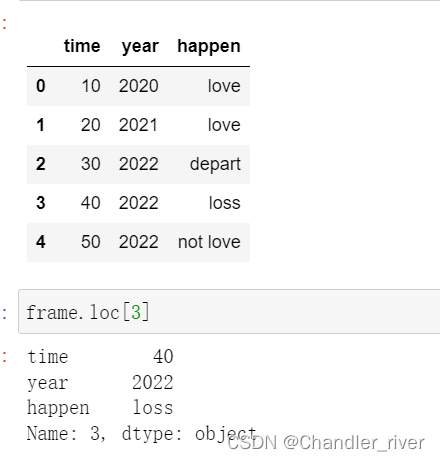
通过loc选取frame里的某一行
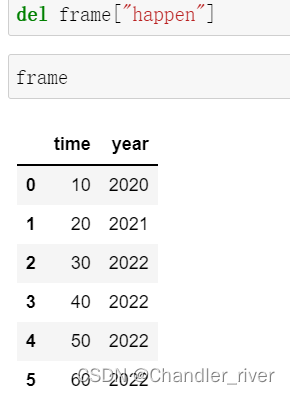
通过del删除一列
转置操作

基本功能
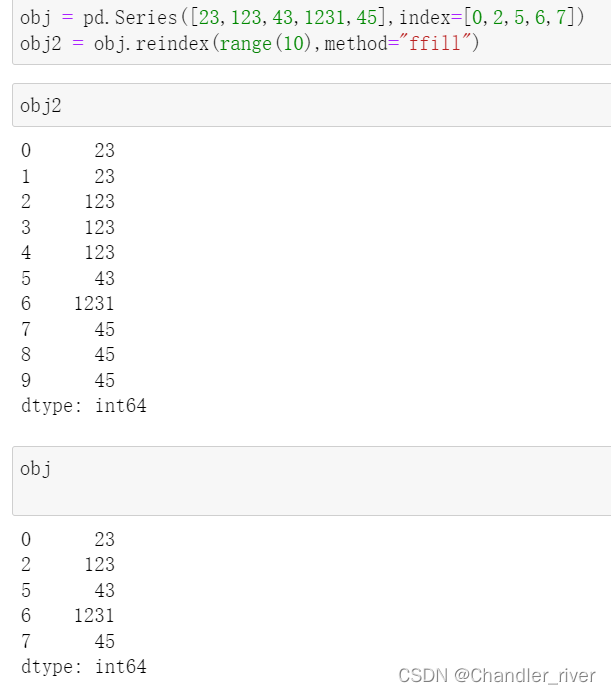
reindex重建索引
ffill在重建索引时插值
reindex方法的参数
| 参数 | 描述 |
| method | 插值方式 "ffill"向前填充 "bfill"向后填充 |
| fill_value | 通过重新索引引入缺失数据时使用的替代值 |
| limit | 向前/后填充时,所需填充的最大尺寸间隙 |
| tolerance | 所需填充的不精确匹配下的最大尺寸间隙 |
| level | 匹配MultiIndex级别的简单索引,否则选择子集 |
| copy | 为True 总是复制底层数据 False 那肯定是不复制的啦 |
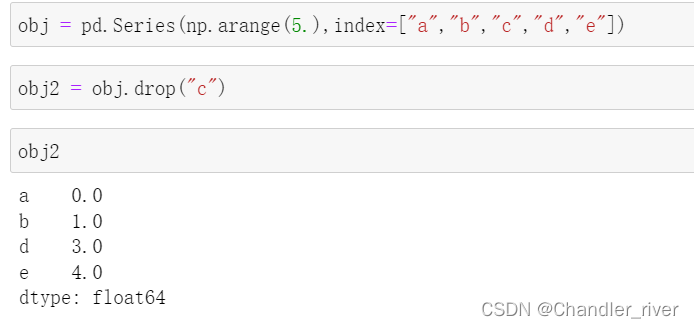
轴向上删除条目drop
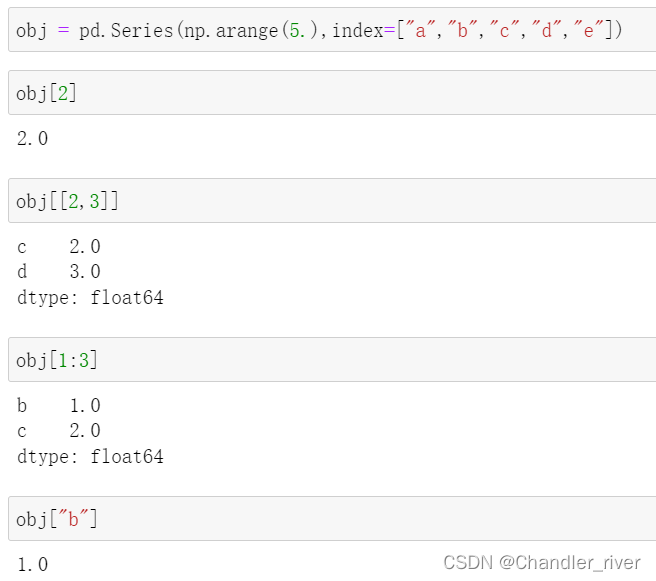
索引,选择与过滤
描述性统计的概述和计算
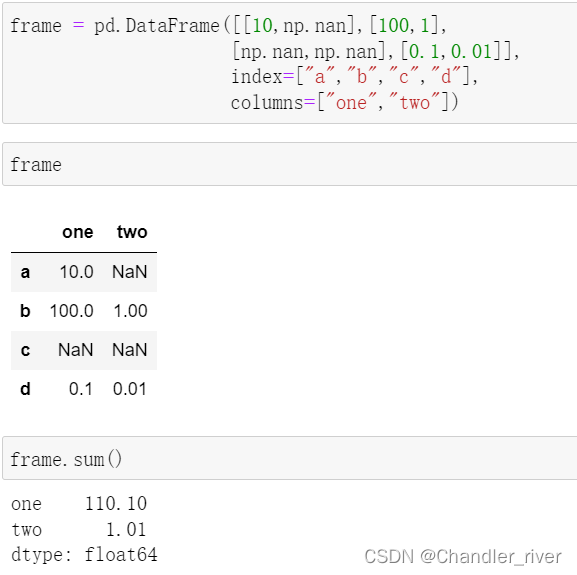
若向sum()方法传递axis="columns"或axis=1
会将一行上各个列的值相加
归约方法可选参数
| 方法 | 描述 |
| axis | 归约轴,0为行,1为列 |
| skipna | 排除缺失值,默认为True |
| level | 若轴是多层索引的,该参数可以缩减分组层级 |
描述性统计和汇总统计
| 方法 | 描述 |
| count | 非NA的值 |
| describe | 计算各列的汇总统计集合 |
| min,max | 计算最小值,最大值 |
| argmin,argmax | 最小值,最大值所在的索引 |
| idxmin,idxmax | 最小值,最大值所在的标签 |
| quantile | 样本从0到1的分位数 |
| sum | 和 |
| mean | 均值 |
| median | 中位数 |
| mad | 平均值的平均绝对偏差 |
| prod | 累积 |
| var | 样本方差 |
| std | 样本标准差 |
| skew | 样本偏度值 |
| kurt | 样本峰度值 |
| cumsum | 累计值 |
| cummin,cummax | 累计值的最小/最大 |
| cumprod | 累计积 |
| diff | 计算第一个算术差值 |
| pct_change | 计算百分比 |
















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











