







目录
0. 名词解释
- image:应用程序/容器所依赖的所有二进制文件和库都可以与应用程序一起有效地封装在image中。一旦image导入到本地存储后,容器可以从相同的image中派生(容器可以从同一个映像派生出多个相同的实例,这些实例之间可能会运行不同的服务或应用程序,但它们共享相同的基础映像。)。
- image metadata:镜像元数据。表示image和layer之间的映射关系。
- registry:注册表。在集群内的image分发中起核心作用,分发image的副本(copy件)。通常,Docker image由很多layer组成,代表软件或库的不同文件集。所有image layers都以gzip压缩文件的形式存储在registry中。image metadata也存储在registry中(见图1)。
- Ceph:分布式块存储集群。无中心、分布式、自修复原则。主要组件如下:
(1) RADOS:可扩展自愈分布式对象存储。核心组件,提供存储服务。数据被分为对象并存储在集群中的多个节点上,实现了高度的可扩展性和冗余性。RADOS 使用 CRUSH 算法来决定数据的存储位置,以实现均衡的数据分布和高度的容错性。
(2) RBD:RADOS 块设备。RBD 允许在 Ceph 存储集群上创建块设备,这些块设备可以直接映射到客户机上,类似于本地块设备。RBD 支持快照、克隆等功能。
(3) CephFS:Ceph文件系统。CephFS 提供了分布式的文件系统服务,允许多个客户端同时访问存储集群中的文件。它实现了 POSIX 兼容性,并支持文件系统快照、复制等功能。
(4) RGW:RADOS Gateway。提供了对象存储服务的 RESTful 接口,兼容 S3 和 Swift 等标准。这使得 Ceph 可以作为对象存储服务用于云环境。 - 可扩展性:可扩展性指的是系统、应用程序或服务能够有效地应对增长的需求和负载而进行扩展的能力。分为水平扩展(Scale Out)、垂直扩展(Scale Up)、弹性(Elasticity)、容错性(Fault Tolerance)。
【Abstract】
- 提出原因:
1.传统方法容器部署步骤很慢;
2.大规模高并发部署中,中央镜像存储库(central image repository)上的资源竞争也会加剧这种情况;
镜像拉取(pull)操作是导致性能下降的主要原因。由此提出Cider——可以高并发和可扩展方式实现容器的快速部署的一种新系统。
- 主要改动:
1.将工作节点的本地Docker存储改为全节点共享的网络存储,按需加载镜像;
2.容器的本地写时复制层(COW)确保Cider在整体部署期间的可扩展性;
实验结果表明:Cider在部署单个容器时,整体部署时间缩短62%;部署100个并发容器时,缩短85%。
【Keywords】container; network storage; copy-on-write; application deployment
Ⅰ. Introduction
- Docker与虚拟机相比的优点
以极低的虚拟化开销提供性能和用户空间隔离;它为大规模集群管理提供了几个关键功能,如资源约束、进程隔离等。
- Docker主要问题
缓慢的容器部署带来的系统延时增大。这在爆炸流量处理、快速系统的组件故障替代(转移)等场景至关重要。
调查发现,平均部署时间13.4s,92% 的时间是由通过网络传输image数据导致的。
- 研究过程:
(1) 集群管理系统采用P2P方式加速image分发,Harbor也集成了去中心化的image分发机制 -----> app image仍需完全下载到工作节点,导致了通过本地网络传输大量数据的时延延长;
(2) Harter提出了一种单节点容器,数据按需拉取的策略虽可有效减少时延,但在高并发和大规模部署场景中的实验尚未验证;
现实场景中高并发与大规模容器部署是常用的。由此体现了此课题的迫切性。
Ⅱ. Background and Motivation
随image的增大,容器部署效率将受到负面影响。传统的容器部署方法存在着很大的缺陷。
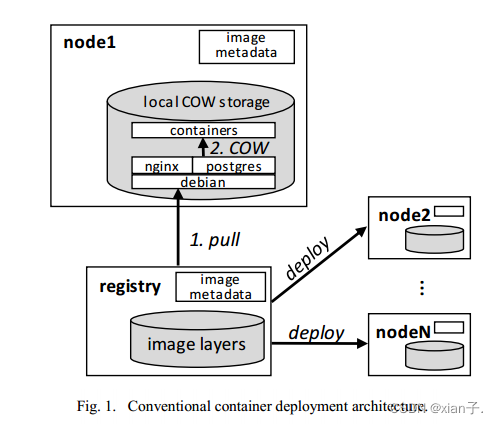
传统容器部署方法采用了集中式架构。要跨计算集群部署容器,工作节点(1-N)首先需要完整的image并存储到本地的写时复制(COW)层,完成之后,存储驱动程序会为容器在image上设置另一个COW层。
传统部署方法无法满足需要快速部署的情况(服务应立即向外扩展以应对突发流量,而应用程序应在故障转移事件到来时尽快恢复以保持系统可用性)。
容器的部署过程主要分为两步:deploy = pull + run
- pull
一个image由多个layer组成以gzip形式存储在registry中,本地工作节点可以同时下载这些layers,当一个layer下载完成可以迅速被解压到本地存储中。但由于依赖项有顺序,解压过程不能同时。 能同时下不能同时解
- run
要运行一个容器,存储驱动首先在image上创建一个Init layer初始化一些特定于容器的文件(hostname、DNS address等),随后在Init layer上创建第二个layer,作为容器根目录系统。所有本地存储中的这些层都是通过利用COW技术提高空间利用率和启动性能。最后,容器的根目录被更换到顶层,app就能启动了。
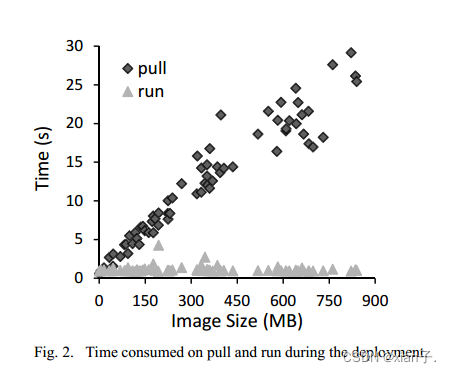
由图可见,pull过程耗时更长(pull过程占据92%部署时长,在image大时)。因此我们应该寻找个方法最小化部署期间传输的数据量。
Ⅲ. Design and Implementation
Cider (Ceph image deployer) 能显著减少容器部署过程中的数据传输,提高整体性能。
1. 使用ceph作为底层存储
在本文的设计架构中,可以使用任何一个都具有快照(snapshot)和克隆(clone)特性的网络存储以满足基本需求,选Ceph的原因:
(1)开源,很好的与Linux内核集成;
(2)Ceph社区活跃,作为云存储后端很有前景;
(3)性能、可扩展性和容错性都比较合适。
2. Cider架构
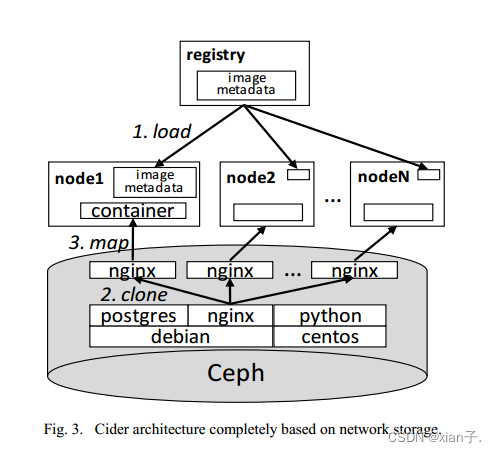
相较于传统方法(将image存储中registry中并分发副本(copy)),Cider将所有数据(包括images和集群容器)以分层结构存储中RBD池中,一个image对应一个RBD,通过COW机制,在父子image间进行重复数据删除。
(例如如图,Nginx image实际上没有必要从Debian复制所有数据。映像只需要构建在父image Debian之上,只要在Debian映像上增加一个COW层并写入增量数据就足够了。)
创建子RBD包含两个过程:在父RBD上创建快照并克隆,clone操作将生成与父RBD相同的RBD。
Cider的Registry充当metadata服务器,Registry中仅存储image列表、一个image的layer信息、layers和RBD间的映射关系。
Cider的工作节点没有本地存储。
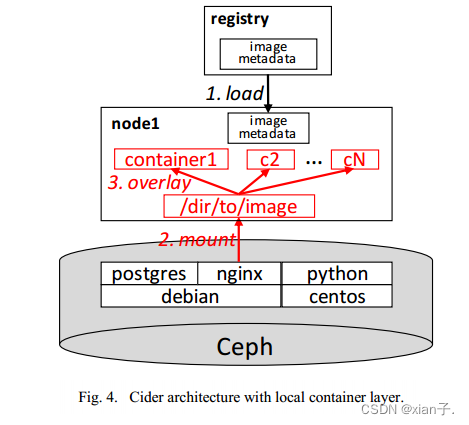
- 此过程具体分为三部分(图3):
(1)image metadata load
从Registry中下载image metadata并解压,看看需要几个RBD(根据metadata中的image list)。
元数据的大小可比整个大小小多了,就几百k甚至可忽略不计。因此下载metadata的时间也很短(0.2~0.3s),同时可以一定程度上缓解Registry的压力。
(2)image snapshot clone
image在更新之前不会更改,因此snapshot可以在多克隆中使用。clone生成的COW副本将作为容器的读/写层。
(3)mapping container RBD to worker nodes
克隆的RBD可作为正常RBD使用。将克隆RBD映射为本地块设备后才能在本地工作节点上使用。*map操作=在本地内核中注册一个网络RBD(/dev/rbd)。**将本地RBD挂载到特定目录是为容器设置根文件系统的最后一步。要想运行容器,工作节点需要从容器RBD中读取程序二进制文件和配置信息等,数据块只会从Ceph中按需获取。
clone和map操作是由Ceph的存储驱动程序执行。
上述load、clone、map轻量级操作将替代传统方法的pull,大部分操作使用metadata:load=image metadata;clone=RBD metadata;map=kernel metadata。启动容器所需的唯一数据将按需获取。
3. 实现
(1) 镜像元数据下载 --> load
使用rsync检索Registry中的镜像元数据,当metadata下载完成后,给Docker守护进程发送一个信号,让其从本地磁盘中重新加载metadata。实际上Docker的守护进程没有重载metadata的方法,因此作者实现了一个metadata的重载方法,在获得信号时调用它。
后续设想:以一种自动化的形式对load过程进行改进,使Docker的守护进程能够自动地提取和加载image metadata;将数据请求协议转化为http协议,推广适用性。
(2) Ceph存储驱动插件 --> clone+map
Docker允许开发人员使用插件形式对存储驱动程序进行开发,方便从Docker守护进程中安装和删除。
该插件接收来自Docker的命令,转化成Ceph操作,将结果返回给Docker。本质上驱动程序插件是一个运行在Docker容器中的进程,通过UNIX Domain Socket与Docker daemon通信。使用APIs of librbd操纵Ceph的RBDs。
- 应实现的接口如下:(重要的)
| 函数接口 | 功能 |
|---|---|
| Create(id, parent) | 在父层上创建一个具有特定id的新层。在Cider中,获取父RBD快照并克隆快照生成名为id的新快照。除base RBD外的所有RBD都以此方式(用此函数)生成。 |
| Remove(id) | 删除带有此id的层。只删除名为id的RBD,不删除快照,以加快clone的下次迭代。 |
| Get(id) | 返回由该id引用的挂载点。Cider将名为id的RBD映射到工作节点作为本地块设备,将其挂载到本地目录并返回挂载点。 |
| Put(id) | 释放指定id的系统资源。从工作节点中通过此id unmount(卸载挂载)这个块设备并unmap(卸载映射)相应RBD。 |
| Diff(id, parent)和ApplyDiff(id, diff) | Diff生成id层与父层之间更改的存档;ApplyDiff从给定diff中提取更改送到id层。Cider利用Docker提供的NaiveDiffDriver来实现这两个接口。 |
4. 可扩展性
单个容器部署 --> 多个容器高并发部署,解决可扩展性(Scalability)。
实验表明,RBD clone步骤耗时最多。
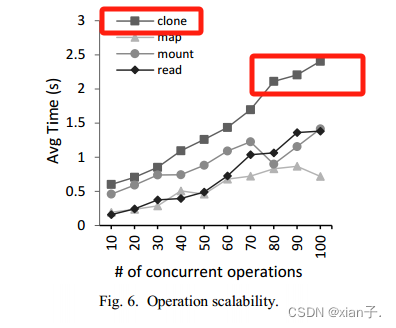
问题:当读取来自同一镜像不同容器的同一文件副本时,无法有效重用页面缓存,因为Cider在文件系统(Ceph内部)下实现了容器层的COW,可能导致内存消耗过多。
- Scalability:改进了Cider架构。
改进后的步骤为:
a.Load image metadata(与之前相同)
b.Mount image RBD
之前的clone操作耗时最长。因此将images RBD直接从池中映射到设备并将它挂载到本地目录,该目录将包含一个名为roofts的完整文件系统树。
c.Do overlays on roofts
利用overlays (Docker已采用)实现文件级的COW。这个操作①消除clone操作;②消除clone引入元数据时的竞争。同时overlay实现的local COW比RBD clone快得多。
5. 内存优化
主要问题:页面缓存重用问题
Ceph内部实现的COW机制是在本地文件系统下实现。因此,操作系统无法将同一映像生成的不同容器中的同一个文件数据块识别为一个数据块。当读取相同的数据块时,缓存将重复执行。在同一节点上运行N个容器将消耗比运行一个容器多N倍的页面缓存。
overlay可以解决这个问题,原理如下(下图描述了4.中的overlay覆盖操作):
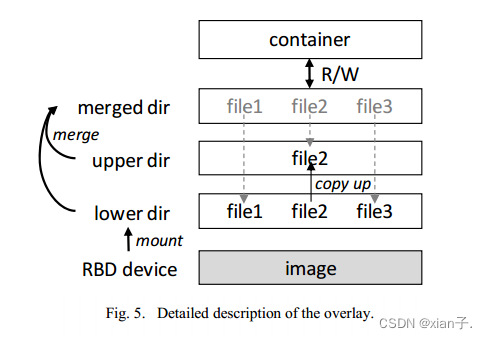
(1) 映像RBD直接挂载到本地目录,该目录是覆盖堆栈的“lower dir”。
(2) “merge dir”中的所有文件实际上都是指向下面目录的硬链接。
(3) 容器的读写操作将在“merge dir”上执行。如果一个文件需要更改,它将首先被复制到“upper dir”,覆盖原始文件。
上面的介绍是对文件级COW如何工作的简要解释。通过这种方法,可以在从一个节点上的相同映像引导多个容器时重用页面缓存。
就大文件而言,我们采用的文件级COW方法可能在复制操作上有一定程度的开销。但是,容器rootfs中的文件大小非常小(平均几十KB),并且文件修改操作不是典型的,在rootfs中发生的频率要低得多(通常在Docker卷中表现出来)。因此,简单的设计所带来的文件级COW的可靠性在Docker容器的情况下更有价值。
Ⅳ. Evaluation(可据此复现此论文)
1. 实验环境设置
- 环境
硬件——12台相同物理机器的集群,每台机器都有两个Intel Xeon E5-2650v4(12核)处理器和256 GB内存,以10gbps的网络相互连接。
软件——如下:
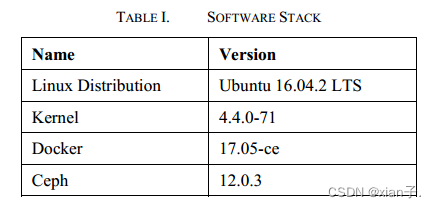
将Ceph部署在具有3个Monitor节点和12个OSD节点的集群上。即每个OSD占用一台机器。OSD存储磁盘为4tb SATA硬盘。我们打开Ceph的Bluestore特性,它使Ceph能够直接管理块设备(而不是通过本地文件系统)。
修改的Docker代码基于17.05-ce版本,并安装了Ceph存储驱动程序。
- 方法及指标
传统架构——采用Overlay2作为基线的本地存储驱动程序,使用官方的Registry应用程序来分发image。
Cider架构——完全在网络存储上运行的苹果酒简称为Cider-network;带有本地容器层的Cider简称为Cider-local。
检测系统效率——测量了部署单个容器时消耗的时间,并分别验证了多个应用程序在单个节点和多个节点上的部署性能。
检测容器执行性能和效率——测量了反映缓存重用率的页面缓存量。通过使用几个具有不同参数的基准测试来评估对运行应用程序的影响。(Nginx和Postgres分别代表web服务器和数据库。Python是一种编程语言。在这种情况下,记录吞吐量统计数据,并在我们的方法和基线之间进行比较。)
2. 实验结果
- 单容器部署
前69个映像(Docker-Hub)使用Cider进行部署。下图显示了部署单个容器所耗费的时间。
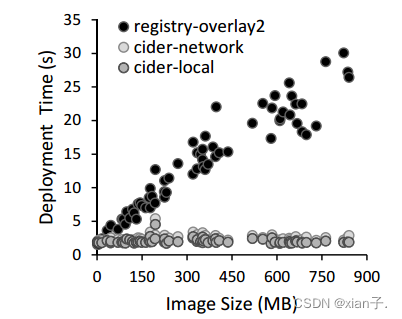
(1) 使用Cider架构,time随着image size的增长浮动不大(很稳定),即所提出的Cider系统它的耗时不受image size的影响。平均时间约为2.5s(相较于Registry-Overlay2(传统部署方法)的13.4s缩短了近82%),这主要得益于按需加载机制。
(2) 由于更快的local COW,Cider-local比Cider-network快18%,比Registry-overlay2快85%。
- 单节点部署(单个节点部署三种容器)
使用Registry-Overlay2、Cider-network、Cider-local在单个节点上部署这三个应用程序(三个不同类别的Docker镜像的代表——Nginx (109 MB), Postgres (269 MB)和Python (684 MB)),部署的容器个数为1~10,同一轮的所有容器并发部署。结果如下图:

(1) 显然无论是1~10,均是Cider优于Registry-Overlay2;
(2) 由于拥有本地COW,Cider-local较Cider-network拥有更好的可扩展性。
- 多节点部署(三种容器部署到三个节点)
重复实验并改变节点数量来验证系统的可扩展性(最多将使用100个容器)。结果如下:
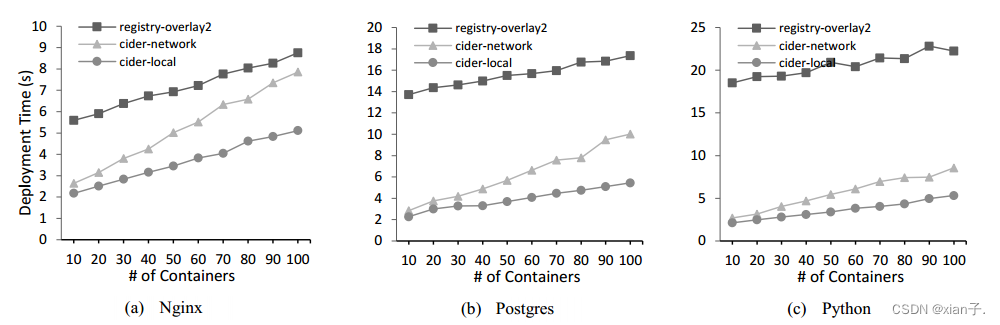
(1) Cider-network随所部署的容器数量的增加急剧增加(几乎是Cider-local的两倍),前面也提到Cider-network是适用于单个节点容器部署的。
- 页面缓存消耗
从Python image中部署1~20个容器,计算Registry-Overlay2、Cider-network、Cider-local所消耗的页面缓存,通过free命令显示buff/cache获得。实验在集群外的虚拟机上进行,以消除Ceph带来的缓存干扰。每次实验前都会清理页面缓存。结果如下:
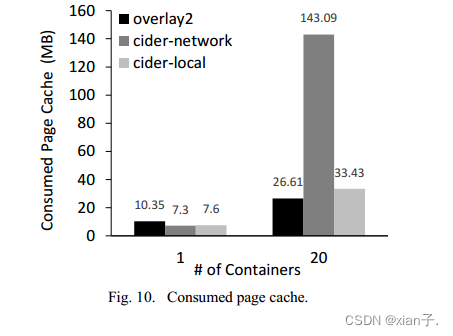
(1) 部署单容器时差别不大;
(2) 部署20容器时,Registry-Overlay2和Cider-local差别不大,但Cider-network急剧增加,即Cider-network消耗的页面缓存与容器数量成正比。
原因是:Overlay2和Cider-local都是在文件级别上实现COW,因此在访问同一文件时能够重用页面缓存,而Cider-network的COW机制是在文件系统下,导致同一数据的缓存分配过多。(可以借鉴Ⅲ.5内存优化部分)
- 应用程序运行性能
由于数据从网络中按需获取,因此运行性能是一大问题。使用了几种不同工作负载的基准测试:
● Nginx,网页请求使用wrk进行;
● Postgres, TPCB事务是通过pgbench提交的;
● 对于Python,使用数独解谜程序。
所有工作负载执行5分钟。结果如下:
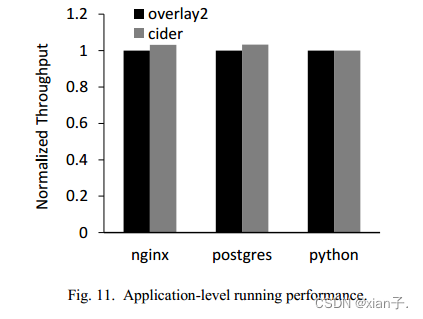
发现每个应用程序的标准化吞吐量在两种架构间无明显差异。(只有在python中性能小有损失,<0.3%)
Ⅴ. Related Work
介绍了前辈们相关的工作,对Cider的提出很有启发。
Ⅵ. Conclusion and Future Work
主要技术: loading-ondemand network storage for images and local copy-on-write layer for containers
日后工作:enhance the scalability of Cider to eliminate contentions on local disk existing in concurrent deployment, shortening the local provision latency.
可借鉴技术: lazy merge of overlayfs layers















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









