







参考链接:
https://www.cnblogs.com/ysocean/p/8032660.html#_label0
https://blog.csdn.net/abcd1f2/article/details/54863445
https://www.cnblogs.com/skywang12345/p/3602162.html
这几个链接写的非常好,我只是记录我自己需要的内容,大家可以仔细阅读。
最后一个链接最好了
目录
堆的概念
1.小根堆
若根节点存在左子女则根节点的值小于左子女的值;若根节点存在右子女则根节点的值小于右子女的值。
2.大根堆
若根节点存在左子女则根节点的值大于左子女的值;若根节点存在右子女则根节点的值大于右子女的值。
3.结论
(1)堆是一棵完全二叉树(如果共有h层,那么1~h-1层均满,在h层连续缺失若干个右叶子)。
(2)小根堆的根节点的值是最小值,大根堆的根节点的值是最大值。
(3)堆适合于采用顺序存储。在第一个元素的索引为 0 的情形中:
性质一:索引为i的左孩子的索引是 (2*i+1);
性质二:索引为i的左孩子的索引是 (2*i+2);
性质三:索引为i的父结点的索引是 floor((i-1)/2);
堆排序算法
将数组构造成初始堆(若想升序则建立大根堆,若想降序,则建立小根堆)
从最后一个节点开始调整,得到初始堆。
初始化:
在堆排序算法中,首先要将待排序的数组转化成二叉堆。
下面演示将数组{20,30,90,40,70,110,60,10,100,50,80}转换为最大堆{110,100,90,40,80,20,60,10,30,50,70}的步骤。
i=11/2-1,即i=4
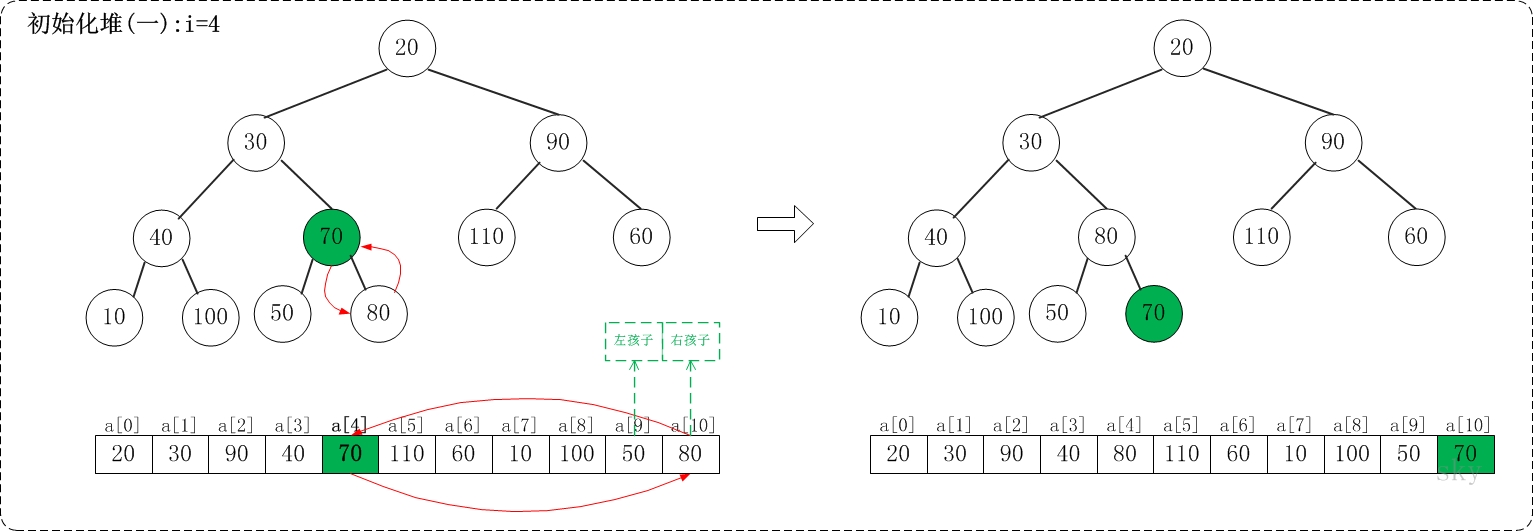
上面是maxheap_down(a, 4, 9)调整过程。maxheap_down(a, 4, 9)的作用是将a[4...9]进行下调;a[4]的左孩子是a[9],右孩子是a[10]。调整时,选择左右孩子中较大的一个(即a[10])和a[4]交换。
i=3
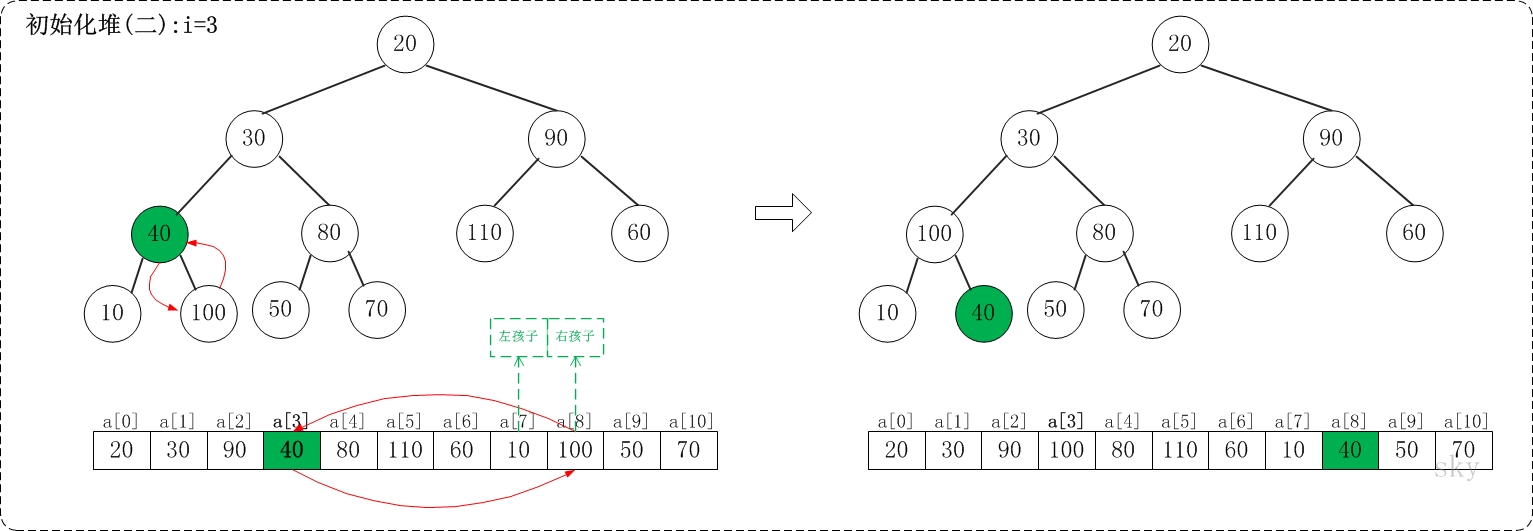
上面是maxheap_down(a, 3, 9)调整过程。maxheap_down(a, 3, 9)的作用是将a[3...9]进行下调;a[3]的左孩子是a[7],右孩子是a[8]。调整时,选择左右孩子中较大的一个(即a[8])和a[4]交换。
i=2

上面是maxheap_down(a, 2, 9)调整过程。maxheap_down(a, 2, 9)的作用是将a[2...9]进行下调;a[2]的左孩子是a[5],右孩子是a[6]。调整时,选择左右孩子中较大的一个(即a[5])和a[2]交换。
i=1
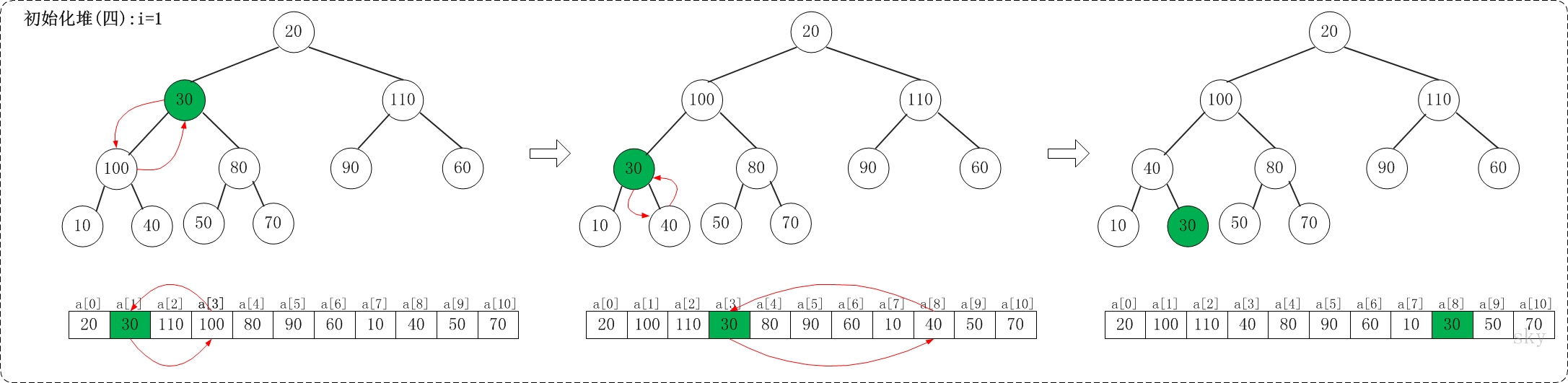
上面是maxheap_down(a, 1, 9)调整过程。maxheap_down(a, 1, 9)的作用是将a[1...9]进行下调;a[1]的左孩子是a[3],右孩子是a[4]。调整时,选择左右孩子中较大的一个(即a[3])和a[1]交换。交换之后,a[3]为30,它比它的右孩子a[8]要大,接着,再将它们交换。
i=0

上面是maxheap_down(a, 0, 9)调整过程。maxheap_down(a, 0, 9)的作用是将a[0...9]进行下调;a[0]的左孩子是a[1],右孩子是a[2]。调整时,选择左右孩子中较大的一个(即a[2])和a[0]交换。交换之后,a[2]为20,它比它的左右孩子要大,选择较大的孩子(即左孩子)和a[2]交换。
调整完毕,就得到了最大堆。此时,数组{20,30,90,40,70,110,60,10,100,50,80}也就变成了{110,100,90,40,80,20,60,10,30,50,70}。
开始排序:
交换堆顶的元素和最后一个元素,此时最后一个位置作为有序区,然后进行其他无序区的堆调整,重新得到大顶堆后,交换堆顶和倒数第二个元素的位置……
举例子:
初始堆为:

交换堆顶的元素和最后一个元素,此时最后一个位置作为有序区(有序区显示为黄色),然后进行其他无序区的堆调整,重新得到大顶堆后,交换堆顶和倒数第二个元素的位置……

重复此过程:

最后,有序扩展完成即排序完成:

package LeetCode;
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
int[] a = {49, 38, 65, 97, 76, 13, 27, 49, 78, 34, 12, 64};
int arrayLength = a.length;
//循环建堆
for (int i = 0; i < arrayLength - 1; i++) {
//建堆
buildMaxHeap(a, arrayLength - 1 - i);
//交换堆顶和最后一个元素
swap(a, 0, arrayLength - 1 - i);
System.out.println(Arrays.toString(a));
}
}
//对data数组从0到lastIndex建大顶堆
public static void buildMaxHeap(int[] data, int lastIndex) {
//从lastIndex处节点(最后一个节点)的父节点开始
//在第一个元素的索引为 0 的情形中:
//性质一:索引为i的左孩子的索引是 (2*i+1);
//性质二:索引为i的左孩子的索引是 (2*i+2);
//性质三:索引为i的父结点的索引是 floor((i-1)/2);
for (int i = (lastIndex - 1) / 2; i >= 0; i--) {
//k保存正在判断的节点
int k = i;
//如果当前k节点的子节点存在
while (k * 2 + 1 <= lastIndex) {
//k节点的左子节点的索引
int biggerIndex = 2 * k + 1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if (biggerIndex < lastIndex) {
//若果右子节点的值较大
if (data[biggerIndex] < data[biggerIndex + 1]) {
//biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
//如果k节点的值小于其较大的子节点的值
if (data[k] < data[biggerIndex]) {
//交换他们
swap(data, k, biggerIndex);
//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k = biggerIndex;
} else {
break;
}
}
}
}
//交换
private static void swap(int[] data, int i, int j) {
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
}
删除:
堆在删除元素时,只可以删除根节点。
算法描述:将根节点删除后用堆尾结点进行填补,调整二叉树,使之依然成为一个堆。
- 移走根
- 把最后一个节点移动到根的位置
- 一直向下筛选这个节点,直到它在一个大于它的节点之下,小于它的节点之上为止
注意:向下筛选的时候,将目标节点和其子节点比较,谁大就和谁交换位置。


插入:
将一个数据元素插入到堆中,使之依然成为一个堆。
算法描述:先将结点插入到堆的尾部,再将该结点逐层向上调整,直到依然构成一个堆,调整方法是看每个子树是否符合大(小)根堆的特点,不符合的话则调整叶子和根的位置。插入时,选择向上筛选,节点初始时插入到数组最后第一个空着的单元,数组容量大小增一。然后进行向上筛选的算法。
注意:向上筛选和向下不同,向上筛选只用和一个父节点进行比较,比父节点小就停止筛选了

















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









