







1. redis介绍
1.1. 什么是redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求
Redis支持的键值数据类型
字符串类型
散列类型 (对应Java中的Object,它主要用来存储对象)
列表类型 (List)
集合类型 (Set)
有序集合类型。 (TreeSet)
1.2. redis的应用场景
缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多使用)
分布式集群架构中的session分离。
聊天室的在线好友列表。
任务队列。(秒杀、抢购、12306等等)
应用排行榜。
网站访问统计。
数据过期处理(可以精确到毫秒)
2. Redis的安装
2.1 在Windows上安装
Redis官方只提供了Linux和macos的版本,并没有提供Windows安装包,但是微软的github仓库中我们可以下载到Windows上可用的Redis程序包,但已经很久没有更新,建议仅用来作为开发练手,不要用于实际的生产环境中。
下载地址: https://github.com/microsoftarchive/redis/tags
下载后直接解压就可以用了
2.2 在Linux上安装
redis是C语言开发,建议在linux上运行,示例使用CentOS7作为安装环境。
-
安装redis需要先将官网下载的源码进行编译,编译依赖gcc环境,如果没有gcc环境,需要安装gcc
yum install gcc-c++阿里云的CentOS7默认已经内置了gcc,可以跳过这一步
-
下载redis
从官网下载
http://download.redis.io/releases/redis-5.0.5.tar.gz
将redis-5.0.5.tar.gz拷贝任意路径下,如 /home/john/opt/
-
解压源码
cd /home/john/opt/ tar -zxvf redis-5.0.5.tar.gz -
进入解压后的目录进行编译安装
cd /home/john/opt/redis-5.0.5/src make # 编译源代码 make install # 安装 # 上面两步也可以直接通过 make && make install两步并一步执行Redis默认的安装目录是/usr/local/bin, 我们在执行make install命令时添加prefix参数可修改默认安装位置,如: make PREFIX=/usr/local/redis install
3. redis单机启动
redis.conf是redis的配置文件,默认在redis源码包解压后的根目录有一份redis.conf文件,我们可将其拷贝一份到上一步中redis的安装目录
cp /home/john/opt/redis-5.0.5/src/redis.conf /usr/local/bin
我们装完redis以后,默认的安装路径是/usr/local/bin,系统会自动来此目录寻找命令,所以我们不需要在配置环境变量,在任意目录都可以使用redis相关的命令,如redis-server、redis-cli
3.1. 前端模式启动
启动命令:
redis-server /usr/local/bin/redis.conf
通过上面的命令启动,redis将以前端模式启动,前端模式启动的缺点是ssh命令窗口关闭则redis-server程序结束,不推荐使用此方法。
3.2. 后端模式启动
3.2.1 开启远程连接
配置文件(redis.conf)
- 注释掉 bind 127.0.0.1这行
- 关闭保护模式 将protected-mode yes 改成 protected-mode no
3.2.2 添加密码验证
放开 # requirepass foobared 这行注释,将后面的foobared改成你自己需要设置的密码
客户端连接时,需要添加-a 参数指定密码才能连上来。
3.2.3 开启后台守护进程运行模式
将 # daemonize no 这行放开注释, 并且改成 yes, Redis server将以后台方式运行。
3.2.4 指定日志文件
将 logfile “” 改成 logfile “你需要的redis日志文件名称”, 默认的空字符串代表输出到前端控制台(标准输出)
修改redis.conf配置文件, daemonize yes 以后端模式启动。
3.2.5 启动
启动命令和前端启动一样,只不过控制台不会输出任何信息,而且命令结束,如果没有异常会马上退出。
5. redis集群
5.1. 集群原理
5.1.1. redis-cluster架构图
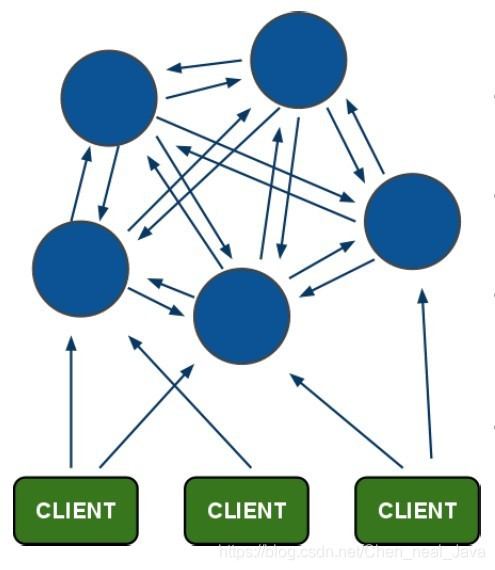
架构细节:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
- 节点的fail是通过集群中超过半数的节点检测失效时才生效.
- 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
5.1.2. redis-cluster投票:容错
!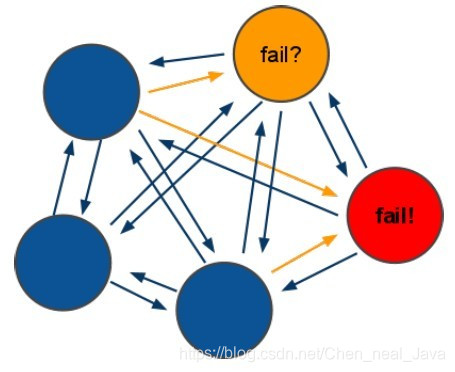
- 投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
- 什么时候整个集群不可用(cluster_state:fail)?
- 如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态
- 如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
5.3. 创建集群
5.3.1. 集群结点规划
这里在同一台服务器用不同的端口表示不同的redis服务器(伪集群),如下:
主节点:192.168.101.3:7001 192.168.101.3:7002 192.168.101.3:7003
从节点:192.168.101.3:7004 192.168.101.3:7005 192.168.101.3:7006
5.3.2 修改配置
修改redis.conf配置文件
port 7001 # 将每个节点的端口号改成不一样的(因为同一台机器上一个端口只能被一个进程绑定)
cluster-enabled yes #是否开启集群模式
cluster-config-file nodes.conf #集群配置文件名称
cluster-node-timeout 5000 #集群中节点间投票通信的超时时间
appendonly yes #配置集群中当前节点仅开启AOF持久化模式
pidfile /var/run/redis_7001.pid #将pid文件改成不同的名称,建议和当前节点的端口号对应
5.3.3 创建集群目录
在/usr/local下创建redis-cluster目录,其下创建7001、7002。。7006目录,如下:
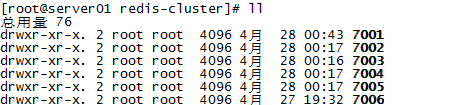
将redis安装目录bin下的文件拷贝到每个700X目录内,并且将配置文件也拷贝一份到每个700X目录
cp /usr/local/bin/redis/redis* /usr/local/redis-cluster/7001
cp /home/john/opt/redis-5.0.5/src/redis.conf /usr/local/redis-cluster/7001
修改每个700X目录下的redis.conf配置文件中的端口号和pid文件路径
5.3.4. 启动每个节点redis服务
进入/usr/local/redis_cluster目录下,编写启动集群脚本:start_redis_cluster.sh
cd /usr/local/redis_cluster
vim start_redis_cluster.sh
#!/bin/bash
work_dir=`pwd`
echo "开始启动redis集群中的每个节点"
for idx in {1..6}
do
cd $work_dir
cd "./700$idx" && ./redis-server ./redis.conf
if [ $? != 0 ]
then
echo "启动700$idx节点失败,停止启动集群"
exit 1
fi
echo "启动700$idx"
done
echo "所有集群节点启动完成"
编辑完成后,按ESC切换到命令模式, 输入ZZ 或者 :wq保存退出。(此处可能需要给此文件加权限!!)
启动Redis集群中所有节点
./start_redis_cluster.sh
查看redis进程:
ps aux | grep redis

5.3.4. 执行创建集群命令
Redis 5开始,集群不需要依赖Ruby,官方直接提供了集群管理支持
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 \
127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 \
--cluster-replicas 1
注意,这里用127.0.0.1仅适用于在本机练习集群搭建,真实环境下需要换成外公网IP,否则无法远程连接到你的redis集群
命令说明:
redis集群至少需要3个主节点,每个主节点有一个从节点总共6个节点
–cluster-replicas指定为1表示为集群中每个master都指定一个slave,也就是说上面6个节点会有3个主节点和对应的3个从节点
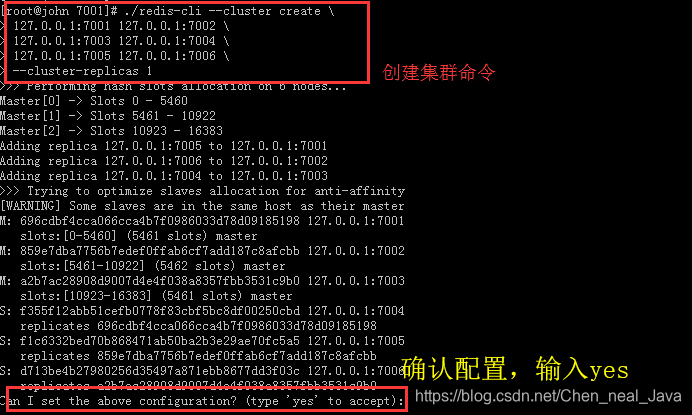
如果一切正常,最后会看到如下输出
[OK] All 16384 slots covered.
可能会遇到的错误
错误一:
如果创建redis集群的时候,ip用的是127.0.0.1,那么你在用Java客户端远程操作Redis集群的时候,会死活连不上,一直是报127.0.0.1:7001无法连接
解决办法:创建Redis集群时,创建命令中传入的节点IP参数列表使用外部可以访问的IP
错误二:
如果执行时报如下错误:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,如果不行则说明现在创建的节点包括了旧集群的结点信息,需要删除redis的持久化文件后再重启redis,比如:appendonly.aof、dump.rdb
5.4. 停止Redis集群
在/usr/local/redis_cluster目录下,创建脚本文件:stop_redis_cluster.sh
输入以下内容:
#!/bin/bash
work_dir=`pwd`
count=0
err_count=0
echo "开始停止redis集群"
for idx in {1..6}
do
cd $work_dir
cd "./700$idx" && ./redis-cli -c -p "700$idx" shutdown
if [ $? != 0 ]
then
echo "停止700$idx节点失败"
let err_count++
fi
echo "停止700$idx节点"
let count++
done
echo "Redis集群一共有$count个节点,成功停止`expr $count - $err_count`个节点,有$err_count个节点停止失败."
执行此脚本可以停止redis集群
5.5. 查询集群信息
集群创建成功登陆任意redis结点查询集群中的节点情况。
客户端以集群方式登陆:

说明:
./redis-cli -c -h 192.168.101.3 -p 7001,其中-c表示以集群方式连接redis,-h指定ip地址,-p指定端口号
5.5.1 查看集群状态相关命令
cluster nodes 查询集群结点信息
cluster info 查询集群状态信息
5.6. 添加主节点
集群创建成功后可以向集群中添加节点,下面是添加一个master主节点
添加7007节点,参考集群节点规划章节添加一个“7007”目录作为新节点。
Redis 5 添加主节点命令:
语法:
redis-cli –cluster add-node 要添加节点的ip:端口 集群中当前存在的任何一个节点的ip和端口
示例:
redis-cli --cluster add-node 10.10.14.166:7006 10.10.14.166:7000
输出结果
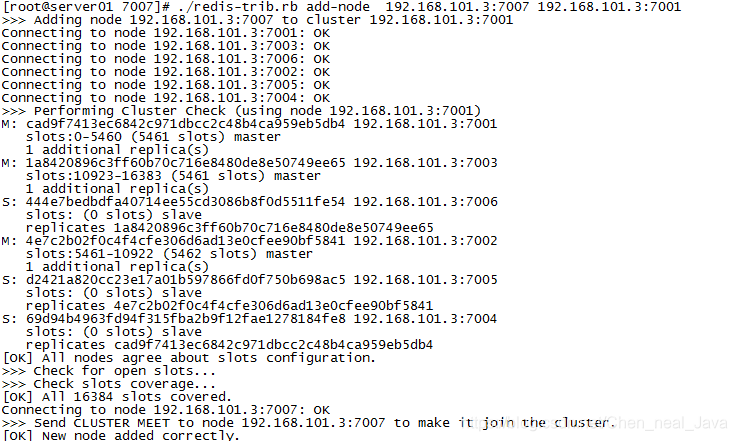
查看集群结点发现7007已添加到集群中:

注意:新添加的master node有以下两个特征
- 由于它没有分配hash槽,所以该节点无法存储任何数据
- 由于它没有分配hash槽,所以在其他从节点要升级成主节点的过程中,该节点不参与投票(没有投票权)
5.6.1. hash槽重新分配
添加完主节点需要对主节点进行hash槽分配这样该主节才可以存储数据。
redis集群有16384个槽,集群中的每个结点分配自已的槽,通过查看集群结点(cluster nodes命令)可以看到槽占用情况。 可以看到新添加的7007节点并没有分配到hash槽
给刚添加的7007结点分配槽
第一步:连接上集群
redis-cli --cluster reshard 127.0.0.1:7001 #(连接集群中任意一个可用结点就行)
第二步:输入要分配的槽数量
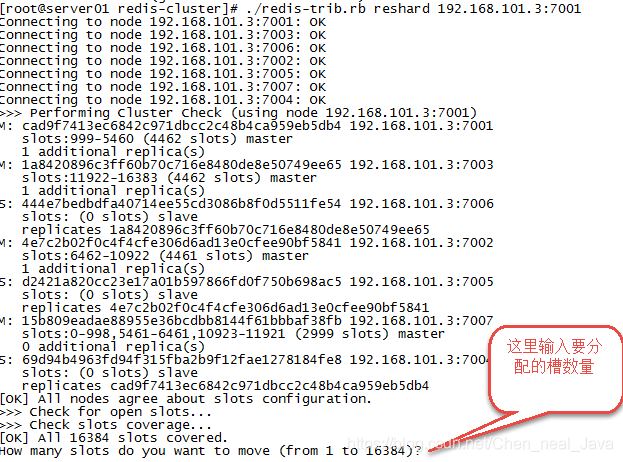
输入 500表示分配500个槽
第三步:输入接收槽的结点id
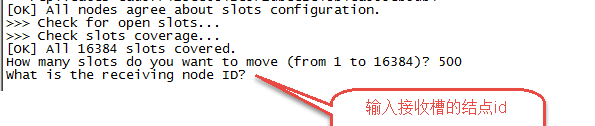
这里准备给7007分配槽,通过cluster nodes查看7007结点id为15b809eadae88955e36bcdbb8144f61bbbaf38fb
输入:15b809eadae88955e36bcdbb8144f61bbbaf38fb
第四步:输入源结点id
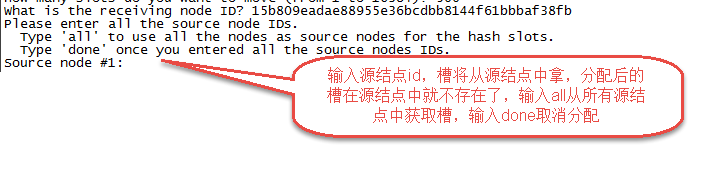
这里输入all
第五步:输入yes开始移动槽到目标结点id

至此,新添加的7007 master节点的hash槽就分配完毕,可以存储数据了!
关于Redis 集群的hash slots相关知识,可以参阅:
5.7. 添加从节点
集群创建成功后可以向集群中添加节点,下面是添加一个slave从节点。
添加7008从结点,将7008作为7007的从结点。
Redis 5中添加从节点命令:
语法:
redis-cli –cluster add-node 要添加节点的ip:端口 集群中任意已有master的ip和端口 --cluster-slave [--cluster-master-id masterid]
示例:
添加一个从节点,不指定目标主节点
redis-cli --cluster add-node 10.10.14.166:7008 10.10.14.166:7001 --cluster-slave
注意:该命令只是向集群中添加了一个从节点,但并没有指名要作为哪个master node的从节点,Redis集群会将其添加到集群中随机挑一个从节点较少的master node上,作为其从节点
添加一个从节点,并指定所属主节点
redis-cli --cluster add-node 10.10.14.166:7008 10.10.14.166:7001 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
我们通过增加了一个cluster-master-id参数,指定从节点要添加到哪个主节点上。主节点的ID可以通过cluster nodes查看到
注意:如果原来该结点在集群中的配置信息已经生成cluster-config-file指定的配置文件中(如果cluster-config-file没有指定则默认为nodes.conf),这时可能会报错:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,删除后再执行添加从节点指令
查看集群中的结点可以发现,刚添加的7008为7007的从节点
5.8. 删除结点:
Redis5以后删除节点命令:
语法:
redis-cli --cluster del-node ip:port node_id
注:上面的ip:port为集群中存在的任意节点,node_id是你要删除的节点的id
示例:
redis-cli --cluster del-node 10.10.14.166:7001 d3b977fd46386db84fd85b9240deb602087c8617
删除已经占有hash槽的结点会失败,报错如下:
[ERR] Node 127.0.0.1:7005 is not empty! Reshard data away and try again.
需要将该结点占用的hash槽分配出去(参考hash槽重新分配章节)。
6. Redis持久化策略
6.1 RDB快照模式
缺省情况情况下,Redis把数据快照存放在磁盘上的二进制文件中,文件名为dump.rdb。你可以配置Redis的持久化策略,例如数据集中每N秒钟有超过M次更新,就将数据写入磁盘;或者你可以手工调用命令SAVE或BGSAVE。
6.1.1 工作步骤
- Redis forks;
- 子进程开始将数据写到临时RDB文件中;
- 当子进程完成写RDB文件,用新文件替换老文件;
- 当RedisServer重新启动时,读取RDB文件恢复到内存中。
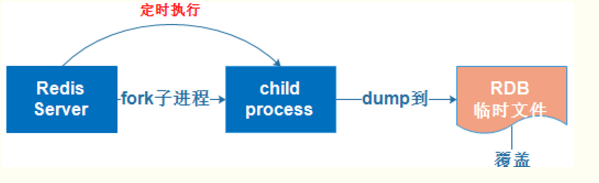
6.1.2 配置参数
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
# save "" # 将上面三个配置注释掉,只保留一个save "", 代表禁用RDB快照模式
6.2 AOF模式
快照模式并不十分健壮,当系统停止,或者无意中Redis被kill掉,最后写入Redis的数据就会丢失。这对某些应用也许不是大问题,但对于要求高可靠性的应用来说,
Redis就不是一个合适的选择。
Append-only-file 模式是另一种选择。
你可以在配置文件中打开AOF模式
6.2.1 工作步骤
- Redis客户端发送读写命令
- RedisServer接收并执行命令,同时同步记录命令到AOF文件中
- Redis重新启动时读取AOF文件,执行其中每一条指令完成数据恢复

6.2.2 配置参数
# appendfsync always # 命令过来后,立刻写入AOF文件(会强制flush操作系统IO缓冲)
appendfsync everysec # 默认策略, 每秒钟将缓存的命令写入到AOF文件中
# appendfsync no # 关闭AOF备份
6.3 RDB模式与AOF模式的对比
6.3.1 RDB模式的优点
- 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
- 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
- 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
- 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
6.3.2 RDB模式的缺点
- 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
- 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
6.3.3 AOF模式的优点
- 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
- 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
- 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
6.3.4 AOF模式的缺点
- 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
二者选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 eventually consistent的意思了。
如果RDB文件和AOF同时存在,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件完整
7. 通过SpringBoot操作redis
注: 下面的教程以最新的SpringBoot版本 2.2.0为例
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.0.RELEASE</version>
</parent>
7.1. SringBoot操作单机版Redis
7.1.1 引入依赖
<!-- SpringBoot2以后,默认的redis客户端已经由jedis改成了lettuce,下面依赖会把lettuce-core也添加进来 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 如果项目中用到了redis连接池,需要添加如下依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
7.1.2 SpringBoot配置
application.yml
spring:
redis:
host: www.taotao.com
# port: 6379 # 如果端口号不是默认端口需要制定
# password: xxx # 如果redis服务端开启了口令验证,需要添加
lettuce:
pool: # 如果使用redis连接池,需要添加apche的common-pool2依赖
max-idle: 2
max-wait: 1000ms
7.1.3. Java代码
通过创建单实例jedis对象连接redis服务,如下代码:
@Slf4j
@SpringBootTest
public class TestRedisClient {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
public void testRedis() {
Set<String> keys = redisTemplate.keys("*");
log.info("操作前存在的keys: " + keys);
String key = "lanou_F4";
redisTemplate.opsForList().rightPushAll(key, new String[]{"宋超", "国胜", "国伟", "高飞"});
long size = redisTemplate.opsForList().size(key);
log.info("当前"+key+"值的数量: " + size);
List<String> values = redisTemplate.opsForList().range(key, 0, size);
log.info("当前" + key +"的值: " + values);
keys = redisTemplate.keys("*");
log.info("操作后存在的keys: " + keys);
}
}
7.2. SpringBoot操作Redis集群
7.2.1. 引入依赖
<dependencies>
<!-- 添加spring-boot-starter-data-redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<!-- 排除掉lettuce客户端相关依赖 -->
<!-- lettuce客户端连接阿里云上自建的redis集群会有连接超时的问题 -->
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 替换成jedis客户端 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<!-- redis连接池依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
</dependencies>
7.2.2. SpringBoot配置
application.yml
spring:
redis:
jedis:
pool: # 配置redis连接池相关参数
max-idle: 2
max-active: 10
min-idle: 1
cluster:
nodes: teacher.lanou.com:7001,teacher.lanou.com:7002,teacher.lanou.com:7003,teacher.lanou.com:7004,teacher.lanou.com:7005,teacher.lanou.com:7006
7.2.3. Java代码
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
public void testPutKV() {
ValueOperations<String, String> ops = redisTemplate.opsForValue();
ops.set("name", "张三");
String name = ops.get("name");
Assertions.assertEquals("张三", name, "应该返回张三");
}
@Test
public void testOpsForList() {
ListOperations<String, String> ops = redisTemplate.opsForList();
ops.rightPush("yanfa3", "王康健");
ops.leftPush("yanfa3", "于漫漫");
ops.rightPushAll("yanfa3", "李光", "星辰", "鹏杰", "士军");
Assertions.assertEquals(6, ops.size("yanfa3"), "应该是由6个元素才对");
List<String> stuNames = ops.range("yanfa3", 0, -1);
stuNames.forEach((v) -> {
System.out.println(v);
});
}
}
集群模式只是依赖和配置不同,在代码中使用的API没有什么区别
7.3. 外部连接不上redis的解决方法
由于linux防火墙默认开启,redis的服务端口6379并不在开放规则之内,所有需要将此端口开放访问或者关闭防火墙。
查看防火墙状态:sevice iptables status
关闭防火墙命令:sevice iptables stop
如果是修改防火墙规则,可以修改:/etc/sysconfig/iptables文件
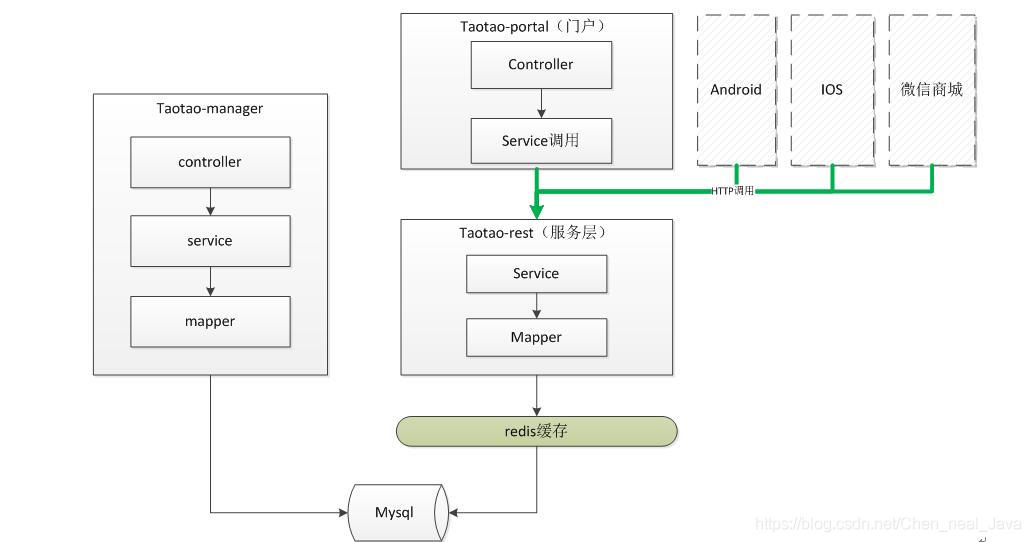
8. 系统添加缓存逻辑示例
添加缓存逻辑的原则:缓存逻辑不能影响正常的业务逻辑执行。
8.1. 添加缓存后系统架构

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









