







数据载入
文本格式数据的读写
read_csv 和 read_table
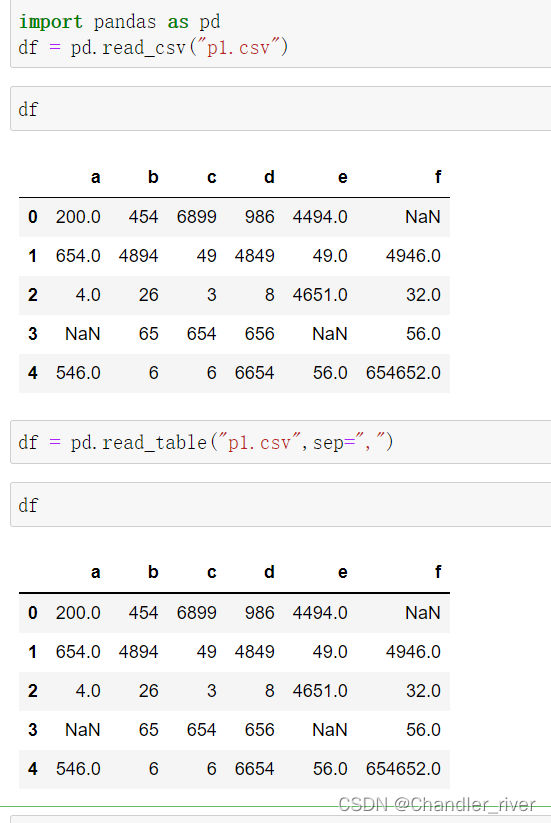
一些reaf_csv/read_table函数参数
| path | 表明文件系统位置 |
| header | 用作列名的行号,默认为0,没有列名的话,应该为None |
| names | 结果的列名列表,要和header=None一起使用 |
| nrows | 从文件开头读入的行数 |
数据写出
![]()
一些参数列表
| sep | 分隔符 |
| na_rep | 对缺失值进行标注 |
| index=False | 隐藏行标签 |
| header=False | 隐藏列标签 |
| columns=[] | 选择写入的列,并按照columns的顺序 |
数据清洗与准备
处理缺失值
dropna过滤DataFrame缺失值
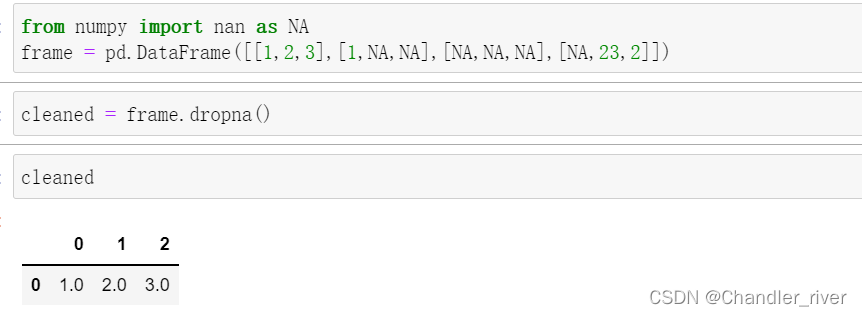
当传入how="all"时,将只删除所有值均为NA的行
如果要删除列,需要传入参数axis=1
fillna补全缺失值
1.fillna()使用一个常数来替代缺失值
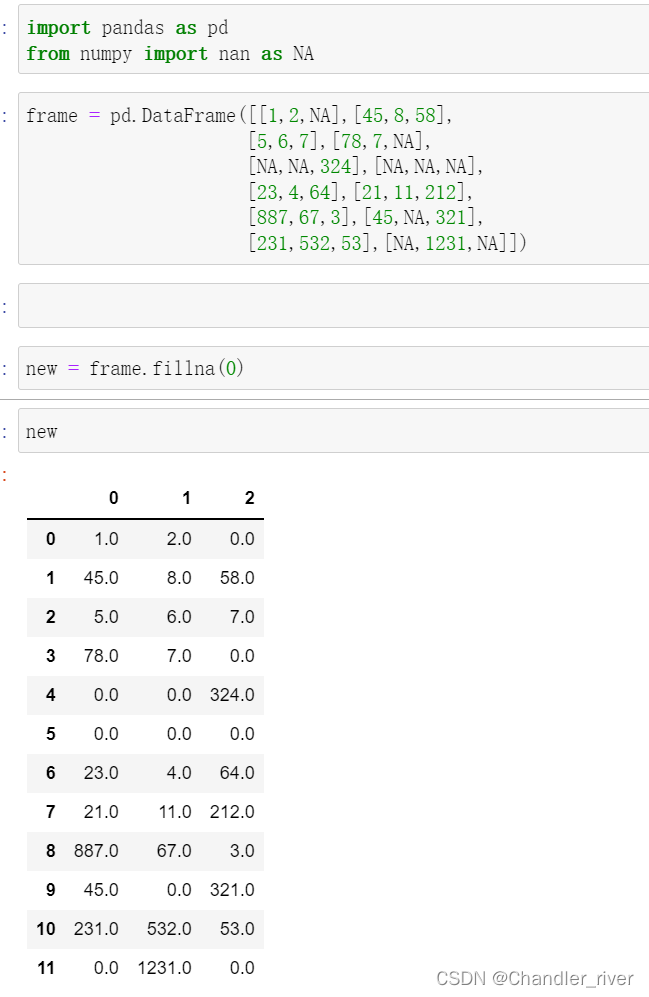
或者用一个字典为不同列设置不同的填充值
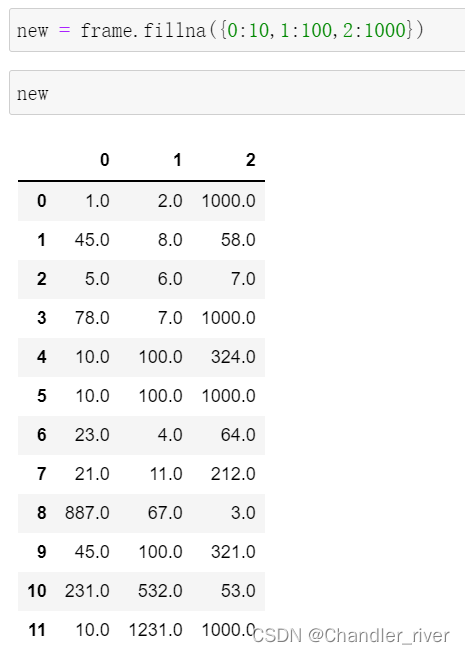
fillna返回的是一个新对象,但是如果传入参数inplace=True可以修改原对象
fillna参数列表
| 参数 | 描述 |
| value | 标量值或字典对象用于填充缺失值 |
| method | 插值方法,默认为"ffill" |
| axis | 需要填充的轴,默认为axis=0 |
| inplace | 修改被调用的对象 |
| limit | 向前或向后填充的最大填充范围 |
数据转换
删除重复值
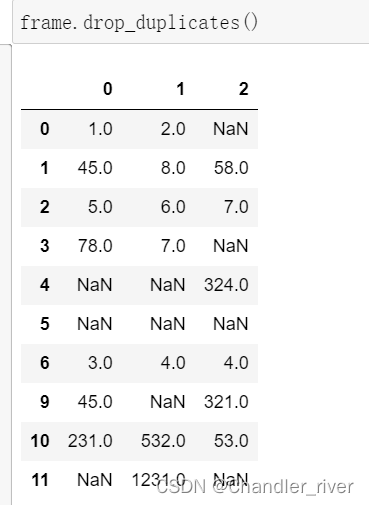
duplicate()方法和drop_duplicates()返回DataFrame
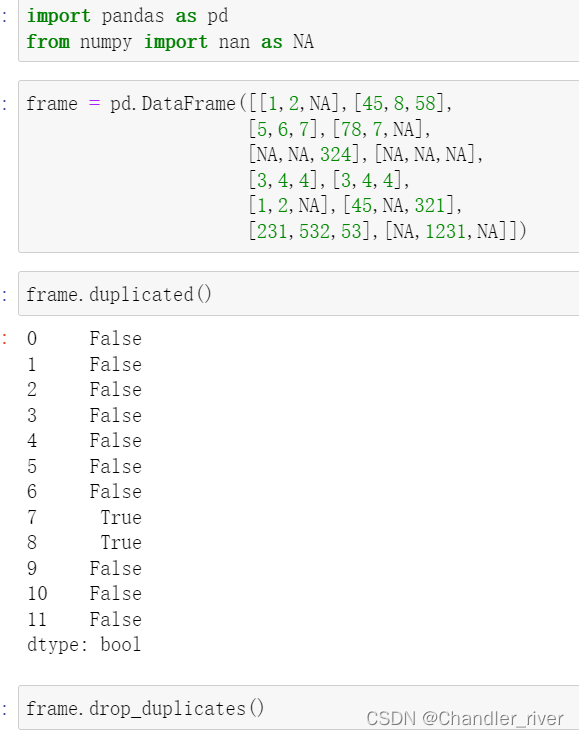
drop_duplicated()返回的是数组中为False的部分
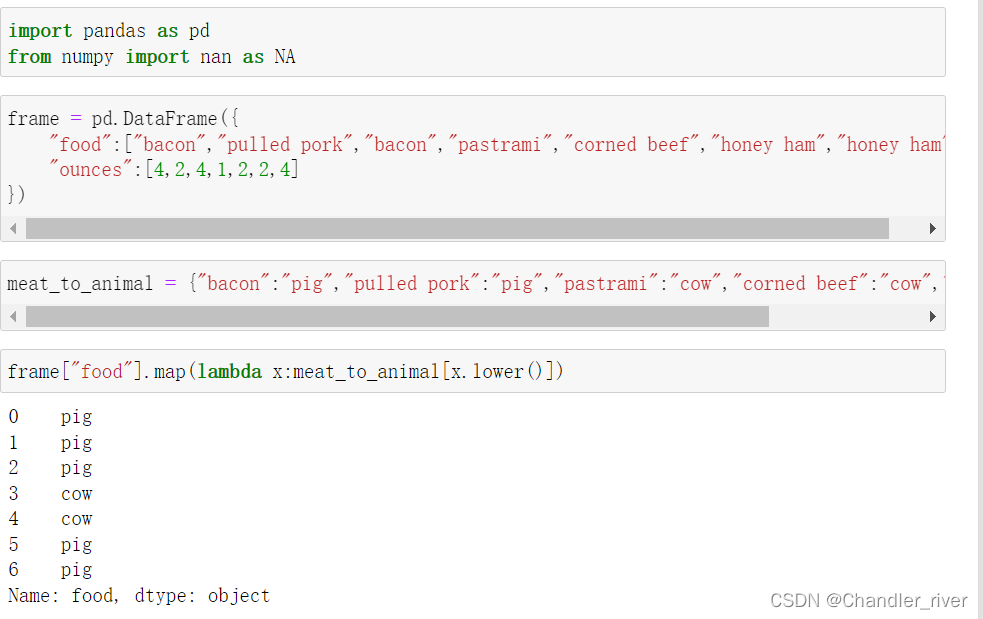
利用map做数据转换
利用replace做替代值
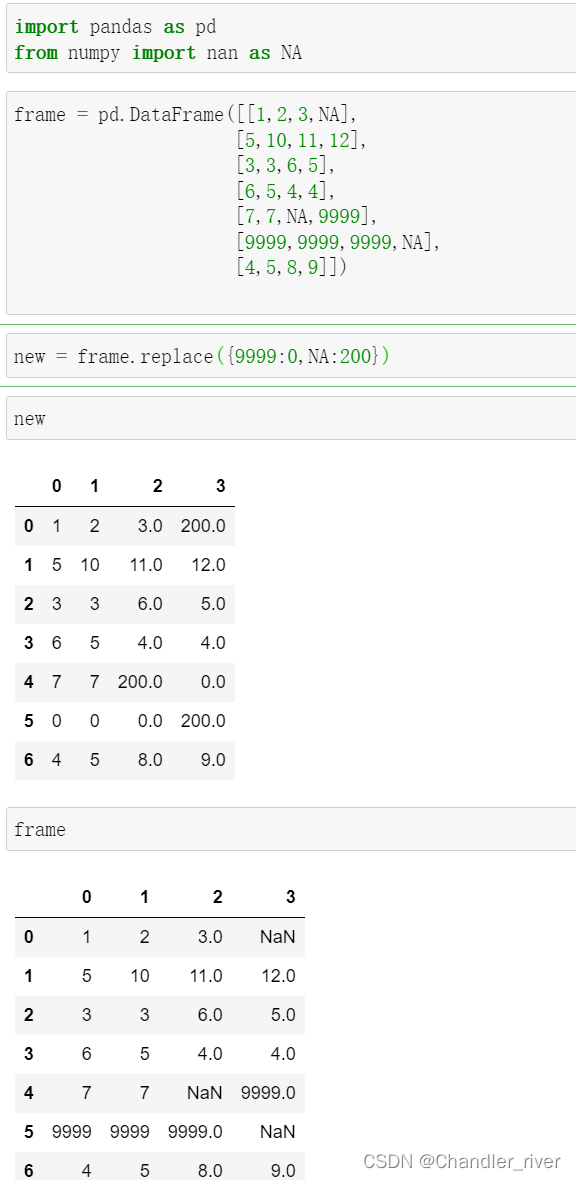
离散化和分箱
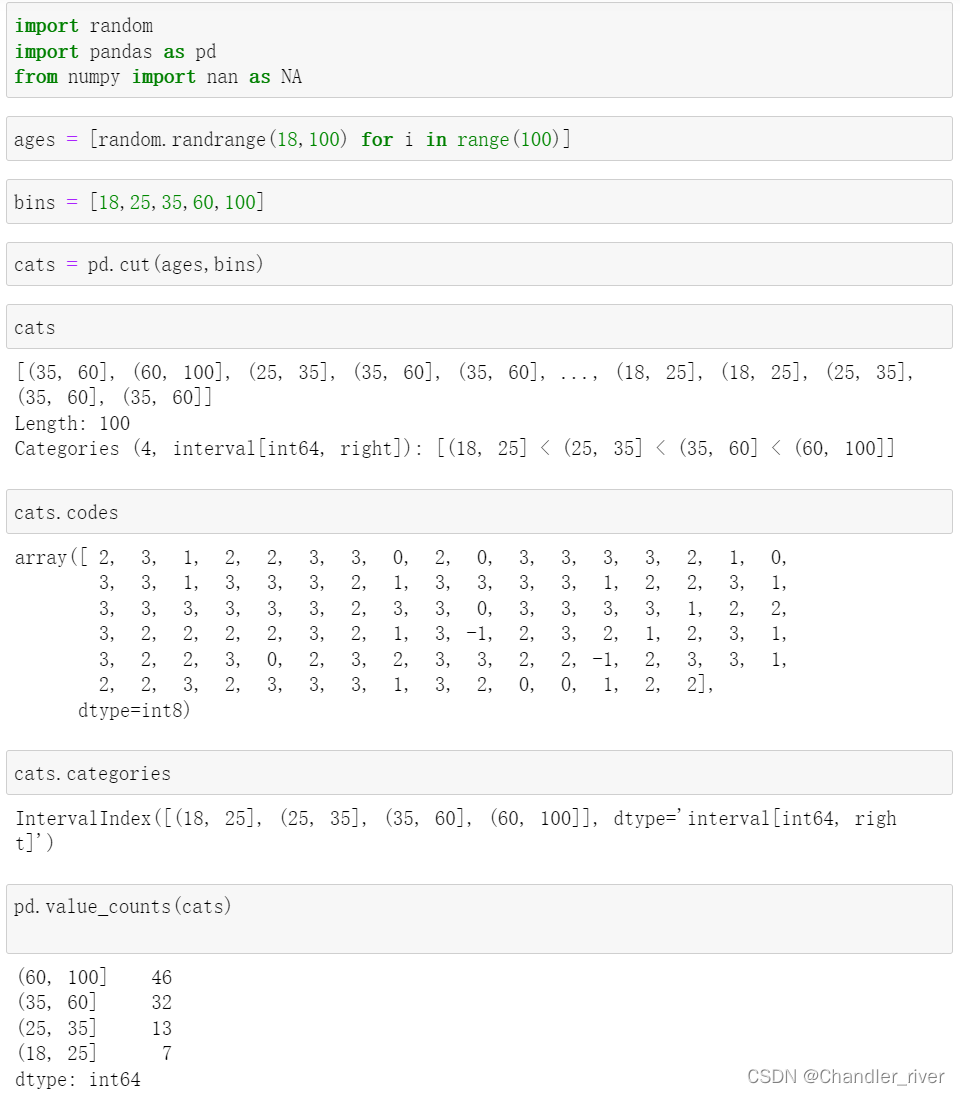
codes,categories方法和cut,value_counts函数
可以向cut函数传递参数right=False来改变封闭的一边
可以向labels选项传递一个参数来自定义箱名
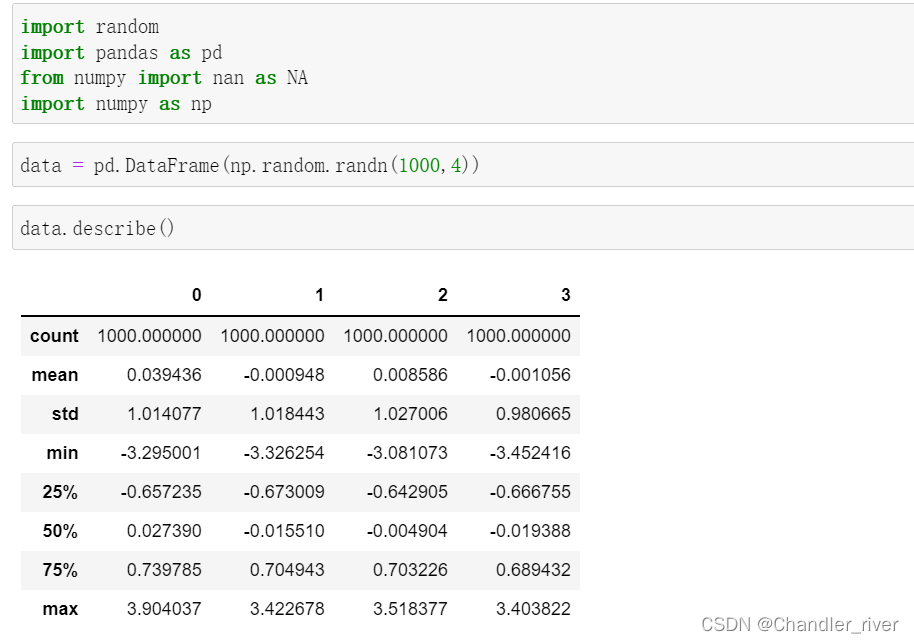
检测和过滤异常值
describe方法
选取行或者列
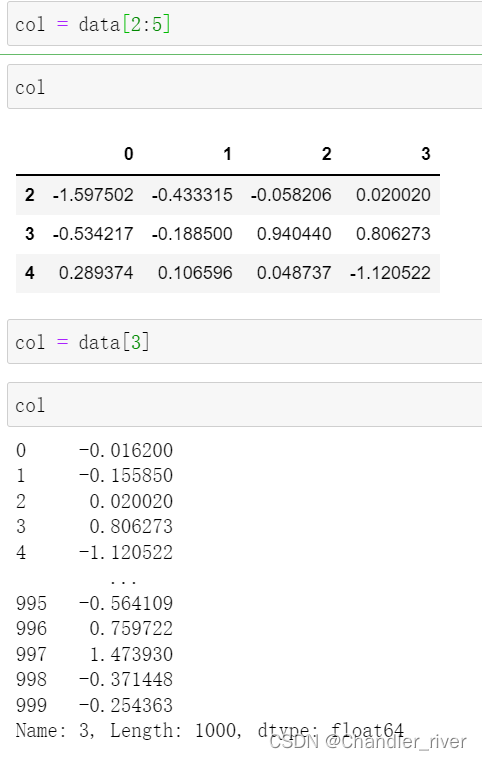
选取一列中绝对值大于三的值
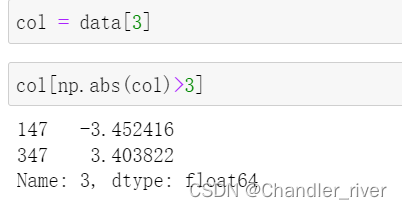
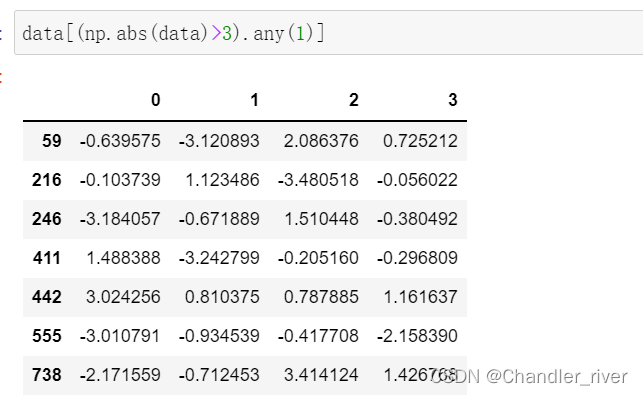
在这里使用any方法
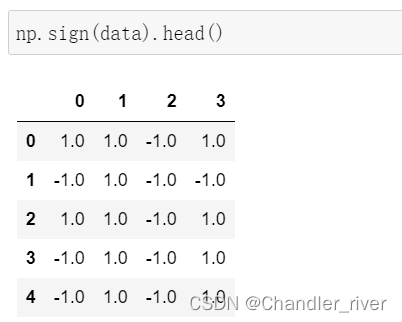
用sign函数判断正负
完
















 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











