







性能不够,缓存来凑。
作为一名开发人员,不管是面试还是平时工作都会被问到如何优化项目性能的问题,回答不外乎缓存、Redis,不行搞进程级别的缓存。可是你真的会做缓存吗?我看过很多的缓存方案,大多数与业务代码强耦合,代码侵入性极大,且缓存方案替代(如ehcache迁移到redis,redis的序列化方式由json替换为protobuf)需要修改大量代码。
本人多年开发总结下来一套耦合度极小,且灵活高效的项目缓存方案,跟大家分享。
样例程序背景,首先我的项目基于是SpringBoot的,程序里涉及学生模块和分数模块。
一:项目总体结构

config:配置
db:数据库实体和repository
lock:是一个基于注解的分布式锁方案
proto:是protobuf相关的一些东西
provider:是数据提供者
dto和model:模型和传输对象
service:是业务逻辑处理层
controller:接口层
注明:本人的开发习惯,使用四层结构:controller->service->provider->repository
二:缓存操作的具体实现
我的缓存一般放在数据提供层(provider),我的原则是尽量少用join的方式从数据库取数据,而是每个模块分别缓存,然后通过程序组装的方式输出最终的结果
举例:现在有A B C三个模块,有几个接口,每个接口涉及到的数据可能包含三个模块中的任意组合,试想一下,如果我在业务处理地方做缓存,那么我的缓存种类超过三种,且每当A B C中的任意一个模块有数据变动,清理缓存也是一个麻烦,现在我做成了A B C三个模块分别缓存,各自在自己的Provider里做增删改查及对应的缓存操作,界限非常明确,任何一个模块的数据变动都只需要清理对应模块的缓存即可,接口层通过聚合的方式来组装数据并返回,可能会比原来多访问几次redis,但是换来的是程序逻辑的清晰和代码的严谨,可读性翻倍,我认为这样的方案换来程序的优雅是值得的,我一直认为程序的可读性也是一个非常重要的方面。
StudentProvider代码如下:
package chen.huai.jie.springboot.cache.provider;
import chen.huai.jie.springboot.cache.db.entity.Student;
import chen.huai.jie.springboot.cache.db.repository.StudentRepository;
import chen.huai.jie.springboot.cache.lock.DistributedLock;
import chen.huai.jie.springboot.cache.provider.access.StudentAccess;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cache.annotation.Caching;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import static chen.huai.jie.springboot.cache.model.CacheConstants.STUDENT_BY_ID;
import static chen.huai.jie.springboot.cache.model.CacheConstants.STUDENT_BY_NO;
/**
* @author chenhuaijie
*/
@Slf4j
@Service
public class StudentProvider extends BaseProvider {
@Autowired
private StudentRepository studentRepository;
@Autowired
private StudentAccess studentAccess;
/**
* 根据ID查找
* <p>
* 只有当id!=null&&id>0时候才进入缓存,否则直接进入程序
* 缓存null值
* 缓存Key为id
*
* @param id
* @return
*/
@Cacheable(cacheNames = STUDENT_BY_ID, condition = "#id!=null and #id>0", key = "#id", sync = true)
@DistributedLock(keyPrefix = "cache:lock:StudentProvider:findById", waitTime = 10, key = "#id")
public Student findById(Long id) {
if (id == null || id <= 0) {
log.warn("id is null or less than 0,id:{}", id);
return null;
}
Student student = studentAccess.findById(id);
if (student != null) {
return student;
}
log.info("从数据库加载数据:id:{}", id);
return studentRepository.findById(id).orElse(null);
}
/**
* 根据学号查找
*
* @param no
* @return
*/
@Cacheable(cacheNames = STUDENT_BY_NO, condition = "#no != null and !\"\".equals(#no)", key = "#no", sync = true)
@DistributedLock(keyPrefix = "cache:lock:StudentProvider:findByNo", waitTime = 10, key = "#no")
public Student findByNo(String no) {
if (StringUtils.isEmpty(no)) {
return null;
}
Student student = studentAccess.findByNo(no);
if (student != null) {
return student;
}
return studentRepository.findByNo(no);
}
/**
* 添加
*
* @param student
* @return
*/
@Caching(evict = {
@CacheEvict(cacheNames = STUDENT_BY_ID, condition = "#student!=null", key = "#student.id"),
@CacheEvict(cacheNames = STUDENT_BY_NO, condition = "#student!=null", key = "#student.no")
})
public Student add(Student student) {
if (student == null) {
return null;
}
return studentRepository.save(student);
}
/**
* 修改
*
* @param student
* @return
*/
@Caching(evict = {
@CacheEvict(cacheNames = STUDENT_BY_ID, condition = "#student!=null", key = "#student.id"),
@CacheEvict(cacheNames = STUDENT_BY_NO, condition = "#student!=null", key = "#student.no")
})
public Student update(Student student) {
if (student == null) {
return null;
}
return studentRepository.save(student);
}
/**
* 删除
*
* @param student
*/
@Caching(evict = {
@CacheEvict(cacheNames = STUDENT_BY_ID, condition = "#student!=null", key = "#student.id"),
@CacheEvict(cacheNames = STUDENT_BY_NO, condition = "#student!=null", key = "#student.no")
})
public void delete(Student student) {
if (student == null) {
return;
}
studentRepository.deleteById(student.getId());
}
}
这个类一共有五个方法:
public Student findById(Long id);
public Student findByNo(String no);
public Student add(Student student);
public Student update(Student student);
public void delete(Student student);两个获取的方法和三个修改的方法,在缓存操作层我利用的是Spring的Cacheable(写入缓存)和CacheEvict(清理缓存)。
Cacheable注解有几个参数,解释如下:
cacheNames(value):缓存的名字
key:具体缓存的Key(支持SPEL表达式)
cacheManager:指定的缓存管理器
condition:条件,满足这个条件就进入缓存,否则直接跳过缓存进入方法
unless:条件,满足这个条件就写入缓存,否则不写入缓存
sync:是否同步操作
接下来我们解析findById方法的注解:
@Cacheable(cacheNames = STUDENT_BY_ID, condition = "#id!=null and #id>0", key = "#id", sync = true)
@DistributedLock(keyPrefix = "cache:lock:StudentProvider:findById", waitTime = 10, key = "#id")第一个注解是缓存注解,
这个模块的缓存名是:STUDENT_BY_ID,对应的值是 cache:student:id:;
只有当id!=null&&id>0才进入缓存获取数据,否则跳过缓存直接进入方法;
key是按照参数id的值来确定的,基于Spel表达式
sync=true,同步写入缓存,意味着服务的一个程序实例里,缓存写入读取是一个同步的过程,避免出现大并发的情况下缓存击穿。(仅在单实例下有效,多实例下会出现每个实例访问一次数据库的情况)
缓存null值,防止缓存穿透(缓存时间不要太大,防止攻击导致redis写满)。
第二个注解是分布式锁:
为了解决缓存击穿问题,光在Cacheable里家sync=true,并不能解决多实例下的问题,可能会出现每个实例访问一次数据库的情况,而不是希望的总共只访问一次数据库的情况,所以我们在这里增加一个分布式锁来协调不同实例直接的缓存读取存入操作。经过多次测试,明确用此方法可以保证高并发情况下只会有一次数据访问。
studentAccess.findById其实就是从缓存中取一下数据,代码如下,不管任何情况都会进入缓存获取数据,且不缓存null值,这样程序返回的null不会写入缓存。
/**
* 从缓存获取学生信息
* 直接进入缓存
* 不缓存null值
*
* @param id
* @return
*/
@Cacheable(cacheNames = STUDENT_BY_ID, unless = "#result==null", key = "#id")
public Student findById(Long id) {
log.warn("缓存数据不存在:id:{}", id);
return null;
}我们都知道多个切面的执行顺序,如下图:
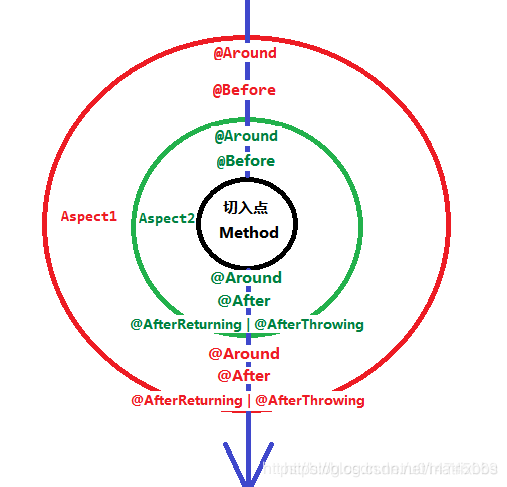
注解的执行顺序是有注解切面上的@Order的值决定的,我们这里DistributedLock的值要大于Cacheable的,所以Cacheable的代码先执行,如图上的外圈。
通过测试,我们也确定Cacheable比DistributedLock先执行(缓存有数据执行返回,缓存没有数据进入分布式锁的切面执行代码)
假设一共有200个线程分别进入A、B两个实例,各自100个线程。
A实例的100个线程,当进入Cacheable注解时候会同步执行,此时只有一个线程会进入到DistributedLock的切面,如果此时获取到分布式锁,则进入方法执行,此时全局只有这一个线程进入到了方法内部,先判断参数是否有效,无效则返回null缓存起来,然后从缓存里取一下数据,如果不为空则返回,否则从数据库获取数据返回。
当B实例的第一个线程现在正在等待获取锁,A实例的线程执行完了方法并释放了锁,此时如果没有执行完Cacheabe切面的代码,B实例会再次从数据库加载一次数据,如果此时有执行完Cacheable切面的额代码,B实例的线程会进入方法通过studentAccess.findById获取数据并返回。
终极解决方案还是要在方法内部用分布式锁控制,这样就用不了分布式锁注解了。
实际上经过我几次测试200个线程2个实例同时跑,几乎没有出现从数据库取2遍数据的情况,这个概率极低。
CacheEvict注解是缓存清除注解,当方法执行完毕后,会触发缓存的清理工作。
一次增删改可能会触发多个缓存失效,如上。
三、缓存的配置
第二节的缓存操作只给我们提供了缓存操作的抽象实现,具体缓存是放到进程还是redis,是json序列化还是protobuf序列化,其实我们并不需要在provider层来指定,我们需要通过配置来指定。
缓存配置我准备了三套:
进程内缓存(主要采用的是ehcache):
package chen.huai.jie.springboot.cache.config;
import chen.huai.jie.springboot.cache.model.CacheConstants;
import net.sf.ehcache.Cache;
import net.sf.ehcache.config.CacheConfiguration;
import net.sf.ehcache.store.MemoryStoreEvictionPolicy;
import org.springframework.cache.CacheManager;
import org.springframework.cache.ehcache.EhCacheCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
/**
* @author chenhuaijie
*/
@Profile("ehcache")
@Configuration
public class EhcacheCacheConfig {
@Bean
public CacheManager cacheManager() {
return new EhCacheCacheManager(buildCacheManager());
}
private net.sf.ehcache.CacheManager buildCacheManager() {
net.sf.ehcache.CacheManager cacheManager = new net.sf.ehcache.CacheManager();
cacheManager.addCache(createCache(CacheConstants.STUDENT_BY_ID, 100, 600));
cacheManager.addCache(createCache(CacheConstants.STUDENT_BY_NO, 100, 600));
cacheManager.addCache(createCache(CacheConstants.SCORE_LIST_BY_STUDENT_NO, 100, 600));
return cacheManager;
}
private Cache createCache(String cacheName, int maxEntries, long timeToLiveSeconds) {
CacheConfiguration cacheConfiguration = new CacheConfiguration();
cacheConfiguration.name(cacheName)
.maxEntriesLocalHeap(maxEntries)
.memoryStoreEvictionPolicy(MemoryStoreEvictionPolicy.LFU)
.timeToLiveSeconds(timeToLiveSeconds);
return new Cache(cacheConfiguration);
}
}
分布式缓存(主要是用redis):
redis缓存里又分为
json序列化:
package chen.huai.jie.springboot.cache.config;
import chen.huai.jie.springboot.cache.db.entity.Score;
import chen.huai.jie.springboot.cache.db.entity.Student;
import chen.huai.jie.springboot.cache.model.CacheConstants;
import com.fasterxml.jackson.databind.JavaType;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.CacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import java.time.Duration;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author chenhuaijie
*/
@Slf4j
@Profile("json")
@Configuration
public class RedisJsonCacheConfig {
@Autowired
private ObjectMapper objectMapper;
@Bean
public CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
return RedisCacheManager
.builder(RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory))
.withInitialCacheConfigurations(buildRedisCacheConfigurationMap())
.build();
}
private Map<String, RedisCacheConfiguration> buildRedisCacheConfigurationMap() {
Map<String, RedisCacheConfiguration> redisCacheConfigurationMap = new HashMap<>(3);
redisCacheConfigurationMap.put(CacheConstants.STUDENT_BY_ID, buildRedisCacheConfiguration4Class(Student.class));
redisCacheConfigurationMap.put(CacheConstants.STUDENT_BY_NO, buildRedisCacheConfiguration4Class(Student.class));
redisCacheConfigurationMap.put(CacheConstants.SCORE_LIST_BY_STUDENT_NO, buildRedisCacheConfiguration4JavaType(List.class, Score.class));
return redisCacheConfigurationMap;
}
private RedisCacheConfiguration buildRedisCacheConfiguration4Class(Class clazz) {
return buildRedisCacheConfiguration(new Jackson2JsonRedisSerializer(clazz));
}
private RedisCacheConfiguration buildRedisCacheConfiguration4JavaType(Class collectionClazz, Class clazz) {
JavaType javaType = objectMapper.getTypeFactory().constructParametricType(collectionClazz, clazz);
return buildRedisCacheConfiguration(new Jackson2JsonRedisSerializer(javaType));
}
private RedisCacheConfiguration buildRedisCacheConfiguration(Jackson2JsonRedisSerializer jackson2JsonRedisSerializer) {
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.computePrefixWith(name -> name)
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer));
}
}
protobuf序列化:
package chen.huai.jie.springboot.cache.config;
import chen.huai.jie.springboot.cache.model.CacheConstants;
import chen.huai.jie.springboot.cache.proto.codec.ScoreListRedisSerializer;
import chen.huai.jie.springboot.cache.proto.codec.StudentRedisSerializer;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cache.CacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
/**
* @author chenhuaijie
*/
@Slf4j
@Profile("proto")
@Configuration
public class RedisProtoCacheConfig {
@Bean
public CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
return RedisCacheManager
.builder(RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory))
.withInitialCacheConfigurations(buildRedisCacheConfigurationMap())
.build();
}
private Map<String, RedisCacheConfiguration> buildRedisCacheConfigurationMap() {
Map<String, RedisCacheConfiguration> redisCacheConfigurationMap = new HashMap<>(3);
redisCacheConfigurationMap.put(CacheConstants.STUDENT_BY_ID, buildRedisCacheConfiguration(new StudentRedisSerializer()));
redisCacheConfigurationMap.put(CacheConstants.STUDENT_BY_NO, buildRedisCacheConfiguration(new StudentRedisSerializer()));
redisCacheConfigurationMap.put(CacheConstants.SCORE_LIST_BY_STUDENT_NO, buildRedisCacheConfiguration(new ScoreListRedisSerializer()));
return redisCacheConfigurationMap;
}
private RedisCacheConfiguration buildRedisCacheConfiguration(RedisSerializer redisSerializer) {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.computePrefixWith(name -> name)
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer));
}
}
补充一点:开发中遇到一个问题,就是清缓存的时候,事务还没有结束,缓存就清理掉了,导致数据不一致。很好解决设置transactionAware=true。
四、压测及数据
接下来我们用压测工具测试下性能和吞吐量:
单机的情况下:jvm内存给到2048m
200个线程跑500遍,一共10万个请求,每个场景取三次
redis-json的情况下:吞吐量大概在1500左右



redis-protobuf情况下:吞吐量在2000左右,在同等硬件资源及其他资源的情况下,protobuf凭借着出色的序列化性能,可以使我们的性能和吞吐量再提升33%,且占用更少的redis内存,同时我们需要付出的代价是:需要手工去实现protobuf每个类的序列化和反序列化,写入redis的数据也不像json一样具有可读性,因为都是二进制数组。如果有极致性能需要,这个也不失为一个精益求精的方案。



ehcache情况下:吞吐量在4800左右,进程级缓存省去了序列化反序列化和网络开销,速度可谓是一骑绝尘,但是要付出很大的代价,占用了过多的jvm内存,同时多实例的情况下,还需要借助第三方工作来同步各个实例的缓存数据,除非有非常严苛的要求,一般可以不考虑这种缓存方案。



谈谈我的这个方案是怎么解决常见的缓存问题的:
缓存穿透:采用了缓存null值得方式,此时缓存的时间应该尽量设置的小。
缓存击穿:为了防止大量线程同时涌入数据库查询,采用了分布式锁和Cacheable的sync=true结合的方式,保证了当大量线程查询同一个key的情况下,最终只有一个线程会查询到数据库。
缓存雪崩:我们的缓存配置某个缓存是定死的,无法做到每个key的缓存时间不同,如果是程序启动的时候加载了所有数据,大概率会在同一时刻全部失效,方案是在失效前进行一次reload.
大Key:将一个大的Key按照条件拆分为几个小的Key
热Key:进程级缓存+定期reload
总结:
性能优化是我们开发过程中非常重要的一项技能,
我们的终极目标是优化性能,但是在优化的过程中,我们也不能增加程序的复杂度,代码的复杂程度,我认为在缓存方案实施的过程中,除了追求我们要的极致性能体验外,程序的设计,代码的侵入性等方面我们也需要做进一步的思考,灵活多变。















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









