







序言
本教程直接面向华中科技大学计算机专业大数据导论课程结业项目,是基础向教程,不涉及进阶应用
经过一学期的大数据导论学习后,我们突然接到了结业大作业——进行一次大数据分析项目的通知。
刚刚学习了一些大纲类型的知识的我们自然是不知所措的,经过资料查阅后我们决定通过虚拟机搭建Hadoop集群进行伪分布式计算完成该项目,然后就开始了安装了20次虚拟机的折磨之路。
由于我本人非常反感由于某些原因(如网络教程版本,库名修改等)去在仅使用基础功能的项目中强行使用老版本的,一个正常软件的正常迭代一定是不会删除功能的,一定会有更好的实现方法来替代。只要思想不滑坡,办法总比困难多,这也是本文诞生的初衷之一,遇到问题就要去解决问题,而不是盲目地退回老版本。
本博客同时也作为 视频教程 的台本方便各位查阅,对Linux基础操作不熟悉的同学可以对着视频一步步操作,对应代码可以直接复制博客中代码。
搭建环境
- CentOS v7.9.2009
- jdk-8u202-linux-x64(1.8.202)
- Hadoop-v3.3.1
- VMWare Workstation Player 16
推荐下载地址
- CentOS 下载地址:THU镜像站(亲测可以满速)
- 下载列表 7.9.2009
- 选择如图所示选项,也可以直接点击下方下载链接(一样的)

- 选择如图所示选项,也可以直接点击下方下载链接(一样的)
- 完整包下载地址 7.9.2009
- 下载列表 7.9.2009
- jdk 下载地址
- Oracle 官方(需要网络环境+注册登录账号)
- 注意选择 Linux x64 Compressed Archive

- Java Archive Downloads - Java SE 8u211 and later (oracle.com)
- jdk17 Downloads | Oracle
- 注意选择 Linux x64 Compressed Archive
- 阿里网盘:分享已被删除
- Oracle 官方(需要网络环境+注册登录账号)
- Hadoop 下载地址(THU镜像):hadoop-v3.3.1
- VMWare Player 下载地址(官方):VMware Workstation Player - VMware Customer Connect
搭建目标
搭建一个1主机+2从机的Hadoop伪分布式集群(因为并没有真正利用到分布式的特性,只是采用了分布式的形式所以叫伪分布式),并进行简单的wordcount示例计算
Hadoop 安装与配置
Ⅰ 系统安装与基础配置
-
虚拟机环境:VMWare Workstation 16 Player
- 选择该软件的原因有
- 普适性强:网络上有很多相关资料可供查阅
- 免费:支持正版!苦逼大学生自然是用不起企业级的Pro版本的~~(如果家境优渥可以考虑一下)另外希望学校可以把Workstation Pro也纳入正版平台~~
- 如果有方法可以用Pro版,更加稳定(有虚拟网络编辑器)
- 没有虚拟网络编辑器,DHCP动态分配可能导致后续网段不稳定
- 选择该软件的原因有
-
系统选择:CentOS 7 64-bit
- CentOS,大家的选择!稳定又轻量!而且还免费!
- 安装的时候可以选择最小安装,毕竟安一个桌面没啥用还费资源
安装步骤
虚拟机创建与系统安装
VMWare Player的下载与安装不会的建议自行百度
- 在Player中选择新建一个虚拟机

- 在弹出窗口中选择 稍后安装(如果此时选择直接安装会默认安装桌面GUI,会占用大量资源且没有作用
当然如果你电脑强到可以随便霍霍当我没说)
- 一直下一步直到这一步,名称和位置都自己选一下
- 然后一直下一步到完成即可
- 在这个界面双击打开虚拟机
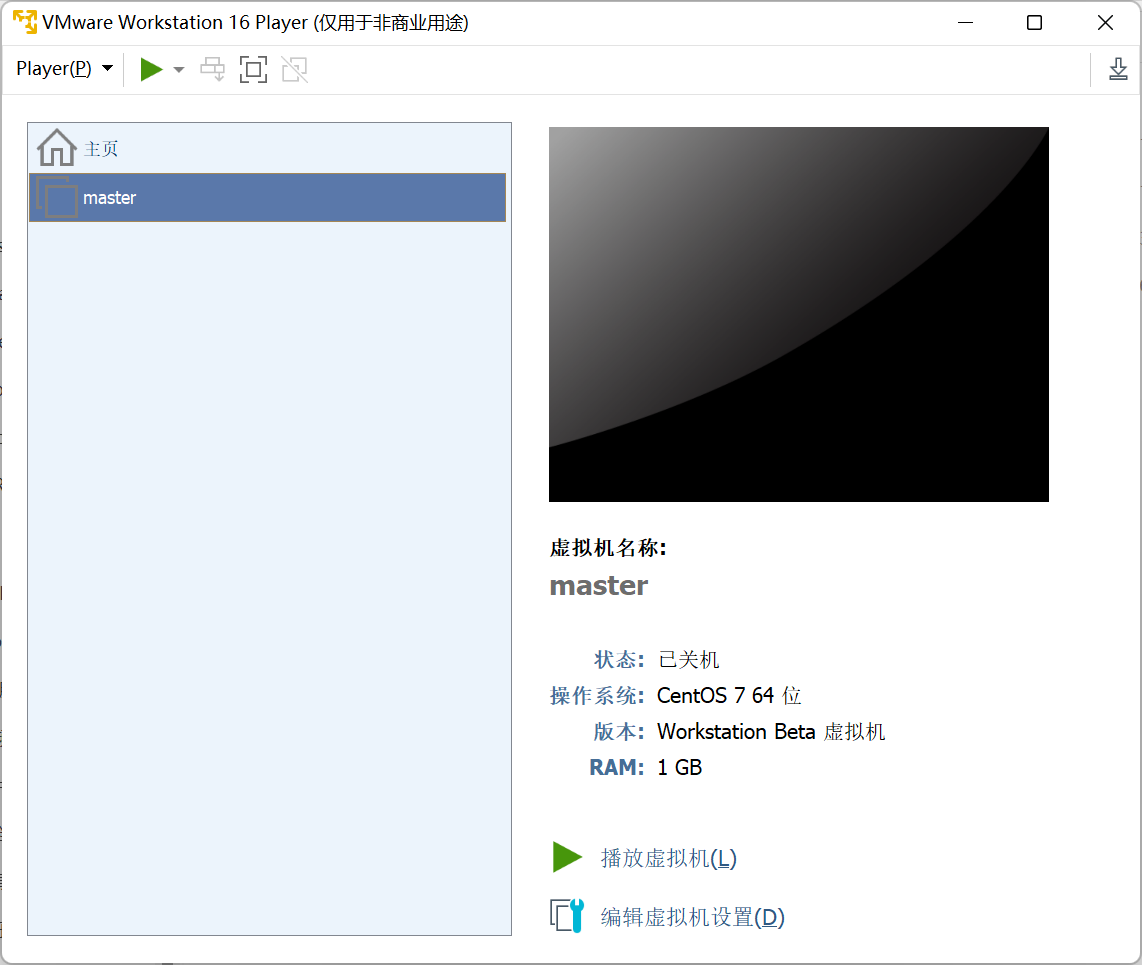
- 进入虚拟机后会弹出一个是否连接的对话框,选择是
- 进入页面后选择如下选项
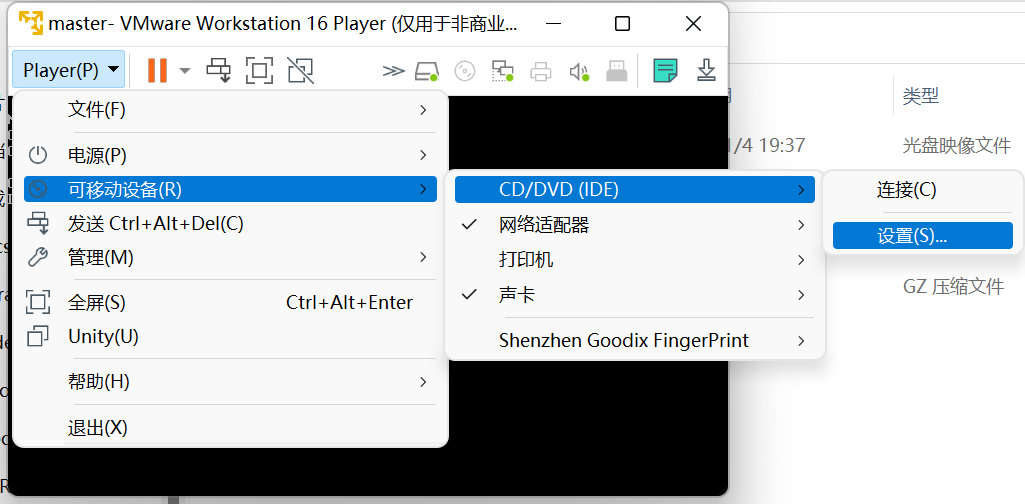
- 在弹出窗口中选择 使用ISO映像 并选择下载的镜像,并勾选 已连接
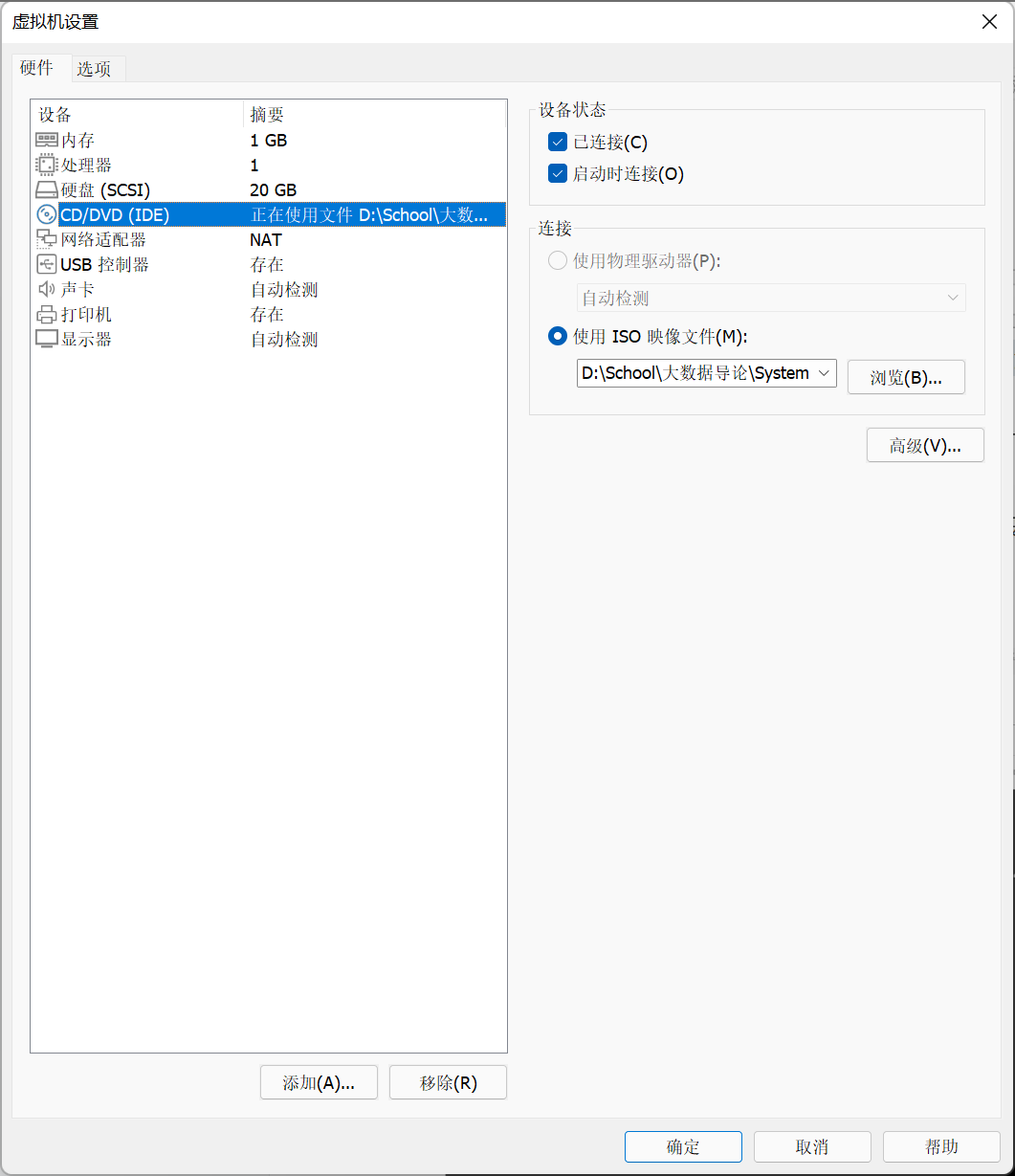
- 确定后通过如下方式重启虚拟机,等待进入安装界面
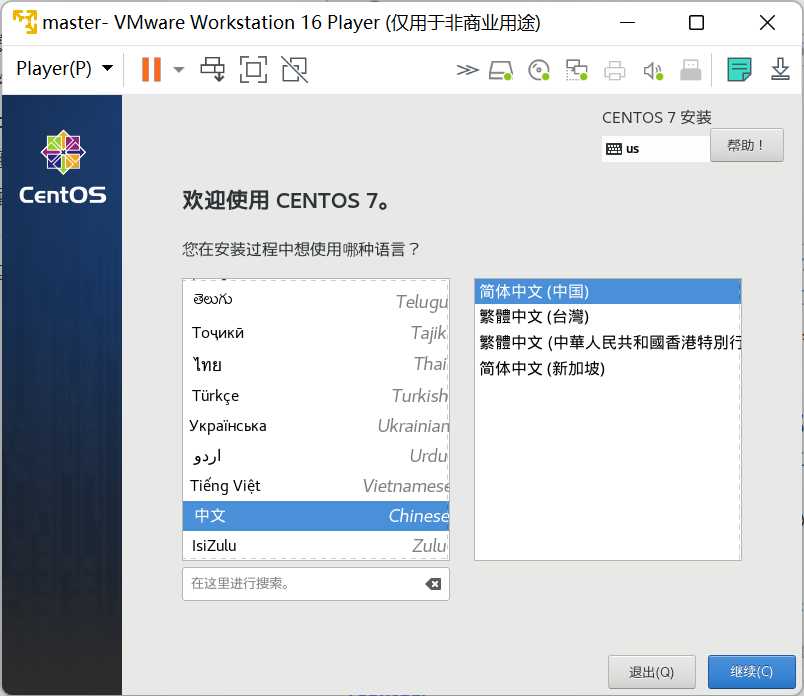
- 首先选择语言
- 继续后依次配置需要配置的三项
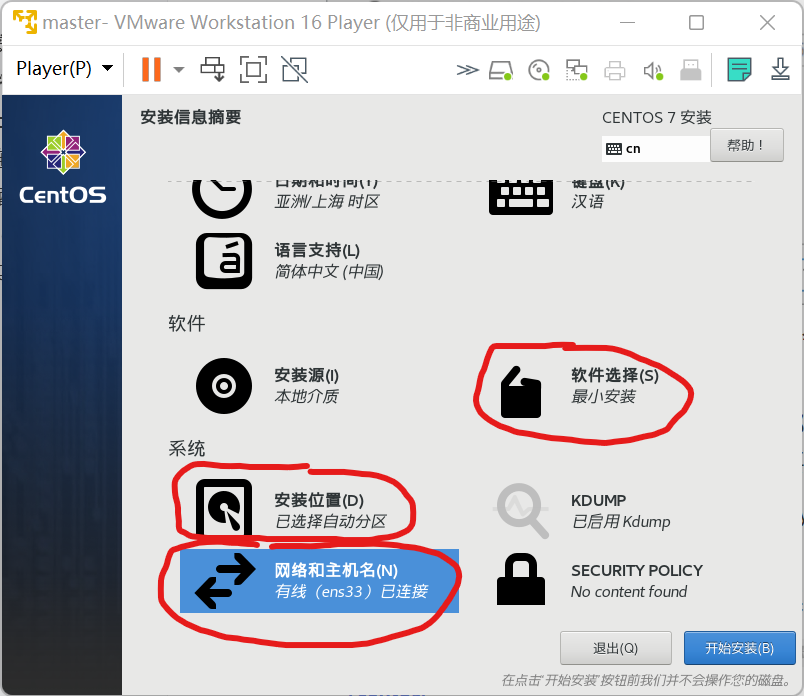
- 网络配置[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o2uEodRh-1643099750664)(C:/Users/kirito/AppData/Roaming/Typora/typora-user-images/image-20220125152456308.png)]
- 软件选择
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









