







Python爬虫系列
文章目录
前言
本文将介绍如何把爬取的数据,使用Item Pipeline实现数据清洗,同步存储至关系型与文档型数据库。
一、数据结构分析
1.1 爬取数据内容
{
"title": "寂静岛之异兽",
"director": "汪帅",
"actor": "主演张皓承 / 董潞蔓 / 黄宥天",
"duration": "62 Mins",
"movie_image": "https://btdx8.dnscf.vip/cdn-cgi/image/w=200,h=300,fit=cover/uploads/2024/12/848d7eba33c8e2ea27aa672a6ccc0b1c.jpg",
"rating": "",
"release time": "2024-12-27(中国大陆网络)",
"language": "汉语普通话",
"type": "科幻/惊悚/灾难",
"referer": "btdx"
}
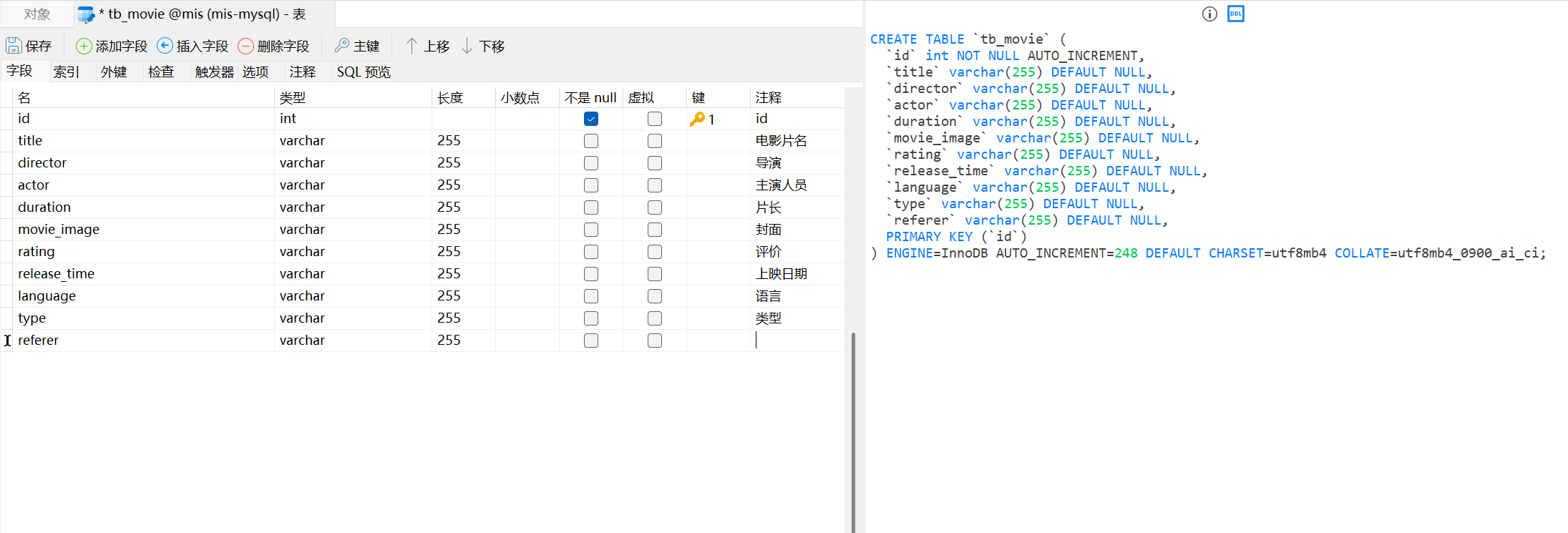
1.2 表结构设计
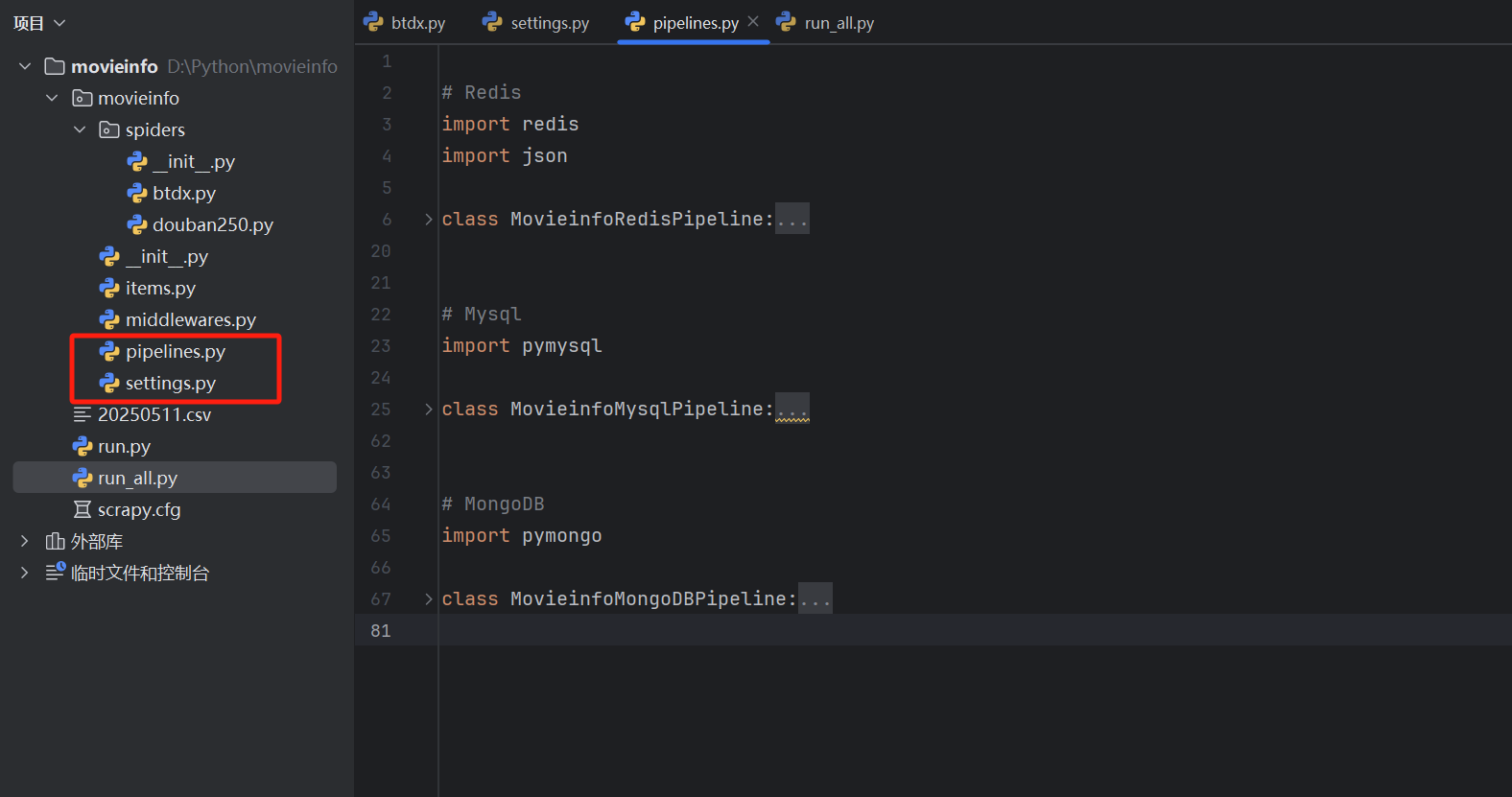
1.3 项目目录结构
二、数据库连接
2.1 项目依赖库下载
# redis mysql mongodb
pip install redis pymysql pymongo
2.2 python连接Redis
# Redis
import redis
import json
class MovieinfoRedisPipeline:
host = '121.40.242.19'
port = 7009
password = '数据库密码'
def open_spider(self, spider):
print(spider.name)
self.conn = redis.Redis(host=self.host, port=self.port, password=self.password)
def process_item(self, item, spider):
item['referer'] = spider.name
if item.get('title', False):
self.conn.set(item['title'], json.dumps(item))
return item
def close_spider(self, spider):
self.conn.close()
2.3 python连接Mysql
# Mysql
import pymysql
class MovieinfoMysqlPipeline:
# 数据库
database = 'mis'
# 数据库表名称
table = 'tb_movie'
def open_spider(self, spider):
self.conn = pymysql.connect(
host='121.40.242.199',
port=7001,
db=self.database,
user='root',
password='abc123456',
charset='utf8',
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider): # f-string
insert_sql = f"""
INSERT INTO {self.table}
SET
title='{item["title"]}',
director='{item["director"]}',
actor='{item["actor"]}',
duration='{item["duration"]}',
movie_image='{item["movie_image"]}',
rating='{item["rating"]}',
release_time='{item["release time"]}',
type='{item["type"]}',
LANGUAGE='{item["language"]}',
referer='{spider.name}'
"""
# print(insert_sql)
self.cursor.execute(insert_sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
2.4 python连接MondoDB
# MongoDB
import pymongo
class MovieinfoMongoDBPipeline:
# 数据库
database = 'admin'
# 数据库
password = 'abc123456'
# ip
host = '121.40.242.199'
# 端口
port = 7003
def open_spider(self, spider):
# mongoDB配置
connection_string = f"mongodb://{self.database}:{self.password}@{self.host}:{self.port}/"
client = pymongo.MongoClient(connection_string)
self.db = client['movies'][spider.name]
pass
def process_item(self, item, spider):
item['referer'] = spider.name
self.db.insert_one(item)
return item
def close_spider(self, spider):
self.db.close()
2.5 settings设置释放管道
ITEM_PIPELINES = {
"movieinfo.pipelines.MovieinfoRedisPipeline": 400,
"movieinfo.pipelines.MovieinfoMysqlPipeline": 500,
"movieinfo.pipelines.MovieinfoMongoDBPipeline": 600
}
2.6 完整代码
pipelines.py文件完整代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import csv
import datetime
from scrapy import signals
# CSV
class MovieinfoPipeline:
keys = [
'title', 'director', 'actor',
'duration', 'movie_image', 'rating',
'release time', 'type', 'language', 'spider'
]
def open_spider(self, spider):
# csv_filename = "{}_{}.csv".format(spider.name, datetime.datetime.now().strftime("%Y%m%d%H%M%S"))
csv_filename = "{}.csv".format(datetime.datetime.now().strftime("%Y%m%d%H%M%S"))
self.file = open(csv_filename, 'a', encoding='utf8', newline='')
self.csv_writer = csv.writer(self.file)
self.csv_writer.writerow(self.keys)
def process_item(self, item, spider):
item_values = []
for key in self.keys[:-1]:
value = item.get(key, ' ')
item_values.append(value)
item_values.append(spider.name)
self.csv_writer.writerow(item_values)
return item
def close_spider(self, spider):
self.file.close()
# Redis
import redis
import json
class MovieinfoRedisPipeline:
def open_spider(self, spider):
print(spider.name)
self.conn = redis.Redis(host='121.40.242.197', port=7002, password='abc123456')
def process_item(self, item, spider):
item['referer'] = spider.name
if item.get('title', False):
self.conn.set(item['title'], json.dumps(item))
return item
def close_spider(self, spider):
self.conn.close()
# Mysql
import pymysql
class MovieinfoMysqlPipeline:
database = 'mis'
table = 'tb_movie'
def open_spider(self, spider):
self.conn = pymysql.connect(
host='121.40.242.197',
port=7001,
db=self.database,
user='root',
password='abc123456',
charset='utf8',
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider): # f-string
insert_sql = f"""
INSERT INTO {self.table}
SET
title='{item["title"]}',
director='{item["director"]}',
actor='{item["actor"]}',
duration='{item["duration"]}',
movie_image='{item["movie_image"]}',
rating='{item["rating"]}',
release_time='{item["release time"]}',
type='{item["type"]}',
LANGUAGE='{item["language"]}',
referer='{spider.name}'
"""
# print(insert_sql)
self.cursor.execute(insert_sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
# MongoDB
import pymongo
class MovieinfoMongoDBPipeline:
def open_spider(self, spider):
# mongoDB配置
connection_string = "mongodb://admin:abc123456@121.40.242.197:7003/"
client = pymongo.MongoClient(connection_string)
self.db = client['movies'][spider.name]
pass
def process_item(self, item, spider):
item['referer'] = spider.name
self.db.insert_one(item)
return item
def close_spider(self, spider):
self.db.close()
三、数据抓取与同步存储
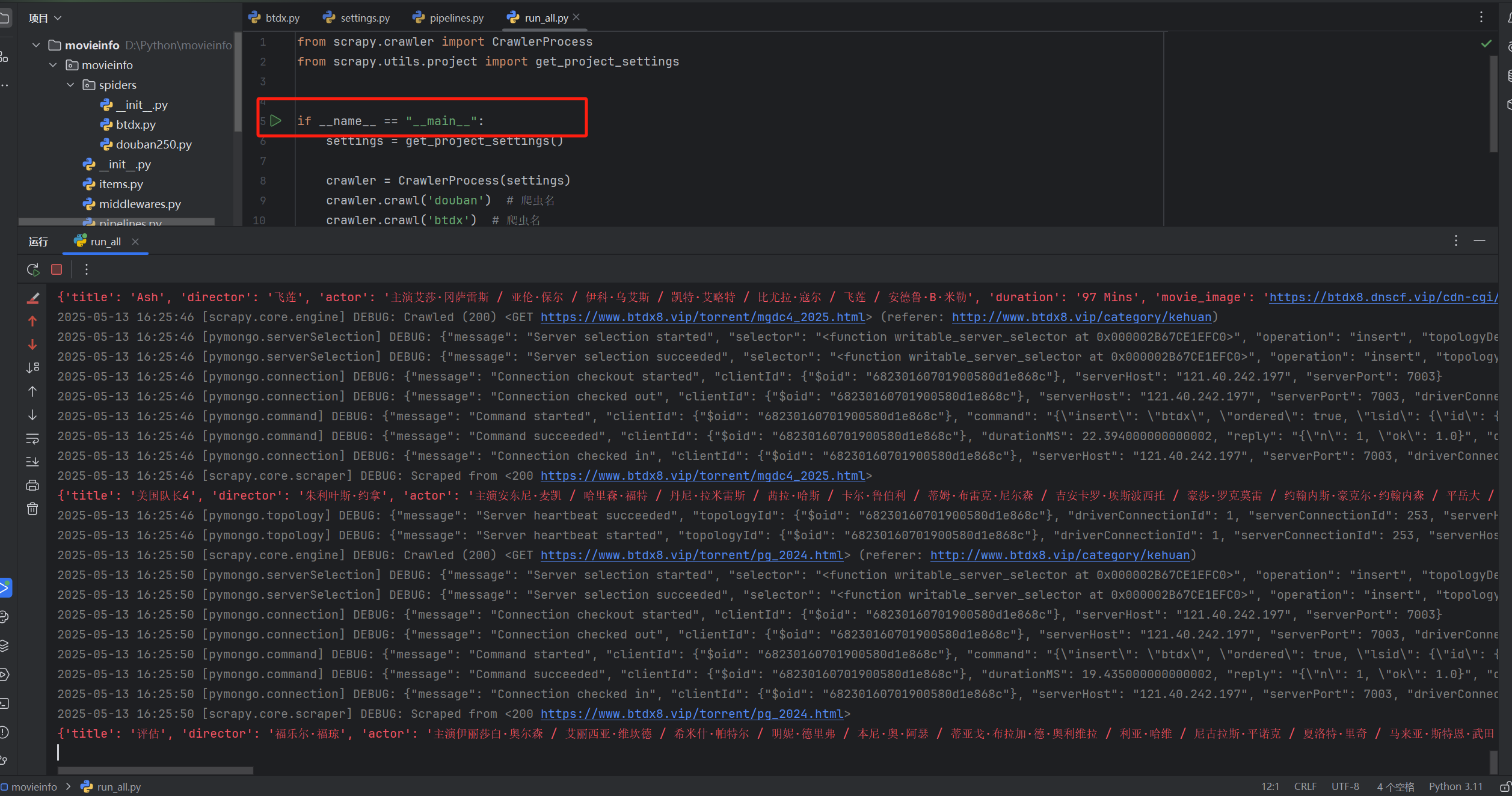
3.1 多爬虫任务启动
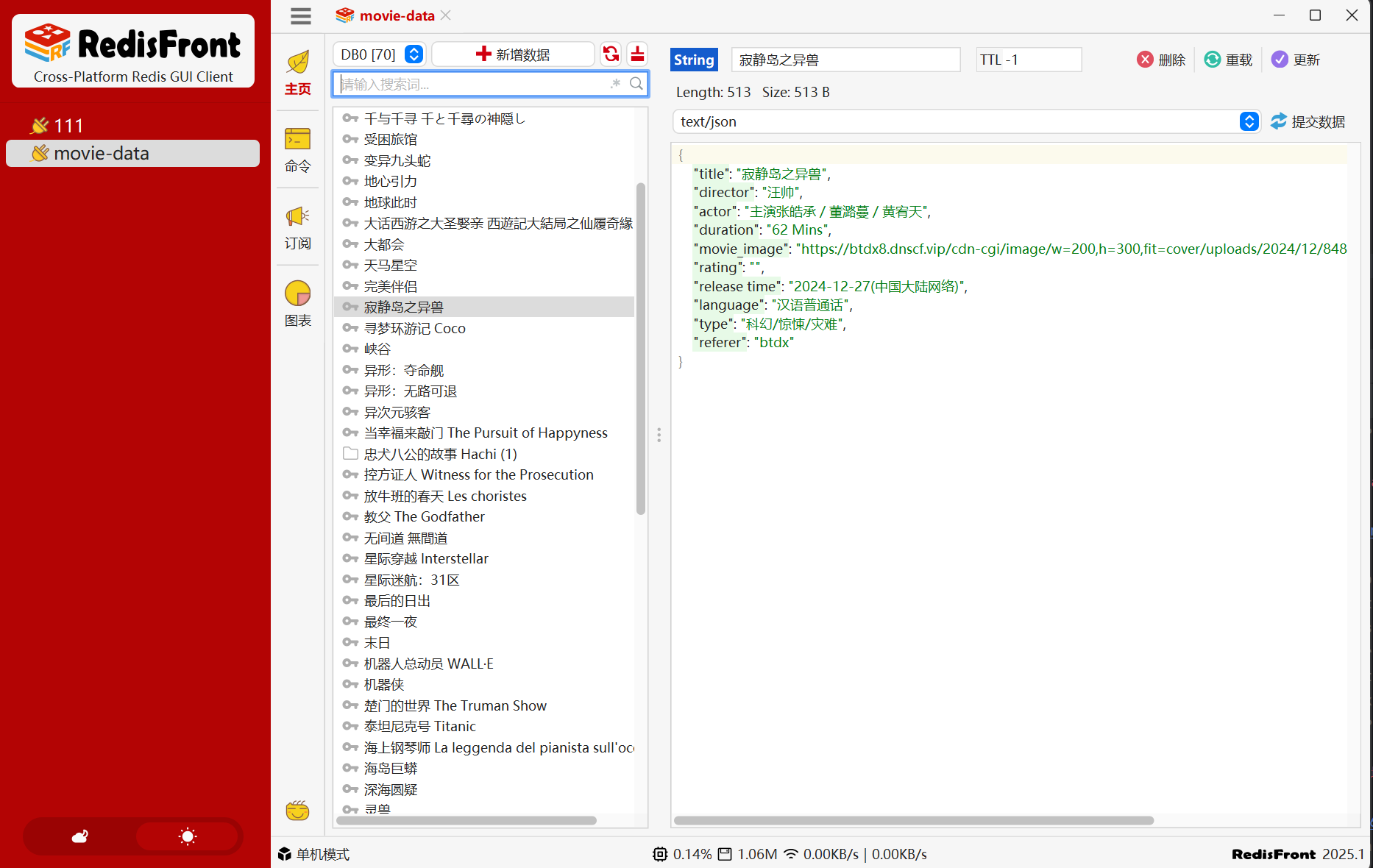
3.2 数据入库Rdis
3.3 数据入库Mysql
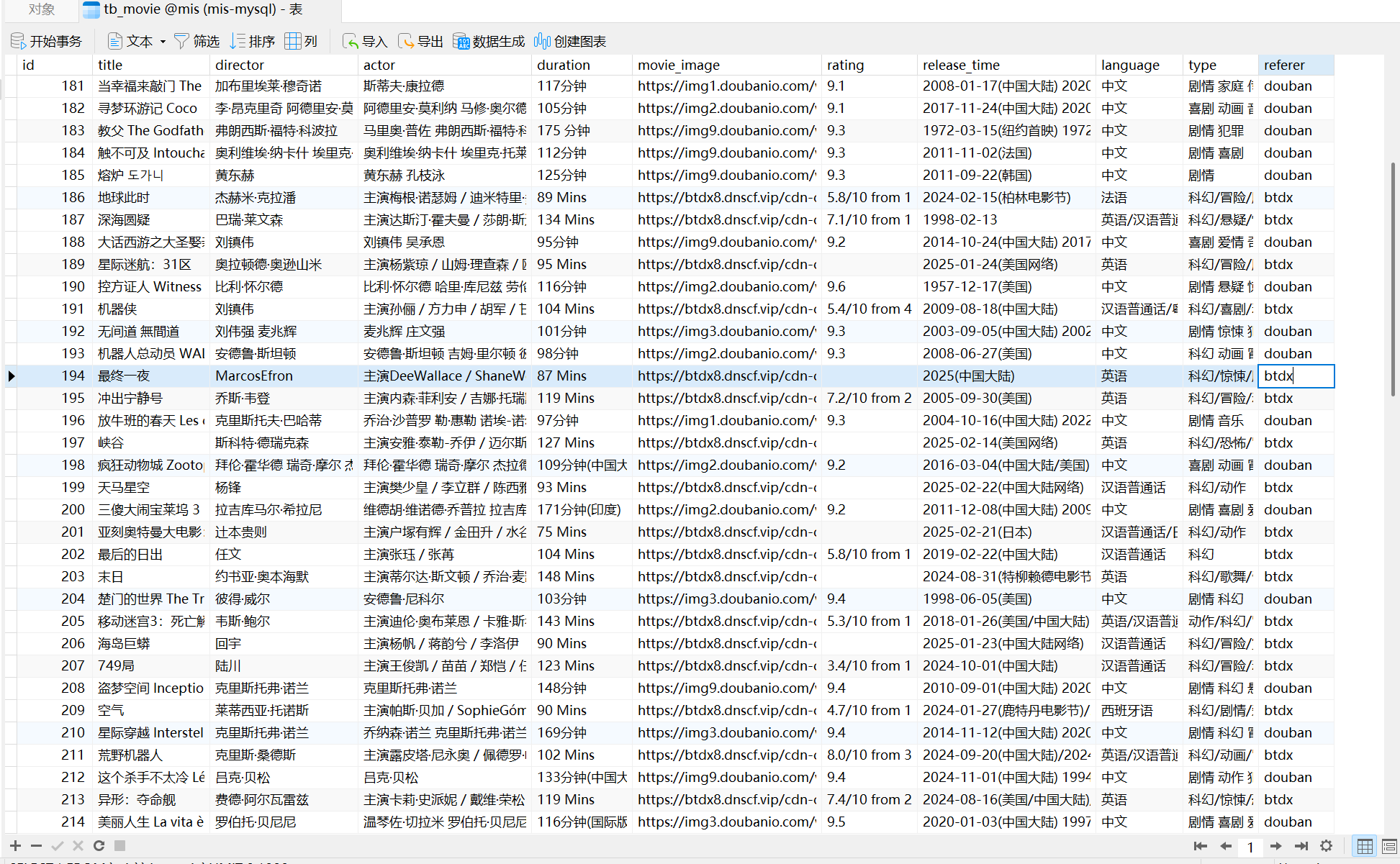
3.4 数据入库MongoDB
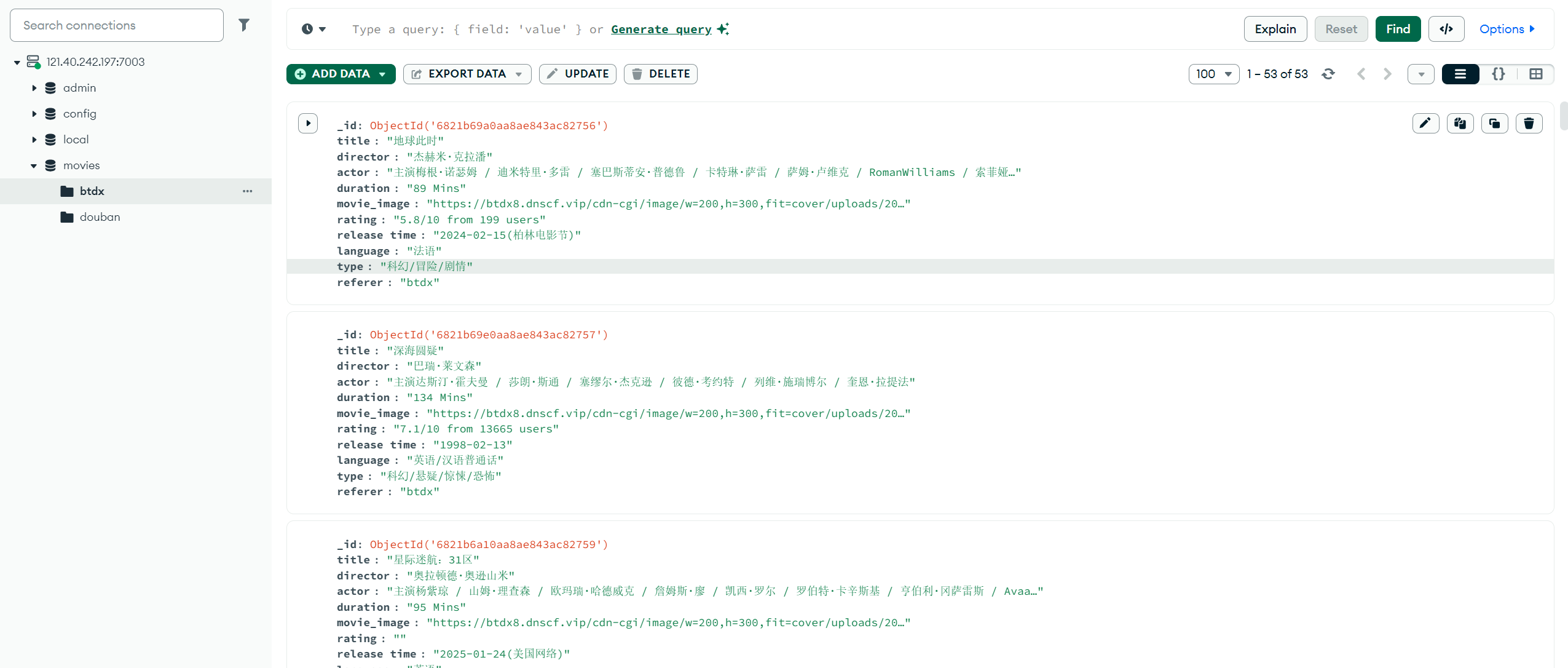

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









