







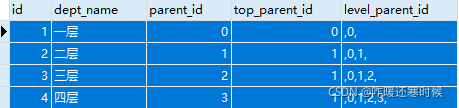
项目开发过程中经常会遇到具有层级关系的数据,进行表结构设计时可设计如下四个必备参数:
参数1:id(表主键id,一般为int类型)
- 一般为int类型,可设置主键自增
参数2:parent_id(直属父级id)
- 和id相同类型,一般为int类型
- 顶级数据parent_id为0,即没有父级的时候parent_id为0
- 有父级的时候parent_id的值为直属父级的id值
参数3:top_parent_id(顶级父级id)
- 和id相同类型,一般为int类型
- 顶级数据top_parent_id为0,即没有父级的时候top_parent_id为0
- 有父级的时候top_parent_id的值为顶级父级(类似于根节点)的id值
参数4:level_parent_id(层级父级id)
- varchar类型,字符串
- 顶级数据level_parent_id为英文逗号+0+英文逗号(,0,)即没有父级的时候level_parent_id=,0,
- 层级父级id值为每一层父级的id值拼接,中间用英文逗号隔开,首位都带有英文逗号
示例请看下图:














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









