







前言:
数据的质量直接关乎最后数据分析出来的结果。
在进行数据分析前,我们必须对数据进行清洗。
如果数据较少,我们可以对缺失值,异常值进行拉格朗日插值法进行插值处理。
在这篇博客里,因为数据样本较充足,我们直接对少量的异常值进行简单粗暴也是最有效的删除。
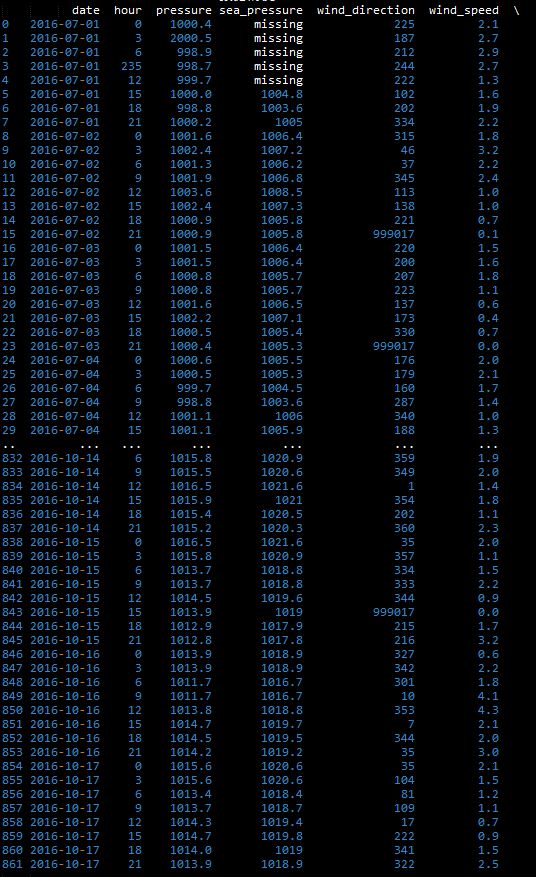
先上图看一下数据(注:因为博客上传不了附件,如有需要样本数据自己进行实测的可以留言索要)

上图为要进行清洗的数据的一部分。
这里,我们首先用Pandas直接读入数据变成DataFrame.(Pandas库不懂的同学要去看看《Python数据分析》)
import pandas as pd
import numpy as np
# 读入数据
data=pd.DataFrame(pd.read_excel('000.xlsx',index=False))
print(data)打印出数据,打印出原始数据如下图所示:

目标:
这里,我们可以看到,日期列没什么问题,时间列(hour)出现235小时明显不符,一天时间只能落在0-24。气压(pressure)超过1500不正常。sea_pressure有存在空值现象。wind_direction也存在值=999017的异常数据。我们要做的是对存在异常值的记录整行进行删除,最后写入数据。
我们首先利用describe()函数看样本数据的大概情况。
print(data.describe())
count非空数据总和。可以看到 sea_pressure 的非空数据总和为857,rel_humidity为861,证明这两列数据分别存在5,1行空值(缺失值)
mean均值
std标准差,值越大表示此行数据越离散。存在异常值概率越大。
min,max:最小值最大值。时间hour列最大值为235明显为异常值。
开始数据清洗
1 填充缺失值空格,方便下面对缺失值行进行处理。
# 填充缺失值
data=data.fillna('missing')我们可以看到,缺失值被填充成‘missing’,填充成什么值不重要,只要不予数据里的其它值一样就行。
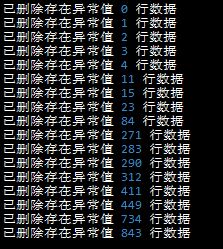
2 逐行扫描数据,只要此行存在一个异常值。对此行进行删除。
这里,any([])函数如若里面一个为真,则返回True.即逐行扫描,发现‘missing’存在此行中,或此行时间不落在0-24之间,或气压rpessure大于1500,或风向不落在0-360度之间,或风速大于10级,或precipitation降雨量大于10,则此行数据为异常数据进行删除。
for i in range(data.index.max()):
if any([
'missing' in data.loc[i,:].values,
data.loc[i,'hour'] not in range(25),
data.loc[i,'pressure']>1500,
data.loc[i,'wind_direction']<0 or data.loc[i,'wind_direction']>360,
data.loc[i,'wind_speed']>10,
data.loc[i,'precipitation']>10
]):
print('已删除存在异常值 %s 行数据'%i)
data.drop([i],inplace=True)运行结果:
3显示处理后数据信息:
print(data)
print(data.describe())

4最后,查看无异常后保存清洗后的数据。
data.to_csv('clean.csv')全部代码:
import pandas as pd
import numpy as np
# 读入数据
data=pd.DataFrame(pd.read_excel('000.xlsx',index=False))
print('原始数据\n',data)
print('----------------------------基本信息 describe()-----------------------------')
print(data.describe())
# print(data.std(),data.min(),data.max())
'''
print('\n-----------------------极差变异系数四分位间距-------------------------')
statistics = data.describe() #保存基本统计量
statistics.loc['range'] = statistics.loc['max']-statistics.loc['min'] #极差
statistics.loc['var'] = statistics.loc['std']/statistics.loc['mean'] #变异系数
statistics.loc['dis'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距
# print(statistics)
'''
print('-------------------------------数据清洗-------------------------------')
# 填充缺失值
data=data.fillna('missing')
for i in range(data.index.max()):
if any([
'missing' in data.loc[i,:].values,
data.loc[i,'hour'] not in range(25),
data.loc[i,'pressure']>1500,
data.loc[i,'wind_direction 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9691
9691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









