







python爬虫系列
文章目录
前言
本文将介绍如何使用scrapy框架,简单爬取豆瓣、比特大熊电影网站数据。
一、目标站点分析
1.1豆瓣网

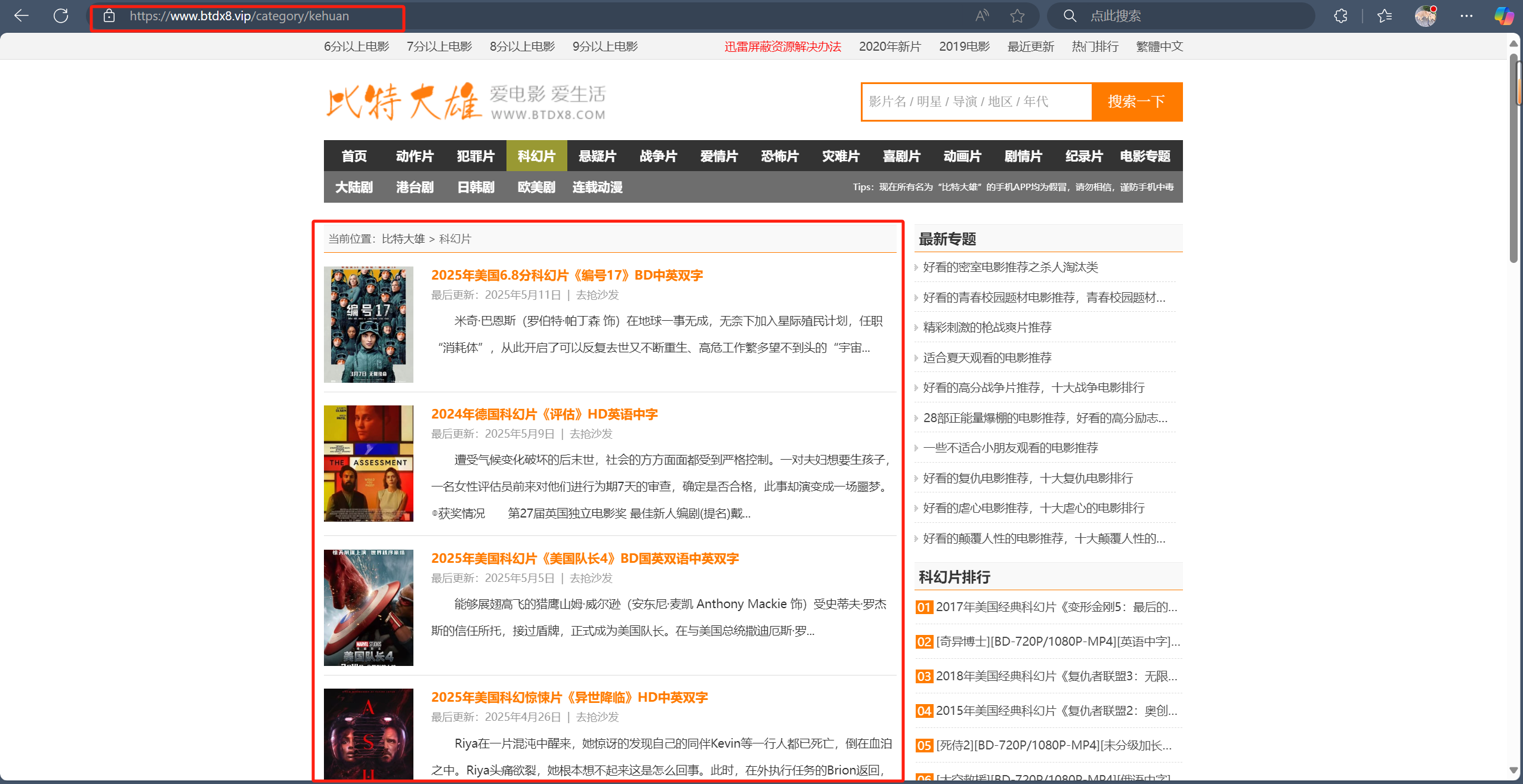
1.2比特大熊
二、项目配置
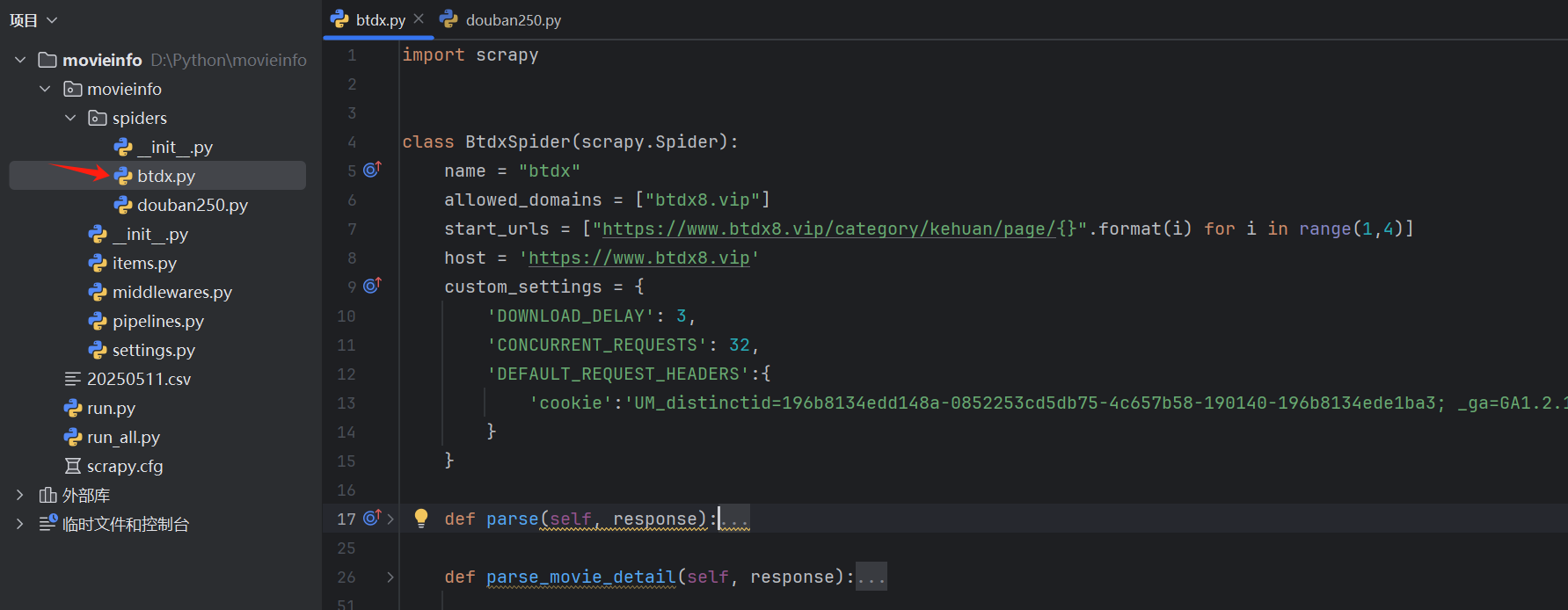
2.1 目录结构
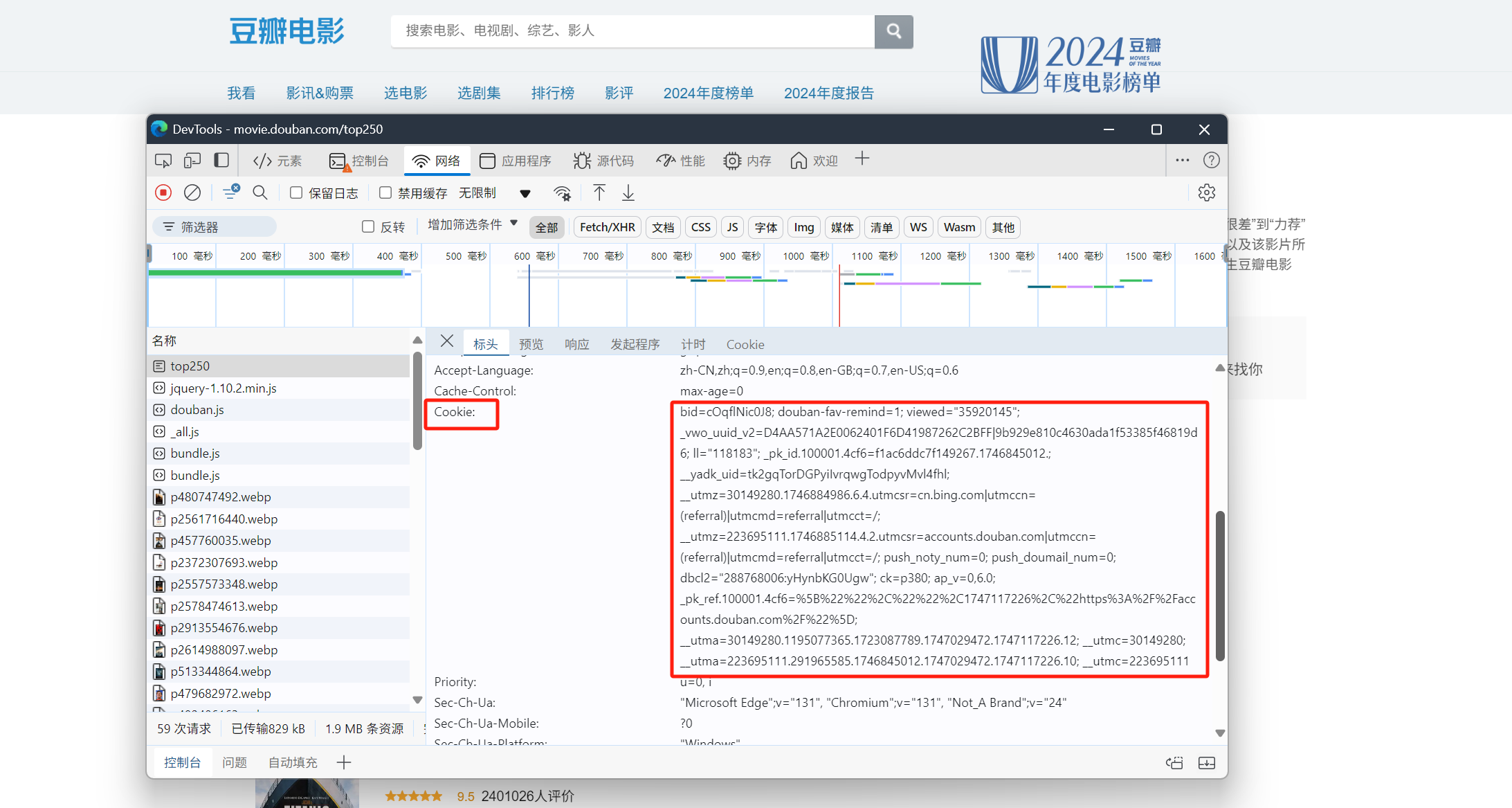
2.2 绕过登录校验
提示:有些网站可能需要登录才能访问,需要携带cookie,以豆瓣网为例:
2.1 豆瓣top250
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com/top250"]
custom_settings = {
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 2,
'DEFAULT_REQUEST_HEADERS':{
'cookie':'目标站点cookie'
}
}
2.2 btdx8.vip
name = "btdx"
allowed_domains = ["btdx8.vip"]
start_urls = ["https://www.btdx8.vip/category/kehuan/page/{}".format(i) for i in range(1,4)]
host = 'https://www.btdx8.vip'
custom_settings = {
'DOWNLOAD_DELAY': 3,
'CONCURRENT_REQUESTS': 32,
'DEFAULT_REQUEST_HEADERS':{
'cookie':'目标站点cookie'
}
}
三、目标站点爬取
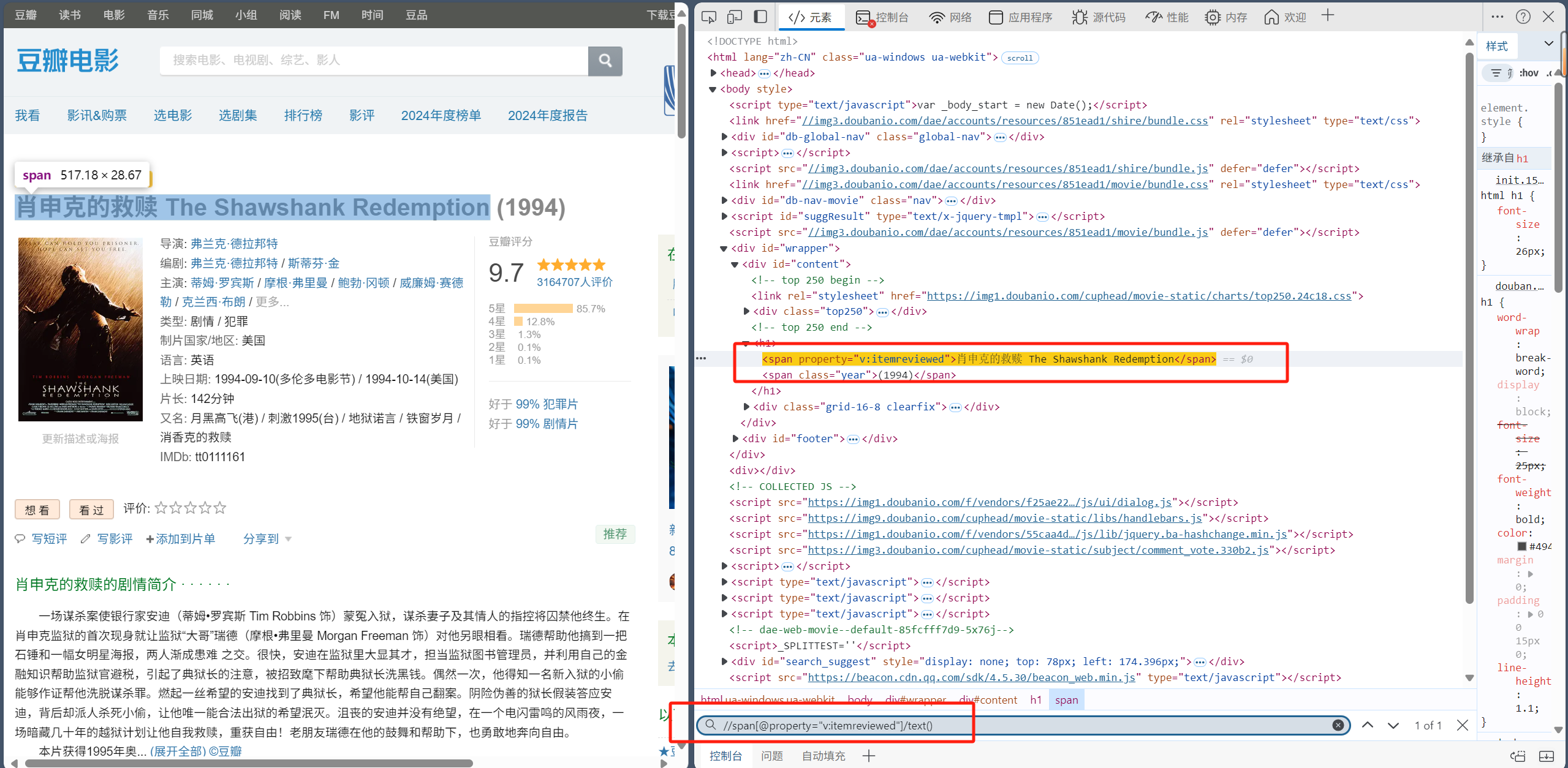
3.1 xpath语法解析
3.2 获取豆瓣电影数据
3.2.1 数据格式处理
item = {}
item['title'] = response.xpath('.//span[@property="v:itemreviewed"]/text()').get()
item['director'] = " ".join(response.xpath('.//div[@id="info"]/span[1]/span[2]/a/text()').extract())
item['actor'] = " ".join(response.xpath('.//div[@id="info"]/span[2]/span[2]/a/text()').extract())
item['duration'] = response.xpath('.//span[@property="v:runtime"]/text()').get()
item['movie_image'] = response.xpath('.//div[@id="mainpic"]/a/img/@src').get()
item['rating'] = response.xpath('.//strong[@property="v:average"]/text()').get()
item['release time'] = " ".join(response.xpath('.//span[@property="v:initialReleaseDate"]/text()').extract())
item['type'] = " ".join(response.xpath('.//span[@property="v:genre"]/text()').extract())
item['language'] = ''
item['info_source'] = response.xpath('.//div[@id="info"]').get()
3.2.2 返回数据
{
'title': '肖申克的救赎 The Shawshank Redemption',
'director': '弗兰克·德拉邦特', 'actor': '弗兰克·德拉邦特 斯蒂芬·金', 'duration': '142分钟',
'movie_image': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg', 'rating': '9.7',
'release time': '1994-09-10(多伦多电影节) 1994-10-14(美国)',
'type': '剧情 犯罪',
'language': '中文'
}
3.3 获取比特大熊电影数据
3.2.1 数据格式处理
information_list = response.xpath('.//div[@id="movie_info"]//text()').extract()
information_list = [info.replace('\u3000', '').replace('\n', '') for info in information_list]
actor_number = [information_list.index(info) for info in information_list if "主演" in info]
alias_number = [information_list.index(info) for info in information_list if "译名" in info]
item = {}
item['title'] = "".join([info.replace("片名", '') for info in information_list if "片名" in info])
try:
item['director'] = "".join(information_list[:actor_number[0]]).replace('导演', '')
except:
item['director'] = ''
try:
item['actor'] = "".join(information_list[actor_number[0]:alias_number[0]]).replace('导演', '')
except:
item['actor'] = ''
# print(information_list)
item['duration'] = "".join([info.replace("片长", '') for info in information_list if "片长" in info])
item['movie_image'] = response.xpath('.//div[@id="poster_src"]/img/@src').get()
item['rating'] = "".join([info.replace("豆瓣评分", '') for info in information_list if "豆瓣评分" in info])
item['release time'] = "".join([info.replace("上映日期", '') for info in information_list if "上映日期" in info])
item['language'] = "".join([info.replace("语言", '') for info in information_list if "语言" in info])
item['type'] = "".join([info.replace("类别", '') for info in information_list if "类别" in info])
item['info_source'] = response.xpath('.//div[@class="poster"]').get()
3.2.2 返回数据
{
"title": "地球此时",
"director": "杰赫米·克拉潘",
"actor": "主演梅根·诺瑟姆 / 迪米特里·多雷 / 塞巴斯蒂安·普德鲁 / 卡特琳·萨雷 / 萨姆·卢维克 / RomanWilliams / 索菲娅·勒萨弗尔 / 尼古拉斯·阿维尼 / YoannThibautMathias / 阿卡帝·拉德夫 / 莎宾·蒂莫提欧 / MarieBray / 克里斯蒂安·布耶特",
"duration": "89 Mins",
"movie_image": "https://btdx8.dnscf.vip/cdn-cgi/image/w=200,h=300,fit=cover/uploads/2025/01/c21575208da342ea5143725c17e58bbd.jpg",
"rating": "5.8/10 from 199 users",
"release time": "2024-02-15(柏林电影节)",
"language": "法语",
"type": "科幻/冒险/剧情",
"referer": "btdx"
}
五、Scrapy调试模式
提示:创建run.py、run_all.py文件,用于项目启动
5.1 单个爬虫任务执行
from scrapy.cmdline import execute
# 单个爬虫运行
if __name__ == "__main__":
# execute("scrapy crawl btdx".split())
execute("scrapy crawl douban".split())
5.2 多个个爬虫任务执行
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
# 一键运行多个爬虫
if __name__ == "__main__":
settings = get_project_settings()
crawler = CrawlerProcess(settings)
crawler.crawl('douban')
crawler.crawl('btdx')
crawler.start()
六、数据爬取与展示
在管道文件pipelines.py编写对数据处理的逻辑
6.1 数据存入CSV
# CSV
class MovieinfoPipeline:
keys = [
'title', 'director', 'actor',
'duration', 'movie_image', 'rating',
'release time', 'type', 'language', 'spider'
]
def open_spider(self, spider):
# csv_filename = "{}_{}.csv".format(spider.name, datetime.datetime.now().strftime("%Y%m%d%H%M%S"))
csv_filename = "{}.csv".format(datetime.datetime.now().strftime("%Y%m%d%H%M%S"))
self.file = open(csv_filename, 'a', encoding='utf8', newline='')
self.csv_writer = csv.writer(self.file)
self.csv_writer.writerow(self.keys)
def process_item(self, item, spider):
item_values = []
for key in self.keys[:-1]:
value = item.get(key, ' ')
item_values.append(value)
item_values.append(spider.name)
self.csv_writer.writerow(item_values)
return item
def close_spider(self, spider):
self.file.close()
6.2 运行获取数据
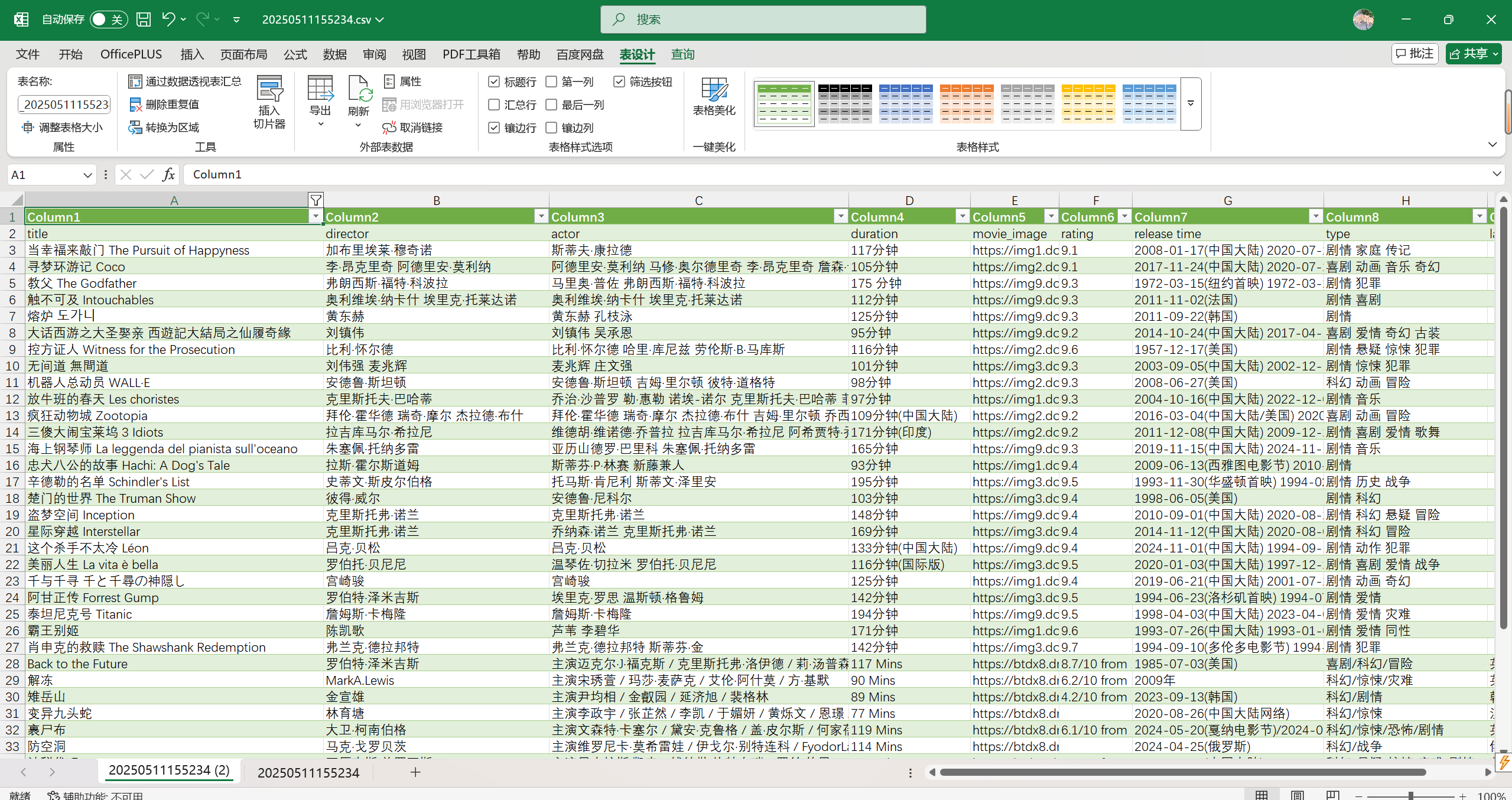
6.3 Excel数据展示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









