







1. CH2-kNN(1)
2. CH2-kNN(2)
3. CH2-kNN(3)
4. CH3-决策树(1)
5. CH3-决策树(2)
6. CH3-决策树(3)
7. CH4-朴素贝叶斯(1)
8. CH4-朴素贝叶斯(2)
9. CH5-Logistic回归(1)
10. CH5-Logistic回归(2)
======== No More ========
这是k-近邻算法的最后一个例子——手写数字识别!
怎样?是不是听起来很高大上?
呵呵。然而这跟图像识别没有半毛钱的关系
因为每个数据样本并不是手写数字的图片,而是有由0和1组成的文本文件,就像这样:


嗯,这个数据集中的每一个样本用图形软件处理过,变成了宽高都是32像素的黑白图像。用文本格式表示出来就成了上面这个样子,是一个32*32的矩阵。于是每个样本就有1024维,这些0或1就是每个样本的特征值,标签是手写的数字,范围0~9,比如左边这幅是3,右边这幅是6。
每个标签都有将近200个样本,可供训练。

---------------------------------------------------------------------------------------------
我们首先定义一个函数,用于把上面这样的一个txt文件,变成一个1*1024的特征矩阵。
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
然后,基于训练集合测试集,测试classify0分类器的效果。
from os import listdir
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))hwLabels 存放每条训练集数据的标签。
listdir 函数列出路径下的所有文件和文件夹。'trainingDigits' 这个目录下放的是训练集数据样本(就是上面那张图展现的众多文本文件)。m是训练集样本数量。trainingMat是训练集特征矩阵。
8~13行这个循环:每个训练样本命名规则是n_x.txt,n就是标签,x是该标签的第几个样本。比如1_6.txt就是标签1的第6的样本。标签存入hwLabels这个list里面。然后把文本文件转换成特征矩阵,用的是刚才那个img2vector函数。
然后开始搞测试样本。测试样本放在'testDigits' 这个目录下,mTest是测试样本数量。
17~24行这个循环:首先也是通过文件名把测试样本的正确标签抠出来,存入classNumStr。然后把文本文件转换成特征矩阵,存入vectorUnderTest。然后把vectorUnderTest当做待测试数据传入classify0分类器(源码在第一篇博客)。得出的分类结果和classNumStr相比较,统计错误率。
运行结果(运行的过程比较慢):
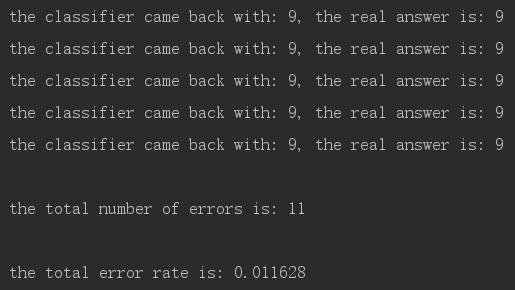
错误率仅为1.2%,效果还是不错的。















 2123
2123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









