










A Survey of Large Language Models for Autonomous Driving
文章链接:https://arxiv.org/abs/2311.01043
💡摘要
自动驾驶技术是交通和城市出行革命的催化剂,它倾向于从基于规则的系统过渡到数据驱动的策略。传统的基于模块的系统受到级联模块之间累积误差和不灵活的预设规则的限制。相比之下,端到端自动驾驶系统由于其完全数据驱动的训练过程而有可能避免错误积累,尽管它们由于其“黑匣子”性质而常常缺乏透明度,从而使决策的验证和可追溯性变得复杂。最近,大型语言模型(LLM)展示了包括理解上下文、逻辑推理和生成答案在内的能力。一个自然的想法是利用这些能力来增强自动驾驶能力。通过将LLM与基础视觉模型相结合,它可以打开开放世界理解、推理和小样本学习的大门,而这是当前自动驾驶系统所缺乏的。在本文中,我们系统地回顾了自动驾驶大型语言模型(LLM4AD)的研究方向。这项研究评估了技术进步的现状,明确概述了该领域的主要挑战和前景方向。为了方便学术界和工业界的研究人员,我们通过指定链接提供该领域最新进展的实时更新以及相关开源资源:https://github.com/Thinklab-SJTU/Awesome-LLM4AD。
Introduction
自动驾驶正在迅速重塑我们对交通的理解,预示着技术革命的新时代。这种转变不仅意味着交通运输的未来,也意味着各个行业的根本性转变。在传统的自动驾驶系统中,算法通常采用模块化设计,具有负责感知等关键任务的独立组件和规划 。具体来说,感知组件处理对象检测 、跟踪和复杂的语义分割任务 。预测组件分析外部环境 并估计周围智能体的未来状态 。规划组件通常依赖于基于规则的决策算法,确定到达预定目的地的最佳且最安全的路线。虽然基于模块的方法在各种场景中提供了可靠性和增强的安全性,但它也带来了挑战。系统组件之间的解耦设计可能会导致转换期间关键信息丢失以及潜在的冗余计算。此外,由于各模块之间优化目标不一致,系统内可能会积累误差,影响车辆的整体决策性能。基于规则的决策系统由于其固有的局限性和可扩展性问题,正在逐渐让位于数据驱动的方法。端到端自动驾驶解决方案日益成为该领域的共识。通过消除多个模块之间的集成错误并减少冗余计算,端到端系统增强了视觉和感官信息的表达,同时确保更高的效率。然而,这种方法也引入了“黑匣子”问题,这意味着决策过程缺乏透明度,使解释和验证变得复杂。同时,自动驾驶的可解释性已成为重要的研究热点。尽管用于从驾驶场景收集大量数据的较小语言模型(如早期版本的 BERT 和 GPT )有助于解决这个问题,但它们通常缺乏足够的泛化能力来执行最佳地。最近,大型语言模型[OpenAI,2023; Touvron et al., 2023] 在理解上下文、生成答案和处理复杂任务方面表现出了非凡的能力。它们现在还与多模式模型集成。这种集成实现了图像、文本、视频、点云等的统一特征空间映射。这种整合显着增强了系统的泛化能力,使其具备零样本或少样本快速适应新场景的能力。
在此背景下,开发可解释且高效的端到端自动驾驶系统已成为研究热点。大型语言模型具有广泛的知识库和卓越的泛化能力,可以帮助更轻松地学习复杂的驾驶行为。通过利用视觉语言模型 (VLM) 强大而全面的开放世界理解和上下文学习能力 ,解决感知网络的长尾问题、辅助决策并为这些决策提供直观的解释成为可能。本文旨在全面概述这一迅速兴起的研究领域,分析其基本原理、方法和实现过程,并详细介绍LLM在自动驾驶方面的应用。最后,我们讨论了相关挑战和未来的研究方向。
Motivation of LLM4D
在当今的技术格局中,大型语言模型如 GPT-4 和 GPT-4V [OpenAI,2023; Yang et al., 2023b] 以其卓越的情境理解和情境学习能力而引起人们的关注。他们丰富的常识知识促进了许多下游任务的重大进展。我们提出一个问题:这些大型模型如何协助自动驾驶领域,特别是在决策过程中发挥关键作用?
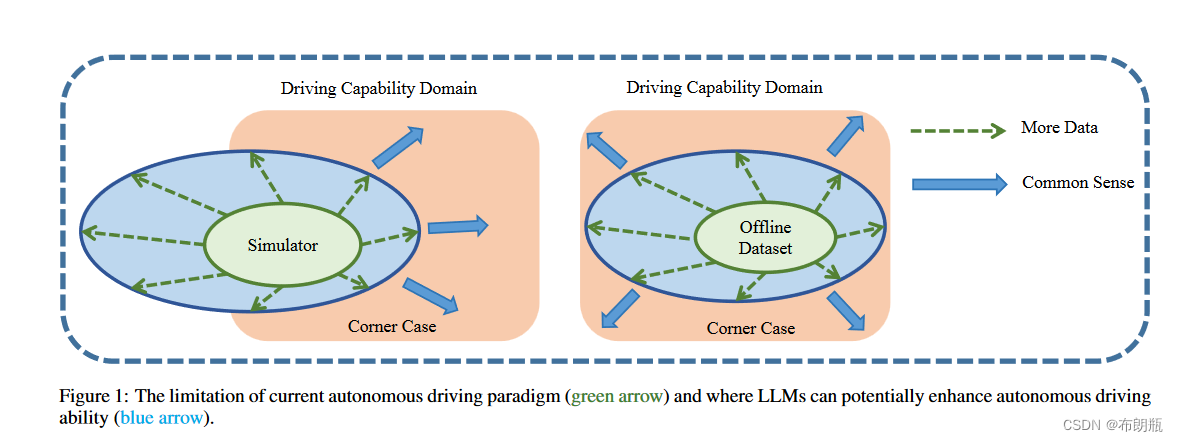
在图1中,我们直观地展示了当前自动驾驶范式的局限性以及LLM可以在哪些方面潜在地增强自动驾驶能力。我们总结了驾驶技能的两个主要方面。橙色圆圈代表理想的驾驶能力水平,类似于经验丰富的人类驾驶员所拥有的水平。获得这种熟练程度的方法主要有两种:一是在模拟环境中通过基于学习的技术;二是通过模拟环境中的学习技术。第二,通过类似的方法从离线数据中学习。需要注意的是,由于模拟与现实世界之间的差异,这两个领域并不完全相同,即 sim2real 差距 [Ḧofer et al., 2021]。同时,离线数据是现实世界数据的子集,因为它是直接从实际环境中收集的。然而,由于自动驾驶任务臭名昭著的长尾性质 [Jain et al., 2021],很难完全覆盖分布。
自动驾驶的最终目标是通过大量的数据收集和深度学习,将驾驶能力从基础的绿色阶段提升到更高级的蓝色阶段。然而,与数据收集和注释相关的高昂成本,以及模拟环境和现实环境之间的固有差异,意味着在达到专家驾驶技能水平之前仍然存在差距。在这种情况下,如果我们能够有效地利用大型语言模型中嵌入的固有常识,我们可能会逐渐缩小这一差距。直观地说,通过采用这种方法,我们可以逐步增强自动驾驶系统的能力,使其更接近或可能达到理想的专家驾驶熟练程度。通过这样的技术整合和创新,我们预计自动驾驶的整体性能和安全性将得到显着提升。
大语言模型在自动驾驶领域的应用确实涵盖了广泛的任务类型,深度和广度兼具,具有革命性的潜力。自动驾驶领域的LLM pipeline如图2所示。
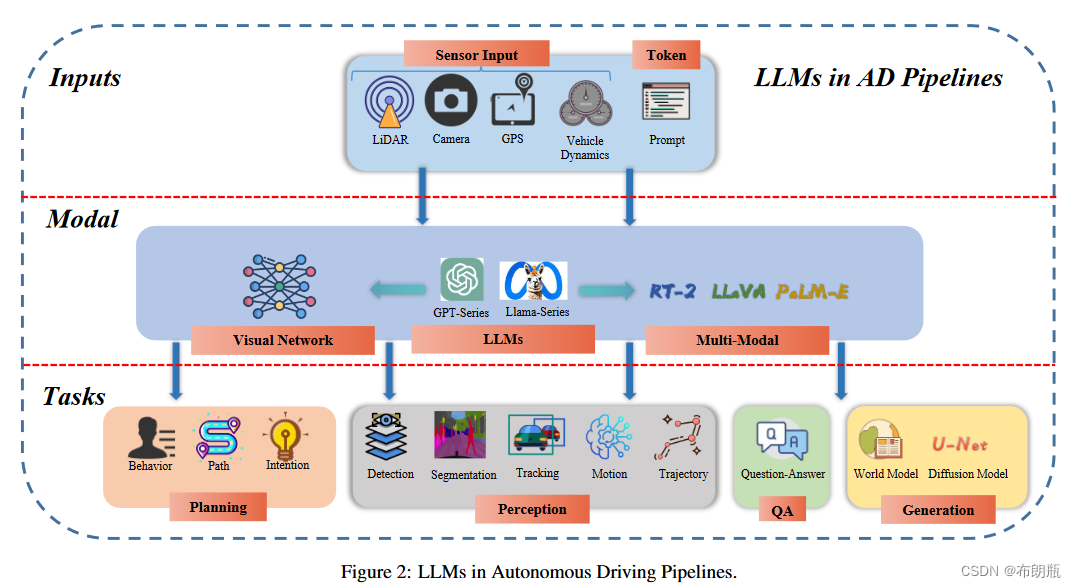
Application of LLM4AD
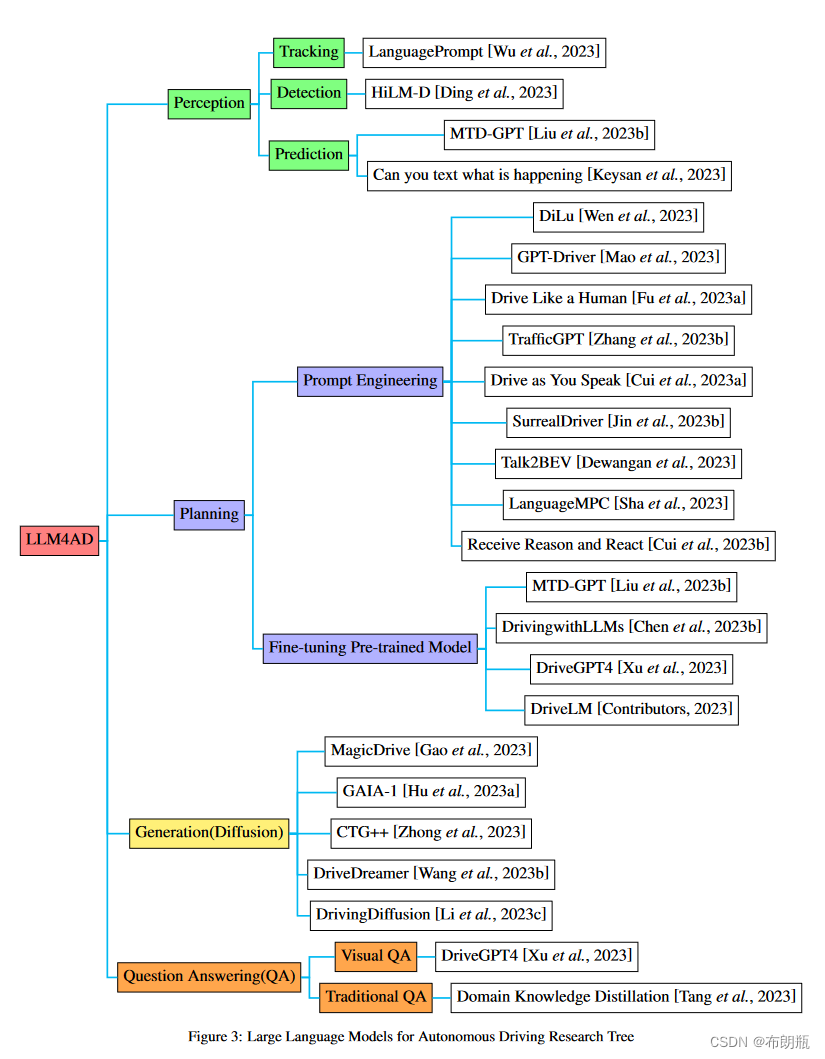
在下面的部分中,我们根据LLM应用的角度来划分现有的工作:规划、感知、问答和生成。对应的分类树如图3所示
3.1 Planning
大型语言模型(LLM)凭借其开放世界的认知和推理能力取得了巨大的成功[Radford et al., 2018;雷德福德等人,2019;布朗等人,2020;欧阳等人,2022; OpenAI,2023]。这些功能可以为自动驾驶决策过程提供透明的解释,显着增强系统可靠性和用户对该技术的信任[Deruyttere et al., 2019; Kim 等人,2019a;阿塔基什耶夫等人,2023;金等人,2023a; Malla 等人,2023]。在这个领域内,根据是否调整LLM,相关研究可以分为两大类:微调预训练模型和即时工程。
在微调预训练模型的应用中,MTDGPT [Liu et al., 2023b]将多任务决策问题转化为序列建模问题。通过对混合多任务数据集进行训练,它可以解决无信号交叉口的各种决策任务。尽管这种方法优于单任务决策强化学习模型的性能,但所使用的场景仅限于无信号交叉口,这可能足以证明现实世界应用的复杂性。 Driving with LLM [Chen et al., 2023b] 设计了一种架构,通过两阶段预训练和微调方法将矢量化输入融合到 LLM 中。由于矢量化表示的限制,他们的方法仅在仿真中进行测试。 DriveGPT4 [Xu et al., 2023] 提出了基于 Valley [Luo et al., 2023a] 的多模式LLM,并开发了用于可解释自动驾驶的视觉指令调整数据集。除了预测车辆的基本控制信号外,它还实时响应,解释采取行动的原因。它在各种 QA 任务中都优于基线模型,而有关规划的实验很简单。
从提示工程的角度来看,一些方法试图通过巧妙的提示设计来挖掘LLM的深层推理潜力。 DiLu [Wen et al., 2023] 设计了一个 LLM 框架作为代理来解决闭环驾驶任务。该方法引入了一个记忆模块来记录经验,利用LLM来促进推理和反思过程。与基于 SOTA RL 的方法相比,DiLu 表现出强大的泛化能力。但推理和反思过程需要多轮问答,其推理时间也不容忽视。同样,Receive Reason and React [Cui et al., 2023b] 和 Drive as You Speak [Cui et al., 2023a] 将LLM的语言和推理能力集成到自动驾驶汽车中。除了内存和反射过程之外,这些方法还引入了额外的原始传感器信息,例如相机、GNSS、激光雷达和雷达。然而,推理速度也尚未解决。此外,SurrealDriver [Jin et al., 2023b] 将记忆模块分为短期记忆、长期指导方针和安全标准。同时,它采访了 24 名司机,并利用他们对驾驶行为的详细描述作为思路提示,开发了“教练代理”模块。然而,缺乏与传统算法的比较来证明大型语言模型确实带来了性能提升。 LanguageMPC [Sha et al., 2023] 还为驾驶场景中的 LLM 设计了一个思想链框架,并通过引导参数矩阵自适应与低级控制器集成。尽管其性能在简化的模拟器环境中超过了基于 MPC 和 RL 的方法,但缺乏在复杂环境中的验证。 TrafficGPT [Zhang et al., 2023b] 是 ChatGPT 和流量基础模型的融合,可以解决复杂的流量相关问题并提供富有洞察力的建议。它利用多模态数据作为数据源,为各种交通相关任务提供全面支持。 Talk2BEV [Dewangan et al., 2023] 引入了一个大型视觉语言模型 (LVLM) 接口,用于自动驾驶环境中的鸟瞰图 (BEV) 地图。它不需要任何训练或微调,仅依赖于预先训练的图像语言模型。此外,它还提供了评估 AD 应用 LVLM 后续工作的基准。 GPT-Driver [Mao et al., 2023] 将运动规划任务转化为语言建模问题。它在 L2 指标上超过了 UniAD[Hu et al., 2023b]。然而,由于它使用了过去的速度和加速度信息,因此有人担心与 UniAD 进行不公平的比较。此外,L2仅反映驾驶路线的拟合程度,可能无法反映驾驶性能[Dauner et al., 2023]。 DriveLM [Contributors, 2023] 使用轨迹标记器来处理文本的自我轨迹信号,使它们属于同一域空间。这样的分词器可以应用于任何通用视觉语言模型。此外,他们利用按逻辑顺序排列多个 QA 对的图结构推理,从而提高了最终的规划性能。
Metric:
MTD-GPT使用单子任务成功率作为模拟中的指标,并且它超过了 RL Expert。 DriveGPT4使用均方根误差 (RMSE) 和阈值精度进行评估。在车辆动作描述、论证和完整句子中,它使用 BLEU-4、METEOR、CIDER 和 chatgpt Score。LLM驾驶 使用平均绝对误差 (MAE) 来预测汽车和行人的数量、归一化加速度和制动压力。此外,它还测量交通灯检测的准确性以及用于交通灯距离预测的平均绝对距离误差(以米为单位)。除了与感知相关的指标之外,它还使用 GPT-3.5 对模型的答案进行评分,这是一种最近新兴的技术 - 对自然语言响应进行评分。 DiLu 使用模拟中的成功步骤作为评估泛化和转换能力的指标。 SurrealDriver 基于两个主要维度评估智能体:安全驾驶能力和人性化。安全驾驶能力是通过碰撞率来评估的,而人类相似度是通过对 24 名合法驾驶的成年参与者(年龄 29.3 ± 4.9 岁,男性 = 17 岁)进行的用户实验来评估的。 LanguageMPC自定义了一些指标:故障/碰撞案例、交通流效率、自我车辆的时间成本以及自我车辆驾驶行为的安全性。类似地,Talk2BEV从空间推理、实例属性、实例计数和视觉推理的角度来衡量他们的方法。 GPT-Driver和 DriveLM包含两个指标:L2 错误(以米为单位)和冲突率(以百分比为单位)。通过测量规划轨迹和离线记录的人类驾驶员轨迹中每个路点的距离来计算平均L2误差。它反映了规划轨迹与人类驾驶轨迹的拟合程度。通过在计划轨迹的每个路点放置一个自我车辆框,然后检查与其他物体的地面真实边界框的碰撞来计算碰撞率。它反映了规划轨迹的安全性。目前LLM4AD对于规划任务缺乏统一的衡量标准,无法统一评价每种方法与传统方法的优劣。
3.2 Percetion
大型语言模型在“感知”任务中展示了其独特的价值和强大的能力。尤其是在数据相对稀缺的环境下,这些模型可以依靠其few-shot学习特性来实现快速准确的学习和推理。这种学习能力在自动驾驶系统的感知阶段具有重要意义,大大提高了系统在多变、复杂的驾驶环境中的适应能力和泛化能力。 PromptTrack在提示推理分支中融合跨模态特征来预测 3D 对象。它使用语言提示作为语义线索,并将 LLM 与 3D 检测任务和跟踪任务相结合。尽管与其他方法相比,LLM 取得了更好的性能,但 LLM 的优势并不直接影响跟踪任务。相反,跟踪任务充当查询来协助 LLM 执行 3D 检测任务。 HiLM-D将高分辨率信息合并到多模态大语言模型中,用于风险对象定位以及意图和建议预测 (ROLISP) 任务。它将LLM与2D检测任务相结合,与Video-LLaMa、ePALM等其他多模态大型模型相比,在检测任务和QA任务中获得了更好的性能。值得注意的是,该数据集的一个潜在限制是:每个视频仅包含一个风险对象,这可能无法捕捉现实场景的复杂性。 [Keysan et al., 2023] 将预训练的语言模型集成为基于文本的输入编码器,用于自动驾驶轨迹预测任务。两种模式的联合编码器(图像和文本)比单独使用单个编码器的性能更好。虽然联合模型显着改善了基线,但其性能尚未达到最先进的水平。
Metric:
PromptTrack 使用平均多目标跟踪精度 (AMOTA) 指标 、平均多目标跟踪精度 (AMOTP) 和身份开关 (IDS)指标。 HiLM-D使用 BLEU-4 、METEOR 、CIDER 和 SPICE,IoU 作为与最先进技术进行比较的指标。使用 nuScenes-devkit 中提供的标准评估指标:最小平均位移误差 (minADEk)、最终位移误差 (minFDEk) 和 2 米以上的失误率。
3.3 Question Answering
问答是一项重要任务,在智能交通、辅助驾驶和自动驾驶汽车等领域有着广泛的应用]。它主要通过不同的问答范式来体现,包括传统的QA机制和更详细的视觉QA方法。 [Tang et al., 2023]通过与ChatGPT“聊天”来构建领域知识本体。它开发了一个基于网络的助手,可以在运行时进行手动监督和早期干预,并保证全自动蒸馏结果的质量。这一问答系统增强了车辆的交互性,将传统的单向人机界面转变为交互式的沟通体验,或许能够培养用户的参与感和控制感。这些复杂的模型 [Tang et al., 2023; Xu et al., 2023],具有解析、理解和生成类人响应的能力,在实时信息处理和提供中至关重要。他们设计了与场景相关的综合问题,包括但不限于车辆状态、导航辅助、对交通状况的了解。
Metric:
在QA任务方面,经常使用NLP的metric。在 DriveFPT4 [Xu et al., 2023] 中,它使用 BLEU-4 [Papineni et al., 2002]、METEOR [Banerjee and Lavie, 2005]、CIDER[Vedantam et al., 2015] 和 chatgpt 评分 [Fu et al. ., 2023b]。
3.4 Generation
在“生成”任务领域,大型语言模型利用其先进的知识库和生成能力在特定环境因素下创建逼真的驾驶视频或复杂的驾驶场景[Khachatryan et al., 2023;罗等人,2023b]。这种方法为自动驾驶数据收集和标记的挑战提供了革命性的解决方案,还构建了一个安全且易于控制的设置来测试和验证自动驾驶系统的决策边界。此外,通过模拟各种驾驶情况和紧急情况,生成的内容成为细化和丰富自动驾驶系统应急响应策略的重要资源。
常见的生成模型包括变分自动编码器(VAE)[Kingma and Welling,2022]、生成对抗网络(GAN)[Goodfellow et al., 2014]、归一化流(Flow)[Rezende and Mohamed, 2016],以及去噪扩散概率模型(Diffusion)[Ho et al., 2020]。扩散模型最近在文本到图像方面取得了巨大成功 [Ronneberger et al., 2015; Rombach 等人,2021; Ramesh et al., 2022],一些研究已经开始研究使用扩散模型来生成自动驾驶图像或视频。 DriveDreamer [Wang et al., 2023b] 是一个源自现实世界驾驶场景的世界模型。它使用文本、初始图像、HDmap和3Dbox作为输入,然后生成高质量的驾驶视频和合理的驾驶策略。类似地,Driving Diffusion [Li et al., 2023c] 采用 3D 布局作为控制信号来生成逼真的多视图视频。 GAIA-1 [Hu et al., 2023a] 利用视频、文本和动作输入来生成交通场景、环境要素和潜在风险。在这些方法中,文本编码器都采用 CLIP [Radford et al., 2021],它在图像和文本之间具有更好的对齐效果。除了生成自动驾驶视频外,还可以生成交通场景。 CTG++ [Zhong et al., 2023] 是一种场景级扩散模型,可以生成真实且可控的流量。它利用 LLM 将用户查询转换为可微的损失函数,并使用扩散模型将损失函数转换为现实的、符合查询的轨迹。 MagicDrive [Gao et al., 2023] 生成高度逼真的图像,通过独立编码道路地图、对象框和相机参数来利用 3D 注释中的几何信息,以进行精确的几何引导合成。这种方法有效地解决了多摄像机视图一致性的挑战。尽管与 BEVGen [Swerdlow et al., 2023] 和 BEVControl [Yang et al., 2023a] 相比,它在生成保真度方面取得了更好的性能,但在一些复杂场景中也面临着巨大的挑战,例如夜景和未见的天气条件。
这些方法探索了自动驾驶数据的定制真实生成。尽管这些基于扩散的模型在视频和图像生成指标上取得了良好的效果,但仍不清楚它们是否真的可以用于闭环以真正提高自动驾驶系统的性能。
Metric:
DriveDreamer 和 DrivingDiffusion 使用逐帧 Frechet Inception Distance (FID) 来评估生成图像和 Frechet 的质量视频距离 (FVD)用于视频质量评估。 DrivingDiffusion 还通过将预测布局与地面实况 BEV 布局进行比较,使用可行驶区域的平均交叉路口 (mIoU) 分数和所有对象类别的 NDS 。 CTG++继 [Xu 等人,2022; [Zhong et al., 2022],使用故障率、驾驶档案归一化直方图之间的 Wasserstein 距离、真实性偏差 (real) 和场景级真实性指标 (rel real) 作为指标。 MagicDrive [Gao 等人,2023] 利用道路 mIoU 和车辆 mIoU [Taran 等人,2018] 等分段指标,以及 mAP [Henderson 和 Ferrari,2017] 和 NDS [Yin 等人] 等 3D 对象检测指标.。
Datasets in LLM4AD
传统数据集,例如 nuScenes 数据集 [Caesar et al., 2019; Fong et al., 2021]缺乏用于与LLM互动的动作描述、详细标题和问答对。 BDD-x [Kim 等人,2018]、Rank2Tell [Sachdeva 等人,2023]、DriveLM [贡献者,2023]、DRAMA [Malla 等人,2023]、NuPrompt [Wu 等人,2023] 和NuScenes-QA [Qian et al., 2023] 数据集代表了 LLM4AD 研究的关键进展,每个数据集通过广泛、多样化和场景丰富的注释为理解代理行为和城市交通动态做出了独特的贡献。我们在表 1 中给出了每个数据集的摘要。我们在下面给出了详细的描述。
BDD-X 数据集 [Kim et al., 2018]:该数据集在 6,970 个视频中捕获了超过 77 小时的不同驾驶条件,是现实世界驾驶行为的集合,每个行为都附有描述和解释。它包括跨 840 万帧的 26K 活动,从而为理解和预测不同条件下的驾驶员行为提供了资源。
本田研究院建议数据集 (HAD) [Kim et al., 2019b]:HAD 提供 30 小时的驾驶视频数据,搭配自然语言建议以及与 CAN 总线信号数据集成的视频。该建议包括旨在引导车辆执行导航任务的目标导向建议(自上而下的信号)和突出显示用户期望车辆控制器主动关注的特定视觉提示的刺激驱动的建议(自下而上的信号)。
Talk2Car [Deruyttere et al., 2019]:Talk2Car 数据集包含针对 nuScenes 850 个视频的 11959 个命令 [Caesar et al., 2019; Fong et al., 2021] 训练集作为 3D 边界框注释。其中,55.94%的命令来自波士顿录制的视频,44.06%来自新加坡。平均每个命令包含 11.01 个单词,其中包括 2.32 个名词、2.29 个动词和 0.62 个形容词。通常,每个视频中约有 14.07 个命令。它是一个对象引用数据集,包含用自然语言编写的自动驾驶汽车命令。
DriveLM 数据集 [贡献者,2023]:该数据集将类人推理集成到自动驾驶系统中,增强感知、预测和规划 (P3)。它采用“思维图”结构,通过“假设”场景鼓励未来主义方法,从而促进驾驶系统中先进的、基于逻辑的推理和决策机制。
Drama数据集 [Malla et al., 2023]:从东京街道收集,包括使用摄像机捕获的 17,785 个场景剪辑,每个剪辑的持续时间为 2 秒。它包含不同的注释:视频级问答、对象级问答、风险对象边界框、自由格式标题、自我汽车意图的单独标签、场景分类器以及给驾驶员的建议。
Rank2Tell 数据集 [Sachdeva et al., 2023]:它是从旧金山湾区高度互动的交通场景中的移动车辆捕获的。它包括 116 个 10FPS 剪辑(每个 20 秒),使用配备三台 Point Grey Grasshopper 摄像机(分辨率为 1920 × 1200 像素)、Velodyne HDL-64E S2 LiDAR 传感器和高精度 GPS 的仪表车辆捕获。该数据集包括视频级 Q/A、对象级 Q/A、LiDAR 和 3D 边界框(带跟踪)、3 个摄像头的视野(缝合)、重要对象边界框(每帧多个重要对象,具有多个级别)重要性高、中、低)、自由格式标题(每个对象多个对象的多个标题)、自我汽车意图。
NuPrompt 数据集 [Wu et al., 2023]:它代表了 nuScenes 数据集的扩展,丰富了专门为驾驶场景设计的带注释的语言提示。该数据集包含 35,367 个 3D 对象的语言提示,平均每个对象有 5.3 个实例。该注释增强了数据集在自动驾驶测试和训练中的实用性,特别是在需要语言处理和理解的复杂场景中。
NuScenes-QA 数据集 [Qian et al., 2023]:这是一个自动驾驶数据集,包含来自 34,149 个不同视觉场景的 459,941 个问答对。它们被分为来自 28,130 个场景的 376,604 个问题用于训练,来自 6,019 个场景的 83,337 个问题用于测试。 NuScenes-QA 展示了各种问题长度,反映了不同的复杂程度,这对 AI 模型来说具有挑战性。除了纯粹的数字之外,该数据集还确保了问题类型和类别范围的平衡,从识别对象到评估其行为,例如它们是在移动还是停车。这种设计抑制了模型出现偏见或依赖语言捷径的倾向。
Conclusion
在本文中,我们对 LLM4AD 进行了全面的调查。我们对使用LLM进行自动驾驶的不同应用进行了分类和介绍,并总结了每个类别中的代表性方法。同时我们总结了LLM4AD相关的最新数据集。我们将继续关注该领域的发展并突出未来的研究方向。


















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









