









- 概念
逻辑回归就是这样的一个过程:面对或者分类问题,建立代价函数然后通优化方法迭代求解出最优的模型参数,然后测试验证我们这个好坏。
- Regression常规步骤
Ÿ寻找h函数(即预测函数);
Ÿ构造 J函数(损失);函数(损失);
Ÿ想办法使得 J函数最小并求得回归参(θ)
- 构造预测函数h:
logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
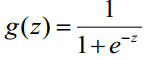
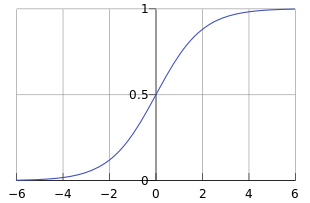
对于线性边界的情况,边界形式如下:

构造预测函数为:
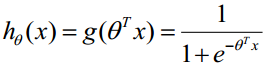
函数h(x)的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
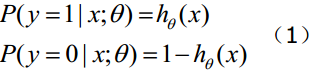
- 构造损失函数J:
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。
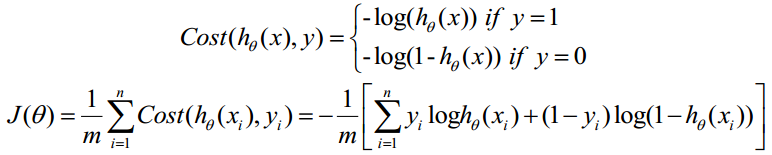
下面详细说明推导的过程:
(1)式综合起来可以写成
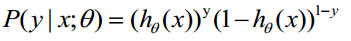
取似然函数为:
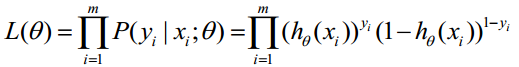
对数似然函数为:
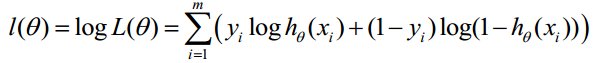
最大似然估计就是求使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。(最大似然概率,就是在已知观测的数据的前提下,找到使得似然概率最大的参数值。)
但是,在Andrew Ng的课程中将J(θ)取为下式,即:
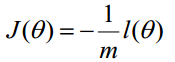
因为乘了一个负的系数-1/m,所以取J()最小值时的θ为要求的最佳参数。
- 梯度下降法求的最小值
θ更新过程:
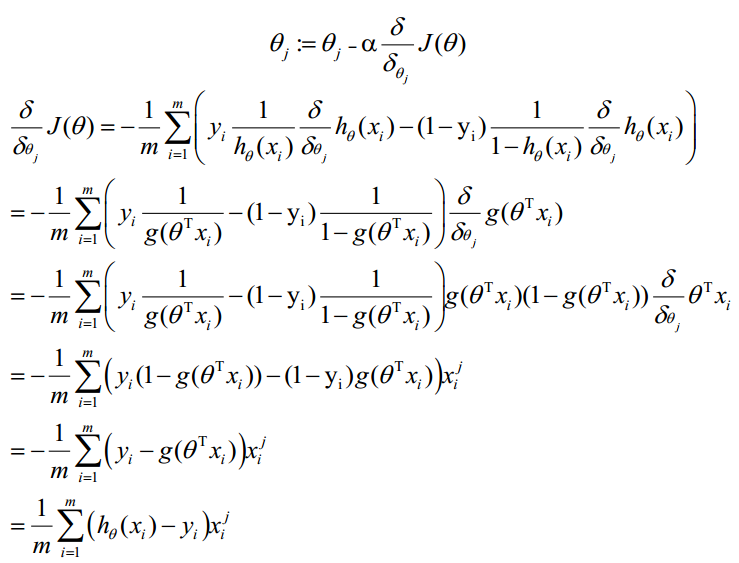
θ更新过程可以写成:

- 向量化 Vectorization
Vectorization是使用矩阵计算来代替 for循环,以简化计算过程提高效率。如上式,Σ(...)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization。
下面介绍向量化的过程:
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:

g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知h(x)-y,可由g(A)-y一次计算求得。θ更新过程可以改为:
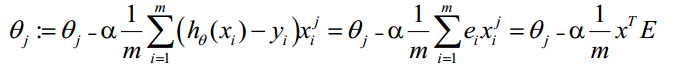
综上所述,Vectorization后θ更新的步骤如下:
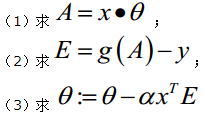
- python算法包实现逻辑回归
- 使用的算法包:
numpy: Python的语言扩展,定义了数字的数组和矩阵
pandas: 直接处理和操作数据的主要package
statsmodels: 统计和计量经济学的package,包含了用于参数评估和统计测试的实用工具
pylab: 用于生成统计图
- 逻辑回归的实例<http://www.powerxing.com/logistic-regression-in-python/>
辨别不同的因素对研究生录取的影响。数据集中的前三列可作为预测变量(predictorvariables):gpa/gre分数/rank表示本科生母校的声望。第四列admit则是二分类目标变量(binary targetvariable),它表明考生最终是否被录用。
- 加载数据
使用 pandas.read_csv加载数据,这样我们就有了可用于探索数据的DataFrame
import pandas as pd
import statsmodels.apias sm
import pylab as pl
import numpy as np
# 加载数据
# 备用地址: http://cdn.powerxing.com/files/lr-binary.csv
df = pd.read_csv("http://www.ats.ucla.edu/stat/data/binary.csv")
# 浏览数据集
print df.head()
# admit gre gpa rank
# 0 0 380 3.61 3
# 1 1 660 3.67 3
# 2 1 800 4.00 1
# 3 1 640 3.19 4
# 4 0 520 2.93 4
#重命名'rank'列,因为dataframe中有个方法名也为'rank'
df.columns = ["admit", "gre", "gpa", "prestige"]
print df.columns
# array([admit, gre, gpa,prestige], dtype=object)
- 统计摘要(Summary Statistics) 以及 查看数据
现在我们就将需要的数据正确载入到Python中了,现在来看下数据。我们可以使用pandas的函数describe来给出数据的摘要–describe与R语言中的summay类似。这里也有一个用于计算标准差的函数std,但在describe中已包括了计算标准差。我特别喜欢pandas的pivot_table/crosstab聚合功能。crosstab可方便的实现多维频率表(frequencytables)(有点像R语言中的table)。你可以用它来查看不同数据所占的比例。
# summarize the data
print df.describe()
# admit gre gpa prestige
# count 400.000000 400.000000400.000000 400.00000
# mean 0.317500 587.7000003.389900 2.48500
# std 0.466087 115.5165360.380567 0.94446
# min 0.000000 220.0000002.260000 1.00000
# 25% 0.000000 520.0000003.130000 2.00000
# 50% 0.000000 580.0000003.395000 2.00000
# 75% 1.000000 660.0000003.670000 3.00000
# max 1.000000 800.0000004.000000 4.00000
# 查看每一列的标准差
print df.std()
# admit 0.466087
# gre 115.516536
# gpa 0.380567
# prestige 0.944460
# 频率表,表示prestige与admin的值相应的数量关系
print pd.crosstab(df['admit'], df['prestige'],rownames=['admit'])
# prestige 1 2 3 4
# admit
# 0 28 97 93 55
# 1 33 54 28 12
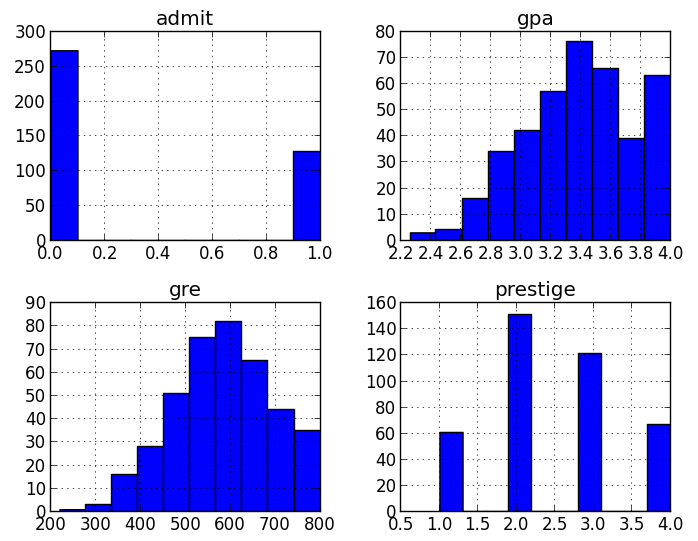
# plot all of the columns
df.hist()
pl.show()
- 虚拟变量(dummy variables)
虚拟变量,也叫哑变量,可用来表示分类变量、非数量因素可能产生的影响。在计量经济学模型,需要经常考虑属性因素的影响。例如,职业、文化程度、季节等属性因素往往很难直接度量它们的大小。只能给出它们的“Yes—D=1”或”No—D=0”,或者它们的程度或等级。为了反映属性因素和提高模型的精度,必须将属性因素“量化”。通过构造0-1型的人工变量来量化属性因素。
pandas提供了一系列分类变量的控制。我们可以用get_dummies来将”prestige”一列虚拟化。
get_dummies为每个指定的列创建了新的带二分类预测变量的DataFrame,在本例中,prestige有四个级别:1,2,3以及4(1代表最有声望),prestige作为分类变量更加合适。当调用get_dummies时,会产生四列的dataframe,每一列表示四个级别中的一个。
# 将prestige设为虚拟变量
dummy_ranks = pd.get_dummies(df['prestige'],prefix='prestige')
print dummy_ranks.head()
# prestige_1 prestige_2prestige_3 prestige_4
# 0 0 0 1 0
# 1 0 0 1 0
# 2 1 0 0 0
# 3 0 0 0 1
# 4 0 0 0 1
# 为逻辑回归创建所需的data frame
#除admit、gre、gpa外,加入了上面常见的虚拟变量(注意,引入的虚拟变量列数应为虚拟变量总列数减1,减去的1列作为基准)
cols_to_keep = ['admit', 'gre', 'gpa']
data = df[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])
print data.head()
# admit gre gpa prestige_2prestige_3 prestige_4
# 0 0 380 3.61 0 1 0
# 1 1 660 3.67 0 1 0
# 2 1 800 4.00 0 0 0
# 3 1 640 3.19 0 0 1
# 4 0 520 2.93 0 0 1
# 需要自行添加逻辑回归所需的intercept变量
data['intercept'] = 1.0
这样,数据原本的prestige属性就被prestige_x代替了,例如原本的数值为2,则prestige_2为1,prestige_1、prestige_3、prestige_4都为0。将新的虚拟变量加入到了原始的数据集中后,就不再需要原来的prestige列了。在此要强调一点,生成m个虚拟变量后,只要引入m-1个虚拟变量到数据集中,未引入的一个是作为基准对比的。最后,还需加上常数intercept,statemodels实现的逻辑回归需要显式指定。
- 执行逻辑回归
实际上完成逻辑回归是相当简单的,首先指定要预测变量的列,接着指定模型用于做预测的列,剩下的就由算法包去完成了。
本例中要预测的是admin列,使用到gre、gpa和虚拟变量prestige_2、prestige_3、prestige_4。prestige_1作为基准,所以排除掉,以防止多元共线性(multicollinearity)和引入分类变量的所有虚拟变量值所导致的陷阱(dummy variable trap)。
# 指定作为训练变量的列,不含目标列`admit`
train_cols = data.columns[1:]
# Index([gre, gpa, prestige_2,prestige_3, prestige_4], dtype=object)
logit = sm.Logit(data['admit'], data[train_cols])
# 拟合模型
result = logit.fit()
在这里是使用了statesmodels的Logit函数,更多的模型细节可以查阅statesmodels的文档
- 使用训练模型预测数据
通过上述步骤,我们就得到了训练后的模型。基于这个模型,我们就可以用来预测数据。
# 构建预测集
# 与训练集相似,一般也是通过 pd.read_csv() 读入
# 在这边为方便,我们将训练集拷贝一份作为预测集(不包括 admin 列)
import copy
combos = copy.deepcopy(data)
# 数据中的列要跟预测时用到的列一致
predict_cols = combos.columns[1:]
# 预测集也要添加intercept变量
combos['intercept'] = 1.0
# 进行预测,并将预测评分存入 predict 列中
combos['predict'] = result.predict(combos[predict_cols])
# 预测完成后,predict 的值是介于 [0, 1]间的概率值
# 我们可以根据需要,提取预测结果
# 例如,假定 predict > 0.5,则表示会被录取
# 在这边我们检验一下上述选取结果的精确度
total = 0
hit = 0
for value in combos.values:
# 预测分数 predict, 是数据中的最后一列
predict = value[-1]
# 实际录取结果
admit = int(value[0])
# 假定预测概率大于0.5则表示预测被录取
if predict > 0.5:
total += 1
# 表示预测命中
if admit == 1:
hit += 1
# 输出结果
print 'Total: %d, Hit: %d, Precision: %.2f' % (total, hit, 100.0*hit/total)
# Total: 49, Hit: 30, Precision:61.22
- 结果解释
statesmodels提供了结果的摘要,如果你使用过R语言,你会发现结果的输出与之相似
# 查看数据的要点
print result.summary()
Logit Regression Results
==============================================================================
Dep. Variable: admit No. Observations: 400
Model: Logit Df Residuals: 394
Method: MLE Df Model: 5
Date: Sun, 03 Mar 2013 Pseudo R-squ.: 0.08292
Time: 12:34:59 Log-Likelihood: -229.26
converged: True LL-Null: -249.99
LLR p-value: 7.578e-08
==============================================================================
coef std err z P>|z| [95.0% Conf. Int.]
------------------------------------------------------------------------------
gre 0.0023 0.001 2.070 0.038 0.000 0.004
gpa 0.8040 0.332 2.423 0.015 0.154 1.454
prestige_2 -0.6754 0.316 -2.134 0.033 -1.296 -0.055
prestige_3 -1.3402 0.345 -3.881 0.000 -2.017 -0.663
prestige_4 -1.5515 0.418 -3.713 0.000 -2.370 -0.733
intercept -3.9900 1.140 -3.500 0.000 -6.224 -1.756
==============================================================================
你可以看到模型的系数,系数拟合的效果,以及总的拟合质量,以及一些统计度量。[待补充:模型结果主要参数的含义]当然你也可以只观察结果的某部分,如置信区间(confidence interval)可以看出模型系数的健壮性。
# 查看每个系数的置信区间
printresult.conf_int()
# 0 1
# gre 0.000120 0.004409
# gpa 0.153684 1.454391
# prestige_2 -1.295751 -0.055135
# prestige_3 -2.016992 -0.663416
# prestige_4 -2.370399 -0.732529
# intercept -6.224242 -1.755716
在这个例子中,我们可以肯定被录取的可能性与应试者毕业学校的声望存在着逆相关的关系。
换句话说,高排名学校(prestige_1==True)的湘鄂生呗录取的概率比低排名学校(prestige_4==True)要高。
- 相对危险度(odds ratio)
使用每个变量系数的指数来生成odds ratio,可知变量每单位的增加、减少对录取几率的影响。例如,如果学校的声望为2,则我们可以期待被录取的几率减少大概50%。UCLA上有一个对oddsratio更为深入的解释:在逻辑回归中如何解释oddsratios?。
# 输出 odds ratio
printnp.exp(result.params)
# gre 1.002267
# gpa 2.234545
# prestige_2 0.508931
# prestige_3 0.261792
# prestige_4 0.211938
# intercept 0.018500
我们也可以使用置信区间来计算系数的影响,来更好地估计一个变量影响录取率的不确定性。
# odds ratios and 95% CI
params = result.params
conf = result.conf_int()
conf['OR'] = params
conf.columns = ['2.5%', '97.5%', 'OR']
print np.exp(conf)
# 2.5% 97.5% OR
# gre 1.000120 1.004418 1.002267
# gpa 1.166122 4.281877 2.234545
# prestige_2 0.273692 0.9463580.508931
# prestige_3 0.133055 0.5150890.261792
# prestige_4 0.093443 0.4806920.211938
# intercept 0.001981 0.1727830.018500
- 小结
逻辑回归是用于分类的优秀算法,尽管有一些更加性感的,或是黑盒分类器算法,如SVM和随机森林(RandomForest)在一些情况下性能更好,但深入了解你正在使用的模型是很有价值的。很多时候你可以使用随机森林来筛选模型的特征,并基于筛选出的最佳的特征,使用逻辑回归来重建模型。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









