







 本文介绍了如何在Huggingface Transformers中利用DeepSpeed库进行模型加速。DeepSpeed由微软开发,能显著提高大规模模型训练的速度。文章详细讲解了安装配置DeepSpeed,包括设置OpenMPI的临时文件夹,以及在Huggingface Transformers中进行微调和多卡训练的步骤。同时,还提到了在后续任务中使用微调模型时需要注意的事项。
本文介绍了如何在Huggingface Transformers中利用DeepSpeed库进行模型加速。DeepSpeed由微软开发,能显著提高大规模模型训练的速度。文章详细讲解了安装配置DeepSpeed,包括设置OpenMPI的临时文件夹,以及在Huggingface Transformers中进行微调和多卡训练的步骤。同时,还提到了在后续任务中使用微调模型时需要注意的事项。
Transformers 🤗支持多种加速库,例如Fairseq使用的FairScale,这里只是使用了DeepSpeed,但加速方法不只一种
1. DeepSpeed
DeepSeed是一个针对大规模模型预训练和微调加速的一个库,由微软出品。
文档地址 https://www.deepspeed.ai/getting-started/
DeepSpeed对Huggingface 🤗 Transformers和Pytorch Lightning都有着直接的支持
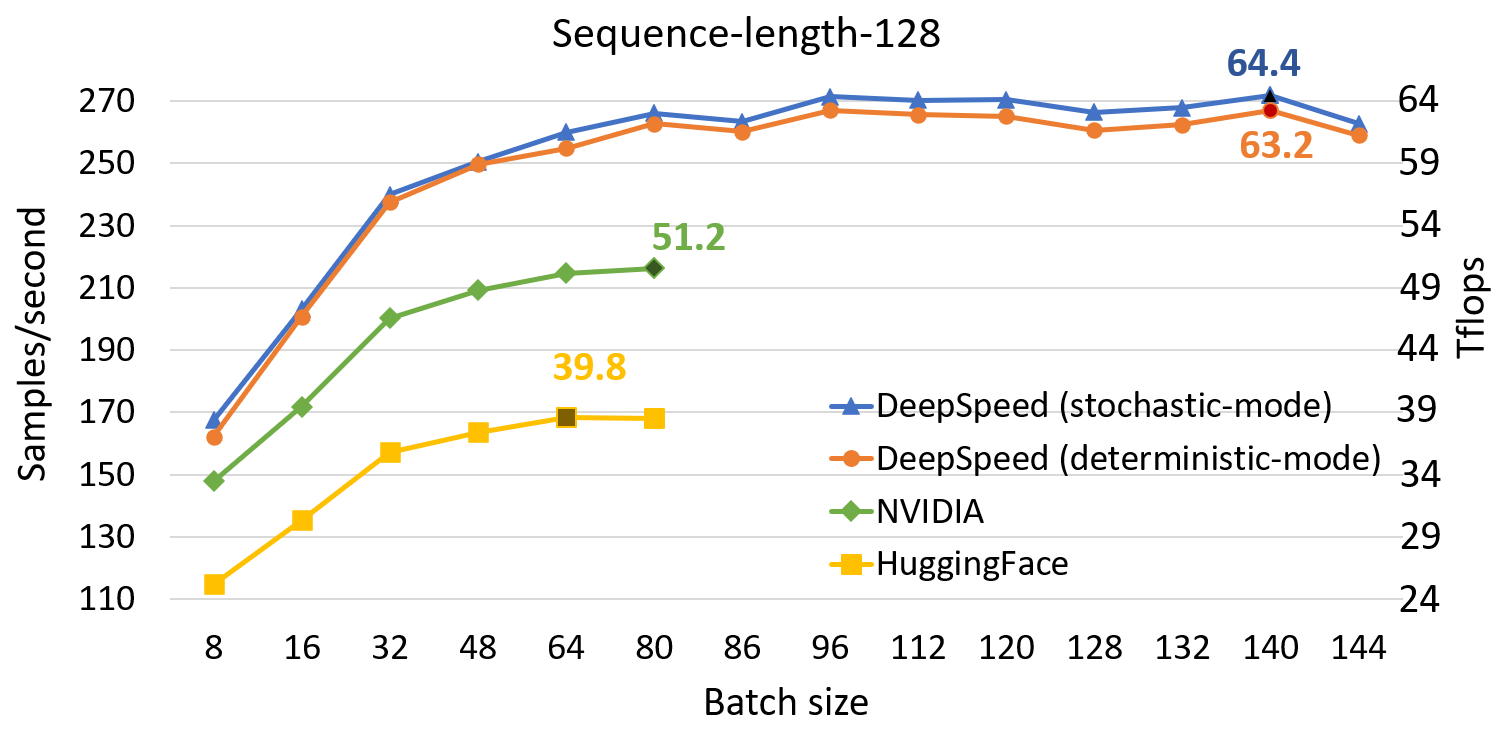
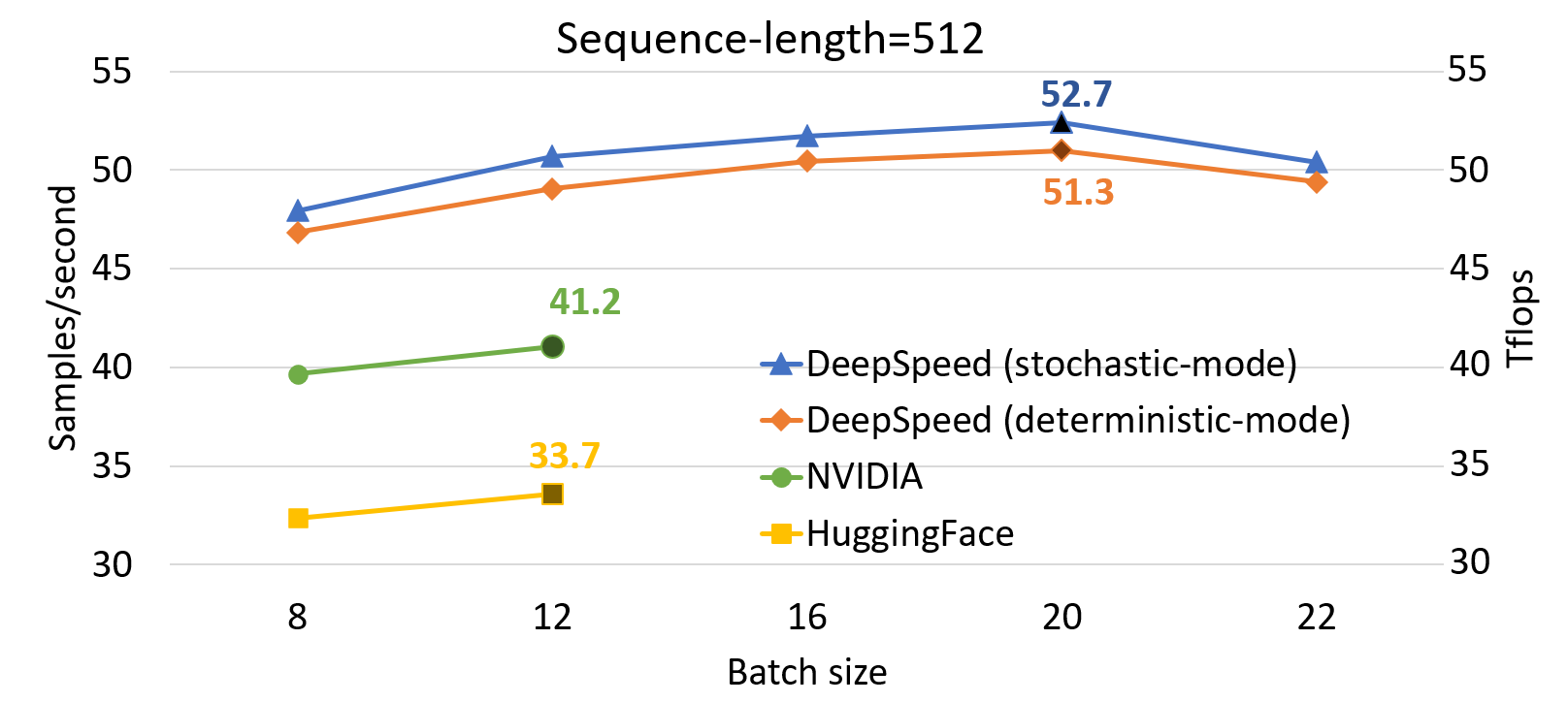
DeepSpeed加速使得微调模型的速度加快,在pre-training BERT的效果上,有着更快的计算速度,相较于原生的Huggingface 🤗Transformers有着接近1.5倍的加速
2. 配置
2.1 安装DeepSpeed及其前置安装
deepspeed需要使用mpi4py和cupy
pip install mpi4py deepspeed
conda install cupy
2.2 配置OpenMPI
DeepSpeed是直接支持大规模集群的,所以基于OpenMPI,在学校服务器上已经安装OpenMPI,由于我们没有写入/tmp文件夹的权限,所以我们需要对OpenMPI进行设置
唯一需要的设置是指定OpenMPI的temp文件夹位置
OpenMPI的配置文件有两个位置
- $HOME/.openmpi/mca-params.conf 高优先级
- $prefix/etc/openmpi-mca-params.conf 低优先级
所以需要在自己创建$HOME/.openmpi/mca-params.conf覆盖默认设置
设置一个有权限访问的temp文件夹
orte_tmpdir_base = /where/you/have/permission/tmp
如果是在AutoDL上,直接更改/tmp权限即可
chmod 777 /tmp
3. 使用
在Huggingface 🤗 中使用DeepSpeed只需要写DeepSpeed的配置文件即可
3.1 使用huggingface🤗进行微调
官方教程https://huggingface.co/docs/transformers/tasks/language_modeling
总结下来的主要流程就是
- 加载模型与tokenizer,以xlmr为例子
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-base")
model = AutoModelForMaskedLM.from_pretrained("xlm-roberta-base")
-
加载数据集
对于数据集需要处理为csv格式方便加载,加载的数据路径需要写为
data={
"train":"/train/file/path" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1339
1339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









