







Tab键自动完成
Tab键自动完成功能是对标准Python shell的主要改进之一,大部分交互式数据分析环境都有这个功能。在shell中输入表达式时,只要按下Tab键,当前命名空间中任何与已输入的字符串相匹配的变量(对象/函数等)就会被找出来
In [10]: an_apple=27
In [11]: an_example=42
In [13]: an//这里按住Tab键
an_apple an_example and any
还显示了python关键字and和内值函数any。可以在任何对象后面输入一个句点以便自动完成方法和属性的输入:
In [14]: b=[1,2,3]
In [15]: b.//这里按住Tab键
b.append b.extend b.insert b.remove b.sort
b.count b.index b.pop b.reverse
In [15]: b.
这一效果还可以使用在import出的模块上
Tab键自动完成功能不只可以用于搜索命名空间和自动完成对象或模块属性,当输入任何看上去像是文件路径的东西时(即使是在一个Python字符串中),按下Tab键即可找出电脑文件系统中与之匹配的东西:(要使用正斜杠/,不然认不出来。文件夹或文件名中间不能有空格,不然也无法正常继续操作)

内省
在变量的前面或后面加上一个问号,就可以将有关该对象的一些通用信息显示出来:
In [17]: b?
Type: list
String form: [1, 2, 3]
Length: 3
Docstring:
list() -> new empty list
list(iterable) -> new list initialized from iterable's items这就叫做对象内省(object introspection)
如果该对象是一个函数或实例方法,则其docstring也会被显示出来//docstring是一个函数或者模块的帮助文档
?还有一个用法,即搜索ipython命名空间,一些字符再配以通配符(*)即可显示出所有与该通配符表达式相匹配的名称
%run命令
在ipython会话环境中,所有文件都可以通过%run命令当做python程序来运行。
记得要加路径!!!书实在是太坑了QAQ
In [1]: %run /home/mint/workspace/hello.py
hello world
In [2]: 中断正在执行的代码
不管是通过%run执行的脚本,还是长时间运行的命令,只要按下Ctrl+C,就会印发一个KeyboardInterrupt,除了一些非常特殊的情况之外,绝大部分python程序都将立即停止执行
特殊情况【抠鼻】:当python代码已经调用了某个已编译的拓展模块时,按下Ctrl+C将无法使程序立即停止执行。在这种情况下,要么只能等待python解释器重新获得控制权,要么之恩那个通过操作系统的任务管理器强制终止python进程
执行剪贴板中的代码
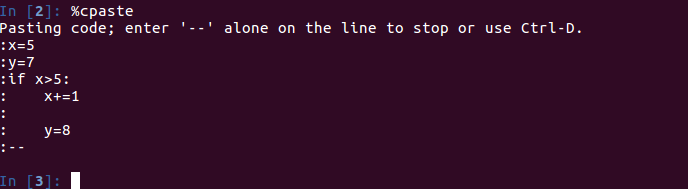
在ipython中执行代码最简单方式是粘贴剪贴板中的代码(比如你在网上找了一段合用的代码,但又不想专门为其新建一个.py文件)
多数情况下,我们都可以通过“Ctrl-Shift-V”将剪贴板中的代码片粘贴出来
特殊情况【抠鼻】:这种粘贴方式模拟的是在ipython中逐行输入代码,换行符会被处理为,如果粘贴的是一段缩进代码,并且其中有一个空行,ipython就会认为缩进在空行那里结束了。当执行到缩进块后面的那行代码是,就会出现【IndentationError】
但是,我们有解决方法:使用%paste和%cpaste魔术函数
键盘快捷键

异常和跟踪
如果%run某段脚本或执行某条语句时发生了异常,ipython默认会输出整个调用栈跟踪(traceback),其中还会附上调用栈个点附近的几行代码作为上下文参考
魔术命令
%timeit 检测任意python语句的执行时间
%reset 将命名空间都替换成用户定义的



搜索并重用命令历史

输入和输出变量
输入的文本被保存在名为_iX的变量中,其中X是输入行的行号
每个输入变量都有一个对应的输出变量_X.
与操作系统交互


交互式调试器
在发生异常之后马上输入%debug命令,将会调用“事后”调试器,并直接跳转到引发异常的那个栈帧(stack frame)
在这个调试器中,可以执行任意python代码并查看各个栈帧的一切对象和数据(解释器还留了条生路的那些)默认是从最低级开始的(即错误发生的地方),输入U(或up)和d(或down)即可在栈跟踪的各级别之间切换
执行%pdb命令可以让ipython在出现异常之后自动调用调试器
调试器还可以为代码开发工作提供帮助,当想要设置断点或对函数/脚本惊醒单步调试以查看各条语句的执行情况时。首先使用带有-d选项的%run命令,这将会在执行脚本文件中的代码之前先打开调试器,然后输入s进入脚本,在某个地方设置断点,然后输入c(或continue)使脚本一直运行下去直到该断点时为止。单步前进到发生错误的那一行,查看在此范围内的变量。调试器命令的优先级高于变量名。在变量前面加上感叹号(!)即可查看其内容
python调试器命令


重新加载模块依赖项
在python中,当输入import some_lib时,这个里面的代码就会被执行,且其中所有的变量、函数和引用项都会被保存在一个新建的some_lib模块命名空间中。当下次再输入import some_lib时,就会得到这个模块命名空间的一个引用。这对于ipython的交互式代码开发模式就会有一个问题,比如说,用%run执行的某段脚本牵扯到了某个刚刚做了修改的模块。假设我们有一个test_script.py文件,其中有下列代码:
import some_lib
x=5
y=[1,2,3,4]
result=some_lib.get_answer(x,y)如果在执行了%run test_script.py之后又对some_lib.py进行了修改,下次再执行%run test_script.py时将仍然会使用老版的some_lib。原因是python的“一次加载”模块系统。这个行为不同于其他一些数据分析环境(matlab会自动应用代码修改)。
有两个解决方案
1.使用python内置的reload函数,将test_script.py修改成下面这个样子:
import some_lib
reload(some_lib)
x=5
y=[1,2,3,4]
result=some_lib.get_answer(x,y)
这样就可以保证了。
2.但是,当依赖变得更强时,就需要在很多地方插入很多的reload。对于这个问题,ipython 提供了一个特殊的dreload 函数来解决模块的递归重加载。如果执行import some_lib之后再输入dereload(some_lib)则他会尝试重新加载some_lib及其所有的依赖项
3.如果真的不行了。。。。重启ipython就行了















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









