









- 概念
数据降维基本原理是将样本点从输入空间通过线性或非线性变换映射到一个低维空间,从而获得一个关于原数据集紧致的低维表示。
- 为什么要降维:
在原始的高维空间中,包含有冗余信息记忆噪声信息;feature太多会造成模型复杂,训练速度过慢,因此我们引入降维;多维数据很难进行可视化分析,因此我们需要降维分析。例如淘宝店铺的数据,“浏览量”访客数往往有较强的相关关系,如果删除其中一个指标,应该期待并不会丢失太多信息,从而降低机器学习算法的复杂度。
- 降维本质:
学习一个映射函数 F:XàY,其中 ,其中 X是原始数据点的表达,目前最多使用向量形式。
- 常用降维算法:
PCA---主成分析法 (Principal componentanalysis),常用线性降维方法
LDA---线性判别分析 (Linear Discriminant Analysis)
LLE---局部线性嵌入 (Locally Linear Embedding)
LaplacianEigenmaps --- 拉普斯特征映射
- PCA(principal component analysis)主成分分析
- 基本思想:
最常用的线性降维方法,它目标通过某种投影将高的数据映射到低维空间中表示,并期望在所投影的维度上数据方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。(一种直观的看法是:希望投影后的投影值尽可能分散。而这种分散程度,可以用数学上的方差来表述。)
- 算法流程:
假设有 m个samples(x(1),x(2),……,x(m)),每个数据有n个特征 x(1)= [x1(1), x2(1), x3(1),……, xn(1)]
- 数据预处理
1)计算各个feature的平均值,记为μj ;(Xj(i)表示第i个样本的第j维特征的valueμj = Σm Xj(i)/m
2)将每一个featurescaling:将在不同scale上的feature进行归一化(只有训练样本获得相应参数)
3)将特征进行 zero mean normalization 零均值归一化令 Xj(i)= (Xj(i)-μj)/sj
- PCA算法选取 k个主分量
1)求 N×N的协方差矩阵 Σ
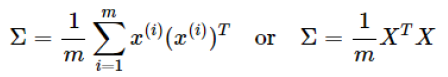
2)根据 SVD奇异值分解求取特征值和特征向量 [U,S,V] = SVD(Σ) Σ = USV’=USU’
目的:从 N维降到 K维,即选出这 N个特征中最重要的 K个
3)按特征值从大到小排列,重新组织 U
4)选择 K个分类
- 从压缩数据汇总恢复原始数据
Xapprox = (U')-1×z = (U-1)-1×z = UZ
这里恢复出的 xapprox并不是原先的 x,而是向量 x的近似值
- 如何决定降维个数/主成分个数
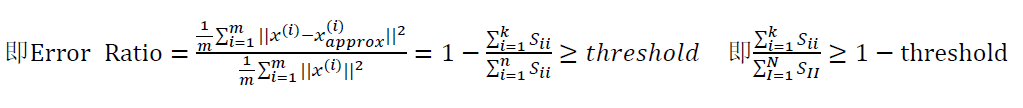
- 应用 PCA进行降维的建议
1)应用 PCA提取主成分可能会解决一些overfitting的问题,但是不建议使用这种方法解决 overfitting的问题,建议加入 regularization项(也称 ridgeregression)来解决
2)PCA选择主成分的时候只应用 选择主成分的时候只应用 training data
3)只有当在原数据上跑到了一个比较好的结果,但又嫌它太慢时候才采取PCA进行降维
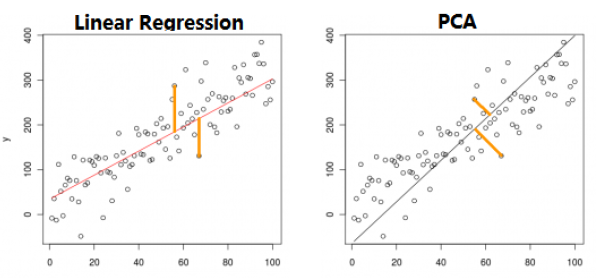
- PCA与 Linear Regression的区别
PCA cost function:样本点到拟合线的垂直距离
Linear Regresiion:计算样本上线垂直到拟合的距离
- PCA算法 Python实现:
函数: Scikit-Learn中 sklearn.decomposition.PCA(n_components=None, copy=True,whiten=False)
参数说明:
- n_components
含义: PCA算法中所要保留的主成分个数n,也即保留下来的特征个数。可以是设置解释变量的比例。如: pca =PCA(n_components=.98)
类型:int或者string,缺省时默认为 None,所有成分保留
intà比如 n_components=1,将 把原始数据降到一个维度
stringàn_components=’mle’,将自动选取特征个数n,使得满足所要求的方差百分比
- Ÿ copy
含义:表示是否在运行算时,将原始数据复制一份若为 True,则在副本上运行PCA算法后,原始数据的值不会有任何改变
类型: bool,True 或者 False,缺省时默认为 True
- Ÿ Written
1.含义:使得每个特征具有相同的方差
2.类型: bool,缺省时默认为 False
fromsklearn.decomposition import PCA
importnumpy as np
importpandas as pd data=np.random.randn(10,4)
#array([[2.27793149, 0.41199224, -1.80281988, 0.72065799],
#[-0.80082211, 0.04550286, -0.70304146, 0.42561992],
#[-0.16401835, -0.75932542, -0.81129943, 0.13719183],
# [0.20487482, -0.98320166, 1.04128367, 2.85097795],
# [ 1.29263802, -0.54013543, -0.19102035,-1.4808882 ],
# [0.03716913, -2.08803088, 2.18752182, 0.28308089],
# [0.33470243, 0.76565395, 0.91381749, -0.63045713],
# [0.7814005 , 0.46238208, 0.76730049, 1.5696756 ],
# [ 0.30049055, -2.04246298, -0.15875265,0.79178319],
#[-0.4805177 , 0.595143 , 1.08569314, -1.74164893]])
pca=PCA()
pca.fit(data)
pca.components_
#返回模型的各个特征向量
#array([[-0.06417142, -0.44346869, 0.24356304, 0.86017126],
# [-0.44837036, -0.23987254, 0.77443235, -0.37640367],
# [ 0.08925189, -0.86101597, -0.37581387, -0.3308316 ],
# [-0.88706265, 0.06669478, -0.44687305, 0.09474246]])pca.explained_variance_ratio_
#返回各个成分各自的方差百分比(贡献率)
#array([ 0.40107547, 0.33304522, 0.15769605, 0.10818325])
#重新建立 PCA模
pca=PCA(3)
pca.fit(data)low_d=pca.transform(data)
#用这个方法来降低维度
pd.DataFrame(low_d).to_excel('result.xlsx')
#保存结果 pca.inverse_transform(low_d)
#必要时,可以用这个函数来复原数据















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









