






0 概括
本文用于记录 x86-Linux 应用程序发生持续性内存泄漏问题时的定位方法。主要介绍valgrind工具的应用。
1 原理
对于内存泄漏问题的定位,一种朴素的想法就是对内存申请点进行监控。对于一个内存申请调用点(例如c/c++中的malloc函数),记录下该调用点被触发时的调用栈 c a l l s t a c k callstack callstack,以及申请到的内存 m e m o r y memory memory。同一个调用栈可能申请多次内存,我们把申请到的内存都记录下来,于是我们得到了一个统计表,表中元素长这样: ( c a l l s t a c k i , { m e m o r y i 1 , m e m o r y i 2 , . . . } ) (callstack_i,\{memory_{i}^{1},memory_{i}^{2},...\}) (callstacki,{memoryi1,memoryi2,...})。当 m e m o r y i j memory_{i}^{j} memoryij内存被释放(例如c/c++中的free函数),则把统计表中的 m e m o r y i j memory_{i}^{j} memoryij项删除即可。如此一来,当程序结束,依旧持有 m e m o r y memory memory的那些 c a l l s t a c k callstack callstack就可以认为是潜在的内存泄漏点。
上述的朴素想法,ASAN工具已经帮我们实现。本文讨论更特殊的场景,对ASAN工具的使用不再赘述。在程序持续运行,持续内存泄漏的场景中,我们需要对上述朴素想法做一点点改变。在 t i m e s t a m p timestamp timestamp时刻,我们记录一下该时刻的统计表 ( c a l l s t a c k i , { m e m o r y i 1 , m e m o r y i 2 , . . . } ) (callstack_i,\{memory_{i}^{1},memory_{i}^{2},...\}) (callstacki,{memoryi1,memoryi2,...})。随程序的运行,我们便得到了一张随时间变化的统计表 [ t i m e s t a m p , { ( c a l l s t a c k i , { m e m o r y i 1 , m e m o r y i 2 , . . . } } ) ] [timestamp, \{(callstack_i,\{memory_{i}^{1},memory_{i}^{2},...\}\})] [timestamp,{(callstacki,{memoryi1,memoryi2,...}})]。某一时刻的统计表我们称之为一个内存切片。如此一来,当我们观测到一个 c a l l s t a c k i callstack_i callstacki的内存持有量随时间不断增加,则可以识别该点为潜在的内存泄漏点。这种内存切片的想法,valgrind工具已经帮我们实现。
2 valgrind工具的使用
本文不详细介绍valgrind工具,只通过简单案例介绍如何使用valgrind工具形成内存切片图。
x86-Linux服务器环境,先执行以下命令安装valgrind工具。
sudo apt install valgrind
sudo apt install massif-visualizer
再给出一个持续运行持续内存泄漏的简单范例main.cpp。
#include <thread>
#include <chrono>
#include <vector>
#include <string>
void sleepMs(int milliseconds) {
std::this_thread::sleep_for(std::chrono::milliseconds(milliseconds));
}
int main(int /*argc*/, char** /*argv*/) {
std::vector<std::string> vec;
while(true) {
// 新增10个数据
for (size_t i = 0; i < 10U; i++) {
vec.push_back(std::string(1000000, 'A'));
sleepMs(100);
}
// 释放9个数据
for (size_t j = 0; j < 9U; j++) {
vec.pop_back();
sleepMs(100);
}
}
return 0;
}
对应的编译命令为g++ -g -o exe main.cpp。

接下来使用valgrind运行这个程序,生成内存切片。对应的命令为
valgrind --tool=massif --time-unit=B ./exe
运行一段时间后,ctrl+c结束程序,就生成了对应的内存切片文件massif.out.<pid>。使用可视化工具打开这个内存切片文件,执行命令与效果如下。
massif-visualizer massif.out.<pid>
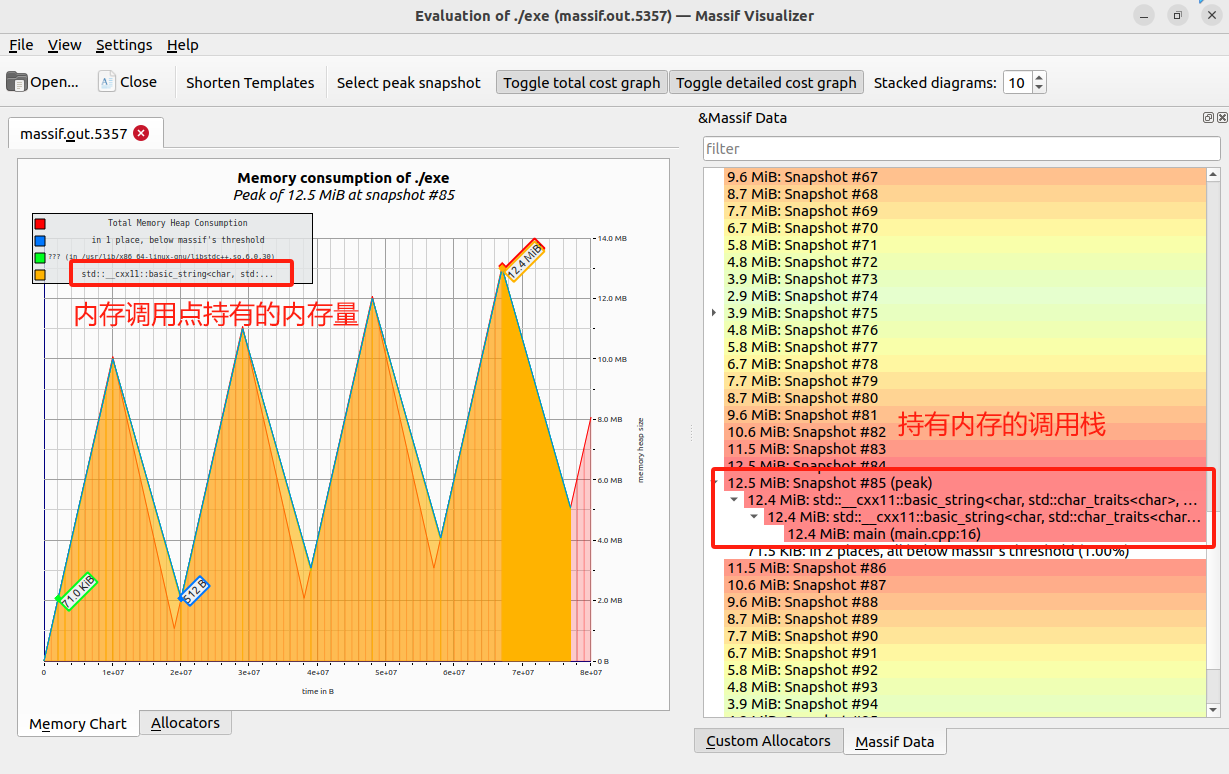
可以看到调用点持有的内存量随时间的变化,还可以看到不同时刻,各调用栈持有的内存量。至此可以协助我们分析持续性的内存泄漏。
2.1 valgrind常用参数解释
Linux系统下可以通过man valgrind命令查看valgrind提供的具体参数及其含义。本小节重点介绍massif工具相关的几个参数。以下给出一个长时间监控的命令参数范例,再对其参数进行简单介绍。
valgrind --tool=massif \
--threshold=0.1 \
--peak-inaccuracy=1.0 \
--time-unit=ms \
--detailed-freq=8 \
--max-snapshots=128 \
--massif-out-file=massif.out \
<进程名字> <进程运行参数>
| 参数 | 解释 |
|---|---|
| –tool=massif | 使用valgrind中的massif工具进行内存检测,valgrind还提供了memcheck等一系列其他工具,请自行查阅,这里不赘述。 |
| –threshold=0.1 | 在内存切片里,内存持有量小于总内存的threshold%部分会被聚合成一个小块,提高threshold可以过滤掉那些小块的内存,关注大的内存分配情况。 |
| –peak-inaccuracy=1.0 | valgrind会识别出现内存占用峰值的时刻,并详细记录峰值时刻内存切片。这个peak-inaccuracy就是辅助valgrind识别是否出现内存峰值的,当内存占用上涨超过原有peak-inaccuracy%时,valgrind识别当前时刻为峰值时刻。提高peak-inaccuracy可以避免内存占用抖动引发频繁地记录详细切片。 |
| –time-unit=ms | 告诉valgrind什么时候触发一次内存切片,ms为1ms触发一次。注意valgrind中区分内存切片与详细内存切片。普通内存切片可能就只是记录一个总的内存占用,而详细内存切片则是记录下具体的内存持有调用栈。控制是否记录详细切片,参考detailed-freq参数。 |
| –detailed-freq=8 | 为提高效率,valgrind并不是每次内存切片都详细记录内存调用栈,大多数时候valgrind只记录总的内存占用量,只对关键时刻,如启动,峰值等特殊情况,才记录详细调用栈。detailed-freq参数则是告诉valgrind间隔多少个内存切片就记录一次详细内存切片。detailed-freq=1是最保守的方法,每次切片都会详细记录,但是也会引入更大的开销。笔者建议大家使用2^n作为间隔。 |
| –max-snapshots=128 | valgrind监控程序时,内部维护的内存切片队列的有限的。当内存切片记录条数超过了队列大小时,valgrind会抛弃掉当前队列的一些记录,重新把队列空出来。大体上可以认为,每次队列满时,valgrind会对队列进行1/2采样,即只保留奇数(或偶数)位置的记录,一下子把一半的队列空出来,然后内存切片采样频率也同时降低一半,直到队列被再次塞满。max-snapshots参数就是队列大小。一般而言,最总的统计文件中,统计条数在[max-snapshots/2, max-snapshots]之间,valgrind文档中也有相关的描述。 |
| –massif-out-file=massif.out | 指定内存切片输出文件的文件名。 |
3 结论
本文记录持续内存泄漏问题的一种定位方法,记录valgrind工具的使用。但是valgrind工具会极大影响程序性能。对商用程序,如果设计得不好,性能受影响的情况下有可能功能都不正常。所以本文方法只是一种参考,具体情况还需要具体分析。

















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









